

Команда Kubernetes as a Service в Mail.ru Cloud Solutions перевела контрольный список для запуска Redis внутри кластера Kubernetes. С ним стоит ознакомиться до того, как перейти к использованию Redis под рабочей нагрузкой.
Redis — популярное in-memory хранилище данных и кэш с открытым исходным кодом. Этот продукт стал важным компонентом построения масштабируемых микросервисных систем. Многие облачные провайдеры предлагают полностью управляемые сервисы Redis: Amazon ElastiCache, Azure Cache for Redis, GCP Memorystore (и на платформе MCS тоже есть такой управляемый сервис — прим. переводчика). Однако Redis также можно легко развернуть в Kubernetes, если вам нужно полнее контролировать его конфигурации. Прямо из коробки у него уже достойная производительность, но если вы собираетесь использовать Redis с рабочей нагрузкой, то сначала проверьте, выполняются ли все пункты этого чек-листа.
Оптимизация аппаратного обеспечения
Как и у многих других баз данных, производительность Redis зависит от характеристик виртуальных машин. Создайте пул узлов (node pool) с машинами, оптимизированными по памяти и с высокой пропускной способностью сети, чтобы минимизировать задержку между клиентами и серверами Redis. Это однопоточная база данных, то есть быстрые процессоры с большими кэшами (например, виртуальные машины на Intel Skylake или Cascade Lake) будут работать лучше, а добавление новых ядер лишь опосредованно влияет на производительность.
Если ваша рабочая нагрузка состоит в основном из маленьких объектов (меньше 10 Кб), то размер и пропускная способность памяти не так критичны для оптимизации производительности Redis. Подробнее о скорости работы Redis на разном оборудовании читайте здесь.
Выбор метода развертывания
Развернуть Redis-кластер в Kubernetes можно с помощью Bitnami Redis Helm или одного из операторов Redis. Хотя обычно я выступаю за операторы Kubernetes, однако не похоже, что есть популярный и отработанный оператор Redis по сравнению с Bitnami Helm Chart. Компания Redis Labs, создавшая Redis, предлагает официальный оператор Redis Enterprise Kubernetes, но если вам нужна настоящая Open Source-версия, то можете выбрать между оператором Spotahome или Amadeus IT Group (альфа). Я с ними не работал, но есть хорошая статья о проблемах при использовании Redis-оператора Spotahome.
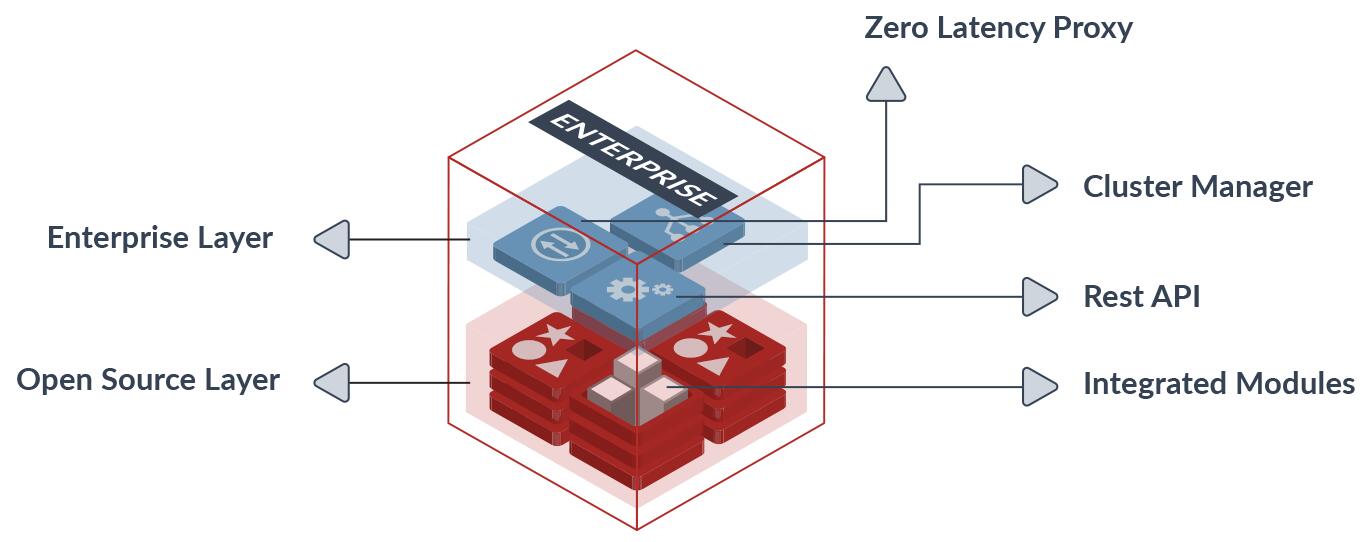
Redis Enterprise и Redis Open Source
Bitnami поддерживает два вида развертывания Redis: кластер Master-Slave с Redis Sentinel и топологию Redis-кластера с шардированием. Если у вас большая нагрузка на чтение, то кластер Master-Slave поможет перенести операции чтения на Slave-поды. Классы Sentinel конфигурируются для предоставления Slave-пода мастеру в случае сбоя. А Redis-кластер шардирует данные на многочисленные экземпляры и отлично подходит для ситуаций, когда требования к памяти превышают ограничения для одного мастера, а процессор становится узким местом (больше 100 Гб). Redis-кластер также поддерживает высокую доступность с каждым мастером, подключенным к одному или нескольким Slave-подам. Когда Master-под падает, один из Slave становится новым мастером.
