Комментарии 86
А можно получить ваши базу неправильных слов, раз уж вы проделали эту работу?
Да, только она сейчас неполная. Перед тем, как скармливать данные майнингу, я убрал из неё то, что отсекается описанными в этой статье простыми фильтрами. Сейчас в ней порядка 38М слов.
самые важные фичи: кол-во согласных, кол-во согласных подряд, позиция расположения ' с начала слова/с конца слова, буква после ', сумма букв, где каждая буква это ее частота появления в словаре
На каком объеме данных? Слова были уникальными, или так, как спарсили, так и передавали, включая повторы?
Во второй части будет описание, как я уменьшил словарь до 390000 без потерь.
Кусочек отчета теста одной из последних версий — http://dl2.joxi.net/drive/2016/05/28/0001/1653/99957/57/1518a62432.jpg
Это моей было ключевой стратегией для уменьшения размера словаря – выделить слова, включающие в себя другие слова, и закодировать, сколько букв спереди или сзади можно отбросить для получения правильных слов.
Стемер мне тоже не помог. Сделал тупо серией sql-запросов. Сами запросы будут во второй части.
Что ж, ждем вторую часть )
Там легко заменяются сети на деревья, быстро настраиваются, автоматически находятся important features, tuning параметров…
SQL база у меня была локальная. Я хотел попробовать Azure ML, но споткнулся о существенную разницу в скорости выполнения запросов между азуровским и локальным SQL-серверами. В частности, создания таблицы с несуществующими четвёрками согласных, на азуре я так и не смог дождаться. Понимаю, что можно было поработать над оптимальностью запросов, но задача была другой.
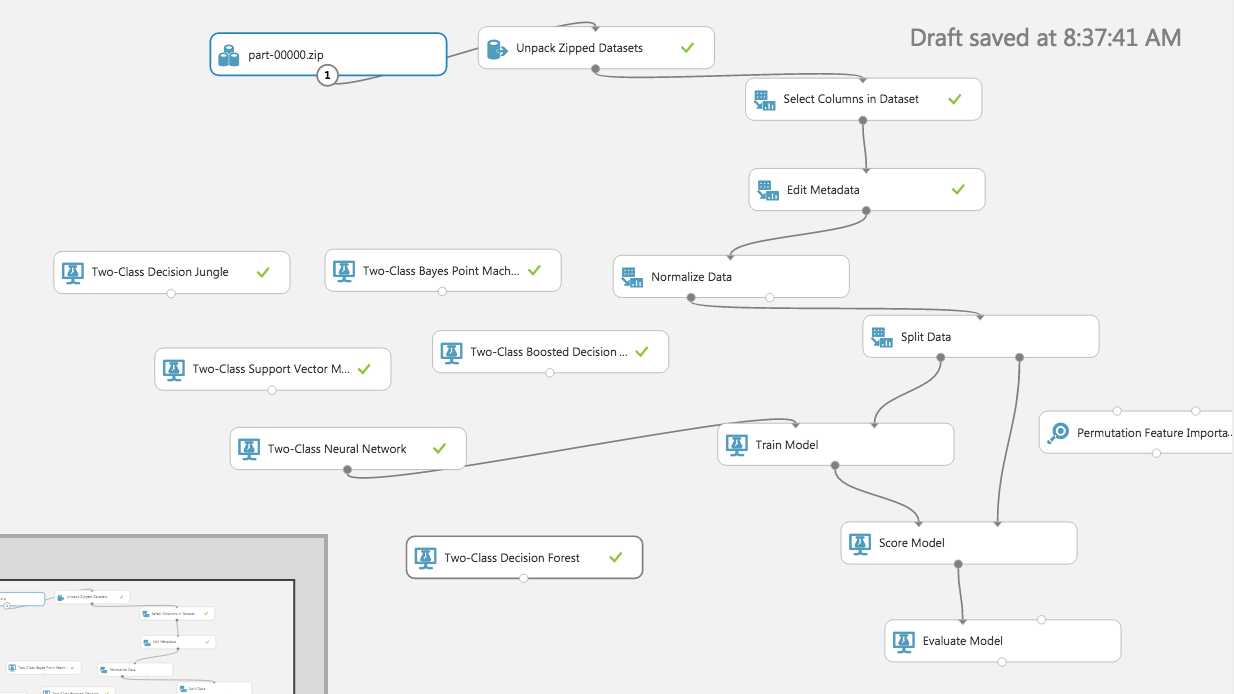
var lh = [0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1];
module.exports = {init:function() {
}, test:function(word) {
return !!lh[word.length];
}};
Проверил. Не даёт. На 1000 блоках 55.27%
2. Это набросок, который потом ушёл под тюнинг на видеокарту, и там уже были совсем другие коэфициенты.
Перепосчитал
function c(a,l,h){return(a<l)?0:(a>h)?h-l:a-l};r=function(w){w=w.replace(/\'/g,'`');f1=c(w.length,3,32);return!!([0,0,0,1,1,1,1,1,1,1][f1])}
solution.js
var a;module.exports={init:function(b){a=eval(b.toString())},test:function(b){return a(b)}}
test 0-200k 61.98225%
crossvalidation 200k-400k 61.9829%
1. Длина слова от 3 до 30
2. ASCII Код буквы на позиции от 0 до 20 (' преобразовывал в `)
3. Количество вхождений буквы a-z`
Для каждой фичи для 8M слов подсчитан результат и закэширован.
В начале есть дерево из 1 узла. Точность решения 50%
Дальше перебираются все возможные варианты как можно поделить этот узел на N узлов при помощи какой-то фичи.
Выбирается фича и узел которые имеют больше всего сумму abs(pos-neg) на всех узлах, которые образуются после разделения узла на много узлов.
А теперь всё тоже самое, только 8000 раз.
Ну плюс еще пробовал не раз озвученный фильтр Блюма. Последней идей как сделать его сильно меньше была попытка повысить изотропность добавляющихся в него слов путем их разбивки, но не по количству букв, а с помощью split по букве.
Сначала отбирал слова содержащие в середине наиболее частую в середине слова букву (e), затем среди оставшихся проделывал тоже самое (i) и так далее.
После резал слова по этим символам, так что слов delimiter превращалось в 0d, 1limit, _r (числа перед частями означали их порядок, а _ означал последний блок слова). Список букв разделителей добавляемые в данные однозначно задавал разбиение. В данном случае было например понятно что слово надо бить по e, так как она идет в списке раньше чем i.
Следующей идеей была рекурсивная разбивка, где ei напримерм означало что слово необходимо разделить так: 00d, 10l, 11m, 12t, _0r. Полученные строки добавлял в блюм. Разбиение глубже не помогало ((
В сочетании с несуществующеми парами, практически полностью повторяющими ваше решение и еще одной штукой которую назвал consonantsSignature удалось выжать ~71%.
Так же пытался бить слова на кластеры и хранить данные для каждого кластера отдельно. В чстности ластерами были длины, символы разбиений и более сложные механизмы.
Диапазон слов от 5 до 9 символов назвал изотропным провалом — именно тут мне не удалось добиться приемлемого решения. Ну да логично — там сосредоточено огромное количество слов.
Но это все.
Решение не отправил.
Уменьшение словаря до 390К, карта "соседских" двоек и троек, блум и ещё что-то читайте через неделю.
Лучше всего себя показал Porter + Nysiis
Примерная точность 73-75% на миллионе тестовых пар при размере словаря в 130 000 слов.
— Наивный Байес по букве + её позиции давал порядка 63% причем размер финального словаря ужатым получался порядка 10kb
Лучше всего НБ работал на двух буквах + позиции(порядка %73), но результат не вмещался в 63kb
(Естественно тренировка и проверка велась на разных датасетах)
— Еще была идея попробовать разобрать работу генератора через (hidden markov model).
Т.к. генератор можно, по идее, считать марковским процессом. (Не пробовал).
Но я рассуждал так. Если генератор это функция от словаря то ловить, в принципе, там нечего кроме возможных искажений в распределениях.
— Еще была идея отсекать гарантировано не слова по энтропии. (Порог отсечения подобрать бинарным поиском).
— Дальше были идеи как все это ужать через DAWG, Bloom фильтр или count min sketch(для подсчета статистики по каждому ужатому корню). Но, честно говоря, выдохся. Все равно >80% точности было добится не реально.
Решение не отправил.
Забегая вперёд этой части статьи, скажу, что я пришел к выводу, что из-за того, что большая часть неправильных слов — псевдонеправильные(слова, не поддающиеся отсечению по правилам), единственный вариант решения- формальными правилами уменьшить словарь настолько, насколько это возможно, скормить его блуму или аналогу(если есть), а затем перед проверкой на блуме на входе по редким комбинациям отсекать "мусор".
