

В этот статье я хочу еще раз пройтись по особенностям работы транзакций в Tarantool, применительно к движку в памяти и дисковому движку. И главное — расскажу про новый менеджер транзакций, который появился в Tarantool версии 2.6, про его особенности, преимущества и устройство.
Когда меня спрашивают, что такое Tarantool, я отвечаю давно въевшееся в мозг: «Tarantool — persistent in-memory noSQL СУБД с хранимыми процедурами на Lua». Но всë не так просто. Вот in-memory — да, в основном в Tarantool используется memtx engine, движок в памяти, однако дисковый движок (vinyl) тоже давным-давно есть, и у него множество нюансов и особенностей. Или noSQL — да, в основном Tarantool используется как noSQL БД, но SQL он тоже умеет, точнее, какую-то его часть, а какую именно — это надо почитать.
Даже с хранимыми процедурами не совсем всё просто: то, что затевалось как способ сделать JOIN в noSQL БД, обросло кооперативно-многозадачной инфраструктурой для работы с сетью, файлами, HTTP, массой модулей и документации; сейчас Tarantool именуют сервером приложений с БД на борту. Да и хранимые процедуры бывают не только на Lua, но и на C.
Но это, в общем, скорее приятные оговорки, дескать, что поделать, Tarantool сложный и поэтому есть много деталей. А когда меня кто-нибудь спрашивал, есть ли в Tarantool’е транзакции и какой у них уровень изоляции, то я отвечал: «есть, serializable, но...» И далее следовали оговорки мелким шрифтом, которые портили радужную картину и время от времени вызывали негодование пользователей.
Больше никаких оговорок, пора рассмотреть новый менеджер транзакций под микроскопом.
Требования к менеджеру транзакций
Вряд ли я сильно совру, если скажу, что само понятие «транзакция» нужно только для обеспечения их изоляции. Если бы не транзакции, то базу данных можно было сделать примитивно. Запись производилась бы непосредственно в структуру данных индекса (TREE, HASH и прочие), удаляя предыдущее значение с тем же ключом. А чтение показывало бы последнее записанное значение по данному ключу. Я обозначу для удобства такую гипотетическую реализацию базы данных как примитивную базу.
Но транзакции вносят свои требования. Если рассматривать транзакцию как набор некоторых действий — чтений и записей в базу данных, — то все эти действия должны давать такой же результат, как если бы эта транзакция выполнялась в одиночестве в примитивной базе (см. выше). То есть существование одновременных транзакций допускается, но оно должно быть таким, чтобы незавершенные транзакции не влияли друг на друга.
Существуют стандартные требования к менеджеру транзакций:
- Read committed;
- Repeatable read;
- Serializable;
- Snapshot isolation.
Добавлю от себя ещё один критерий, который бессмыслен в примитивной базе, но который не хотелось бы упустить при реализации более сложного менеджера:
- Read own changes.
Давайте рассмотрим эти критерии подробнее.
Read own

Я начал с самого простого, чтобы познакомить с моим способом визуализации транзакций. Разные транзакции я буду обозначать разными цветами. По оси Х откладывается время, по оси Y — ключи и значения. Для простоты будем считать, что база у нас key-value.
Изначально в базе данных по ключу 1 хранилось значение a, по ключу 2 — значение b, по ключу 3 — значение c. Допустим, транзакция переписала значение по ключу 2 — стало d. И тогда при чтении этого ключа она должна прочитать новое (свое) значение — d. Как я говорил, это, очевидно, работает в примитивной базе, но для менеджера транзакций это готовый тест.
Read committed

- Первой начинается красная транзакция.
- Потом возникает синяя, она перезаписывает значение по ключу 1.
- После этого возникает зеленая, которая перезаписывает по ключу 2 и сразу же коммитится. А синяя, обратите внимание, так и остается незавершенной.
- После этого просыпается красная транзакция и начинает читать значения по ключам 1 и 2.
Критерий Read committed означает, что красная транзакция не должна увидеть синюю (значение d), поскольку она еще не завершена. Красная может увидеть зеленую (значение e), это ничему не противоречит, так как зеленая транзакция завершена.
Repeatable read

