

Команда Kubernetes aaS от Mail.ru Group продолжает серию переводов о правильном использовании Kubernetes. В этот раз — об антипаттернах разработки на Kubernetes с рекомендациями, как сделать по-другому.
Когда есть контейнеры, работающие в продакшен, нужно, чтобы продакшен-окружение оставалось стабильным и отказоустойчивым. Если один из контейнеров падает, нужно, чтобы в любое время ему на замену был запущен другой. Kubernetes предоставляет платформу для отказоустойчивой работы распределенных систем — от масштабирования до аварийного переключения и балансировки нагрузки. И есть много инструментов, которые интегрируются с Kubernetes, чтобы помочь вам в этом.
В этой статье рассмотрим десять распространенных практик развертывания Kubernetes, для которых есть другие решения. Автор не вдается в детали практик, поскольку реализация может различаться у разных пользователей.
1. Размещение файлов конфигурации внутри/рядом с образом Docker
Этот антипаттерн Kubernetes связан с антипаттерном Docker (см. антипаттерны 5 и 8 в этой статье). Контейнеры дают разработчикам возможность использовать единый образ на протяжении всего жизненного цикла программного обеспечения, от разработки/контроля качества до подготовки к продакшен и деплоя в продакшен.
Однако общепринятой практикой является предоставление каждой фазе жизненного цикла собственных образов, каждый из которых построен с различными артефактами, характерными для его среды: контроль качества, stage или продакшен. Но тогда вы больше не деплоите то, что тестировали.
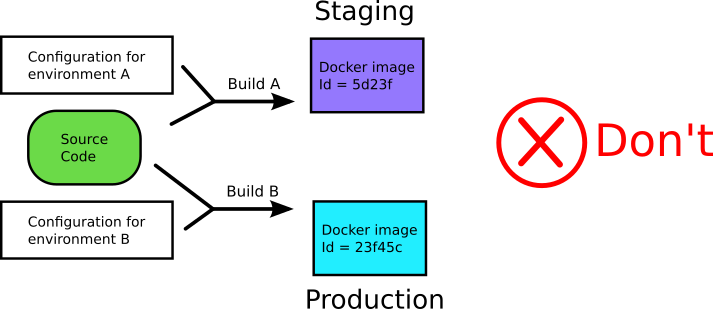
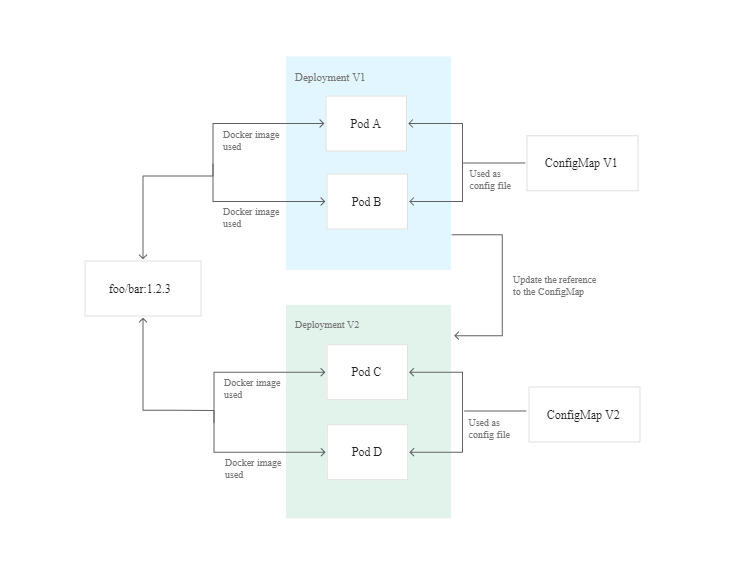
Не включайте конфигурационные файлы в докер-образы (отсюда)
Лучшей практикой является хранение конфигурации общего назначения в ConfigMaps, в то время как конфиденциальная информация (например, ключи и секреты API) может храниться в ресурсе Secrets. Он имеет кодировку Base64, но в остальном работает так же, как ConfigMaps.
ConfigMaps можно монтировать как тома или передавать как переменные среды, но секреты следует монтировать как тома. Я упоминаю ConfigMaps и Secrets, потому что они являются собственными ресурсами Kubernetes и не требуют интеграции, но у них есть свои ограничения.
Существуют и другие решения, такие как ZooKeeper и Consul от HashiCorp для ConfigMaps или Vault от HashiCorp, Keywhiz и Confidant для секретов. Они могут лучше соответствовать вашим потребностям.
Если вы отделили конфигурацию от приложения, больше не нужно пересобирать приложение, когда нужно обновить конфигурацию. Ее можно обновлять во время работы приложения. Ваши приложения получают конфигурацию во время выполнения, а не во время сборки. Что еще более важно, вы используете один и тот же исходный код на всех этапах жизненного цикла программного обеспечения.
