Перевод статьи Брайна Беренда.
Когда вы впервые приступаете к изучению теории анализа и обработки данных, то одними из первых вы изучаете алгоритмы классификации. Их суть проста: берётся информация о конкретном результате наблюдений (data point), на основании которой этот результат относится к определённой группе или классу.
Хороший пример — спам-фильтр электронной почты. Он должен помечать входящие письма (то есть результаты наблюдений) как «спам» или «не спам», ориентируясь на информацию о письмах (отправитель, количество слов, начинающихся с прописных букв, и так далее).

Это пример хороший, но скучный. Спам-классификацию приводят в качестве примера на лекциях, презентациях и конференциях, так что вы наверняка уже не раз слышали о нём. Но что если поговорить о другом, более интересном алгоритме классификации? Каком-то более странном? Более… волшебном?
Всё верно! Сегодня мы поговорим о Распределяющей шляпе (Sorting Hat) из мира Гарри Поттера. Возьмём какие-то данные из сети, проанализируем и создадим классификатор, который будет сортировать персонажей по разным факультетам. Должно получиться забавно!
Примечание:
Наш классификатор будет не слишком сложным. Так что его нужно рассматривать как «первичный подход» к решению проблемы, демонстрирующий некоторые базовые методики извлечения текста из сети и его анализа. Кроме того, учитывая относительно небольшой размер выборки, мы не будем использовать классические обучающие методики вроде перекрёстной проверки. Мы просто соберём определенные данные, построим простой классификатор на основе правил и оценим результат.
Второе примечание:
Идея этого поста навеяна прекрасной презентацией Брайана Ланга на конференции PyData Chicago 2016. Видеозапись здесь, слайды здесь.
На случай, если последние 20 лет вы провели в пещере: Распределяющая шляпа — это волшебная шляпа, которая помещает поступающих студентов по четырём факультетам Хогвартса: Гриффиндор, Слизерин, Хаффлпафф и Рэйвенклоу. У каждого факультета свои характеристики. Когда шляпу надевают на голову студента, она считывает его разум и определяет, какой факультет подходит ему лучше всего. Согласно этому определению, Распределяющая шляпа — это многоклассовый классификатор (multiclass classifier) (сортирует более чем по двум группам), в отличие от бинарного классификатора (сортирует строго по двум группам), которым является спам-фильтр.
Чтобы распределить студентов по факультетам, нам нужно знать о них определенную информацию. К счастью, достаточно данных есть на harrypotter.wikia.com. На этом сайте лежат статьи почти по всем аспектам вселенной Гарри Поттера, включая описания студентов и факультетов. Приятный бонус: компания Fandom, заведующая сайтом, предоставляет простой в использовании API и массу прекрасной документации. Ура!

