
В своем первом посте в этом блоге я обещал рассказать вам о NetApp «с технической стороны». Однако прежде чем рассказать о большинстве из имеющихся в системах NetApp возможностей, мне придется рассказать о «фундаменте», о том, что лежит в основе любой системы хранения NetApp — о специальной структуре организации данных, которую традиционно принято называть «файловой системой WAFL» — Write Anywhere File Layout — Файловой Структурой с Записью Повсюду, если перевести дословно.
Если вы сочтете, что «для Хабра» текст суховат, то потерпите, дальше будет интереснее, но не рассказать об устройстве того, что лежит в основе подавляющего большинства практических «фич» NetApp я не могу. В дальнейшем будет куда сослаться «для интересующихся» на подробное объяснение в следующих постах, о более практических «фишках».
Так, или иначе, но почти все, что NetApp умеет уникального растет именно из придуманной в начале 90-х Дэвидом Хитцем и Джеймсом Лау, сооснователями «стартапа» Network Appliance, файловой системы. Хороший аргумент за то, насколько важной и полезной может оказаться в будущем развитии изначально грамотная и продуманная «архитектура» продукта.
Но сначала о том, почему NetApp понадобилась своя файловая система, чем ему не подходили существующие на тот момент? Вот что говорит по этому поводу один из создателей NetApp, сооснователь и CTO компании Dave Hitz:
«Изначально мы не предполагали писать свою файловую систему. Нам представлялось, что Berkeley FFS нам вполне подходила. Но несколько присущих ей неразрешимых проблем вскоре заставили нас заняться собственной файловой системой.
Тестирование целостности файловой системы в случае нештатной остановки (fsck) у FFS на тот момент делалось неприемлемо медленно. С увеличением размеров файловой системы ситуация все более ухудшалась, что делало практически невозможной нашу идею объединить все диски в единый дисковый том с единым пространством.
Мы хотели сделать максимально простое в использовании устройство. Для этого нам надо было объединить все диски в единую файловую систему. На тот момент (речь идет о начале 90-х, прим track) люди обычно создавали на каждом отдельном диске отдельную файловую систему и монтировали их вместе в общее дерево, что было неудобно и неуниверсально.
Используя много дисков разом, с общей файловой системой на них, нам потребовался бы RAID. На то было две причины. Первая: при объединении сразу множества дисков в единую файловую систему вы рисковали потерять всю файловую систему в результате сбоя одного из множества дисков. Вторая: вероятность сбоя повышалась с увеличением количества дисков. Нам был нужен RAID, и мы решили реализовать RAID просто как часть нашей файловой системы.
Ранее существовавшие файловые системы работали поверх RAID, и ничего не знали о том, как происходит размещение данных на физическом уровне, поэтому не могли оптимизировать свою работу с учетом этих сведений. Построив нашу собственную файловую систему, которая знала все особенности расположения данных на множестве физических дисков, и самостоятельно реализуя RAID, мы смогли максимально оптимизировать ее работу.
Вот поэтому, посмотрев на все это, мы решили написать свою собственную файловую систему для нашего устройства.»
(кто сказал «с блэкджеком и шлюхами»? ;)
Главный принцип, положенный в основу функционирования файловой системы WAFL, отличающий ее от всех тогда существовавших файловых систем, может показаться немного парадоксальным: единожды записанный блок данных в составе файла в дальнейшем не перезаписывается. Он может быть только удален (очищен), но НЕ ПЕРЕЗАПИСАН.
Таким образом любой блок данных на файловой системе может быть либо «пустым», и тогда он может быть записан, либо «записанным», и тогда он может быть либо считан, либо стерт, когда на него больше не ссылается ни одна запись вышележащей структуры. Запись (перезапись) в уже занятый какими либо данными блок невозможна по внутренней логике файловой системы.
Необходимые же изменения содержимого записанного файла «дописываются» к нему, на свободное пространство файловой системы.
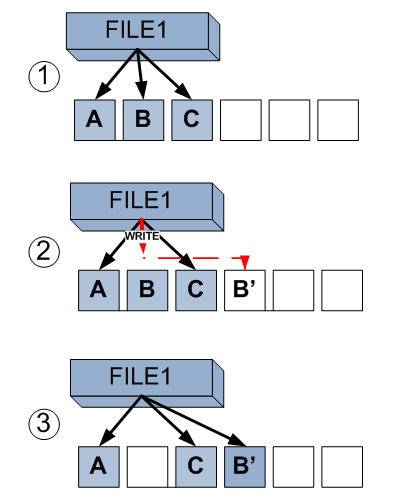
Рассмотрим по шагам.
На первом шаге мы видим файл, занимающий три блока на файловой системе: A, B и C.
Шаг 2. Использующая этот файл программа желает изменить данные в его середине, которые хранятся в блоке B. Открыв файл на запись она изменяет эти данные, но FS, вместо изменения данных в уже записанном блоке B, записывает их вполностью пустой блок в области свободных блоков.
Шаг 3. Файловая система переставляет указатель используемых файлом блоков на записанный блок B' с блока B. А так как на блок B никто больше не ссылается, то он освобождается и становится пустым.
Такая своеобразная модель позволяет нам получить две важных особенности использования:
- Превратить случайные (random) записи на систему хранения в последовательные (sequental).
- Очень просто и эффективно организовать так называемые Snapshots, снэпшоты, или мгновенные «снимки» состояния данных на дисках.
Разберем эти моменты подробнее.
Структура организации блоков файловой системы WAFL будет понятна всем, знакомым с файловыми системами «инодового» (inodes) типа, всех многочисленных «юниксных» наследников Berkeley's FFS.
Блоки данных файла адресуются с помощью структуры, под названием 'inode'.
Inode может указывать как на блоки непосредственно данных файла, так и на промежуточные inodes «непрямой адресации», образуя своеобразное «дерево», где в «корне» — «корневой inode», а на самом конце ветвей — блоки непосредственно данных.
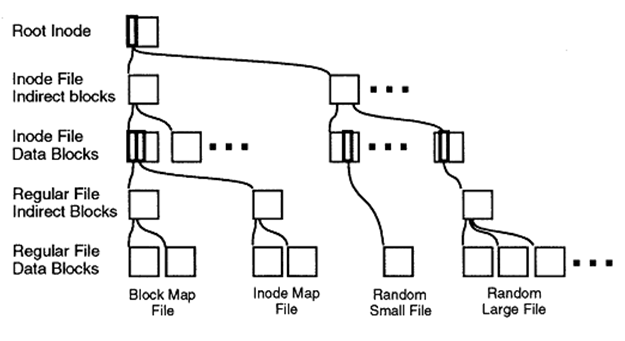
Такую схему использует большинство «юниксных» файловых систем, что же придумано нового в WAFL?
Поскольку, как я уже упомянул выше, содержимое уже записанных данных файловой системы не изменяется, а новые блоки к «дереву» лишь только добавляются (и остаются там, пока на них хоть кто-то ссылается), очевидно, что сохранив «корень» такого дерева, корневой inode, на какой-то момент времени, мы получим в результате полный «мгновенный снимок» всех данных на диске на этот момент. Ведь содержимое никаких уже записанных блоков (например, с прежним содержимым файла) гарантировано не изменится.
Сохраняя единственный блок, содержащий корневой inode мы сохраняем и все данные, на которые он так или иначе ссылается.
Это позволяет легко создавать «снэпшоты» состояний данных на дисках.
Такой «снэпшот» выглядит как полное содержимое всей вашей файловой системы на определенный момент времени, тот, в который был сохранен корневой inode. Каждый файл на нем доступен для чтения (изменять его, конечно, не получится).
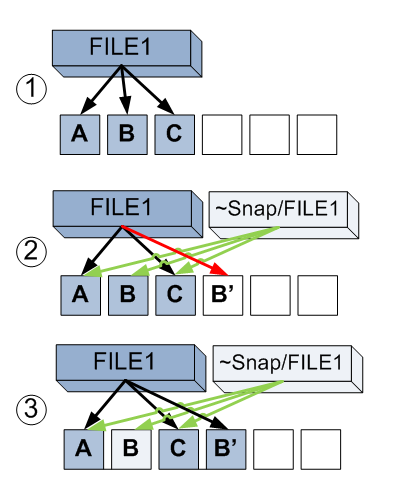
Рассмотрим подробнее. На первом шаге у нас вновь файл, занимающий три блока файловой системы.
На шаге 2 мы создаем «снэпшот». Как уже рассказано выше, это просто копия ссылок активной файловой системы на занимаемые файлами блоки. Теперь каждый из блоков A, B и C имеет по две ссылки. Один от файла File1, второй — от этого файла из сделанного снэпшота. Это похоже на линк в UNIX-файловой системе, но линки ведут не на файл, а на блоки данных этого файла на файловой системе. Программа изменяет данные в блоке B файла, вместо которого происходит запись нового содержимого в блок B'.
Шаг 3. Однако старый блок B не становится пустым, так на него ссылаются из снэпшота. Теперь, если мы хотим прочитать содержимое File1 до изменений, мы можем использовать файл ~snap/File1, который обратится к блокам A, B и C. А новое содержимое доступно при чтении самого File1 — A, B' и C. Таким образом нам доступно как старое, через ее снэпшот, так и новое содержимое файловой системы.
Как я уже сказал выше, такая организация записи на файловую систем позволяет достичь с точки зрения системы сразу нескольких важных вещей:
- Превратить операцию random write в значительно более быструю и эффективную для системы хранения операцию sequental write (так как всю группу записей в кэше, логически предназначавшихся разным файлам в разных местах FS можно записать в один последовательный сегмент пустых блоков).
- Делать запись на диски эффективно, «полным страйпом».
Необычно в системах NetApp также то, что они реализовали в своей файловой системе, которая, напомню, является еще и сама себе RAID-ом и менеджером томов, необычный тип RAID — RAID type 4. Это, напомню, модель «чередование с четностью», похожая на привычный RAID-5, но диск четности выделен на отдельный физический диск (а не «размазан» по всему RAID как в type 5).
Обычно RAID-4 редко используется «в живой природе», так как ему присущ один, но очень серьезный недостаток — его производительность, при «обычном» его использовании, упирается в производительность диска parity, на каждую операцию записи на RAID-группу приходится операция изменения на диске parity, а значит сколь ни увеличивай размер RAID-группы, ее суммарная производительность все равно упрется в производительность одного диска на запись.
С другой стороны, RAID-4, как RAID с выделенным parity (в отличие от, например, RAID-5, «с невыделенным parity») имеет очень солидный плюс, заключающийся в возможности расширить емкость RAID добавлением дисков «мгновенно». Добавление диска в RAID-4 не приводит к необходимости «перестроения RAID», непосредственно после физического вставления HDD и добавления диска данных в уже существующий RAID, мы можем начать на него писать, расширив на него как внутреннюю файловую систему WAFL, так и лежащие поверх нее структуры, например тома данных CIFS, NFS или LUN-ы. Для устройства, изначально ориентированного на простоту обслуживания, и «не-IT-шные» компании в качестве клиентов, это было большим плюсом.
Однако, что делать с быстродействием?
Оказалось, что если мы пишем на RAID-4 последовательно, и «полными RAID- страйпами», то проблемы с упиранием в диск parity просто нет. Подготовленный страйп одной операцией записи заносится во все диски RAID-группы, затем ожидает сборки следующего страйпа, и «в один присест» записывает и его.
Что же мешает делать также на любой файловой системе?
«Random-ность» записи. Подавляющее большинство записей на современных задачах это довольно хаотические записи по пространству диска. Поскольку в классической файловой системе мы вынуждены перезаписывать тысячи, десятки тысяч блоков данных, произвольно разбросанных по пространству диска, причем обычно без какой-либо логики с точки зрения диска, становится чрезвычайно сложно собрать в кэше «полный страйп». Для этого надо либо увеличивать пространство кэша на запись, либо увеличивать время нахождения данных в нем, что повышает вероятность того, что, наконец, мы, в какой-то момент соберем нужный нам страйп в этом «паззле», и сможем сбросить его максимально эффективно на RAID.
Однако, как вы помните, в WAFL у нас нет нужды гонять головки дисков по «блину», чтобы перезаписать пару (кило)байт где-то в середине файла. Нужно изменить данные? Не проблема. Вот там у нас большой пустой сегмент, пишите все скопившееся разом туда, а потом переставьте указатель в inode на новое место. Вся ожидающая очереди на запись группа байт разом, не гоняя по блину головки, в один прием, последовательно (Sequental), утекает на диски. Запись завершена, а значение parity, предварительно обсчитанное для страйпа, также в один прием, занесено на диск parity.
Конечно ничто не дается даром, и превращение случайной записи в последовательную в ряде случаев может превратить «последовательное» чтение в «случайное». Однако, практика показывает, что и последовательных чтений (как и последовательных записей) в практике случается не так много, а на случайном чтении такая «размазанность» файла по файловой системе сказывается сравнительно мало.
К тому же большой кэш чтения чаще всего успешно справляется с этой проблемой.
Для тех же случаев, когда производительность ПОСЛЕДОВАТЕЛЬНОГО чтения действительно важна (например при резервном копировании, которое происходит в пределах файла преимущественно последовательно) на системах NetApp работает специальный фоновый процесс оптимизации, непрерывно повышающий степень «последовательности» размещения данных (то что в unix-ных FS называется 'contiguous'), при этом данные, оцененные как располагающиеся последовательно, собираются в более длинные последовательные «чанки», что облегчает их дальнейшее последовательное чтение (sequental read).