- Допустим, одна транзакция прочитала значение по ключу 2.
- После этого приходит синяя транзакция, перезаписывает это значение на d и коммитится.
- Теперь красная транзакция должна по ключу 2 продолжать читать значение b.
Это и есть Repeatable read: для одной транзакции однажды прочитанное значение должно оставаться неизменным (пока она его сама не изменит).
Serializable
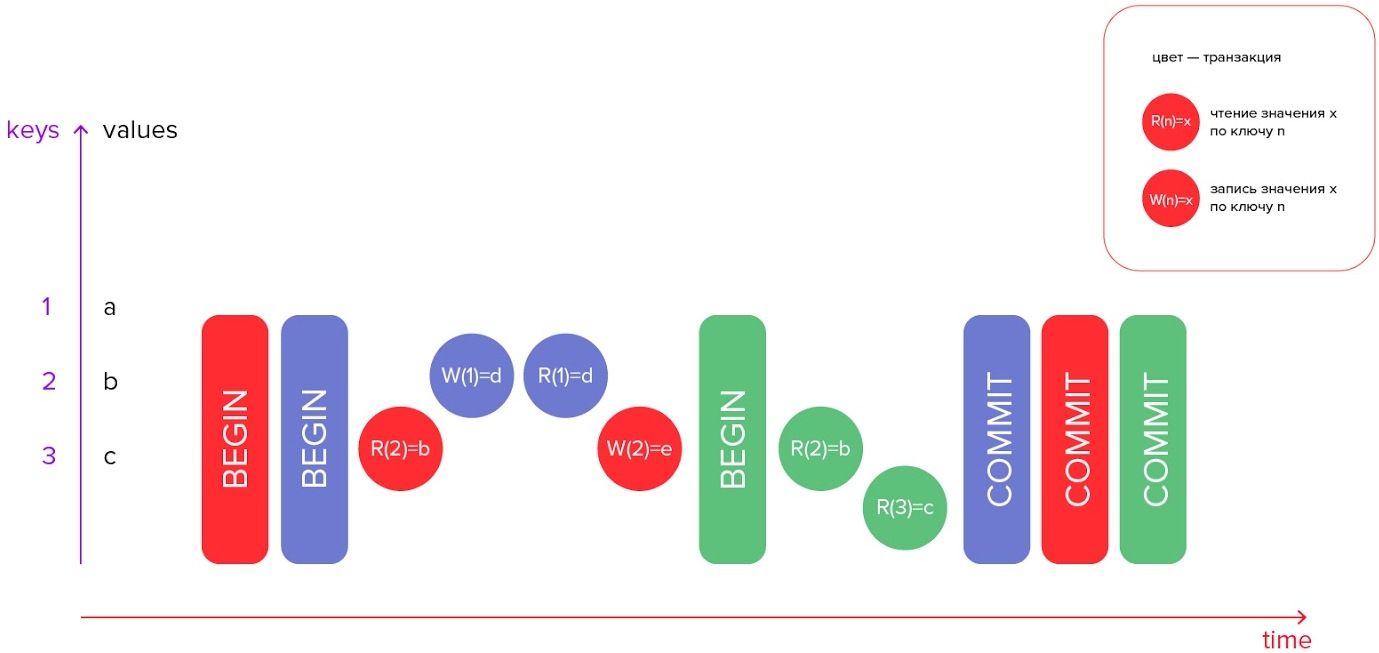
Предполагается, что транзакция совершает какие-то действия, которые каждый раз имеют какой-то результат. Результат чтения — данные, которые мы прочитали. При записи результат — данные, которые мы записали.
Операция UPDATE должна вернуть обновленный кортеж, который получился с учетом всех изменений. А INSERT может выдать, например, ошибку о том, что значение уже есть в спейсе и его не удалось вставить.
Критерий Serializable означает, что менеджер транзакций может определить любым способом некий порядок, в котором транзакции могли бы целиком исполняться последовательно в примитивное базе. При этом внутри транзакций порядок не меняется, а порядок выполнения самих транзакций выбран таким, чтобы результаты каждой операции не менялись.

На иллюстрации видно, что транзакции сериализуются в порядке зеленая — синяя — красная. Обратите внимание, что эти транзакции были завершены в другом порядке, в общем случае это не важно.
Этот порядок сериализации крайне важен для описания того, что происходит с транзакциями. Иногда важна только часть данных об этом порядке. К примеру, можно сказать, что зеленая транзакция сериализуется до синей и красной, или красная — после синей и зеленой.
Не Snapshot isolation

