Автор: Андрей Лазарев
Одним из главных узких мест в вычислениях, требующих обработки больших объемов данных, является сетевой трафик, проходящий через коммутатор. К счастью, выполнение map-кода на том узле, где находятся данные, делает данную проблему намного менее серьезной. Такой метод, именуемый «локальностью данных», – одно из главных преимуществ модели Hadoop Map/Reduce.
В данной статье мы рассмотрим требования к локальности данных, а также то, как виртуализированная среда OpenStack влияет на топологию кластера Hadoop, и как обеспечить локальность данных при использовании Hadoop с Savanna.
Чтобы воспользоваться всеми преимуществами локальности данных, нужно убедиться в том, что архитектура вашей системы удовлетворяет ряду условий.
Во-первых, у кластера должна быть соответствующая топология. Map-код Hadoop должен иметь возможность «локального» чтения данных. Некоторые популярные решения, такие как сетевые хранилища (сетевая система хранения данных [NAS] и сети хранения данных [SANs]), будут всегда порождать сетевой трафик, так что в некотором смысле вы можете не считать их «локальными», но, на самом деле, это зависит от точки зрения. Исходя из вашей ситуации, вы можете определить «локальный» как «находящийся в пределах одного дата-центра» или «все, что находится на одной стойке».
Во-вторых, кластеру Hadoop должна быть известна топология узлов, на которых выполняются задания. Узлы Tasktracker используются для выполнения Map-заданий, поэтому для надлежащего распределения заданий планировщику Hadoop необходима информация о топологии сети.
И последнее, но не менее важное, кластеру Hadoop должно быть известно, где расположены данные. С этим может быть немного сложнее из-за поддержки различных систем хранения данных в Hadoop. Так, HDFS поддерживает локальность данных по умолчанию, тогда как другие драйверы (например, Swift) требуют расширения для возможности предоставления информации о топологии в Hadoop.
Как правило, Hadoop использует 3-уровневую сетевую топологию. Изначально к этим трем уровням относились центр обработки данных, стойка и узел, хотя случай с кросс-центром обработки данных не является распространенным и этот уровень часто используется для определения коммутаторов верхнего уровня.
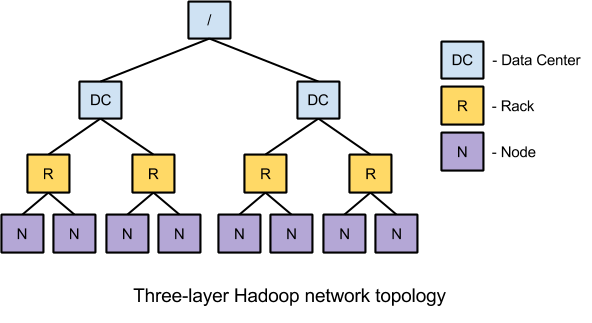
Такая топология хорошо подходит для традиционной реализации кластеров Hadoop, но виртуальную среду трудно отобразить на этих трех уровнях, т.к. в них нет места для гипервизора. При определенных условиях две виртуальные машины, работающие на одной хост-машине, могут взаимодействовать намного быстрее, чем если бы они работали на отдельных хост-машинах, поскольку при этом не задействуется никакая сеть. Поэтому, начиная с версии 1.2.0, Hadoop поддерживает 4-уровневую топологию.

Этот новый уровень, который называется «группа узлов», соответствует гипервизору, на котором размещены виртуальные машины. В отдельных виртуальных машинах может быть несколько узлов на одной хост-машине, которыми управляет один гипервизор, что делает возможным взаимодействие без прохождения данных через сеть.
Итак, зная все вышеперечисленное, как реализовать это на деле? Одним из вариантов является использование Savanna для настройки ваших кластеров Hadoop.
Savanna – это проект OpenStack, позволяющий развернуть кластеры Hadoop поверх платформы OpenStack и выполнять на ней задания. В последнем релизе Savanna 0.3 была добавлена поддержка локальности данных для плагина Vanilla (в плагине Hortonworks поддержка локальности данных планируется в ближайшем релизе Icehouse). С таким усовершенствованием Savanna может продвинуть конфигурацию кластерной топологии в Hadoop и обеспечить локальность данных. Это позволяет Savanna поддерживать как 3-, так и 4-уровневую топологию сети. Для 4-уровневой топологии Savanna использует ID хоста вычислительного узла в качестве идентификатора группы узлов кластера Hadoop. (Примечание: Будьте внимательны и не путайте группы узлов кластера Hadoop и группы узлов Savanna, у которых различные цели).
Savanna также может обеспечить локальность данных для входных потоков Swift в Hadoop, но для этого потребуется добавить в Hadoop определенный драйвер Swift, поскольку плагин Vanilla использует Hadoop 1.2.1 без встроенной поддержки Swift. Драйвер Swift был разработан командой проекта Savanna и уже частично интегрирован в Hadoop 2.4.0. Планируется полностью интегрировать его в 2.x repo, а затем применить на старой версии 1.x.
Использование локальности данных в Swift предполагает включение функции локальности данных в Savanna, а затем указание как топологии Compute, так и топологии Swift. Представленный ниже ролик показывает, как в Savanna запустить кластер Hadoop и осуществить на нем настройку локальности данных:
http://youtu.be/XayHkbmjK9g
Обработка данных в виртуальной среде Hadoop, возможно, является следующим шагом в развитии больших данных. По мере роста кластеров исключительную важность приобретает оптимизация потребляемых ресурсов. Такие технологии, как локальность данных, могут существенно понизить степень использования сети и позволить вам работать с большими распределенными кластерами без потери преимуществ использования более мелких и более локальных кластеров. Это делает возможности масштабирования кластера Hadoop практически безграничными.
Оригинал статьи на английском языке.
Одним из главных узких мест в вычислениях, требующих обработки больших объемов данных, является сетевой трафик, проходящий через коммутатор. К счастью, выполнение map-кода на том узле, где находятся данные, делает данную проблему намного менее серьезной. Такой метод, именуемый «локальностью данных», – одно из главных преимуществ модели Hadoop Map/Reduce.
В данной статье мы рассмотрим требования к локальности данных, а также то, как виртуализированная среда OpenStack влияет на топологию кластера Hadoop, и как обеспечить локальность данных при использовании Hadoop с Savanna.
Требования к локальности данных в Hadoop
Чтобы воспользоваться всеми преимуществами локальности данных, нужно убедиться в том, что архитектура вашей системы удовлетворяет ряду условий.
Во-первых, у кластера должна быть соответствующая топология. Map-код Hadoop должен иметь возможность «локального» чтения данных. Некоторые популярные решения, такие как сетевые хранилища (сетевая система хранения данных [NAS] и сети хранения данных [SANs]), будут всегда порождать сетевой трафик, так что в некотором смысле вы можете не считать их «локальными», но, на самом деле, это зависит от точки зрения. Исходя из вашей ситуации, вы можете определить «локальный» как «находящийся в пределах одного дата-центра» или «все, что находится на одной стойке».
Во-вторых, кластеру Hadoop должна быть известна топология узлов, на которых выполняются задания. Узлы Tasktracker используются для выполнения Map-заданий, поэтому для надлежащего распределения заданий планировщику Hadoop необходима информация о топологии сети.
И последнее, но не менее важное, кластеру Hadoop должно быть известно, где расположены данные. С этим может быть немного сложнее из-за поддержки различных систем хранения данных в Hadoop. Так, HDFS поддерживает локальность данных по умолчанию, тогда как другие драйверы (например, Swift) требуют расширения для возможности предоставления информации о топологии в Hadoop.
Топология кластера Hadoop в виртуализированной инфраструктуре
Как правило, Hadoop использует 3-уровневую сетевую топологию. Изначально к этим трем уровням относились центр обработки данных, стойка и узел, хотя случай с кросс-центром обработки данных не является распространенным и этот уровень часто используется для определения коммутаторов верхнего уровня.

Такая топология хорошо подходит для традиционной реализации кластеров Hadoop, но виртуальную среду трудно отобразить на этих трех уровнях, т.к. в них нет места для гипервизора. При определенных условиях две виртуальные машины, работающие на одной хост-машине, могут взаимодействовать намного быстрее, чем если бы они работали на отдельных хост-машинах, поскольку при этом не задействуется никакая сеть. Поэтому, начиная с версии 1.2.0, Hadoop поддерживает 4-уровневую топологию.

Этот новый уровень, который называется «группа узлов», соответствует гипервизору, на котором размещены виртуальные машины. В отдельных виртуальных машинах может быть несколько узлов на одной хост-машине, которыми управляет один гипервизор, что делает возможным взаимодействие без прохождения данных через сеть.
Локальность данных в Savanna и Hadoop
Итак, зная все вышеперечисленное, как реализовать это на деле? Одним из вариантов является использование Savanna для настройки ваших кластеров Hadoop.
Savanna – это проект OpenStack, позволяющий развернуть кластеры Hadoop поверх платформы OpenStack и выполнять на ней задания. В последнем релизе Savanna 0.3 была добавлена поддержка локальности данных для плагина Vanilla (в плагине Hortonworks поддержка локальности данных планируется в ближайшем релизе Icehouse). С таким усовершенствованием Savanna может продвинуть конфигурацию кластерной топологии в Hadoop и обеспечить локальность данных. Это позволяет Savanna поддерживать как 3-, так и 4-уровневую топологию сети. Для 4-уровневой топологии Savanna использует ID хоста вычислительного узла в качестве идентификатора группы узлов кластера Hadoop. (Примечание: Будьте внимательны и не путайте группы узлов кластера Hadoop и группы узлов Savanna, у которых различные цели).
Savanna также может обеспечить локальность данных для входных потоков Swift в Hadoop, но для этого потребуется добавить в Hadoop определенный драйвер Swift, поскольку плагин Vanilla использует Hadoop 1.2.1 без встроенной поддержки Swift. Драйвер Swift был разработан командой проекта Savanna и уже частично интегрирован в Hadoop 2.4.0. Планируется полностью интегрировать его в 2.x repo, а затем применить на старой версии 1.x.
Использование локальности данных в Swift предполагает включение функции локальности данных в Savanna, а затем указание как топологии Compute, так и топологии Swift. Представленный ниже ролик показывает, как в Savanna запустить кластер Hadoop и осуществить на нем настройку локальности данных:
http://youtu.be/XayHkbmjK9g
Заключение
Обработка данных в виртуальной среде Hadoop, возможно, является следующим шагом в развитии больших данных. По мере роста кластеров исключительную важность приобретает оптимизация потребляемых ресурсов. Такие технологии, как локальность данных, могут существенно понизить степень использования сети и позволить вам работать с большими распределенными кластерами без потери преимуществ использования более мелких и более локальных кластеров. Это делает возможности масштабирования кластера Hadoop практически безграничными.
Оригинал статьи на английском языке.