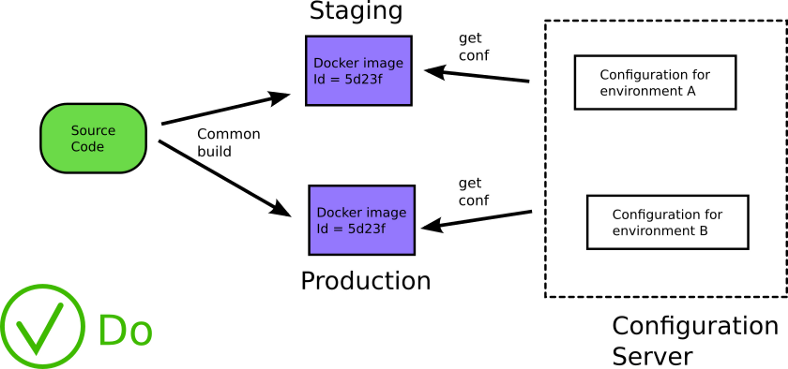
Загрузка конфигурации во время выполнения (отсюда)
2. Работа без Helm или других шаблонизаторов
Вы можете управлять деплоем в Kubernetes, напрямую обновляя YAML. При развертывании новой версии кода вам, вероятно, придется обновить один или несколько ресурсов:
Имя образа Docker.
Тег образа Docker.
Количество реплик.
Сервисные метки.
Поды.
ConfigMaps и так далее.
Этот процесс может оказаться утомительным, если вы управляете несколькими кластерами и применяете одни и те же обновления в своих средах разработки, тестовой и производственной среде. Вы в основном изменяете одни и те же файлы с небольшими изменениями во всех ваших развертываниях. Здесь много операций копирования и вставки или поиска и замены, при этом нужно не забыть о среде, для которой предназначено ваше развертывание YAML.
В этом процессе есть много возможностей для ошибок:
Опечатки: неправильные номера версий, неправильное написание имен образов и так далее.
Изменение YAML с неправильными данными, например, подключение к неправильной базе данных.
Отсутствует ресурс для обновления и так далее.
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80Взято отсюда
Возможно, вам нужно изменить ряд вещей в YAML, и если вы будете невнимательны, YAML одного деплоймента можно легко принять за YAML другого деплоймента.
Шаблоны помогают упростить установку приложений Kubernetes и управление ими. Поскольку Kubernetes не предоставляет собственный механизм шаблонов, мы должны искать сторонние шаблонизаторы.
Helm был первым доступным менеджером пакетов, появился в 2015 году. Он был назван «Homebrew для Kubernetes» и расширен за счет включения возможностей создания шаблонов.
Helm упаковывает свои ресурсы с помощью чартов, где чарт представляет собой набор файлов, описывающих связанный набор ресурсов Kubernetes. В репозитории чартов имеется более 1400 общедоступных чартов (вы также можете использовать helm search hub [ключевое слово] [флаги]), в основном многоразовые рецепты для установки, обновления и удаления в Kubernetes.
С помощью чартов Helm вы можете изменить файл values.yaml, чтобы задать изменения, необходимые для деплойментов в Kubernetes, и вы можете иметь разные чарты Helm для каждой среды. Поэтому, если у вас есть среда контроля качества, промежуточная и производственная среды, нужно управлять только тремя чартами Helm вместо того, чтобы изменять каждый YAML в каждом деплойменте в каждой среде.
Еще одно преимущество Helm заключается в том, что с помощью откатов Helm можно легко вернуться к предыдущей версии, если что-то пойдет не так:
helm rollback [REVISION] [flags]Если вы хотите вернуться к предыдущей версии, вы можете использовать:
helm rollback <RELEASE> 0Вы увидите что-то вроде:
$ helm upgrade -- install -- wait -- timeout 20 demo demo/
$ helm upgrade -- install -- wait -- timeout 20 -- set
readinessPath=/fail demo demo/
$ helm rollback -- wait -- timeout 20 demo 1
Rollback was a success.И история чарта Helm прекрасно это отслеживает:
$ helm history demo
REVISION STATUS DESCRIPTION
1 SUPERSEDED Install complete
2 SUPERSEDED Upgrade "demo" failed: timed out waiting for the condition
3 DEPLOYED Rollback to 1Kustomize от Google — популярная альтернатива, которую можно использовать в дополнение к Helm.
3. Деплой приложения в определенном порядке
Приложения не должны аварийно завершаться, потому что зависимость не готова. В традиционной разработке существует определенный порядок запуска и остановки задач при запуске приложений.
Важно не переносить это мышление в оркестровку контейнеров, то есть в Kubernetes, Docker и так далее. Эти компоненты запускаются одновременно, что делает невозможным определение порядка запуска. Даже когда приложение запущено и работает, его зависимости могут выйти из строя или быть перенесены, что приведет к дальнейшим проблемам.
В реальности Kubernetes также существует множество точек потенциальных сбоев связи, где невозможно установить зависимости, во время которых может произойти сбой пода или служба может стать недоступной. Задержки в сети, такие как слабый сигнал или прерывание сетевого соединения, является частой причиной сбоев связи.
Для простоты давайте рассмотрим гипотетическое приложение для покупок, в котором есть две службы: база данных инвентаризации и пользовательский интерфейс витрины. Прежде чем приложение сможет запуститься, внутренняя служба должна запуститься, пройти все проверки и начать работу. Затем интерфейсная служба может запуститься, выполнить ее проверки и начать работу.
