Комментарии 794
Когда мы поделились планами с разработчиками, стало понятно, что команда не готова к изменениям. Большинство людей покинули компанию: остались только те, кто пришёл совсем недавно. Чтобы провести миграцию, мы решили заново собрать команду разработки.
Несколько не ясно. Т.е. уже работающим разработчикам озвучили новую задачу и все они сразу покинули компанию? Если не все, то оставшихся уволили/перевели в другие команды? Просто интересно, если пришлось менять команду, какова участь тех, кто по вашему мнению, не должен был в ней остаться? Или я чего-то не понял.
К сожалению, не все готовы выходить из зоны комфорта и штурмовать новые вершины.
А может проблема в вершинах? Может они увидели там огромный такой овраг? Может они решили, что все же не очень интересно — возвращаться во времена программирования на оракле.
Конечно, с таким бэкграундом кто их возьмёт))
есть ещё вариант, что никто не хочет работать с начальством, которое говорит эту хранимку разрабатывать с отладкой 2 часа: то же знаете ли так себе удовольствие в 10-й раз объяснять новому руководству что подготовка данных для теста хранимки может занять 8 часов, если тебе аналитик не сказал, что в определенных ситуациях возможны дубликаты которых не должно быть. и потом этот аналитик ещё и увольняется.
однако это все вопросы личного предпочтения. разработчик может искать работу 2 года, если он сам этого хочет (что говорит о хорошей зп до поиска).
в остальное мне сложно поверить так как бекграунд при найме не имеет никакого ровным счетом никакого значения:
можно нанимать хоть человека который ни 1 селекта или чтроки кода за всю жизнь до интервью не написал. имеет значение только — может он решить вопрос (говоря проще показать результат или нет) например с выводом данных, добавлением модуля, и прочей фигней, что нужна на данном проекте или нет. + подходит ли он по общению (грубо говоря может ли он не раздражая остальных понимать, что от него хотят и делать это). остальное играет роль только если вам нужен ключевой сотрудник который больше для удовлетворения эго руководства, чем для реальной необходимости.
В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python. Так что я прекрасно могу понять желание перенести все эти расчеты в БД. А если разработчик выучил Python и теперь пытается использовать его везде, где только можно и нельзя, то это, ИМХО, контрпродуктивный подход. Никак не пойму, почему все так боятся SQL.
"Боятся" не SQL, а отсутствия удобных инструментов разработки хранимок, триггеров и т. п. Со схемой-то полно проблем, но её хоть редактировать можно, а уж с ними...
Если сразу с компактной (10- 15 таблиц) и гибкой (можно вводить сотни новых сущностей без изменения таблиц) структуры данных, то и сами хранимки получаются очень простыми и удобными.
Подписывайтесь — скоро новые статьи на эту тему будут
Этот This 'pdadmin' command line utility is a part of IBM Tivoli Access Manager?
Со сдержанным энтузиазмом жду статей: может действительно что-то сильно изменилось и теперь с хранимками хотя бы только на PgSql можно нормально работать, в частности:
- легко переключаться между версиями кодовой базы для разных задач разработки, тестирования и даже продакшена
- сливать разные версии с удобным средством разрешения конфликтов вплоть до уровня отдельных символов
- проводить ревью изменений по конкретной задаче, видя конкретные изменения хранимой процедуры, а не имея последовательность CREATE OR REPLACE
- проводит статический анализ всей кодовой базы на предмет хотя бы совпадений объявлений и использований таблиц, хранимок и т. п.
- инструменты рефакторинга: переименование, выделение, инлайнинг
Когда в последний раз занимался исследованием вопроса (года 4 назад) то ничего сравнимого с современной IDE c исходниками под git/hg не нашёл. Основную проблему, почему за 40+ лет существования SQL ничего подобного не было создано, для себя обозначил как "Не смотря на заявленную декларативность языка, по факту он императивный. Мы пишем множество команд на изменение состояния схемы и подобных вещей, а не редактируем это состояние и даём одну команду на приведение текущего состояния к ожидаемому. Инструментов, позволяющих из двух описаний состояния сделать набор команд на приведение одного к другому ("сгенерировать патч"), не то чтобы совсем нет, но они очень ограничены и примитивны."
Инструментов, позволяющих из двух описаний состояния сделать набор команд на приведение одного к другому («сгенерировать патч»), не то чтобы совсем нет, но они очень ограничены и примитивны.
Тихо-тихо, visual studio очень отлично это делает! =) Database project там очень хорошо работает.
Хранимки прекрасно разрабатываются в pdAdmin. Они небольшие (200 — 400 строк), их даже для крупного проекта не требуется более 200. Триггеры, при правильной архитектуре проекта, вообще не требуются (у нас нет ни одного триггера).
Лол, на прошлой работе делал проект, в котором хранимок более 800шт, а одна из самых больших по размеру занимает более 1200 строк (впрочем, обычно я не приветствую такое, но в том месте необходимо было подготовить и передать дальше данные довольно сложной сущности, задача относительно уникальная и бить на кучу процедурок не было смысла). pgAdmin в принципе не вариант, редактор функций там убогий.
Использовать триггеры можно, например, для логирования изменений, это удобнее чем впихивать запись в журнал в каждое место, где эти данные меняются (хинт: гарантированно забудете в одном-двух местах вписать, да и вбухаете на это гораздо больше времени). Есть и другие задачи, для которых при нормальной архитектуре проекта предпочтительным.
Хранимки прекрасно разрабатываются в pdAdmin.
20+ лет пишу хранимки в PG, давно читаю хабр, вдруг оказалось, что тут можно постить до знакомства с разработкой и редакторами. Впечатлен.
Похоже, современное поколение разработчиков привыкло к использованию инструментов и библиотек.
Когда я сказал, что написал на PostgreSQL функции для реализации поиска в графе это вызвало детское удивление — как сам?
А что такого? Задачка то элементарная, 3-й курс института.
Папки с текстовыми файлами и текстового редактора с подсветкой SQL вполне достаточно даже для разработки крупного проекта.
За "простоту" приходится всегда платить. Всегда. Вопрос, в том: видите вы то, чем вы платите или нет.
Ощущение, что вы нашили серебренную пулю и обманули всех — оно ведь всегда ошибочное, оно сохраняется лишь до момента когда вы наткнетесь на понимание чем вы за это платите.
Не даром есть поговорка: "простота хуже воровства".
То что выглядит "просто" — может быть временным решением, которое эффективно решает ситуационную задачу, но завтра может оказаться "сильно упрощенным" для более сложной задачи. Возможно вы не четко очертили круг задач которые решаете при помощи хранимок в БД, что заставляет людей думать о том что при помощи хранимок вы решаете совсем все. Что с моей точки зрения, вводит в справедливое заблуждение. Опять же, с моей точки зрения, это не правильный пиар для такого подхода (лучше когда четко определили какие задачи решаются при помощи хранимок в БД и какие не стоит решать, и какие особенности при работе с хранимками в БД и как лечить).
Каких-либо сложностей в обработке данных внутри хранимок я пока не встретил. Если у Вас есть иной опыт — приведите примеры.
Обработка данных — это сильно расплывчатое понятие. Программирование, в принципе, занимается обработкой данных. Что вы имеете ввиду под этим?
Получение данных из таблиц, преобразование и сохранение данных в таблицах по определенным критериям
Формирование ответа с данными по определенным спецификациям
Критерий, где делать обработку, на мой взгляд следующий: если действие можно сделать с помощью одной/нескольких SQL-команд, то делать в хранимке. Если SQL бесполезен, то в микросервисах на других языках. Здесь главное понимать, какие есть возможности у SQL — не все об этом знают(
Другое дело!
С последним кстати вообще удобней всего на v8 работать внутри пг
json.loads(something, parse_float=decimal.Decimal)С другой стороны, если нужно возвращать json из pl/python функции, то смысла парсить json в python-е перед возвратом результата нет никакого.
Реализовать поиск на графе — это одно. Реализовать его максимально эффективно — совсем другое.
Кто угодно умеет писать "шифротексты" ксором на ключ или более прошаренные могут вспомнить асимметринчное шифрование. Но почему-то пользуются библиотеками для этого.
Хранимка с рекурсивным CTE, 50 строк, примерно час ушел на разработку. Скорость обработки в 20 раз быстрее, чем скрипт на питоне. И по размеру кода в 10 раз меньше
Если у вас парсер в 20 раз быстрее в БД мне страшно представить сколько времени работал скрипт на питоне.
Было бы прикольно показать на конкретном примере, вот текст, на питоне разбираем с таким вот слоаврем за Х мс, а на постгре за Y.
Ок, пойду напишу пережиматель жпегов на SQL, там всё просто, стандарт открыт, библиотеки не нужны :)
"Не тот случай"
Не тот случай, где MS развернулась лицом к FOSS
что ставит любой диалог с вами в лог тупик - ибо ваш ответ будет известен ещё до постановки вопроса/ предложения вам примера - вы с успехом продемонстрировали ваше отношение к вопросу диалога ниже.
ключевое для вас это "не тот случай" - именно для вас это недостаточно идеальный.
инструменты есть. за 1 день вы не получите достаточно знаний что бы грамотно их использовать. ну это как сделать вывод о java за 1 ночь.
получается странная штука - программист об "отсутствии каких то инструментов" говорит.
а руководство совсем другие причины называет.
и мне кажется что "отсутствие удобных инструментов" в данном случае наименее вероятная (и субъективная) причина "боязни sql". жаль что этот короткий и очевидный факт мне не удалось изложить коротко.
наличие таких инструментов не отменит необходимость в дба, непонятных методах переноса и взаимодействия с веб, контроля версий с мерджем как минимум. возможности держать 1 программиста на все случаи жизни без необходимости услуг дба как минимум (а в идеале и архитектора до кучи) и прочих требований.
а раз удобные инструменты не снизят порог входа для сотрудника, а так же не нивелируют факт "желательно для работы нанять дба + архитектора" - не в "удобных инструментах" дело.
sql боятся имхо именно по причине понимания, что можно не суметь контролировать процесс доработок и переноса, так же очевидно как на оопе.
ну и второй факт - наивно предполагать, что в эпоху капитализма и прибыли что то, что подходит под категорию "неудобно и ненужно" будет поддерживаться годами, а так же все про это будут знать и не любить. такие вещи отмирают очень быстро, а не развиваются до версий 2022.
"sql раньше все использовали его вот и скопилось" - раньше и паскакаль использовали и асм. тем не менее они формально для бизнесса мертвы (очевидная причина: не потому что эти языки убоги - а потому что специалистов по ним на рынке найти маловероятно массово).
косвенно: раз sql server уже 2022 - наверно "отсутствие удобных инструментов" не причина боязни сиквела для мира в целом. для вас же никто не сомневается. но в бизнесу субъективные переживания "очередного кандидата" (вас, меня, ещё вон того парня)... ну вы поняли. )
итог (кратко а то многие не могут понять): "боязнь сиквела" = субъективное мнение не отражающее реальную картину. кто то боится, кто то может адаптироваться. сугубо личное. а как известно мастер своего дела может быть очень гибким.
"Обработка данных" это что? Например, определить что у пользователя в списке покупок есть 3 товара одной категории, и если у пользователя в настройках задано "оповещать о скидках" то отправить смс — это всё в храникмке должно быть?
Речь не только про хранимки. Например нам нужно получить некоторое аналитическое представление каких-то данных в БД. Часто вижу, что это начинает лопатиться на бэке. С аргументацией "логики в БД быть не должно". Ну начнем с того, что даже фильтр по какому-то полю относится к логике. WHERE тоже на бэке будете делать? При тщательном рассмотрении можно понять, что БД — это и есть отражение предметной области с которой вы работаете. А если это не так, то Вас ждут проблемы. Где та грань, что нельзя делать в БД? Прям реально любопытно. Сможете рассказать?
Всё что не относится к SELECT/WHERE/GROUP BY/ORDER BY в бд быть не должно. В частности обработка ошибок, любые "если то-то то сделай то-то", контракт для конечного пользователя, и так далее.
Даже то что делается аналитическими функциями часто имеет смысл делать на беке, просто потому что так проще. Если нет конкретных бенчей которые показывают что система тормозит от таких запросов, тогда конечно.
А почему имеет смысл делать это на бэке? Я про аналитические функции. Давайте возьмем простейшее. Нужно посчитать SUM() по разным срезам и, возможно, фильтрам. Допустим где-то по месяцам разбить, а где-то по годам. Причем само отношение, которое мы будем группировать, получается путем джойна 5 таблиц. Итак, что вы будете делать в БД, а что на бэке? Мой вариант — создать вьшку, которая джойнит эти 5 таблиц, а потом обращаться к ней с разными WHERE и GROUP BY, применяя SUM(), как агрегирующую функцию. Это будет в 5 раз короче, чем то же делать на бэке. Это будет быстрее. Это будет дешевле по памяти. Это будет удобнее поддерживать. В частности это удобнее читать. А какой Ваш вариант?
Тут нет никакой сложной логике, и это можно считать на БД.
Хотя даже этот вариант в современном софте будет лежать в коде. Вьюшка будет сделана к модели БД в коде, после чего запросы улетят в БД и вернутся с ответом. Логика останется на беке, правда исполняться будет на базе. Типичный ОРМ в общем.
1. Фронт дергает ручку «Список покупок»
2. Прокси-сервис получает запрос и дергает соответствующую хранимку в базе (в этой точке возможен гибкий роутинг к слэйвам, например)
3. Хранимка формирует ответ в виде json. В ответе есть атрибут с инструкцией для прокси-сервиса: «вызови микросервис sms_sending, вот ему json с параметрами»
4. Прокси-сервис выполняет инструкцию
5. Прокси-сервис отправляет готовый ответ на фронт (п. 4 и 5 могут параллельно выполняться, если независимые)
Что нужно:
1. Разработать хранимку на 50-100 строк
2. Время разработки и отладки: 1 — 2 часа
3. Скорость отклика: 1 — 2 мсек (если структура данных правильная)
Зачем здесь нужны прослойки на PHP/…?
Зачем здесь нужны прослойки на PHP/…?
Повторюсь — проще найти десяток джуниоров для бека, чем одного мидла для БД.
Я другой причины для переноса бизнес-логики на бек пока не вижу.
И эта причина подтверждена на практике.
А ваш "прокси сервис" на чем написан?
Или Sedna, про неё на Хабре тоже писали.
а как организован процесс тестирования/деплоя всего этого хранимого счастья? Как работает параллельная разработка фич? Это ж никакого version -контроля? Или он через какие-то миграционные скрипты?
— вы уже делали такое.
— структура данных отлдажена
— формат json отлажен и есть метод формирования.
— есть механизм аналогичный шине который туда сюда ответы гоняет.
в остальном — задания выданные в таком формате вряд ли возможно выполнить за пару часов, если не разбираться хорошо в архитектуре.
Есть деньги на сервера и OLAP-решения, то удобнее работать в них.
Нет. Используем «модные технологии», например Hadoop+Spark.
При этом — да, загрузка данных может быть и долгой.
Но обычно это не критично.
но и бесполезно (ответ на простой запрос занимал часы вместо секунд)
очень странно. так как вряд ли бизнесс любой будет ждать ответ на запрос несколько часов.
второй момент — методов организации хранения данных в олап — он может существенно отличатся по скорости.
третье — кол-во данных — если вы каждый день закачиваете несколько миллиардов строк — ну да все это будет довольно долго обрабатываться — и тут надо уже решать какими обходными методами пользоваться. но в этом случае у вас запрос просто физически не сможет работать намного быстрее, чем олап кубы. тем более на порядки.
и тут мы приходим к главному — молотком можно дерево срубить. просто долго. что бы на порядок дольше работало, надо специально делать. сейчас много защиты от дурака. и это действительно странно — что кубы медленнее работают, чем запросы.
1. С фронта идет через прокси-сервис запрос к базе: «дай список покупок»
2. Хранимка выбирает необходимые данные и возвращает в json на фронт (также через прокси)
3. Если нужно сделать дополнительные действия (отправить SMS), то в ответе в отдельном атрибуте идет инструкция прокси-сервису «вызывай микросервис sms_sending, вот ему json с данными)
4. Проксик все эти инструкции обрабатывает
Итог:
1. Фронт дернул один! запрос к бэку
2. Хранимка сделала один! запрос к базе
3. Все дополнительные действия сделаны в фоне
Размер такой хранимки — 50-100 строк (это если запрос достаточно сложный)
Время разработки и отладки — не более 1 часа
Скорость ответа — 1-2 мсек.
При рассылке почты основная проблема не в том, как отправить письмо, а в том, кому и что отправить. Вопросы, кому и что отправить, решаются на стороне базы (это и есть данные), а сам процесс отправки нужного текста на нужный адрес — это уже микросервис
Тем более, что тот же Python можно для хранимок использовать.
Нужно ли — это другой вопрос.
Ну как бы сказать… Нет. Вообще ни разу. Просто он привычнее людям, которым надо декларативно описать выборку, а не программировать. И у этого есть как плюсы, так и минусы.
> Так что я прекрасно могу понять желание перенести все эти расчеты в БД.
Только вот PostgreSQL — не аналитическая база. Это обычный OLTP, изначально не заточенный так под аналитическую нагрузку, как, скажем, Vertica. И в аналитических базах часто есть коннекторы и расширения, позволяющие делать аналитику куда удобнее. Но тут уж своя мотивация и своя модель данных.
> В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python
Ну как бы сказать… Нет. Вообще ни разу. Просто он привычнее людям, которым надо декларативно описать выборку, а не программировать. И у этого есть как плюсы, так и минусы.
Интересно будет посмотреть, как на Python делается JOIN нескольких таблиц. И сколько он будет работать (особенно в том случае, если однажды соотношение количества отбираемых записей сильно поменяется).
SQL для своих задач выбирают не потому, что привычнее декларативно описать выборку, а потому что он для этих задач предназначен и написать вручную альтернативный функционал крайне дорого и неэффективно.
например
import myorm
let data = myorm.sql("SELECT TOP 10 * FROM A JOIN B ON A.Id = B.OtherId")Это "джоин в питоне" или уже нет?
А как по-вашему по другому в языках с БД взаимодействуют? Всё в память грузят и на клиенте бегают в циклах? Нет конечно, оно вот так и выглядит, и когда говорят "логика на бекенде" имеют в виду именно такое. Иногда оно спрятано за каким-нибудь LINQ, но всё сводится к тому чтобы сгенерировать SQL на бекенде и выполнить его на базе.
Что касается генерации запроса, большинство ORM не умеют генерировать нормальные запросы чуть сложнее простейших.
Большинство ORM позволяют перехватить фазу генерации SQL и вставить свой, как угодно оптимизированный, включая обращение к хранимке :) Задача ORM не автоматическая генерация SQL запросов, это лишь для удобства добавляют.