Начнём с импортирования
Также нам нужно грамотно пройтись по всем студентам Хогвартса и записать факультеты, по которым они раскиданы Распределяющей шляпой (это будут «реальные данные», с которыми мы будем сравнивать результаты нашей сортировки). На сайте статьи разбиты по категориям, вроде «Студенты Хогвартса» и «Фильмы». API позволяет создавать списки статей в рамках конкретной категории.
Возьмём для примера Рэйвенклоу. Закинем все данные в переменную
Количество статей: 158
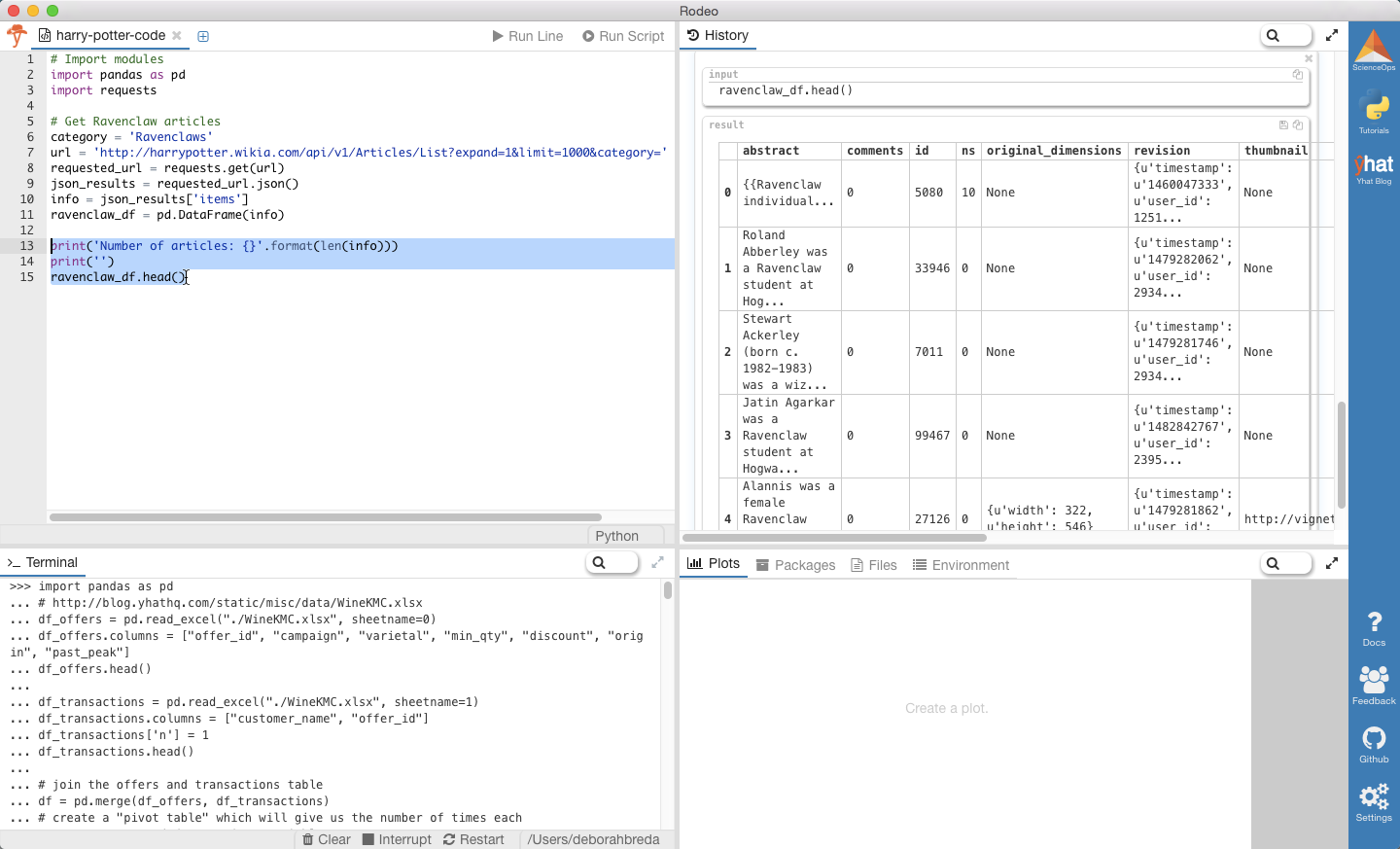
Вы можете проследить полное выполнение анализа с помощью Rodeo!
Примечание:
Если воспользуетесь нашим Python IDE, Rodeo, то просто скопируйте и вставьте вышеприведённый код в Editor или Terminal. Результат вы увидите в окне History или Terminal. Бонус: можно просто перетаскивать окна мышью, меняя их расположение и размер.
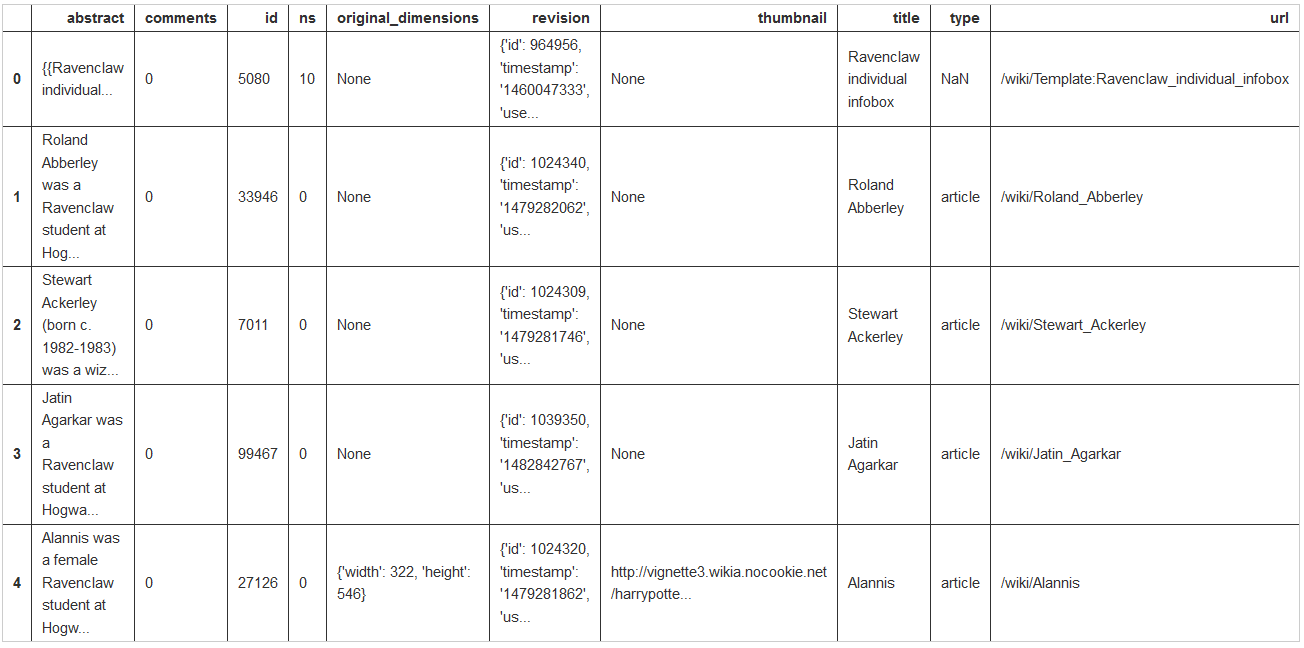
На основе этих данных мы узнаем:
Количество статей о студентах: 748

Имея ID статей, мы можем начать запрашивать содержания. Но некоторые из статей просто ОГРОМНЫ, они содержат невероятное количество подробностей. Вы только взгляните на статьи про Гарри Поттера и Волан-де-Морта!

В статьях про всех ключевых персонажей есть раздел «Личность и черты характера». Логично было бы извлекать отсюда информацию, которую Распределяющая шляпа будет использовать при принятии решений. Но такой раздел есть не во всех статьях, так что если ориентироваться только на него, то количество персонажей сильно уменьшится.
Нижеприведённый код извлекает из каждой статьи раздел «Личность и черты характера» и вычисляет его длину (количество знаков). Затем на основе ID объединяет эти данные с нашим начальным фреймом данных mydf (на это уходит немного времени).
Количество подходящих статей: 94

