Несколько дней назад мы публиковали обзор первого дня Data Science Weekend 2018, который прошел 2-3 марта на Мансарде Rambler&Co. Изучив практику использования алгоритмов машинного обучения, теперь перейдем к обзору второго дня конференции, в течении которого спикеры рассказывали об использовании различных инструментов дата инженера для нужд дата-платформ, ETL, сервисах подсказок при поиске и многом другом.

Второй день DSWknd2018 открыл Юрий Бабак — руководитель разработки модуля машинного обучения для платформы Apache Ignite в компании GridGain, рассказав о том, как компания справлялась с оптимизацией распределенного машинного обучения на кластере.
Обычно, говоря об оптимизации процесса машинного обучения, имеют в виду в первую очередь оптимизацию самих тренировок. Мы же решили зайти с другой стороны и решить проблему того, что данные обычно хранятся отдельно от той системы, где они обрабатываются и обучаются.
Следовательно, мы решили сосредоточиться на проблеме длинного ETL, (ведь бессмысленно соревноваться в производительности машинного обучения с Tensorflow) в результате чего нам удалось тренировать распределенные модели на всем кластере, что у нас есть. Получился новый подход в области ML, использующий не параллельную, а именно распределенную систему обучения.
Добиться поставленной цели нам удалось за счет того, что мы разработали новый модуль машинного обучения в Apache Ignite, который опирается на ту функциональность, которая уже в нем есть (стриминг, нативный persistence и многое другое). Хотелось бы рассказать вам о двух особенностях получившегося модуля: распределенное key-value хранилище и collocated computing.
Больше информации об Apache Ignite вы можете найти тут, тут и тут.
После этого Алексей Кузнецов и Михаил Сеткин, выпускники наших программ Data Engineer и «Специалист по большим данным», поделились опытом построения Real-Time Decision Platform (RTDP) на базе Hortonworks Data Platform и Data Flow.
У любой организации есть данные, характеризующие события, которые можно отобразить на временной шкале, и как-то их использовать для принятия real-time решений. К примеру, можно представить сценарий, когда у клиента банка 2 раза прошел отказ оплаты по карте, затем он позвонил в call-центр, зашел в интернет-банк, оставил заявку и т.д. Нам бы, конечно, хотелось получать какие-то сигналы, исходя из этих событий, чтобы своевременно предложить клиенту какие-то услуги, специальные предложения или помощь с его проблемой.
В основе каждой RTDM системы лежит стриминг, который работает таким образом, что есть источники, из которых мы можем снимать события и класть в шину данных, а потом оттуда забирать, причем мы не можем соединять события из разных источников и как-то их агрегировать.
Следующий уровень абстракции над стримингом — это Complex Events Processing (CEP), который отличается от простого стриминга тем, что появляется много источников, которые мы пытаемся обрабатывать одновременно, то есть мы видим события совместно, появляются join-ы этих событий, можем как-то их на лету агрегировать и т.д.
Последний элемент абстракции и есть сама система RTDM, основное отличие которой от CEP в том, что в ней есть набор преднастроенных решений и действий, которые можно принимать в онлайне: звонок из call-центра в случае заявки на консультацию в интернет-банке, SMS со специальным предложением в случае пополнения счета на крупную сумму и другие действия.
Как эту систему реализовать? Можно пойти к вендорам и в 99% случаев это является стандартной практикой в области. С другой стороны у нас есть команда инженеров данных, которая может все сделать сама, использовав open-source решения. Главный недостаток большинства из них — это отсутствие user-интерфейса.
Однако нам удалось найти подходящую для нас платформу — выбор пал на HortonWorks Data Flow 3.0, в новой версии которой появилось как раз то, что нам нужно — Streaming Analytics Manager (SAM), где был реализован графический интерфейс, а учитывая, что HortonWorks уже был у нас в продакшне, мы пошли по пути наименьшего сопротивления.
Перейдем к архитектуре нашего RTDM решения. Данные из источников приходят в шину данных, где агрегируются, а затем с помощью HDF забираются и кладутся в Kafka. Далее вступает SAM, где с помощью user-интерфейса пользователь запускает кампанию на исполнение, тут же компилируется JAR-файл и отправляется в Apache Storm.

Центральным элементом всей системы является SAM, благодаря которому все это стало возможным. Вот как выглядит его интерфейс:

SAM предоставляет пользователю большие возможности: есть выбор источников данных, набора процессоров, которыми он обрабатывает поток данных, группа фильтров, бранчевание, выбор действия для определенного клиента, будь-то абсолютно персонализированное предложение или общее для определенной группы людей действие.
Наш Data Science Weekend был в самом разгаре и на очереди Игорь Мосягин — еще один выпускник программы Data Engineer и R&D разработчик в компании Lamoda. Игорь рассказал о том, как они оптимизировали поисковые подсказки на сайте и пытались подружить Apache Solr, Golang и Airflow.
На нашем сайте, как и на многих других, есть поисковое поле, куда люди что-то вводят и по ходу появляются подсказки, которыми мы пытаемся предугадать, что именно нужно пользователю. На тот момент у нас уже было некоторое готовое решение, однако оно не совсем нас устраивало. К примеру, система не реагировала, если пользователь путал раскладку.
Apache Solr является центром всей получившейся системы, его мы использовали и в старом решении, однако теперь мы решили внедрить и Airflow, про которого я узнал на программе Data Engineer. В результате запрос, который приходит от пользователя попадает в наш сервис, написанный на Go, который его предобрабатывает и отправляет в Solr, а затем получает ответ и возвращает его пользователю. При этом регулярно, в какое-то заранее заданное время запускается Airflow, который лезет в базу данных и если требуется, то запускает импорт данных в Solr. Главное во всем этом тот факт, что от запроса пользователя до ответа проходит 50 мс, из них львиная доля — 40 мс — это запрос в Solr и получение ответа от него.
Вообще говоря, Apache Solr — это такая большая «махина» с хорошей документацией, в ней есть много саджестеров, которые работают по разной логике: могут возвращать ответ только по точному совпадению, либо есть варианты, когда пенализируется нахождения строки далеко от начала слова и т.д. Всего есть 7 или 8 вариантов саджестеров, но мы использовали только 3, так как остальные в большинстве случаев отрабатывали очень медленно.
Также важно время от времени обновлять веса, так как меняются частотности запросов. К примеру, если в этом месяце одним из наиболее популярных запросов являются зимние сапоги, то, конечно, это надо учитывать.
Далее подошла очередь Николая Маркова, который является Senior Data Engineer в компании Aligned Research Group, а также читает лекции на наших программах «Специалист по большим данным» и Data Engineer. Николай рассказал о преимуществах и недостатках экосистемы Hadoop и почему анализ и обработка данных в командной строке может быть неплохой альтернативой.
Если смотреть на Hadoop с современной инженерной точки зрения, то можно найти не только множество плюсов, но и ряд недостатков. К примеру, MapReduce является парадигмой общего назначения. По сути все сводится к тому, что вы кучу времени тратите на то, чтобы ваш алгоритм перенести на MapReduce, чтобы там что-то посчиталось, при этом, возможно, наделав в процессе кучу ошибок. Иногда нужно настакать много MapReduce-ов, чтобы другую вещь сделать, и выходит, что вместо того, чтобы заниматься написанием бизнес-логики, вы тратите время на MapReduce.

Преимуществом Hadoop, конечно, является поддержка Python. Он всем хорош, я на нем пишу и всем рекомендую, но проблема в том, что, когда мы пишем на Python под Hadoop, нам нужно много инженерной поддержки, чтобы все это заставить работать в продакшне: все аналитические пакеты (Pandas, Numpy и т.д.) должны стоять на конечных нодах, все это должно развертываться автоматически. В итоге получается, что мы либо подстраиваемся под конкретного вендора, который позволяет свои версии туда поставить, либо нам нужна система управления конфигурацией, которая и будет заниматься развертыванием.
Естественно, один из основных минусов Hadoop и одновременно главная причина появления Spark заключаются в том, что Hadoop всегда пишет результаты на диск, читает с него и пишет туда же. По сути, даже если мы разбросаем этот процесс на множество нод, то он все равно будет работать со скоростью диска (усредненной).
Решить проблему скорости можно, конечно, масштабированием Hadoop-а, то есть попросту «закидать деньгами». Однако есть и более эффективные альтернативы. Одной из них является анализ и обработка данных в командной строке. В ней действительно можно решать серьезные аналитические задачи, и это будет в несколько раз быстрее чем на Hadoop. Единственный минус представлен ниже:

Кому-то это может показаться нечитабельным, однако эта штука работает на порядок быстрее, чем скрипт на Python, поэтому отлично, если у вас есть инженер, способный писать такие вещи в командной строке.
Также я не совсем понимаю, почему в компаниях обязательно ваша бизнес-логика должна быть завязана на реляционной базе данных, ведь ничего не мешает взять в современном виде какую-то нереляционную БД (тот же MongoDB). Не стоит оправдываться тем, что у вас там кучу join-ов и невозможно обойтись без SQL. На сегодняшний день БД очень много, и вы можете выбрать себе, какая к вам ближе лежит.
Если же вам все-таки никак не обойтись без SQL, то можете попробовать Presto — это расширяемый движок для распределенной работы со многими источниками данных сразу. То есть вы можете написать плагин для вашего источника данных и по сути извлекать с помощью SQL все, что угодно. В принципе в Hive та же логика, но он завязан на инфраструктуру Hadoop, а Presto — независимая разработка. Плюсом идет интеграция с Apache Zeppelin — это такой красивый front-end, где можно писать SQL-запросы и сразу получать графики.
Закончить наши продуктивные выходные выпала честь Александру Шорину — преподавателю на программе Data Engineer и старшему инженеру-разработчику Python в Rambler&Co, который продолжал историю своих коллег с предыдущего дня конференции о том, как они распознавали пол и возраст посетителей кинотеатров с помощью компьютерного зрения. В этот раз основное внимание было уделено именно инженерной части проекта.
Исходный пайплайн выглядит следующим образом:
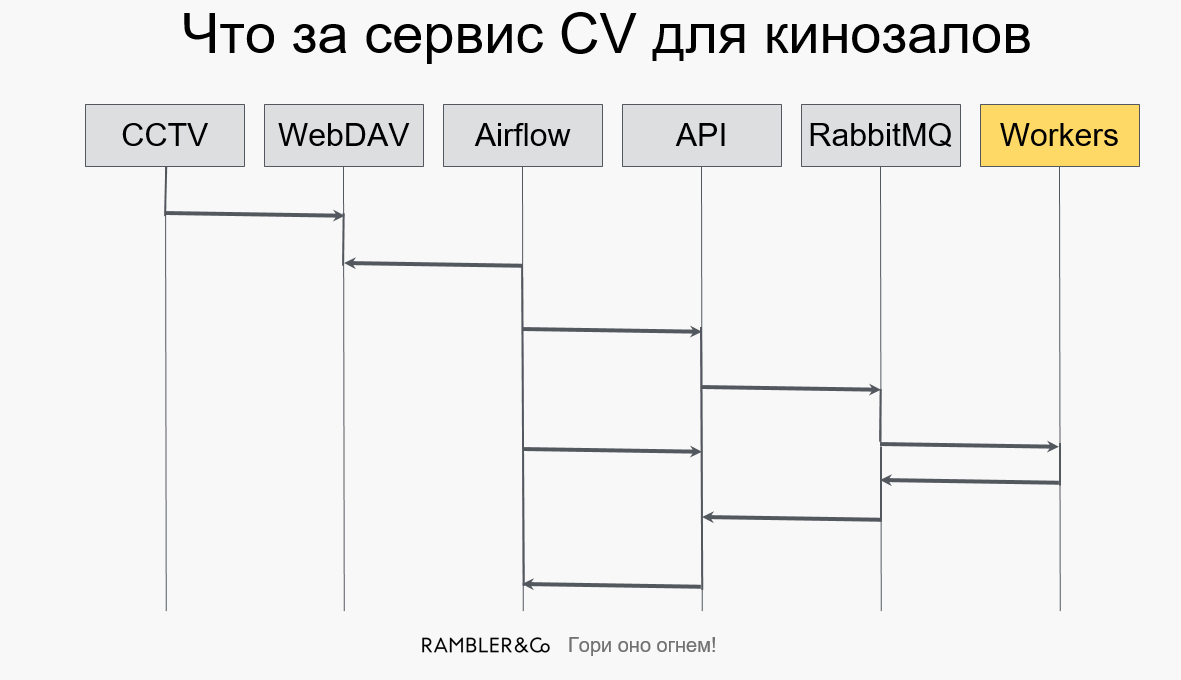
Камеры передают фотографии на WebDAV, далее задача из Airflow вытаскивает новые фотки и отсылает их в API, формирующая все это в отдельные задачи, а затем закидывает в RabbitMQ. Из «кролика» воркеры забирают эти задания, делают с ними некие преобразования и отправляют результаты обратно.
Как мы можем масштабировать этот процесс с технической точки зрения? Сколько нам нужно еще машин, чтобы справляться со всем потоком фотографий? Чтобы ответить на этот вопрос, возьмем профайлер. Мы решили взять PyFlame, сделанный компанией Uber, — это фактически обертка над Ptrace, которая цепляется к процессу в Linux, смотрит, что он делает, и записывает, что и сколько раз было.
Мы запустили тестовый датасет, состоящий из 472 фотографий, и он обсчитался за 293 секунды. Много это или мало? Отчет PyFlame при этом выглядит следующим красивым образом:
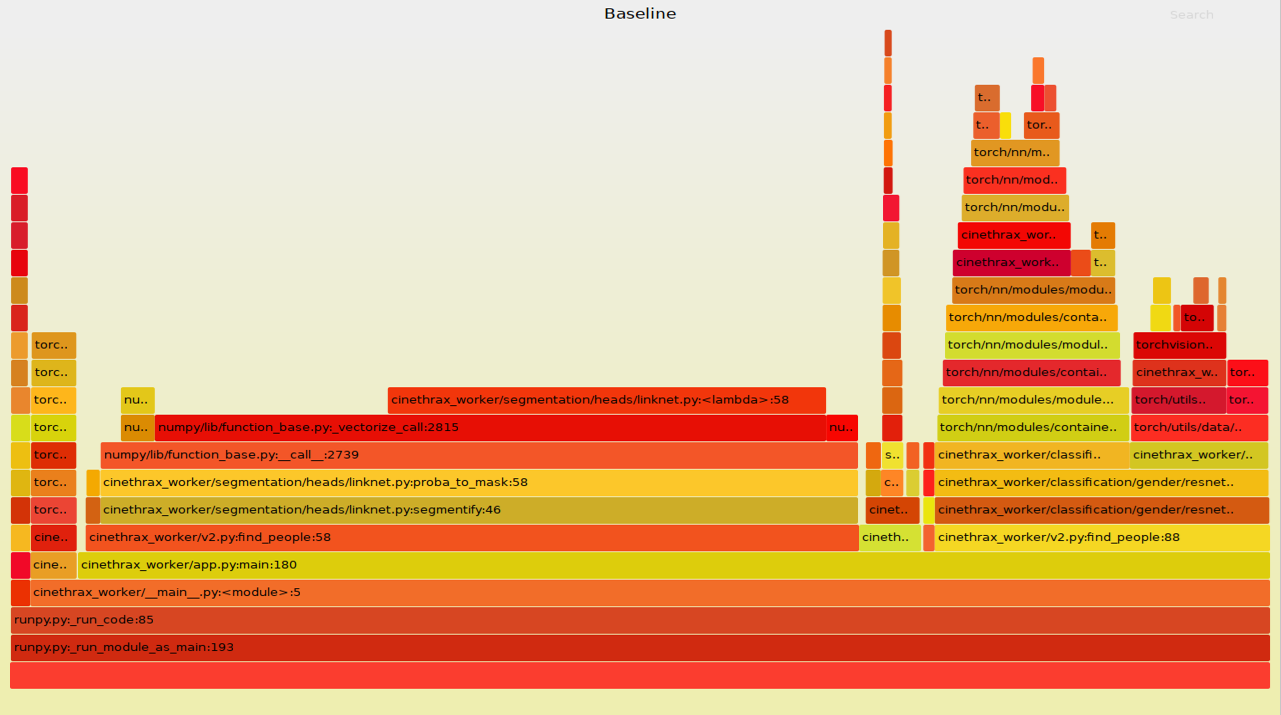
Тут мы видим «ущелье» загрузки моделей, есть «долина» сегментации и другие интересные штуки. На этом отчете видно, что наш код тормозит, поскольку на него ссылается огромная планка в центре картинки.
На деле оказалось, что нам требовалось поменять лишь одну строчку в Jupyter ноутбуке, чтобы оптимизировать сегментацию: длительность процесса упала с 293 до 223 секунд. Также мы перешли с PIL-а, который за медлительность не ругал только ленивый, на OpenCV, благодаря чему общее время работы уменьшилось еще на 20 секунд. Наконец, использование Pillow-SIMD, о котором рассказал Александр Карпинский в своем выступлении на конференции Piter Py #4, для обработки изображений позволило уменьшить время выполнения задачи до 183 секунд. Правда на PyFlame это сказалось незначительно:
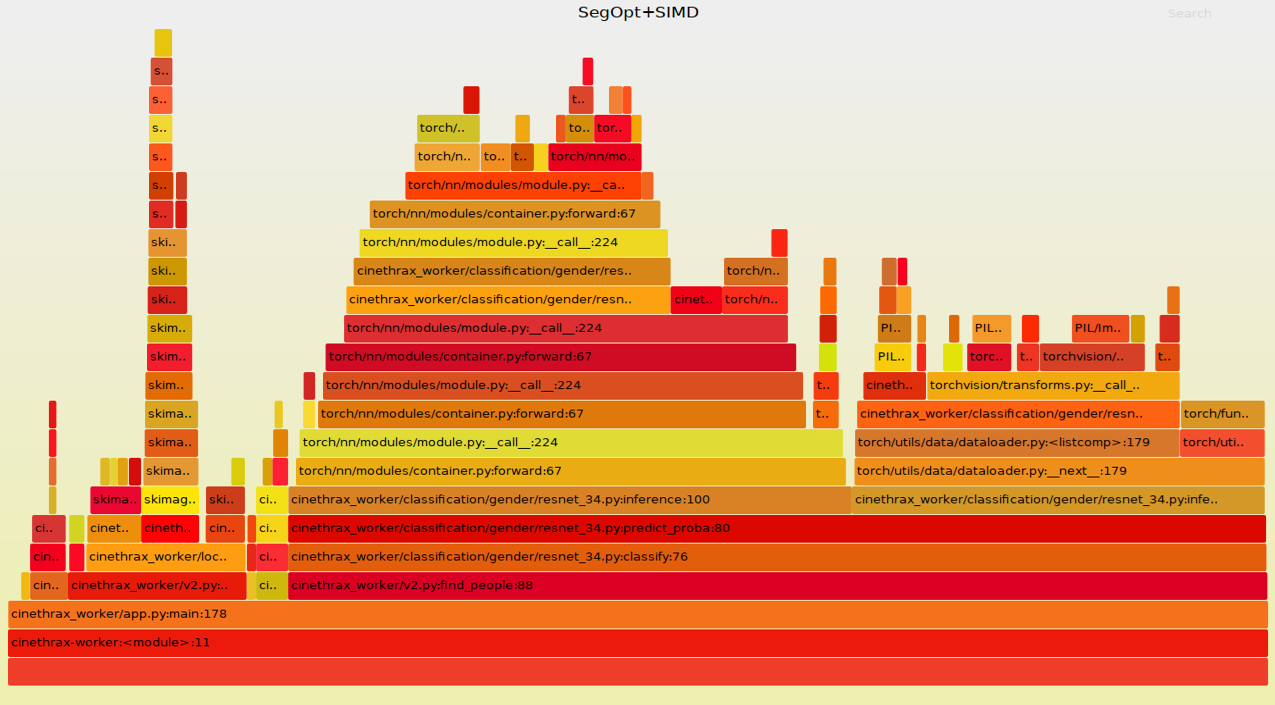
Как видим, тут все еще выделяется PyTorch, поэтому будем «пинать» его. Что с ним можно сделать? У PyTorch при отправке данных на видеокарточку, они сначала проходят предобработку, а потом кидаются в DataLoader.
Изучив принципы работы DataLoader-а, мы увидели, что он поднимает воркеры, обрабатывает датасет, а потом убивает воркеры. Возникает вопрос: а зачем нам постоянно поднимать и убивать воркеры, если у нас в кинозале мало людей, а обработка фотографии занимает около секунды? Зачем каждую секунду поднимать и убивать два процесса, если это неэффективно?
Оптимизировать DataLoader удалось за счет его модификации: теперь он не убивает воркеры и не использует их, если в зале находится менее 24 человек (число взято более-менее с потолка). При этом такая оптимизация не дала значимый прирост к скорости обработки, однако средняя утилизация CPU снизилась с ~600% до ~200%, то есть в 3 раза.
Наконец, в число прочих доработок входит облегчение реализации Conv2d, удаление лишних лямбд из модели нейронной сети и конвертирование Image в np.array для ToTensor.
Напоследок еще немного отзывов о нашей конференции от докладчиков и слушателей:
«Очень комфортная тусовка, где можно в кулуарах и пообщаться в целом про индустрию и подловить спикеров с вопросами. Как докладчик отмечу профессионализм организаторов, видно что всё сделано так, чтобы и спикерам и слушателям было максимально комфортно.» — Игорь Мосягин, докладчик, R&D developer, Lamoda.
«Очень понравилось выступать. Доброжелательная публика, умные вопросы.» — Михаил Сеткин, докладчик, Product Manager, Райффайзенбанк.
Полные выступления всех спикеров вы можете посмотреть на нашей странице в Facebook. Скоро увидимся на других наших мероприятиях!

