

В прошлом году в Tarantool была проведена колоссальная работа по реализации синхронной репликации. При этом мы придерживались алгоритма Raft. Вся работа была разделена на два крупных этапа: так называемую кворумную запись, то есть синхронную репликацию, и автоматические выборы лидера.
Синхронная репликация появилась в релизе 2.5.1, а в конце октября в релизе 2.6.1 появилась поддержка автоматических выборов лидера на основе Raft.
Меня зовут Сергей Петренко, и я участвовал в разработке этих больших фич. Сегодня я расскажу, как они устроены, а также коснусь конфигурирования выборов лидера и новых возможностей, которые алгоритм Raft даёт пользователям Tarantool.
1. Репликация вообще
Прежде чем погрузиться в дебри алгоритма выборов лидера, зададимся вопросом: откуда вообще возникла необходимость в таких алгоритмах?
Нужда выбирать лидера возникает в кластере из нескольких узлов, между которыми настроена репликация — синхронизация данных между несколькими узлами. Тех, кто уже знаком с репликацией, можно сразу перейти в следующий раздел.
Со всеми же, кто остался, продолжим разговор о репликации. Она бывает двух видов.
Асинхронная репликация: транзакция подтверждается сразу же после попадания в журнал мастера, и только после этого отправляется на реплики. Благодаря этому асинхронная репликация очень быстрая.
Кроме того, кластер с асинхронной репликацией не теряет доступность при отказе любого количества реплик. До тех пор, пока мастер функционирует, сохраняется возможность применять транзакции.
Но платить за скорость и доступность приходится надёжностью. Если мастер откажет, то некоторые из подтвержденных им транзакций могут не успеть попасть ни на одну из реплик и просто «пропадут».
Выглядит асинхронная репликация так:
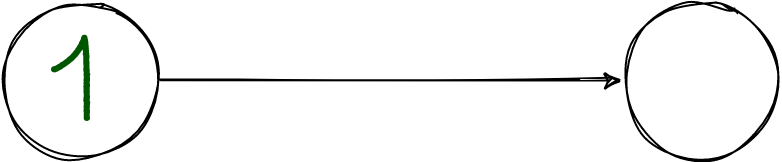
Слева мастер. Он отвечает клиенту «ок», как только запишет транзакцию в свой журнал.
или так =(
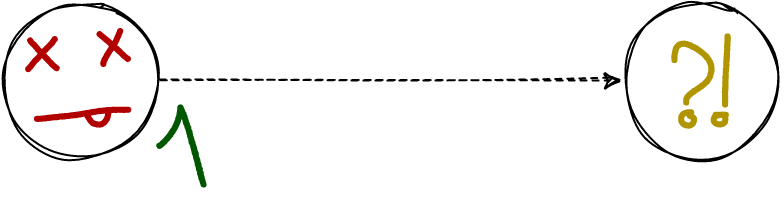
Мастер, опять же, слева. Клиенту он ответил, что всё хорошо, но потом всё стало плохо, а на других узлах транзакция отсутствует.
В случае же синхронной репликации транзакция сначала отправляется на реплики, с некоторого количества реплик собираются подтверждения, и только после этого мастер коммитит транзакцию. Такая репликация достаточно надёжна. В случае смерти мастера гарантируется, что все транзакции, которые он подтвердил, попадут хотя бы на одну из реплик.
К сожалению, наличие такого достоинства, как сохранность данных, влечёт за собой и некоторые недостатки. В первую очередь страдает доступность кластера на запись: в случае отказа достаточного количества реплик мастер теряет возможность применять транзакции, поскольку больше не может собирать кворум. Также задержка между записью транзакции в журнал и её подтверждением намного больше, чем при асинхронной репликации. После записи в журнал нужно ещё отправить транзакцию репликам и дождаться от них ответа.
Выглядит синхронная репликация так:
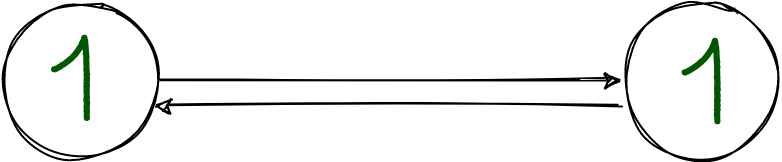
Мастер слева. Прежде чем отвечать клиенту, он отправляет данные реплике и дожидается её ответа.