Теперь мы знаем количество студентов, надо распределить их по факультетам. Для этого составим список характеристик каждого факультета. Начнём собирать из с harrypotter.wikia.com.
Обратите внимание, что все слова — существительные. Это хорошо. Нам нужна консистентность при описании черт характера. Некоторые из них были представлены не в виде существительных, так что приведём их к общему порядку:
Получив список характеристик для каждого факультета, можем просто сканировать колонку «Текст» и подсчитать, сколько раз использовались соответствующие слова в описаниях персонажей. Звучит несложно, верно?
К сожалению, это ещё не всё. Вот фраза из раздела «Личность и черты характера» про Невила Лонгботтома:
Выделенные слова должны засчитываться в пользу каких-то факультетов, но они не будут засчитаны, потому что являются прилагательными. Также не будут учтены слова вроде «bravely» и «braveness». Чтобы наш алгоритм классификации работал правильно, нужно идентифицировать синонимы, антонимы и другие словоформы.
Исследовать синонимы можно с помощью функции
Озадачены? Давайте запустим код, а затем разберём его:
Synonym sets associated with the word 'bravery': [Synset('courage.n.01'), Synset('fearlessness.n.01')]
Synonym sets associated with the word 'fairness': [Synset('fairness.n.01'), Synset('fairness.n.02'), Synset('paleness.n.02'), Synset('comeliness.n.01')]
Synonym sets associated with the word 'wit': [Synset('wit.n.01'), Synset('brain.n.02'), Synset('wag.n.01')]
Synonym sets associated with the word 'cunning': [Synset('craft.n.05'), Synset('cunning.n.02'), Synset('cunning.s.01'), Synset('crafty.s.01'), Synset('clever.s.03')]
Synonym sets associated with the noun 'cunning': [Synset('craft.n.05'), Synset('cunning.n.02')]
('courage.n.01', ['courage', 'courageousness', 'bravery', 'braveness']) ('fearlessness.n.01', ['fearlessness', 'bravery']) ('fairness.n.01', ['fairness', 'equity']) ('fairness.n.02', ['fairness', 'fair-mindedness', 'candor', 'candour']) ('paleness.n.02', ['paleness', 'blondness', 'fairness']) ('comeliness.n.01', ['comeliness', 'fairness', 'loveliness', 'beauteousness']) ('wit.n.01', ['wit', 'humor', 'humour', 'witticism', 'wittiness']) ('brain.n.02', ['brain', 'brainpower', 'learning_ability', 'mental_capacity', 'mentality', 'wit']) ('wag.n.01', ['wag', 'wit', 'card']) ('craft.n.05', ['craft', 'craftiness', 'cunning', 'foxiness', 'guile', 'slyness', 'wiliness']) ('cunning.n.02', ['cunning'])
Так, мы получили много выходных данных. Рассмотрим некоторые моменты и потенциальные проблемы:
Как вы могли заметить, функция
Перевод: получить синонимы труднее, чем кажется

После того, как мы собрали все синонимы, нужно позаботиться об антонимах и разных словоформах (например, применительно к «bravery» — «brave», «bravely» и «braver»). Немало тяжёлой работы можно выполнить в nltk, но всё же придётся вручную набивать деепричастия и прилагательные в сравнительной / превосходной степени.
Synset: courage.n.01; Lemma: courage; Antonyms: [Lemma('cowardice.n.01.cowardice')]; Word Forms: [Lemma('brave.a.01.courageous')]
Synset: courage.n.01; Lemma: courageousness; Antonyms: []; Word Forms: [Lemma('brave.a.01.courageous')]
Synset: courage.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Synset: courage.n.01; Lemma: braveness; Antonyms: []; Word Forms: [Lemma('brave.a.01.brave'), Lemma('audacious.s.01.brave')]
Synset: fearlessness.n.01; Lemma: fearlessness; Antonyms: [Lemma('fear.n.01.fear')]; Word Forms: [Lemma('audacious.s.01.fearless'), Lemma('unafraid.a.01.fearless')]
Synset: fearlessness.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Следующий код создаёт список синонимов, антонимов и словоформ для каждой характеристики факультетов. Для полноты анализа некоторые из слов могут быть записаны неправильно.
Характеристики Гриффиндора: ['bold', 'bolder', 'boldest', 'boldly', 'boldness', 'brass', 'brassier', 'brassiest', 'brassily', 'brassiness', 'brassy', 'brave', 'bravely', 'braveness', 'braver', 'bravery', 'bravest', 'cheek', 'cheekier', 'cheekiest', 'cheekily', 'cheekiness', 'cheeky', 'chivalry', 'courage', 'courageous', 'courageouser', 'courageousest', 'courageously', 'courageousness', 'daring', 'face', 'fearless', 'fearlesser', 'fearlessest', 'fearlessly', 'fearlessness', 'gallantry', 'hardihood', 'hardiness', 'heart', 'mettle', 'nerve', 'nervier', 'nerviest', 'nervily', 'nerviness', 'nervy', 'politesse', 'spunk', 'spunkier', 'spunkiest', 'spunkily', 'spunkiness', 'spunky']
Антихарактеристики Гриффиндора: ['cowardice', 'fear', 'timid', 'timider', 'timidest', 'timidity', 'timidly', 'timidness']
Есть какие-то повторы в словаре черт характера? False
Повторы в словаре антонимов? False

Пришло время распределить студентов по факультетам! Наш алгоритм классификации будет работать следующим образом:
Допустим, в разделе «Личность и черты характера» есть лишь предложение «Алиса была храброй». Тогда Алиса получит 1 балл для Гриффиндора и 0 баллов для остальных факультетов. Соответственно, Алиса попадёт в Гриффиндор.
Gryffindor Tie!
Похоже, функция работает. Применим её к нашим данным и посмотрим, что получится!

Совпадение: 0.2553191489361702
Доля ничьих: 0.32978723404255317

Хм. Мы ожидали других результатов. Давайте выясним, почему Волан-де-Морт попал в Хаффлпафф.