Допустим, мы принудительно установили порядок деплоя с помощью команды kubectl wait, например:
kubectl wait -- for=condition=Ready pod/serviceAНо если это условие никогда не выполнится, следующий деплой не может быть продолжен, процесс прерывается.
Вот упрощенная схема того, как может выглядеть порядок развертывания:

Процесс не может двигаться дальше, пока предыдущий этап не завершен
Поскольку Kubernetes является самовосстанавливающимся, стандартный подход состоит в том, чтобы позволить всем службам в приложении запускаться одновременно, а контейнерам дать возможность сбоя и перезапуска, пока все они не будут запущены и не заработают.
У меня есть службы A и B, запускаемые независимо, как и должно быть построено облачное приложение без сохранения состояния. Но для удобства пользователя, возможно, я мог бы указать пользовательскому интерфейсу (службе B) отображать красивое сообщение о загрузке, пока служба A не готова. При этом фактический запуск службы B не должен зависеть от службы A.
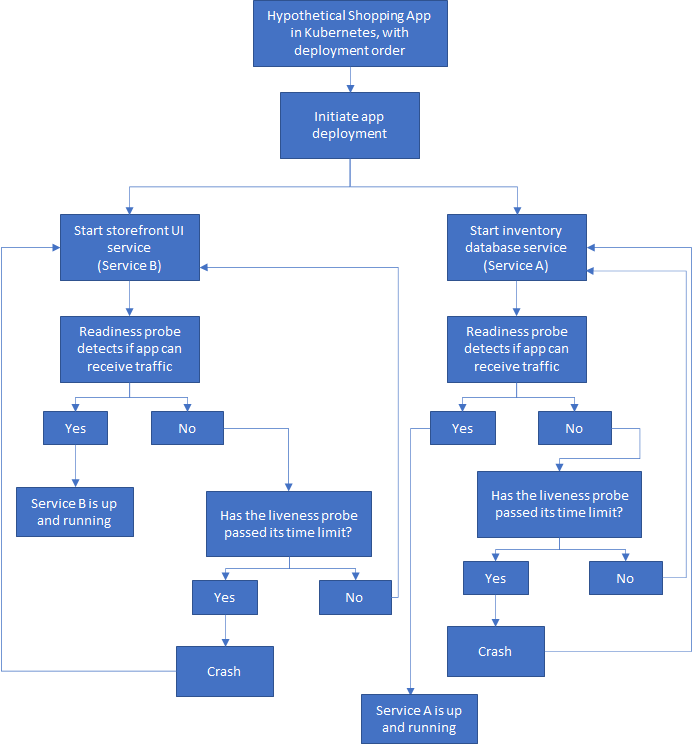
Теперь, если в поде происходит сбой, Kubernetes перезапускает службу, пока все не заработает. Если вы застряли в CrashLoopBackOff, стоит проверить свой код, конфигурацию или конкуренцию за ресурсы
Конечно, нужно делать больше, чем просто полагаться на самовосстановление. Стоит внедрять решения, справляющиеся с отказами, которые неизбежны и будут. Мы должны предвидеть, что они произойдут, и заложить основы для реагирования таким образом, чтобы избежать простоев и/или потери данных.
В моем гипотетическом приложении для покупок пользовательский интерфейс витрины (услуга B) нуждается во второй части (услуга A), чтобы предоставить пользователю то, что нужно. Поэтому при сбоях, например, если служба A недоступна в течение какого-то времени, система все равно должна иметь возможность восстановиться после этой проблемы.
Подобные временные сбои возможны, а чтобы минимизировать их последствия, мы можем реализовать шаблон Retry.
Шаблоны повторных попыток помогают повысить стабильность приложения с помощью таких стратегий, как:
Отмена. Если сбой не является временным или процесс вряд ли будет успешным при повторных попытках, приложение должно отменить операцию и сообщить об исключении, например, об ошибке аутентификации. Недействительные учетные данные никогда не должны работать!
Повторить попытку. Если неисправность необычная или редкая, это может быть связано с необычными ситуациями, например, повреждением сетевого пакета. Приложение должно немедленно повторить запрос, потому что повторение такой же ошибки маловероятно.
Повторить попытку после задержки. Если сбой вызван обычными явлениями, такими как сбой подключения или ошибками занятости, лучше всего разрешить выполниться всем невыполненным рабочим операциям или трафику, прежде чем пытаться снова. Приложение должно подождать, прежде чем повторить запрос.
Свой вариант. Вы также можете реализовать свой шаблон повтора с экспоненциальным откатом, то есть экспоненциально увеличивая время ожидания и устанавливая максимальное количество повторов.
Реализация схемы отключения также является важной стратегией при создании отказоустойчивых приложений на основе микросервисов. Как автоматический выключатель в доме сам отключается, чтобы защитить вас от серьезных повреждений из-за чрезмерного тока или короткого замыкания, так схема отключения цепи предоставляет метод написания приложений с ограничением влияния неожиданных сбоев, которые могут занять много времени. Это такие сбои, как, например, частичная потеря связи или полный отказ службы.
В таких ситуациях, если повторная попытка не сработает, приложение должно уметь установить, что произошел сбой, и отреагировать соответствующим образом.