Пишите руками. Как все и делают.
А все простейшее они вам отлично сгенерят. Время секономите, да и не набажите при миллионом написании одного и того же.
На самом деле уровень простейшего довольно высокий. Оконных функций от ОРМ ожидать не стоит, но при прямых руках они джойнят и фильтруют успешно. Это покрывает большую часть всех запросов.
Типичная ситуация — DBA ловит проблемный запрос, предлагает хинты, чтобы заставить хоть как-то его работать, а разработчики ему — а мы не можем, у нас запрос сгенерённый в ORM.
Раньше, до всех этих мапредьюсов и nosql так приходилось делать. Просто выбора не было. Но сейчас зачем?
Не нужно всех этих гиганских перегруженых sql баз. Возьмите подходящую технологию и сделайте на ней. Их валом на любой вкус и потребность.
Взять миллионы строй из sql базы повертеть их и записать миллионы строк в sql базу вам не надо. Бывают исключения, но в общем просто не надо.
Взять миллионы строй из sql базы повертеть их и записать миллионы строк в sql базу вам не надо. Бывают исключения, но в общем просто не надо.
Зависит от входных требований. Если для удовлетворения каких-то из них требуются (напрямую или косвенно) ACID-свойства СУБД, то самый дешевый способ их обеспечить — применить SQL СУБД.
Кстати, замечу, что PostgreSQL тоже является nosql СУБД и успешно позволяет хранить документы, которые плохо ложатся на какую либо схему. Так что при необходимости, можно совместить две части данных в одном месте, чтобы расширять зоопарк технологий.
Более того, тот же Python выстрелил здесь, потому что код на нем, написанный аналитиками, потом могут относительно легко поддерживать обычные разработчики на рынке, в отличие от академических инструментов потипу R или Matlab.
Есть гибридные решения с попыткой натянуть
Генерация графиков и отчетов — это вспомогательная задача, не имеющая отношения к бизнес-логике. Нужно взять данные и заполнить шаблон. Изредка бывают хитрые варианты, требующие постобработки данных в движке, который генерирует визуальное представление отчета (типа построения cross-tab), но это тоже по сути задача заполнения шаблона (при этом основная бизнес-логика по обработке данных может происходить в БД).
Машинное обучение, математические расчеты и т.п. — тут соглашусь, такие задачи точно не для СУБД. Но наличие таких задач не противоречит утверждению «В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python», если к нему добавить фразу «в тех случаях, когда SQL применим».
> Генерация графиков и отчетов — это вспомогательная задача, не имеющая отношения к бизнес-логике.
Это чуть ли не основная задача всего департамента аналитики, на самом деле. Потому что бизнесу не интересно слушать о схождении кросс-валидации или количестве слоев в нейросети, а им надо смотреть, чтобы циферка красиво на графике вверх шла. В этом случае база нужна только для хранения предпосчитанных метрик, по которым строятся графики, да и то в этом случае большой вопрос в нужности SQL. Потому что мы рисуем метрики, а не джойним датасеты.
> Но наличие таких задач не противоречит утверждению «В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python»
Противоречит, потому что реально большинство задач — это именно аналитика, математика, машинное обучение и те самые графики, а не только делание выборок. Поэтому я за то, чтобы оставить кесарю кесарево, а бизнес-логику писать уже на нормальном языке, а не на языке запросов к БД.
Какой хороший работодатель...
Разбить текст для перевода довольно трудно… Функция была очень громоздкой, перевод мог занимать много времени.
Поскольку система должна отражать только свои внутренние тексты, то разбивку на слова можно делать при добавлении материала в базу. Скорость функции будет не важна.
По мне запихивание логики в базу имеет несколько потенциальных проблем
- Языки базы данных уступают по выразительности обычным языкам.
- Проблемы с версионностью и, вероятно, тестированием.
- Если сервер базы данных упрется в свои ограничения, то поправить будет сложно. Хотя, если он у вас там json отдает, то это случится не скоро.
Сложилось впечатление, что вы переехали с монолита на php, на монолит на PL/pgSQL.
У вас достаточно статичный контент, который лично я бы максимально закешировал в оперативной памяти и отдавал оттуда. В чем хранить данные было бы не принципиально.
Отвечу с конца:
1. «У вас достаточно статичный контент»: у нас очень динамичный контент по пользователям, каждую секунду обрабатываются сотни транзакций, в т.ч. по обновлению словарей пользователей, прогресса, статусам тренировок и т.д. Т.е. база данных постоянно обновляется.
2. «Языки базы данных уступают по выразительности обычным языкам.»: на мой взгляд, самый удобный и наглядный язык для работы с данными — это SQL. А если в рамках одного SQL запроса можно и распарсить json, и за доли миллисекунды получить данные из таблиц с миллиардами записей, и ответ запаковать в json — то что может быть проще и выразительней)
3. «Проблемы с версионностью и, вероятно, тестированием.»: у нас все хранимые функции поддерживают параметр apiVersion, поэтому как раз проблем с версионностью нет.
4. «Если сервер базы данных упрется в свои ограничения»: тут уже зависит от умения архитектора базы данных. Для обработки сложных запросов мы используем слэйвы, мастер только пишет данные и реплицирует их на слэйвы. Также архитектура позволяет поддержать модель мультимастера.
5. «разбивку на слова можно делать при добавлении материала в базу»: это не всегда эффективно, особенно если размер материала измеряется мегабайтами. Также разбивка на слова периодически перерассчитывается по мере улучшения внутренних словарей (например, добавляются новые устойчивые выражения).
Надеюсь, ответил на основные вопросы)
это не всегда эффективно, особенно если размер материала измеряется мегабайтами
Разбиваете вы его один раз и дальше он лежит в холодном хранилище, никого не трогая. Хранилище нарастить почти всегда проще, чем добавить вычислительных мощностей, поэтому если текст меняется реже, чем пользователи его запрашивают, то разбить впрок всегда эффективнее.
Также разбивка на слова периодически перерассчитывается по мере улучшения внутренних словарей (например, добавляются новые устойчивые выражения)
Никто не мешает при улучшении словарей запускать фоновый воркер, который будет переразбивать заново потихоньку, это вполне обычная практика для таких процессов.
1. Я имел в виду часть, относящуюся к словарям, текстам, заданиям и прочее. По большому счету в память можно положить и базу пользователей и их действий, которую обновлять по
pg_notify, к примеру. Сама информация, кроме финансовой составляющей, у вас достаточно не критична, так что in-memory в данном случае очень неплохо подходит.2. Для работы с данными, конечно. Для реализации бизнес-логики — не всегда. База не имеет внутри какой то магии по работе с json. php справился бы с этим не хуже.
3.4. Ок.
5. Пересчитали и положили опять таки на сервер. Какая разница сколько весит исходный материал? Более того, пользователь сразу всю книгу (а речь видимо о них) не читает. При загрузке страницы сразу можно отдавать её разметку на фразы (это копейки).
В целом я могу понять, почему старая команда не согласилась. Решение использовать базу на полную катушку спорное. За нее еще лет 15 назад топил Том Кайт, и мне казалось, что на модную ныне микросервисную архитектуру она не очень ложится.
База не имеет внутри какой то магии по работе с json
Тут вы не правы, если речь идёт про постгрес. Он умеет, например, индексы по полям в json(b).
Скорее всего ТС этим не пользуется, но речь была про то, что магия там всё-таки есть некоторая.
5. Да, при отдаче материала мы сразу и отдаем готовую разметку. Разница лишь в том, что мы ее рассчитываем при первом запросе, и только ту страницу которая запрашивается. Это решает проблему парсинга больших материалов.
5. То же вариант. Но лично я бы сразу рассчитывал, при добавлении. С местом, для хранения, сейчас проблем нет, в отличии от мощностей, как уже упомянули выше.
5. Да, согласен, скорее всего поддержим такой гибридный вариант. Спасибо!
Также архитектура позволяет поддержать модель мультимастера.
А с каких пор в PostgreSQL появился мультимастер? Или у вас не ванильный PostgreSQL?
У нас админы тестировали одну из платных кластерных модификаций PostgreSQL, производительность по транзакциям была так себе.
мы перенесли всю логику внутрь
А язык какой? PL/php?
У постгреса хоть процедурный язык и хороший, и сторонние можно приделать к хранимым процедурам, но поддержка кода в БД — это кошмар.
Нормальной работы с VCS нет, миграторы для функций не подходят совершенно. Да и те, что есть, каждый имеет "свой путь" и везде неудобно интегрироваться с git в любом случае (и в принципе ни с чем неудобно).
Поэтому было бы интересно почитать на тему того, как вы поддерживаете код в базе.
«поддержка кода в БД — это кошмар.»: код у нас стал примерно в 50 раз меньше, в основном это SQL запросы. Если умеешь их читать (и писать), то проблем нет. А времени и ресурсов экономится прилично.
«миграторы для функций не подходят совершенно»: а зачем они нужны? Гораздо проще и эффективнее написать хранимку с нуля — много времени это не занимает.
«неудобно интегрироваться с git»: не требуется такая интеграция, т.к. код очень компактый. Делайте периодически снапшоты хранимок (это текстовый файл на пару мегабайт), и все.
По быстрой и удобной разработке хранимок скоро будет цикл статей…
А когда хранимки уже написаны и изменяются в процессе разработки?
Как изменения сравнить? Как узнать, что последний раз хранимку такую-то менял Петя Петечкин -дцатого -бря прошлого года?
С хранением хранимок обычно нет проблем, есть проблемы с их эволюцией и отладкой.
Посмотреть снапшот от такого-то числа большой проблемы нет (как я писал выше, это текстовый файл на пару МБ), хотя не припомню, чтобы в этом была необходимость.
Разработка и поддержка хранимок кардинально отличается от разработки кода на не-SQL языках. Некоторые секреты раскроем в ближайших статьях…
не припомню, чтобы в этом была необходимость
Потому что то бесполезно. В процессе разработки единица изменения кода — это отдельная задача, а не сутки/недели. Поэтому важно знать "почему сделано было такое изменение", "в рамках какого блока задач", а не в какой день и потом искать в трекере задачи за это число.
За день может быть сделано много отдельных правок, и одна большая правка может оказаться в снепшоте, несмотря на то, что её делали две недели.
Какой бы не была разработка хранимок философски отличной, отслеживать изменения должно быть удобно. А их неудобно в таком виде, как вы говорите.
Но опять-таки, это мой личный опыт. Сколько людей — столько и мнений
Справедливости ради, что мешает хранить хранимки в гите?
А вы видели хоть один удобный способ для этого?
Каким образом их хранить так, чтобы на базу накатывать прямо из гита?
Чтобы изменения в одной хранимке можно было сравнить с этой же хранимкой, а не искать по тысячам файлов с миграциями? Не делать pg_dump на несколько десятков мегабайт и пр.
Чтобы без всяких магических комментариев, без хранения схемы в XML, без утилит со смутной документацией?
Если вы знаете, как хранить хранимки в гите без костылей, поделитесь секретом.
Ну миграция хранимки в данном случае это просто деплой. Накатывается из гита обычным шагом какого-нибудь тимсити. То есть у нас есть мастер-ветка в гите, туда нафигачили всякого. После этого пришла пора релизиться — просто запускается мигратор который все скриптики в папке. А в папке лежат скрипты создания хранимок GET OR CREATE.
Пониаю, звучит смешно, вроде 2020 год на дворе, но в целом так жить можно.
Второй вариант мы даже в реальности использовали, когда писали хранмики в монге. Работало это по принципу EF миграций: есть системная коллекция MigrationsHistory. Есть папка со скриптами в гите. При релизе мигратор берет все файлы из папки, который выглядят как add_some_storedp_19-05-2018-16-05.js. После этого определяет, какие нужно накатить. После этого основываясь на таймстампе в имени файла по-очереди накатывает их, после накатывания инсертит в коллекцию MigrationsHistory имя файла.
Да не смешно это звучит, а грустно (:
Пониаю, звучит смешно, вроде 2020 год на дворе, но в целом так жить можно.— почему смешно?
Потому что SQL это язык запросов. По общим возможностям не связанным с обработкой множеств он хорошо если 5% функционала языков общего назначения имеет.
Потому что SQL это язык запросов— а, то есть вы хотели сказать:
«понимаю использовать sql в 2020 году СМЕШНО, потому что это язык запросов, но в целом так жить можно». Правильно интерпретировал вашу фразу?
и что входит в язык зпросов, что есть в остальных языках? то есть что общего с остальными языками у которых +95% функционала.
о каких возможностях sql идет речь?
я просто не понимаю, как вы рассчитали цифру 5%.
и что входит в язык зпросов, что есть в остальных языках? то есть что общего с остальными языками у которых +95% функционала.
Обрабокта ошибок (писать EXCEPT в каждой хранимке это не смешно), переиспользование кода (я могу какое-нибудь хитросделанное шифрование в одну строчку написать, импортировав какую-нибудь библиотеку), тулинг (для веба есть утилиты вроде сваггера, ELK библиотек, ...), и так далее и так далее. Я языки без генериков-то не воспринимаю как нормальные, там приходится очень много копипастой заниматься из-за этого, а SQL на порядок менее приспособлен.
В качестве эксперимента что у нас есть логика в БД, подумайте как будет выглядеть например реализация вызова удаленного сервиса асинхронно по https с exponential backoff стратегией ожидания между неудачными запросами, и структурное логгирование возможных ошибок в эластик (чтобы потом можно было по отдельным полям фильтровать). Это достаточно тривиальная и распространенная задача на бекенде, как делать такое в SQL плохо представляю. В качестве бонуса желательно иметь сгенерированные клиенты для JS/C#/Java/C++, чтобы можно было эту логику вызывать внешним сервисам, не задумываясь о том как оно устроено внутри.
Обрабокта ошибоквы настолько непонятно объясняете, что если честно ничего неясно. зачем писать except в каждой процедуре?
я могу какое-нибудь хитросделанное шифрование в одну строчку написать, импортировав какую-нибудь библиотеку— вопрос только зачем? можно демки сжимать в 64 кб, которые потом разворачивались на несколько мб… только в работе (в жизни) это никак не нужно. поэтому не понимаю зачем?
представьте что пришел другой человек и он не понимает сразу, что написано вами в 1 строчке. и этот человек явно не на позиции джуна. а ему поддерживать ваш код. и ему нужно дергать вас, что бы вы ему это поясняли и ещё много подобных вещей.
тулинг— что такое тулинг?
Я языки без генериков-то не воспринимаю как нормальныечто такое генерики? скажите то что вы не воспринимаете… любой работодатель именно на это ориентируется?
а SQL на порядок менее приспособлен— для чего???? для копипасты??????
В качестве эксперимента что у нас есть логика в БД, подумайте как будет выглядеть например реализация вызова удаленного сервиса асинхронно по https с exponential backoff стратегией ожидания между неудачными запросами, и структурное логгирование возможных ошибок в эластик— для начала попробуйте разговаривать на человеческом пожалуйста. я половины не понял.
второй момент: вроде я вас не просил мне задачки давать, а попросил пояснить, что не так с sql в 2020 году. я что задал слишком сложный вопрос?
В качестве бонуса желательно иметь сгенерированные клиенты для JS/C#/Java/C++, чтобы можно было эту логику вызывать внешним сервисам, не задумываясь о том как оно устроено внутри.— какого бонуса?
p.s. фразой про хитрое шифрование вы похвалиться решили? слушайте я не задавался вопросом, лучший вы в рф разработчик или нет. у меня даже вопроса на эту тему не возникало. я только спросил правильно ли я понял фразу про sql. а вы мне в ответ «я это могу и это могу»… мне было бы достаточно, если бы вы могли на вопрос ответить и желательно без использования терминов через каждое слово. ну что бы хоть кому то, кроме вас было понятно.
если, конечно, это не слишком сложный вопрос. все что я хотел понять почему смешно использовать sql в 2020 году. а не кто во сколько строк шифрование делает или решать
тривиальная и распространенная задача на бекенде… по реализация вызова удаленного сервиса асинхронно по https с exponential backoff стратегией ожидания между неудачными запросами, и структурное логгирование возможных ошибок в эластик(на которые видимо достаточно пары часов с тестом раз это тривиальные задачи ).
Если вы знаете, как хранить хранимки в гите без костылей, поделитесь секретом.
sqitch и pgtap
Для постгреса пока удобного метода не нашёл (смотрю на FlyWay), для Sql Server используем https://www.red-gate.com/products/sql-development/sql-change-automation/. Он позволяет хранить миграционные скрипты + текущий снапшот схемы данных.
Скажем, есть у нас папка, в которой лежат исходники всех хранимок некоторой схемы БД (вроде account/create.sql и т.п.) и там же файлы с их тестами.
Как делать миграцию? Удалили схему и в одной транзакции накатили все файлы. Если тесты пройдут — делаем коммит. Это удобно или это с костылями?
Если у вас десяток хранимок — удобно.
Если сотни и тысячи — уже как-то не особенно удобно
А при разработке правите файл и на каждый чих удаляете-накатываете?
Мы используем Flyway (правда для Оракла), можно использовать Liquibase.
И там, и там, есть repeatable миграции. Во Флайвее это те, что начинаются с буквы R. А в Liquibase это делается через атрибут runOnChange.
Потому что то бесполезно— если не уметь, и отрицать любую возможность — то действительно бесполезно.
Поэтому важно знать «почему сделано было такое изменение»— кому важно в каком случае? необходим пример.
За день может быть сделано много отдельных правок— это из опыта — «никогда не работал с сиквелом, но учить остальных буду»? привидите конкретный пример.
отслеживать изменения должно быть удобно. А их неудобно в таком виде, как вы говорите.— что мешает хранимки хранить в собственном приложении к своей же бд, или в тфс гите и т.п. вещах? в чем неудобство?
инструменты есть, они вполне удобны для 90% случаев, почему для хранимок по другому?
Каким образом их хранить так, чтобы на базу накатывать прямо из гита?— это прямо необходимость накатывать из гит?
Чтобы без всяких магических комментариев, без хранения схемы в XML, без утилит со смутной документацией?—
чем плохи комментарии?
чем плохи утилиты?
зачем сравнивать предыдущий код?
Если вы знаете, как хранить хранимки в гите без костылей — что за костыли в гите можно пример?
В чём проблема хранить под гитом файлы с create or replace хранимок? При мердже в мастер просто запускаются все скрипты. Точно также можно отслеживать построчные изменения. Тестирование до мерджа осуществляется на локальных и тестовых инстансах бд. Разве что пошагового режима отладки нет, зато есть встроенный eval для быстрых проверок кода.