GridGain
Второй день DSWknd2018 открыл Юрий Бабак — руководитель разработки модуля машинного обучения для платформы Apache Ignite в компании GridGain, рассказав о том, как компания справлялась с оптимизацией распределенного машинного обучения на кластере.
Обычно, говоря об оптимизации процесса машинного обучения, имеют в виду в первую очередь оптимизацию самих тренировок. Мы же решили зайти с другой стороны и решить проблему того, что данные обычно хранятся отдельно от той системы, где они обрабатываются и обучаются.
Следовательно, мы решили сосредоточиться на проблеме длинного ETL, (ведь бессмысленно соревноваться в производительности машинного обучения с Tensorflow) в результате чего нам удалось тренировать распределенные модели на всем кластере, что у нас есть. Получился новый подход в области ML, использующий не параллельную, а именно распределенную систему обучения.
Добиться поставленной цели нам удалось за счет того, что мы разработали новый модуль машинного обучения в Apache Ignite, который опирается на ту функциональность, которая уже в нем есть (стриминг, нативный persistence и многое другое). Хотелось бы рассказать вам о двух особенностях получившегося модуля: распределенное key-value хранилище и collocated computing.
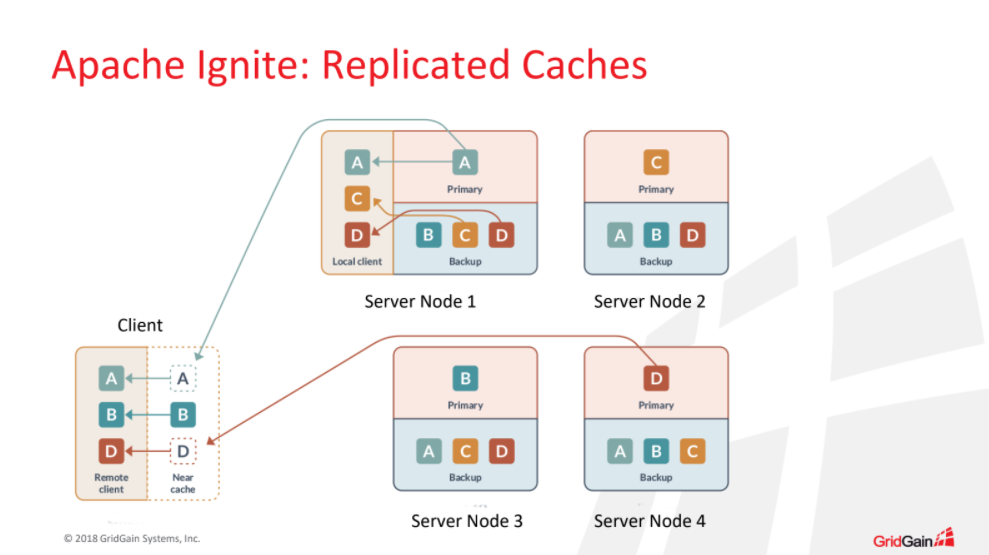
- Key-value хранилище. Во-первых, нам нужны были распределенные реплицируемые кэши, которые в общем виде имеют следующую структуру: у нас есть кэш с какими-то данными, он «размазан» по кластеру, а Apache Ignite заботится о том, как балансировать данные, чтобы они равномерно распределялись по кластеру. На схеме ниже представлена ситуация, когда в каждой партиции у нас есть 3 копии данных, и даже в том случае, если кластер валится, и из 4 узлов останется лишь один, у нас все равно в целости останутся все данные.

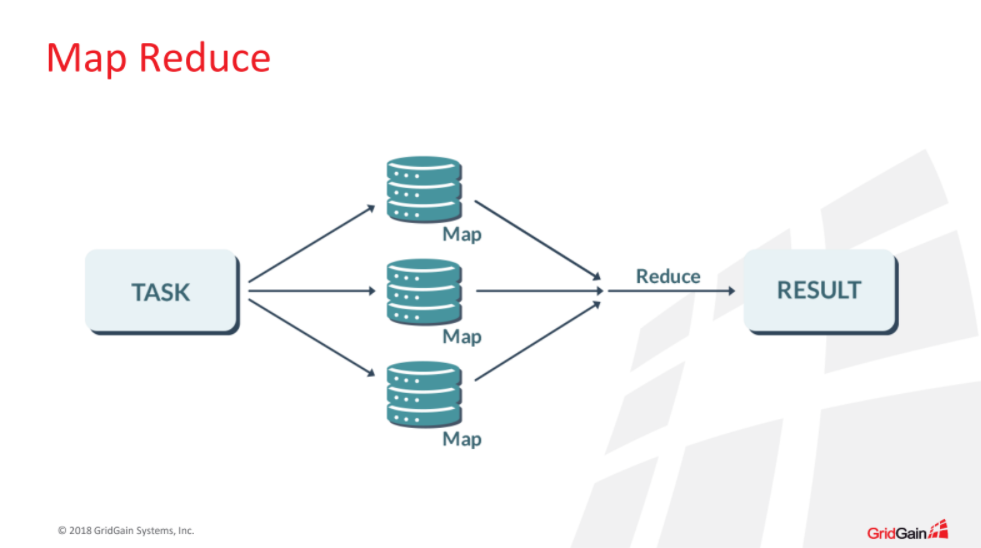
- Collocated computing. Это по сути наша реализация концепции MapReduce, когда мы не пытаемся сагрегировать данные в одном месте и сделать вычисления, а, наоборот, «доставляем» вычисления до наших данных, тем самым минимизируя нагрузку на кластер. Схема выглядит следующим образом: на шаге Map мы рассылаем нашу задачу только на те узлы, где есть необходимые данные, затем она выполняется локально на каждом конкретном узле, чтобы на шаге Reduce мы могли агрегировать результаты и куда-то их дальше отсылать.

Больше информации об Apache Ignite вы можете найти тут, тут и тут.
Райффайзенбанк
После этого Алексей Кузнецов и Михаил Сеткин, выпускники наших программ Data Engineer и «Специалист по большим данным», поделились опытом построения Real-Time Decision Platform (RTDP) на базе Hortonworks Data Platform и Data Flow.
У любой организации есть данные, характеризующие события, которые можно отобразить на временной шкале, и как-то их использовать для принятия real-time решений. К примеру, можно представить сценарий, когда у клиента банка 2 раза прошел отказ оплаты по карте, затем он позвонил в call-центр, зашел в интернет-банк, оставил заявку и т.д. Нам бы, конечно, хотелось получать какие-то сигналы, исходя из этих событий, чтобы своевременно предложить клиенту какие-то услуги, специальные предложения или помощь с его проблемой.
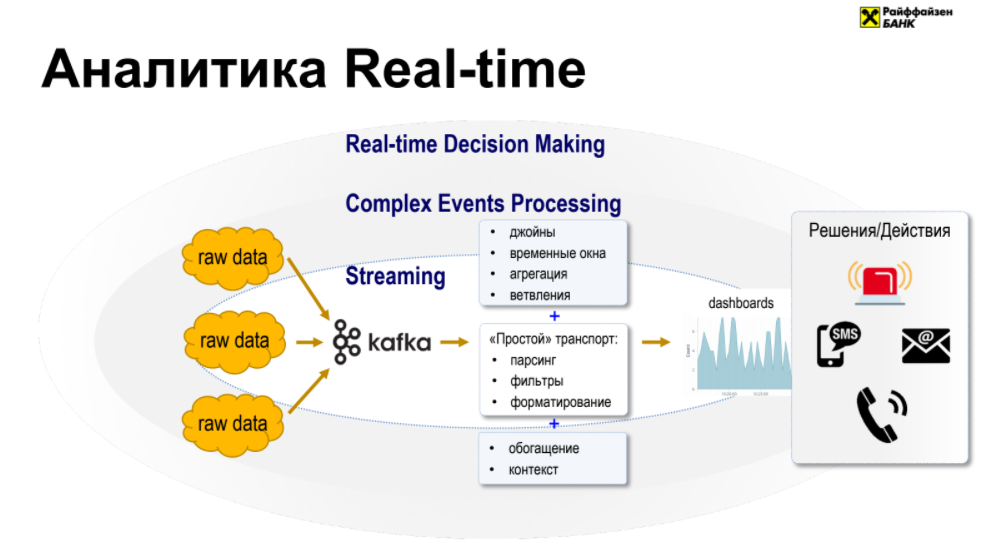
В основе каждой RTDM системы лежит стриминг, который работает таким образом, что есть источники, из которых мы можем снимать события и класть в шину данных, а потом оттуда забирать, причем мы не можем соединять события из разных источников и как-то их агрегировать.
Следующий уровень абстракции над стримингом — это Complex Events Processing (CEP), который отличается от простого стриминга тем, что появляется много источников, которые мы пытаемся обрабатывать одновременно, то есть мы видим события совместно, появляются join-ы этих событий, можем как-то их на лету агрегировать и т.д.

Последний элемент абстракции и есть сама система RTDM, основное отличие которой от CEP в том, что в ней есть набор преднастроенных решений и действий, которые можно принимать в онлайне: звонок из call-центра в случае заявки на консультацию в интернет-банке, SMS со специальным предложением в случае пополнения счета на крупную сумму и другие действия.
Как эту систему реализовать? Можно пойти к вендорам и в 99% случаев это является стандартной практикой в области. С другой стороны у нас есть команда инженеров данных, которая может все сделать сама, использовав open-source решения. Главный недостаток большинства из них — это отсутствие user-интерфейса.
Однако нам удалось найти подходящую для нас платформу — выбор пал на HortonWorks Data Flow 3.0, в новой версии которой появилось как раз то, что нам нужно — Streaming Analytics Manager (SAM), где был реализован графический интерфейс, а учитывая, что HortonWorks уже был у нас в продакшне, мы пошли по пути наименьшего сопротивления.
Перейдем к архитектуре нашего RTDM решения. Данные из источников приходят в шину данных, где агрегируются, а затем с помощью HDF забираются и кладутся в Kafka. Далее вступает SAM, где с помощью user-интерфейса пользователь запускает кампанию на исполнение, тут же компилируется JAR-файл и отправляется в Apache Storm.

Центральным элементом всей системы является SAM, благодаря которому все это стало возможным. Вот как выглядит его интерфейс:

SAM предоставляет пользователю большие возможности: есть выбор источников данных, набора процессоров, которыми он обрабатывает поток данных, группа фильтров, бранчевание, выбор действия для определенного клиента, будь-то абсолютно персонализированное предложение или общее для определенной группы людей действие.
Lamoda
Наш Data Science Weekend был в самом разгаре и на очереди Игорь Мосягин — еще один выпускник программы Data Engineer и R&D разработчик в компании Lamoda. Игорь рассказал о том, как они оптимизировали поисковые подсказки на сайте и пытались подружить Apache Solr, Golang и Airflow.
На нашем сайте, как и на многих других, есть поисковое поле, куда люди что-то вводят и по ходу появляются подсказки, которыми мы пытаемся предугадать, что именно нужно пользователю. На тот момент у нас уже было некоторое готовое решение, однако оно не совсем нас устраивало. К примеру, система не реагировала, если пользователь путал раскладку.
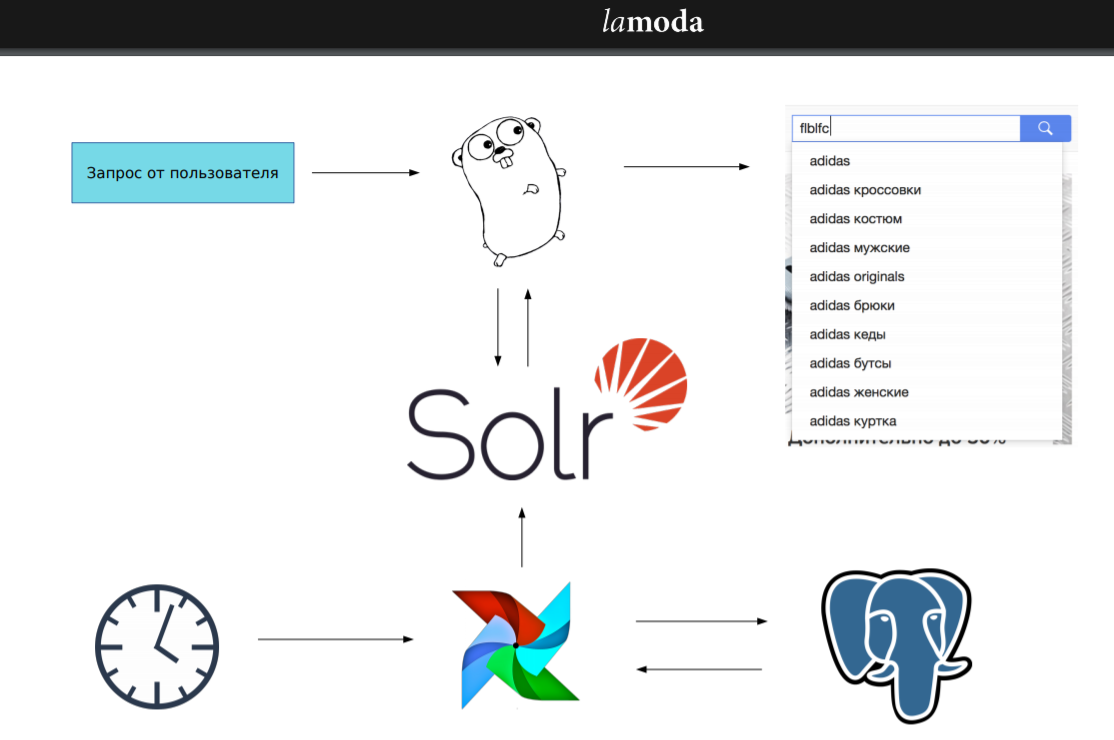
Apache Solr является центром всей получившейся системы, его мы использовали и в старом решении, однако теперь мы решили внедрить и Airflow, про которого я узнал на программе Data Engineer. В результате запрос, который приходит от пользователя попадает в наш сервис, написанный на Go, который его предобрабатывает и отправляет в Solr, а затем получает ответ и возвращает его пользователю. При этом регулярно, в какое-то заранее заданное время запускается Airflow, который лезет в базу данных и если требуется, то запускает импорт данных в Solr. Главное во всем этом тот факт, что от запроса пользователя до ответа проходит 50 мс, из них львиная доля — 40 мс — это запрос в Solr и получение ответа от него.

Вообще говоря, Apache Solr — это такая большая «махина» с хорошей документацией, в ней есть много саджестеров, которые работают по разной логике: могут возвращать ответ только по точному совпадению, либо есть варианты, когда пенализируется нахождения строки далеко от начала слова и т.д. Всего есть 7 или 8 вариантов саджестеров, но мы использовали только 3, так как остальные в большинстве случаев отрабатывали очень медленно.
Также важно время от времени обновлять веса, так как меняются частотности запросов. К примеру, если в этом месяце одним из наиболее популярных запросов являются зимние сапоги, то, конечно, это надо учитывать.
Aligned Research Group
Далее подошла очередь Николая Маркова, который является Senior Data Engineer в компании Aligned Research Group, а также читает лекции на наших программах «Специалист по большим данным» и Data Engineer. Николай рассказал о преимуществах и недостатках экосистемы Hadoop и почему анализ и обработка данных в командной строке может быть неплохой альтернативой.
Если смотреть на Hadoop с современной инженерной точки зрения, то можно найти не только множество плюсов, но и ряд недостатков. К примеру, MapReduce является парадигмой общего назначения. По сути все сводится к тому, что вы кучу времени тратите на то, чтобы ваш алгоритм перенести на MapReduce, чтобы там что-то посчиталось, при этом, возможно, наделав в процессе кучу ошибок. Иногда нужно настакать много MapReduce-ов, чтобы другую вещь сделать, и выходит, что вместо того, чтобы заниматься написанием бизнес-логики, вы тратите время на MapReduce.

