

Отличную функцию недавно добавили в основную ветку компилятора Clang. С помощью атрибутов
[[clang::musttail]] или __attribute__((musttail)) теперь можно получить гарантированные хвостовые (tail) вызовы в C, C++ и Objective-C.int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
(Онлайн-компилятор)
Обычно эти вызовы ассоциируются с функциональным программированием, но меня они интересуют только с точки зрения производительности. В некоторых случаях с их помощью можно получить от компилятора более качественный код — по крайней мере, при имеющихся технологиях компилирования, — не прибегая к ассемблеру.
Применение этого подхода в парсинге протокола сериализации дало поразительные результаты: мы смогли парсить на скорости свыше 2 Гб/с., более чем вдвое быстрее лучшего предыдущего решения. Это ускорение будет полезно во многих ситуациях, так что неверно будет ограничиваться одним лишь утверждением «хвостовые вызовы == двукратное ускорение». Однако эти вызовы — ключевой элемент, благодаря которому стал возможен такой прирост скорости.
Я расскажу, в чём достоинства хвостовых вызовов, как мы с их помощью парсим протокол и как можно распространить эту методику на интерпретаторы. Думаю, что благодаря ей интерпретаторы всех основных языков, написанных на С (Python, Ruby, PHP, Lua и т.д.), могут получить значительный прирост производительности. Главный недостаток связан с портируемостью: сегодня
musttail является нестандартным расширением компилятора. И хотя я надеюсь, что оно приживется, однако пройдет некоторое время, прежде чем расширение распространится достаточно широко, чтобы C-компилятор вашей системы мог его поддерживать. При сборке вы можете пожертвовать эффективностью в обмен на портируемость, если окажется, что musttail недоступно.Основы хвостовых вызовов
Хвостовой вызов — это вызов любой функции, находящейся в хвостовом положении, последнее действие перед тем, как функция вернёт результат. При оптимизации хвостовых вызовов компилятор компилирует для хвостового вызова инструкцию
jmp, а не call. Тогда не выполняются служебные действия, которые в обычной ситуации позволяют вызываемой g() возвращать вызывающей f(), например, создание нового фрейма стека или передача адреса возврата. Вместо этого f() напрямую обращается к g(), как если бы та была частью неё самой, а g() возвращает результат напрямую тому, кто вызвал f(). Эта оптимизация безопасна, потому что фрейм стека f() больше не нужен после начала хвостового вызова, ведь стало невозможно обратиться к какой-либо локальной переменной f().Пусть это и выглядит банально, но у такой оптимизации есть две важные особенности, открывающие новые возможности по написанию алгоритмов. Во-первых, при выполнении n последовательных хвостовых вызов стек памяти уменьшается с O(n) до O(1). Это важно потому, что что стек ограничен и переполнение может обрушить программу. Так что без этой оптимизации некоторые алгоритмы являются опасными. Во-вторых,