Alter table для таблиц нужен только чтобы не терять данные, а на самом деле он даже усложняет разработку, так как не видно полное состояние бд в коде.
Хранить не проблема, конечно, если не считать нарушения семантики в простых случаях: храним не исходный код процедуры, а команду на её создание замену, но шаг влево-шаг вправо:
- удаление процедуры как делать? Или сначала дропаем все-все процедуры, а потом создаём всё с нуля?
- переименование — аналогично. Не заморачиваемся, дропаём всё и создаём с нуля?
- проверка того какая версия (коммит, ветка) накатаны на базу, хотя бы проверить вот накатана конкретная версия или какая-то другая?
Они указали, что вся их система разбита на несвязанные модули, так что накатывание изменений вряд ли долго происходит, ибо в одном модуле хранимок немного. Плюс в отличии от модификации таблиц создание хранимок очень быстрое, так как не надо перелопачивать огромные массивы данных, а просто сохранить на диск несколько сотен строчек текста. Многомегебайтные исходники или бинарные файлы деплоятся явно не быстрее будут.
Зачем нужен git? Чтобы можно было понять какую конкретно строчку и кто изменил в каждый момент времени. SQL-скрипт под git с кучей create function отлично отслеживается. Это не схема БД, которую нельзя каждый раз дропать, так как данные нельзя терять и приходится на каждое изменение писать отдельный скрипт с alter table. Такое действительно git не может отследить.
По факту проблема только с последним пунктом из перечисленных, хотя и легко напрашивается костыль с какой-нибудь табличкой с одной строчкой с версией (в конце миграции перед COMMIT делать обновление) или ещё чего. Да и в общем-то, версию задеплоенного обычного приложения без дополнительных телодвижений тоже может быть нелегко узнать.
Я вот единственную реальную проблему вижу в ограниченности SQL самого по себе, но они же не отказались совсем от бекэнда. Какие-то задачи на SQL действительно выразительнее решаются, нежели на обычных языках, какие-то очень болезненно. Тут главное правильно разделить. Ну и разработчиков им труднее будет найти на недостаточно популярную технологию. Но никаких проблем с контролем версий быть не может при правильном подходе. Вы просто экстраполируете негативный опыт с миграциями схемы БД, где из-за невозможности просто пересоздать схему действительно всё не гладко.
А в чём проблема то дропнуть всё в рамках одной транзакции и создать заново?
Могут существовать хранимки, которые не под контролем гита. Например, созданные DBA, а не разработчиками
По факту проблема только с последним пунктом из перечисленных
По факту проблема в том, что нет нормального тулинга для синхронизации текстовых файлов в каталоге (опционально под управлением гита) и хранимок и подобных сущностей в базе. Его создание очень упростилось бы если бы SQL базы давали доступ к своему внутреннему стейту, но они дают возможность управлять им только через последовательность команд.
Могут существовать хранимки, которые не под контролем гита. Например, созданные DBA, а не разработчиками
Это решается запретом на то чтобы лезть ручонками в БД напрямую. Хранимки или нет, не принципиальо уже, общее правило.
А потом получившееся выгружается в гит автоматически, командой в батнике по расписанию.
Если у каждого будет локальная база, то ничто не помешает сначала вести разработку с такой выгрузкой перед пушем на сервер. С общей базой мы просто договорились при изменениях в коде писать в коммент разработчика и причину изменений. Криво, но при редких изменениях — вполне понятно. И что менялось и как и кем и зачем.
Разрабатываем кто в чём — единого стандарта нет, а такой способ позволяет отслеживать изменения именно в базе.
А если доработать утилиту или написать новую, то можно будет и данные с небольших таблиц-справочников отслеживать.
Ну и в базу загружать всё это не проблема, поскольку выгружается всё в виде DDL. Просто открыл в редакторе, выполнил и готово. Таблицы так обновлять не получится, но пока эта сложность не особо большая. Всё равно их вручную контролировать надо. А если понадобится автоматизировать, то можно будет старую переименовывать, новую добавлять и переливать: несколько дополнительных строк в коде.
Делайте периодически снапшоты хранимок (это текстовый файл на пару мегабайт), и все.
А где лежат эти снапшоты?
А как понять кто и по какой причине поменял ту или иную хранимку / ввёл новую версию хранимки?
это API-вызов с определенным набором параметров внутри JSON
Хранимая процедура получается вообще не содержит сложной логики и не вызывает другие хранимые процедуры? На первый взгляд мало похоже на юнит тесты, скорее на интеграционное тестирование.
А тестовая среда(база данных над которыми производит вычисления хранимка) одна на всех разработчиков? Откуда данные там появляются на проверку?
Процесс наполнения базы данных для юнит-тестов зависит от сложности самой базы. У нас достаточно компактныая структура (всего 12 таблиц, в каждой по 4-5 колонок), поэтому первичное наполнение данных не представляет сложности — это просто SQL-скрипт
В этом случае можно не только загрузить код в БД, но и прогнать все его тесты в той же транзакции. Не думали об этом?
Спасибо, что поделились опытом — очень смело с вашей стороны.
Архитектура сервиса — мрак, а всё, что написано в статье про БД — адЪ и погибель.
Пожалуйста, обязательно напишите через два года статью о состоянии вашего бэкенда, о том сколько инженеров текущего состава у вас еще работают, особенно Олег Правдин.

Со стороны видится, что:
1) проблема бэкенда была не в том, что бизнес-логика не в БД;
2) почему решили менять MySQL на PostgreSQL? Смена БД — шаг серьезный, и делать его без каких-то очевидных профитов едва ли стоит. Какая мотивация была у вас?
Вы верно сказали, что миграция должна быть оправдана. В нашем случае мы поставили такие KPI:
1. Снизить стоимость разработки в 5+ раз
2. Увеличить скорость разработки в 5+ раз
3. Снизить стоимость владения в 10+ раз
4. Сделать структуру прозрачной
Вроде удалось выполнить, но только с помощью переноса бизнес-логики в БД. Альтернативных вариантов найти не удалось.
Подробнее о процессе миграции можно посмотреть в моем докладе на PGConf'20:
www.youtube.com/watch?v=yHWFunXpZDU
Альтернативных вариантов найти не удалось.
А какие варианты рассматривали и как анализировали — подходят они для достижения требуемого или нет?
Вопрос — как сравнивали? Внутреннее строение? Наличие/отсутствие определенных видов индексом? Сравнительная производительность на определенных видах запросов? Можно вот MySql vs Postgres: вот 10 параметров по которым мы сравнивали, и вот по 7 из них постгрес оказался лучше.
Пока что это выглядит "я сходил на конфу и там рассказали, какой mysql отстой, а друг с Highload приехал, сказал что там на постгре такую нагрузку держат, что жуть. Пойду расскажу начальству про полную смену парадигмы!"
- Снизить стоимость разработки в 5+ раз
- Увеличить скорость разработки в 5+ раз
- Снизить стоимость владения в 10+ раз
Вот тут было бы интересно узнать, каким образом снимались метрики, и каким образом сравнивались =)
Вроде удалось выполнить
По ходу, на глазок :)
А стоимость владения оценили по нагрузке процессоров и памяти при равном количестве онлайн-пользователей. В итоге снизили мощность серверов при сохранении достаточно большого резерва.
Оценили, сколько часов разработки и тестирования уходило на решение схожей задачи в старой архитектуре и в новой.
По какому количеству задач эта оценка была проведена?
А оценка включала в себя затраты на исправления, которые могли случиться после реализации задачи? На каком интервале времени считались такие оценки?
«А оценка включала в себя затраты на исправления...»
Да, оценивали от начала разработки до стабильного релиза.
Время решения старых задач оценивали по jira (когда завели, когда закрыли).
А время решения новых как оценивали?
1. Проекте с кучей легаси кода, отсутствием документации, и отсутствием людей кто вообще знает хотя бы 80% проекта.
2. Проектом абсолютно новым (с сохранением той же бизнес логики), написанном с нуля, документированном, и наличием специалистов знающих этот проект.
И если да, то вы не задумывались что возможно, ну вдруг, всякое бывает, что ускорение не связанно с новой архитектурой?
Никто не заставлял разработчиков делать 500 различных таблиц (сейчас всего 12, и их структура не меняется, хотя каждую неделю добавляется по несколько новых сущностей и фичей). Конечно, 500 таблиц сложнее вести, чем 12.
Никто не заставлял разработчиков обрабатывать данные в PHP и микросервисах: 1 млн строк кода сложно документировать, 30 тыс. строк гораздо проще.
Поэтому мы полностью поменяли философию разработки (как процесс, так и инструментарий), что иметь прозрачную систему и не плодить легаси и
Первоначально когда «прошлые» разработчики писали, пытались сделать «нормализацию» данных. При этом 500 таблиц — это не проблема.
Есть-ли предположение что можно сейчас написать обычную трехзвенку на java/kotlin/python и любой БД с лучшей производительностью чем у Вас?
Вопрос не только в производительности (здесь не проблема обеспечить запас, достаточный для любого крупного проекта с десятками миллионов онлайн-пользователей), но в скорости разработки, в возможности расширения функционала. Любой код для работы с данными вне базы — это излишний код, зачем на него тратить время и ресурсы?
Ну вот вы же пишете какие-то то ли прокси, то ли API гейтвеи. Это у вас лишний код или нет? Почему он не в базе?
И вообще, а бывает код для работы не с данными? Ну кроме sleep(100) и то, 100 — это данные.
1. Отправить SMS с таким-то текстом на такой-то номер
2. Отправить письмо, пуш,…
3. Дернуть АПИ внешнего сервиса с такими-то параметрами
4. Слушать нотификации и отправлять данные в хранимку
…
- Текст СМС, номер — данные
- Текст, адрес — данные
- Параметры — данные
- Отправлять данные
Похоже у вас какое-то оригинально определение данных, слабо пересекающееся с общепринятыми.
Похоже для вас данные — это только то, что проходит через базу.
Вот прямо всегда если данные проходят через базу, то лучше использовать SQL? Чем лучше, например, в рамках записи новых данных, проводить валидацию этих данных в инсерт запросе (с трудом представляю даже как), а не сначала их проверить в приложении, а уже потом вставлять?
1. Распарсить json
2. Валидировать атрибуты
3. Выбрать данные из множества таблиц исходя из этих атрибутов
4. Провести дополнительую валидацию
5. Обновить / вставить данные в таблицу 1
6. Удалить данные в таблице 2
7. Сформировать ответ в json
Почему это удобнее:
1. Все данные уже в памяти, во временных таблицах (CTEs): вам не надо каждый раз что-то выбирать из таблицы, сохранять в массиве, обрабатывать массив, потом опять считать данные, и т.д.
2. Логика в одном месте (а не разбросана по микросервисам), ее легко проверить (понятно, что из чего получается), легко накатить (одна хранимка)
3. Про скорость разработки и размер кода уже много раз писал
Похоже у нас ещё и разное понимание, что такое "SQL-запрос".
www.postgresql.org/docs/11/sql.html
А чего не https://www.postgresql.org/docs/11/queries-overview.html? Там хоть слово query есть )
Приведите примеры, когда могут возникнуть проблемы целостности
Пока не ясно как будет реализовано — каждому сервису своя база или одна база на все сервисы. В первом случае, как обеспечить ссылочную целостность по внешним ключам, опять таки интересно будет посмотреть.
В общем кейс обещает быть интересным.
Один запрос к сервису — одна транзакция by design. Никаких проблем.
Ссылочной между сервисами нет by definition :)
RLS как и любая другая S — в чём проблемы?
Ну и опять же — хорошо, когда вы владеете всеми данными. А тут поскольку есть все-таки какие-то сервисы, то сценарий
1. Обновить сущность А
2. Сходить на внешний сервис за данными
3. Обновить на их основании сущность Б
либо лишится транзакционной целостности, либо поменяет местами шаги 1 и 2 и тем самым превратится в другой сценарий, где обновление сущности А условное.
1. Обновить сущность А
2. Сходить на внешний сервис за данными
3. Обновить на их основании сущность Б
а тут то какая проблема?
трензакция открывается сущность обновляется, комит роллбак
если комит — получаем данные из сервиса шины файла таблицы обновляем Б
хотя по класике ты сначала получаешь данные для обновления передаешь их в бд — дальше целиком обновляешь сущность или необновляешь в бд.
и не понимаю, какая транзакционная целостность в данном случае будет нарушена? можно поподробнее.
Проблема 2. Если внешний сервис будет тупить, то получите долгоиграющую транзакцию, что может плохо сказаться на работе БД, а также занимает подключение в пуле (надеюсь, не нужно объяснять, зачем нужен пул подключений), а также чревато блокировками других сессий.
надеюсь, не нужно объяснять, зачем нужен пул подключений— нужно.
Значительно снизить такую вероятность можно переходом на mq— что такое mq?
где применяется архитектура описанная в проблеме 1? насколько я понимаю, помимо того, что в проблеме 1 используется бд, у которой очередь транзакций, есть своя, есть ещё внешний сервис/апи/приложение, транзакции которой имеют не меньший приоритет. и, если будет ситуация, что в бд, в результате нагрузки (к примеру), транзакция прошла через 30 секунд вместо 1, а в апи это было принято как «таймаут вышел, я откатываю», в результате чего, этот откат начинает влиять на бд (аналог бд с чем и шла работа).
в проблеме 2 тоже возникает подобная тразакционная целостность?
а также чревато блокировками других сессий.— в каком случае будет возникать блокировка?
— нужно.
подключение к БД — довольно дорогая операция, поэтому целесообразно их переиспользовать и заводить заранее (до появления нагрузки, требующей работу с БД). В некоторых случаях используется пул со стороны БД — pg_bouncer, но он имеет свои накладные расходы и ограничения, а по сути это такой-же пул.
— что такое mq?message queue, выше уже приводили это сокращение.
транзакция прошла через 30 секунд вместо 1, а в апи это было принято как «таймаут вышел, я откатываю»Проблема не в таймауте, а в том, что когда сервис отдаёт ответ, он не может получить гарантий того, что этот ответ полностью успешно получен. С точки зрения общей надежности системы, вероятность неполучения достаточно мала. Но с точки зрения базы данных это практически гарантирует потерю консистентности.
— в каком случае будет возникать блокировка?Клиент F5 понажимал, прилетело несколько запросов работающих с теми же данными.
Ну вы ведь сравнивали с дремучим legacy. Может быть новый чистый PHP/go код был бы сравним с новым кодом в PG?
Особенно, непонятно для чего нужна реляционная база данных с тремя ключами и бинарным значением, если есть redis.
Похоже, что человек хорошо знает PostgreSQL и немного зациклился на этом инструменте. Хотя тут в комментариях упоминаются какие-то микросервисы и какой-то шибко умный прокси, возможно, в PostgreSQL разумная часть данных и логики, а про остальное просто забыли сказать.
Не понятно, чем не подошел типичный подход растаскивания монолита на микросервисы, без потери команды, данных и даунтайма. Не понятно, почему не применять более широкий набор БД и сервисов, есть же кеширование, полнотекстовый поиск, Redis, MongoDB, какие-то фоновые действия, основанные на менеджерах очередей, типа RabbitMQ или Apache Kafka.
Зачем нужна Монга, если Постгре работает быстрее
www.youtube.com/watch?v=SNzOZKvFZ68
и всё можно дёрнуть 1 декларативным запросом и не париться о согласованности данных
Как PostgreSQL справляется с полнотекстовым поиском? Или с очередями? Redis и MongoDB за счет своей простоты могут масштабироваться горизонтально, хотя я тоже сторонних использовать их только для нишевых задач. А есть еще граф, который я не упомянул. Думаю, что большая часть этого зоопарк есть на проекте в "микросервисах".
Почему для СУБД оставляют только хранение данных — я аргументов не слышал. Как будут реализована транзакционная и ссылочная целостность — пока тишина.
Очень интересно наблюдать — чем все кончится.
Вы видимо не видели хранимок на 5к строк которые делают все, что можно. Языки СУБД очень бедные по сравнению с любым языком общего назначения, и попытка выполнять бизнес-логику в БД превращается в адок.
Но вы можете продолжать считать, что те разработчики которые годами пилили систему свалили потому что глупенькие и не оценили гениального манёвра руководства.
Почему для СУБД оставляют только хранение данных
Ну я считал и, пожалуй, до сих пор считаю, что специализированное решение имеет более широкий функционал и высокую производительность.
Специальные менеджеры очередей явно проще в использование. Если говорить об Elasticsearch, то там огромные возможности по морфологии, синонимам и многому другому.
Как будут реализована транзакционная и ссылочная целостность — пока тишина.
Что касается целостности данных, то даже в случае применения реляционных БД их далеко не всегда обмазывают транзакциями и внешними ключами. В данном случае, PostgreSQL так же используется скорее как NoSQL база и целостность данных и даже их структура данных не гарантирована.
Если у вас критические данные, типа платежей, то их конечно же стоит делать строго с транзакциями и хранить в одной базе с ключами.
Каждый вызов хранимки — это изолированная транзакция, с автоматическим коммитом (или роллбэком на exception)
Давно хотел попробовать PostgreSQL, но Uber отбил желание, возможно, время пришло.
Редис in-memory если что
Но для этого и делался этот шаг, чтобы архитектура и структура стали прозрачной, чтобы и нынешнее, и будущие команды разработки могли развивать продукт, а данные пользователей не терялись
Печально, что ряд пользователей это задело(
Так это ваше решение было уничтожить наши словари?
"данные были разбросаны по сотням таблиц, без документации. Вытащить данные из такого ящика без потерь не представлялось возможным "
А можете подробнее рассказать? Откуда потери взялись вдруг? Не смогли со структурой разобраться и грохнули часть данных?
Мы честно дебажили монолит из 1 млн. строк, пытаясь выстроить это болто осушить. В итоге более 99% данных пользователей мы смогли восстановить, что очень хорошо — мои первые оценки были не более 80%
Также стоит упомянуть, что всем пользователям, данные которых пострадали, был предоставлен бесплатный премиум.
То есть вы просто дропнули прод базу с юзер данными? Серьезно?
Они такие с рождения. Лет десять назад пришел по стать с хабра из любопытства. Не впечатлился и забыл о них. А потом стала приходить их рассылка, на которую я не подписывался. Отписаться невозможно — нужно залогиниться. Пароль не помню и восстановление не работает. Написал в саппорт — ответили, что все работает как надо и нечего важных людей отвлекать пустяками. Написал вроде и на Хабре коммент… не помню. Помню точно, что пометил их письма как спам. Оказывается легко отделался.