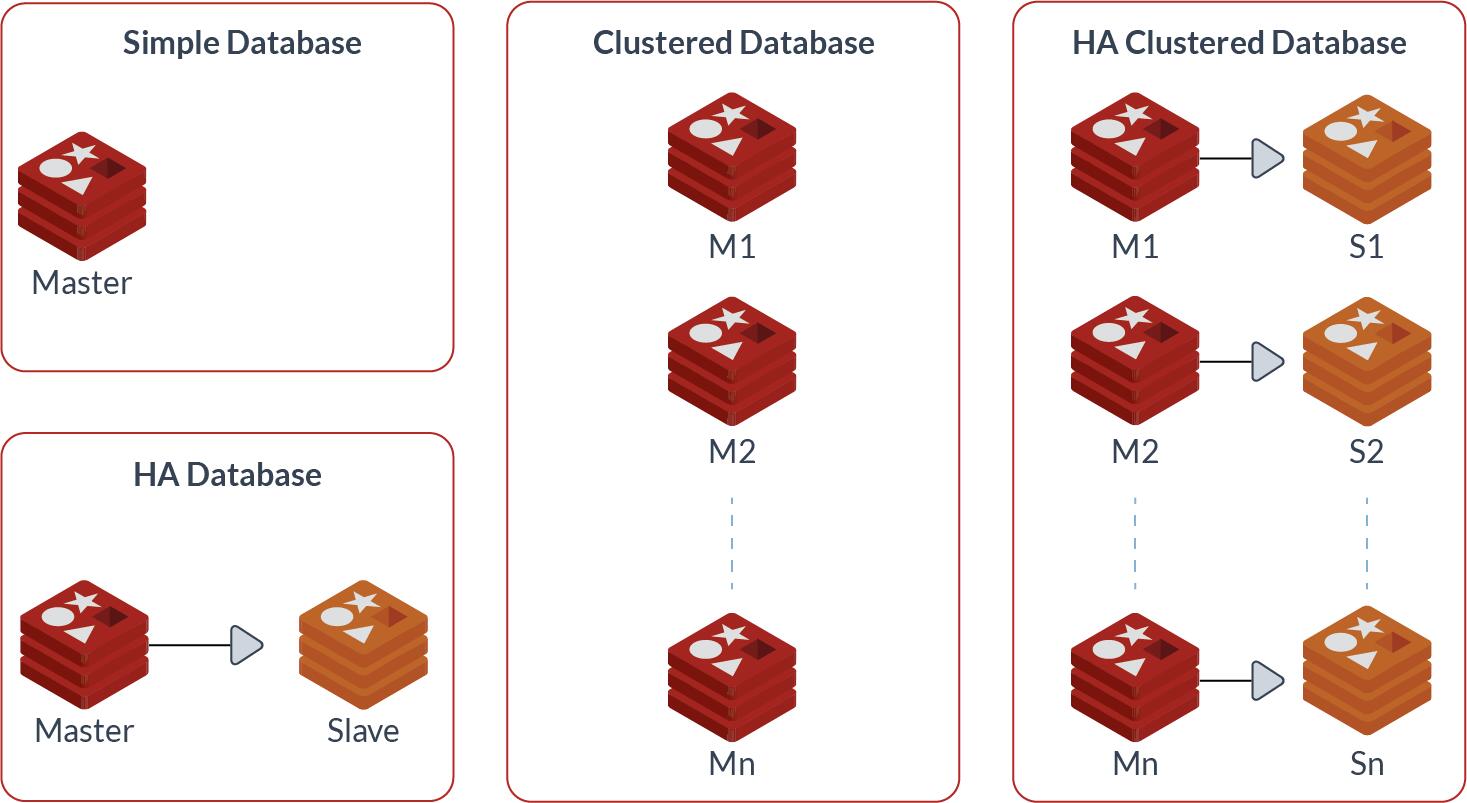
Архитектура Redis
Постоянное хранилище
Часть данных Redis держит во временном хранилище, но для высокой доступности необходимы постоянные тома. Redis предлагает два варианта:
- RDB (Redis Database File): моментальные снимки на определенный момент времени;
- AOF (Append Only File): журналирование всех операций Redis.
