

Tarantool — это платформа для in-memory вычислений, где упор всегда делался на горизонтальную масштабируемость. То есть при нехватке мощности одного инстанса нужно добавить больше инстансов, а не больше ресурсов одному инстансу.
С самого начала из средств горизонтального масштабирования в Tarantool была только встроенная асинхронная репликация, которой для большинства задач хватало. При этом у нас не было синхронной репликации, заменить которую в некоторых задачах нельзя никаким внешним модулем.
Задача реализации синхронной репликации стояла перед командой разработчиков Tarantool долгие годы, к ней было совершено несколько подходов. И вот теперь в релизе 2.6 Tarantool обзавёлся синхронной репликацией и выборами лидера на базе алгоритма Raft.
В статье описан долгий путь к схеме алгоритма и его реализации. Статья довольно длинная, но все её части важны и складываются в единую историю. Однако если нет времени на 60 000 знаков, то вот краткое содержание разделов. Можно пропустить те, которые уже точно знакомы.
- Репликация. Введение в тему, закрепление всех важных моментов.
- История разработки синхронной репликации в Tarantool. Прежде чем переходить к технической части, я расскажу о том, как до этой технической части дошли. Путь был длиной в 5 лет, много ошибок и уроков.
- Raft: репликация и выборы лидера. Понять синхронную репликацию в Tarantool без знания этого протокола нельзя. Акцент сделан на репликации, выборы описаны кратко.
- Асинхронная репликация. В Tarantool до недавнего времени была реализована только асинхронная репликация. Синхронная основана на ней, так что для полного погружения надо сначала разобраться с асинхронной.
- Синхронная репликация. В этом разделе алгоритм и его реализация описаны применительно к жизненному циклу транзакции. Раскрываются отличия от алгоритма Raft. Демонстрируется интерфейс для работы с синхронной репликацией в Tarantool.
1. Репликация
Репликация в базах данных — это технология, которая позволяет поддерживать актуальную копию базы данных на нескольких узлах. Группу таких узлов принято называть «репликационная группа», или менее формально — репликасет. Обычно в группе выделяется один главный узел, который занимается обновлением/удалением/вставкой данных, выполнением транзакций. Главный узел принято называть мастером. Остальные узлы зовутся репликами. Ещё бывает «мастер-мастер» репликация, когда все узлы репликасета способны изменять данные.

Репликация призвана решить сразу несколько задач. Одна из наиболее частых и очевидных — наличие резервной копии данных. Она должна быть готова принимать клиентские запросы, если мастер откажет. Ещё одно из популярных применений — распределение нагрузки. При наличии нескольких инстансов БД клиентские запросы между ними можно балансировать. Это нужно, если для одного узла нагрузка слишком велика, или на мастере хочется иметь наименьшую задержку на обновление/вставку/удаление записей (латенси, latency), а чтения не страшно распределить по репликам.
Типично выделяется два типа репликации — асинхронная и синхронная.
Асинхронная репликация
Асинхронная репликация — это когда коммит транзакции на мастере не дожидается отправки этой транзакции на реплики. То есть достаточно её успешного применения к данным и попадания в журнал базы данных на диске, чтобы клиентский запрос уже получил положительный ответ.
Цикл жизни асинхронной транзакции сводится к следующим шагам:
- создать транзакцию;
- поменять какие-то данные;
- записать в журнал;
- ответить клиенту, что транзакция завершена.
Параллельно с этим после записи в журнал транзакция поедет на реплики и там проживёт тот же цикл.

Такой репликации хватает для большинства задач. Но здесь есть не всегда очевидная проблема, которая для некоторых областей разработки делает асинхронную репликацию либо вовсе не применимой, либо её нужно обкладывать костылями, чтобы получить желаемый результат. А именно: мастер-узел может отказать между шагами 3 и 5 на картинке. То есть после того, как клиент получил подтверждение применения транзакции, но до того, как эта транзакция заедет на реплики.
В результате, если новым мастером будет выбрана одна из оставшихся реплик, транзакция с точки зрения клиента окажется просто потеряна. Сначала клиент получил ответ, что она применена, а в следующий момент она испарилась без следа.
Иногда это нормально: если хранятся некритичные данные вроде некой аналитики, журналов. Но если хранятся банковские транзакции, или сохранённые игры, или игровой инвентарь, купленный за деньги, или ещё какие-либо архиважные данные, то это недопустимо.
Решать эту проблему можно по-разному. Есть способы остаться на асинхронной репликации и действовать в зависимости от ситуации. В случае Tarantool можно написать логику своего приложения таким образом, чтобы после успешного коммита не торопиться отвечать клиенту, а подождать явно, пока реплики транзакцию подхватят. API Tarantool такое делать позволяет после определённых приседаний. Но подходит такое решение не всегда. Дело в том, что даже если запрос-автор транзакции будет ждать её репликации, остальные запросы к БД уже будут видеть изменения этой транзакции, и исходная проблема может повториться. Это называется «грязные чтения» (dirty reads).
Client 1 | Client 2
-------------------------------+--------------------------------
box.space.money:update( v
{uid}, {{'+', 'sum', 50}} |
) v
-------------------------------+--------------------------------
v -- Видит незакоммиченные
| -- данные!!!
v box.space.money:get({uid})
-------------------------------+--------------------------------
wait_replication(timeout) |
v
В примере два клиента работают с базой. Один клиент добавляет себе 50 денег и начинает ждать репликации. Второй клиент уже видит данные транзакции до её репликации и логического «коммита». Этим вторым клиентом может быть сотрудник банка или автоматика, делающая зачисление на счёт. Теперь если транзакция первого клиента не реплицируется в течение таймаута и будет «откачена», то второй клиент видел несуществующие данные и мог принять на их основании неверные решения.
Это означает, что ручное ожидание репликации — довольно специфичный хак, который использовать трудно и не всегда возможно.
Синхронная репликация
Самое правильное при таких требованиях — использовать синхронную репликацию. Тогда транзакция не завершится успехом, пока не будет реплицирована на некоторое количество реплик.
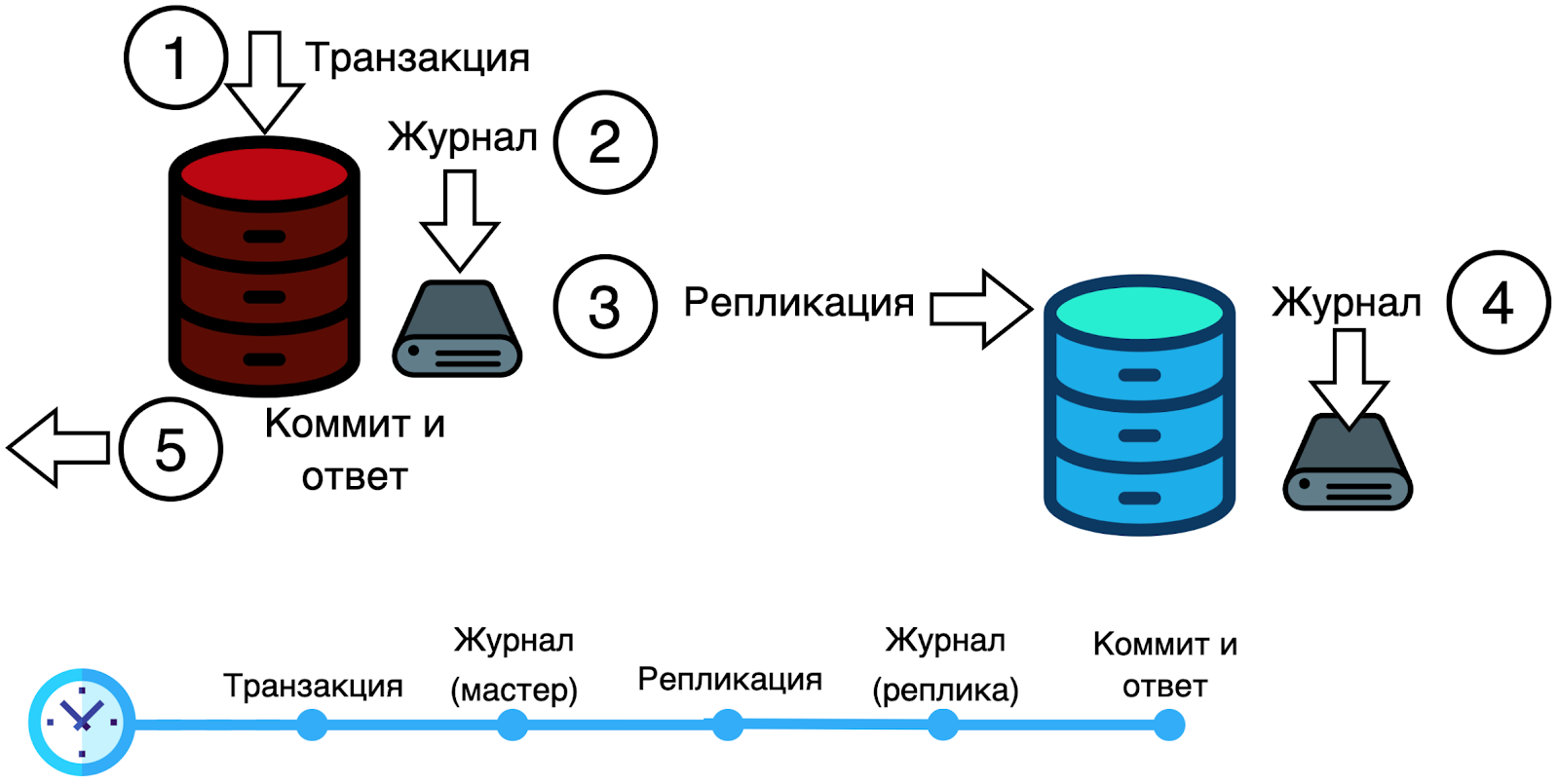
Стоит обратить внимание, что шаг «коммит и ответ» выполняется в конце, уже после репликации.