jmp устраняет накладные расходы на call, и в результате вызов функции становится таким же эффективным, как и любая другая ветка. Обе эти особенности позволяют использовать хвостовые вызовы в качестве эффективной альтернативы обычным итеративным структурам управления вроде for и while.Эта идея вовсе не нова и восходит к 1977 году, когда Гай Стил (Guy Steele) написал целую работу, в которой утверждал, что вызовы процедур повышают чистоту архитектур по сравнению с
GOTO, и что при этом оптимизация хвостовых вызовов позволяет не терять в скорости. Это была одна из «Лямбда-работ», написанных в период с 1975 по 1980, в которых был сформулировано много идей, лёгших в основу Lisp и Scheme.Оптимизация хвостовых вызовов даже для Clang не в новинку. Он и до этого мог оптимизировать их, как GCC и многие другие компиляторы. На самом деле атрибут
musttail в этом примере совсем не меняет результат работы компилятора: Clang уже оптимизировал хвостовые вызовы под -O2.Новое здесь — это гарантия. Хотя компиляторы зачастую успешно оптимизируют хвостовые вызовы, однако это «лучшее из возможного», и вы не можете на это полагаться. В частности, оптимизация наверняка не сработает в неоптимизированных сборках: онлайн-компилятор. В этом примере хвостовой вызов скомпилирован в
call, так что мы вернулись к стеку размером O(n). Вот почему нам нужен musttail: пока у нас нет гарантии от компилятора, что наши хвостовые вызовы будут всегда оптимизированы во всех режимах сборки, писать алгоритмы с такими вызовами для итерации будет небезопасно. А придерживаться кода, который работает только при включённых оптимизациях, будет довольно жёстким ограничением.Проблема с циклами интерпретатора
Компиляторы — это невероятная технология, но они не совершенны. Майк Пол (Mike Pall), автор LuaJIT, решил написать интерпретатор LuaJIT 2.x на ассемблере, а не C, и он назвал это главным фактором, благодаря которому интерпретатор получился таким быстрым. Позднее Пол подробнее объяснил, почему С-компиляторам трудно даются главные циклы интерпретатора. Два главных тезиса:
- Чем больше функция и чем сложнее и обширнее набор соединений её потока управления, тем сложнее распределителю регистров в компиляторе поддерживать в регистрах самые важные данные.
- Когда в одной функции смешаны быстрые и медленные пути, наличие медленных путей снижает качество кода быстрых путей.
Эти наблюдения хорошо отражают наш опыт оптимизации парсинга протокола сериализации. И решить обе проблемы помогут нам хвостовые вызовы.
Вам может показаться странным сравнивать циклы интерпретатора с парсерами протокола сериализации. Однако их неожиданное для вас сходство определяется природой wire-формата протокола: это набор пар ключ-значение, в которых ключ содержит номер поля и его тип. Ключ работает как код операции в интерпретаторе: он говорит нам, какую операцию нужно выполнить для парсинга этого поля. Номера полей в протоколе могут идти в любом порядке, так что нужно быть готовым в любой момент перейти к любой части кода.