Что ни делай с синхронной репликацией, потери подтверждённых данных не произойдёт:
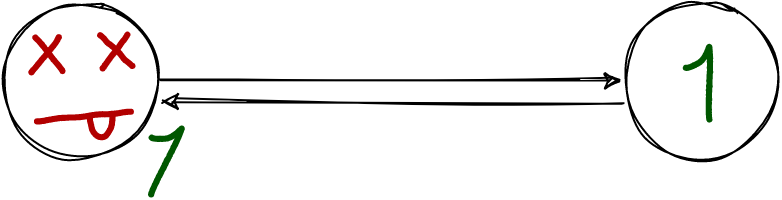
Пусть мастер и отказал, на реплике транзакция осталась.
Ключевое понятие синхронной репликации — это кворум. Прежде чем применить транзакцию, мастер убеждается, что она попала на кворум узлов и может быть применена на них. Размер кворума можно настраивать. Например, если кворум равен двум, то транзакция должна попасть хотя бы на одну реплику, помимо мастера, прежде чем её можно будет закоммитить.
2. Лидер и его выборы
В этой статье термины «лидер» и «мастер» означают одно и то же, а именно узел, который может применять транзакции и реплицировать их на остальные узлы кластера.
Что мы будем делать, когда текущий лидер откажет? Нужно каким-то образом назначить нового лидера. И при этом нельзя допускать ситуации, когда выбрано несколько лидеров. Мы хотим, чтобы «истиной в последней инстанции» был единственный узел. Иначе пришлось бы прилагать дополнительные усилия для исключения конфликтов транзакций, примененных на разных узлах.
Как же нам назначить единственного лидера? Есть два пути. Во-первых, все реплики после пропажи лидера могут ждать, пока внешнее средство не назначит среди них одного лидера. Это может быть, например, администратор, который перевёл один узел из режима read-only в read-write, либо же какой-то внешний инструмент, управляющий репликацией. В таком случае, конечно, удастся назначить единственного лидера, но потребуются лишние действия, и поэтому время простоя кластера будет заметным. Поясню, что я имею в виду: после пропажи лидера нельзя допустить, чтобы транзакций, применённых им, не было на новом лидере. Поскольку лидер у нас — «источник правды», отсутствие транзакций означало бы, что данные сначала были подтверждены, а затем исчезли. Это особенно важно для синхронной репликации. То есть лидером нельзя назначить абы какой узел. Выбрать нужно тот, который меньше других отстал от старого мастера. Следующим шагом нужно применить все синхронные транзакции, которые не успел применить старый лидер. Нужно ждать их репликации на кворум узлов, а затем рассылать подтверждения этих транзакций.
В общем, работы немало, и делать её руками не очень хочется.
Другой вариант — научить узлы кластера «договариваться», кто из них станет лидером. Здесь мы и приходим к идее алгоритма выборов. Узлы, общаясь между собой, должны решить, кто из них станет новым лидером. Затем свежеизбранный лидер, конечно, должен добиться подтверждения синхронных транзакций, оставшихся от старого лидера. То есть выполнить всю работу, описанную выше, но только автоматически. Достоинство такого решения — минимизация времени простоя после отказа лидера; а недостаток, который, впрочем, существенен только для нашей команды, — необходимость выбрать и реализовать алгоритм выборов лидера.
К счастью, нам не пришлось изобретать велосипед. Широко известным и хорошо проверенным является алгоритм Raft, который мы и взялись реализовывать.
3. Алгоритм Raft
Raft включает в себя синхронную репликацию журнала и выборы с гарантией единственности лидера на протяжении всего времени существования кластера.
Обычно кластер выглядит так: один узел находится в состоянии leader и может писать в журнал, применять транзакции и так далее. Все остальные узлы находятся в состоянии follower и применяют всё, что получают от лидера. Если follower получит по каналу репликации какую-то транзакцию от не-лидера, он её проигнорирует.