Количество реплик, нужное для коммита транзакции, называется кворум. Обычно это 50 % размера репликасета + 1. То есть в случае двух узлов синхронная транзакция должна попасть на два узла, в случае трёх — тоже на два, в случае четырёх — на 3 узла, 5 — на 3, и так далее.
50 % + 1 берётся для того, чтобы кластер мог пережить потерю половины узлов и всё равно не потерять данные. Это просто хороший уровень надёжности. Ещё одна причина: обычно в алгоритмах синхронной репликации предусмотрены выборы лидера, в которых для успешных выборов за нового лидера должно проголосовать более половины узлов. Любой кворум из половины или меньше узлов мог бы привести к выборам более чем одного лидера. Отсюда и выходит 50 % + 1 как минимум. Один кворум на любые решения — коммиты транзакций и выборы.
Почему просто не использовать синхронную репликацию всегда, раз она лучше асинхронной? Потому что за синхронность нужно платить.
- Расплата будет в скорости. Синхронная репликация медленнее, так как существенно возрастает задержка от начала коммита до его конца. Это происходит из-за участия сети и журналов других узлов: транзакцию надо на них послать, там записать и ответ получить. Сам факт присутствия сети увеличивает задержку потенциально до порядка миллисекунд.
- В синхронной репликации сложнее поддерживать доступность репликасета на запись. Ведь при асинхронной репликации правило простое: если мастер есть, то данные можно менять. Неважно, есть ли живые реплики и сколько их. При синхронной, даже если мастер доступен, он может быть не способен применять новые транзакции, если подключенных реплик слишком мало — какие-то могли отказать. Тогда он не может собирать кворум на новые транзакции.
- Синхронную репликацию сложнее конфигурировать и программировать. Нужно аккуратно подбирать значение кворума (если каноническое 50 % + 1 недостаточно), таймаут на коммит транзакции, готовить мониторинг. В коде приложения придётся быть готовым к различным ошибкам, связанным с сетью.
- Синхронная репликация не предусматривает «мастер-мастер» репликацию. Это ограничение алгоритма, который используется в Tarantool в данный момент.
Но в обмен на эти сложности можно получить гораздо более высокие гарантии сохранности данных.
К счастью, придумывать алгоритм синхронной репликации с нуля не нужно. Есть уже созданные алгоритмы, принятые практически как стандарт. Сегодня самым популярным является Raft. Он обладает рядом особенностей, которые его популярность оправдывают:
- Гарантия сохранности данных, пока живо больше половины кластера.
- Алгоритм очень простой. Для его понимания не нужно быть разработчиком баз данных.
- Алгоритм не новый, существует уже некоторое время, опробован и проверен, в том числе его корректность доказана формально.
- Включает в себя алгоритм выбора лидера.
Raft был реализован в Tarantool в двух частях — синхронная репликация и выборы лидера. Обе чуть изменены, чтобы адаптироваться к существующим системам Tarantool (формат журнала, архитектура в целом). Про Raft и реализацию его синхронной репликации пойдёт речь в данной статье далее. Выборы лидера — тема отдельной статьи.
2. История разработки синхронной репликации в Tarantool
Прежде чем переходить к технической части, я расскажу о том, как до этой технической части дошли. Путь был длиной в 5 лет, за которые почти вся команда Tarantool, кроме меня, сменилась новыми людьми. А один разработчик даже успел уйти и вернуться обратно в нашу дружную команду.
Задача разработки синхронной репликации существует в Tarantool с 2015 года, сколько я помню себя работающим здесь. Синхронная репликация изначально не рассматривалась как что-то срочно необходимое. Всегда находились более важные задачи, или просто не хватало ресурсов. Хотя неизбежность её реализации была ясна.
С развитием Tarantool становилось всё более очевидно, что без синхронной репликации некоторые области применения для этой СУБД закрыты. Например, определённые задачи в банках. Необходимость обходить отсутствие синхронной репликации в коде приложения существенно повышает порог входа, увеличивает вероятность ошибки и стоимость разработки.
Сначала на задачу был поставлен один человек, сделать её сразу и с наскоку. Но сложность оказалась слишком высока, а разработчик в итоге покинул команду. Было решено разбить синхронную репликацию на несколько задач поменьше, которые можно делать параллельно:
Реализация SWIM — протокола построения кластера и обнаружения отказов. Дело в том, что в Raft выделяются два компонента, друг от друга почти не зависящие — синхронная репликация при известном лидере и выборы нового лидера. Чтобы выбрать нового лидера, нужен способ обнаружить отказ старого. Это можно выделить в третью часть Raft, которую мог бы отлично решить протокол SWIM.
Также он мог бы быть использован как транспорт сообщений Raft, например, для голосования за нового лидера. Ещё SWIM мог бы быть использован для автоматической сборки кластера, чтобы узлы сами друг друга обнаруживали и подключались каждый к каждому, как того требует Raft.
Реализация прокси-модуля для автоматического перенаправления запросов с реплик на лидера. В Raft говорится, что если запрос был послан на реплику, то реплика должна перенаправить его лидеру сама. План был таков, что на каждом инстансе пользователь сможет поднять прокси-сервер, который либо принимает запрос на этот инстанс, если это лидер, либо посылает его на лидера. Полностью прозрачно для пользователя.
Ручные выборы лидера —
box.ctl.promote(). Это должна была быть такая функция, которую можно вызвать на инстансе и сделать его лидером, а остальных — репликами. Предполагалось, что в выборах лидера самое сложное — начать их, и что начать можно с того, чтобы запускать выборы вручную.Оптимизации, без которых Raft якобы не смог бы работать. Первой была оптимизация по уменьшению избыточного трафика в кластере. Вторая — создание и поддержка кеша части журнала транзакций в памяти, чтобы реплицировать быстрее и эффективнее в плане потребления времени процессора.
Всё это должно было закончиться вводом автоматических выборов лидера, логически завершая Raft.
Список задач был сформирован в 2015, и с тех пор на несколько лет был отложен в долгий ящик. Команда сильно отвлеклась на более приоритетные задачи, такие как дисковый движок vinyl, SQL, шардинг.
Ручные выборы
В 2018 году появились ресурсы, и синхронная репликация снова стала актуальна. В первую очередь попытались реализовать
box.ctl.promote(). Несмотря на кажущуюся простоту, в процессе проектирования и реализации оказалось, что даже при ручном назначении лидера возникают почти все те же проблемы, что и при автоматическом выборе. А именно: остальные узлы должны согласиться с назначением нового лидера (проголосовать), как минимум большинство из них, и старый лидер в случае своего возвращения должен игнорироваться остальными узлами.
Получались выборы практически как в Raft, но автоматически голосование никто не начинает, даже если текущий лидер недоступен. В результате стало очевидно, что смысла делать
box.ctl.promote() в его изначальной задумке нет. Это получалась чуть-чуть урезанная версия целого Raft.Прокси
В том же 2018 году было решено подступиться к реализации модуля проксирования. По плану он должен был работать даже с асинхронной репликацией для роутинга запросов на главный узел.
Модуль был спроектирован и реализован. Но было много вопросов к тому, как правильно делать некоторые технически непростые детали без поломок обратной совместимости, без переусложнения кода и протокола, без необходимости доделывать что-либо в многочисленных коннекторах к Tarantool; а также как сделать интерфейс максимально удобным.
Должен ли это быть отдельный модуль, или надо встроить его в существующие интерфейсы? Должен ли он поставляться «из коробки» или скачиваться отдельно? Как должна или не должна работать авторизация? Должна ли она быть прозрачной, или у прокси-сервера должна быть своя авторизация, со своими пользователями, паролями?
Задача была отложена на неопределённое время, потому что таких вопросов было слишком много. Тем более, в том же году появился модуль vshard, который задачу проксирования успешно решал.
SWIM
Следующая попытка продолжить синхронную репликацию произошла в конце 2018 — начале 2019. Тогда за год был реализован протокол SWIM. Реализация была выполнена в виде встроенного модуля, доступного для использования даже без репликации, для чего угодно, прямо из Lua. На одном инстансе можно было создавать много SWIM-узлов. Планировалось, что у Tarantool будет свой внутренний SWIM-узел специально для Raft-сообщений, обнаружений отказов и автопостроения кластера.
Модуль был успешно реализован и попал в релиз, но с тех пор так и остался неиспользованным для синхронной репликации, поскольку необходимость его внедрения в синхрон оказалась сильно преувеличена. Хотя до сих пор очевидно, что SWIM может упростить в репликации многое, и к этому ещё стоит вернуться.
Оптимизации репликации
В то же время параллельно со SWIM около года велась разработка оптимизаций репликации. Однако в конце оказалось, что заявленные оптимизации не очень-то и нужны, а одна из них после проверки оказалась вредна.
В рамках задачи оптимизаций велась переработка журнала базы данных, его внутреннего устройства и интерфейса, чтобы он стал «синхронным». То есть репликацией до коммита транзакции занимался бы сам журнал, а не транзакционный движок. Такой подход не привёл ни к чему хорошему, так как результат оказался далёк от Raft и его корректность была под сомнением.