Критерий Snapshot isolation тут приведен скорее для примера, чтобы показать, как делать неправильно. Поэтому на картинке изображен не Snapshot isolation, а то, как работает Tarantool (точнее новый MVCC, ну и старый Vinyl).
Идея Snapshot isolation в том, что в тот момент, когда транзакция начинается (вызывает begin), она сразу же попадает в read view. Она не видит вообще никакие изменения БД, которые происходят начиная с этого момента. Таким образом гарантируется Read committed и Repeatable read. Однако это не лучшее поведение базы данных.
На иллюстрации:
- Первой начинается красная транзакция.
- Затем начинается синяя транзакция, она меняет значение d, но не завершается.
- Потом начинается зеленая, тоже изменяет данные (e) и успешно коммитится.
- После этого просыпается красная транзакция и начинает читать значения, которые писали синяя с зеленой.
Если бы режим был Snapshot isolation, то красная транзакция не видела бы зеленое значение e, а только изначальные a и b. Однако такой подход сразу фиксирует относительный порядок сериализации красной и зеленой транзакций: красная должна быть строго до завершившейся зеленой.
Это ограничение, наложенное на порядок, может привести к конфликту позже, когда выяснится, что красная транзакция еще должна существовать после зеленой (это не обязательно, но часто вытекает из того, что красная еще выполняет действия после завершения зеленой).
Поэтому мы стремимся реализовывать не snapshot isolation. Read view, конечно, создавать приходится, но не всегда и как можно позже, так будет меньше конфликтов. Поэтому на иллюстрации видно, что красная транзакция читает зеленое значение e, успешно его перезаписывает и успешно завершается.
Транзакции в memtx 2.5 и ниже
Итак, как же были реализованы транзакции для движка в памяти в более ранних версиях Tarantool?
Тут надо сказать, что Tarantool использует кооперативную многозадачность. Физически поток исполнения транзакций один, однако каждая хранимая процедура выполняется в отдельном файбере (зеленом потоке). Или просто каждый запрос, если пользователь не использует хранимую процедуру, а обращается напрямую к данным. Управление из файбера отдается исключительно по желанию самого файбера.
Многие функции внутри себя содержат функции передачи управления, например, к этому относятся все I/O-операции. Это значит, что если в хранимой процедуре сделать запись в сокет, то этот файбер уснет до того, как запись в сокет фактически произойдет. В это время другие файберы могут проснуться и сделать свою полезную работу.
Такие функции называют йилдящими (от yield). При этом какие-то функции могут быть гарантированно не йилдящими. За время их выполнения никакие другие файберы никаких действий сделать не могут.
В Tarantool операции чтения из in-memory таблиц никогда не уступают управление. В то же время отдельностоящие (autocommit) операции записи отдают управление до тех пор, пока в WAL не появится запись об этой операции. Однако при явном начале транзакции (при вызове
box.begin()) все операции записи начинают накапливать записи в WAL, соответственно, перестают передавать управление. При этом все операции над индексами — вставки, замены, удаления — выполняются как в примитивной базе. Таким образом, выполняется Read own. Только при успешном завершении транзакции (вызов
box.commit()) инициируется запись в WAL и управление передается другим файберам. При ошибке транзакция будет целиком откачена, в том числе будут возвращены предыдущие данные в индексы. То же самое случится, если же во время выполнения транзакции произойдет передача управления, например, нам вздумается сделать запись в сокет внутри транзакции. Таким образом, транзакции в Tarantool были строго атомарны! Получается, строго serializable в порядке записи в WAL? Да, почти… кроме одного случая. Это то самое, мелким шрифтом.
Дело в том, что не все транзакции ждут записи в WAL. Есть read-only транзакции, которые отдают результат пользователю моментально. Если такая транзакция прочитает данные, которые записала другая транзакция, ожидающая окончания записи в WAL, и эта запись в WAL завершится с ошибкой… Тогда вторая транзакция будет откачена, а первая прочитает никогда не существовавшее значение.

Таким образом мы получаем dirty read, то есть нарушается критерий read committed. Конечно, это происходит только при сбое WAL. Можно сказать, что транзакции в memtx 2.5 и ниже имеют уровень изоляции serializable, но в момент сбоя WAL могут быть dirty read.
То есть если всё хорошо — то всё очень хорошо, а если всё плохо — то всё очень плохо. Отношение к такому механизму сильно зависит от оптимистичности пользователя. Такое поведение всех более-менее устраивало. Но когда мы начали реализовывать синхронную репликацию, проблема грязных чтений встала в полный рост. Синхронная репликация заставила нас форсировать разработку нового менеджера транзакций.
Резюмируя достоинства и недостатки старого варианта движка memtx:
- Транзакции действительно атомарны.
- Fiber yield приводил к отмене транзакции.
- Интерактивных транзакций не предусмотрено.
- При сбое WAL — откат и read uncommitted.
- В синхронной репликации дела еще хуже, чем с WAL.
- Минимум (если не сказать ноль) накладных расходов.
Транзакции в vinyl
Vinyl — это дисковый движок, сделанный на основе LSM-дерева. В нем подход memtx сразу не подошел из-за неизбежного I/O. Поэтому был написан специальный менеджер транзакций.
В общем, он заслуживает отдельной статьи. Если вкратце, то он честно serializable:
- Каждая транзакция хранит свои read set и write set.
- Каждый кортеж (ряд в таблице) хранит тип операции и LSN.
- История кортежей хранится в самом индексе — фактически, LSN, — это еще одно измерение ключа.
- MVCC: при чтении происходит слияние данных из разных источников; помимо разных уровней LSM еще и собственный write set текущей транзакции.
- Conflict Manager: при коммите транзакция пересекает свой write set с read setами остальных транзакций. При пересечении фиксируются конфликты, и читающая транзакция либо уходит в read view, либо абортится.
Тут возникает логичный вопрос: а почему так нельзя сделать в memtx, и дело с концом? И вот на него ответы, по пунктам соответственно:
- Дорого по CPU (memtx обязан быть быстрым), дорого в реализации (это же для каждого типа индекса надо делать).
- Дорого по памяти. Лишние 9 байт на кортеж — это много, особенно для тех, кому не нужен менеджер транзакций.
- Это подойдет только для tree-like индекса и в некоторых ситуациях имеет существенные проблемы с производительностью.
- Это же только для LSM tree. Более-менее понятно для TREE и HASH. Непонятно, как мержить rtree и bitset.
- Опять же, непонятно, что делать для rtree и bitset.
Требования для менеджера транзакций в 2.6
Для нового менеджера транзакций memtx мы сформировали список требований, которому не удовлетворяли ни текущая реализация транзакций memtx, ни менеджер транзакций vinyl:
- Дешево по памяти и производительности по принципу «не используешь — не платишь». Если разные транзакции работают с непересекающимися данными, то хочется иметь обычную производительность, как без менеджера.
- При пересекающихся множествах данных производительность также должна оставаться на достойном уровне.
- Реализация должна быть максимально независимой от типа индекса.
- Serializable без блокировок (то есть с абортами при конфликте), как в vinyl.
Дополнительным, независимым фактором является решение о том, что транзакции должны быть сериализованы в порядке записи в WAL. В общем случае это необязательно, но иные подходы приводят к массе проблем, связанных с непрерывной консистентностью при восстановлении и репликации. Учитывая, что read only транзакции не записываются в WAL, они сериализуются в любом удобном для менеджера порядке.
Подсистемы
Менеджер транзакций можно удобно разделить на две почти независимые подсистемы: MVCC и менеджер конфликтов.
MVCC — Multi version concurrency control
- Хранит в себе все модифицирующие действия всех транзакций.
- Создает для каждой транзакции её видение состояния БД.
- Умеет создавать read view — зафиксированное состояние БД, которое уже никогда не изменится другими транзакциями.
Менеджер конфликтов
- Хранит информацию о том, какие данные читала каждая транзакция.
- При завершении транзакции для каждой другой транзакции принимает решение о возможности существования состояния БД, которое оно наблюдала.
- Умеет посылать транзакцию в read view при необходимости.
- Умеет абортить транзакцию, если ее видение БД стало невозможным.
MVCC: основная идея
У нас есть одна точка входа на запись в любой спейс — метод
replace (old_tuple, new_tuple). В общем случае он принимает два кортежа, старый и новый, с определенными ограничениями (если задан new_tuple, то old_tuple должен быть строго тем кортежем, который заменяется в первичном индексе). Все операции записи сводятся к такому replace. Например, delete — это вариант, когда old_tuple не нулевой, а new_tuple — нулевой. Примитивная реализация в этом случае выполняет простую работу: удаляет из всех индексов старый кортеж и добавляет новый. В некоторых случаях это приводит к ошибке, если добавление кортежа приводит к замене какого-то другого кортежа (не old_tuple).Поскольку для MVCC нужно в первую очередь собирать данные о записи транзакций, то логично внедряться именно в этой точке.
Основную идею реализации нового MVCC можно расписать в пять пунктов:
- Во все кортежи добавляется всего один бит информации — флаг
is_dirty. По-умолчанию этот бит не установлен, то есть все кортежи «чистые». - Изменяется поведение функции
replaceдля спейса: добавляемый в индексы кортеж помечается флагомis_dirty. Одновременно удаляемыйold_tupleтакже помечается флагомis_dirtyи специально не удаляется сразу из индексов (кроме случая, когда он явно замещается новым кортежемnew_tuple). - Для всех грязных кортежей хранится дополнительная структура (история), в которой записывается информация о том, какие транзакции что делали с данным кортежем.
- Для связи грязных кортежей и истории используется простейшая хеш-таблица, где ключом является сам указатель на кортеж. Никакой информации о ключевых полях кортежа не требуется.
- Вялый сборщик мусора постепенно удаляет историю и очищает кортежи.
Такой подход позволяет добиться сразу пяти целей:
- Неизбежных расходов — всего один бит на кортеж.
- Для чистых кортежей индексы (например, на чтение) работают по-старому и с той же скоростью.
- Для грязных кортежей можно легко получить историю, которую при селектах можно анализировать и находить кортеж, который должен быть в этом месте индекса для данной транзакции.
- В частности, можно делать
read_view. - Независимость от типа индекса.
Детали реализации
При всей красоте такого подхода было довольно сложно подобрать удобную структуру хранения для такой истории. Есть некоторые, не очевидные сразу проблемы, которые приходится решать.
- Индексов в одном спейсе может быть много. Для чтения желательно исследовать историю конкретного ключа. Например, если первый индекс построен по первому полю кортежа, а второй индекс — по второму, то прочитав из первого индекса грязный кортеж
{1, 2, «data»}нужно искать, что этот кортеж заменил в первом индексе по ключу «1», а прочитав этот же кортеж во втором индексе, нужно искать других предшественников, у которых во втором поле ключ «2». - Историю удобно хранить последовательно, в порядке возрастания времени. А порядком времени в менеджере транзакций фактически является порядок сериализации. При этом порядок сериализации совпадает с порядком коммитов транзакций. Получается, что при добавлении изменения в историю кортежа изменений нескольких транзакций мы еще не можем знать порядок сериализации и, соответственно, порядок, в котором эти изменения нужно располагать.
- Не могу не упомянуть одну досадную особенность операций удаления. В обычной, примитивной базе один кортеж может быть удален только один раз, это, в общем, логично. Однако при хранении истории это может быть не совсем так: могут быть несколько транзакций, которые собираются удалить кортеж, и это надо зафиксировать в истории, нельзя запрещать намерение удаления кортежа, так как неизвестно еще, какая из транзакций и когда соизволит закоммититься.
В результате попыток увязать это всё в одно родилось понятие tuple story: история одного кортежа. Она хранит информацию о том, кто и/или когда добавил в спейс этот кортеж и кто и/или когда удалил его.

Истории кортежей являются узлами сразу в нескольких двусвязных списках, по списку на каждый индекс. То есть в истории хранится по паре указателей для каждого индекса.

Порядок следования в списках совпадает с порядком транзакций, то есть для еще незавершенных транзакций он не определен. В самом верху списка, среди изменений, которые сделали еще не завершенные транзакции, их порядок еще может измениться, то есть при коммите транзакций их (возможно) придется переупорядочивать.
Однако в простейшем случае, когда транзакции не передают управление (единственно возможный режим в версии 2.5), они сразу будут находиться в нужном порядке. Это согласуется с принципом «не используешь — не платишь»: дополнительная работа появляется только при использовании yield. Также вверху этих списков, среди незавершенных транзакций, для одной истории кортежа может быть создан целый список транзакций, намеревающихся его удалить.

Таким образом формируется история, которая позволяет с любого места (начиная с любого кортежа) раскручивать историю по каждому индексу. MVCC-менеджер для каждой транзакции и для каждого индекса анализирует эти списки, игнорируя чужие незавершенные операции.
Менеджер конфликтов: основная идея
В общем случае он собирает информацию о чтении всех транзакций и ориентируется на совокупность записей всех транзакций. Именно он должен отправлять их в read view, принимать решение об объявлении какой-то транзакции как невозможной.
Основная идея нового менеджера конфликтов: в истории кортежа хранить также историю чтения этого кортежа различными транзакциями. В новом менеджере сразу собираются потенциальные конфликты, в отличие от vinyl. Там история чтений просто собирается, а все решения принимаются при коммите какой-либо транзакции.
Это отлично вписываются в работу с историей кортежа. И при чтении, и при записи грязного кортежа приходится покопаться в его истории. В этот момент очень легко собрать информацию типа «если транзакция A будет закоммичена, то транзакцию B придется заабортить». При коммите транзакции придется пробежаться по этому списку и расставить соответствующие флаги — минимум накладных расходов. Но приходится делать грязными кортежи при чтении, чтобы в их историю записывать чтения.
Помимо аборта, менеджер конфликтов может перевести какую-нибудь транзакцию в read view, например, чтобы обеспечить repeatable read. Если какая-нибудь транзакция что-нибудь прочитала, а другая заменила это значение и перезаписалась, то первая отправляется в read view, чтобы не видеть наши изменения.
Как происходит отправка в read view:

Красная транзакция читает какое-то значение, синяя его перезаписывает. При коммите синей транзакции просыпается менеджер конфликтов и понимает, что красная транзакция теперь должна существовать до синей, и создает для нее специальный read view. В этому read view красная транзакция по-прежнему получает значение b при последующих чтениях ключа 2.
А вот немного другая ситуация:

Красная транзакция записала два ключа. Синяя понимает, что с точки зрения ключа 2 красная транзакция должна находиться до синей. Она не должна видеть синие изменения. Но с точки зрения ключа 3 мы понимаем, что потом красная транзакция захочет закоммититься. И тогда ей придется попасть в WAL уже после синей.
А мы очень хотим, чтобы порядок сериализации совпадал с порядком записи в WAL. Получается неискоренимый конфликт: красная транзакция должна быть и до, и после синей. Поэтому приходится помечать красную как конфликтную и дальнейшие действия над ней приведут к отмене транзакции.
Всë это позволяет достичь:
- Сериализуемость с обнаружением конфликтов, без блокировок.
- Эффективный, ленивый read view.
- Независимость от типа индекса, как и MVCC.
Но есть и проблемы. Подход, когда история чтения привязывается к кортежу, конечно, во многом хорош. Однако когда при чтении было обнаружено «ничего», такую историю просто некуда записывать, а записывать её надо для обнаружения конфликтов. Помимо этого в индексе типа TREE могут быть диапазонные чтения (от A до B) и чтения по неполным ключам. Для таких случаев приходится изобретать дополнительные индекс-зависимые структуры данных.
Smoke test и пример
Новый режим включается специальной опцией конфига, без неё всё работает по-старому. А как проверить, какой режим сейчас?
В консоли Tarantool мы можем выполнять произвольные команды. Очевидно, что после каждой команды происходит какой-то yield. То есть по нажатию Enter просыпается файбер, выполняет команду и снова засыпает, отдавая управление главному и прочим файберам. Значит выполняя транзакцию по частям в консоли, мы должны увидеть аборт в старом режиме, и корректную работу — в новом.
Режим «по-старому». На мой взгляд, происходит какая-то дичь:
memtx_use_mvcc_engine=false
tarantool> box.begin()
tarantool> s:replace{1, 2}
tarantool> s:replace{2, 1}
tarantool> s:select{}
---
- []
...
tarantool> box.commit()
2020-10-26 11:16:27.149 [21322] main/103/run.lua txn.c:705 E> ER_TRANSACTION_YIELD: Transaction has been aborted by a fiber yield
---
- error: Transaction has been aborted by a fiber yield
…
Режим «по-новому». Совсем другое дело:
memtx_use_mvcc_engine=true
tarantool> box.begin()
tarantool> s:replace{1, 2}
tarantool> s:replace{2, 1}
tarantool> s:select{}
---
- - [1, 2]
- [2, 1]
...
tarantool> box.commit()
---
…
Дальше можно проверить, что до выполнения
box.commit() никакие другие транзакции не видят этих изменений. Конечно, это и много другое проверяется в наших тестах.Дальнейшие планы
Сейчас начинать и заканчивать транзакции можно только внутри хранимых процедур. На ближайшее время запланировано создание новых команд сетевого протокола
begin и commit для возможности интерактивных транзакций по сети. Пока что есть понимание, что для этого нужно будет сделать независимые стримы в одном соединении.Хотим сделать cross-engine транзакции, чтобы в одной транзакции можно было бы делать изменения и в memtx, и в vinyl. Вполне возможно, это получится очень легко, но могут быть определенные накладки.
Также у нас широкий простор для оптимизаций. Идей много, они записаны в отдельном тикете и ждут того момента, когда у нас дотянутся до них руки.
А еще мы планируем использовать подобный механизм и накопленный опыт для распределенных транзакций. Там тоже должен быть какой-то менеджер конфликтов, какой-то MVCC. Вполне возможно, что наработки из этой области мы будем использовать в наших дальнейших разработках по кластерам.