Можно оба типа комбинировать, но нужно понимать их особенности, чтобы добиться наилучшей производительности.
RDB — компактный снимок базы данных (снапшот), оптимизированный под типичные операции резервного копирования. Такие операции минимально влияют на производительность Redis, потому что для создания резервной копии родительский процесс форкает дочерний. При восстановлении после аварии RDB запускается быстрее AOF, потому что размер файлов меньше. Но поскольку RDB — это моментальный снимок, в случае сбоев теряются данные между созданием снапшотов.
С другой стороны, AOF сохраняет каждую операцию и надежнее RDB, поскольку его можно сконфигурировать для применения fsync каждую секунду или при каждом запросе. При сбое AOF может пройти по журналу и повторить каждую операцию. Redis также может автоматически и безопасно переписать AOF в фоновом режиме, если тот становится слишком большим. К недостаткам AOF относятся размер файла и скорость работы. С включенной репликацией Slave иногда не могут синхронизироваться с Master достаточно быстро, чтобы извлечь все данные. Также AOF может работать медленнее RDB в зависимости от политики fsync.
Redis Helm по умолчанию включает AOF и выключает RDB, но вы можете применить ConfigMap с другими стратегиями fsync или использования RDB:
configmap: |-
# Enable AOF https://redis.io/topics/persistence#append-only-file
appendonly yes # Disable RDB persistence, AOF persistence already enabled.
save ""Подробнее о постоянном хранении в Redis читайте статью на официальном сайте.
Отключение THP
После развертывания Redis в Kubernetes вы наверняка увидите такое сообщение:
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command echo never > /sys/kernel/mm/transparent_hugepage/enabled as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.ВНИМАНИЕ: в вашем ядре включена поддержка Transparent Huge Pages (THP). Это приведет к задержкам и проблемам в использовании памяти Redis. Чтобы это исправить, выполните с root-правами команду echo never > /sys/kernel/mm/transparent_hugepage/enabled и добавьте ее в /etc/rc.local, чтобы сохранить настройку после перезагрузки. После отключения THP нужно перезагрузить Redis.
Чтобы отключить THP, можно добавить для запуска команды инициализирующий контейнер или развернуть DaemonSet в узловом пуле с Redis. Например, у меня есть пул, исполняющийся в GKE, и тогда я разворачиваю DaemonSet таким образом:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: thp-disable
namespace: kube-system
spec:
selector:
matchLabels:
name: thp-disable
template:
metadata:
labels:
name: thp-disable
spec:
tolerations:
- key: "database"
operator: "Equal"
value: "true"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-nodepool
operator: In
values:
- database
restartPolicy: Always
terminationGracePeriodSeconds: 1
volumes:
- name: host-sys
hostPath:
path: /sys
initContainers:
- name: disable-thp
image: busybox
volumeMounts:
- name: host-sys
mountPath: /host-sys
command: ["sh", "-c", "echo never >/host-sys/kernel/mm/transparent_hugepage/enabled"]
containers:
- name: busybox
image: busybox
command: ["watch", "-n", "600", "cat", "/sys/kernel/mm/transparent_hugepage/enabled"]Измерение производительности
После настройки кластера Redis можно измерить производительность с помощью различных хорошо поддерживаемых инструментов:
- Redis Benchmark — поставляется с Redis;
- Memtier Benchmark — также разрабатывается компанией Redis Labs;
- Redis Memory Analyzer — Python-инструмент компании GameNet;
- YCSB — от Yahoo Cloud;
- PerfKit Benchmarker — от Google Cloud;
- Redis RDB tools — парсит файлы Redis dump.rdb;
- Harvest — берет ключи Redis и показывает самые многочисленные префиксы.