Человек, занимавшийся реализацией, покинул команду. Незадолго до него ушёл автор изначального разбиения задач и по совместительству CTO Tarantool. Почти одновременно с этим команду покинул ещё один сильный разработчик, соблазнившись оффером из Google. В итоге команда была обескровлена, а прогресс по синхронной репликации был отброшен практически к нулю.
После смены руководства кардинально изменился подход к планированию и разработке. От прежнего подхода без жёстких дедлайнов по методу «сделать сразу всё от начала до конца, сразу идеально и когда-нибудь» к подходу «составить план со сроками, сделать минимальную рабочую версию и развивать её по четким дедлайнам».
Прогресс пошёл значительно быстрее. В 2020-м, менее чем за год была реализована синхронная репликация. За основу снова взяли протокол Raft. В качестве минимальной рабочей версии оказалось нужно сделать всего две вещи: синхронный журнал и выборы лидера. Вот так сразу, без годов подготовки, без бесчисленных подзадач и переработок существующих систем Tarantool. По крайней мере, для первой версии.
3. Raft: репликация и выборы лидера
Чтобы понять техническую часть, нужно знать протокол Raft, хотя бы его часть про синхронную репликацию. Настоящий раздел бегло обе части описывает, если читатель не хочет ознакамливаться с оригинальной статьёй целиком. Если же алгоритм знаком, то можно раздел пропустить.
Оригинальная статья с полным описанием Raft называется «In Search of an Understandable Consensus Algorithm«. Алгоритм делится на две независимые части: репликация и выборы лидера.
Под лидером подразумевается единственный узел, принимающий запросы. Можно сказать, что лидер в терминологии Raft — это почти то же самое, что мастер в Tarantool.
Первая часть Raft обеспечивает синхронность репликации при известном лидере. Raft объясняет, что для этого должен из себя представлять журнал транзакций, как транзакции идентифицируются, как распространяются, какие гарантии и при каких условиях действуют.
Вторая часть Raft занимается обнаружением отказа лидера и выборами нового.
В классическом Raft все узлы репликасета имеют роль: лидер (leader), реплика (follower) или кандидат (candidate):
- Лидер — это узел, который принимает все запросы на чтение и запись.
- Реплики получают транзакции от лидера и подтверждают их. Все запросы от клиентов реплики перенаправляют на лидера (даже чтения).
- Кандидатом становится реплика, когда видит, что мастер пропал и надо начать новые выборы.
При нормальной работе кластера (то есть почти всегда) в репликасете ровно один лидер, а все остальные — реплики.
Выборы лидера
Всё время жизни репликасета делится на термы — пронумерованные промежутки времени между разными выборами лидера. Терм обозначается неубывающим числом, хранящимся на всех узлах индивидуально. В каждом терме проходят новые выборы лидера, и либо успешно выбирается один, либо никто не выбирается и начинается новый терм с новыми выборами.
Решение о переходе к следующему терму принимают реплики индивидуально, когда долго ничего не слышно от лидера. Тогда они становятся кандидатами, увеличивают свой терм и начинают голосование. Оно заключается в том, что кандидат голосует за себя и рассылает запрос на голос остальным участникам.

Другие узлы, получив запрос на голос, действуют исходя из своего состояния. Если их терм меньше или такой же, но в этом терме ещё не голосовали, то узел голосует за кандидата.
Кандидат собирает ответы на запрос голоса, и если собирает большинство, то становится лидером, о чём сразу рассылает уведомление. Если же никто большинство не собрал, то спустя случайное время узлы начнут перевыборы. Время рандомизируется на каждом участнике кластера по-своему. За счёт этого минимизируется вероятность того, что все начнут одновременно, проголосуют за себя и никто не выиграет. Если же лидер был успешно выбран, то он способен применять новые транзакции.
Синхронная репликация
Raft описывает процесс репликации как процедуру
AppendEntries, которую лидер вызывает на репликах на каждую транзакцию или пачку транзакций. В терминологии Raft это что-то вроде функции. Она занимается всей логикой применения изменений к базе данных и ответом лидеру. Если большинство реплик не набирается, то лидер должен посылать AppendEntries бесконечно, пока не получится собрать кворум.Но как только кворум на ожидающие транзакции набрался, они коммитятся через ещё одну запись в журнал. При этом не происходит ожидания остальных реплик, как и синхронной рассылки самого факта коммита. Иначе бы получилась бесконечная последовательность кворумов и коммитов.

На реплики, не попавшие в кворум сразу, транзакция и факт её коммита доставляются асинхронно.
Транзакции при этом друг друга не блокируют: запись новых транзакций в журнал и их репликация не требуют того, чтобы все более старые транзакции уже были закоммичены. За счёт этого, в том числе, в Raft транзакции могут рассылаться и собирать кворум сразу пачками. Но несколько усложняется структура журнала.

Журнал в Raft устроен как последовательность записей вида «key = value». Каждая запись содержит саму модификацию данных и метаданные — индекс в журнале и терм, когда запись была создана на лидере.
В журнале лидера поддерживается два «курсора»: конец журнала и последняя закоммиченная транзакция. Журналы реплик же являются префиксами журнала лидера. Лидер по мере сборки подтверждений от реплик пишет коммиты в журнал и продвигает индекс последней завершённой транзакции.
В процессе работы Raft поддерживает два свойства:
- Если две записи в журналах двух узлов имеют одинаковые индекс и терм, то и команда в них одна и та же. Та, которая «key = value».
- Если две записи в журналах двух узлов имеют одинаковые индекс и терм, то их журналы полностью идентичны во всём, вплоть до этой записи.
Первое следует из того, что в каждом терме новые изменения генерируются на единственном лидере. Они содержат одинаковые команды и термы, распространяемые на все реплики. Ещё индекс всегда возрастает, и записи в журнале никогда не переупорядочиваются.
Второе следует из проверки, встроенной в
AppendEntries. Когда лидер этот запрос рассылает, он включает туда не только новые изменения, но и терм + индекс последней записи журнала лидера. Реплика, получив AppendEntries, проверяет, что если терм и индекс последней записи лидера такие же, как в её локальном журнале, то можно применять новые изменения. Они точно следуют друг за другом. Иначе реплика не синхронизирована — не хватает куска журнала с лидера, и даже могут быть транзакции не с лидера! Не синхронизированные реплики, согласно Raft, должны отрезать у себя голову журнала такой длины, чтоб остаток журнала стал префиксом журнала лидера, и скачать с лидера правильную голову журнала.Здесь стоит сделать лирическое отступление и отметить, что на практике отрезание головы журнала не всегда возможно. Ведь данные хранятся не только в журнале! Например, это может быть B-дерево в SQLite в отдельном файле, или LSM-дерево, как в Tarantool в движке vinyl. То есть только отрезание головы журнала не удалит данные, ждущие коммита от лидера, если они попадают в хранилище сразу. Для такого журнал, как минимум, должен быть undo. То есть из каждой записи журнала можно вычислить, как сделать обратную запись, «откатив» изменения. Undo-журнал может занимать много места. В Tarantool же используется redo-журнал, то есть можно его проигрывать с начала, но откатывать с конца нельзя.
Может быть не очевидно, как именно реплики де-синхронизируются с лидером. Такое происходит, когда узлы неактивны. Недолго, или даже в течение целых термов. Далее пара примеров.
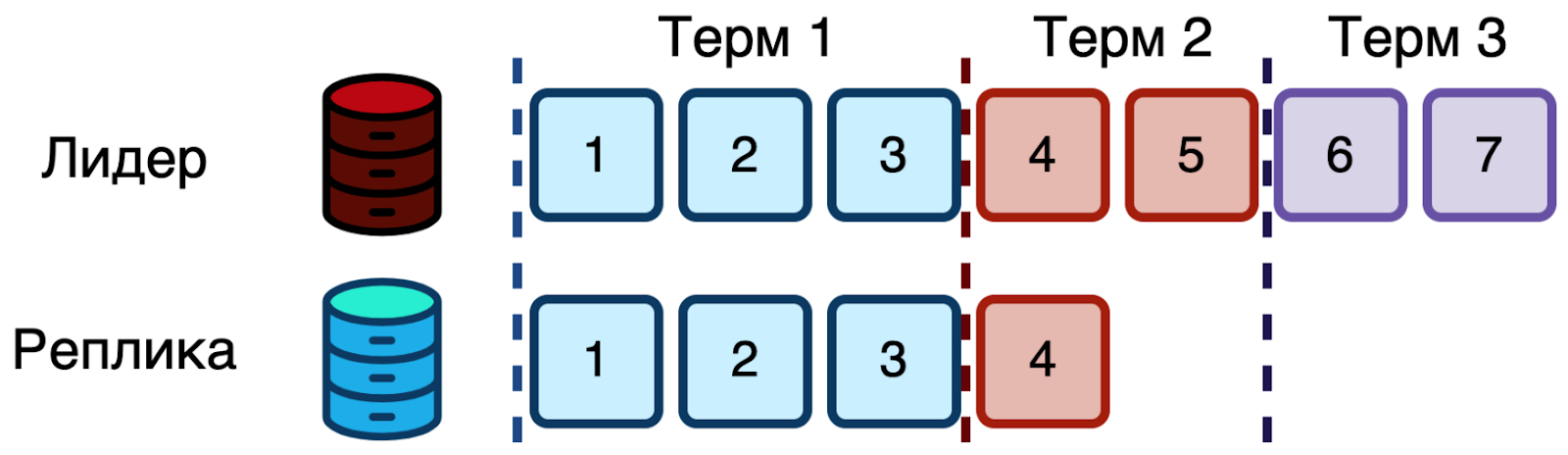
На реплике просто может не быть куска журнала и целого терма. Например, реплика была выключена, проспала терм, проснулась. Пока она была неактивна, лидер жил и делал изменения. Реплика просыпается, а журнал сильно отстал — надо догонять.