{'Slytherin': ['ambition'], 'Ravenclaw': ['intelligent', 'intelligent', 'mental', 'individual', 'mental', 'intelligent'], 'Hufflepuff': ['kind', 'loyalty', 'true', 'true', 'true', 'loyalty'], 'Gryffindor': ['brave', 'face', 'bold', 'face', 'bravery', 'brave', 'courageous', 'bravery']}
{'Slytherin': [], 'Ravenclaw': ['common'], 'Hufflepuff': [], 'Gryffindor': ['fear', 'fear', 'fear', 'fear', 'fear', 'fear', 'cowardice', 'fear', 'fear']}
Как видите, Слизерин набрал (1-0) = 1 баллов, Рэйвенклоу — (6-1) = 5, Хаффлпафф — (6-0) = 6, Гриффиндор — (8-9) = -1.
Интересно отметить, что в разделе «Личность и черты характера» Волан-де-Морта, самом длинном среди всех студентов, со словарями совпало лишь 31 слово. Это означает, что по другим студентам, вероятно, было гораздо больше совпадений. То есть мы принимаем решение о классификации на основании слишком небольшого количества данных, что и объясняет высокую долю ошибок и большое количество ничьих.
Созданный нами классификатор работает не слишком хорошо (немногим точнее, чем простое угадывание), но не забывайте, что наш подход был упрощённым. Современные спам-фильтры очень сложны и не классифицируют лишь на основании наличия конкретных слово. Так что наш алгоритм можно улучшить так, чтобы он учитывал больше информации. Вот небольшой список идей:
Однако в процессе работы мы много узнали об API и nltk, так что результат можно считать хорошим. Эти инструменты дают нам прочную основу для будущих начинаний, так что мы можем выходить и покорять Python, как Невил сокрушил Нагайну.

Когда вы впервые приступаете к изучению теории анализа и обработки данных, то одними из первых вы изучаете алгоритмы классификации. Их суть проста: берётся информация о конкретном результате наблюдений (data point), на основании которой этот результат относится к определённой группе или классу.
Хороший пример — спам-фильтр электронной почты. Он должен помечать входящие письма (то есть результаты наблюдений) как «спам» или «не спам», ориентируясь на информацию о письмах (отправитель, количество слов, начинающихся с прописных букв, и так далее).

Это пример хороший, но скучный. Спам-классификацию приводят в качестве примера на лекциях, презентациях и конференциях, так что вы наверняка уже не раз слышали о нём. Но что если поговорить о другом, более интересном алгоритме классификации? Каком-то более странном? Более… волшебном?
Всё верно! Сегодня мы поговорим о Распределяющей шляпе (Sorting Hat) из мира Гарри Поттера. Возьмём какие-то данные из сети, проанализируем и создадим классификатор, который будет сортировать персонажей по разным факультетам. Должно получиться забавно!
Примечание:
Наш классификатор будет не слишком сложным. Так что его нужно рассматривать как «первичный подход» к решению проблемы, демонстрирующий некоторые базовые методики извлечения текста из сети и его анализа. Кроме того, учитывая относительно небольшой размер выборки, мы не будем использовать классические обучающие методики вроде перекрёстной проверки. Мы просто соберём определенные данные, построим простой классификатор на основе правил и оценим результат.
Второе примечание:
Идея этого поста навеяна прекрасной презентацией Брайана Ланга на конференции PyData Chicago 2016. Видеозапись здесь, слайды здесь.
Шаг первый: извлекаем данные из сети
На случай, если последние 20 лет вы провели в пещере: Распределяющая шляпа — это волшебная шляпа, которая помещает поступающих студентов по четырём факультетам Хогвартса: Гриффиндор, Слизерин, Хаффлпафф и Рэйвенклоу. У каждого факультета свои характеристики. Когда шляпу надевают на голову студента, она считывает его разум и определяет, какой факультет подходит ему лучше всего. Согласно этому определению, Распределяющая шляпа — это многоклассовый классификатор (multiclass classifier) (сортирует более чем по двум группам), в отличие от бинарного классификатора (сортирует строго по двум группам), которым является спам-фильтр.
Чтобы распределить студентов по факультетам, нам нужно знать о них определенную информацию. К счастью, достаточно данных есть на harrypotter.wikia.com. На этом сайте лежат статьи почти по всем аспектам вселенной Гарри Поттера, включая описания студентов и факультетов. Приятный бонус: компания Fandom, заведующая сайтом, предоставляет простой в использовании API и массу прекрасной документации. Ура!
Начнём с импортирования
pandas и requests. Первые будут использоваться для упорядочивания данных, а последние — для запросов к API на получение данных.Также нам нужно грамотно пройтись по всем студентам Хогвартса и записать факультеты, по которым они раскиданы Распределяющей шляпой (это будут «реальные данные», с которыми мы будем сравнивать результаты нашей сортировки). На сайте статьи разбиты по категориям, вроде «Студенты Хогвартса» и «Фильмы». API позволяет создавать списки статей в рамках конкретной категории.
Возьмём для примера Рэйвенклоу. Закинем все данные в переменную
info и затем положим их во фрейм данных (Data Frame) Pandas.# Импортирует модули
import pandas as pd
import requests
# Получает статьи из категории Рэйвенклоу
category = 'Ravenclaws'
url = 'http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=' + category
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
ravenclaw_df = pd.DataFrame(info)
print('Number of articles: {}'.format(len(info)))
print('')
ravenclaw_df.head()Количество статей: 158

Вы можете проследить полное выполнение анализа с помощью Rodeo!
Примечание:
Если воспользуетесь нашим Python IDE, Rodeo, то просто скопируйте и вставьте вышеприведённый код в Editor или Terminal. Результат вы увидите в окне History или Terminal. Бонус: можно просто перетаскивать окна мышью, меняя их расположение и размер.

На основе этих данных мы узнаем:
- Первым пунктом в списке идёт «Ravenclaw individual infobox». Поскольку это не студент, нам нужно отфильтровать результаты по колонке «Тип».
- К сожалению, в
ravenclaw_dfне указаны содержания статей… только описания. Чтобы получить содержания, придётся воспользоваться другим видом запроса к API и запрашивать данные на основе ID статей. - Также мы можем написать цикл, пройтись по всем факультетам и получить один фрейм со всеми необходимыми данными.
# Задаём переменные
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
mydf = pd.DataFrame()
# Получаем ID статей, URL статей и факультеты
for house in houses:
url = "http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=" + house + 's'
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
house_df = pd.DataFrame(info)
house_df = house_df[house_df['type'] == 'article']
house_df.reset_index(drop=True, inplace=True)
house_df.drop(['abstract', 'comments', 'ns', 'original_dimensions', 'revision', 'thumbnail', 'type'], axis=1, inplace=True)
house_df['house'] = pd.Series([house]*len(house_df))
mydf = pd.concat([mydf, house_df])
mydf.reset_index(drop=True, inplace=True)
# Выводим результаты
print('Number of student articles: {}'.format(len(mydf)))
print('')
print(mydf.head())
print('')
print(mydf.tail())Количество статей о студентах: 748

Получение содержаний статей
Имея ID статей, мы можем начать запрашивать содержания. Но некоторые из статей просто ОГРОМНЫ, они содержат невероятное количество подробностей. Вы только взгляните на статьи про Гарри Поттера и Волан-де-Морта!
В статьях про всех ключевых персонажей есть раздел «Личность и черты характера». Логично было бы извлекать отсюда информацию, которую Распределяющая шляпа будет использовать при принятии решений. Но такой раздел есть не во всех статьях, так что если ориентироваться только на него, то количество персонажей сильно уменьшится.
Нижеприведённый код извлекает из каждой статьи раздел «Личность и черты характера» и вычисляет его длину (количество знаков). Затем на основе ID объединяет эти данные с нашим начальным фреймом данных mydf (на это уходит немного времени).
# Циклически проходим по статьям и извлекаем разделы " Личность и черты характера " по каждому студенту
# Если в статье про какого-то студента такого раздела нет, то оставляем пустую строку
# Это займёт несколько минут
text_dict = {}
for iden in mydf['id']:
url = 'http://harrypotter.wikia.com/api/v1/Articles/AsSimpleJson?id=' + str(iden)
requested_url = requests.get(url)
json_results = requested_url.json()
sections = json_results['sections']
contents = [sections[i]['content'] for i, x in enumerate(sections) if sections[i]['title'] == 'Personality and traits']
if contents:
paragraphs = contents[0]
texts = [paragraphs[i]['text'] for i, x in enumerate(paragraphs)]
all_text = ' '.join(texts)
else:
all_text = ''
text_dict[iden] = all_text
# Помещаем данные в DataFrame и вычисляем длину раздела "Личность и черты характера"
text_df = pd.DataFrame.from_dict(text_dict, orient='index')
text_df.reset_index(inplace=True)
text_df.columns = ['id', 'text']
text_df['text_len'] = text_df['text'].map(lambda x: len(x))
# Снова объединяем текст с информацией о студентах
mydf_all = pd.merge(mydf, text_df, on='id')
mydf_all.sort_values('text_len', ascending=False, inplace=True)
# Создаём новый DataFrame только с теми студентами, про которых есть разделы "Личность и черты характера"
mydf_relevant = mydf_all[mydf_all['text_len'] > 0]
print('Number of useable articles: {}'.format(len(mydf_relevant)))
print('')
mydf_relevant.head()Количество подходящих статей: 94