Второй особенностью WAFL является необычная схема «журналирования». Тут надо сказать, что для 1993 года, когда появилась WAFL, журналирование все еще было довольно редкой «фичей» в файловых системах, и одной из задач при созданииWAFL была организация консистентного хранения данных и быстрый перезапуск после сбоя. В эти годы «грязный» перезапуск объемных файловых систем на UNIX-серверах зачастую вызывал запуск fsck на многие минуты, а, иногда, и часы.
В WAFL используется несколько необычная схема, с «журналом», вынесенным на отдельное физическое устройство — NVRAM.

NVRAM это необычное устройство. Хотя внешне оно действительно напоминает привычный сегодня кэширующий контроллер, с ОЗУ и батареей для питания его на выключенной системе, и сохранения данных в нем, принцип работы его совсем иной.
Поступающие на систему хранения данные и команды (например операции NFS) предварительно накапливаются в NVRAM, после чего, «атомарно», переносятся на диски, создавая при этом так называемые Consistency Points (CP), «точки консистентности», «непротиворечивого состояния» (кстати CP это тоже такой специальный внутренний «снэпшот», используется тот же самый логический механизм). Операция создания CP происходит либо раз в несколько секунд, либо по заполнению определенного объема памяти в NVRAM (high watermark). Между CP состояние файловой системы полностью консистентно, а переключение на следующую CP — моментально и атомарно, поэтому файловая система всегда находится в целостном состоянии, что похоже на то, как организована работа у SQL-баз данных.
С точки зрения системы, данные либо целиком успешно записаны, либо еще не покинули NVRAM и не попали на диски. Так как файловая система не перезаписывает свое уже занесенное на диски содержимое, то организовать «атомарность» очень просто, ситуация, когда в части блоков уже изменены данные, а в части — еще нет (например произошел программный или аппаратный сбой) попросту невозможна. Возможна ситуация, когда в часть считающихся ПУСТЫМИ блоков уже занесены новые данные, но пока не переставлен «указатель» на новый CP (моментальное действие), фиксирующий новое состояние файловой системы, она остается в консистентном состоянии предыдущего CP, и это не страшно. Если работоспособность системы будет восстановлена, запись продолжится с момента, на котором ее прервали на последнем успешном CP, и запишет лежащие в NVRAM с батарейным питанием (до недели без электропитания системы в целом) данные, те, на которых процесс оборвался, и тогда переставит CP. «Полузаписанные» данные в момент сбоя будут «на уровне ФС» считаться «пустыми» (а данные в NVRAM — его не покинувшими), пока не обновится указатель на CP.
То есть работа системы выглядит следующим образом:
NVRAM — системе: Пора писать CP!
Система — NVRAM-у: Ну, поехали.
Пишем.
Система NVRAM-у: Как там у вас дела? Все готово?
NVRAM: Готово, шеф!
Система — файловой системе: Ну, с богом! Плюсадин!
Файловая система: (инкрементирует указатель своего текущего состояния на сформированный CP) хрю!
Вариант неудачной записи:
NVRAM — системе: Все пропало, шеф! Диски не отвечают! Шеф? Вы здесь?
Система (загрузившись): Уф, шоэто было? NVRAM! Замри! Файловая система — никто никуда не идет! Используем последнюю валидную запись CP перед сбоем! NVRAM — теперь повтори последнюю операцию записи, на которой прервали, с самого ее начала!
NVRAM: Есть, шеф!
Такая остроумная схема делает файловую систему исключительно целостной и устойчивой, вплоть до того, что многие практические администраторы за много лет работы систем NetApp никогда не сталкиваются ни с какими случаями нарушения ее целостности и с необходимостью «запускать chkdsk (fsck для жителей соседней OS-галактики;)».
В скобках отмечу, что средства контроля целостности WAFL в системе конечно же есть, в том случае, если они вам понадобятся.
Подробнее о устройстве и принципах работы WAFL вы сможете из авторской публикации «Создание специализированной файловой системы для файлового сервера NFS», опубликованной в 1994-м году в журнале USENIX, и описывающей базовые принципы построения WAFL. На сайте российского дистрибутора компании Netwell, в регулярно пополняемой библиотеке переведенных Best Practices можно скачать перевод этого документа.
В следующей статье я расскажу о том, как на WAFL удалось реализовать дедупликацию данных, не замедляющую работу системы хранения.