На реплике журнал может быть длиннее и даже иметь термы новее, чем в журнале лидера. Хотя текущий терм лидера всё равно будет больше, даже если он ещё ничего не записал (иначе бы он не избрался). Такое может произойти, если реплика была лидером в терме 3 и успела записать две записи, но кворум на них не собрала. Потом был выбран новый лидер в терме 4, и он успел записать две другие записи. Но на них тоже кворум не собрал, а только реплицировал на лидера терма 3. А потом выбрался текущий лидер в терме 5.
В Raft истина всегда за лидером, а потому реплики с плохим журналом должны отрезать от него часть, чтобы стал префиксом лидера. Это полностью валидно и не ведёт к потере данных, так как такое может происходить только с изменениями, не собравшими кворум, а значит не закоммиченными и не отданными пользователю как успешные. Если изменение собрало кворум, то при выборах нового лидера будет выбран один из узлов этого кворума. Если более половины кластера живо. Но это уже отдельная задача для модуля выборов лидера.
Это краткое изложение сути Raft с упором на синхронную репликацию. Алгоритм достаточно несложный по сравнению с аналогами вроде Paxos. Для понимания данной статьи изложения выше хватит.
4. Асинхронная репликация
В Tarantool до недавнего времени была реализована только асинхронная репликация. Синхронная основана на ней, так что для полного понимания надо сначала разобраться с асинхронной.
В Tarantool есть три основных потока выполнения и по одному потоку на каждую подключенную реплику:
- транзакционный поток («TX»);
- сетевой поток («IProto»);
- журнальный поток («WAL»);
- репликационный поток («Relay»).
Транзакционный поток — TX
Это главный поток Tarantool. TX — transaction. В нём выполняются все пользовательские запросы. Поэтому Tarantool часто называют однопоточным.
Поток работает в режиме кооперативной многозадачности при помощи легковесных потоков — корутин (coroutine), написанных на С и ассемблере. В Tarantool они называются файберами (fiber).
Файберов могут быть тысячи, а настоящий поток с точки зрения операционной системы один. Поэтому при наличии, в некотором смысле, параллельности здесь полностью отсутствуют мьютексы, условные переменные, спинлоки и все прочие примитивы синхронизации потоков. Остается больше времени на выполнение реальной работы с данными вместо скачек с блокировками. Ещё это очень сильно упрощает разработку. Как команде Tarantool, так и пользователям.
Пользователям полностью доступно создание новых файберов. Запросы пользователей из сети запускаются в отдельных файберах автоматически, после чего каждый запрос может порождать новые файберы. Сам Tarantool тоже внутри активно их использует для служебных задач, в том числе для репликации.
Сетевой поток — IProto
Это поток, задачи которого — чтение и запись данных в сеть и из сети, декодирование сообщений по протоколу Tarantool под названием IProto. Это значительно разгружает TX-поток от довольно тяжелой задачи ввода-вывода сети. Пользователю этот поток недоступен никак, но и делать ему в нём всё равно нечего.
Однако существует запрос от сообщества на возможность создавать свои потоки и запускать в них собственные серверы, например, по протоколу HTTPS. Забегая вперёд, скажу, что в эту сторону начались работы.
Журнальный поток — WAL
Поток, задача которого — запись транзакций в журнал WAL (Write Ahead Log). В такой журнал транзакции записываются до того, как они применяются к структурам базы данных и становятся видимыми всем пользователям. Поэтому Write Ahead — «пиши наперёд».
Если произойдёт отказ узла, то после перезапуска он сможет прочитать журнал и проиграть сохранённую транзакцию заново. Если бы транзакция сначала применялась, а потом писалась бы в журнал, то в случае перезапуска узла между этими действиями транзакция не восстановилась бы.
Журнал в Tarantool — redo. Его можно проигрывать с начала и заново применять транзакции. Это и происходит при перезапуске узла. При этом проигрывание возможно только с начала до конца. Нельзя откатывать транзакции, проходя в обратную сторону. Для компактности транзакции в redo-журнале не содержат информации, необходимой для их отката.
Сила Tarantool отчасти в том, что он всё старается делать большими пачками. Особенно это касается журнала. Когда в основном потоке много-много транзакций выполняют коммиты в разных файберах, они объединяются в одну большую пачку коммитов. Она отправляется в журнальный поток и там сбрасывается на диск за одну операцию записи.
При этом пока WAL-поток пишет, TX-поток уже принимает новые транзакции и готовит следующую пачку транзакций. Так Tarantool экономит на системных вызовах. Пользователю этот поток недоступен никак. В схеме асинхронной репликации запись в журнал — это единственное и достаточное условие коммита транзакции.
Репликационный поток — Relay
Помимо трёх главных потоков Tarantool создает потоки репликации. Они есть только при наличии репликации и называются relay-потоками.
По одному relay-потоку создаётся на каждую подключённую реплику. Relay-поток получает от реплики запрос на получение всех транзакций, начиная с определённого момента. Он исполняет этот запрос в течение жизни репликации, постоянно отслеживая новые транзакции, попавшие в журнал, и посылая их на реплику. Это репликация на другой узел.
Для репликации с другого узла, а не на другой узел, Tarantool создаёт в TX-потоке файбер под названием applier — «применяющий» файбер. К этому файберу подключается relay на исходном инстансе. То есть relay и applier — это два конца одного соединения, в котором данные плывут в одном направлении: от relay к applier. Метаданные (например, подтверждения получения) посылаются в обе стороны.
Например, есть узел 1 с конфигурацией
box.cfg{listen = 3313, replication = {«localhost:3314»}}, и узел 2 с конфигурацией box.cfg{listen = 3314}. Тогда на обоих узлах будут TX-, WAL-, IProto-потоки. На узле 1 в TX-потоке будет жить applier-файбер, который скачивает транзакции с узла 2. На узле 2 будет relay-поток, который отправляет транзакции в applier узла 1.
Relay сделаны отдельными потоками, так как занимаются тяжёлой задачей: чтением диска и отправкой записей журнала в сеть. Чтение диска здесь самая долгая операция.
Идентификация транзакций
Чтобы упорядочивать транзакции в репликации, отсеивать дубликаты транзакций при избыточных соединениях в репликасете, и чтобы договариваться о том, кто, кому, что и с какого момента отправляет, транзакции особым образом идентифицируются.
Идентификация записей в журнале происходит по двум числам: replica ID и LSN. Первое — это уникальный ID узла, который создал транзакцию. Второе число — LSN, Log Sequence Number, идентификатор записи. Это число постоянно возрастает внутри одного replica ID, и не имеет смысла при сравнении с LSN под другими replica ID.
Такая парная идентификация служит для поддержки «мастер-мастер» репликации, когда много инстансов могут генерировать транзакции. Для их различия они идентифицируются по ID узла-автора, а для упорядочивания — по LSN. Разделение по replica ID позволяет не заботиться о генерировании уникальных и упорядоченных LSN на весь репликасет.
Всего реплик может быть 31, и ID нумеруются от 1 до 31. То есть журнал в Tarantool в общем случае — это сериализованная версия 31-го журнала. Если собрать все транзакции со всеми replica ID на узле, то получается массив из максимум 31-го числа, где индекс — это ID узла, а значение — последний примененный LSN от этого узла. Такой массив называется vclock — vector clock, векторные часы. Vclock — это точный снимок состояния всего кластера. Обмениваясь vclock, инстансы сообщают друг другу, кто на сколько отстаёт, кому какие изменения надо дослать, и фильтруют дубликаты.
Есть ещё 32-я часть vclock под номером 0, которая отвечает за локальные транзакции и не связана с репликацией.
Реплицированные транзакции на репликах применяются ровно так же, как и на узле-авторе. С тем же replica ID и LSN. А потому продвигают ту же часть vclock реплики, что и на узле-авторе. Так автор транзакций может понять, надо ли посылать их ещё раз, если реплика переподключается, и сообщает свой полный vclock.
Далее следует пример обновления и обмена vclock на трёх узлах. Допустим, узлы имеют replica ID 1, 2 и 3 соответственно. Их LSN изначально равны 0.
Узел 1: [0, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
Пусть узел 1 выполнил 5 транзакций и продвинул свой LSN на 5.
Узел 1: [5, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
Теперь происходит репликация этих транзакций на узлы 2 и 3. Узел 1 будет посылать их через два relay-потока. Транзакции содержат в себе
{replica ID = 1}, и потому будут применены к первой части vclock на других узлах.Узел 1: [5, 0, 0]
Узел 2: [5, 0, 0]
Узел 3: [5, 0, 0]
Пусть теперь узел 2 сделал 6 транзакций, а узел 3 сделал 9 транзакций. Тогда до репликации vclock будут выглядеть так:
Узел 1: [5, 0, 0]
Узел 2: [5, 6, 0]
Узел 3: [5, 0, 9]
А после — так:
Узел 1: [5, 6, 9]
Узел 2: [5, 6, 9]
Узел 3: [5, 6, 9]
Общая схема
Схема асинхронной репликации в такой архитектуре:
- Транзакция создаётся в TX-потоке, пользователь начинает её коммит и его файбер засыпает.
- Транзакция отправляется в WAL-поток для записи в журнал, записывается, в TX-поток уходит положительный ответ.
- TX-поток будит файбер пользователя, пользователь видит успешный коммит.
- Просыпается relay-поток, читает эту транзакцию из журнала и посылает её в сеть на реплику.
- На реплике её принимает applier-файбер, коммитит её.
- Транзакция отправляется в WAL-поток реплики, записывается в её журнал, в TX-поток уходит положительный ответ.
- Applier-файбер посылает ответ со своим новым vclock, что всё нормально применилось.
Пользователь к последнему шагу уже давно ушёл. Если выключить Tarantool из розетки до того, как транзакция будет выслана на реплики (после конца шага 3, до конца шага 4) и больше не включать, то эта транзакция уже никуда не доедет и будет потеряна. Конечно, если узел включится снова, то он будет продолжать пытаться отправить транзакцию на реплики, но на сервере мог сгореть диск, и тогда уже ничего не поделать.
В такой архитектуре синхронности можно достигнуть, если транзакция не будет завершена успехом, пока не будет отправлена на нужное число реплик.
5. Синхронная репликация
Прежде чем приступать к реализации Raft, было решено зафиксировать несколько правил, которых было обязательно придерживаться в процессе разработки:
- Если синхронная репликация не используется, то протокол репликации и формат журнала не должны быть изменены никак, полная обратная совместимость. Это позволит обновить существующие кластеры на новый Tarantool и уже потом включить синхронность, по необходимости.
- Если синхронность используется, нельзя менять формат существующих записей журнала, снова из целей обратной совместимости. Можно только добавлять новые типы записей. Или добавлять новые опциональные поля в существующие типы записей. То же самое про сообщения в репликационных каналах.
- Нельзя существенно изменить архитектуру Tarantool. Иначе это приведет к изначальной проблеме, когда задача был раздута и растянута на годы. То есть надо оставить основные потоки Tarantool делать то, что они делали, и сохранить их связность в текущем виде. TX-поток должен управлять транзакциями, WAL должен остаться тривиальной системой записи на диск, IProto остается простейшим интерфейсом к клиентам из сети, и relay-потоки должны только читать журнал и посылать транзакции на реплики. Любые последующие оптимизации и перераспределения обязанностей систем должны быть выполнены отдельно, не являться блокировщиками.
Правила достаточно просты, но их явная формулировка была полезна. Это позволило отметать некоторые нереалистичные идеи.
Проще всего будет понять, как синхронная репликация сделана практически поверх асинхронной, на рассмотрении этапов жизни синхронной транзакции:
- создание;
- начало коммита;
- ожидание подтверждений;
- сборка кворума;
- коммит или отмена транзакции.
По мере прохождения этапов будут следовать объяснения того, как и что работает, что отличается от асинхронной репликации. В процессе описания и в конце разобраны отличия от Raft.
Создание транзакции
Синхронность в Tarantool — это свойство не всей БД. Это свойство каждой транзакции по отдельности. Это значит, что пользователи сами выбирают, для каких данных им синхронность нужна, а для каких — не особо.
Такой подход практически никак не усложнил реализацию и не влияет на алгоритм обработки синхронных транзакций. Но предоставляет существенную гибкость для пользователей. Можно просто не платить за синхронность тех данных, которым она не требуется. Особенно это удобно, если синхронность нужна для небольшого количества данных, которые обновляются редко.
Синхронными являются те транзакции, которые затрагивают хотя бы один синхронный спейс. Спейс — это аналог SQL-таблицы в Tarantool. При создании можно указать опцию
is_sync, и все транзакции над этим спейсом будут синхронными. Даже если транзакция меняет обычные спейсы, но меняет ещё и хотя бы один синхронный спейс, она вся станет синхронной.Как это выглядит в коде:
Включить синхронность на существующем спейсе:
box.space[name]:alter({is_sync = true})
Включить синхронность на новом спейсе:
box.schema.create_space(name, {is_sync = true})
Синхронная транзакция на одном спейсе:
sync = box.schema.create_space(
‘stest’, {is_sync = true}
):create_index(‘pk’)
-- Транзакция из одного выражения,
-- синхронная.
sync:replace{1}
-- Транзакция из двух выражений, тоже
-- синхронная.
box.begin()
sync:replace{2}
sync:replace{3}
box.commit()
Синхронная транзакция на двух спейсах, один из которых — не синхронный:
async = box.schema.create_space(
‘atest’, {is_sync = false}
):create_index(‘pk’)
-- Транзакция над двумя спейсами, один
-- из них — синхронный, а значит вся
-- транзакция — синхронная.
box.begin()
sync:replace{5}
async:replace{6}
box.commit()
С момента создания и до начала коммита транзакция ведёт себя неотличимо от асинхронной.
Начало коммита транзакции
Транзакция, независимо от того, синхронная она или нет, в первую очередь должна попасть в журнал. В случае асинхронных успешная запись в журнал = коммит. Зачем делать это для синхронных, если ещё не собраны подтверждения от реплик?
Пример — пусть синхронная транзакция была создана, передана на реплики, они её записали в свои журналы, и потом лидер был перезапущен. После перезапуска на нём этой транзакции нет, так как она не успела попасть в журнал. А это ровно обратная проблема от той, что нужно решить. При асинхронной репликации транзакция может отсутствовать на репликах. При подобной схеме синхронной репликации она могла бы отсутствовать на лидере, но быть на репликах.
Чтобы транзакция не была потеряна при перезапуске инстанса, но и не была завершена до отправки на нужное число реплик, коммит нужно делить на две части. Это запись в журнал самой транзакции с её данными, и отдельно запись в журнал специального маркера COMMIT после того, как кворум собран. Это очень напоминает алгоритм двухфазного коммита. Если репликация не сработала за разумное время, то по таймауту надо писать маркер ROLLBACK.
На самом деле Raft это и подразумевает. Просто он не декларирует, как именно это сохранять в журнал, в каком формате. Столкновение с этими деталями происходит уже в процессе проектирования применительно к конкретной БД.
Кроме того, в Raft отсутствует понятие ROLLBACK как такового. Транзакции на лидере будут ждать вечно, пока не собран кворум. В реальном мире бесконечные ожидания — редко хорошая идея. На репликах Raft подразумевает подрезания журнала вместо отката, что в реальности тоже может не работать, как было замечено в одном из разделов выше.
В Tarantool в начале коммита синхронная транзакция попадает в журнал, но ещё не коммитится — её изменения не видны. В конце она должна быть завершена отдельной записью COMMIT или ROLLBACK. На COMMIT её изменения становятся видны.
Ожидание подтверждений от реплик
После записи в журнал надо дождаться репликации на кворум реплик. Пока подтверждений ещё нет, транзакция должна быть удержана в памяти. В неком месте, куда можно было бы эти подтверждения доставлять и считать, у кого уже есть кворум.
В Tarantool это место называется лимб. Это обитель транзакций, судьба которых ещё не решена, где они дожидаются своей участи. Транзакция записывается в журнал, получает LSN и попадает сюда в конец очереди таких же транзакций.
Лимб находится в TX-потоке, куда также стягиваются все подтверждения от реплик из relay-потоков. Такая организация позволяет практически никак не менять существующие подсистемы Tarantool. Всё ядро синхронной репликации, все её действия происходят в новой подсистеме лимб, который взаимодействует с другими подсистемами через их интерфейсы.

Пользователи могут этого не видеть, но внутри Tarantool у подсистем (WAL, репликация, транзакционный движок, и т.д.) есть внутренний API, который стараются не менять и держать подсистемы независимыми друг от друга. Потому очень важно, чтобы синхронная репликация не ломала всю эту изоляцию. Лимб с этим очень помогает.
Сбор кворума
Пока транзакция находится в лимбе, relay-потоки читают её из журнала и высылают на реплики. Реплика получает транзакцию и делает всё тоже самое: пишет её в свой журнал и кладет в свой собственный лимб. Синхронная транзакция или нет, реплика понимает так же, как лидер — смотря на синхронность измененных спейсов.
Отличие тут в том, что реплика своим лимбом не владеет. Лимб на реплике — это как бы безвольная копия лимба лидера, несамостоятельное отражение. Реплика не может сама решать, что делать с транзакциями в лимбе, здесь у них нет таймаутов, и они здесь не собирают подтверждения от других реплик. Это просто хранилище транзакций от лидера. Тут они ждут, что лидер скажет с ними сделать. Поскольку только лидер может принимать решения, что делать с синхронными транзакциями.
После записи в журнал реплика посылает лидеру подтверждение о записи. Подтверждения в Tarantool посылались всегда, для разных подсистем, для мониторинга. И их формат не изменен нисколько.
Подтверждение суть vclock реплики. Он меняется при каждой записи в журнал. Получив это сообщение с vclock реплики, лидер может посмотреть, какой его LSN реплика уже записала в журнал. Например, лидер посылает 3 транзакции на реплику, одной пачкой,
{LSN = 1}, {LSN = 2}, {LSN = 3}. Реплика отвечает {LSN = 3} — это значит, что все транзакции с LSN <= 3 попали в её журнал. То есть они «подтверждены».На лидере подтверждения от реплик читаются в relay-потоке, оттуда попадают в TX-поток и становятся видны в
box.info.replication. Лимб эти уведомления отлавливает и следит, не собрался ли кворум для старейшей ждущей транзакции.Для отслеживания кворума по мере прогрессирования репликации лимб на лидере строит картину того, какая реплика как далеко зашла. Он поддерживает у себя векторные часы, в которых записаны пары
{replica ID, LSN}. Только это не совсем обычный vclock. Первое число — идентификатор реплики, а второе — последний LSN от лидера, применённый на этой реплике.Получается, что лимб хранит множество версий LSN лидера, как он хранится на репликах. Обычный vclock хранит LSN разных инстансов, а тут разные LSN одного инстанса — лидера.
Для любой синхронной транзакции по её LSN лимб может точно сказать, сколько реплик её применило, просто посчитав, сколько частей этих специальных векторных часов >= этого LSN. Это немного отличается от того, какой vclock пользователи могут видеть в
box.info. Но суть очень похожа. В итоге, каждое подтверждение от реплики немного продвигает одну часть этих часов.Далее следует пример, как обновляется vclock лимба на лидере в кластере из трех узлов. Узел 1 — лидер.
Узел 1: [0, 0, 0], лимб: [0, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
Пусть лидер начал коммитить 5 синхронных транзакций. Они попали в его журнал, но ещё не были отправлены на реплики. Тогда vclock будут выглядеть так:
Узел 1: [5, 0, 0], лимб: [5, 0, 0]
Узел 2: [0, 0, 0]
Узел 3: [0, 0, 0]
В vclock лимба продвинулась первая компонента, так как эти 5 транзакций были применены на узле с
replica ID = 1, и совершенно не важно, лидер это или нет. Лидер — тоже участник кворума.Теперь предположим, что первые 3 транзакции были реплицированы на узел 2, а первые 4 — на узел 3. То есть репликация ещё не завершена. Тогда vclock будут выглядеть следующим образом:
Узел 1: [5, 0, 0], лимб: [5, 3, 4]
Узел 2: [3, 0, 0]
Узел 3: [4, 0, 0]
Стоит обратить внимание, как обновился vclock лимба. Он фактически является столбиком в матрице vclock-ов. Так как узел 2 подтвердил LSN 3, в лимбе это отражено как LSN 3 во второй компоненте. Так как узел 3 подтвердил LSN 4, в лимбе это LSN 4 в третьей компоненте. Так, глядя на этот vclock, можно сказать, на какой LSN есть кворум.
Например, здесь на LSN 4 есть кворум — два узла: 1 и 3, так как они этот LSN подтвердили. А на LSN 5 кворума ещё нет — этот LSN есть только на узле 1. Под кворумом подразумевается 50 % + 1, то есть два узла.
Когда лимб видит, что кворум собран хотя бы для первой в очереди транзакции, он начинает действовать.
Коммит транзакции
Заметив, что первая (то есть самая старая) ждущая транзакция получила кворум, лимб просыпается. Он начинает сворачивать очередь с головы, собирая все транзакции друг за другом, у кого собрался кворум. Это легко может быть больше одной транзакции, если они были высланы на реплику пачкой, попали в её журнал пачкой, и пришло подтверждение на них всех сразу.
Транзакции упорядочены по LSN, поэтому в какой-то момент встретится транзакция, у которой кворума ещё нет, и 100 % у следующих транзакций его тоже нет. Либо лимб окажется пуст. Для последней собранной транзакции с максимальным LSN лимб пишет в журнал запись COMMIT. Это также автоматически подтвердит все предыдущие транзакции, поскольку репликация строго последовательна. То есть если транзакция с LSN L собрала кворум, то все транзакции с LSN < L тоже его собрали. Это экономит количество операций записи в журнал и место в нём.
После записи COMMIT все завершённые транзакции отвечаются пользователям как успешные и удаляются из памяти.
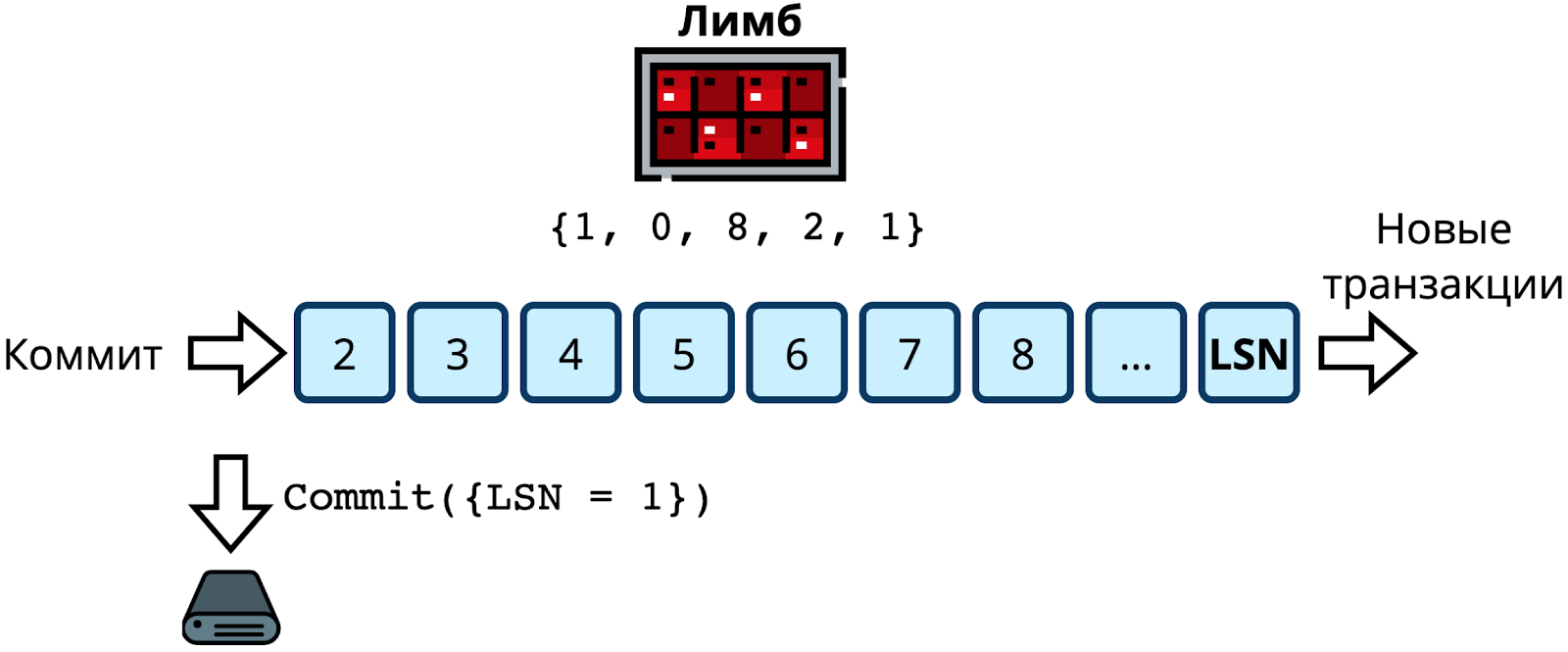
Рассмотрим пример, как лимб сворачивается. Пусть в кластере 5 узлов. Лидер — третий. В лимбе накопились транзакции в ожидании кворума.

Коммитить пока ничего нельзя: самая старая транзакция имеет LSN 1, который подтверждён только лидером. Пусть часть реплик подтвердила несколько LSN-ов.

Теперь LSN 1 подтвержден узлами 1, 3, 4, 5 — то есть это больше половины и кворум собран, можно коммитить. Следующий LSN — 2, на него только два подтверждения, от узлов 3 и 4. Его коммитить пока нельзя, как и все последующие. Значит в журнал надо записать COMMIT LSN 1.
Спустя ещё время получены новые подтверждения от реплик.
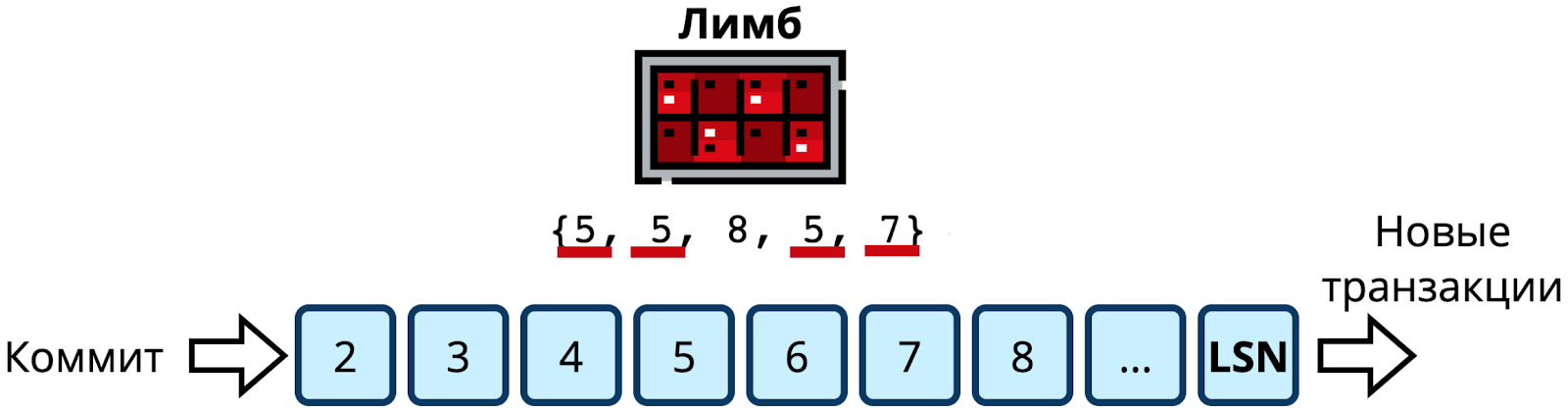
Теперь кворум есть на LSN 5 — его подтвердили все. Так как везде LSN >= 5. На LSN 6 кворума нет, он есть только на двух узлах (3-й и 5-й), а это меньше половины. Значит коммитить можно все LSN <= 5.

Стоит обратить внимание, как одна запись COMMIT завершает сразу 4 транзакции.
Так как COMMIT попадает в журнал, а журнал реплицируется, то эта запись автоматически уедет на реплики и отпустит завершённые транзакции в их лимбах. Ровно таким же образом, но только реплики не будут писать ещё один COMMIT. Они только запишут тот, что пришёл от лидера.
Отмена транзакции
Может быть, что кворум собрать никак не удаётся. Например, недостаточно активных реплик в кластере. Или они не справляются с нагрузкой и слишком медленно отвечают лидеру — тогда очередь в лимбе растёт быстрее, чем разгребается.
Бесконечный рост очереди — типичная проблема архитектуры очередей. Обычно ограничивают их размер или время ожидания в очереди. В случае Tarantool было бы странно вводить ограничение на количество транзакций. Поэтому, чтобы избежать бесконечного роста очереди, на синхронные транзакции накладывается таймаут. Максимальное время на сбор подтверждений от реплик.
Устанавливается таймаут при помощи опции конфигурации. Если транзакция в таймаут не укладывается, то происходит откат её и всех более новых транзакций, так как их изменения могут быть связаны с той, которая откатилась. Ещё это нужно, чтобы сохранить линейность журнала. А так как таймаут — это опция глобальная, то таймаут любой транзакции значит, что все предыдущие транзакции тоже его провалили.
В итоге лимб очищается полностью в случае таймаута старейшей транзакции. Откат происходит через запись в журнал особой записи ROLLBACK. Она отменяет все незавершённые в данный момент транзакции.
Здесь надо очень хорошо осознавать, что и COMMIT, и ROLLBACK сами на себя кворум не собирают. Это привело бы к бесконечной последовательности сбора кворумов, COMMIT на COMMIT, и так далее. Если записан COMMIT, это даёт определенную гарантию, что транзакция есть как минимум на кворуме реплик. И если лидер откажет, то можно сделать новым лидером одну из реплик, участвовавших в последнем кворуме — тогда транзакция не будет потеряна.
Если будет потеряно большинство реплик (больше, чем кворум), то даже коммит транзакции не даёт гарантий.
Если был записан ROLLBACK, то никаких гарантий нет вообще. Транзакция могла попасть на кворум реплик, но лидер не дождался подтверждений, записал ROLLBACK, ответил клиенту отказом, а потом выключился прежде, чем ROLLBACK был отправлен остальным узлам. Новый выбранный лидер увидит кворум на транзакцию, не увидит никакого ROLLBACK и запишет COMMIT. То есть пользователь мог увидеть отказ от старого лидера, а потом всё равно увидеть транзакцию закоммиченной на новом лидере.
К сожалению, в распределённых системах нет никаких 100 % гарантий ни на что. Можно лишь увеличивать шансы на успех, наращивать надёжность, но идеального решения физически невозможно создать.
Смена лидера
Бывает, что лидер становится недоступен по какой-либо причине. Тогда надо выбрать нового лидера. Делать это можно разными способами, включая вторую часть Raft, которая тоже реализована в Tarantool и делает смену автоматически. Можно каким-то другим способом.
Но есть общие рекомендации, которых придерживается встроенная реализация выборов, так и должны использовать остальные. В данном разделе они объяснены, но без конкретного алгоритма выборов.
При выборах надо выбирать новым лидером узел с максимальным LSN относительно старого лидера. Такой узел точно будет содержать последние закоммиченные транзакции старого лидера. То есть он участвовал в последнем кворуме.
Если выбрать лидером не тот узел, то можно потерять данные. Так как узел после становления лидером будет единственным источником правды. Если на нём есть не все закоммиченные данные, то они будут считаться несуществующими, и это состояние будет форсировано на весь кластер.
Рассмотрим пример. Есть 5 узлов. Один из них лидер, и он выполнил транзакцию по обновлению ключа A в значение 20 вместо старого 10. На эту транзакцию он собрал кворум из трёх узлов, закоммитил её, ответил клиенту.
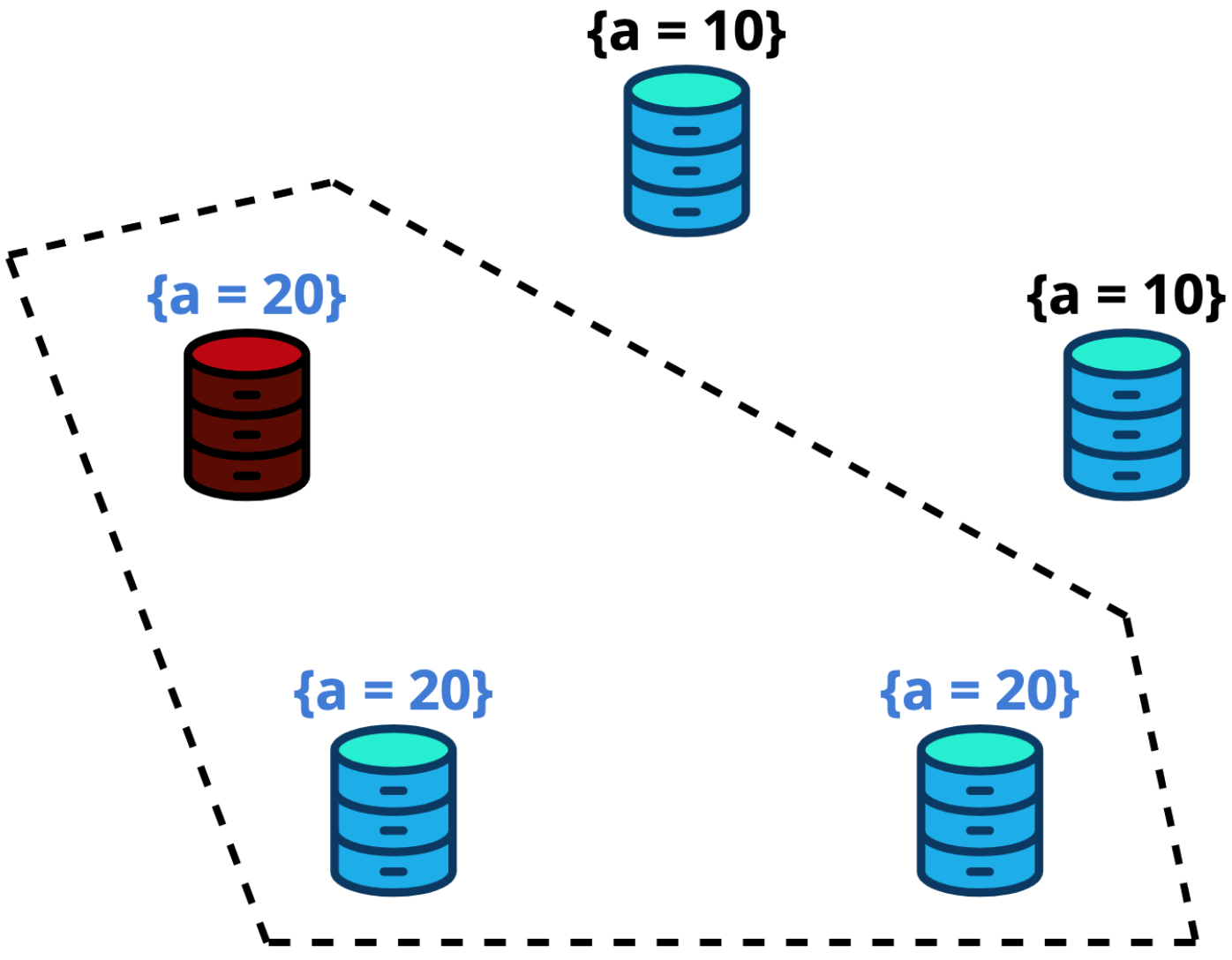
Теперь лидер был уничтожен до того, как успел послать эту транзакцию на другие два узла.

Новым лидером может стать только один из узлов под синим контуром. Если лидером сделать один из узлов под красным контуром, то он форсирует на остальных состояние
{a = 10}, что приведёт к потере транзакции. Несмотря на то, что на неё был собран кворум, произошел коммит и более половины кластера всё ещё цело.Выбрав лидера, надо завершить транзакции, которые находятся в его лимбе после старого лидера, если такие есть. Делается это при помощи функции
box.ctl.clear_synchro_queue(). Она будет ждать, пока на незавершённые транзакции соберётся кворум, запишет COMMIT от имени старого лидера, и лимбы в кластере опустеют, когда этот COMMIT будет доставлен на остальные узлы через репликацию. Новый лидер присваивает пустой лимб себе и становится готов к работе.Достойно упоминания, почему очистка очереди не может ничего откатить —
clear_synchro_queue может только ждать кворум и коммитить. Происходит это из-за того, что в случае смерти старого лидера на новом лидере нет информации о том, не были ли эти ждущие транзакции уже на самом деле завершены на старом лидере, и не увидел ли их успех пользователь.Действительно, старый лидер мог собрать кворум, записать COMMIT, ответить пользователю положительно, а потом отказать вместе с несколькими другими участниками кворума при сохранении более половины кластера. Тогда новый лидер может увидеть, что транзакция прямо сейчас кворума не имеет, но всё равно нельзя полагать, что она не была закоммичена. И нужно ждать.
С другой стороны, даже если транзакция была откачена на старом лидере, её коммит на новом лидере полностью валиден, если ROLLBACK ещё не разошелся по всему кластеру, так как на ROLLBACK и так нет никаких гарантий.
Интерфейс
Функции для работы с синхронной репликацией в Tarantool делятся на две группы: для управления синхронностью и для выборов лидера. Для включения синхронности на спейсе нужно указать опцию
is_sync со значением true при его создании или изменении.Создание:
box.schema.create_space('test', {is_sync = true})
Изменение:
box.space[‘test’]:alter({is_sync = true})
Теперь любая транзакция, меняющая синхронный спейс, становится синхронной. Для настройки параметров синхрона есть глобальные опции:
box.cfg{
replication_synchro_quorum = <count or expression>,
replication_synchro_timeout = <seconds>,
memtx_use_mvcc_engine = <boolean>
}
Replication_synchro_quorum — это количество узлов, которые должны подтвердить транзакцию для её коммита на лидере. Можно задать его как число, а можно как выражение над размером кластера. К примеру, каноническая форма — box.cfg{replication_synchro_quorum = «N/2 + 1»}, которая означает кворум 50 % + 1. Tarantool вместо N подставляет количество узлов, известных лидеру. Кворум можно выбрать и больше канонического, если нужны более сильные гарантии. Но выбирать половину или меньше уже небезопасно.Replication_synchro_timeout — сколько секунд дается транзакции на сборку кворума. Может быть дробным числом, так что точность практически произвольная. По истечении таймаута в журнал пишется ROLLBACK для всех ждущих транзакций, и они откатываются.Memtx_use_mvcc_engine — позволяет избавиться от грязных чтений. Дело в том, что в Tarantool грязные чтения существовали всегда, так как изменения транзакций (асинхронных) становились видны ещё до записи в журнал. Это стало серьёзной проблемой с появлением синхронной репликации, так как вступить в них стало сильно проще. Но просто взять и выключить грязные чтения по умолчанию нельзя, это может сломать совместимость с существующими приложениями. Кроме того, для их выключения требуется выполнение большого количества дополнительной работы в процессе выполнения транзакций, что может повлиять на производительность. Поэтому выключение грязных чтений опционально и контролируется этой опцией. По умолчанию грязные чтения включены!Для выборов лидера можно пользоваться автоматикой, освещённой в отдельной статье. А можно выбирать вручную или своей собственной автоматикой через API Tarantool.
Для поиска нового лидера надо знать, у кого самый большой LSN от старого лидера. Чтобы его найти, следует воспользоваться
box.info.vclock, где указан весь vclock узла, и в нём надо найти компоненту старого лидера. Ещё можно попытаться искать узел, где все части vclock больше или равны всех частей vclock на других узлах, но можно наткнуться на несравнимые vclock.После нахождения кандидата следует позвать на нем
box.ctl.clear_synchro_queue(). Пока эта функция не вернёт успех, лидер не может начать делать новые транзакции.Отличия от Raft
Идентификация транзакций
Главное отличие от Raft — идентификация транзакций. Происходит отличие из формата журнала. Дело в том, что в Raft журнал един. В нём нет векторности. Записи журнала Raft имеют формат вида
{{key = value}, log_index, term}. В терминологии Tarantool это изменения транзакции и её LSN. Tarantool не хранит термы в каждой записи, и в нём нет единой последовательности log_index — нужно хранить replica ID. В Tarantool расчёт LSN идёт индивидуально на каждом узле для транзакций его авторства.Блокирующими проблемами это, на самом деле, не является. Потому как, во-первых, транзакции генерирует только один узел, а значит из всех компонент vclock меняется только один — с ID = replica ID лидера. То есть журнал на самом деле линеен, пока лидер известен и работает. Во-вторых, хранить терм в каждой записи не нужно, и вообще может быть дорого. Достаточно фиксировать в журнале, когда терм был изменён, и в памяти держать текущее значение терма. Это делается модулем выборов лидера отдельно от синхронной репликации.
Сложность возникает, когда лидер меняется. Тогда нужно во всём кластере перевести отсчёт LSN на другую часть vclock, с отличным replica ID. Для этого новый лидер завершает все транзакции старого лидера, захватывает лимб транзакций и начинает генерировать свои собственные транзакции. На репликах произойдёт то же самое: они получат от нового лидера COMMIT и ROLLBACK на транзакции старого лидера, и потом новые транзакции с другим replica ID. Лимбы всего кластера переключаются автоматически, когда их опустошили, и начали давать новые транзакции с другим replica ID.
Это выглядит почти как если бы в кластере был 31 протокол Raft, работающий поочередно.
Нет отката журнала
Что проблемой является — это природа журнала. Согласно Raft, журнал надо уметь откатывать, удалять из него транзакции с конца. Это происходит в Raft, когда выбран новый лидер, но в кластере ещё могли остаться реплики с ушедшим вперёд журналом. Они, например, могли быть недоступны во время выборов, а потом стали доступны и потому не выбрались. Закоммиченные данные они содержать не могут — иначе бы они были на кворуме реплик и на новом лидере. Raft отрезает у них голову журнала, чтобы соблюсти свойство, что у реплик журнал является префиксом журнала лидера.
В Tarantool отката журнала нет, так как он redo, а не undo. Кроме того, архитектурой не предусмотрен откат LSN. Если в кластере появляются такие реплики, то нет выбора кроме как их удалить и подключать как новые, скачать все данные с лидера заново. Это называется rejoin.
Однако в этом направлении ведутся работы, в результате которых откат будет работать без пересоздания реплики.
Заключение
Синхронная репликация в Tarantool доступна с версии 2.5, а автоматические выборы — с версии 2.6. На данный момент эта функциональность находится в бета-версии, то есть ещё не обкатана в реальных системах, а интерфейсы и их поведение ещё могут измениться. И пока существующая реализация полируется, есть планы по её оптимизации и расширению. Оптимизации главным образом технические.
Что касается расширений, то благодаря векторному формату журнала Tarantool есть возможность сделать «мастер-мастер» синхронную репликацию. То есть транзакции могут генерироваться более чем на одном узле одновременно. Это уже помогает в асинхронной репликации, чтобы размазать нагрузку пишущим транзакциям, если они сопряжены со сложными вычислениями. И может также пригодиться в синхронной.
В заключение ещё стоит отметить один из главных выводов, с реализацией не связанный: при проектировании большой задачи переусердствование может серьёзно навредить. Иногда бывает, что проще и эффективнее сделать рабочий прототип нужной функциональности и постепенно развивать его, чем пытаться сделать всё сразу и идеально.
Помимо развития синхронной репликации в будущих релизах Tarantool запланированы некоторые не менее интересные вещи, отчасти связанные с синхроном, на часть из которых уже можно пролить свет.
Транзакции в бинарном протоколе
С момента создания Tarantool в нём не было возможно делать «долгие» транзакции из более чем одного выражения прямо по сети, используя только удалённый коннектор к Tarantool. Для любой операции сложнее, чем один replace/delete/insert/update, требовалось написать код на Lua, который бы делал нужные операции в одной транзакции, и вызывать этот код как функцию.
В данный момент запланирована реализация транзакций прямо в протоколе. Со стороны клиента на Lua это будет выглядеть, например, так:
c = netbox.connect(host)
c:begin()
c.space.test1:replace{100}
c.space.test2:delete({5})
c:commit()
Никакого кода со стороны сервера не потребуется. Так можно будет работать, в том числе, с синхронными транзакциями.
Опции транзакции
Коммит транзакции в Tarantool всегда блокирующий. То есть текущий файбер перестаёт выполнять код, пока коммит не завершён. Это может быть довольно долго, что увеличивает задержку ответа клиенту, даже если ожидание коммита не обязательно. Особенно остро эта проблема встаёт с синхронными транзакциями, коммит которых может занять миллисекунды.
Запланировано расширение интерфейса коммита, чтобы файбер не блокировался. Выглядеть будет, например, вот так:
box.begin()
box.space.test1:replace{100}
box.commit({is_lazy = true})
box.begin()
box.space.test2:replace{200}
box.space.test3:replace{300}
box.commit({is_lazy = true})
Оба
box.commit() вернут управление сразу, а транзакция попадёт в журнал и будет закоммичена в конце итерации цикла событий Tarantool (event loop). Такой подход не только может уменьшить задержку на ответ клиенту, но и лучше использовать ресурсы WAL-потока, так как больше транзакций сможет попасть в одну пачку записи на диск к концу итерации цикла событий.Кроме того, касательно синхронных транзакций иногда может быть удобно сделать синхронным не целый спейс, а только определённые транзакции, даже над обычными спейсами. Для такого запланировано добавлении ещё одной опции в
box.commit() — is_sync. Выглядеть будет так: box.commit({is_sync = true}).Мониторинг
В данный момент нет способа узнать, сколько синхронных транзакций ожидают коммита (находятся в лимбе). Ещё нет способа узнать, каково значение кворума, если пользователь использовал выражение в
replication_synchro_quorum. Например, если было задано «N/2 + 1», то в коде узнать фактическое значение кворума нельзя никаким вменяемым способом (но способ есть).Для устранения этих неизвестностей будет выведена отдельная функция мониторинга —
box.info.synchro.