Преимуществом Hadoop, конечно, является поддержка Python. Он всем хорош, я на нем пишу и всем рекомендую, но проблема в том, что, когда мы пишем на Python под Hadoop, нам нужно много инженерной поддержки, чтобы все это заставить работать в продакшне: все аналитические пакеты (Pandas, Numpy и т.д.) должны стоять на конечных нодах, все это должно развертываться автоматически. В итоге получается, что мы либо подстраиваемся под конкретного вендора, который позволяет свои версии туда поставить, либо нам нужна система управления конфигурацией, которая и будет заниматься развертыванием.
Естественно, один из основных минусов Hadoop и одновременно главная причина появления Spark заключаются в том, что Hadoop всегда пишет результаты на диск, читает с него и пишет туда же. По сути, даже если мы разбросаем этот процесс на множество нод, то он все равно будет работать со скоростью диска (усредненной).
Решить проблему скорости можно, конечно, масштабированием Hadoop-а, то есть попросту «закидать деньгами». Однако есть и более эффективные альтернативы. Одной из них является анализ и обработка данных в командной строке. В ней действительно можно решать серьезные аналитические задачи, и это будет в несколько раз быстрее чем на Hadoop. Единственный минус представлен ниже:

Кому-то это может показаться нечитабельным, однако эта штука работает на порядок быстрее, чем скрипт на Python, поэтому отлично, если у вас есть инженер, способный писать такие вещи в командной строке.
Также я не совсем понимаю, почему в компаниях обязательно ваша бизнес-логика должна быть завязана на реляционной базе данных, ведь ничего не мешает взять в современном виде какую-то нереляционную БД (тот же MongoDB). Не стоит оправдываться тем, что у вас там кучу join-ов и невозможно обойтись без SQL. На сегодняшний день БД очень много, и вы можете выбрать себе, какая к вам ближе лежит.
Если же вам все-таки никак не обойтись без SQL, то можете попробовать Presto — это расширяемый движок для распределенной работы со многими источниками данных сразу. То есть вы можете написать плагин для вашего источника данных и по сути извлекать с помощью SQL все, что угодно. В принципе в Hive та же логика, но он завязан на инфраструктуру Hadoop, а Presto — независимая разработка. Плюсом идет интеграция с Apache Zeppelin — это такой красивый front-end, где можно писать SQL-запросы и сразу получать графики.
Rambler&Co
Закончить наши продуктивные выходные выпала честь Александру Шорину — преподавателю на программе Data Engineer и старшему инженеру-разработчику Python в Rambler&Co, который продолжал историю своих коллег с предыдущего дня конференции о том, как они распознавали пол и возраст посетителей кинотеатров с помощью компьютерного зрения. В этот раз основное внимание было уделено именно инженерной части проекта.
Исходный пайплайн выглядит следующим образом:

Камеры передают фотографии на WebDAV, далее задача из Airflow вытаскивает новые фотки и отсылает их в API, формирующая все это в отдельные задачи, а затем закидывает в RabbitMQ. Из «кролика» воркеры забирают эти задания, делают с ними некие преобразования и отправляют результаты обратно.
Как мы можем масштабировать этот процесс с технической точки зрения? Сколько нам нужно еще машин, чтобы справляться со всем потоком фотографий? Чтобы ответить на этот вопрос, возьмем профайлер. Мы решили взять PyFlame, сделанный компанией Uber, — это фактически обертка над Ptrace, которая цепляется к процессу в Linux, смотрит, что он делает, и записывает, что и сколько раз было.
Мы запустили тестовый датасет, состоящий из 472 фотографий, и он обсчитался за 293 секунды. Много это или мало? Отчет PyFlame при этом выглядит следующим красивым образом:

Тут мы видим «ущелье» загрузки моделей, есть «долина» сегментации и другие интересные штуки. На этом отчете видно, что наш код тормозит, поскольку на него ссылается огромная планка в центре картинки.
На деле оказалось, что нам требовалось поменять лишь одну строчку в Jupyter ноутбуке, чтобы оптимизировать сегментацию: длительность процесса упала с 293 до 223 секунд. Также мы перешли с PIL-а, который за медлительность не ругал только ленивый, на OpenCV, благодаря чему общее время работы уменьшилось еще на 20 секунд. Наконец, использование Pillow-SIMD, о котором рассказал Александр Карпинский в своем выступлении на конференции Piter Py #4, для обработки изображений позволило уменьшить время выполнения задачи до 183 секунд. Правда на PyFlame это сказалось незначительно:

Как видим, тут все еще выделяется PyTorch, поэтому будем «пинать» его. Что с ним можно сделать? У PyTorch при отправке данных на видеокарточку, они сначала проходят предобработку, а потом кидаются в DataLoader.
Изучив принципы работы DataLoader-а, мы увидели, что он поднимает воркеры, обрабатывает датасет, а потом убивает воркеры. Возникает вопрос: а зачем нам постоянно поднимать и убивать воркеры, если у нас в кинозале мало людей, а обработка фотографии занимает около секунды? Зачем каждую секунду поднимать и убивать два процесса, если это неэффективно?
Оптимизировать DataLoader удалось за счет его модификации: теперь он не убивает воркеры и не использует их, если в зале находится менее 24 человек (число взято более-менее с потолка). При этом такая оптимизация не дала значимый прирост к скорости обработки, однако средняя утилизация CPU снизилась с ~600% до ~200%, то есть в 3 раза.
Наконец, в число прочих доработок входит облегчение реализации Conv2d, удаление лишних лямбд из модели нейронной сети и конвертирование Image в np.array для ToTensor.
Напоследок еще немного отзывов о нашей конференции от докладчиков и слушателей:
«Очень комфортная тусовка, где можно в кулуарах и пообщаться в целом про индустрию и подловить спикеров с вопросами. Как докладчик отмечу профессионализм организаторов, видно что всё сделано так, чтобы и спикерам и слушателям было максимально комфортно.» — Игорь Мосягин, докладчик, R&D developer, Lamoda.
«Очень понравилось выступать. Доброжелательная публика, умные вопросы.» — Михаил Сеткин, докладчик, Product Manager, Райффайзенбанк.
Полные выступления всех спикеров вы можете посмотреть на нашей странице в Facebook. Скоро увидимся на других наших мероприятиях!