Логично будет писать такой парсер с помощью цикла
while с вложенным выражением switch. Это был лучший подход для парсинга протокола сериализации в течение всего времени существования протокола. Вот, например, код парсинга из текущей С++-версии. Если представить поток управления графически, то получим такую схему: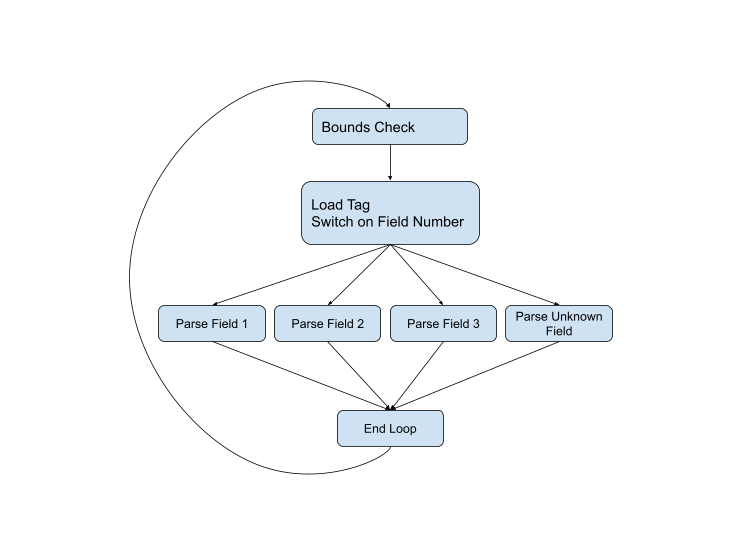
Но схема не полная, потому что почти на каждом этапе могут возникнуть проблемы. Тип поля может оказаться неправильным, или данные окажутся повреждены, или мы можем просто перейти в конец текущего буфера. Полная схема выглядит так:
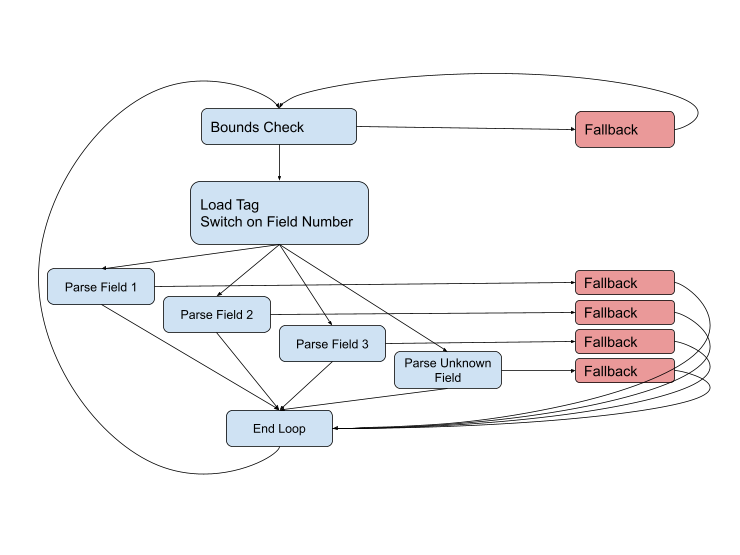
Нам нужно как можно дольше оставаться на быстрых путях (голубого цвета), но столкнувшись с трудной ситуацией придётся обрабатывать её с помощью fallback-кода. Такие пути обычно длиннее и сложнее быстрых, они затрагивают больше данных и зачастую используют неудобные вызовы других функций для обработки ещё более сложных случаев.
В теории, если объединить эту схему с профилем, то компилятор получит всю необходимую информацию для генерирования наиболее оптимального кода. Но на практике при таком размере функции и количестве связей нам часто приходится бороться с компилятором. Он выкидывает важную переменную, которую мы хотим сохранить в регистре. Он применяет манипуляции с фреймом стека, которые мы хотим обернуть вокруг вызова fallback-функции. Он объединяет идентичные пути кода, которые мы хотим оставить разделёнными для прогнозирования ветвления. Всё это выглядит на попытку играть на пианино в варежках.
Улучшаем циклы интерпретатора с помощью хвостовых вызовов
Описанные выше рассуждения — это по большей части перефразированные наблюдения Пола об основных циклах интерпретатора. Но вместо того, чтобы кидаться в ассемблер, мы обнаружили, что адаптированная под хвостовые вызовы архитектура может дать нам необходимое управление для получения из С почти оптимального кода. Я работал над этим со своим коллегой Гербеном Ставенгой (Gerben Stavenga), который придумал большую часть архитектуры. Наш подход аналогичен архитектуре WebAssembly-интерпретатора wasm3, в котором этот паттерн назван «метамашиной».
Мы поместили код нашего двухгигабитного парсера в upb, маленькую protobuf-библиотеку на C. Он полностью рабочий и проходит все тесты соответствия протоколу сериализации, но пока нигде не развёрнут, а архитектура не реализована в С++-версии протокола. Но когда в Clang появилось расширение
musttail (и upb обновили для его использования), упал один из главных барьеров на пути к полному внедрению нашего быстрого парсера.Мы отошли от одной большой парсинговой функции и применяем для каждой операции свою собственную маленькую функцию. Каждая хвостовая функция вызывает следующую операцию в последовательности. Например, вот функция для парсинга одиночного поля фиксированного размера (код упрощён по сравнению с upb, многие мелкие подробности архитектуры я убрал).
Код
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Для такой маленькой и простой функции Clang генерирует код, который практически невозможно превзойти:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Обратите внимание, что здесь нет пролога и эпилога, нет вытеснения регистров, вообще не используется стек. Единственные выходы —
jmp из двух хвостовых вызовов, но для передачи параметров код не нужен, потому что аргументы уже лежат в правильных регистрах. Пожалуй, единственное возможное улучшение, которое мы здесь видим, заключается в условном переходе для хвостового вызова jne fallback вместо jne с последующим jmp.Если бы вы увидели дизассемблирование этого кода без символьной информации, то не поняли бы, что это была вся функция. Это в равной степени мог быть быть базовый блок более крупной функции. И именно это мы делаем: берём цикл интерпретатора, который представляет собой большую и сложную функцию, и программируем его блок за блоком, передавая между ними поток управления через хвостовые вызовы. Мы полностью контролируем распределение регистров на границе каждого блока (как минимум шести регистров), и поскольку функция достаточно простая и не вытесняет регистры, мы достигли своей цели — хранения самого важного состояния на протяжении всех быстрых путей.
Мы можем независимо оптимизировать каждую последовательность инструкций. И компилятор будет обрабатывать все последовательности тоже независимо, потому что они расположены в отдельных функциях (при необходимости можно предотвращать инлайнинг с помощью
noinline). Так мы решаем описанную выше проблему, при которой код из fallback-путей ухудшает качество кода быстрых путей. Если поместить медленные пути в полностью отдельные функции, то можно гарантировать стабильность скорости быстрых путей. Красивый ассемблер остаётся неизменным, на него не влияют никакие изменения в других частях парсера.Если применить этот паттерн к примеру Пола из LuaJIT, то можно примерно сопоставить его написанный вручную ассемблер с небольшими ухудшениями качества кода:
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Получившийся ассемблер:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
Я вижу здесь лишь одну возможность улучшения не считая вышеупомянутой
jne fallback: по какой-то причине компилятор не хочет генерировать jmp qword ptr [rsi + 8*rax], вместо этого он загружает в rax и затем выполняет jmp rax. Это небольшие проблемы генерирования кода, которые, надеюсь, в Clang скоро исправят без излишних затруднений.Ограничения
Один из главных недостатков этого подхода заключается в том, что все эти прекрасные последовательности на ассемблере катастрофически пессимизируются при отсутствии хвостовых вызовов. Любой нехвостовой вызов приводит к созданию фрейма стека и вытеснению в стек многих данных.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Неожиданно получаем вот это
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Чтобы избежать подобного, мы пытались вызывать другие функции только через инлайнинг или хвостовые вызовы. Это может утомлять, если у операции много мест, в которых может возникнуть необычная ситуация, не являющаяся ошибкой. Например, когда мы парсим протокол сериализации целочисленные переменные часто бывают длиной один байт, но более длинные не являются ошибкой. Инлайнинг обработки таких ситуаций может ухудшить качество быстрого пути, если fallback-код окажется слишком сложным. Но хвостовой вызов fallback-функции не позволяет легко вернуться к операции при обработке нестандартной ситуации, так что fallback-функция должна уметь завершать операцию. Это приводит к дублированию и усложнению кода.
В идеале это проблему можно решить с помощью добавления __attribute__((preserve_most)) в fallback-функции с последующим нормальным вызовом, а не хвостовым. Атрибут
preserve_most возлагает на вызываемого ответственность за сохранение почти всех регистров. Это позволяет перекладывать задачу вытеснения регистров на fallback-функции, если такое понадобится. Мы экспериментировали с этим атрибутом, но столкнулись с таинственными проблемами, решить которые не смогли. Возможно, мы где-то допустили ошибку, вернёмся к этому в будущем.Главное ограничение заключается в том, что
musttail не является портируемым. Очень надеюсь, что атрибут приживётся, его внедрят в GCC, Visual C++ и других компиляторах, а однажды даже стандартизируют. Но это случится не скоро, а что нам делать сейчас?Когда расширение
musttail недоступно, нужно для каждой теоретической итерации цикла выполнить хотя бы один верный return без хвостового вызова. Мы ещё не реализовали такой fallback в библиотеке upb, но думаю, что она превратится в макрос, который в зависимости от доступности musttail будет либо делать хвостовые вызовы, либо просто возвращать.