Шаг второй: Получение характеристик факультетов с помощью NLTK
Теперь мы знаем количество студентов, надо распределить их по факультетам. Для этого составим список характеристик каждого факультета. Начнём собирать из с harrypotter.wikia.com.
trait_dict = {}
trait_dict['Gryffindor'] = ['bravery', 'nerve', 'chivalry', 'daring', 'courage']
trait_dict['Slytherin'] = ['resourcefulness', 'cunning', 'ambition', 'determination', 'self-preservation', 'fraternity',
'cleverness']
trait_dict['Ravenclaw'] = ['intelligence', 'wit', 'wisdom', 'creativity', 'originality', 'individuality', 'acceptance']
trait_dict['Hufflepuff'] = ['dedication', 'diligence', 'fairness', 'patience', 'kindness', 'tolerance', 'persistence',
'loyalty']Обратите внимание, что все слова — существительные. Это хорошо. Нам нужна консистентность при описании черт характера. Некоторые из них были представлены не в виде существительных, так что приведём их к общему порядку:
- «ambitious» (прилагательное) — можно легко заменить на 'ambition'
- «hard work», «fair play» и «unafraid of toil» — эти фразы тоже можно легко заменить на однословные существительные:
- «hard work» --> 'diligence'
- «fair play» --> 'fairness'
- «unafraid of toil» --> 'persistence'
Получив список характеристик для каждого факультета, можем просто сканировать колонку «Текст» и подсчитать, сколько раз использовались соответствующие слова в описаниях персонажей. Звучит несложно, верно?
К сожалению, это ещё не всё. Вот фраза из раздела «Личность и черты характера» про Невила Лонгботтома:
Когда он был моложе, Невил был неуклюж, забывчив, застенчив, и многие считали, что он плохо подходит для факультета Гриффиндор, потому что он казался робким.
Благодаря поддержке друзей, которым он был очень предан; вдохновению профессора Римуса Люпина предстать перед лицом своих страхов на третьем году обучения; и тому, что мучители его родителей разгуливают на свободе, Невил стал храбрее, увереннее в себе, и самоотверженным в борьбе против Волан-де-Морта и его Пожирателей Смерти.
(When he was younger, Neville was clumsy, forgetful, shy, and many considered him ill-suited for Gryffindor house because he seemed timid.
With the support of his friends, to whom he was very loyal, the encouragement of Professor Remus Lupin to face his fears in his third year, and the motivation of knowing his parents’ torturers were on the loose, Neville became braver, more self-assured, and dedicated to the fight against Lord Voldemort and his Death Eaters.)
Выделенные слова должны засчитываться в пользу каких-то факультетов, но они не будут засчитаны, потому что являются прилагательными. Также не будут учтены слова вроде «bravely» и «braveness». Чтобы наш алгоритм классификации работал правильно, нужно идентифицировать синонимы, антонимы и другие словоформы.
Синонимы
Исследовать синонимы можно с помощью функции
synsets из WordNet, лексической базы данных английского языка, включённой в модуль nltk (NLTK — Natural Language Toolkit). “Synset” — это «synonym set», коллекция синонимов, или «лемм». Функция synsets возвращает наборы синонимов, которые ассоциированы с конкретными словами.Озадачены? Давайте запустим код, а затем разберём его:
from nltk.corpus import wordnet as wn
# Наборы синонимов из разных слов
foo1 = wn.synsets('bravery')
print("Synonym sets associated with the word 'bravery': {}".format(foo1))
foo2 = wn.synsets('fairness')
print('')
print("Synonym sets associated with the word 'fairness': {}".format(foo2))
foo3 = wn.synsets('wit')
print('')
print("Synonym sets associated with the word 'wit': {}".format(foo3))
foo4 = wn.synsets('cunning')
print('')
print("Synonym sets associated with the word 'cunning': {}".format(foo4))
foo4 = wn.synsets('cunning', pos=wn.NOUN)
print('')
print("Synonym sets associated with the *noun* 'cunning': {}".format(foo4))
print('')
# Выводим синонимы ("леммы"), ассоциированные с каждым synset
foo_list = [foo1, foo2, foo3, foo4]
for foo in foo_list:
for synset in foo:
print((synset.name(), synset.lemma_names()))Synonym sets associated with the word 'bravery': [Synset('courage.n.01'), Synset('fearlessness.n.01')]
Synonym sets associated with the word 'fairness': [Synset('fairness.n.01'), Synset('fairness.n.02'), Synset('paleness.n.02'), Synset('comeliness.n.01')]
Synonym sets associated with the word 'wit': [Synset('wit.n.01'), Synset('brain.n.02'), Synset('wag.n.01')]
Synonym sets associated with the word 'cunning': [Synset('craft.n.05'), Synset('cunning.n.02'), Synset('cunning.s.01'), Synset('crafty.s.01'), Synset('clever.s.03')]
Synonym sets associated with the noun 'cunning': [Synset('craft.n.05'), Synset('cunning.n.02')]
('courage.n.01', ['courage', 'courageousness', 'bravery', 'braveness']) ('fearlessness.n.01', ['fearlessness', 'bravery']) ('fairness.n.01', ['fairness', 'equity']) ('fairness.n.02', ['fairness', 'fair-mindedness', 'candor', 'candour']) ('paleness.n.02', ['paleness', 'blondness', 'fairness']) ('comeliness.n.01', ['comeliness', 'fairness', 'loveliness', 'beauteousness']) ('wit.n.01', ['wit', 'humor', 'humour', 'witticism', 'wittiness']) ('brain.n.02', ['brain', 'brainpower', 'learning_ability', 'mental_capacity', 'mentality', 'wit']) ('wag.n.01', ['wag', 'wit', 'card']) ('craft.n.05', ['craft', 'craftiness', 'cunning', 'foxiness', 'guile', 'slyness', 'wiliness']) ('cunning.n.02', ['cunning'])
Так, мы получили много выходных данных. Рассмотрим некоторые моменты и потенциальные проблемы:
wn.synsets('bravery')связано с двумя наборами синонимов: один дляcourage.n.01и один дляfearlessness.n.01. Давайте посмотрим, что это означает:- Первая часть ('courage' и 'fearlessness') это слово, вокруг которого выстроен весь конкретный набор синонимов. Назовём его «центральным» словом. То есть все синонимы в данном наборе («леммы») аналогичны по смыслу центральному слову.
- Вторая часть ('n') означает «существительное» («noun»). К примеру, набор, ассоциированный со словом «cunning», включает в себя
crafty.s.01иclever.s.03(прилагательные). Они появились тут потому, что слово «cunning» может быть и существительным, и прилагательным. Чтобы оставить только существительные, можно задатьwn.synsets('cunning', pos=wn.NOUN). - Третья часть ('01') ссылается на конкретный смысл центрального слова. Например, 'fairness' может означать как «соответствие правилам и стандартам», так и «вынесение суждений без дискриминации или нечестности».
Как вы могли заметить, функция
synset может предоставлять нежелательные наборы синонимов. Например, со словом 'fairness' также ассоциированы наборы paleness.n.02 («иметь от природы светлую кожу») и comeliness.n.01 («хорошо выглядеть и быть привлекательным»). Эти черты явно не ассоциируются с Хаффлпаффом (хотя Невил Лонгботтом и вырос красавчиком), так что придётся вручную исключать такие наборы из нашего анализа.Перевод: получить синонимы труднее, чем кажется
Антонимы и словоформы
После того, как мы собрали все синонимы, нужно позаботиться об антонимах и разных словоформах (например, применительно к «bravery» — «brave», «bravely» и «braver»). Немало тяжёлой работы можно выполнить в nltk, но всё же придётся вручную набивать деепричастия и прилагательные в сравнительной / превосходной степени.
# Выводим разные леммы (синонимы), антонимы и производные словоформы для наборов синонимов к "bravery"
foo1 = wn.synsets('bravery')
for synset in foo1:
for lemma in synset.lemmas():
print("Synset: {}; Lemma: {}; Antonyms: {}; Word Forms: {}".format(synset.name(), lemma.name(), lemma.antonyms(),
lemma.derivationally_related_forms()))
print("")Synset: courage.n.01; Lemma: courage; Antonyms: [Lemma('cowardice.n.01.cowardice')]; Word Forms: [Lemma('brave.a.01.courageous')]
Synset: courage.n.01; Lemma: courageousness; Antonyms: []; Word Forms: [Lemma('brave.a.01.courageous')]
Synset: courage.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Synset: courage.n.01; Lemma: braveness; Antonyms: []; Word Forms: [Lemma('brave.a.01.brave'), Lemma('audacious.s.01.brave')]
Synset: fearlessness.n.01; Lemma: fearlessness; Antonyms: [Lemma('fear.n.01.fear')]; Word Forms: [Lemma('audacious.s.01.fearless'), Lemma('unafraid.a.01.fearless')]
Synset: fearlessness.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Собираем всё вместе
Следующий код создаёт список синонимов, антонимов и словоформ для каждой характеристики факультетов. Для полноты анализа некоторые из слов могут быть записаны неправильно.
# Вручную выбираем наборы, которые нам подходят
relevant_synsets = {}
relevant_synsets['Ravenclaw'] = [wn.synset('intelligence.n.01'), wn.synset('wit.n.01'), wn.synset('brain.n.02'),
wn.synset('wisdom.n.01'), wn.synset('wisdom.n.02'), wn.synset('wisdom.n.03'),
wn.synset('wisdom.n.04'), wn.synset('creativity.n.01'), wn.synset('originality.n.01'),
wn.synset('originality.n.02'), wn.synset('individuality.n.01'), wn.synset('credence.n.01'),
wn.synset('acceptance.n.03')]
relevant_synsets['Hufflepuff'] = [wn.synset('dedication.n.01'), wn.synset('commitment.n.04'), wn.synset('commitment.n.02'),
wn.synset('diligence.n.01'), wn.synset('diligence.n.02'), wn.synset('application.n.06'),
wn.synset('fairness.n.01'), wn.synset('fairness.n.01'), wn.synset('patience.n.01'),
wn.synset('kindness.n.01'), wn.synset('forgivingness.n.01'), wn.synset('kindness.n.03'),
wn.synset('tolerance.n.03'), wn.synset('tolerance.n.04'), wn.synset('doggedness.n.01'),
wn.synset('loyalty.n.01'), wn.synset('loyalty.n.02')]
relevant_synsets['Gryffindor'] = [wn.synset('courage.n.01'), wn.synset('fearlessness.n.01'), wn.synset('heart.n.03'),
wn.synset('boldness.n.02'), wn.synset('chivalry.n.01'), wn.synset('boldness.n.01')]
relevant_synsets['Slytherin'] = [wn.synset('resourcefulness.n.01'), wn.synset('resource.n.03'), wn.synset('craft.n.05'),
wn.synset('cunning.n.02'), wn.synset('ambition.n.01'), wn.synset('ambition.n.02'),
wn.synset('determination.n.02'), wn.synset('determination.n.04'),
wn.synset('self-preservation.n.01'), wn.synset('brotherhood.n.02'),
wn.synset('inventiveness.n.01'), wn.synset('brightness.n.02'), wn.synset('ingenuity.n.02')]
# Функция, получающая разные словоформы из леммы
def get_forms(lemma):
drfs = lemma.derivationally_related_forms()
output_list = []
if drfs:
for drf in drfs:
drf_pos = str(drf).split(".")[1]
if drf_pos in ['n', 's', 'a']:
output_list.append(drf.name().lower())
if drf_pos in ['s', 'a']:
# Наречия + "-ness" существительные + сравнительные & превосходные прилагательные
if len(drf.name()) == 3:
last_letter = drf.name()[-1:]
output_list.append(drf.name().lower() + last_letter + 'er')
output_list.append(drf.name().lower() + last_letter + 'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-4:] in ['able', 'ible']:
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name()[:-1].lower()+'y')
elif drf.name()[-1:] == 'e':
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-2:] == 'ic':
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ally')
elif drf.name()[-1:] == 'y':
output_list.append(drf.name()[:-1].lower()+'ier')
output_list.append(drf.name()[:-1].lower()+'iest')
output_list.append(drf.name()[:-1].lower()+'iness')
output_list.append(drf.name()[:-1].lower()+'ily')
else:
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
return output_list
else:
return output_list
# Создаём копию словаря черт характера
# Если этого не сделать, то мы сразу же обновим словарь, по которому проходим циклически, что приведёт к бесконечному циклу
import copy
new_trait_dict = copy.deepcopy(trait_dict)
antonym_dict = {}
# Добавляем синонимы и словоформы в (новый) словарь черт характера; также добавляем антонимы (и их словоформы) в словарь антонимов
for house, traits in trait_dict.items():
antonym_dict[house] = []
for trait in traits:
synsets = wn.synsets(trait, pos=wn.NOUN)
for synset in synsets:
if synset in relevant_synsets[house]:
for lemma in synset.lemmas():
new_trait_dict[house].append(lemma.name().lower())
if get_forms(lemma):
new_trait_dict[house].extend(get_forms(lemma))
if lemma.antonyms():
for ant in lemma.antonyms():
antonym_dict[house].append(ant.name().lower())
if get_forms(ant):
antonym_dict[house].extend(get_forms(ant))
new_trait_dict[house] = sorted(list(set(new_trait_dict[house])))
antonym_dict[house] = sorted(list(set(antonym_dict[house])))
# Выводим некоторые результаты
print("Gryffindor traits: {}".format(new_trait_dict['Gryffindor']))
print("")
print("Gryffindor anti-traits: {}".format(antonym_dict['Gryffindor']))