Часть протокола, касающаяся репликации журнала, достаточно проста. Текущий лидер рассылает всем членам кластера запросы AppendEntries, содержащие новые записи. Как только более половины членов кластера успешно применят записи, отправленные лидером, эти записи считаются подтверждёнными.
Другая часть протокола, которую мы будем рассматривать в этой статье, касается выборов лидера.
Далее следует краткое описание работы алгоритма Raft, необходимое для дальнейшего повествования. Чтобы разобраться в деталях, рекомендую прочитать оригинальную статью.
Всё время существования кластера разделено на логические блоки, называемые термами (term). Они пронумерованы целыми числами начиная с 1, и каждый терм начинается с выборов нового лидера. После того как лидер выбран, он принимает запросы и сохраняет в журнал новые записи, которые рассылает остальным членам кластера.
Чтобы узел был выбран лидером, за него должны проголосовать более половины узлов в кластере. Это гарантирует, что в каждом терме будет выбран либо единственный лидер, либо никто. В некоторых термах выборы могут так и не закончиться назначением лидера. Такое может произойти, если все узлы проголосовали, но ни один из кандидатов не получил большинство голосов. В таком случае начнётся новый терм, а значит будут проведены новые выборы. Все узлы проголосуют заново. Таким образом, рано или поздно один из узлов станет лидером.
Согласно Raft каждый узел может быть в одном из трёх состояний — follower, candidate, leader.
Follower — состояние, в котором узел может только отвечать на запросы AppendEntries от лидера и RequestVote от кандидатов. Если follower давно не получал ничего от лидера (в течение так называемого Election Timeout), то он переходит в состояние candidate и начинает новый терм, а вместе с тем и новые выборы.
Candidate — состояние узла, инициировавшего новые выборы. В этом случае узел голосует сам за себя, а затем рассылает всем членам кластера запросы RequestVote. Ответ на этот запрос — поле VoteGranted, принимающее значение true, если узел проголосовал за кандидата. Сам кандидат никогда не отвечает на запросы RequestVote других кандидатов. Он уже проголосовал за себя и больше ни за кого не голосует. Кандидат ведёт подсчёт отданных за него голосов. Как только их становится больше, чем половина всех узлов в кластере, кандидат становится лидером, о чём сообщает всем рассылкой пустого запроса AppendEntries (своеобразный хартбит, который может послать только лидер).
Если с момента начала выборов прошёл Election Timeout, а нужное число голосов так и не собрано, это может означать, что при голосовании никто не получил достаточное количество голосов. В таком случае кандидат инициирует новые выборы, увеличив свой term и повторно разослав другим узлам запрос RequestVote. Чтобы избежать бесконечного цикла из перевыборов, Election Timeout слегка рандомизируется на каждом из узлов. Благодаря этому рано или поздно один из кандидатов первым инициирует новые выборы и соберёт необходимое количество голосов.
Leader — единственное состояние, в котором узел может писать в журнал. Лидер реплицирует этот журнал с помощью запроса AppendEntries. Кроме того, в случае, когда новые запросы не поступают, лидер периодически рассылает хартбиты (пустые запросы AppendEntries), чтобы избежать наступления таймаута и выдвижения новых кандидатов.
Если лидер или кандидат внезапно узнаёт от одного из узлов, что начался новый терм (больший, чем тот, в котором они находятся), он сразу же становится follower’ом. После этого election timeout начинает отсчёт сначала.
В журнале хранятся только номер текущего терма и голос, отданный в этом терме. Нужно это для того, чтобы не позволять узлам повторно голосовать после перезапуска.
Состояние узла в журнал не попадает. После перезапуска узел всегда оказывается в состоянии follower.
4. Наша реализация синхронной репликации
Часть протокола Raft, отвечающая за репликацию журналов, была реализована как отдельная задача на три месяца раньше, чем началась работа над выборами лидера.
Синхронность можно включить отдельно для спейса с ценными данными. Тогда синхронными будут только транзакции, касающиеся этого спейса.
Синхронная транзакция перед применением ждёт подтверждения от кворума реплик. То есть сначала она должна попасть в журнал, после чего отправиться на кворум реплик, а те должны подтвердить получение транзакции. Только после этого транзакция будет завершена и применена.
Если транзакция не дождётся кворума в заданный промежуток времени, (который можно конфигурировать, об этом речь пойдёт ниже) то она откатится по таймауту.
Особенность журнала Tarantool в том, что он хранит только redo-записи, а не undo. Это значит, что после перезапуска журнал можно проиграть только от начала до конца, повторив все применённые транзакции. Однако журнал нельзя «развидеть», то есть отменить транзакцию, прочитанную из журнала. В нём просто нет необходимых для этого структур. Это позволяет сделать журнал компактнее. Структуры, которые нужны для отмены транзакции, хранятся в памяти, и в случае асинхронной репликации освобождаются сразу после успешной записи в журнал, а в случае синхронной — либо после подтверждения транзакции кворумом узлов, либо после её отката по таймауту.
Наш журнал append only: при отмене транзакции нельзя просто так взять и удалить из него «лишние» записи. Кроме того, поскольку транзакция уже разослана репликам, теперь нужно сообщить им, что она была отменена. Из-за особенностей журнала все транзакции первым делом попадают в него, независимо от того, синхронные они или нет. Поэтому некоторое время в журнале находятся синхронные транзакции, о которых неизвестно, подтверждены они или нет.
Из-за этого появилась нужда в новом типе записей в журнале — ROLLBACK. Как только на мастере наступает таймаут на ожидание подтверждений от реплик, он вносит в журнал запись ROLLBACK с LSN (порядковым номером) отмененной транзакции. Эта запись, как и все остальные в журнале, пересылается на реплику. Получив такую запись, реплика отменяет неуспешную синхронную транзакцию и все транзакции с бо̒льшим LSN. Сделать она это может благодаря хранящемуся в памяти undo log. То же самое делает и мастер.
Если же кворум реплик, получивших транзакцию, собран, то репликам нужно сообщить, что транзакция подтверждена. Во-первых, это позволит им освободить undo log. Во-вторых, при восстановлении из журнала им будет нужна информация о том, какие транзакции применены, а какие — нет. Для этой цели была добавлена ещё одна служебная запись в журнал — CONFIRM.
Поскольку репликация в Tarantool реализована как построчная пересылка записей из журнала мастера репликам, изобретение записей CONFIRM и ROLLBACK сыграло нам на руку: сообщения о подтверждении или откате синхронных транзакций реплики получали по обычному каналу репликации. Не пришлось придумывать, каким образом мастер будет отправлять им системные сообщения. Он просто считывает их из журнала и отправляет как обычные данные. Кроме того, реплики могут без изменений записывать полученные служебные сообщения в свои собственные журналы, что позволило им корректно восстанавливаться, игнорируя отменённые синхронные транзакции.
При разработке мы могли пойти по альтернативному пути: сперва разослать транзакцию репликам, и записать её в свой журнал только в случае применения на кворуме реплик. Но это не избавило бы нас от проблем. Репликам всё ещё нужно давать знать, что транзакция отменена. Кроме того, становится возможной ситуация, когда реплики транзакцию применили, а мастер отказал и после перезапуска вообще забыл о её существовании. В случае же с «упреждающей» записью в журнал мастер пусть и не сможет применить неподтверждённую транзакцию автоматически, но, по крайней мере, не потеряет её.
Итак, все транзакции, и синхронные, и асинхронные, первым делом попадают в WAL. После успешной записи асинхронные транзакции сразу коммитятся, а синхронные попадают в специальную очередь — limbo, где они ждут своей репликации на кворум узлов. Когда кворум подтверждений собран, транзакция коммитится, а в журнал записывается CONFIRM. Если же произошёл таймаут ожидания подтверждений, в журнал пишется ROLLBACK, а транзакция откатывается вместе со всеми следующими за ней в очереди.
Следует добавить, что если очередь синхронных транзакций не пуста, то в неё перед своим коммитом попадают и асинхронные транзакции. Они не ждут подтверждений, но должны быть в очереди, чтобы их можно было откатить, если вдруг синхронная транзакция не соберёт кворум. Это нужно потому, что синхронная транзакция может изменить данные и в синхронном, и в обычном спейсе, в результате асинхронная транзакция, обращающаяся к тому же спейсу, будет зависеть от этой синхронной транзакции.