Убираем из слов все окончания 's, потом делаем
porter2+bloom+gzip
Профит.
Я, правда, не успел попробовать блум фильтры. Тут уже кому повезло с чего начать.
Согласен. Если бы я сразу с него начал, то не было бы этой статьи :-).
А как у Вас получилось сохранить блум в <64k? У меня минимально рабочий с 80% на 390K словаря занимал минимум 120K.
Так а получилось в результате их ужать в <64?
Товарищ по работе сделал больше 81%, но он дополнительно вырезал длинные слова, в остальном алгоритм тот же
var bits = массив с фильтром
var buf = new Buffer(Object.keys(bits).length*4)
var j=0
for(var i in bits){
buf.writeInt32LE(bits[i],i*4)
}
fs.writeFileSync('test1.txt',s,{encoding:"ascii"});Но на самом деле так места занимает больше из-за того, что бинарные данные почти не сжимаются.
var dic=[];
var avg=1;
function test(w){
var h=2166136261;
for (var i=0;i
http://pastebin.com/i6YeDJxn
У меня он дал 43%.
Да. В любом случае, если он это действительно делает, то Вы победите в этом конкурсе.
а еще есть англоязычные участники…
На большом числе слов безусловно победят самообучающиеся или гибридные варианты.
Теперь и я могу начинать кусать локти, потому что искусственно ограничил свой алгоритм, прерывая сбор статистики на 20 миллионах слов )
Интересно, что будут делать организаторы, если таких решений будет много? Ведь у всех будет близко к 100%
Кстати, вышеприведенный алгоритм не совершенен, и при достаточно долгом тестировании он сломается, поскольку значения в массиве dic начнут переполняться. Т.е. нельзя сказать, что данный алгоритм достаточно надёжен. Правда раньше начнут переполняться переменные и в тестирующем скрипте ;) А еще раньше наступит конец света.
Начнём с 1000 блоков, а потом видно будет.
Такое, какое потребуется, чтобы увидеть уверенную разницу между лидерами.
Когда решим, сколько нужно для лучших, прогоним на этом количестве всех.
Всё больше склоняюсь к мысли, что организаторы не ожидали подобного подхода в реализации, иначе, постарались бы его исключить на этапе постановки задачи. А теперь им остается лишь максимально придерживаться первоначальных условий конкурса.
Ясно, что генерированных разных «неслов» гораздо больше, чем реальных слов из словаря.
Поэтому шанс встретить еще раз уже встреченное ранее реальное слово гораздо выше, чем шанс встретить еще раз придуманное слово.
Просто берем от каждого слова хэш и записываем по нему в таблицу количество раз, сколько мы его встретили.
Так же еще ведем подсчет среднего.
Ответ на тест: если значение по хэшу выше среднего, то говорим «да», иначе – «нет».
Минус решения: нужна огромная выборка. Сейчас у меня выборка примерно 200к слов, а точность 52.5%, но она растет и гипотетически приближается к 100%.
Мне кажется, это решение получит приз за оригинальность, но не получит главный приз. Потому что оно фактически не выполняет свою функцию сразу из коробки. На небольших произвольный выборках результат всегда будет плохим.
Кстати, вышеприведенный алгоритм не совершенен, и при достаточно долгом тестировании он сломается, поскольку значения в массиве dic начнут переполняться. Т.е. нельзя сказать, что данный алгоритм достаточно надёжен.Это просто proof of concept, в теме конкурса обсуждают подход, а кода нет (я там писать не могу, кстати).
* от слов отрезаются самые частые окончания 's, s, ing; слова с апострофом считаются ложными
* основной алгоритм похож на фильтр Блума:
для каждого слова считается хеш-функция, по получившемуся индексу в чанке устанавливается единичный бит;
размер чанка подобран так, что после прохода по словарю остаётся приблизительно 15 нулевых битов;
позиции этих нулевых битов сохраняются в файл;
дальше происходит заполнение нового чанка с новой хеш-функцией, всего таких хеш-фунций около 3000;
при тестировании слова происходит проверка, не попала ли хеш-функция слова на один из этих нулевых битов
* дополнительно используются эвристики для отсечения ложноположительных срабатываний, подсчёт подряд идущих согласных и т.п. (+4% правильных ответов)
* стоит уделить внимание изменяемой хеш-функции, небольшие изменение в мутаторе хеш-функции дали прирост +3%
* для улучшения сжатия файла (~+7% к степени сжатия), сохраняются только расстояния между нулевыми битами, старшие байты, которые имеют схожие значения рядом с нулём, перенесены в отдельную часть файла (сделано с расчётом на gzip, для других архиваторов такая предварительная обработка может навредить)
1) От слов отрезаются префиксы и суффиксы.
2) Несколькими эвристиками отрезаются «неслова» (больше 14 букв, много гласных/согасных подряд/в_конце_слова, апостроф в слове)
3) Немного модифицированный bloom: вместо добавления в фильтр битов hash1(word) и hash2(word) добавляются hash1(word.substring(0,6)) и hash2(word.substring(0,9)), что дало сокращение false positives и примерно +1% к результату
4) За полчаса до дедлайна осознал, что bloom filter тоже можно «обучать» удаляя из него биты с false_positives больше positives. «В полубессознательном состоянии» до дедлайна удалось выжать из этой идеи +0.5%. Уже после дедлайна это обучение дало почти 83%
В основе алгоритма фильтр блума.
Но не по целым словам, а по нграммам: слово разбивается на части по фиксированному шаблону и эти части уже заносятся в фильтр.
Само решение результат перебора, который перебирал seed для хеш функции, сами хеш функции, размеры фильтра, параметры для разбивки на нграммы и списки частых суффиксов и префиксов, и пр. После чего выбиралось лучшее решение, которое после сжатия вместе с кодом влезало бы в 65536 байт.
Особенности:
-код решения вынесен в доп. данные и сжат gzip'ом, основной код в файле просто запускает его через eval
-битовый массив блума переводится в символьное представление (по 8 бит на символ) (такое представление жмется лучше всего)
-также символьное представление блума дополнительно сжимается по алгоритму LZMA (даже с учетом размера кода на распаковку мы остаемся в выигрыше примерно на 2 кб по сравнению с gzip сжатием)
Эвристики:
-удаляем из слов частые суффиксы и префиксы (как перед обучением, так и перед тестированием)
-все что по длине меньше 3 считаем за true
-все что по длине больше 17 считаем за false
-все слова, в которых есть апостроф, кроме тех которые заканчиваются на 's, считаем за false
-проверка на редкие пары символов (142 пары)
В последний день перед отправкой я понял, что могу использовать накопленную статистику. Попробовав разные варианты остановился на том, который дает 90% (а по правде 86% как потом оказалось) на большой выборке, побоялся за переполнение по памяти и ограничил сбор статистики на 20 миллионах слов, хотя эта проблема решается на раз-два, но был уже вечер и я затупил.
У меня было бы еще меньше 81% если бы я не сэкономил несколько килобайт сжав блюм не гзипом, а lzma.
Didi открывает конкурс машинного обучения с главным призом в $100,000
Второй — обучение на входящих словах. В комментариях к основной задаче это называют читерством, но все условия задачи соблюдаются.
Первый нужен что бы не было провала до 50% пока второй не обучился. После 630040*6 слов первый алгоритм отключается т.к. начинает тянуть вниз, этот момент явно выражен на графике.
Результат: i.imgur.com/IK3LCZ6.png
{kind=link}
У меня было только 6,2кк слов из генератора, я их прогнал 5 раз по кругу. Поэтому мат.ожидание неправильных слов было x5 от нормального и обучение прошло некорректно. Асимптота в районе 91%.
Для тестов написал простой генератор if (rand(1) < 0.5) {return rand(0, 10000)} else {return rand(10000, 40000)} Тут мощность набора некорректных в 3 раза больше мощности корректных. В словах из генератора она начинается с 5 и растет до бесконечности.
На 20кк тестов получилось 95% точность, в обученной базе 604030 слов, из них 99,8% правильные.
У обучения есть очистка базы, удаляющая слова с низким мат. ожиданием, поэтому память не превышает 1,5Gb независимо от кол-ва тестов, хоть миллиард.
Скорость работы получилось разогнать до миллион тестов в минуту на corei5.
Осталось дождаться решения организаторов по кол-ву запусков.
Отпуск по-программистски, или как я не поучаствовал в конкурсе по программированию на JS. Часть первая