4. Развертывание подов без установленных ограничений на память и/или CPU
Распределение ресурсов зависит от сервиса, который вы деплоите. Может быть сложно предсказать, какие ресурсы потребуются контейнеру для оптимальной производительности без тестирования в реальных условиях. Для одного сервиса может потребоваться фиксированный профиль потребления CPU и памяти, в то время как профиль потребления другого сервиса может быть динамическим.
Когда вы деплоите поды без тщательного анализа ограничений памяти и CPU, это может привести к сценариям конкуренции за ресурсы и нестабильным рабочим средам.
Если контейнер не имеет ограничения памяти или CPU, планировщик видит его использование памяти и CPU как нулевое, поэтому на любом узле можно запланировать неограниченное количество подов. Это может привести к чрезмерному использованию ресурсов и возможным сбоям узлов и кубелетов.
Когда ограничение памяти не указано для контейнера, есть несколько возможных сценариев (они также применимы к CPU):
Верхнего предела объема памяти, который может использовать контейнер, не существует. Таким образом, контейнер может использовать всю доступную память на своем узле, возможно, вызывая OOM Killer. OOM Killer чаще происходит для контейнеров без ограничений ресурсов.
Лимит памяти по умолчанию для пространства имен, в котором работает контейнер, назначается контейнеру. Администраторы кластера могут использовать LimitRange, чтобы указать значение по умолчанию для ограничения памяти.
Объявление ограничений памяти и CPU для контейнеров в кластере позволяет эффективно использовать ресурсы, доступные на узлах кластера. Это помогает планировщику Kubernetes определить, на каком узле должен располагаться под для наиболее эффективного использования оборудования.
При установке лимитов памяти и CPU для контейнера следует позаботиться о том, чтобы не запрашивать больше ресурсов, чем установлено лимитами. Для подов, содержащих более одного контейнера, совокупные запросы ресурсов не должны превышать установленные лимиты — в противном случае под никогда не будет запланирован.

Запросы ресурсов не должны превышать лимиты
Установка запросов памяти и CPU ниже их лимитов позволяет добиться двух целей:
Под может использовать память/CPU, когда они доступны, что приводит к всплескам активности.
Во время всплеска активности под ограничен разумным объемом памяти/CPU.
Хорошей практикой считается использовать запросы CPU на уровне одного ядра или ниже, и использовать ReplicaSets для масштабирования.
Что происходит, когда разные команды соревнуются за ресурсы при деплое контейнеров в одном кластере? Если процесс превысит предел по памяти, он будет остановлен, а если он превысит предел по CPU, для процесса будет включен троттлинг, что приведет к снижению производительности.
Вы можете управлять ограничениями ресурсов с помощью квот ресурсов и LimitRange в настройках пространства имен. Эти параметры помогают учитывать развертывание контейнеров без ограничений или с большими запросами ресурсов.
Установка жестких ограничений ресурсов может быть не лучшим выбором для ваших нужд. Другой вариант — использовать режим рекомендаций ресурсов в Vertical Pod Autoscaler.
5. Использование тега latest в продакшене
Использование тега latest считается плохой практикой, особенно в производственной среде. Поды неожиданно аварийно завершают работу по разным причинам, поэтому они могут в любой момент удалить докер-образы.
К сожалению, последний тег не очень информативен, когда дело доходит до определения того, когда сборка сломалась. Какая версия образа была запущена? Когда в последний раз он работал? Это особенно плохо в продакшене, поскольку вам нужна возможность восстановить работу с минимальным временем простоя.
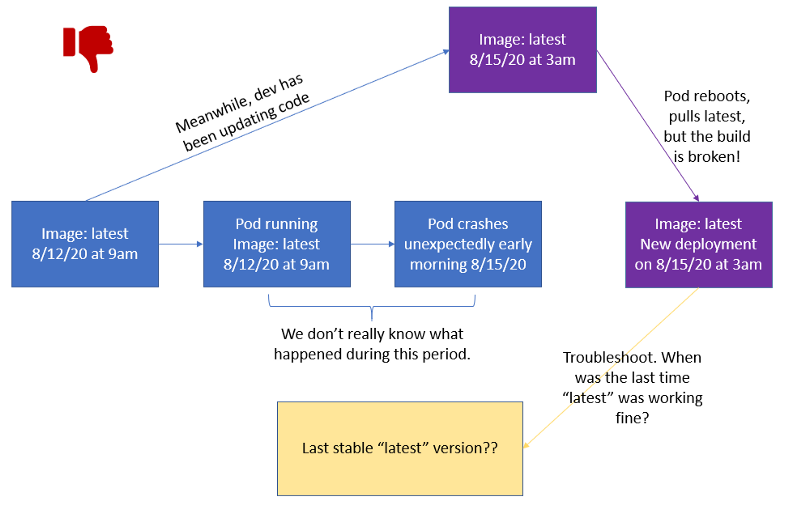
Не используйте тег latest в продакшен
По умолчанию для imagePullPolicy установлено значение Always, при перезапуске образ всегда скачивается. Если вы не укажете тег, Kubernetes по умолчанию будет использовать последнюю версию.
Однако, развертывание будет обновлено только в случае сбоя, когда под удаляет образ при перезапуске, или при изменении шаблона пода развертывания (.spec.template). Смотрите это обсуждение на форуме, чтобы увидеть, как тег latest не работает должным образом в процессе разработки.
Даже если вы изменили imagePullPolicy на другое значение, кроме Always, ваш под все равно будет скачивать образ, если ему необходимо перезапуститься, будь то из-за сбоя или преднамеренной перезагрузки.
Если вы используете управление версиями и устанавливаете imagePullPolicy со значимым тегом, например v1.4.0, то можете вернуться к самой последней стабильной версии и легче устранять неполадки, если что-то в коде пошло не так. Вы можете узнать больше о передовых методах управления версиями в Semantic Versioning Specification и GCP Best Practices.
Помимо использования конкретных и значимых тегов Docker, вы также должны помнить, что контейнеры не имеют состояния и неизменны. Они также должны быть эфемерными, вы должны хранить любые данные вне контейнеров в постоянном хранилище. После того, как вы развернули контейнер, нельзя его изменять: никаких патчей, никаких обновлений, никаких изменений конфигурации. Когда вам нужно обновить конфигурацию, вы должны развернуть новый контейнер с обновленной конфигурацией.
Неизменность Docker, взято из Best Practices for Operating Containers
Эта неизменность обеспечивает более безопасное и повторяемое развертывание. Вы также можете легко выполнить откат, если нужно повторно развернуть старый образ. Сохраняя неизменными образы Docker и сам контейнер, вы можете развернуть один и тот же образ контейнера в каждой отдельной среде. Смотрите антипаттерн №1, где мы говорили об экстернализации данных конфигурации, чтобы ваши образы оставались неизменными.

Мы можем вернуться к предыдущей стабильной версии, пока будем устранять неполадки
6. Деплой новых обновлений/исправлений путем уничтожения подов, чтобы они извлекали новые образы Docker во время процесса перезапуска
Подобно тому как полагаться на тег latest для получения обновлений, полагаться на удаление подов для развертывания новых обновлений — плохая практика, поскольку вы не управляете версиями своего кода.
Если вы убиваете поды для получения обновленных образов Docker в продакшен, то так лучше не делать. После того, как версия была выпущена в продакшен, ее нельзя перезаписывать. Если что-то сломается, вы не будете знать, где и когда что-то пошло не так и как далеко нужно вернуться, если нужно откатить код во время устранения неполадок.
Вторая проблема заключается в том, что перезапуск контейнера для получения нового образа Docker не всегда работает. Перекатка деплоя запускается тогда и только тогда, когда изменяется шаблон деплоя пода (то есть .spec.template), например, если обновляются ярлыки или образы контейнеров шаблона. Другие обновления, такие как масштабирование деплоя, не запускают перекатку.
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80Источник: deployment-1.yaml
Вы должны изменить .spec.template, чтобы перезапустить деплой.
Правильный способ обновления ваших подов для получения новых образов Docker — это использование версий или инкремента для исправлений/патчей вашего кода. А затем изменение спецификации деплоя, чтобы отразить изменения в значимом теге. Не latest (см. антипаттерн №5), а, например, v1.4.0 для нового выпуска или v1.4.1 для патча.
Kubernetes запустит обновление с нулевым временем простоя:
Kubernetes запускает новый под с новым образом.
Ожидает прохождения проверки работоспособности.
Удаляет старый под.
7. Смешивание производственной и непроизводственной нагрузок в одном кластере
Kubernetes поддерживает пространства имен, которые позволяют пользователям управлять разными окружениями (виртуальными кластерами) в одном физическом кластере. Их можно рассматривать как экономичный способ управления различными окружениями в одном физическом кластере. Например, вы можете запустить stage и продакшен окружения в одном кластере и сэкономить ресурсы и деньги. Однако существует большая разница между запуском Kubernetes в разработке и запуском Kubernetes в рабочем окружении.
При смешивании производственных и непроизводственных нагрузок в одном кластере необходимо учитывать множество факторов. Так, нужно будет рассмотреть ограничения ресурсов, чтобы убедиться, что производительность продакшен окружения не скомпрометирована. Обычная практика — это не ставить квоты на продакшен пространства имен и устанавливать квоты на любые непродакшен пространства имен.
Вам также следует помнить об изоляции. Разработчикам требуется гораздо больше доступов и разрешений, чем нужно в продакшен окружении, и которые вы хотели бы максимально заблокировать. Хотя пространства имен скрыты друг от друга, по умолчанию они не изолированы полностью. Это означает, что ваши приложения в пространстве имен для разработки могут вызывать приложения в тестовом, промежуточном или продакшен окружении (или наоборот), что не считается хорошей практикой. Конечно, вы можете использовать NetworkPolicies, чтобы установить правила для изоляции пространств имен.
Однако тщательное тестирование ограничений ресурсов, производительности, безопасности и надежности требует времени, поэтому выполнение производственных рабочих нагрузок в том же кластере, что и непроизводственных, не рекомендуется. Вместо того чтобы смешивать эти нагрузки в одном кластере, используйте отдельные кластеры для разработки/тестирования/продакшен — так вы улучшите изоляцию и повысите безопасность. Вы также должны максимально автоматизировать CI/CD, чтобы снизить вероятность человеческой ошибки. Ваше продакшен окружение должно быть как можно более надежным.
8. Отказ от сине-зеленых или канареечных деплойментов для критически важных развертываний
Многие современные приложения развертываются часто: от нескольких изменений в течение месяца до нескольких развертываний за один день. Это, безусловно, достижимо с помощью микросервисной архитектуры, поскольку различные компоненты могут разрабатываться, управляться и выпускаться в разных циклах, если они работают вместе, обеспечивая бесперебойную работу. И, конечно же, при выпуске обновлений важно поддерживать приложения в рабочем состоянии 24/7.
Стратегии Rolling Updates Kubernetes не всегда достаточно. Распространенной стратегией выполнения обновлений является использование функции rolling updates Kubernetes по умолчанию:
.spec.strategy.type==RollingUpdateВы можете установить поля maxUnavailable — процент или количество недоступных подов, и maxSurge — необязательный параметр, для управления процессом обновления. При правильной реализации так выполняется постепенное обновление с нулевым временем простоя, так как поды обновляются по очереди. Вот пример того, как одна команда обновила свои приложения с нулевым временем простоя за счет rolling update.
Однако после обновления развертывания до следующей версии не всегда легко откатиться. У вас должен быть план, как откатить деплоймент на случай, если он перестанет работать. Когда ваш под обновится до следующей версии, при развертывании будет создан новый ReplicaSet, хотя Kubernetes будет хранить предыдущие ReplicaSets. По умолчанию их десять, но вы можете изменить это количество с помощью spec.revisionHistoryLimit.
ReplicaSets сохраняются под именами в случайном порядке, например app6ff34b8374, вы не найдете ссылки на ReplicaSets в YAML для развертывания приложения. Вы можете найти его с помощью:
ReplicaSet.metatada.annotationИ проверить ревизию с помощью:
kubectl get replicaset app-6ff88c4474 -o yamlТак вы найдете номер ревизии. Процесс усложняется тем, что история развертывания не содержит никаких логов, если вы не оставите примечание в ресурсе YAML. Это вы можете сделать с помощью флага - record:
$kubectl rollout history deployment/app
REVISION CHANGE-CAUSE
1 kubectl create -- filename=deployment.yaml -- record=true
2 kubectl apply -- filename=deployment.yaml -- record=trueКогда у вас есть десятки, сотни или даже тысячи развертываний, которые обновляются одновременно, сложно отслеживать их все сразу. И если все ваши сохраненные ревизии содержат одну и ту же регрессию, тогда ваше продакшен окружение не будет в хорошей форме! Подробнее об использовании rolling updates можно прочитать в этой статье.
Еще некоторые проблемы:
Не все приложения могут одновременно запускать несколько версий.
В середине обновления вашему кластеру может не хватить ресурсов, что способно нарушить весь процесс.
Все это очень неприятные и стрессовые проблемы, с которыми приходится сталкиваться в продакшен средах.
Альтернативные способы более надежного обновления приложений включают два варианта.
Сине-зеленое (красно-черное) развертывание
При сине-зеленом развертывании одновременно существует полный набор старых и новых экземпляров приложения. Синий — это живая версия, а новая версия развернута на зеленой реплике.
Когда зеленое окружение прошло все тесты и проверки, балансировщик нагрузки просто переключает трафик на зеленую версию, которая становится новым синим окружением, а старая версия становится зеленой. Поскольку у нас поддерживаются две полные версии, выполнить откат просто — нужно лишь переключить балансировщик нагрузки обратно.

Балансировщик нагрузки переключается между синим и зеленым окружением, чтобы установить активную версию. Из стратегий непрерывного развертывания с Kubernetes
Дополнительные преимущества:
Поскольку мы никогда не выполняем развертывание непосредственно в продакшен окружении, переход от зеленого к синему не вызывает стресса.
Перенаправление трафика происходит сразу, поэтому простоев нет.
Перед переключением может быть проведено обширное тестирование, чтобы полностью проверить новое продакшен окружение. Это важно, так как среда разработки сильно отличается от производственной.
Kubernetes не включает сине-зеленые развертывания в качестве одного из собственных инструментов. В этом руководстве вы можете узнать больше о том, как реализовать их при автоматизации CI/CD.
Канареечные развертывания
Канареечное развертывание позволяет проверять потенциальные проблемы и соответствие ключевым показателям, прежде чем влиять на всю продакшен систему/базу пользователей. Мы «тестируем в продакшене», выполняя развертывание непосредственно в продакшен окружении, но только для небольшой группы пользователей.
Вы можете выбрать маршрутизацию на основе процента использования или в зависимости от региона/местоположения пользователя, типа клиента и параметров биллинга. Даже при развертывании в небольшом подмножестве важно тщательно отслеживать производительность приложения и измерять ошибки — эти показатели определяют порог качества. Если приложение ведет себя так, как ожидалось, мы начинаем переводить больше трафика на экземпляры новой версии.
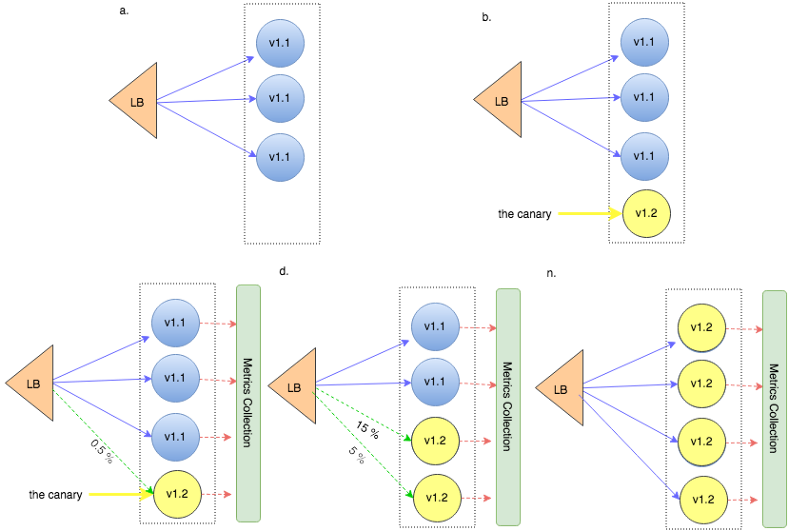
Балансировщик нагрузки постепенно выпускает новую версию в продакшен. Из стратегий непрерывного развертывания с Kubernetes
Другие преимущества:
Наблюдаемость.
Возможность тестирования на продакшен трафике. Протестировать в cреде разработки так же, как в производственной, сложно.
Возможность задеплоить версию для небольшой группы пользователей и получить реальную обратную связь перед более крупным деплоем.
Быстро получить отказ. Поскольку мы развертываем прямо в продакшен, мы можем быстро получить отказ работы, то есть немедленно вернуться на рабочую версию, если что-то сломается. При этом сбой затронет только часть пользователей, а не все сообщество.
9. Отсутствие метрик, позволяющих понять, был ли деплой успешным или нет
Проверки работоспособности требуют поддержки со стороны приложения.
Вы можете использовать Kubernetes для выполнения множества задач по оркестровке контейнеров, например:
Контроль потребления ресурсов приложением или командой: пространство имен, CPU/память, ограничения, а также предотвращение потребления приложением слишком большого количества ресурсов.
Балансировка нагрузки между разными экземплярами приложений, перемещение экземпляров приложений с одного хоста на другой, если есть нехватка ресурсов или если хост перестает работать.
Самовосстановление — перезапуск контейнеров в случае их сбоя.
Автоматическое использование дополнительных ресурсов при добавлении нового хоста в кластер.
Из-за этих возможностей иногда о показателях и мониторинге легко забывают. Однако успешное развертывание — это еще не конец вашей работы. Лучше проявить инициативу и приготовиться к сюрпризам. Есть еще много уровней для мониторинга, а динамический характер K8s затрудняет устранение неполадок.
Например, если вы невнимательно следите за доступными ресурсами, автоматическое перепланирование подов может вызвать проблемы с недостатком ресурсов. Тогда ваше приложение может дать сбой или никогда не развернуться. Это особенно прискорбно в продакшен, так как вы не узнаете о сбое, пока кто-то не отправит отчет об ошибке или если вы не захотите проверить работоспособность вручную.
В мониторинге есть свой набор проблем: много уровней, за которыми нужно следить, и необходимость поддерживать достаточно низкую нагрузку на инженеров по обслуживанию.
Когда приложение, работающее в Kubernetes, сталкивается с проблемой, существует множество логов, данных и компонентов, которые необходимо исследовать. Особенно если проблема связана с несколькими микросервисами, в отличие от традиционной монолитной архитектуры, где все выводится в несколько логов.
Анализ поведения вашего приложения, например, того, как оно работает, поможет постоянно его улучшать. Также потребуется довольно целостное представление о контейнерах, подах, службах и кластере в целом. Если вы можете определить, как приложение использует ресурсы, то сможете использовать Kubernetes, чтобы лучше обнаруживать и устранять узкие места.
Чтобы получить полное представление о приложении, нужно использовать решения для мониторинга производительности приложений, такие как Prometheus, Grafana, New Relic или Cisco AppDynamics, либо какие-либо еще.
Независимо от того, решите вы использовать решения для мониторинга или нет, вот ключевые показатели, которые документация Kubernetes рекомендует вам внимательно отслеживать:
Запущенные поды и их развертывания.
Метрики ресурсов: CPU, использование памяти, дисковый ввод-вывод.
Метрики, связанные с контейнерами.
Метрики приложения.
10. Особенности работы с поставщиками облачных услуг
Существует несколько типов vendor lock-in (Мартин Фаулер написал отличную статью, если вы хотите узнать больше), привязка к поставщику не должна сводить на нет основную ценность развертывания в облаке: гибкость контейнеров.
Это правда, что выбрать подходящего поставщика облачных услуг — нелегкое решение. У каждого провайдера есть свои собственные интерфейсы, открытые API, а также проприетарные спецификации и стандарты. Кроме того, один поставщик может удовлетворить ваши потребности лучше, чем другие, в случае неожиданного изменения нужд бизнеса.
К счастью, контейнеры не зависят от платформы и их можно переносить, и все основные поставщики используют платформу Kubernetes, которая не зависит от облака. Не надо перестраивать архитектуру или переписывать код своего приложения, когда нужно перемещать рабочие нагрузки между облаками.
Вот список вещей, которые следует учитывать, чтобы оставаться гибкими, и предотвратить или минимизировать привязку к поставщику услуг.
Читайте написанное мелким шрифтом
Согласуйте стратегии входа и выхода. Многие поставщики упрощают запуск — и этим вас привязывают к себе. Сюда могут входить такое стимулирование, как бесплатный пробный период или кредиты, но эти расходы могут вырасти по мере увеличения масштаба вашего бизнеса.
Проверьте такие вещи, как автоматическое продление, плата за досрочное прекращение и поможет ли поставщик с такими вещами, как деконверсия при переходе к другому поставщику и SLA, связанные с выходом.
Создавайте/проектируйте свои приложения так, чтобы они могли работать везде
Если вы уже разрабатываете для облака и используете принципы работы с облаком, то, скорее всего, код вашего приложения должно быть легко поднять и переместить.
Например, вы можете:
Убедиться, что ваши службы и функции (например, базы данных, API-интерфейсы и так далее.), используемые вашим приложением, переносимы.
Проверить ваши сценарии развертывания и подготовки. Существует множество инструментов, которые можно использовать для автоматизации облачной инфраструктуры, они совместимы со всеми основными поставщиками облачных услуг, например: Puppet, Ansible и Chef. В этом блоге есть удобная диаграмма, в которой сравнивают характеристики распространенных инструментов автоматизации.
Проверить, может ли ваша среда DevOps, которая обычно включает Git и CI/CD, работать в любом облаке. Например, во многих облаках есть свои собственные инструменты CI/CD, такие как IBM Cloud Continuous Delivery, Azure CI/CD или AWS Pipelines, для переноса которых на другого поставщика облачных услуг могут потребоваться дополнительные усилия. Вместо этого вы можете использовать что-то вроде Codefresh, то есть решения, которые поддерживают Docker и Kubernetes и интегрируются с другими популярными инструментами. Есть также множество других решений, некоторые из них CI или CD, или и то, и другое. Например: GitLab, Bamboo, Jenkins, Travis и так далее.
Проверить, нужно ли менять процесс тестирования при смене поставщика.
Вы также можете выбрать стратегию работы с несколькими облаками одновременно
Используя мультиоблачную стратегию, вы можете выбирать сервисы от разных облачных провайдеров, которые лучше всего подходят для вашего типа приложений. Когда вы планируете развертывание в нескольких облаках, следует тщательно обдумать возможность взаимодействия между компонентами.
Заключение
Kubernetes действительно популярен, но с него сложно начать, и в традиционной разработке есть много практик, которые не переносятся на облачную разработку.
В этой статье мы рассмотрели:
Размещение файлов конфигурации внутри/рядом с образом Docker. Сделайте внешнее хранение данных конфигурации. Вы можете использовать ConfigMaps и Secrets или что-то подобное.
Не использовать Helm или другие шаблонизаторы. Используйте Helm или Kustomize, чтобы упростить оркестровку контейнеров и уменьшить количество человеческих ошибок.
Деплой приложения в определенном порядке. Приложения не должны аварийно завершаться, потому что зависимости не готовы. Используйте механизм самовосстановления Kubernetes и реализуйте повторные попытки и автоматические выключатели.
Развертывание подов без установленных ограничений на память и/или CPU. Вам следует подумать об установке ограничений памяти и CPU, чтобы снизить риск конфликта за ресурсы, особенно при совместном использовании кластера.
Использование тега latest в продакшене. Никогда не используйте тег latest. Всегда используйте что-то значимое, например, v1.4.0 в соответствии со спецификацией семантического управления версиями, а также неизменяемые образы Docker.
Деплой новых обновлений/исправлений путем уничтожения подов, чтобы они извлекали новые образы Docker во время процесса перезапуска. Версионирование вашего кода приводит к более хорошему управлению деплоями.
Смешивание производственных и непроизводственных нагрузок в одном кластере. Если это возможно, деплойте продакшен и непродакшен в отдельные кластера. Это снижает риск для продакшена столкнуться с нехваткой ресурсов и непредусмотренным смешиванием окружений.
Не использовать сине-зеленые или канареечные деплойменты для критически важных развертываний (rolling update по умолчанию не всегда достаточно). Вам следует подумать о сине-зеленом или канареечном деплое, чтобы уменьшить количество проблем при выкатке на продакшен и получить более значимые результаты.
Отсутствие метрик, позволяющих понять, был ли деплой успешным или нет. Вы должны следить за своими деплоями, чтобы избежать сюрпризов. Можно использовать такие инструменты, как Prometheus, Grafana, New Relic и так далее, чтобы лучше понимать, что происходит при деплоях.
Стоит подумать об особенностях работы с облачными поставщиками. Вы можете легко поднимать и переносить облачные приложения, если позаботиться об этом заранее.
Успехов!
В этих двух Telegram-каналах — новости наших сервисов, включая Kubernetes aaS и анонсы мероприятий @Kubernetes meetup.
Что почитать еще:
