Уважаемые читатели, доброго дня!
Задача построения ИТ-платформ для накопления и анализа данных рано или поздно возникает у любой компании, в основе бизнеса которой лежат интеллектуально нагруженная модель оказания услуг или создание технически сложных продуктов. Построение аналитических платформ — сложная и трудозатратная задача. Однако любую задачу можно упростить. В этой статье я хочу поделиться опытом применения low-code-инструментов, помогающих в создании аналитических решений. Данный опыт был приобретён при реализации ряда проектов направления Big Data Solutions компании «Неофлекс». Направление Big Data Solutions компании «Неофлекс» с 2005 года занимается вопросами построения хранилищ и озёр данных, решает задачи оптимизации скорости обработки информации и работает над методологией управления качеством данных.
Избежать осознанного накопления слабо и/или сильно структурированных данных не удастся никому. Пожалуй, даже если речь будет идти о малом бизнесе. Ведь при масштабировании бизнеса перспективный предприниматель столкнётся с вопросами разработки программы лояльности, захочет провести анализ эффективности точек продаж, подумает о таргетированной рекламе, озадачится спросом на сопроводительную продукцию. В первом приближении задача может быть решена «на коленке». Но при росте бизнеса приход к аналитической платформе все же неизбежен.
Однако в каком случае задачи аналитики данных могут перерасти в задачи класса «Rocket Science»? Пожалуй, в тот момент, когда речь идёт о действительно больших данных.
Чтобы упростить задачу «Rocket Science», можно есть слона по частям.

Чем большая дискретность и автономность будет у ваших приложений/сервисов/микросервисов, тем проще вам, вашим коллегам и всему бизнесу будет переваривать слона.
К этому постулату пришли практически все наши клиенты, перестроив ландшафт, основываясь на инженерных практиках DevOps-команд.
Но даже при «раздельной, слоновьей» диете мы имеем неплохие шансы на «перенасыщение» IT-ландшафта. В этот момент стоит остановиться, выдохнуть и посмотреть в сторону low-code engineering platform.
Многих разработчиков пугает перспектива появления тупика в карьере при уходе от непосредственного написания кода в сторону «перетаскивания» стрелочек в UI-интерфейсах low-code систем. Но появление станков не привело к исчезновению инженеров, а вывело их работу на новый уровень!
Давайте разбираться почему.
Анализ данных в сфере логистики, телеком-индустрии, в области медиаисследований, финансовом секторе, всегда сопряжён со следующими вопросами:
То есть у инженеров имеется огромное количество высокоуровневых задач, выполнить которые с достаточной эффективностью можно, лишь очистив сознание от задач низкоуровневой разработки.
Предпосылками перехода разработчиков на новый уровень стали эволюция и цифровизация бизнеса. Ценность разработчика также изменяется: в значительном дефиците находятся разработчики, способные погрузиться в суть концепций автоматизируемого бизнеса.
Давайте проведём аналогию с низкоуровневыми и высокоуровневыми языками программирования. Переход от низкоуровневых языков в сторону высокоуровневых – это переход от написания «прямых директив на языке железа» в сторону «директив на языке людей». То есть добавление некоторого слоя абстракции. В таком случае переход на low-code-платформы с высокоуровневых языков программирования — это переход от «директив на языке людей» в сторону «директив на языке бизнеса». Если найдутся разработчики, которых этот факт опечалит, тогда опечалены они, возможно, ещё с того момента, как на свет появился Java Script, в котором используются функции сортировки массива. И эти функции, разумеется, имеют под капотом программную имплементацию другими средствами того же самого высокоуровнего программирования.
Следовательно, low-code – это всего лишь появление ещё одного уровня абстракции.
Тема low-code достаточно широка, но сейчас я хотел бы рассказать о прикладном применении «малокодовых концепций» на примере одного из наших проектов.
Подразделение Big Data Solutions компании «Неофлекс» в большей степени специализируется на финансовом секторе бизнеса, cтроя хранилища и озёра данных и автоматизируя различную отчётность. В данной нише применение low-code давно стало стандартом. Среди прочих low-code-инструментов можно упомянуть средства для организации ETL-процессов: Informatica Power Center, IBM Datastage, Pentaho Data Integration. Или же Oracle Apex, выступающий средой быстрой разработки интерфейсов доступа и редактирования данных. Однако применение малокодовых средств разработки не всегда сопряжено с построением узконаправленных приложений на коммерческом стеке технологий с явно выраженной зависимостью от вендора.
С помощью low-code-платформ можно также организовывать оркестрацию потоков данных, создать data-science-площадки или, например, модули проверки качества данных.
Одним из прикладных примеров опыта использования малокодовых средств разработки — является коллаборация «Неофлекс» c компанией Mediascope, одним из лидеров российского рынка исследований медиа. Одна из задач бизнеса данной компании – производство данных, на основе которых рекламодатели, интернет-площадки, телеканалы, радиостанции, рекламные агентства и бренды принимают решение о покупке рекламы и планируют свои маркетинговые коммуникации.

Медиаисследования – технологически нагруженная сфера бизнеса. Распознавание видеоряда, сбор данных с устройств, анализирующих просмотр, измерение активности на веб-ресурсах – всё это подразумевает наличие у компании большого IT-штата и колоссального опыта в построении аналитических решений. Но экспоненциальный рост количества информации, числа и разнообразия ее источников заставляет постоянно прогрессировать IT-индустрию данных. Самым простым решением масштабирования уже функционирующей аналитической платформы Mediascope могло стать увеличение штата IT. Но гораздо более эффективное решение — это ускорение процесса разработки. Одним из шагов, ведущих в эту сторону, может являться применение low-code-платформ.
На момент старта проекта у компании уже имелось функционирующее продуктовое решение. Однако реализация решения на MSSQL не могла в полной мере соответствовать ожиданиям по масштабированию функционала с сохранением приемлемой стоимости доработки.
Стоявшая перед нами задача была поистине амбициозной – «Неофлекс» и Mediascope предстояло создать промышленное решение менее чем за год, при условии выхода MVP уже в течение первого квартала от даты начала работ.
В качестве фундамента для построения новой платформы данных, основанной на low-code-вычислениях, был выбран стек технологий Hadoop. Стандартом хранения данных стал HDFS с использованием файлов формата parquet. Для доступа к данным, находящимся в платформе, использован Hive, в котором все доступные витрины представлены в виде внешних таблиц. Загрузка данных в хранилище реализовывалась с помощь Kafka и Apache NiFi.
Lowe-code-инструмент в данной концепции был применён для оптимизации самой трудозатратной задачи в построении аналитической платформы – задачи расчёта данных.
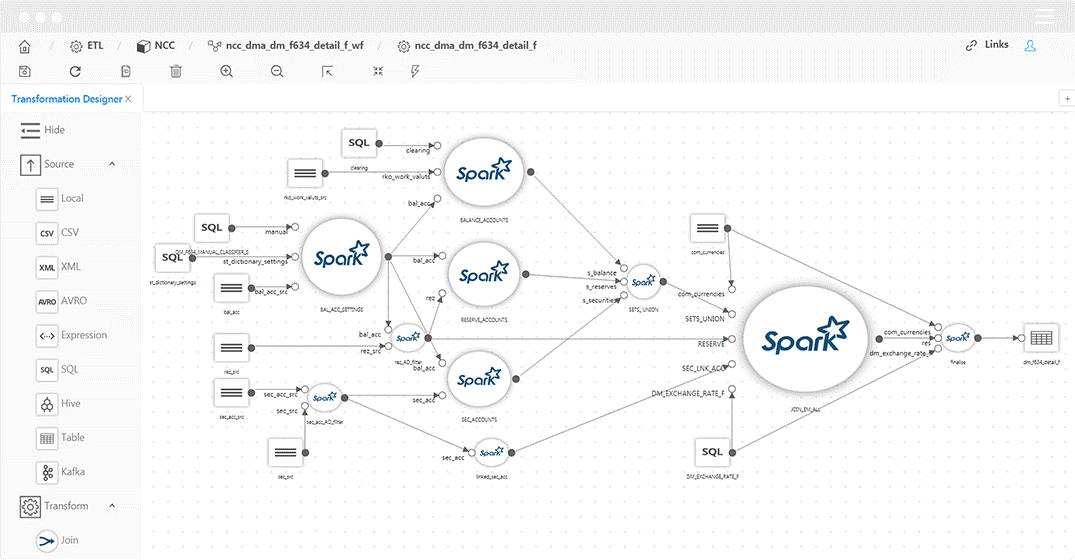
Основным механизмом для маппирования данных был выбран low-code-инструмент Datagram. Neoflex Datagram — это средство для разработки трансформаций и потоков данных.
Применяя данный инструмент, можно обойтись без написания кода на Scala «вручную». Scala-код генерируется автоматически с использованием подхода Model Driven Architecture.
Очевидный плюс такого подхода – ускорение процесса разработки. Однако помимо скорости есть ещё и следующие достоинства:
Порог вхождения в low-code-решения для генерации трансформаций достаточно невысок: разработчику необходимо знать SQL и иметь опыт работы с ETL-инструментами. При этом стоит оговориться, что code-driven-генераторы трансформаций – это не ETL-инструменты в широком понимании этого слова. Low-code-инструменты могут не иметь собственного окружения для выполнения кода. То есть сгенерированный код будет выполняться на том окружении, которое имелось на кластере ещё до инсталляции low-code-решения. И это, пожалуй, ещё один плюс в карму low-code. Так как в параллель с low-code-командой может работать «классическая» команда, реализующая функционал, например, на чистом Scala-коде. Втягивание доработок обеих команд в продуктив будет простым и «бесшовным».
Пожалуй, стоит ещё отметить, что помимо low-code есть ещё и no-code решения. И по своей сути это разные вещи. Low-code в большей степени позволяет разработчику вмешиваться в генерируемый код. В случае с Datagram возможен просмотр и редактирование генерируемого кода Scala, no-code такой возможности может не предоставлять. Эта разница весьма существенна не только в плане гибкости решения, но и в плане комфорта и мотивации в работе дата-инженеров.
Давайте попробуем разобраться, как именно low-code-инструмент помогает решить задачу оптимизации скорости разработки функционала расчёта данных. Для начала разберём функциональную архитектуру системы. В данном случае примером выступает модель производства данных для медиаисследований.
Источники данных в нашем случае весьма разнородны и многообразны:
Имплементация as is загрузки из систем-источников в первичный staging сырых данных может быть организована различными способами. В случае использования для этих целей low-code возможна автоматическая генерация сценариев загрузки на основе метаданных. При этом нет необходимости спускаться на уровень разработки source to target мэппингов. Для реализации автоматической загрузки нам необходимо установить соединение с источником, после чего определить в интерфейсе загрузки перечень сущностей, подлежащих загрузке. Создание структуры каталогов в HDFS произойдёт автоматически и будет соответствовать структуре хранения данных в системе-источнике.
Однако в контексте данного проекта эту возможность low-code-платформы мы решили не использовать в силу того, что компания Mediascope уже самостоятельно начала работу по изготовлению аналогичного сервиса на связке Nifi + Kafka.
Стоит сразу обозначить, что данные инструменты являются не взаимозаменяющими, а скорее дополняющими друг друга. Nifi и Kafka способны работать как в прямой (Nifi -> Kafka), так и в обратной (Kafka -> Nifi) связке. Для платформы медиаисследований использовался первый вариант связки.
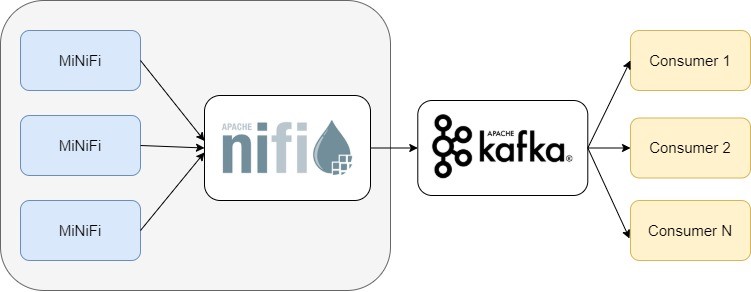
В нашем случае найфаю требовалось обрабатывать различные типы данных из систем-источников и пересылать их брокеру Kafka. При этом направление сообщений в определённый топик Kafka производилось посредством применения Nifi-процессоров PublishKafka. Оркестрация и обслуживание этих pipeline`ов производится в визуальном интерфейсе. Инструмент Nifi и использование связки Nifi + Kafka также можно назвать low-code-подходом к разработке, обладающим низким порогом вхождения в технологии Big Data и ускоряющим процесс разработки приложений.
Следующим этапом в реализации проекта являлось приведение к формату единого семантического слоя детальных данных. В случае наличия у сущности исторических атрибутов расчёт производится в контексте рассматриваемой партиции. Если же сущность не является исторической, то опционально возможен либо пересчёт всего содержимого объекта, либо вовсе отказ от пересчёта этого объекта (вследствие отсутствия изменений). На данном этапе происходит генерация ключей для всех сущностей. Ключи сохраняются в соответствующие мастер-объектам справочники Hbase, содержащие соответствие между ключами в аналитической платформе и ключами из систем-источников. Консолидация атомарных сущностей сопровождается обогащением результатами предварительного расчёта аналитических данных. Framework`ом для расчёта данных являлся Spark. Описанный функционал приведения данных к единой семантике был реализован также на основе маппингов low-code-инструмента Datagram.
В целевой архитектуре требовалось обеспечить наличие SQL-доступа к данным для бизнес-пользователей. Для данной опции был использован Hive. Регистрация объектов в Hive производится автоматически при включении опции «Registr Hive Table» в low-code-инструменте.
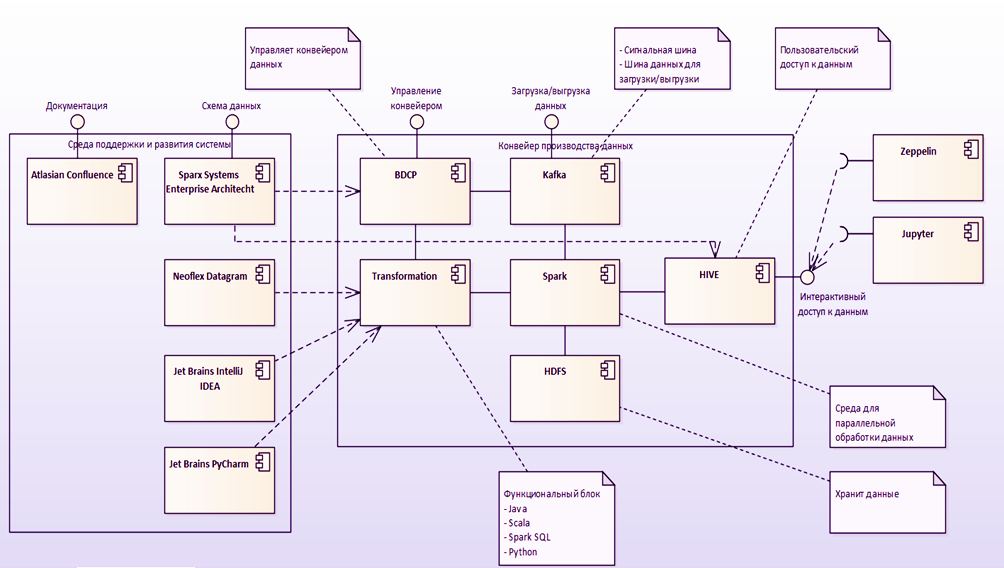
Datagram имеет интерфейс для построения дизайна потоков workflow. Запуск маппингов может осуществляться с использованием планировщика Oozie. В интерфейсе разработчика потоков возможно создание схем параллельного, последовательного или зависящего от заданных условий исполнения преобразований данных. Имеется поддержка shell scripts и java-программ. Также возможно использование сервера Apache Livy. Apache Livy используется для запуска приложений непосредственно из среды разработки.
В случае, если у компании уже есть собственный оркестратор процессов, возможно использование REST API для встраивания маппингов в уже имеющийся поток. Например, у нас имелся достаточно успешный опыт встраивания маппингов на Scala в оркестраторы, написанные на PLSQL и Kotlin. REST API малокодового инструмента подразумевает наличие таких операций, как генерация исполняемого года на основе дизайна маппинга, вызов маппинга, вызов последовательности маппингов и, разумеется, передача в URL параметров для запуска маппингов.
Наравне с Oozie возможно организовать поток расчёта средствами Airflow. Пожалуй, не буду долго останавливаться на сравнении Oozie и Airflow, а просто скажу, что в контексте работ по проекту медиаисследований выбор пал в сторону Airflow. Главными аргументами на этот раз оказались более активное сообщество, развивающее продукт, и более развитый интерфейс + API.
Airflow также хорош потому, что для описания процессов расчёта в нём используется многими любимый Python. Да и вообще, платформ управления рабочими процессами с открытым исходным кодом не так уж и много. Запуск и мониторинг выполнения процессов (в том числе с диаграммой Ганта) лишь добавляют очков в карму Airflow.
Форматом конфигурационного файла для запуска маппингов low-code-решения стал spark-submit. Произошло это по двум причинам. Во-первых, spark-submit позволяет напрямую запустить jar-файл из консоли. Во-вторых, он может содержать всю необходимую информацию для конфигурирования рабочего потока (что облегчает написание скриптов, формирующих Dag).
Наиболее часто встречающимся элементом рабочего потока Airflow в нашем случае стал SparkSubmitOperator.
SparkSubmitOperator позволяет запускать jar`ники — упакованные маппинги Datagram с предварительно сформированными для них входными параметрами.
Следует упомянуть, что каждая задача Airflow выполняется в отдельном потоке и ничего не знает о других задачах. В связи с чем взаимодействие между задачами осуществляется с помощью управляющих операторов, таких как DummyOperator или BranchPythonOperator.
В совокупности использования low-code-решения Datagram в связке с универсализацией конфигурационных файлов (формирующих Dag) привело к существенному ускорению и упрощению процесса разработки потоков загрузки данных.
Пожалуй, самый интеллектуально нагруженный этап в производстве аналитических данных – это шаг построения витрин. В контексте одного из потоков расчёта данных исследовательской компании на данном этапе происходит приведение к эталонной трансляции с учётом поправки на часовые пояса с привязкой к сетке вещания. Также возможна поправка на локальную эфирную сетку (местные новости и реклама). Среди прочего на данном шаге выполняется разбивка интервалов непрерывного смотрения медиапродуктов на основе анализа интервалов смотрения. Тут же происходит «взвешивание» значений просмотра на основе сведений об их значимости (вычисление поправочного коэффициента).

Отдельным шагом подготовки витрин является валидация данных. Алгоритм валидации сопряжён с применением ряда математических science-моделей. Однако использование low-code-платформы позволяет разбить сложный алгоритм на ряд отдельных визуально считываемых маппингов. Каждый из маппингов выполняет узкую задачу. Вследствие чего возможен промежуточный дебаг, логирование и визуализация этапов подготовки данных.
Алгоритм валидации было решено дискретизировать на следующие подэтапы:
Приведённый выше пример является подтверждением гипотезы о том, что у дата-инженера и так слишком много чего должно быть в голове… И, если это действительно «инженер», а не «кодер», то страх профессиональной деградации при использовании low-code-инструментов у него должен окончательно отступить.
Область применения low-code инструмента для пакетной и потоковой обработки данных без необходимости написания кода на Scala вручную не заканчивается.
Применение low-code в разработке datalake`ов для нас стало уже некоторым стандартом. Наверное, можно сказать, что решения на стеке Hadoop повторяют путь развития классических DWH, основанных на РСУБД. Малокодовые инструменты на стеке Hadoop могут решать, как задачи обработки данных, так и задачи построения конечных BI-интерфейсов. Причём нужно заметить, что под BI может пониматься не только репрезентация данных, но и их редактирование силами бизнес-пользователей. Данный функционал нами часто применяется при построении аналитических платформ для финансового сектора.

Среди прочего, с помощью low-code и, в частности, Datagram возможно решить задачу отслеживания происхождения объектов потока данных с атомарностью до отдельных полей (lineage). Для этого в low-code-инструменте имплементировано сопряжение с Apache Atlas и Cloudera Navigator. По сути, разработчику необходимо зарегистрировать набор объектов в словарях Atlas и ссылаться на зарегистрированные объекты при построении маппингов. Механизм отслеживания происхождения данных или анализ зависимостей объектов экономит большое количество времени при необходимости внесения доработок в алгоритмы расчёта. Например, при построении финансовой отчётности эта фишка позволяет комфортнее пережить период изменений законодательства. Ведь, чем качественнее мы осознаём межформенную зависимость в разрезе объектов детального слоя, тем меньше мы столкнёмся с «внезапными» дефектами и сократим количество реворков.

Ещё одной задачей, реализованной low-code-инструментом на проекте компании Mediascope, стала задача класса Data Quality. Особенностью реализации конвейера проверки данных для проекта исследовательской компании было отсутствие влияния на работоспособность и скорость работы основного потока расчёта данных. Для возможности оркестрирования независимыми потоками проверки данных применялся уже знакомый Apache Airflow. По мере готовности каждого шага производства данных параллельно происходил запуск обособленной части DQ-конвейера.
Хорошей практикой считается наблюдение за качеством данных с момента их зарождения в аналитической платформе. Имея информацию о метаданных, мы можем уже с момента попадания информации в первичный слой проверять соблюдение базовых условий — not null, constraints, foreign keys. Этот функционал реализован на основе автоматически генерируемых мэппингов семейства data quality в Datagram. Кодогенерация в данном случае также основывается на метаданных модели. На проекте компании Mediascope сопряжение происходило с метаданными продукта Enterprise Architect.
Благодаря сопряжению low-code-инструмента и Enterprise Architect автоматически были сгенерированы следующие проверки:
Для более сложных проверок доступности и достоверности данных был создан мэппинг с Scala Expression, принимающий на вход внешний Spark SQL-код проверки, подготовленной силами аналитиков в Zeppelin.

Разумеется, к автогенерации проверок необходимо приходить постепенно. В рамках описываемого проекта этому предшествовали следующие шаги:
Пожалуй, основным преимуществом создания сервиса параметризированных проверок является сокращение времени доставки функционала на продукционное окружение. Новые проверки качества могут миновать классический паттерн доставки кода опосредованно через среды разработки и тестирования:
Риски прямой отгрузки скриптов на прод отсутствуют как таковые. Даже при синтаксической ошибке максимум, что нам грозит, – невыполнение одной проверки, ведь поток расчёта данных и поток запуска проверок качества разведены между собой.
По сути, сервис DQ перманентно запущен на продукционном окружении и готов начать свою работу в момент появления очередной порции данных.
Преимущество применения low-code очевидно. Разработчикам не нужно разрабатывать приложение «с нуля». А освобождённый от дополнительных задач программист даёт результат быстрее. Скорость, в свою очередь, высвобождает дополнительный ресурс времени на разрешение вопросов оптимизации. Следовательно, в данном случае можно рассчитывать на наличие более качественного и быстрого решения.
Разумеется, low-code – не панацея, и волшебство само по себе не случится:

Однако если все недостатки выбранной системы вам известны, и бенефиты от её использования, тем не менее, находятся в доминирующем большинстве, то переходите к малому коду без боязни. Тем более, что переход на него неизбежен – как неизбежна любая эволюция.
Если один разработчик на low-code-платформе будет выполнять свою работу быстрее, чем два разработчика без low-code, то это даёт компании фору во всех отношениях. Порог вхождения в low-code-решения более низкий, чем в «традиционные» технологии, и это положительным образом сказывается на вопросе кадрового дефицита. При использовании малокодовых инструментов возможно ускорение взаимодействия между функциональными командами и более быстрое принятие решений о корректности выбранного пути data-science-исследований. Низкоуровневые платформы могут выступить причиной цифровой трансформации организации, поскольку производимые решения могут быть доступны к пониманию нетехническим специалистам (в частности, бизнес-пользователям).
Если у вас сжатые сроки, нагруженная бизнес-логика, дефицит технологической экспертизы, и вам требуется ускорить time to market, то low-code — это один из способов удовлетворения ваших потребностей.
Не стоит отрицать значимость традиционных инструментов разработки, однако во многих случаях применение малокодовых решений — лучший способ повысить эффективность решаемых задач.
Задача построения ИТ-платформ для накопления и анализа данных рано или поздно возникает у любой компании, в основе бизнеса которой лежат интеллектуально нагруженная модель оказания услуг или создание технически сложных продуктов. Построение аналитических платформ — сложная и трудозатратная задача. Однако любую задачу можно упростить. В этой статье я хочу поделиться опытом применения low-code-инструментов, помогающих в создании аналитических решений. Данный опыт был приобретён при реализации ряда проектов направления Big Data Solutions компании «Неофлекс». Направление Big Data Solutions компании «Неофлекс» с 2005 года занимается вопросами построения хранилищ и озёр данных, решает задачи оптимизации скорости обработки информации и работает над методологией управления качеством данных.
Избежать осознанного накопления слабо и/или сильно структурированных данных не удастся никому. Пожалуй, даже если речь будет идти о малом бизнесе. Ведь при масштабировании бизнеса перспективный предприниматель столкнётся с вопросами разработки программы лояльности, захочет провести анализ эффективности точек продаж, подумает о таргетированной рекламе, озадачится спросом на сопроводительную продукцию. В первом приближении задача может быть решена «на коленке». Но при росте бизнеса приход к аналитической платформе все же неизбежен.
Однако в каком случае задачи аналитики данных могут перерасти в задачи класса «Rocket Science»? Пожалуй, в тот момент, когда речь идёт о действительно больших данных.
Чтобы упростить задачу «Rocket Science», можно есть слона по частям.
Чем большая дискретность и автономность будет у ваших приложений/сервисов/микросервисов, тем проще вам, вашим коллегам и всему бизнесу будет переваривать слона.
К этому постулату пришли практически все наши клиенты, перестроив ландшафт, основываясь на инженерных практиках DevOps-команд.
Но даже при «раздельной, слоновьей» диете мы имеем неплохие шансы на «перенасыщение» IT-ландшафта. В этот момент стоит остановиться, выдохнуть и посмотреть в сторону low-code engineering platform.
Многих разработчиков пугает перспектива появления тупика в карьере при уходе от непосредственного написания кода в сторону «перетаскивания» стрелочек в UI-интерфейсах low-code систем. Но появление станков не привело к исчезновению инженеров, а вывело их работу на новый уровень!
Давайте разбираться почему.
Анализ данных в сфере логистики, телеком-индустрии, в области медиаисследований, финансовом секторе, всегда сопряжён со следующими вопросами:
- Скорость проведения автоматизированного анализа;
- Возможность проведения экспериментов без воздействия на основной поток производства данных;
- Достоверность подготовленных данных;
- Отслеживание изменений и версионирование;
- Data proveance, Data lineage, CDC;
- Быстрота доставки новых фич на продукционное окружение;
- И пресловутое: стоимость разработки и поддержки.
То есть у инженеров имеется огромное количество высокоуровневых задач, выполнить которые с достаточной эффективностью можно, лишь очистив сознание от задач низкоуровневой разработки.
Предпосылками перехода разработчиков на новый уровень стали эволюция и цифровизация бизнеса. Ценность разработчика также изменяется: в значительном дефиците находятся разработчики, способные погрузиться в суть концепций автоматизируемого бизнеса.
Давайте проведём аналогию с низкоуровневыми и высокоуровневыми языками программирования. Переход от низкоуровневых языков в сторону высокоуровневых – это переход от написания «прямых директив на языке железа» в сторону «директив на языке людей». То есть добавление некоторого слоя абстракции. В таком случае переход на low-code-платформы с высокоуровневых языков программирования — это переход от «директив на языке людей» в сторону «директив на языке бизнеса». Если найдутся разработчики, которых этот факт опечалит, тогда опечалены они, возможно, ещё с того момента, как на свет появился Java Script, в котором используются функции сортировки массива. И эти функции, разумеется, имеют под капотом программную имплементацию другими средствами того же самого высокоуровнего программирования.
Следовательно, low-code – это всего лишь появление ещё одного уровня абстракции.
Прикладной опыт использования low-code
Тема low-code достаточно широка, но сейчас я хотел бы рассказать о прикладном применении «малокодовых концепций» на примере одного из наших проектов.
Подразделение Big Data Solutions компании «Неофлекс» в большей степени специализируется на финансовом секторе бизнеса, cтроя хранилища и озёра данных и автоматизируя различную отчётность. В данной нише применение low-code давно стало стандартом. Среди прочих low-code-инструментов можно упомянуть средства для организации ETL-процессов: Informatica Power Center, IBM Datastage, Pentaho Data Integration. Или же Oracle Apex, выступающий средой быстрой разработки интерфейсов доступа и редактирования данных. Однако применение малокодовых средств разработки не всегда сопряжено с построением узконаправленных приложений на коммерческом стеке технологий с явно выраженной зависимостью от вендора.
С помощью low-code-платформ можно также организовывать оркестрацию потоков данных, создать data-science-площадки или, например, модули проверки качества данных.
Одним из прикладных примеров опыта использования малокодовых средств разработки — является коллаборация «Неофлекс» c компанией Mediascope, одним из лидеров российского рынка исследований медиа. Одна из задач бизнеса данной компании – производство данных, на основе которых рекламодатели, интернет-площадки, телеканалы, радиостанции, рекламные агентства и бренды принимают решение о покупке рекламы и планируют свои маркетинговые коммуникации.

Медиаисследования – технологически нагруженная сфера бизнеса. Распознавание видеоряда, сбор данных с устройств, анализирующих просмотр, измерение активности на веб-ресурсах – всё это подразумевает наличие у компании большого IT-штата и колоссального опыта в построении аналитических решений. Но экспоненциальный рост количества информации, числа и разнообразия ее источников заставляет постоянно прогрессировать IT-индустрию данных. Самым простым решением масштабирования уже функционирующей аналитической платформы Mediascope могло стать увеличение штата IT. Но гораздо более эффективное решение — это ускорение процесса разработки. Одним из шагов, ведущих в эту сторону, может являться применение low-code-платформ.
На момент старта проекта у компании уже имелось функционирующее продуктовое решение. Однако реализация решения на MSSQL не могла в полной мере соответствовать ожиданиям по масштабированию функционала с сохранением приемлемой стоимости доработки.
Стоявшая перед нами задача была поистине амбициозной – «Неофлекс» и Mediascope предстояло создать промышленное решение менее чем за год, при условии выхода MVP уже в течение первого квартала от даты начала работ.
В качестве фундамента для построения новой платформы данных, основанной на low-code-вычислениях, был выбран стек технологий Hadoop. Стандартом хранения данных стал HDFS с использованием файлов формата parquet. Для доступа к данным, находящимся в платформе, использован Hive, в котором все доступные витрины представлены в виде внешних таблиц. Загрузка данных в хранилище реализовывалась с помощь Kafka и Apache NiFi.
Lowe-code-инструмент в данной концепции был применён для оптимизации самой трудозатратной задачи в построении аналитической платформы – задачи расчёта данных.

Основным механизмом для маппирования данных был выбран low-code-инструмент Datagram. Neoflex Datagram — это средство для разработки трансформаций и потоков данных.
Применяя данный инструмент, можно обойтись без написания кода на Scala «вручную». Scala-код генерируется автоматически с использованием подхода Model Driven Architecture.
Очевидный плюс такого подхода – ускорение процесса разработки. Однако помимо скорости есть ещё и следующие достоинства:
- Просмотр содержимого и структуры источников/приемников;
- Отслеживание происхождения объектов потока данных до отдельных полей (lineage);
- Частичное выполнение преобразований с просмотром промежуточных результатов;
- Просмотр исходного кода и его корректировка перед выполнением;
- Автоматическая валидация трансформаций;
- Автоматическая загрузка данных 1 в 1.
Порог вхождения в low-code-решения для генерации трансформаций достаточно невысок: разработчику необходимо знать SQL и иметь опыт работы с ETL-инструментами. При этом стоит оговориться, что code-driven-генераторы трансформаций – это не ETL-инструменты в широком понимании этого слова. Low-code-инструменты могут не иметь собственного окружения для выполнения кода. То есть сгенерированный код будет выполняться на том окружении, которое имелось на кластере ещё до инсталляции low-code-решения. И это, пожалуй, ещё один плюс в карму low-code. Так как в параллель с low-code-командой может работать «классическая» команда, реализующая функционал, например, на чистом Scala-коде. Втягивание доработок обеих команд в продуктив будет простым и «бесшовным».
Пожалуй, стоит ещё отметить, что помимо low-code есть ещё и no-code решения. И по своей сути это разные вещи. Low-code в большей степени позволяет разработчику вмешиваться в генерируемый код. В случае с Datagram возможен просмотр и редактирование генерируемого кода Scala, no-code такой возможности может не предоставлять. Эта разница весьма существенна не только в плане гибкости решения, но и в плане комфорта и мотивации в работе дата-инженеров.
Архитектура решения
Давайте попробуем разобраться, как именно low-code-инструмент помогает решить задачу оптимизации скорости разработки функционала расчёта данных. Для начала разберём функциональную архитектуру системы. В данном случае примером выступает модель производства данных для медиаисследований.

Источники данных в нашем случае весьма разнородны и многообразны:
- Пиплметры (ТВ-метры) — программно-аппаратные устройства, считывающие пользовательское поведение у респондентов телевизионной панели – кто, когда и какой телеканал смотрел в домохозяйстве, которое участвует в исследовании. Поставляемая информация – это поток интервалов смотрения эфира с привязкой к медиапакету и медиапродукту. Данные на этапе загрузки в Data Lake могут быть обогащены демографическими атрибутами, привязкой к геострате, таймзоне и другими сведениями, необходимыми для проведения анализа телепросмотра того или иного медиа продукта. Произведённые измерения могут быть использованы для анализа или планирования рекламных кампаний, оценки активности и предпочтений аудитории, составления эфирной сетки;
- Данные могут поступать из систем мониторинга потокового телевещания и замера просмотра контента видеоресурсов в интернете;
- Измерительные инструменты в web-среде, среди которых как site-centric, так и user-centric счётчики. Поставщиком данных для Data Lake может служить надстройка браузера research bar и мобильное приложение со встроенным VPN.
- Данные также могут поступать с площадок, консолидирующих результаты заполнения онлайн-анкет и итоги проведения телефонных интервью в опросных исследованиях компании;
- Дополнительное обогащение озера данных может происходить за счёт загрузки сведений из логов компаний-партнёров.
Имплементация as is загрузки из систем-источников в первичный staging сырых данных может быть организована различными способами. В случае использования для этих целей low-code возможна автоматическая генерация сценариев загрузки на основе метаданных. При этом нет необходимости спускаться на уровень разработки source to target мэппингов. Для реализации автоматической загрузки нам необходимо установить соединение с источником, после чего определить в интерфейсе загрузки перечень сущностей, подлежащих загрузке. Создание структуры каталогов в HDFS произойдёт автоматически и будет соответствовать структуре хранения данных в системе-источнике.
Однако в контексте данного проекта эту возможность low-code-платформы мы решили не использовать в силу того, что компания Mediascope уже самостоятельно начала работу по изготовлению аналогичного сервиса на связке Nifi + Kafka.
Стоит сразу обозначить, что данные инструменты являются не взаимозаменяющими, а скорее дополняющими друг друга. Nifi и Kafka способны работать как в прямой (Nifi -> Kafka), так и в обратной (Kafka -> Nifi) связке. Для платформы медиаисследований использовался первый вариант связки.

В нашем случае найфаю требовалось обрабатывать различные типы данных из систем-источников и пересылать их брокеру Kafka. При этом направление сообщений в определённый топик Kafka производилось посредством применения Nifi-процессоров PublishKafka. Оркестрация и обслуживание этих pipeline`ов производится в визуальном интерфейсе. Инструмент Nifi и использование связки Nifi + Kafka также можно назвать low-code-подходом к разработке, обладающим низким порогом вхождения в технологии Big Data и ускоряющим процесс разработки приложений.
Следующим этапом в реализации проекта являлось приведение к формату единого семантического слоя детальных данных. В случае наличия у сущности исторических атрибутов расчёт производится в контексте рассматриваемой партиции. Если же сущность не является исторической, то опционально возможен либо пересчёт всего содержимого объекта, либо вовсе отказ от пересчёта этого объекта (вследствие отсутствия изменений). На данном этапе происходит генерация ключей для всех сущностей. Ключи сохраняются в соответствующие мастер-объектам справочники Hbase, содержащие соответствие между ключами в аналитической платформе и ключами из систем-источников. Консолидация атомарных сущностей сопровождается обогащением результатами предварительного расчёта аналитических данных. Framework`ом для расчёта данных являлся Spark. Описанный функционал приведения данных к единой семантике был реализован также на основе маппингов low-code-инструмента Datagram.
В целевой архитектуре требовалось обеспечить наличие SQL-доступа к данным для бизнес-пользователей. Для данной опции был использован Hive. Регистрация объектов в Hive производится автоматически при включении опции «Registr Hive Table» в low-code-инструменте.

Управление потоком расчёта
Datagram имеет интерфейс для построения дизайна потоков workflow. Запуск маппингов может осуществляться с использованием планировщика Oozie. В интерфейсе разработчика потоков возможно создание схем параллельного, последовательного или зависящего от заданных условий исполнения преобразований данных. Имеется поддержка shell scripts и java-программ. Также возможно использование сервера Apache Livy. Apache Livy используется для запуска приложений непосредственно из среды разработки.
В случае, если у компании уже есть собственный оркестратор процессов, возможно использование REST API для встраивания маппингов в уже имеющийся поток. Например, у нас имелся достаточно успешный опыт встраивания маппингов на Scala в оркестраторы, написанные на PLSQL и Kotlin. REST API малокодового инструмента подразумевает наличие таких операций, как генерация исполняемого года на основе дизайна маппинга, вызов маппинга, вызов последовательности маппингов и, разумеется, передача в URL параметров для запуска маппингов.
Наравне с Oozie возможно организовать поток расчёта средствами Airflow. Пожалуй, не буду долго останавливаться на сравнении Oozie и Airflow, а просто скажу, что в контексте работ по проекту медиаисследований выбор пал в сторону Airflow. Главными аргументами на этот раз оказались более активное сообщество, развивающее продукт, и более развитый интерфейс + API.
Airflow также хорош потому, что для описания процессов расчёта в нём используется многими любимый Python. Да и вообще, платформ управления рабочими процессами с открытым исходным кодом не так уж и много. Запуск и мониторинг выполнения процессов (в том числе с диаграммой Ганта) лишь добавляют очков в карму Airflow.
Форматом конфигурационного файла для запуска маппингов low-code-решения стал spark-submit. Произошло это по двум причинам. Во-первых, spark-submit позволяет напрямую запустить jar-файл из консоли. Во-вторых, он может содержать всю необходимую информацию для конфигурирования рабочего потока (что облегчает написание скриптов, формирующих Dag).
Наиболее часто встречающимся элементом рабочего потока Airflow в нашем случае стал SparkSubmitOperator.
SparkSubmitOperator позволяет запускать jar`ники — упакованные маппинги Datagram с предварительно сформированными для них входными параметрами.
Следует упомянуть, что каждая задача Airflow выполняется в отдельном потоке и ничего не знает о других задачах. В связи с чем взаимодействие между задачами осуществляется с помощью управляющих операторов, таких как DummyOperator или BranchPythonOperator.
В совокупности использования low-code-решения Datagram в связке с универсализацией конфигурационных файлов (формирующих Dag) привело к существенному ускорению и упрощению процесса разработки потоков загрузки данных.
Расчёт витрин
Пожалуй, самый интеллектуально нагруженный этап в производстве аналитических данных – это шаг построения витрин. В контексте одного из потоков расчёта данных исследовательской компании на данном этапе происходит приведение к эталонной трансляции с учётом поправки на часовые пояса с привязкой к сетке вещания. Также возможна поправка на локальную эфирную сетку (местные новости и реклама). Среди прочего на данном шаге выполняется разбивка интервалов непрерывного смотрения медиапродуктов на основе анализа интервалов смотрения. Тут же происходит «взвешивание» значений просмотра на основе сведений об их значимости (вычисление поправочного коэффициента).

Отдельным шагом подготовки витрин является валидация данных. Алгоритм валидации сопряжён с применением ряда математических science-моделей. Однако использование low-code-платформы позволяет разбить сложный алгоритм на ряд отдельных визуально считываемых маппингов. Каждый из маппингов выполняет узкую задачу. Вследствие чего возможен промежуточный дебаг, логирование и визуализация этапов подготовки данных.
Алгоритм валидации было решено дискретизировать на следующие подэтапы:
- Построение регрессий зависимостей смотрения телесети в регионе со смотрением всех сетей в регионе за 60 дней.
- Расчёт стьюдентизированных остатков (отклонения фактических значений от предсказанных регрессионной моделью) для всех точек регрессии и для расчетного дня.
- Выборка аномальных пар регион-телесеть, где стьюдентизированный остаток расчетного дня превышает норму (заданную настройкой операции).
- Пересчёт поправленного стьюдентизированного остатка по аномальным парам регион-телесеть для каждого респондента, смотревшего сеть в регионе с определением вклада данного респондента (величина изменения стьюдентизированного остатка) при исключении смотрения данного респондента из выборки.
- Поиск кандидатов, исключение которых приводит стьюдентизированный остаток расчетного дня в норму.
Приведённый выше пример является подтверждением гипотезы о том, что у дата-инженера и так слишком много чего должно быть в голове… И, если это действительно «инженер», а не «кодер», то страх профессиональной деградации при использовании low-code-инструментов у него должен окончательно отступить.
Что ещё может low-code?
Область применения low-code инструмента для пакетной и потоковой обработки данных без необходимости написания кода на Scala вручную не заканчивается.
Применение low-code в разработке datalake`ов для нас стало уже некоторым стандартом. Наверное, можно сказать, что решения на стеке Hadoop повторяют путь развития классических DWH, основанных на РСУБД. Малокодовые инструменты на стеке Hadoop могут решать, как задачи обработки данных, так и задачи построения конечных BI-интерфейсов. Причём нужно заметить, что под BI может пониматься не только репрезентация данных, но и их редактирование силами бизнес-пользователей. Данный функционал нами часто применяется при построении аналитических платформ для финансового сектора.

Среди прочего, с помощью low-code и, в частности, Datagram возможно решить задачу отслеживания происхождения объектов потока данных с атомарностью до отдельных полей (lineage). Для этого в low-code-инструменте имплементировано сопряжение с Apache Atlas и Cloudera Navigator. По сути, разработчику необходимо зарегистрировать набор объектов в словарях Atlas и ссылаться на зарегистрированные объекты при построении маппингов. Механизм отслеживания происхождения данных или анализ зависимостей объектов экономит большое количество времени при необходимости внесения доработок в алгоритмы расчёта. Например, при построении финансовой отчётности эта фишка позволяет комфортнее пережить период изменений законодательства. Ведь, чем качественнее мы осознаём межформенную зависимость в разрезе объектов детального слоя, тем меньше мы столкнёмся с «внезапными» дефектами и сократим количество реворков.

Data Quality & Low-code
Ещё одной задачей, реализованной low-code-инструментом на проекте компании Mediascope, стала задача класса Data Quality. Особенностью реализации конвейера проверки данных для проекта исследовательской компании было отсутствие влияния на работоспособность и скорость работы основного потока расчёта данных. Для возможности оркестрирования независимыми потоками проверки данных применялся уже знакомый Apache Airflow. По мере готовности каждого шага производства данных параллельно происходил запуск обособленной части DQ-конвейера.
Хорошей практикой считается наблюдение за качеством данных с момента их зарождения в аналитической платформе. Имея информацию о метаданных, мы можем уже с момента попадания информации в первичный слой проверять соблюдение базовых условий — not null, constraints, foreign keys. Этот функционал реализован на основе автоматически генерируемых мэппингов семейства data quality в Datagram. Кодогенерация в данном случае также основывается на метаданных модели. На проекте компании Mediascope сопряжение происходило с метаданными продукта Enterprise Architect.
Благодаря сопряжению low-code-инструмента и Enterprise Architect автоматически были сгенерированы следующие проверки:
- Проверка присутствия значений «null» в полях с модификатором «not null»;
- Проверка присутствия дублей первичного ключа;
- Проверка внешнего ключа сущности;
- Проверка уникальности строки по набору полей.
Для более сложных проверок доступности и достоверности данных был создан мэппинг с Scala Expression, принимающий на вход внешний Spark SQL-код проверки, подготовленной силами аналитиков в Zeppelin.

Разумеется, к автогенерации проверок необходимо приходить постепенно. В рамках описываемого проекта этому предшествовали следующие шаги:
- DQ, реализованные в блокнотах Zeppelin;
- DQ, встроенные в мэппинг;
- DQ в виде отдельных массивных мэппингов, содержащих целый набор проверок под отдельную сущность;
- Универсальные параметризованные DQ-мэппинги, принимающие на вход информацию о метаданных и бизнес-проверках.
Пожалуй, основным преимуществом создания сервиса параметризированных проверок является сокращение времени доставки функционала на продукционное окружение. Новые проверки качества могут миновать классический паттерн доставки кода опосредованно через среды разработки и тестирования:
- Все проверки метаданных генерируются автоматически при изменении модели в EA;
- Проверки доступности данных (определение наличия каких-либо данных на момент времени) могут быть сгенерированы на основе справочника, хранящего ожидаемый тайминг появления очередной порции данных в разрезе объектов;
- Бизнес-проверки достоверности данных создаются силами аналитиков в notebook`ах Zeppelin. Откуда направляются прямиком в настроечные таблицы модуля DQ на продукционном окружении.
Риски прямой отгрузки скриптов на прод отсутствуют как таковые. Даже при синтаксической ошибке максимум, что нам грозит, – невыполнение одной проверки, ведь поток расчёта данных и поток запуска проверок качества разведены между собой.
По сути, сервис DQ перманентно запущен на продукционном окружении и готов начать свою работу в момент появления очередной порции данных.
Вместо заключения
Преимущество применения low-code очевидно. Разработчикам не нужно разрабатывать приложение «с нуля». А освобождённый от дополнительных задач программист даёт результат быстрее. Скорость, в свою очередь, высвобождает дополнительный ресурс времени на разрешение вопросов оптимизации. Следовательно, в данном случае можно рассчитывать на наличие более качественного и быстрого решения.
Разумеется, low-code – не панацея, и волшебство само по себе не случится:
- Малокодовая индустрия проходит стадию «крепчания», и пока в ней нет однородных индустриальных стандартов;
- Многие low-code-решения не бесплатны, и их приобретение должно быть осознанным шагом, сделать который следует при полной уверенности финансовой выгоды от их использования;
- Многие малокодовые решения не всегда хорошо дружат с GIT / SVN. Либо неудобны в использовании в случае сокрытия генерируемого кода;
- При расширении архитектуры может потребоваться доработка малокодового решения – что, в свою очередь, провоцирует эффект «привязанности и зависимости» от поставщика low-code-решения.
- Должный уровень обеспечения безопасности возможен, но весьма трудозатратен и сложен в реализации движков low-code-систем. Малокодовые платформы должны выбираться не только по принципу поиска выгоды от их использования. При выборе стоит задаться вопросами наличия функционала управлением доступа и делегированием/эскалацией идентификационных данных на уровень всего IT-ландшафта организации.

Однако если все недостатки выбранной системы вам известны, и бенефиты от её использования, тем не менее, находятся в доминирующем большинстве, то переходите к малому коду без боязни. Тем более, что переход на него неизбежен – как неизбежна любая эволюция.
Если один разработчик на low-code-платформе будет выполнять свою работу быстрее, чем два разработчика без low-code, то это даёт компании фору во всех отношениях. Порог вхождения в low-code-решения более низкий, чем в «традиционные» технологии, и это положительным образом сказывается на вопросе кадрового дефицита. При использовании малокодовых инструментов возможно ускорение взаимодействия между функциональными командами и более быстрое принятие решений о корректности выбранного пути data-science-исследований. Низкоуровневые платформы могут выступить причиной цифровой трансформации организации, поскольку производимые решения могут быть доступны к пониманию нетехническим специалистам (в частности, бизнес-пользователям).
Если у вас сжатые сроки, нагруженная бизнес-логика, дефицит технологической экспертизы, и вам требуется ускорить time to market, то low-code — это один из способов удовлетворения ваших потребностей.
Не стоит отрицать значимость традиционных инструментов разработки, однако во многих случаях применение малокодовых решений — лучший способ повысить эффективность решаемых задач.