По умолчанию, пока транзакции находятся в очереди, их изменения будут видны другим транзакциям. Такой эффект называется «грязные чтения», и чтобы с ним бороться, нужно включить менеджер транзакций. В Vinyl — дисковом движке Tarantool — менеджер транзакций был включен всегда, а в Memtx — движке для хранения данных в памяти — он появился в релизе 2.6 стараниями Александра Ляпунова, о чём тот расскажет в своей статье.
5. Адаптация Raft к нашему репликационному протоколу
Всё общение между узлами набора реплик происходит через две сущности: relay (отправка данных) и applier (получение данных). До появления Raft единственной функцией relay была отправка записей журнала. При реализации синхронной репликации удалось добиться того, что системное сообщение получат все реплики, просто записав его в журнал. При этом не пришлось добавлять дополнительную функциональность в relay. Он как пересылал записи из журнала реплике, так и продолжил этим заниматься. В то же время applier пришлось научить обрабатывать системные сообщения, которые он получал от relay мастера.
В случае с реализацией Raft этот трюк не сработал. Дело в том, что, во-первых, не все системные сообщения Raft должны попадать в журнал, а значит и relay неоткуда будет их читать, и, во-вторых, даже сообщения, попадающие в журнал, а именно номер текущего терма и голос, не должны бездумно применяться репликой. Она должна узнавать об изменении терма и отданном голосе, но не обязана голосовать так же, как и другой узел. Поэтому нужно было научить relay по запросу отсылать репликам произвольные сообщения. Делает он это в перерывах между отсылкой порций журнала.
На этапе выборов лидера в Raft рассылается много дополнительной информации: запрос на голос от кандидата, голос от follower. Эти сведения не должны сохраняться в журнале: согласно протоколу, там хранятся только текущий терм и то, за кого отдан голос в этом терме.
Сам модуль Raft работает в потоке tx (этот поток занимается обработкой транзакций). Каждое изменение состояния (речь о персистентной части состояния, то есть терме и голосе) должно, согласно Raft, попадать в журнал. Как только новое состояние записано, его можно разослать репликам. Для этого tx отправляет всем потокам relay-сообщение, в которое включает и неперсистентную информацию: роль узла в Raft-кластере и, опционально, vclock этого узла. Далее каждый relay отсылает эту информацию подключённой к нему реплике, а реплика, в свою очередь, передаёт информацию в свой модуль Raft.
В Raft состояние журнала узла, то есть присутствующие на узле данные, можно обозначить одним числом: количеством записей в журнале, которое называется log index. В Tarantool его аналогом является LSN — log sequence number, порядковый номер, который присвоен каждой транзакции.
Выделяется Tarantool тем, что состояние журнала обозначается не единственным числом, а массивом LSN, называемым vclock. Это наследие асинхронной репликации «мастер-мастер», когда все узлы могут писать одновременно. Транзакции каждого узла при этом подписываются не только LSN, но и ID этого узла.
Все узлы кластера имеют свою собственную компоненту в vclock, и, записав транзакцию, пришедшую от другого узла, реплика присваивает его vclock-компоненте порядковый номер транзакции. В кластере из трёх узлов vclock одной из реплик может выглядеть, например, так: {1: 11, 2:13, 3:5}. Это означает, что на этом узле есть все транзакции с порядковым номером до 11 от узла номер 1, все транзакции с порядковым номером до 13 от узла номер 2, и (считаем, что смотрим на vclock узла 3), сам этот узел записал всего 5 транзакций.
Из-за vclock пришлось внести коррективы в нашу реализацию Raft. Во-первых, по умолчанию алгоритм всегда может определить, какой из узлов имеет более свежие данные, сравнив log index. У нас же нужно сравнивать vclock, которые могут быть несравнимыми, например, {1:3, 2:5} и {1:4, 2:1}. Проблемой это не стало, просто голосующие узлы отдают голос только за тех кандидатов, vclock которых строго больше или равен их собственному.
Как уже говорилось, в Tarantool журнал типа redo, а не undo, да ещё и append only. Это уже добавило трудностей. Дело в том, что хотя большинство узлов и отдало голос за кандидата, меньшинство может иметь более новые данные предыдущего лидера. Поскольку судьбой кластера теперь управляет новый лидер, это меньшинство больше не может работать. Нужно удалить данные таких узлов и заново подключить их к кластеру. Эта операция называется rejoin. А в алгоритме Raft такой трудности не возникало: меньшинство просто отрезало концы своих журналов так, чтобы соответствовать журналу лидера.
6. Конфигурация Raft
6.1. Режим работы узла
Чтобы узел участвовал в выборах лидера, в его конфигурации нужно указать опцию
election_mode.box.cfg{
election_mode = "off", -- значение по умолчанию
}
election_mode можно выставить в одно из следующих значений:‘off’— Raft не работает. При этом узел будет получать и запоминать номер текущего терма. Нужно это для того, чтобы в момент включения Raft узел сразу включился в нормальную работу кластера.‘voter’— узел будет голосовать за других кандидатов, но сам никогда не будет начинать выборы и выдвигать свою кандидатуру. Такие узлы полезны для ограничения набора узлов, из которых может быть выбран лидер. Скажем, можно сделать кластер из трёх узлов: двух кандидатов и одного голосующего. Тогда при отказе лидера второй из кандидатов будет сразу же выигрывать выборы, набрав большинство голосов (2 из 3: свой собственный и голос голосующего узла).
Кроме того, эта настройка полезна, если нужно заставить лидера сложить свои полномочия, не выключая при этом на нём Raft. Если текущего лидера переконфигурировать вvoter, то он сразу же станет read-only и перестанет отправлять лидерские хартбиты follower’ам. По прошествии таймаута на отказ лидера (election timeout) follower’ы начнут новые выборы, и лидером будет выбран другой узел.‘candidate’— узел может начать выборы, как только обнаружит, что лидера нет. Также этот узел может голосовать за других кандидатов, но только если он сам ещё не проголосовал за себя в текущем терме.
Как упоминалось выше, время жизни кластера поделено на интервалы, называемые термами. Термы нумеруются целыми числами начиная с 1. Вместе с выборами начинается и новый терм. Таким образом, в каждом терме либо будет выбран один лидер, либо никто не сможет победить в голосовании. Термы также не позволяют одному узлу проголосовать на одних и тех же выборах дважды. Отдав голос в текущих выборах, узел не только запоминает, что голос был отдан, но и записывает его в журнал. С началом новых выборов (а значит, и началом нового терма) голос обнуляется, что позволяет узлу проголосовать.
Требование Raft к выборам лидера: кворум, равный N/2 + 1 голосу, вместе с запретом голосовать более одного раза за выборы. Это гарантирует, что победить в выборах может не более, чем один узел.
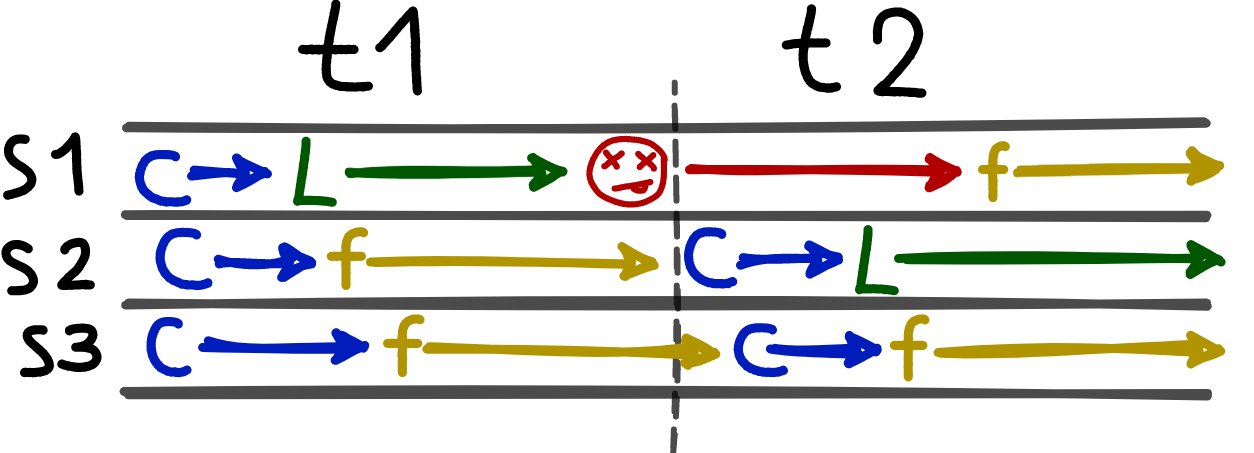
Состояния трёх узлов кластера в двух термах. В терме t1 лидером стал s1, поскольку он первым разослал запрос на голос. Когда s1 отказал, первым это заметил s2, он успел первым послать запрос на голос и стал лидером в терме t2. Когда s1 вернулся, он стал простым follower’ом.
Узел голосует за кандидата, успевшего первым прислать запрос на голос, при условии, что его журнал новее журнала узла или равен ему. Проверяется новизна при помощи сравнения vclock кандидата и голосующего. Голос будет отдан только в случае, если каждая компонента vclock кандидата больше или равна соответствующей компоненте vclock голосующего. То есть все транзакции, которые есть в журнале голосующего, должны быть и в журнале кандидата.
Vclock — векторные часы; структура, показывающая, какие данные на узле есть, а каких — нет. Она представляет собой массив порядковых номеров транзакций, которые попали в журнал на этом узле. Все узлы кластера имеют свою собственную компоненту в vclock, и, записав транзакцию, пришедшую от другого узла, реплика присваивает его компоненте vclock порядковый номер транзакции. В кластере из трёх узлов vclock одного из узлов может выглядеть так: {1: 11, 2:13, 3:5}. Это означает, что на этом узле есть все транзакции с порядковым номером до 11 от узла номер 1, все транзакции с порядковым номером до 13 от узла номер 2, и (считаем, что смотрим на vclock узла 3), сам этот узел записал всего 5 транзакций.
В случае синхронной репликации, при условии, что кворум на подтверждение синхронных транзакций выставлен не меньше, чем N/2+1, голосующие выберут лидера, журнал которого точно содержит все подтверждённые синхронные транзакции. Действительно, раз для подтверждения транзакции она должна попасть хотя бы на N/2+1 узлов, и для выбора нового лидера нужно, чтобы он получил голоса хотя бы N/2 + 1 узлов, то эта транзакция будет в журнале хотя бы одного из проголосовавших. А значит она будет и в журнале нового лидера.
6.2. Таймаут на перевыборы
Важный элемент Raft — перевыборы. Они позволяют бороться с ситуацией, когда ни один из кандидатов не набрал кворум голосов. Работает это так: кандидат собирает голоса за себя в течение election timeout. Если достаточное количество голосов так и не собрано, и лидер не заявил о себе, кандидат начинает новые выборы, увеличив номер терма. Election timeout зависит от опции конфигурации и рандомизируется в пределах 10 % от её значения.
Настраивается election timeout так:
box.cfg{
election_timeout = 5, -- значение по умолчанию, в секундах
}
6.3. Кворум голосов за кандидата
Количество голосов, которое должен получить узел перед тем, как стать лидером, конфигурируется только вместе с кворумом синхронной репликации.
box.cfg{
replication_synchro_quorum = 1, -- значение по умолчанию
}
В случае синхронной репликации имеет смысл любое значение, кроме 1. Кворум узлов, применивших транзакцию, считается так: 1 за успешную запись транзакции в журнал на мастере + 1 за каждую реплику, применившую транзакцию.
Значение 1 фактически означает, что синхронная репликация выключена, поскольку кворум будет достигаться сразу же после записи транзакции в журнал на мастере.
Для выборов лидера значение кворума нельзя ставить меньше, чем N/2 + 1, где N — количество голосующих узлов в кластере (не всех узлов, а именно голосующих, то есть тех, кто сконфигурирован в
election_mode = ‘candidate’ или election_mode = ‘voter’). В противном случае при первых же выборах может появиться несколько лидеров.Соответственно, для того, чтобы корректно добавлять в кластер новые голосующие узлы, действовать нужно так:
- Подключить к кластеру реплику с
election_mode = ‘off’. - Дождаться, пока реплика инициализируется и начнёт нормально работать.
- При необходимости увеличить
replication_synchro_quorumтак, чтобы он был не меньше, чем N/2 + 1 (N — количество голосующих узлов + новая реплика). - Включить Raft на реплике, выставив
election_mode=‘voter’либо‘candidate’.
Если добавляется реплика без права голоса, то кворум обновлять не нужно.
Если нужно вывести голосующую реплику из кластера, то сперва необходимо её отключить и только после этого уменьшить кворум, но не ниже значения N/2 + 1.
6.4. Coming soon
Мы понимаем, что описанный выше процесс достаточно неудобен и подвержен человеческому фактору. Совсем скоро, а именно в версиях 2.6.2 и 2.7.1 появится возможность указать в конфигурации формулу для вычисления кворума. При этом кворум будет обновляться автоматически при каждом добавлении узла в кластер или его удалении. Выглядеть это будет так:
box.cfg{
replication_synchro_quorum = "N / 2 + 1", -- значение по умолчанию
}
Кворум будет обновляться по формуле при каждой вставке и удалении из спейса
_cluster, который хранит информацию обо всех зарегистрированных в кластере узлах. При этом в формулу будет подставляться параметр N, равный количеству записей в спейсе _cluster. Вычисление по формуле будет применяться и для кворума синхронной репликации, и для кворума на голоса в выборах.Заметим, что отказ одного из узлов не повлечёт за собой изменение кворума. Чтобы понизить кворум, нужно будет удалить узел из спейса
_cluster. Tarantool никогда не удаляет узлы из _cluster самостоятельно, это может сделать только администратор.7. Мониторинг кластера Raft
Для мониторинга состояния Raft можно пользоваться таблицей
box.info.election, выглядит она примерно так:box.info.election
---
- state: leader
vote: 1
leader: 1
term: 2
...
Здесь:
state — состояние текущего узла, оно может быть follower, leader, candidate или none. term — номер текущего терма. leader — replica_id узла, который является лидером в этом терме. vote — replica_id узла, за который этот узел голосовал. Vote и leader не обязаны совпадать. Может оказаться, что этот узел тоже был кандидатом и проголосовал сам за себя. Но потом какой-то другой кандидат его опередил и стал лидером первым.Таблица показывает текущую роль узла, номер терма, ID лидера этого терма, а также ID узла, которому был отдан голос в последнем голосовании.
Кроме того, все свои действия Raft подробно журналирует:
2020-11-27 14:41:35.711 [7658] main I> Raft: begin new election round
2020-11-27 14:41:35.711 [7658] main I> Raft: bump term to 2, follow
2020-11-27 14:41:35.711 [7658] main I> Raft: vote for 1, follow
2020-11-27 14:41:35.712 [7658] main/116/Raft_worker I> Raft: persisted state {term: 2, vote: 1}
2020-11-27 14:41:35.712 [7658] main/116/Raft_worker I> Raft: enter leader state with quorum 1
По журналам можно проследить, за кого узел отдавал свой голос, кого считал лидером и в какие моменты становился лидером сам.
Кроме того, журналируется терм, в котором находится узел, и причины, по которым он не голосует за другие узлы, если вдруг получает от них запрос на голос. Среди таких причин — несравнимые vclock’и у голосующего и кандидата, или же то, что в текущем терме лидер уже известен.
8. Заключение
В Tarantool 2.6 появилась встроенная функциональность для автоматических выборов лидера на основе Raft. Теперь можно обходиться без внешних инструментов для смены мастера.
Это позволяет держать все настройки в одном месте — файле конфигурации Tarantool. Как бонус: обновление кворума вскоре будет автоматизировано, что ещё больше повысит удобство использования.
Также достоинствами встроенной реализации являются большая надёжность и максимально быстрая реакция на происходящие события.
Кроме того, теперь встроенная функциональность Tarantool позволяет небольшими усилиями написать автоматический failover. Подробный пример на lua можно найти в нашем репозитории с примерами. Осмотритесь там. Помимо выборов лидера там есть много полезных образцов кода.
В качестве домашней работы рекомендую посмотреть запись вебинара, где я рассказал про выборы лидера в Tarantool 2.6 и показал ещё несколько примеров. Стоит также напомнить, что скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