Чи Хаясида из Google Cloud написал прекрасное руководство по использованию YCSB для измерения производительности Redis при хранении в памяти (Redis под управлением GCP). Те же инструменты позволяют измерять производительность и в Kubernetes. С помощью перенаправления портов отобразите Redis на localhost и прогоните YCSB с разными шаблонами использования. Для тонкой настройки производительности объедините полученные результаты с данными анализаторов памяти:
- Длинные строки или JSON/XML-значения сожмите с помощью Snappy/LZO (низкая задержка) или GZIP (максимальное сжатие).
- Для эффективной сериализации используйте вместо JSON формат MessagePack.
- Задайте соответствующую политику вытеснения: с помощью allkeys вытесняйте все ключи либо применяйте volatile к тем ключам, у которых задано поле TTL/expiration (можно указывать в разделе с дополнительными флагами в Helm).
master:
## Redis command arguments
##
## Can be used to specify command line arguments, for example:
##
command: "/run.sh"
## Additional Redis configuration for the master nodes
## ref: https://redis.io/topics/config
##
configmap:
## Redis additional command line flags
##
## Can be used to specify command line flags, for example:
## extraFlags:
## - "--maxmemory-policy volatile-ttl"
## - "--repl-backlog-size 1024mb"Мониторинг
Наконец, подключите метрики Redis к Prometheus или другому инструменту мониторинга, чтобы выявлять снижение производительности и получать оповещения. Bitnami Helm использует по умолчанию Bitnami Redis Exporter, но вы можете взять популярный инструмент от Oliver006. Есть и сопутствующий Grafana-инструмент для визуализации всех метрик.
Что касается конфигурирования оповещений, то Bitnami предлагает такие примеры правил:
## Custom PrometheusRule to be defined
## The value is evaluated as a template, so, for example, the value can depend on .Release or .Chart
## ref: https://github.com/coreos/prometheus-operator#customresourcedefinitions
prometheusRule:
enabled: false
additionalLabels: {}
namespace: ""
## Redis prometheus rules
## These are just examples rules, please adapt them to your needs.
## Make sure to constraint the rules to the current postgresql service.
# rules:
# - alert: RedisDown
# expr: redis_up{service="{{ template "redis.fullname" . }}-metrics"} == 0
# for: 2m
# labels:
# severity: error
# annotations:
# summary: Redis instance {{ "{{ $labels.instance }}" }} down
# description: Redis instance {{ "{{ $labels.instance }}" }} is down
# - alert: RedisMemoryHigh
# expr: >
# redis_memory_used_bytes{service="{{ template "redis.fullname" . }}-metrics"} * 100
# /
# redis_memory_max_bytes{service="{{ template "redis.fullname" . }}-metrics"}
# > 90 =< 100
# for: 2m
# labels:
# severity: error
# annotations:
# summary: Redis instance {{ "{{ $labels.instance }}" }} is using too much memory
# description: |
# Redis instance {{ "{{ $labels.instance }}" }} is using {{ "{{ $value }}" }}% of its available memory.
# - alert: RedisKeyEviction
# expr: |
# increase(redis_evicted_keys_total{service="{{ template "redis.fullname" . }}-metrics"}[5m]) > 0
# for: 1s
# labels:
# severity: error
# annotations:
# summary: Redis instance {{ "{{ $labels.instance }}" }} has evicted keys
# description: |
# Redis instance {{ "{{ $labels.instance }}" }} has evicted {{ "{{ $value }}" }} keys in the last 5 minutes.
rules: []Либо вы можете использовать оповещения Redis из проекта Awesome Prometheus. Если вам нужно руководство по настройке Prometheus в Kubernetes, то почитайте серию статей Practical Monitoring with Prometheus and Grafana.
Теперь у вас должен получиться в Kubernetes готовый к эксплуатации кластер Redis. С ростом активности использования ожидается снижение производительности. Чтобы справляться с новой нагрузкой, периодически запускайте бенчмарки и анализаторы памяти.
Что еще почитать по теме:
