
Для управления кодом Spark-приложений мы используем подход, описанный в предыдущей статье.
Речь идет об управлении качеством кода при разработке Spark ETL, чтобы не превратить работу над проектом в полет души, пугающий даже автора. В результате Spark ETL application выглядит просто как последовательность Spark SQL-запросов. Сама ETL-трансформация описывается как объект в отдельном файле конфигурации.
Какие плюсы у такого подхода?
- Он обладает большой гибкостью. Собственно, код приложения не зависит от логики трансформации и легко может быть дописан или вообще написан с нуля на новом проекте. Например, в случае необходимости парсинга JSON или XML.
- Важно то, что код остается простым для освоения новым человеком в команде, какие бы сложные трансформации не встречались в проекте. Растет лишь число и объем файлов конфигурации, описывающих отдельные трансформации.
- Для расширения проекта можно нанимать людей, знающих всего лишь SQL.
Однако, такой подход имеет и недостатки, которые являются следствием того, что это не полноценный инструмент, а скорее внутренний регламент разработки. В результате нет многого из того, что хотелось бы. А хотелось бы следующее:
- Создавать автотесты
- Поддерживать шаблонизатор
- Создавать документацию по проекту
- Валидировать модель, описывающую трансформацию
- И главное – чтобы ряд очевидных вещей, типа витрины различного формата сохранения и поддержки полной, частичной и инкрементальной загрузки, поддерживались из коробки.
Как оказалось, такой инструмент уже есть и это приложение, основанное на похожих принципах, предоставляющее возможность описать ETL-трансформацию как набор SQL-запросов и выполнить их на Spark — Data Build Tool (DBT)
Приложение упоминается как очевидный к использованию инструмент для ETL. Более того, в этом можно убедиться, посмотрев, как этот инструмент продвигают Databriks или здесь, прочитав статью.
Мне самому очень понравился вот этот материал: DBT (Data Build Tool) Tutorial from Fishtown Analytics
DBT предлагает вести проект ETL-трансформации в виде иерархии SQL-запросов, поддерживает шаблонизатор, проверяет валидность ссылок-запросов друг на друга, генерит автотесты и документацию. Кроме того, поддерживает различные среды выполнения запросов, умеет создавать граф зависимостей задач проекта. Распространяется бесплатно, но содержит и платные версии с поддержкой среды разработки, а также поддерживается многими другими инструментами: например, есть много материалов по связке Dagster – DBT.
Как же справляется DBT с задачей, по мнению тех, кому пришлось решать те же самые проблемы самостоятельно?
Самое интересное как всегда скрыто в деталях, поэтому интересно посмотреть именно их.
Отлично, попробуем это приложение. Что же предлагает продукт?
- Работа со Spark. Этот пункт понятен. DBT предлагает разные возможности запуска запросов, из которых состоит проект, в том числе и на Spark. К тому же к Spark можно подключаться несколькими способами: через Thrift Server или в облаке;
- Разработка проекта как набора SQL файлов. Разработка проекта на DBT – это разработка SQL запросов, которые могут ссылаться друг на друга, и это – главная фишка DBT, как и в целом такого подхода;
- Сохранение витрин в разных форматах. Результирующие витрины можно сохранять различными способами: как таблицу, витрину, с указанием опций партиционирования;
- Опции обновления витрин. DBT позволяет настраивать полное, частичное и инкрементальное обновление витрины из коробки;
- Наличие шаблонизатора. Запросы в DBT кастомизируются через Ninja Template и с добавлением макросов;
- В DBT есть возможность выполнения addhook-запросов, например, заполнить таблицу с id сессии загрузки или раздать права на целевую таблицу;
- DBT создает автотесты, документацию по проекту, а также строит граф зависимостей между запросами.
В общем, есть все, что так или иначе встречалось в подобных проектах и что приходилось добавлять в собственные разработки.
Единственное, с чем пришлось повозиться и это оказалось неожиданным – подключение к Spark. DBT предлагает различные варианты исполнения запросов. Нас интересует только Spark для подключения к которому тоже есть разные опции. Так как речь идет о собственных кластерах под управлением Cloudera, то нам остается вариант Spark Thrift-сервера. И тут внезапно оказывается, что Cloudera включает в дистрибутив Spark без Thrift-сервера.
Оказывается, они думают, что вам нужна Impala, поэтому старательно собирают дистрибутив Spark без Thrift и радостно включают его в дистрибутив кластера.
Кто виноват – ясно. Что делать?
Скачиваем нужный дистрибутив Spark, ставим его на ноду кластера. Указываем в настройках ссылку на /etc/hadoop/conf. Запускаем из дистрибутива Spark Thrift Server, после чего указываем host-port нашего Thrift-сервера в настройках DBT.
Может быть кто-то знает другой способ? Я не нашел. Ок. Создаем тестовый проект. Настраиваем профиль DBT:

В проекте модель, которая обращается к запросам одной из таблиц Hive, чтобы проверить, что настройки прочлись.
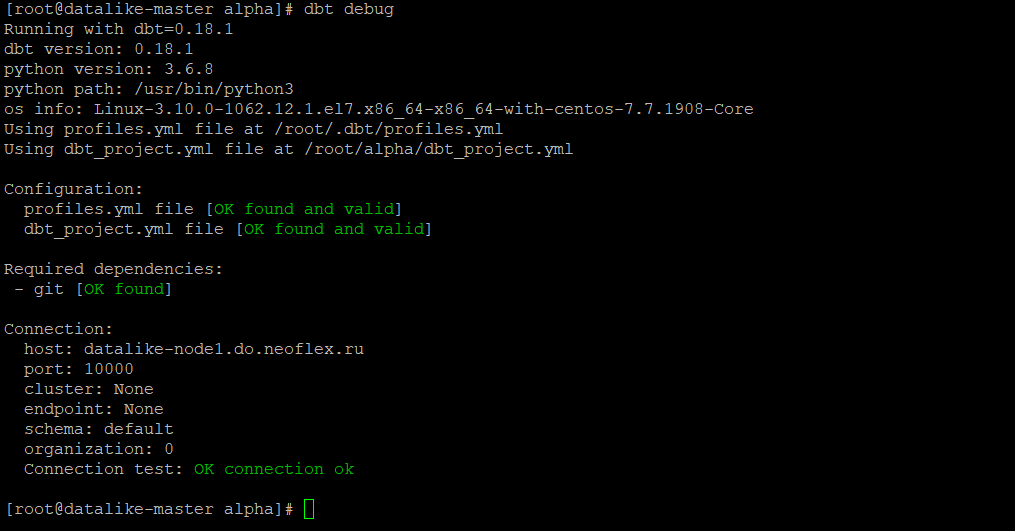
Сначала проверяем, что DBT видит Spark.
DBT debug
Теперь проверяем тестовую модель, которая Spark-запросом обращается в Hive:

Подключился, запросы проходят, все хорошо.