print("")Характеристики Гриффиндора: ['bold', 'bolder', 'boldest', 'boldly', 'boldness', 'brass', 'brassier', 'brassiest', 'brassily', 'brassiness', 'brassy', 'brave', 'bravely', 'braveness', 'braver', 'bravery', 'bravest', 'cheek', 'cheekier', 'cheekiest', 'cheekily', 'cheekiness', 'cheeky', 'chivalry', 'courage', 'courageous', 'courageouser', 'courageousest', 'courageously', 'courageousness', 'daring', 'face', 'fearless', 'fearlesser', 'fearlessest', 'fearlessly', 'fearlessness', 'gallantry', 'hardihood', 'hardiness', 'heart', 'mettle', 'nerve', 'nervier', 'nerviest', 'nervily', 'nerviness', 'nervy', 'politesse', 'spunk', 'spunkier', 'spunkiest', 'spunkily', 'spunkiness', 'spunky']
Антихарактеристики Гриффиндора: ['cowardice', 'fear', 'timid', 'timider', 'timidest', 'timidity', 'timidly', 'timidness']
# Проверяем, что словарь черт характера и словарь антонимов не содержат повторов внутри факультетов
from itertools import combinations
def test_overlap(dict):
results = []
house_combos = combinations(list(dict.keys()), 2)
for combo in house_combos:
results.append(set(dict[combo[0]]).isdisjoint(dict[combo[1]]))
return results
# Выводим результаты теста; должно получиться "False"
print("Any words overlap in trait dictionary? {}".format(sum(test_overlap(new_trait_dict)) != 6))
print("Any words overlap in antonym dictionary? {}".format(sum(test_overlap(antonym_dict)) != 6))Есть какие-то повторы в словаре черт характера? False
Повторы в словаре антонимов? False
Шаг третий: Распределяем студентов по факультетам
Пришло время распределить студентов по факультетам! Наш алгоритм классификации будет работать следующим образом:
- Проходит по каждому слову раздела «Личность и черты характера» по каждому студенту.
- Если какое-то слово есть в списке черт, характерных для конкретного факультета, то к баллам этого факультета добавляется 1.
- Если какое-то слово есть в списке античерт, характерных для конкретного факультета, то из баллов этого факультета вычитается 1.
- Студент приписывается к факультету, который наберёт больше всего баллов.
- Если будет ничья, то просто напишет “Tie!”.
Допустим, в разделе «Личность и черты характера» есть лишь предложение «Алиса была храброй». Тогда Алиса получит 1 балл для Гриффиндора и 0 баллов для остальных факультетов. Соответственно, Алиса попадёт в Гриффиндор.
# Импортируем "word_tokenize", разбивающий предложение на слова и пунктуацию
from nltk import word_tokenize
# Функция, распределяющая студентов
def sort_student(text):
text_list = word_tokenize(text)
text_list = [word.lower() for word in text_list]
score_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
score_dict[house] = (sum([True for word in text_list if word in new_trait_dict[house]]) -
sum([True for word in text_list if word in antonym_dict[house]]))
sorted_house = max(score_dict, key=score_dict.get)
sorted_house_score = score_dict[sorted_house]
if sum([True for i in score_dict.values() if i==sorted_house_score]) == 1:
return sorted_house
else:
return "Tie!"
# Тестируем функцию
print(sort_student('Alice was brave'))
print(sort_student('Alice was British'))Gryffindor Tie!
Похоже, функция работает. Применим её к нашим данным и посмотрим, что получится!
# Отключаем предупреждение
pd.options.mode.chained_assignment = None
mydf_relevant['new_house'] = mydf_relevant['text'].map(lambda x: sort_student(x))
mydf_relevant.head(20)
print("Match rate: {}".format(sum(mydf_relevant['house'] == mydf_relevant['new_house']) / len(mydf_relevant)))
print("Percentage of ties: {}".format(sum(mydf_relevant['new_house'] == 'Tie!') / len(mydf_relevant)))Совпадение: 0.2553191489361702
Доля ничьих: 0.32978723404255317
Хм. Мы ожидали других результатов. Давайте выясним, почему Волан-де-Морт попал в Хаффлпафф.
# Текст о Волан-де-Морте
tom_riddle = word_tokenize(mydf_relevant['text'].values[0])
tom_riddle = [word.lower() for word in tom_riddle]
# Вместо вычисления баллов выведем список слов в тексте, совпадающих со словами из словарей черт характера и антонимов
words_dict = {}
anti_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
words_dict[house] = [word for word in tom_riddle if word in new_trait_dict[house]]
anti_dict[house] = [word for word in tom_riddle if word in antonym_dict[house]]
print(words_dict)
print("")
print(anti_dict){'Slytherin': ['ambition'], 'Ravenclaw': ['intelligent', 'intelligent', 'mental', 'individual', 'mental', 'intelligent'], 'Hufflepuff': ['kind', 'loyalty', 'true', 'true', 'true', 'loyalty'], 'Gryffindor': ['brave', 'face', 'bold', 'face', 'bravery', 'brave', 'courageous', 'bravery']}
{'Slytherin': [], 'Ravenclaw': ['common'], 'Hufflepuff': [], 'Gryffindor': ['fear', 'fear', 'fear', 'fear', 'fear', 'fear', 'cowardice', 'fear', 'fear']}
Как видите, Слизерин набрал (1-0) = 1 баллов, Рэйвенклоу — (6-1) = 5, Хаффлпафф — (6-0) = 6, Гриффиндор — (8-9) = -1.
Интересно отметить, что в разделе «Личность и черты характера» Волан-де-Морта, самом длинном среди всех студентов, со словарями совпало лишь 31 слово. Это означает, что по другим студентам, вероятно, было гораздо больше совпадений. То есть мы принимаем решение о классификации на основании слишком небольшого количества данных, что и объясняет высокую долю ошибок и большое количество ничьих.
Выводы
Созданный нами классификатор работает не слишком хорошо (немногим точнее, чем простое угадывание), но не забывайте, что наш подход был упрощённым. Современные спам-фильтры очень сложны и не классифицируют лишь на основании наличия конкретных слово. Так что наш алгоритм можно улучшить так, чтобы он учитывал больше информации. Вот небольшой список идей:
- Сравнить с факультетами, в которые попадали другие члены семьи этого студента.
- Использовать другие разделы статей, например, «Ранние годы» или введение.
- Вместо маленького списка черт характера и их синонимов создать список наиболее частых слов в разделе «Личность и черты характера» применительно для каждого факультета, и классифицировать на основании этих данных.
- Использовать более сложные методики анализа текстов, вроде анализа тональности текста.
Однако в процессе работы мы много узнали об API и nltk, так что результат можно считать хорошим. Эти инструменты дают нам прочную основу для будущих начинаний, так что мы можем выходить и покорять Python, как Невил сокрушил Нагайну.