— В словарях можно добавить вариант произношения (UK / US)? например как у них https://dictionary.cambridge.org/dictionary/english/cog
Некоторые слова у Вас встречаются с американским акцентом
— Как добавить 2 и более значения для слова в словарь и пример к каждому переводу? т.к. тот же
git commit в определенных ситуациях можно перевести как «мерз… ц соверши что то плохое»— Как сделать сортировку по значению слов?
— В словарях можно добавить вариант произношения (UK / US)?
Да, в настройках профиля можно выставить вариант озвучки.
— Как добавить 2 и более значения для слова в словарь и пример к каждому переводу?
Переводы можно добавлять у себя в словаре (СКРИН)
Как сделать сортировку по значению слов?
При клике значения одного слова/выражения отсортированы по частоте, т.е. вы видите топ-5 популярных значений (СКРИН)
Оргструктура до и после изменений: отказались от технического директора в разработке и упростили структуру в продуктовом отделе. Сейчас продуктовому дизайнеру не нужно общаться с двумя уровнями менеджеров, чтобы передать идею на фронт
Не помню за весь свой рабочий период в компании подобных ситуаций, всегда общались напрямую и никакие менеджеры этому не мешали..
Не нужно договариваться о встрече с техническим директором или готовить презентацию, чтобы подкрепить свою идею.
Ээээ?...
Команды менялись, новички не всегда понимали, как работают старые части системы, в итоге код Lingualeo постепенно превратился в чёрный ящик: непрозрачная логика в бэкенде, перегруженный фронт, обилие костылей, большие пробелы в документации.
И конечно же сейчас, не дай бог что произойдёт с разработчиком БД, подобной ситуации конечно же не произойдёт, потому что… Почему?
А затраты на инфраструктуру на 10 000 активных пользователей превышали 1 000 $ в год.
Вроде и немного совсем.
миграцию сервиса с 20 миллионами пользователей
А тут как-то сильно больше.
Где-то опечатались?
Я полагаю, что первое — это в пересчёте, на каждые 10к пользователей = $1к
Для 20млн сумма чуть больше будет, если умножить.
Но выдерживали они все-равно не более 2000 ;)
На самом деле это дорого, учитывая большинство пользователей на бесплатном тарифе
Наконец, продукт стал безопаснее. Раньше, когда вся бизнес-логика была в прослойке на PHP, оттуда из разных функций шли запросы в базу данных. Открытая для SQL-запросов база данных — это проблема: можно сделать SQL-инъекцию и заставить её выполнить опасный код, например, удаление данных. Сейчас снаружи не приходит ни одного SQL-запроса, потому что мы перенесли всю логику внутрь».
Хм, а разве сейчас какие-то адаптеры к БД не экранируют параметры в SQL запросах, чтобы не сыграл SQL Injection?
И разве хранимки каким-то дополнительным образом от этого защищены? Вот тут говорят что в некоторых случаях при некотором стечении обстоятельств это всё-таки возможно, поправьте меня, если я не прав
И разве хранимки каким-то дополнительным образом от этого защищены?
Их не нужно дополнительно защищать, они нормальным образом от этого защищены. С точки зрения глупого "адаптера", запрос к БД — это просто кусок текста, а для БД запрос — это горсть синтаксических единиц с определенным смыслом. Поэтому если вы передаёте в аргумент функции строку, она ничем кроме строки быть не может, и даже если там будет true; --, оно как строка без какого-либо предположения будет обработано.
Наоборот, в хранимке нужно специально постараться и взять арбалет, завести, приставить его к колену и выстрелить, чтобы словить инъекцию. Но динамический SQL в котором участвует текст который получается от пользователя, это уже залог успеха. Такого не должно быть в нормальных условиях.
Другой вопрос, что в постгресе экранирование на уровне протокола реализовано (возможно везде так) и если специально не конкатенировать строки, то запросы ничем не будут отличаться от того, как ими хранимые процедуры оперируют внутри самого постгреса.
Наоборот, в хранимке нужно специально постараться и взять арбалет, завести, приставить его к колену и выстрелить, чтобы словить инъекцию.
Ну, например, классический косяк джунов — принять имя поля для сортировки и прокинуть его в запрос. В случае хранимок что-то изменится, что не даст джуну так выстрелить?
принять имя поля для сортировки и прокинуть его в запрос. В случае хранимок что-то изменится, что не даст джуну так выстрелить?
Зависит от того, какой подход к работе с хранимками. Если использовать информацию из статьи, а именно:
…, переносим туда расчёты и создание JSON. … прокси-сервис, который направляет запросы в нужную базу данных, а затем отдаёт готовый JSON …
То прокси-сервису ничего не нужно делать, кроме как принять аргументы и передать их в постгрес:
select f($1, $2, $3, ...)
Если весь код написан в таком виде (из предположения, что новые методы всё же вручную пишутся, а не динамически из пути запроса и query генерируются), то сделать ошибку можно разве что специально.
В случае, если входные данные — это тоже json, то аргумент вообще один будет, а невалидный json просто распарсить не получится.
С чего бы он не валидный.
{"order": "field; SELECT * "} — вполне валидный json
Именно что валидный, но order — это строка. то что у вас SELECT * в строке — никакой роли не играет.
Если предположить, что не используется динамический SQL (т.е. поля из JSON никогда не попадают в EXECUTE PL/pgSQL, к примеру), то ничем, кроме строки, order стать не может, просто потому что к тому моменту, когда постгрес наткнётся на содержание этого поля в JSON, весь запрос уже будет построен, и это значение в виде строки.
Вы, вероятно, предполагали что значение поля order подставлялось бы напрямую в order by "field", но проблема в том, что без динамического построения запроса это сделать невозможно.
Но задача наверняка ведь не ставится в виде "послать имя поля для сортировки и использовать как есть в raw sql". Изначально есть необходимость на основе выбора пользователя подобрать критерий для сортировки.
И в таком случае уже делать то, что вы хотите — не обязательно.
Ну и даже если в таком виде делать, у постгреса есть варианты безопасно передать что угодно в запрос. Например через format('%I', request->>'order') или quote_ident(request->>'order').
но проблема в том, что без динамического построения запроса это сделать невозможно.
Но как хранимки защищают от неиспользования создания динамического запроса? Да никак в общем. К этому и подвожу — нет никакой повышенной безопасности. Как в коде можно динамически сунуть параметр забыв про плейсхолдер, так и в хранимке.
Но как хранимки защищают от неиспользования создания динамического запроса?
Их можно запретить гайдлайнами (:
В хранимках самих по себе не "повышенная безопасность", это в вызове SQL из кода приложения безопасность — пониженная.
Встроенный в PHP/Go/Ruby запрос на SQL — это не нативный код, а просто строка. И работать с SQL кодом как со строкой там не то что просто, зачастую это намного проще чем в плейсхолдеры пихать параметры и это не выглядит как что-то криминальное.
Если вы пишете нативно на SQL или pgSQL, то чтобы выполнить запрос из строки, нужно наоборот кучу телодвижений приложить. Ну и код внутри строки не будет красиво подсвечиваться.
Для того, кому не выглядит "как что-то криминальное" пихать параметры не в плейсхолдеры — не выглядит как что-то криминальное и генерировать запросы в хранимке.
Если задаться целью — можно и плюшевым мишкой убиться.
Никто не говорит, что совсем нельзя сделать небезопасно. Но в нативной для SQL среде выполнения писать безопасный SQL тупо проще небезопасного.
Если взять python, например, то для человека, который пишет на python, но слабо подкован в вопросе безопасности SQL запросов, написать такой вот код в принципе естественно:
pq.query('select * from table where x={};'.format('f'))
Вместо вот такого:
pq.query('select * from table where x=$1;', ('f',))
Потому что "а чё такова, запрос — это строка". Ну и как бы, тут параметр, тут параметр.
Когда как в хранимой процедуре это разница примерно между вот этим:
language plpgsql
as $$
begin
execute 'select * from table where x = ' || $1;
end;
$$;И вот этим:
language sql
as $$
select * from table where x = $1;
$$;Вроде не сильно сложно, но если в запросе генерируется JSON в ответ и один-другой JOIN проскакивает, то разница в сложности подхода уже будет более заметна. Вам нужно специально писать код, который будет во всём хуже.
В случае с такими же запросами из какого-либо языка, сложность написания абсолютно одинаковая что с нативными способами форматирования строк языка, что с плейсхолдерами движка БД.
Плюс БД предоставляет из коробки более простые и удобные механизмы для динамического SQL, если всё таки очень нужно, и при этом не надо идти на компромисс между читабельностью и безопасностью.
А как сделать IN с набором данных, которые пришли из json?
У JSON есть свои операторы для работы с включениями. Не вспомню, какие именно, можете почитать в документации "JSON functions and operators", в разделе для jsonb их побольше даже.
в C# генерируется вариант:
WHERE Foo IN ($p1, $p2, $p3, ...) и каждый элемент массива передается отдельным аргументом.
Посчитать разность в обе стороны для двух множеств это вообще страдание. Особенно когда одно из них прилетает извне в твою апишку.
В память оба могут и не влезть.
Писать в таблички дорого.
IN падает.
Батчинг с вычисление разности в обе стороны тормозит.
Все плохо.
where xxx in (select cast(x as xxx_type) from jsonb_array_elements(cast($1 as jsonb) -> 'xxx_values') x)where xxx = any ($1)Кстати, oracle при попытке использования более 1000 значений в IN радостно пошлёт.
в json не может быть поля с именем поля для сортировки?
{«sort»: «first_name»}
Далее уже в хранимке я обрабатываю этот параметр и учитываю его в SQL-запросе. Но никоим образом не подставляю это значение в SQL-запрос как есть
Но это же не означает, что этого вообще не может быть, и какой-нибудь junior-разработчик так по недосмотру может сделать и в таком случае конкретно тот абзац про безопасность хранимок по сравнению с обычным запросом имеет мало смысла?
Так возможность сделать надёжную систему и в обычном SQL-запросе есть
Я тоже не понял автора про повышение надежности. Было бы лучше, если бы данное утверждение было бы продемонстрировано на конкретных примерах.
Как я понимаю, как можно избежать попадания мусора в БД — это жесткие правила валидации входных данных и принудительное экранирование любых строк, а разработчикам с минимальным опытом давать только интерфейсы которые находятся под соответствующей защитой. Данный тезис я могу хоть как то объяснить.
Но динамический SQL в котором участвует текст который получается от пользователя, это уже залог успеха. Такого не должно быть в нормальных условиях.
О чём и речь. Суть-то не в технологии, а в правильном её использовании. И в обычных запросах вроде давно уже принято использовать плейсхолдеры параметров (кажется, так это называется?).
«И разве хранимки каким-то дополнительным образом от этого защищены? „
Все зависит от того, как у вас устроены хранимки. Если там нет исполняемого кода (в который подставляются параметры хранимки), то вариантов инъекции я пока не встречал, на PGConf тоже обсуждали эту тему в применении к хранимкам.
Подготовленные запросы бывают ограничены. Например, подготовить запрос для WHERE t.value =? не проблема, а вот для ORDER BY? — проблема
order by case when $1 = 'asc' and $2 = 'id' then id else null end asc,
case when $1 = 'asc' and $2 = 'parent' then parent else null end asc,
case when $1 = 'desc' and $2 = 'id' then id else null end desc,
case when $1 = 'desc' and $2 = 'parent' then parent else null end descЕсли внутри pgSQL, можно использовать execute:
execute format('select ... order by %1$I', $1);
Кешированные планы реально полезны на системах, где 95% запросов — простые (при которых с планами ошибок точно не будет если не учитывать значения) и их очень много.
Если таблица большая, и обязательно надо делать выборки с учетом сортировки по определенной колонке (например, из ста миллионов статей выбрать 100 лучших по рейтингу), то я предпочитаю разные запросы написать (пока более 3-х вариантов сортировки не попадалось).
Динамический SQL — тоже вариант, поделитесь опытом использования
Еще интересно услышать о архитектуре бэкапа и сколько времени длится откат с резервной копии?
В двух словах: у нас потоковая репликация, бэкап делается на одном из слэйвов. При возникновении проблем на Мастере один из слэйвов становится Мастером.
Если не возражаете, в одной из ближайших статье распишем подробнее…
Расскажите, про архитектуру мастер-слейв базы.
IMHO — данная тема к вопросу о том где хранить бизнес-логику не имеет отношения.
Стандартная конфигурация описанная в мегатоннах источников, докладов и презентациях.
Так уж вышло что мне на протяжении всей моей (не самой долгой) карьеры разработчика приходится переписывать софт, разработчики которого решили что будет круто пихать бизнес логику в SQL.
Каждый раз причина переписывания одна и та же — преимущества в скорости работы с данными не стоят тех ограничений, которые есть в SQL. Как только ваши задачи выходят за рамки «сджоинить несколько таблиц и отдать результат» — бизнес логика на SQL банально получается в разы длиннее и сложнее, чем если бы код был нативный. И хороших SQL специалистов в разы меньше, чем хороших нативных разработчиков.
И это я еще даже не заикаюсь про то что source control при таком подходе просто невозможен так чтобы он не бесил всех кому приходится с этим взаимодействовать, а работать без него в команде больше чем из одного человека — надо быть мазохистом.
Предлагаю дискуссию продолжить немного позже — когда выйдет несколько статей по архитектуре системы…
Насчет спецов полностью согласен — найти сильных разработчиков действительно непросто. Но с другой стороны и самих разработчиков требуется в разы меньше для решения аналогичных задач.
Вопрос не в качестве. Просто индустрия веб разработки дала ответ на спор "Хранимки" vs "Код". И поднимать спор тут как бы уже странно.
А с чего разработчиков в разы меньше? Вы считаете, что если бы вы переписали весь код не на pl/pgsql, а на PHP/Python/Go — потребовалось бы больше разработчиков его поддерживать? За счет чего?
Интересно, кто и когда дал этот ответ ?) Как раз сейчас быстро набирает силу тренд перехода на хранимки по описанным выше причинам — посмотрите доклады на конференциях по базам данных.
»А с чего разработчиков в разы меньше? "
Кода становится примерно в 10 раз меньше. Это упрощает и разработку, и тестирование, и фиксы. Также гораздо меньше времени уходит на написание SQL-запросов, если разработчик именно на этом специализируется. Если не понимать нюансов работы с данными, можно потратить не один день (и даже неделю) на оптимизацию запросов, а даже при использовании PHP/Python/Go без них не обойтись.
Тут, как говорится, лучше один раз увидеть, чем сто раз услышать…
А можно каких-нибудь примеров, чтобы один раз увидеть? Сколько ни получал проектов на поддержку с бизнес-логикой в БД, везде ситуация ровно обратная.
Все игроки на рынке дали этот ответ. Хранимки используются, как защита от ошибок программиста создать не эффективный запрос — это есть. Хранимки используются, когда сервис по сути только выдает данные из базы — но такое реже, ибо уже подводные камни. Но кто использует перенос всей бизнес логики в базу? Ну назовите игроков рынка, раз набирает силу.
Из российских компаний много о хранимках рассказывает Авито, плюс госструктуры активно переходят с Оракла на Постгрес, и хранимки для них — наиболее понятное решение, посмотрите доклады на последнем PGConf.
Ну я про веб разработку, а вы мне про оракл. Это очевидно, что кто работает с ораклом будет делать всех на хранимках, ибо больше не умеет ничего. Но оракл в вебе — это исключение, и появляется он там не потому, что его выбрали, а потому что или "только это и умели" или кто-то решил навариться. Проверочное слово — "интегратор".
Авито — пример как раз хранимок для защиты инфраструктуры от кривого запроса, когда разработчика бизнес-логики не пускают напрямую в базу, а запрос для него пишет DBA. Но база остается базой, а не апликейшн сервером.
Может потому что, что никто в нём полностью разобраться не может, чтобы переписать? :)
Байку про почтовый сервер на Линуксе замурованный в комнате, наверное слышали? ;-)
«Апполон» на Луну слетал с каким процессором и на чем была написана программа расчетов? ;-)
Затем, например, что у конкурентов гораздо ниже пресловутый time-to-market. Стратегия "работает — не трогай" бывает приводит к замедлению внедрению инноваций на национальных и даже мировом уровне. Вот пресловутая "двойная запись", изобретенная для выявления человеческих ошибок в бухгалтерских и подобных учётах, насколько актуальна сейчас? А сколько вычислительных и человеческих ресурсов тратится на её поддержку только потому, что такие требования зафиксированы чуть ли не на законодательном уровне?
пресловутая «двойная запись», изобретенная для выявления человеческих ошибок в бухгалтерских и подобных учётах, насколько актуальна сейчас
Абсолютно актуальна. И будет актуальна всегда. Ибо деньги не терпят ошибок чем бы эти ошибки не были вызваны и последствия весьма чреваты и разнообразны. По крайней мере мой 10-летний опыт работы в ИТ-подразделениях ни разу не показал обратное.
А вот к чему приводят инновации в плане «а давайте не будем делать проводки и придумаем полупроводки» я лично разгребал.
такие требования зафиксированы чуть ли не на законодательном уровнеа иначе бартер, бардак и беспредел 90-х. Я это пережил, помню, опять не хочу.
Можно поподробнее про эти инновации? Может даже в виде отдельного поста
Было очень давно, более 20 лет назад, но волне увлечения EAV. Ребята писали ИС банка и придумали новую сущность «полупроводка». С ростом объемов, сводить баланс, закрывать день был адский ад адов. Однажды 31-го декабря пришел домой встречать новый год за полчаса до полуночи. Не сходился баланс толи на 2 копейки, то ли на 10. Плюс опять таки по классике перспектив performance tuning абсолютно никаких, чем больше объемы, тем больше деградирует производительность. И ничего в схеме EAV с этим не сделать.
Еще был опыт внедрения анкерной модели, тоже в банке, тоже на волне увлечения инновациями. Прошло лет 5 по моему, бюджет съели, все встало колом, всех уволили, проект закрыли.
С тех пор ко всем инноваторам отношусь очень настороженно, ибо накушался и наразгребался достаточно.
-Лелик это не эстетично.
-Зато дешево, надежно и практично.
Я найду чем заняться в свободное время, чем убирать за инноваторами, который уже и след то простыл. А мне тут жить и работать.
Ну вот примерно так.
Ну да, разобраться не могут и годами развивают. Я б на такое посмотрел)
И переписать — это не единственный вариант, для телекома полно даже коробочных решений и если был бы смысл — давно бы переехали, полагаю.
Ну вот ЛингвоЛео годами развивали, а потом переписали, потеряв часть функциональности и даже данных, хотя казалось бы, данные-то как можно потерять, они же в базе были.
Вы сменили тему ветки, но поддержу) Я тоже считаю, что "потеря данных неприемлема", но, в моем случае, считаю это профессиональной деформацией. Да, в банке такой прокол легко измерим деньгами и виновного можно найти и выставить на зарплату всей его остальной жизни. Но вот в других сферах бизнеса я с изумлением наблюдал совершенно иное, в духе "ну ладно, перезальем эти файлы" или "что ж, в этом месяце подняли чуть меньше"… там топам даже искать виновного бывает лень. И тут я вполне допускаю, что какие-то потери ради некоторых плюсов (вроде не положить весь сервис на близком пике) могут быть и оправданы и априори приемлемы… Да, после пика можно бы вернуться к проблеме и все-таки эти данные восстановить. Но "не смогли" и "не захотели" — это разные варианты и оба они к теме текущей статьи, на мой взгляд, отношения не имеют.
Интересно, кто и когда дал этот ответ ?)
Сообщество.
https://trends.google.com/trends/explore?date=all&q=%2Fm%2F05967y,%2Fm%2F09gbxjr,%2Fm%2F05z1_,%2Fm%2F0609p
Кода становится примерно в 10 раз меньше
Кода становится в 10 раз меньше даже если переписать с PHP на PHP :) Ключевое слово тут «переписать».
А-то отличное сравнение выходит, полностью новая кодовая база против десятилетнего монолита который разрабатывали несколько волн разработчиков.
Код на PHP был достаточно качественным — особо его не оптимизируешь
Вы же вроде говорили про чёрный ящик?) Как можно сказать что код был качественным, если его нельзя понять?
Но опять же, на PHP свет клином не сошёлся, вот сейчас go набрал популярность, почему не попробовать его?
Ну, т.е. проблема уже не в PHP, а в неудачном разбиении базы / разбиении базы, которое в какой-то момент переросло допустимые лимиты?
Можно ли было изменить базу, но при этом не пихать туда хранимки, а бизнес-логику переписать на PHP / каком-то другом более шустром языке с соответствии с новой структурой?
А это разве не ваши слова?
Команды менялись, новички не всегда понимали, как работают старые части системы, в итоге код Lingualeo постепенно превратился в чёрный ящик: непрозрачная логика в бэкенде, перегруженный фронт, обилие костылей, большие пробелы в документации.
"Кода становится примерно в 10 раз меньше. Это упрощает и разработку, и тестирование, и фиксы."
Предлагаю ещё вам однобуквенные переменные и названия методов использовать, писать код в одну строку. Это уменьшит количество кода, упростит и разработку, и тестирование, и фиксы.
Алексей, возможно Вам попадались не очень качественные проекты на SQL. Не спорю, что даже с небольшим проектом тут можно так наворотить, что никакие магии Postgres не помогут.
Предлагаю дискуссию продолжить немного позже — когда выйдет несколько статей по архитектуре системы…
А есть ли смысл ждать если вы ниже уже и так написали
В хранимках практически нет циклов, условий, рекурсий и т.д. 90% кода хранимки — это SQL-запрос, в другие языки это особо не перенесешь
…
У нас мало хранимок (около 100), в каждой 200-300 строк кода.
Поправьте если я не правильно это понимаю, но, судя по написанному, у вас среднестатистическая функция бизнес логики плюс-минус такая как я написал выше — сджойнить N таблиц и выдать это наружу, ну обернуть еще в json. Стоит ли с такими входными данными вообще пытаться сравнивать нативную бизнес логику и бизнес логику в бд?
Если база данных все это может сделать, то зачем нужно обрабатывать данные в PHP и других языках? В сбалансированной системе каждый занимается своим делом: пироги печет пирожник (база данных обрабатывает данные и возвращает готовый json, а не сырые данные), а сапоги точит сапожник (PHP / Go взаимодействует с http-серверами и другими внешними ресурсами)
Как обстоят дела с "отправить запрос в БД + получить результат", "сделать http запрос на сторонний ресурс с результатами из БД", "получить http ответ", "сделать запрос в БД на основании http ответа", "вернуть json на фронт". Получается уже 2 запроса в БД. Или у вас все еще один?
Тогда картинку не совсем можно считать честной?

То есть честной ее можно считать наполовину, только для тех случаев, когда формирование ответа не зависит от сторонних http ресурсов.
Подскажите в общих чертах кто ответственен за валидацию входных данных (микросервис или база)?
Получается, что логика размазывается? И прокси-сервис должен быть в курсе, что в ряде случаев он не просто передает запрос-ответ, но и должен выполнить какую-то отдельную логику (сходить во внешний сервис, получить ответ, вызвать другую процедуру)? Это уже совсем не прокси-сервис.
Если базе надо получить внешние данные, то в этом атрибуте заполняются необходимые параметры — и микросервис выполняет инструкцию и затем дергает хранимку, уже с дополнительными данными. Но такие кейсы нечасто происходят (не более 1% от общего числа запросов)
Теперь я могу вернуться к вопросу
Алексей, возможно Вам попадались не очень качественные проекты на SQL. Не спорю, что даже с небольшим проектом тут можно так наворотить, что никакие магии Postgres не помогут.
И ответить: Нет, просто эти проекты гораздо сложнее банального CRUD'а. :)
И это не камень в ваш огород, ничего не имею против задач где не нужна сложная логика. Просто нужно правильный инструмент для каждой задачи выбирать, а не пытаться ломом крутить гайку.
Все зависит от конкретного проекта.
А если вспомнить что есть еще не чистый json, но и какой-нибудь odata, то вообще можно вешаться с таким подходом.
Это совсем не так.
Автор утверждает что гораздо дешевле, быстрее, проще и безопаснее данные (что автор подразумевает под «данными» он тоже ответил в каментах выше) обрабатывать в БД
А в чём проблема на входе до запуска хранимок преобразовать xml в json/ Какие-то надуманные проблемы… Вы так говорите как-будто автор утверждает что остался один чистый SQL.
Это совсем не так.
Автор утверждает что гораздо дешевле, быстрее, проще и безопаснее данные (что автор подразумевает под «данными» он тоже ответил в каментах выше) обрабатывать в БД
Честно признаюсь — мне уже сложно отследить мысли автора разбросанные по десяткам веток комментариев.
По моему мнению, база не должна заниматься парсингом входящего запроса и генерацией готового вывода. Потому что вот эти все преобразования — это уже начинаются костыли из-за того что весь проект живет сегодняшним днем.
Вы совершенно правы! Парсить POST и генерить в ответ HTML или JSON вполне может некий универсальный прокси. Но он как-то будет при этом общаться с БД. И тут, внезапно, оказалось, что для обмена прокси с БД можно использовать JSON и этот прокси практически не нужен. Ну его и убрали, что тут плохого? Будет нужен SOAP — вот тогда и допилят прокси XML <-> JSON. Это не сложно, я проверял)
XML в JSON однозначно и обратимо не преобразуется. В JSON только два "измерения", в XML минимум 3.
Продукт стал не только быстрее для пользователей, но и гораздо проще для работы: теперь команде легче вводить и тестировать новые функции. Мы привели документацию в порядок, а код стал примерно в 40 раз меньше, так что новые разработчики легко разберутся в том, как устроен сервис.
Хочется верить, что все эти изменения и правда были не зря, и что все выводы не умозрительные, а хоть как-то подтверждены на практике =)
Надеюсь у Вас всё получится!
Эх, действительно на лендосе контакты не предусмотрели, вот тут есть контакты если что https://lingualeo.com/en/contacts (доступно для неавторизованных пользователей)
З.Ы. надеюсь, ребята саппорт-то не сократили в порыве оптимизации =))
habr.com/ru/company/lingualeo/blog/515530/#comment_21965660
Остается только дополнить, что отчаявшись добавил рассылку в спам, какое-то время срабатывало, а вот буквально позавчера снова как-то мимо спам фильтра пролезло письмо.
О божечки! Десять лет прошло с того момента, как я столкнулся с точно такой же проблемой! Даже ответ точно такой же. С — Стабильность.
чтобы слал реквест в базу в JSON и отдавал от нее же респонс
А для обработки данных как раз Постгрес отлично подходит. Любая сложная система использует стэк технологий — вопрос правильной балансировки между ними…
Вся логика этой функции вместе с исключениями и сложными правилами деления текста раньше была написана на JavaScript на фронте. Функция была очень громоздкой, перевод мог занимать много времени.
Перевод же не был реализован на фронте? Или я неправильно распарсил выражение?
Мы реализовали эту функцию в базе данных.
Кстати, действительно интересно, насколько вообще приспособлены движки баз данных (и postgresql в частности) для обработки больших текстовых строк (разбиение, поиск, что там ещё понадобилось для парсинга?).
Кстати та функция разбиения на js — моя гордость ^__^
Она конечно сложноватая, но вовсе не потому, что там много исключений для текста — их там вообще не было и базовая логика разбиения выглядит почти как
text.split(/\s+/).map(word => `<tran>${word}</tran>`);(конечно там не так написано, в то время, когда она писалась ещё es6 не был в моде, зато был жив ещё jQuery :-))
Вся основная сложность там заключалась в учёте тегов, которые есть в html (старая переводилка работала не только для джунглей но и для субтитров и курсов, в которых были нередки вкрапления html-а) — надо было обернуть текст в теги так, чтобы это не ломало вёрстку и при этом слово выделялось в тег, т.е. учесть варианты типа <b>pre</b>position и не сделать из этого двух раздельных переводов =)
А так же при этом надо было учесть, что ты оборачиваешь живой DOM, на элементах которых могут висеть обработчики событий и нельзя всё содержимое блока перезаписать через innerHTML
Потому что для меня, как пользователя — это хрестоматийный пример того как не надо делать переработку легаси продукта.
Потому что это было ужасно. Прям ужасно. Релиз абсолютно новой, жутко сырой и кривой версии сайта, безо всякого предупреждения и возможности фолбека на старую. Я сам лично сдался и потребовал деньги за премиум обратно через 2 недели, а я был настроен использовать лингвалео долго и серьезно. Официальные каналы в соцсетях были похожи по уровню негодования на каналы авиаперевозчиков в пандемию: чистейший шторм гнева от пользователей с полной невозможностью поддержки и сммщиков как-то это остановить. И это продолжалось несколько месяцев.
Вам повезло если в итоге по результатам пандемии ваши усилия окупились. Но это чистой воды везение, техническая реализация была ужасающей.
И раз вы предлагаете задавать вопросы:
— какой процент пользовательской базы вы потеряли в первые 3 месяца после выхода этого проекта в продакшн?
— Что бы вы, вернувшись в прошлое и начиная этот проект заново, сделали бы точно по другому?
Да, потери пользователей были, но большинство оценили новшества плюс пришло много новых пользователей.
— Мы офигенные. Нам все говорят что мы офигенные. Наша главная ошибка, что мы не были еще более офигенными.
Да, потери пользователей были, но большинство оценили новшества плюс пришло много новых пользователей.
Если не секрет, в компании есть отдел аналитики, который численно эти вещи измеряет?
У нас мало хранимок (около 100), в каждой 200-300 строк кода. В ближайших статьях я приведу примеры решения задачи на PHP и pgSQL — почувствуйте разницу
В ближайших статьях я приведу примеры решения задачи на PHP и pgSQL — почувствуйте разницу
О, вот это действительно интересно
У нас мало хранимок (около 100), в каждой 200-300 строк кода.
Т.е. миллион строк на PHP транслировался в 30 тысяч на SQL? Что-то слабо верится...
Если пытаться обрабатывать данные в стиле PHP (сделал простой запрос, получил сырые данные в массив, обрабатываешь через множество циклов и условий и т.д.), то скорее всего код только вырастет
В каких-то абстрактных случаях страшного говнокода — согласен, такое возможно.
Но если SQL использовался по назначению, а не просто в духе "SELECT * FROM table1 и потом джойны в приложении через lookup в хеш таблицах" и код приложения написан адекватно — такого упрощения добиться нельзя.
PL/SQL беден до ужаса и писать там что-то адекватное чуть сложнее парочки IF-ов — боль, я не понимаю зачем люди это делают.
Я видел несколько различных больших проектов (e.g. большая ГИС система, управление активами в страховой компании) где вся бизнес-логика была в БД (в основном — MS SQL), клиентские приложения ходили напрямую в базу. Это архитектурный и инженерный ад, никому не пожелаю такое поддерживать.
Фактически, хранимки — это и есть микросервисы: кидаешь ей json — в ответ получаешь json с нужными данными. 100-200 хранимок по 200-400 строк кода — это с одной стороны достаточно крупный проект, со сложной бизнес-логикой, а с другой стороны несложный для поддержки и развития
Есть только один вопрос, как и где вы описываете типы, что лежат в jsonb?
Сломали всем шаблон
вот уж точно
и при этом добились превосходных результатов
вот тут уж время покажет (а когда покажет уже на самом деле и интересно ни кому не будет — забудут уже)
В PG типы внутри jsonb не описываются: можно из объекта получить нужные атрибуты, в виде json или строки, и дальше с ними работать. Непривычно, наверное, но получается достаточно удобно в итоге.
1. Прокси-сервис у нас на GoLang, он как раз занимается балансировкой запросов к Мастеру и Слйэвам, плюс обеспечивает взаимодействие с внешними сервисами
2. «Сохраненные запросы» — это VIEW вы имеете ввиду? Вьюшки мы используем только для внутренних целей (быстро получить данные напрямую из базы). Все запросы снаружи (от прокси-сервиса) идут через хранимки.
3. Деплой довольно простой, с помощью SQL-скриптов: сначала сохраняется текущий хранимок (это просто большой pgSQL-запрос на пару мегабайт), затем выполняем аналогичный pgSQL-запрос с новым кодом.
4. Данные хранятся в одной базе, с одним Мастером и несколькими Слэйвами (мультимастер пока не требуется), а сами хранимки — это фактически и есть микросервисы: каждая хранимка обрабатывает конкретный запрос фронта (например, получить список словарей, получить профиль пользователя, и т.д.). На выходе дает json со всеми необходимыми данными.
Мы планируем в сентябре выложить в публичный доступ шаблон такой системы — с простой и гибкой структурой данной, примером нескольких хранимок, с прокси-сервисом.
3. CREATE OR REPLACE вполне достаточно. За счет версионности (атрибута «apiVersion» во входном json) новые хранимки поддерживают и старые форматы запросов / ответов, поэтому накатить их спокойно можно до обновления самого приложения
4. У нас одна схема, в ней 12 рабочих таблиц плюс еще 4 служебные. Никаких foreign ключей тут не требуется, т.к. обновление данных идет только в хранимках, там можно всю необходимую логику поддержать (например, обновлять данные сразу в нескольких таблицах)
Я сторонник позиции «чем проще — тем надежнее»)
1) Приструните свой PR-отдел, который какое-то время назад свихнулся и стал слать мне письма каждый день, иногда раз в 2-3 дня (пруфов, к сожалению, нет, ибо скормил спам-фильтрам, сейчас есть только одно вчерашнее письмо).
2) Почините кнопку «Отписаться» в своих PR-рассылках, которая ведёт на главную страницу. Я не должен логиниться, чтобы отписаться от рассылки, ни один уважающий пользователей сервис так не работает. Я не помню свой пароль и я из принципа не собираюсь его восстанавливать и логиниться только чтобы отписаться. Со своей стороны я решил проблему тренировкой спам-фильтров (это гораздо проще) и твёрдой уверенностью, что никогда не буду пользоваться вашими услугами, которой я с готовностью делюсь со знакомыми.
А можно правильный ответ в студию? Для андроид-разработчика звучит как «что лучше — tcp, ip или http?» пока.
Мы проводим регулярные встречи и общаемся напрямую, поэтому разработка стала более прогнозируемой, сроки сократились. Технический директор может принять нерациональное решение, например, неправильно распределить ответственность между командами. В системе, где лиды общаются без дополнительного слоя менеджеров, вероятность нерациональных решений снижается: любую проблему мы всегда можем обсудить в личной беседе.
Например, если я понимаю, что какую-то функцию в новой структуре будет логичнее реализовать в базе данных, а не на фронте, я пишу в чат и обсуждаю идею с лидером фронтэнда. Не нужно договариваться о встрече с техническим директором или готовить презентацию, чтобы подкрепить свою идею.
И что вы делаете, когда в это же самое время лидер фронтэнда понимает, что эту же функцию будет логичнее реализовать на фронте, а не в базе данных?
Драка, очевидно же. Кто победил, того и функция.
Чаще бывает так, что достаточно в ответ с бэка добавить один атрибут — и код на фронте уменьшается в 2 раза. Так почему это не сделать, потратив 30 минут на бэке и сэкономив десятки часов на фронте?
Т.е. у вас пока не возникало ситуации, когда каждый из лидов тянет одеяло на себя? Что будете делать, если когда эта ситуация возникнет? Кто у вас отвечает за функционирование всего сервиса? Кто задает общую техническую стратегию развития? Кто представляет компанию с технической стороны перед партнерами / инвесторами? Кто занимается распределением бюджета и отвечает за этот бюджет? И кто, собственно, распределяет ответственность между командами (правильно или неправильно, это уже другой вопрос)?
По-моему, у вас какое-то странное понимание задач CTO. Но если он у вас действительно занимался только тем, что "распределял задачи по разработчикам" – то может и правда, такой CTO был не нужен.
Техническая стратегия развития задается каждым тим-лидом по своему направлению: тим-лид веба выбирает технологии для веба, тим-лид мобильных приложений — для приложений. В итоге получается более верный выбор, чем видение одного (пусть и очень квалифицированного) CTO.
Также по бюджету: тим-лид формирует команду и определяет бюджет. А ответственность распределяется достаточно просто: фронт и бэк взаимодействует через API, есть четкая документация параметров запросов и ответов. Это позволяет в случае ошибок понять, где она произошла. И поправить.
Если все тим-лиды заинтересованы в быстром и качественном развитии сервиса, то нет смысла кому-то тянуть одеяло на себя во вред проекту.
Простите, но это какая-то наивная и идеализированная позиция. FE lead говорит, что эта логика должна быть на фронте, потому что так будет лучше для проекта. BE lead говорит, что эта логика должна быть на бэке, потому что так будет лучше для проекта. Что дальше?
Техническая стратегия развития задается каждым тим-лидом по своему направлению
Т.е. общей стратегии нет. Какой-нибудь банальный выбор систем логгирования / мониторинга ошибок / аналитики – и каждый будет городить свой колхоз?
В итоге получается более верный выбор, чем видение одного (пусть и очень квалифицированного) CTO.
Единая (пусть не идеальная) стратегия почти всегда лучше, чем ее отсутствие. Лебедь, рак и щука искренне старались выполнить задачу, у них не было цели навредить проекту.
Также по бюджету: тим-лид формирует команду и определяет бюджет.
Так а кто определяет общий бюджет для всего IT? У вас CEO садится вместе с лидами, слушает каждого и распределяет деньги? Так значит у него просто достаточно свободного времени, и он может взять на себя роль CTO.
Не знаю, я чаще встречал обратную ситуацию когда фронт говорил "Ну пусть бек сделает, а мы просто дернем", а бек говорил "мы тут отдаем все данные нужные, дальше фронт пусть как хочет их обрабатывает" :)
Раз в квартал обычно какие-то корректировки происходят. Изменяющиеся бюджеты – элементарно: если компания растет, нужны новые разработчики, нужен больший бюджет; если половина пользователей из-за спама сбежала, возможно надо урезать бюджет, сократив пару сеньоров (а то еще прочитают пару книжек и узнают, что бизнес-логику выносить в БД не принято). Кто будет принимать решение, какой команде сильнее урезать бюджет? Какой адекватный лид скажет: "Да увольняйте половину моих, от них все равно толку мало"?
Ну и вообще-то нормальному CTO и кроме бюджета обычно есть, чем заняться. Я ж про это выше и писал.
Простите, но это какая-то наивная и идеализированная позиция. FE lead говорит, что эта логика должна быть на фронте, потому что так будет лучше для проекта. BE lead говорит, что эта логика должна быть на бэке, потому что так будет лучше для проекта. Что дальше?
Мне как-то в одной конторе в подобной ситуации на полном серьезе сказали — а мы будем кидать монетку.
Несколько лет назад бросил пользоваться сервисом в том числе из-за ужасных тормозов веб-версии, которые на не свежем железе и браузере стали невыносимыми. Есть повод попробовать вернуться, спасибо за проделанную работу!
Сколько теперь компания тратит на каждого пользователя, ведь процессорная нагрузка у серверов выросла?
Да, пост для меня разрыв шаблона.
Автору респект за то, что не гонится за модными микросервисами и умеет отстаивать свою точку зрения.
Я все же сторонник "тонкой" БД, чем меньше логики в БД — тем лучше. Хранимые процедуры сложно покрыть юнит тестами, как я понял автора они используют подход который ближе к интеграционным тестам.
Прекрасно понимаю, программистов которые не захотели становиться программистами хранимых процедур, я бы тоже, наверное, ушел.
Ну и мотивация, что технологии на которых был написан проект устарела за 10 лет, и давайте все перепишем на хранимые процедуры — немного хромает. Имхо хранимые процедуры устарели ещё более чем 10 лет назад — а это выливается в стоимость поиска новых кадров, стоимость замены программистов.
А вообще, рад за автора, что проект получился успешным и желаю этого и в долгосрочной перспективе.
Важный момент: хранимки стали эффективными буквально последние 2-3 года. 10+ лет назад они были совершенно бесполезными, особенно в PG.
Судя по количеству комментариев, интерес к теме большой — приступаю к написанию след. статьи на тему хранимок.
стоимость поиска новых кадров
IMHO это основная причина не использовать возможности предоставляемые БД.
Разработчиков БД на рынке на порядки меньше чем Backend.
Спасибо, что неравнодушны к сервису — будем стараться оправдать ваши ожидания
Вижу некоторую долю обмана (процентов 60?) в этих словах.
Возможно во мне говорит моя предвзятость и нападки на ребят с которыми я работал, возможно тут говорит предвзятость автора, который не смог сойтись с ребятами по каким-то организационным вопросам — кто знает?
Помню тоже пошёл в LL из-за одной такой подобной статьи от LL в давние годы… Хорошие были времена! =)
Надеюсь ребята и правда начнут писать больше технических статей
Особенно учитывая то, что на проекте на котором я работаю поступили ровно наоборот — в ходе разработки изменили архитектуру и переносят бизнес-логику на backend.
Наблюдаю и готовлю материалы для статьи «Как мы изменили архитектуру разрабатываемого проекту и чем это кончилось» ;-)
Печально это всё… Вынести бизнес-логику в хранимки — это такой же путь в один конец. Этот код так же превратится в легаси и умрёт с приходом нового CTO\лида разработки.
Ну с другой стороны, он взял и сделал. Да, сделал "как я умею", но что уж. И проживут они еще какое-то время, особо если перестанут расти активно. Главное, что бы новый CTO, когда будет все переписывать, не оказался такой же "ах, черный ящик, зачем разбираться, давайте перепишем все потеряв половину".
Перефразируя старый слоган: "Born to be legacy". Он не станет легаси, он изначально таковым появился.
Спасибо за статью. Неожиданные поворот, как уже многие успели отметить. Появилось несколько вопросов, буду рад ответам. Заведу по саб-треду на каждый вопрос.
В комментариях выше вы упомянули, что "у нас все хранимые функции поддерживают параметр apiVersion". А как выглядит сигнатура ваших хранимых процедур? Какой тип (типы) данных обычно принимается и возвращается из процедур? Возможно, могли бы привести листинг какой-то типовой, но не сильно секретной процедуры?
Все хранимки — это один json на входе, один json на выходе. Других вариантов нет (и пока необходимости не было).
Хранимки достаточно стандартно устроены:
1. Проверяются атрибуты json (например, если это ID пользователя, то должны быть только цифры)
2. Селектом читаются из таблицы актуальные конфиги (урлы, параметры для расчетов и т.д.)
3. Запускается SQL-запрос (для разных версий может быть разный):
WITH
…
тут идет выборка данных из рабочих таблиц в CTEs
…
SELECT jsonb_build_object(...) — строим ответный json из полученных CTEs
INTO ljResult
4. RETURN ljResult
5. Обработка EXCEPTION
Листинги планируем приложить в следующей статье плюс на гитхабе выложить
В том же PHP последние годы активно развиваются статические анализаторы: Psalm, Phan и Phpstan. Есть что-то подобное для хранимок? Пользуетесь?
Не-не, это не то) Статический анализ это не про оптимизацию работы. Это про отлов потенциальных ошибок. Почитайте про https://psalm.dev/ и буду раз уточнённому ответу.
Как реализована обработка ошибок? А исключений? Как это потом транслируется в HTTP ответы?
Все SQL-ошибки в итоге выводятся на дашборд — очень удобно их отслеживать и оперативно исправлять
То есть продцедура с бизнес-логикой знает про то, что она будет вызвана в контексте HTTP запросе?
Для обновления хранимки не надо делать миграцию БД)
А как поддерживается версионность? Допустим есть БД на ервере который несколько месяцев никто не обновлял (сколько точно никто не помнит). Как узнать, какая версия хранимок там?
Допустим, у вас не используется этот подход. Ваше дело, хотя и странное. Получается, для изменения текста ошибки на фронте мне придется на прод выкатывать… что? В случае с миграциями, релиз будет состоять в запуске одного скрипта, который выполнит alter stored procedure, а в вашем случае релиз в чем состоит?
Надо для релиза накатить 3 хранимки — запустил три запроса
А эти запросы лежат в какой-то системе контроля версий? Как гарантируется консистентность нескольких баз? Грубо говоря, есть ли у меня возможность узнать, что моя бд такая же как у Пети, а у Васи — такая же как на проде?
Получается у вас нет миграций и все изменения в базе вы накатываете руками? Как, в таком случае, синхронизировать базы разработчиков?
А логирование у вас включает логирование входных, выходных фактических параметров?
А функции insert/update/delete как логируются?
А сколько exception может быть в процедуре?
Т.е. выше вы писали, что есть страница всего с одним запросом sql. Неужели в этом запросе обрабатываются ВСЕ возможные ошибки в рамках одной страницы?
Как решается взаимодействия с внешним миром? HTTP запросы через pg_curl? А что-то кроме HTTP?
Для PHP есть куча библиотек в OpenSource, которые решают множество мелких (и не очень) задач прикладного уровня. Такого изобилия в SQL мире нет. Вы были осознанно готовы отказаться от этих благ? В обмен на что?
Конечно, есть много задач, не связанных напрямую с базами данных. Обработка видео, например — нет смысла это тащить в базу.
Все операции у программистов связаны с обработкой данных :), так что ответ не по сути вопроса.
Вот мне нужно работать c событиями – я возьму одну из реализаций event-dispatcher. Нужно работать с платежами – посмотрю на OmniPay. Понадобится oAuth2 – возьму oAuth server. Нужно будет по этому сгенерироать Swagger документацию – найду чем это сделать.
Такого выбора для хранимок на постгресе я не вижу. SQL мире нет. Вы были осознанно готовы отказаться от этих благ и писать+поддерживать всё своими силами?
Какие инструменты используете для отладки, профилирования хранимых процедур?
EXPLAIN ANALYZE – это про план выполнения. Я скорее про отладку логических ошибок.
отладку логических ошибок.
Логирование выполнения хранимых функций
На этапе прода, в принципе можно отключать
На отладке, без этого сложно.
Логические ошибки приводят к неверному ответу хранимки (пустые списки, нет нужных данных и т.д.)
del
А вообще, чего я разворчался. Сервис работает, старые фичи потихоньку возвращают (спасибо!), новые фичи добавляют (изучение новых языков — это круто, пусть и в beta ещё).
Пока код обрастёт легаси пройдёт ещё несколько лет успешного развития, так что — а почему бы и нет?
В общем, жду дальнейших статей по хранимкам — может и не так страшен чёрт, как его малюют
это было невозможно.
Защищать проект было сложно, потому что под рукой не было однозначных историй успеха: никто не пишет о том, как провести миграцию сервиса с 20 миллионами пользователей без остановки бизнеса.
Как это «никто не пишет»? Мы в Яндекс.Деньгах в 2016 году проводили миграцию базы всех пользователей и истории их платежей с Oracle на Postgres без простоя. И поделились этим на PgDay в 2017 году: pgday.ru/ru/2017/papers/154 и тут на Хабре: habr.com/en/company/yamoney/blog/326998
Всегда рассматривал PG + postgrest как быструю реализацию для несложных проектов сервер-клиент. Postgrest тут, как простой и стабильный веб-сервер для прямого маппинга таблиц PG в RESTful API. Преимущество в том, что по сути выкидываем из 3-х звенной архитектуры, звено с сервером приложений. Недостаток — риск в том, что при определенных задачах формирования данных для клиента, мы переносим бизнес-логику в звено с СУБД.
Вот задачу связанную со структурой данных должен решать отличный профессионал, который прекрасно понимает и реляционные модели и иерархические, знать SQL, NoSQL и т.д. Иначе будет боль и разочарование. Это как от SQL к NoSQL и видишь большие глаза SQL-разработчика, который не понимает, что теперь имя юзера хранится чуть больше, чем везде где только можно, а не в одной таблице.
Вопрос, у вас структура данных учитывает особенности такой архитектуры с PG и JSON? Насколько она очевидна и проста?
Мы постарались сделать очень простую структуру данных: это всего 12 таблиц, в сумме 70 колонок и 15 индексов. При этом в этих таблицах хранятся данные по 100+ сущностям.
Я активно пропагандирую модель SQL-NoSQL, когда данные быстрой выборки хранятся в числовых колонках, а дополнительные атрибуты — в json-поле. Это позволяет с одной стороны быстро получать нужные данные даже из больших таблиц, а с другой стороны позволяет быстро добавлять новые сущности и атрибуты без изменения структуры данных.
Вот пример таблицы:
entity_id integer
key_id integer
index_scan bigint
jdata jsonb
Первичный ключ по entity_id, key_id, в ключ включен index_scan для Index Only Scan запросов.
Это универсальная таблица, в которой можно хранить сотни разных видов справочников.
CONSTRAINT entity_list_pkey PRIMARY KEY (entity_id, key_id)
INCLUDE(index_scan)
Как вы тестируете логику в хранимках? Есть ли автоматизированные тесты?
habr.com/ru/company/lingualeo/blog/515530/#comment_21964956
Верно ли я понимаю что у вас одна хранимка может вызывать внутри себя другие в зависимости от условий?
У нас есть небольшое количество сервисных хранимок, которые не вызываются снаружи, а используются только другими хранимками. Они довольно компактные и редко меняются.
PS: из примера система стала такой не сразу, примерно за 15 лет. По мере обрастания функционалом.
Странной показалась фраза о трате аж целых 1000$/год на инфраструктуру — это разве много?
Нет, ребят. Стало хорошо от переписывания.… и от частичной чистки от «ненужных» данных. Не хочется «каркать», но впереди автора ждут большие приключения. Как минимум в случае если не удастся сделать легковесное решение какой-нибудь новой бизнес-логики в хранимых процедурах и придется либо «опять все с нуля», либо «выносить часть логики наружу», потом 2..3 года, потом новая статья в таком же духе. Ничо не меняется в этом мире )))
Ну чтож, полный разрыв шаблонов и выглядит как набор антипаттернов по всем пунктам статьи. Но если работает — может таки и надо мыслить гибче…
У меня была похожая мысль так использовать постгрю — сейчас у нас данные в монге лежат. Но, в отличие от автора у нас без серьезного исследования и доказательства профита от переезда "полность сменить парадигму" нельзя. А на тех проверках что я сделал постгрес +- показывает произвоидтельность монги на наших задачах. ПРофит можно получить тонкой подстройкой (монга как сортировка слиянием, худший средний и лучший случаи совпадают), но он не такой чтобы реально переезжать.
А схема там была такая же, да: храним данные в jsonb (как в монге), и денормализуем данные по которым часто ищем в отдельные колонки.
Поэтому мы перенесли бизнес-логику Lingualeo в базы данных на PostgreSQL
А вы знаете толк в извращениях. Разработчиков не жалко? Всегда покрывался холодным потом когда смотрел как MS SQL DBA ищут и фиксят баги в процедурах… копипастят и комментят код (ручной гит лол).
Больше чем уверен что сейчас там все красиво. Можно статейку через годик-два о том как вы это все дебажите, ревертите и т.д?
Мы уже более года живем на новом бэке — пока только положительные эмоции. Новые статьи не за горами — подписывайтесь на наш блог
Когда был баг, они открывали процедуру, и начинали шаманить. Делалось это так:
- Сначала с утра слышны крики — «Как это возможно? Вчера же работало?»
- Потом они открывают файлик с процедурой на 1000 строк и охреневают. Это я писал?
- Копируют эти 1000 строк и вставляют рядом с комментом «revision +100500, fixing bla bla bla»
- На лету фиксят че-та, и пушат в базу
Это был ад в плане мейнтененса и разработки фичеров.
Так а как тестировать логику в БД? Для кода можно тесты написать, зависимости мокнуть, вот это всё. А в БД как?
Есть варианты, в т.ч. pgtap, но тут ничего сложного и дело вкуса, можно повелосипедить, например так:
-- Пример для функции `rpc.func_args(TEXT)` которая возвращает строку таблицы
SELECT pgmig.assert_eq('func_args' -- название теста
, (SELECT row_to_json(r) FROM rpc.func_args('func_args') r)::jsonb -- got
, '{
"arg": "a_code",
"anno": "Имя процедуры",
"type": "text",
"def_val": null,
"required": true
}' -- want
);
ROLLBACK TO SAVEPOINT test_begin; -- откатить изменения, если они быливыполняется в той же транзакции, что и создание функции. Если assert_eq вызовет EXCEPTION — транзакции не будет
Но что насчет связующих компонент? Фейковый сервер платежей, фейковые шлюз отправки СМС уведомлений и вот это всё остальное?
Если я правильно понял посыл автора, то он в том, что есть плюсы от размещения в БД логики, которая оперирует только данными, размещенными в этой же БД. В этом смысл хранимки — держать код рядом с данными. Да, технически можно из БД лезть куда-то еще и иногда это даже оправдано, но статья не об этой технике.
Т.о. на Ваш вопрос ответ такой — интеграционные тесты делаем как обычно, за рамками БД.
Ну автор говорит что они всю логику в БД запихнули. А "если произошли такие-то события то нужно сделать такие-то уведомления" это и есть бизнес логика. Сама отправка это уже инфраструктура, да, но принятие решения — логика. Ergo у них это в постгресе.
Да, это, на мой взгляд, косяк автора — не смог найти слова, чтобы его поняли правильно. Я сбился со счета, сколько раз ему в итоге пришлось постить разъяснения вроде этого. Если не хотите, чтобы он еще раз повторил, предлагаю остановиться на моей версии. По ней это "если произошли" надо читать как "если в БД произошли".
Когда мы поделились планами с разработчиками, стало понятно, что команда не готова к изменениям. Большинство людей покинули компанию: остались только те, кто пришёл совсем недавно.
Да, помню, было так же на одном из предыдущих мест. Пришел новый лид бэкэнда, собрал команду, предложил идеи и просил критики. Часть идей встретили хорошо, часть очень критично. Были предложены альтернативы. По итогу — все альтернативы были выкинуты и осталось всё так, как лид решил сначала, не смотря на потенциальные проблемы. Ушла большая часть команды.
Не смотрели в сторону других баз данных?
Monga, Cassandra, Tarantool?
Кроме того, пока не обнаружено каких-либо подводных камней в PG — весь необходимый функционал есть, шикарная скорость (особенно на классических B-Tree индексах), работа с json(b) тоже выше всяких похвал.
шикарная скорость (особенно на классических B-Tree индексах), работа с json(b) тоже выше всяких похвал.
Ребят, давайте быть профессионалами и подкреплять слова цифрами. Какие ни будь примеры табличек, связей, данных, запросов, количества данных в таблицах. Потому что пока что есть обещания статей и комплименты в адрес PG SQL. У каждой технологии есть как плюсы, так и минусы (на определенном типе задач). И всегда неплохо было бы знать о минусах, чем о плюсах.
Не хочу критиковать вашу работу, но в 2020 хранить бизнес логику в хранимых процедурах в БД… бр… режит слух)
Не только бизнес логику, но ещё и сообщения об ошибках, которые вывести пользователю
:)
EXCEPTION есть в каждой хранимке. В ней формируется ответ на фронт (с описанием ошибки)
Вот цитата автора. Выглядит так, как будто формируется именно ошибка с текстом.
А для меня выглядит так, что кроме кода ошибки есть еще какие-то атрибуты)
И там еще ниже было:
На фронт возвращаются в основном коды ошибок. Текст тоже бывает, если надо его локализовать под язык пользователя.
Например, если я понимаю, что какую-то функцию в новой структуре будет логичнее реализовать в базе данных, а не на фронте, я пишу в чат и обсуждаю идею с лидером фронтэнда.
а лидер фронтэнда считает, что функцию лучше реализовать в БД… и?
обсуждение затягивается… время идет…
а раньше был арбитр, разрешающий эту неопределенность…
а лидер фронтэнда считает, что функцию лучше реализовать в БД… и?
Не припомню случая, чтобы решение данного вопроса занимало более 30 сек.
т.е. «нет так нет, ну ок, сделаем в БД ...»?
(потому и 30 сек)
Какие книги по архитектуре вы до этого прочитали, прежде чем приняли такое решение?
Имхо, стоило сначала разобраться в вопросе, прежде чем утаскивать всех в базы данных.
Обсуждение полной архитектуры веб-сервисов — это наверное темы других статей
Не очень корректно разобрали. Многолетнее легаси и написанное с ноля даже без воспроизведения существующей функциональности и сохранении всех данных.
30 лет, в 2020 году выступал там
Можно ссылку на выступление?
Спасибо.
Думаю речь про вот это:
Собственно как я и предполагал, автор — опытный базист, который стал СТО и теперь все задачи решает через базу. К чему это приведет — ну посмотрим лет через 5. Надеюсь, кто-нибудь из новичков которые придуто тогда на проект на хабр напишут статью о своих приключениях.
Моя любимая цитата из доклада: "Нет внешних ключей — нет проблем".
Насчет внешних ключей написал в комменте к статье
habr.com/ru/post/515628
Там как раз идет конструктивное обсуждение разных кейсов с хранимками
Написали бы так в посте, отпало бы 70% процентов коментов...
вы не одиноки в выборе хранения бизнес логики на уровне БД.
Реализовал тоже самое — habr.com/ru/post/515628
Хотя в моем случае ситуация диаметрально противоположная — идет перенос бизнес логики на уровень backend. Аргументов в пользу данного решения, услышать так и не удалось.
Как кстати и в комментариях к данной статье.
Это какая-та, условно говоря, папка с текстовыми файлами, при деплое какими-то скриптами «загружаемая» в БД, или новые/измененные процедуры вы загружаете в БД руками, или вообще по-другому все происходит?
1. Запускается SQL-скрипт, который все хранимки собирает в одном большом pgSQL-запросе (на пару мегов)
2. Это запрос выполняется на Мастере
Можно также не все хранимки, а только часть залить
Например, чтоб посмотреть все имеющиеся процедуры и что-нибудь поменять/добавить, я клонирую репозиторий со всеми процедурами, что-то в него коммичу, и оно потом само CI/CD-шится куда надо, или вся работа идет в условном DataGrip напрямую через БД?
Так вы прямо в базе всё правите и с девелоперских машин копируете на прод? Без код ревью?
И как оно организовано? Подключаются к чужой базе датагрипом и там комментарии с замечаниями пишут??
Код ревью комментариями в хранимке на едином для всех инстансе БД это просто бомба)
Подход плохо масштабируется на уровне команды разработки. Пока 2-3 разработчика — проблемы масштабирования не видны. Если база продолжит управляться двумя людьми — решение более менее приемлемое. Но здесь другие риски — если проект теряет одного разработчика — теряет большой пласт знаний.
Вы не поняли. Не всегда стоит задача посадить одного человека и хорошо. Наоборот, в некоторых ситуациях для бизнеса это плохо, потому что это единая точка отказа.
Если бизнес маленький — это хорошо. Бизнес вырос — плохо. Контекст важен.
ИС, полностью автоматизирующая средней руки банк...
Автор говорит как раз обратное: всем задачам по обработке данных одно решение — хранимки в СУБД :)
На словах это не проверить, к сожалению.
А можете пример простого SQL запроса привести на этом простом языке? Что примитивное, типа JSON с id, ФИО и сроком окончания подписки для всех пользователей, имеющих активную подписку
, до окончания которой меньше недели осталось с точностью до дня?
RETURN
(WITH "user_list" AS
(SELECT
"user_subscriptions".user_id,
"user_subscriptions".subscr_date
FROM "user_subscriptions"
WHERE ("user_subscriptions".status = 1) AND
("user_subscriptions".subscr_date <= ldLastDate)
)
SELECT jsonb_agg(jsonb_build_object(
'userId', "user_list".user_id,
'userName', "users".user_name
'subscrdate', "user_list".subscr_date))
FROM "user_list"
LEFT JOIN "users"
ON ("users".user_id = "user_list".user_id)
);
Пришлите аналогичный результат на не-SQL языке
Ну написать можно на не-SQL, правда, для конкретно вот этого примера смысла мало. Ну сишарп например:
var userLists = dataContext.UserSubscriptions.
.Where(x =>
x.Status == Status.Updated
&& x.SubscrDate <= ldLastDate)
.Select(x => new {x.UserId, x.SubscrDate};
return userLists
.Join(
dataContex.Users,
x => x.UserId,
x => x.UserId,
(userList, user) =>
user.UserId,
user.YserName,
user.SubscrDate,
userList.SubscrDate)
.ToArrayAsync(); // в этот момент весь этот запрос пойдет в базу и сгенерирует эффективно то же SQL что выше.Хотя даже в этом примере вместо непонятного status = 1 можно написать более понятно с использованием перечисления.
Найти спеца, который отлично знает C# и SQL, гораздо сложнее, чем спеца по SQL. А без знания SQL качество работы с данными будет очень низким.
Собственно, об этом и статья — давайте данные обрабатывать в тех системах, которые для этого созданы.
"Спеца" по сишарпу который не знает LINQ можно смело на собеседовании отправлять домой читать шилдта.
Ну просто вопрос "Знать SQL" понятие растяжимое. Если человек не знает про то в каком порядке например выполняются SELECT/WHERE/GROUP BY или разницу WHERE/HAVING тогда да. А например про GROUPING SETS или аналитические функции прям обязаловки в них шарить я не вижу.
Поэтому сейчас и появилась возможность его активно использовать для 95+% задач по работе с данными. 10 лет назад не было для этого возможностей.
Не поленитесь, попробуйте сами одну-две функции на современном SQL написать. Это реально сдвиг сознания, что с данными можно по-другому работать.
Надеюсь, хватит сил в выходные написать статью с примерами хранимок (и самое главное с примерами их развития с учетом растущих требований проектов). Кидайте идеи, какую проблему будем решать (платежи, емейлинг, ...)
А насколько просто найти спеца по SQL, который хорошо понимает специфику работы HTTP и знает, что нужно делать с заголовками, например, которые передаёт в параметры ваш "прокси"?
Статусы ответов, заголовки откуда он берёт? Из JSON и вырезает их из результирующего ответа? Всегд отдаёт один и тот же набор? Дублирует их из JSON?
Как с обработкой заголовков кэширования, других заголовков прикладного уровня? добавляет их в принятый JSON или полностью игнорирует?
Статус ответа обычно 200 со структурой json и соответствующим Content-Type, описанной в документации, за исключением кейсов связанных неверным запросом или доступом (400/401/403). И конечно 5xx не исключение.
Сама хранимка отдает несколько больше полей в json для целей аналитики, прокси их вырезает и отправляет в сборщик аналитики в фоне, а на фронт летит то, что описано в документации ручки
Есть пара кейсов, где при помощи json описывается http-ответ, т.е. статус, заголовки и тело ответа.
return db.Subscriptions
.Where(s => s.Status == SubscriptionStatus.Active)
.Where(s => s.SubscriptionDate <= currentMoment)
.Select(s => new ActiveSubscription
{
UserId = s.UserId,
UserName = s.User.Name,
Date = s.SubscriptionDate,
})
.ToArrayAsync();
Кстати как у ребят в SQL обстоят дела с константами, понятное дело что значения типа 1, 0 — это еще пол беды, но если например у нас есть тип с множеством значений. И если нужно порефакторить код и переименовать один из типов. Конечно можно replace сделать, но такой подход страдает от неопределенности.
Как производить рефакторинг в SQL?
postgrespro.ru/docs/postgrespro/11/plpgsql-declarations
Насчет рефакторинга: если меняется структура какой-то таблицы, то достаточно обновить SQL-запросы только в тех хранимках, где эта таблица используется. Как правило, это не более 10 хранимок. Отсутствие доступа к таблицам вне хранимок заметно упрощает весь процесс.
Модель SQL-NoSQL позволяет вводить множество новых сущностей без изменения структуры — об этом расскажу в отдельной статье
Разве это не локальные константы? Думаю, вопрос скорее про глобальные константы, которые будут едиными для всех хранимок во всей базе.
Каким образом вы ограничиваете количество хранимок, где используется таблица? Скажем, таблица юзеров у вас правда только в 10 хранимках встречается?
Глобальные константы — это конфиг. Необходимые компоненты вычитываются при запуске хранимки простым селектом.
Таблица юзеров — это скорее исключение, но и структура ее меняется достаточно редко (при условии использования jsonb-поля внутри). А по более специализированным таблицам — да, 3 — 10 хранимок, не больше.
2. Мы говорили о константах для перечислений состояний. Например, у вас есть поле Status, где хранится число — логично, экономно. Числа никто не помнит, если их больше двух, а хранить строки для такого служебного поля — оверкилл. Держать в конфигурации информацию о том, что 1 — это подписка на поздравление с днем рождения, а 21 — на новости о новых фичах — крайне плохая идея, как минимум потому, что сценарий «вот на этом инстансе пожалуйста пускай будет наоборот» становится возможным, но не перестает быть идиотским.
Или под «конфигом» вы понимаете еще одну таблицу в БД?
Уточню, что в моем примере выше использовалась фича языка C# под названием Enum — там можно создавать компайл-тайм константы с привязками к целочисленным значениям, которые спокойно приводятся туда-обратно, но при этом дают возможность на этапе компиляции требовать не 1 или 21, а Subscription.Birthday или Subscription.NewFeatures. Это к вопросу о выразительности и удобстве скуля.
3. Повторю вопрос — каким конкретно образом вы ограничиваете использование таблиц в хранимках? Вы лично бдите за этим? У каждого разработчика есть чеклист? Используется какой-то глобальный тест? Что, если хранимок с данной таблицей уже 10, а мне ну очень нужно сделать новую фичу с ее использованием? А если хранимок уже 12 при этом?
ENUM — это описание типа колонки в БД.
Мы же говорим о коде хранимки, в традиционном бэке есть что то вроде: SubscriptionType::NEWS = 1;, SubscriptionType::OTHER = 21;, и везде в приложении в коде мы оперируем этими типами, а в БД колонка subscription ENUM(1,21).
В случае хранимки есть какой то паттерн/подход к именованию таких типов? И как производится рефакторинг таких типов, например если нужно сменить 21 на 22?
SELECT jsonb_object(key, jsrecord->(value))
FROM jsonb_each_text(ljAttrList)
Я ljAttrList кидаю маппинг (какие атрибуты с какими названиями вернуть), в jsrecord — атрибуты, которые хранимка использует.
Это поддержали, но по опыту не особо пригодилось: в API-документе прописаны нужные названия, их и придерживаемся. Надо добавить пару новых атрибутов — сразу в ответ и добавляем.
function getAlmostExpiredUsers(\PDO $connection, string $ldLastDate) {
$statement = $connection->prepare(<<<SQL
RETURN
(WITH "user_list" AS
(SELECT
"user_subscriptions".user_id,
"user_subscriptions".subscr_date
FROM "user_subscriptions"
WHERE ("user_subscriptions".status = 1) AND
("user_subscriptions".subscr_date <= :ldLastDate)
)
SELECT "user_list".user_id AS userId,
"users".user_name AS userName,
"user_list".subscr_date AS subscrdate
FROM "user_list"
LEFT JOIN "users"
ON ("users".user_id = "user_list".user_id)
);
SQL
);
return \json_encode($statement->execute(["ldLastDate" => $ldLastDate]));
}Как-то так :)
я клонирую репозиторий со всеми процедурами, что-то в него коммичу, и оно потом само CI/CD-шится куда надо
В моем случае — именно так.
После просмотра вашего доклада на PGconf появилось несколько дополнительных вопросов:
1) А при миграции всей бизнес-логики в базу данных, как Вы поступили с логикой, связанной с взаимодействием со сторонними сервисами? Платёжными шлюзами, сервисами отправки email (своими или сторонними), OAuth и прочим, где не обойтись без сетевого запроса от вашего сервиса к стороннему? Где теперь лежит эта логика, и как вызывается?
2) Как в новой архитектуре Вы организовали работу с регулярными событиями и событиями по триггеру (триггеру не в терминах БД, а имею ввиду какое-то ключевое событие — День рождения пользователя, приветственное письмо при регистрации и т.п.).
3) Не приходится ли использовать очереди событий, и если да, то вовлечён ли постгрес в их менеджмент?
Спасибо.
1. В базу мигрировала бизнес-логика, связанная с обработкой данных (все, что можно сделать с помощью SQL). Другую логику переносить в базу данных нет смысла. Взаимодействие с внешними сервисами осталось в микросервисах, взаимодействие между базой и микросервисами — через прокси-сервис.
2. Для триггерных событий мы используем воркер на GoLang, который регулярно (раз в N секунд) дергает определенную хранимку в базе. А хранимка уже по нужному расписанию делает расчеты. Событие по дням рождения, к примеру, рассчитывает в ночные часы, когда нагрузка минимальна.
Приветственное письмо при регистрации отправляется сразу после регистрации: хранимка вместе с ответом фронту возвращает инструкцию для прокси-сервиса, что надо вызвать микросервис «emailing», чтобы он отправил письмо с таким-то текстом на такой-то адрес.
3. Используем, конечно. Например, надо отправить несколько миллионов пушей. За один раз это не сделаешь (внешний API не позволит), поэтому формируется в таблице заданий определенный пул, и по N заданий отправляется на обработку.
Также используем очередь на стороне микросервисов: например, после рассылки приходит миллион нотификаций о статусах доставки. Писать их в базе по одному очень накладно. Удобнее объединить в пакеты по 1000 и одним вызовом записать.
Чтобы любой проект не превратился в легаси, его надо регулярно рефакторить (т.е. переписывать довольно значительные куски кода). Проект растет, появляются новые сущности, меняется структура данных, меняются интерфейсы и т.д.
У нас такая процедура делается ежегодно, занимает 2-3 недели.
К примеру, есть два проекта: в одном 1 млн. строк кода, в другом 30 тыс. строк кода. В рамках рефакторинга обычно переписывается 20% кода (по нашей практике).
Вопрос: на какой из проектов потребуется меньше ресурсов?
Есть задачи и инструменты. Какие то инструменты лучше подходят для решения определенных задач, какие то хуже. Проблемы начинаются там, где говорят, что этот инструмент подходит для всего (Золотой молоток), о чем писали выше. Статья оставляет стойкое ощущение, а точнее не дает четкого определения какие задачи решаются хранимками в SQL, отсюда вся критика и непонимание автора.
Каждому языку есть своя ниша. Главное — использовать по назначению.
В базе только логика работы с данными через SQL.
Как я уже указывал эта фраза понимания не добавляет. Можно передавать в СУБД HTTP-запрос как есть, строкой, и она будет средствами SQL его парсить: методы, пути, заголовки, декодировать json тело, например, и так же строкой возвращать полный HTTP ответ со статусом, заголовками и т. п. Это будет путь прокси.
А можно разобрать запрос в апп-сервере, провалидировать его данные "статически", например на предмет соответствия запроса OpenAPI или JSON-RPC схемам, проверить валидность криптотокенов и только потом передавать. И ещё 100500 вариантов баланса между апп-сервером и СУБД вплоть до единичных запросов без джойнов к каждой таблице.
Главное — это уйти от попыток решать SQL-задачи средствами не-SQL языков. Тогда скорость и качество разработки вырастут в разы (и десятки раз).
Продолжение следует…
Есть SQL-задачи типа джойнов и агрегаций, которые на общих ЯП решаются гораздо хуже, чем на SQL. Есть инфраструктурные задачи, которые на SQL решать очень сложно, если вообще возможно без разработки модулей СУБД. А есть задачи, которые можно решать где угодно и, как я вижу, основная причина решения их вами на SQL — так проще тем, кто знает только SQL, тем, кто считает SQL более лаконичным и выразительным, более масштабируемым и т. п.
При этом за безобидным словом "прокси" вы прячете, как оказывается, довольно сложный то ли сервер приложения, то ли API Gateway
Вот тут привели пример решения задачи выше на PHP:
habr.com/ru/post/515628/#comment_21977132
Есть что сравнивать. И это на очень простой задаче… По мере роста сложности пропасть растет в геометрической прогрессии.
Но, думаю, вы зря считаете, что такие решения стали возможны только с поддержкой JSON. Вариант, когда хранимка имеет список типизированных аргументов и возвращает таблицу, был доступен гораздо раньше и до сих пор имеет плюсом то, что весь АПИ автодокументируется довольно просто. Хоть в swagger, хоть в protobuf.
А скептикам, которые уверены, что подобная архитектура долго не протянет, замечу, что все зависит от людей. А сам SQL консервативен, там не выходит несовместимых версий и хранимки вполне себе живут в проде и 10 лет и 17. И те, кто их не создал, но допиливает, могут быть довольны этим процессом, как и заказчик.
сам SQL консервативен, там не выходит несовместимых версий
Вот ещё кстати аргумент против бизнес-логики в хранимках: они, как правило, очень специфичны для конкретного диалекта SQL и сложность переезда на другую базу возрастает на порядки, субъективно, по сравнению с использованием обычного ЯП с каким-нибудь DBAL.
Какие причины, кроме импортозамещения вас к этому процессу побудили?
Раз 5 за последние 10 лет. Если считать только миграции между SQL диалектами, но не исключать то, где я лично реальные задачи по миграции не делал, но делал PoC и ставил и ревьювил реальные задачи по миграции, консультировал.
Основные причины:
- бОльшая функциональность (mysql -> postgre)
- высокая стоимость лицензий (ms -> mysql, postgre)
- дороговизна эксплуатации и разработки в условиях "зоопарка" (ms, mysql -> mysql, postgre)
Импортозамещения в причинах не было :)
Кстати, да. Есть у хранимок такой аспект — при миграции в другую СУБД код самого приложения может и не придется менять вообще. А только эти хранимки.
Я участвовал в проекте миграции Ora -> Pg, где доступно было только то, что лежит в Ora. Там была одна проблема — старый код хранимок не имел тестов, пришлось их сначала писать. А какой используется "обычный ЯП" и есть ли вообще исходники — значения не имело.
Классически ППКС.
Дело за малым — объяснить все это недавним выпускникам курсов Node.js ;-)
обработка данных должна быть как можно ближе к данным!
Кому должна быть? Допустим, ваша "должна быть" означает "оптимально разместить". И сразу вопрос: по каким метрикам оптимально?
Поражает, что люди слепо используют в повседневной работе архитектурные подходы 2000х, когда вся обработка бизнес-логики по обработке данных была реализована в сервисах — на дворе 2020!!
Поражает, что некоторые люди, думают, что есть только один правильный подход, оптимальный для всех случаев по любым метрикам.
Еще странно что фронтедеры рассуждают о том, что хорошо а что плохо в БД
А можно примеры таких рассуждений?
Ребята сделали все архитектурно правильно
Нельзя судить и правильности или неправильности архитектуры, не зная всех бизнес-требований и планов развития. И вообще, обычно только постфактум можно сказать была архитектура правильной или нет.
Обработка обработке рознь. Базы имеют слабые и сильные стороны, кроме того, есть разные виды нагрузки — например, транзакционная и аналитическая. Далеко не всю логику можно эффективно реализовать поверх конкретной базы, часто как минимум разделяют продакшен и аналитику, то есть уже не один сервис.
> Времена, когда обработка данных выносилась в промежуточные сервисы закончилась еще в 2000х когда появились функции и процедуры в БД.
Ага, именно поэтому последние лет 10-15 мы имеем активное развитие NoSQL-решений и вынесение логики на уровень приложения. А все потому, что это позволяет гораздо лучше масштабироваться и планировать нагрузку.
> Еще странно что фронтедеры рассуждают о том, что хорошо а что плохо в БД
Странно, что некоторые рассуждают на тему того, кому можно о чем-то рассуждать, а кому нет.
> Ребята сделали все архитектурно правильно
Ребята сделали крайне сомнительное с архитектурной точки зрения решение, которое, как выше не раз заметили, с течением времени аукнется довольно серьезными проблемами. При этом избавились от команды хороших специалистов (типа, сэкономили), только вот как-то это слабо коррелирует с количеством людей на рынке, готовых поддерживать простыни чужого SQL-кода.
Понабирают по объявлениям неизвестно кого и потом перевод денег со счета на счет превращается в 3 запроса с АПИ-сервиса в БД (соответственно в 3 раза увеличивая время ответа клиенту) вместо одного но в БД!!!
Я, наверное, сейчас вам Америку открою, но вовсе необязательно время выполнения запроса доминируется именно запросом в БД. Нет ничего плохого в том, что запросов будет несколько, если при этом удастся избежать серьезного вендорлока и чрезмерного усложнения SQL-кода.
пусть теперь фронтендер будет делать вам операцию на сердце??? )
Если он при этом будет профессиональным кардиохирургом — не имею ничего против. Но вообще доведение до абсурда — какая-то незрелая тактика.
Такие архитектурные решения уже десятилетия работают без всяких нареканий
Как мило вы пишете про легаси, которое практически никто не хочет идти поддерживать даже задорого. В отличие от кода на питоне/плюсах/джаве/пхп.
NoSQL во многом были разработаны под влиянием дилетантов желавших работать с базами данных но не освоивших теорию
Глупости какие. Они были разработаны именно как воркэраунд для негибкости традиционных реляционных баз в контексте масштабирования, попутно досыпая такие полезные плюшки, как data locality, нормальный полнотекстовый поиск и примитивные атомарные операции и структуры, типа CRDT.
все осознали что выполнять запросы с клиента — это вообще антипаттерн
Это откуда у вас такая уверенность? Или вы сейчас будете искренне доказывать, что прибитый гвоздями к конкретной базе (даже версии базы) проект, который нельзя ни тестировать нормально, ни моделировать на стенде — это хорошая практика?
Разумеется, это не так. Даже в случае дата-аналитики пихать везде Hive или Presto — далеко не всегда оптимальное решение. Иногда гораздо разумнее обучить людей языку программирования, чем давать им молоток в виде SQL и делать вид, что все проблемы вокруг — это гвозди.
Как мы отказались от хранимок и перевели логику на бэкенд
Долгие годы наша компания страдала из-за сложности изменения кода в хранимках. Невозможность написать тесты, сложность использования контроля версий, постоянный геморрой с вызовом внешних сервисов, обработкой ошибок, работой с персистентными коннектами, записью данных на диск и чтением с него, прибитость гвоздями всего-всего-всего с базе данных у которой оказывается свои ограничения — все это привело нас к решению перевести код на бэкенд и сжечь логику внутри хранимок.
Вопрос возник: а графику в базе храните или как?
Я вот честно скажу- пока читал статью, у меня волосы шевелились во всех местах одновременно. Описанные решения- это такая лютая дичь, что в некоторых моментах я начал сомневаться, а не первое ли сегодня апреля — мб это чей-то такой тонкий тролинг?
НО. К концу чтения у меня сложилось впечатление, что всё вот это вот можно просто рассматривать как некий манифест. Мол, вертел я ваши паттерны, архитектуры, ci с их cd и прочую хипстоту. Деды не для того ныли на Оракл, чтоб теперь всё это бросить — наш проект достаточно мелкий, чтоб взять и написать херню, зато прикольную. Похерить часть данных по пути и доказать всему хабру, что поделка уровня студенческой работы по основам реляционных бд (кстати препод бы за такое банан поставил, потому что про нормализацию в таком формате хранения, как предложил автор, заикаться не приходится) тоже может выдерживать нашу нагрузку в перспективе года-двух. А там уж либо ишак либо падишах, даневажно- зато зырьте: хранимки и json!
Т.е. практического смысла в подобной операции: НОЛЬ. Все бонусы, озвученные автором- они от переписывания в принципе, а не от смены архитектуры.
Геморроя (и реального с версионированием и потенциального с масштабированием, усложнением итд) — тьма тьмущая.
Зато автор в лучших традициях "когда в руках молоток- все вокруг становятся гвоздями" воплотил апофеоз применения своих любимых хранимок.
Можно порадоваться за него — не всем удаётся на работе делать, как хочется, а не как надо.
Ваш пост о том, что вы отрицаете возможность плюсов в идее автора или ему и делиться этим не стоило?
Ну, Ок. А пена-то зачем? Почему эта "лютая дичь" вызвала у Вас столько эмоций?
Я не знаю, где вы у меня вычитали отрицание возможности плюсов, я наоборот сказал, что существует как минимум две точки зрения на описанный в статье процесс:
- академический — это когда пессимисты думают о том, как это всё будет выглядеть через год-другой и молятся, чтоб им такое не досталось на поддержку при смене работодателя
- инфантильный — это когда под девизом "но ведь работает же!" можно втащить любую дичь просто потому что это прикольно и всегда хотел попробовать.
Те, кто из первой группы — с трудом подавляют нервный тик, всё сильнее развивающийся по мере прочтения статьи, а потом на сложных щщах пытаются втолковать автору, насколько несуразную фигню он изобразил.
Те, кто из второй — не парятся по поводу всех этих сложных слов (масштабируемость, тестопригодность, переносимость, зоны ответственности, итд), а просто радуются забавной игрушке и думают, как бы ещё так извернуться, просто потому что можно.
Я же с одной стороны сам, скорее, отношусь к первой категории, но при этом понимаю вторых и по-честному завидую, что мне совесть не позволяет такое учудить.
Вообще же мантра "микросервисы спасут всё" уже чот поддостала. Регулярно приходится наблюдать и то, как их впиливают в каждом захудалом проекте из трёх страничек, и как они же превращаются в бесконтрольный сонм барахла вида просто кинем в кубер, там как-нибудь вывезет… а потом мощей железа докупим.
впечатляющая разница в плане количества кода! можно об этом подробней, какие-то примеры? здесь действительно нет ошибки? может быть что-то опущено?
To build our universal system, we took an idea from the desktop world. Rather than managing dozens of independent features and having each pull information and build its own cache on the app, we leveraged the SQLite database as a universal system to support all the features.engineering.fb.com/data-infrastructure/messenger
Может умеет, да не хочет.
Может не требования, а решения техспециалистов, против которых бизнес не возражал.
Пока что голосует конкретный СТО который сказал "кто не согласен с моим видением — на мороз". А вот как отреагирует бизнес узнаем через пару лет когда это решение начнет расти и масштабироваться, как рекламирует Автор.
За мощь надо платить, а он эту цену платить не хочет, например, не хочет превращать актуальный опыт на бэкенд языке в неакутальный через пару лет, поскольку станет писать только на SQL. Или просто не хочет отказываться от привычных удобных инструментов командной разработки, универсальных для подавляющего большинства мэйнстрим языков, в пользу специфичных для конкретного диалекта SQL, которые "по ощущениям" прежнего удобства не дадут.
К гадалке не ходи — завернут. Если ещё ни одной хранимки на проекте нет, если подробных и убедительных объяснений зачем нет, если инфраструктура для разработки/тестирования/раскатывания не предоставлена и т. п.
Но git давно уже умеет хранить изменения в DDL
Можно поподробнее? Умеет хранить кучу миграций CREATE/ALTER TABLE? Как по мне, это не изменения в DDL — это изменения схемы через последовательность DDL команд. Изменения DDL — Это один CREATE TABLE изменяется, а тулзы генерируют ALTER TABLE
Или вы о чём-то другом?
А можно пример таких двух строк которые нельзя вызвать из питона?
Я не могу к сожалению показать то что хочу, но вот банальный пример из набора агрегатных функций:
select * from (
SELECT s.id,
s.name,
count(ss.id) as subscribers_count,
count(ss.id) FILTER (WHERE ss.cdate > now() - interval '1 month') as last_month_subscribers,
count(ss.id) FILTER (WHERE ss.cdate between now() - interval '2 month' and now() - interval '1 month') as previous_month_subscribers
FROM t_society s
JOIN t_society_subscriptions ss on ss.society_id = s.id
WHERE s.type in (3, 5)
AND s.removed = false
GROUP by s.id
HAVING count(ss.id) > 0
) as subq order by subq.last_month_subscribers - subq.previous_month_subscribers desc;собственно тоже самое может быть в виде json с такими же данными но разбитыми по регионам {ru:...,en:...} для каждого society, и возможностью сортировать уже по трендам в произвольных списках регионов, типа для Европы или типа для франкоговорящих
коллеги подсказали что здесь вокруг этого еще оконная функция может быть типа:
WITH base AS (
SELECT lag(rn, :count_before) OVER window_sorting lag,
lead(rn, :count_after) OVER window_sorting lead,
subq.*
FROM ( <query> ) as subq
WINDOW window_sorting AS ( <order> )
)
SELECT * FROM base
JOIN (
SELECT COALESCE(lag, 0) AS lag,
COALESCE(lead, 99999999) AS lead
FROM base
WHERE id = :starts_from_id
) sub ON base.rn BETWEEN sub.lag AND sub.leadгде rn это
row_number() OVER ( <order> )чтобы выбирать заданное кол-во записей вокруг определенного id с учетом сортировки
Ну предыдущий запрос легко пишется в питоне/где угодно, второй уже нет, но у меня на практике таких запросов единицы на проект.
Хотя насколько я понимаю требования, то LIMIT OFFSET должно быть достаточно чтобы и второй запрос написать.
А что значит первый запрос в питоне можно написать? LIMIT OFFSET не всегда получается использовать, если лента изменится может быть ситуация когда при подгрузке мы дважды загрузим то что уже есть на странице либо пропустим часть данных
Ну я питон плохо знаю, на сишарпе что-то в таком духе (если говорить про первый запрос):
var query = db.Society
.Where(s =>
new[] {Types.Something,Types.SomethingElse}.Contains(s.Type)
&& !s.Removed)
.Where(s => s.SocietySubscriptions.Any())
.Select(s => new {
s.Id,
s.Name,
SubscribersCount = s.SocietySubscriptions.Count(),
LastMonthSubscribers =
s.SocietySubscriptions.Where(ss =>
ss.Date > DateTime.Now.AddMonth(-1)).Count(),
PreviousMonthSubscribers=
s.SocietySubscriptions.Where(ss =>
ss.Date > DateTime.Now.AddMonth(-2)
&& ss.Date <= DateTime.Now.AddMonth(-1)).Count()
})
.OrderByDescending(subq =>
subq.LastMonthSubscribers - subq.PreviousMonthSubscribers);Странслируется в примерно такой же запрос к базе как у вас написан. Но будет существовать в коде, версионироваться контролем версий, тайпчекаться, ну и так далее.
гоняли гигабайты между стойками чтобы потом напрячь python и не расслаблять оперативку
и твоем
Странслируется в примерно такой же запрос к базе как у вас написан
если можно написать при помощи ORM запрос который транслируется в SQL и выполнится на строне базы то это одно, а вещь о которой говорил daemaken, это когда ты ты выдергиваешь в питон 100тыщмильйнов записей и в нем уже обрабатываешь, потомучто ORM недостаточно гибкий для написания нужного запроса.
а можно теперь сгенеренный SQL в студию?
Ну у меня нет вашей базы, я накидал для тестовой базы которая есть у меня в поставке:
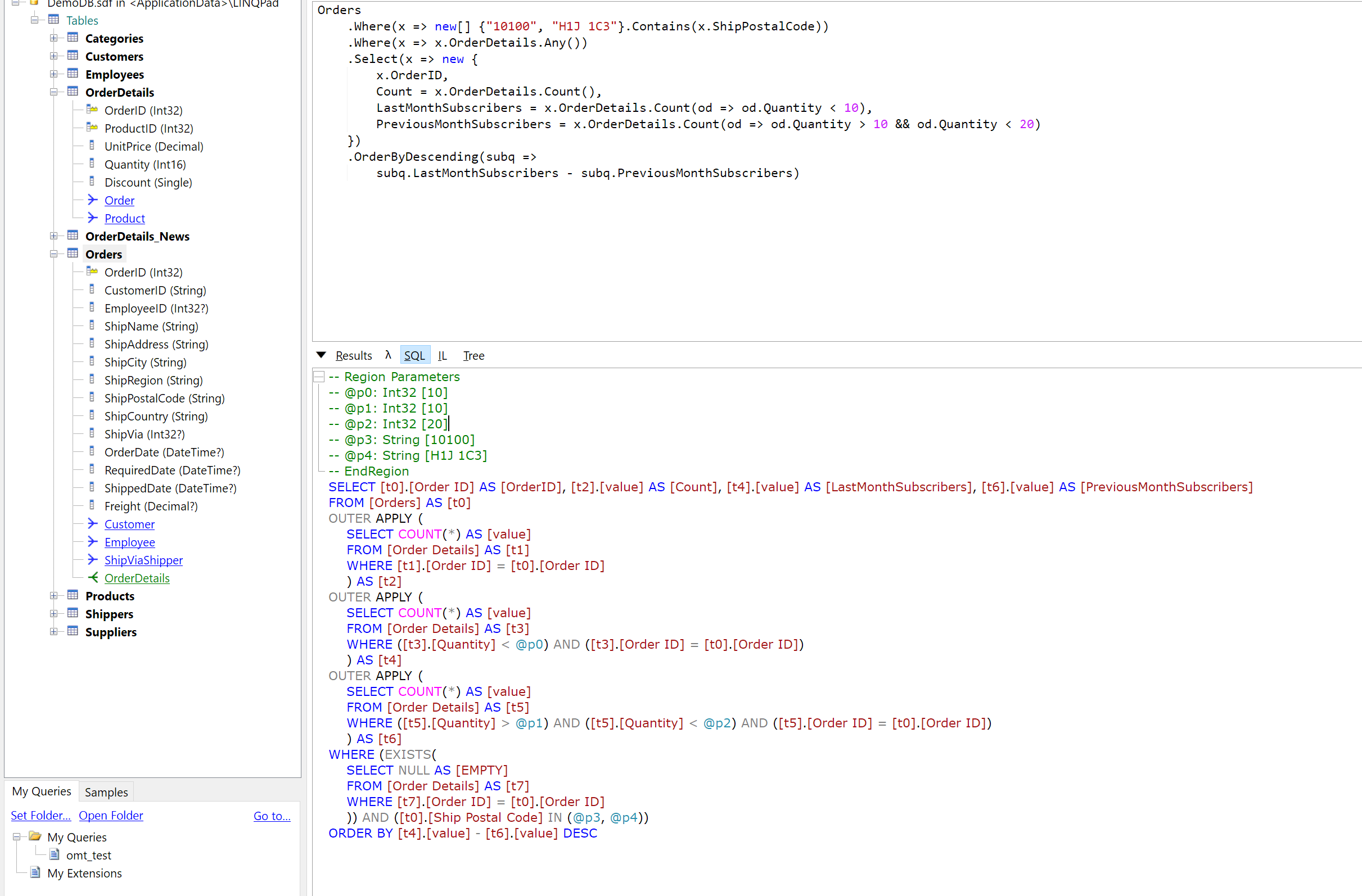
Orders
.Where(x => new[] {"10100", "H1J 1C3"}.Contains(x.ShipPostalCode))
.Where(x => x.OrderDetails.Any())
.Select(x => new {
x.OrderID,
Count = x.OrderDetails.Count(),
LastMonthSubscribers = x.OrderDetails.Count(od => od.Quantity < 10),
PreviousMonthSubscribers = x.OrderDetails.Count(od => od.Quantity > 10 && od.Quantity < 20)
})
.OrderByDescending(subq =>
subq.LastMonthSubscribers - subq.PreviousMonthSubscribers)Такой код генерирует
-- Region Parameters
-- @p0: Int32 [10]
-- @p1: Int32 [10]
-- @p2: Int32 [20]
-- @p3: String [10100]
-- @p4: String [H1J 1C3]
-- EndRegion
SELECT [t0].[Order ID] AS [OrderID], [t2].[value] AS [Count], [t4].[value] AS [LastMonthSubscribers], [t6].[value] AS [PreviousMonthSubscribers]
FROM [Orders] AS [t0]
OUTER APPLY (
SELECT COUNT(*) AS [value]
FROM [Order Details] AS [t1]
WHERE [t1].[Order ID] = [t0].[Order ID]
) AS [t2]
OUTER APPLY (
SELECT COUNT(*) AS [value]
FROM [Order Details] AS [t3]
WHERE ([t3].[Quantity] < @p0) AND ([t3].[Order ID] = [t0].[Order ID])
) AS [t4]
OUTER APPLY (
SELECT COUNT(*) AS [value]
FROM [Order Details] AS [t5]
WHERE ([t5].[Quantity] > @p1) AND ([t5].[Quantity] < @p2) AND ([t5].[Order ID] = [t0].[Order ID])
) AS [t6]
WHERE (EXISTS(
SELECT NULL AS [EMPTY]
FROM [Order Details] AS [t7]
WHERE [t7].[Order ID] = [t0].[Order ID]
)) AND ([t0].[Ship Postal Code] IN (@p3, @p4))
ORDER BY [t4].[value] - [t6].[value] DESCМожет код не самый оптимальный, но почти всегда этого будет достаточно чтобы не тормозило. И это сравнительно тупая ормка, какой-нибудь Linq2Db или JOOQ могут куда лучше сгенерировать запрос.
Ну не могу сказать что он прям отвратительный, я ожидал худшего если честно. То что не самый оптимальный это факт. Очень жалею что не могу показать его модификацию учитывающую локали хранящиеся в json в базе и в виде json же отдающий, он за то же время отдает все тоже самое но сегментированное по странам
в целом ORM хорош чтоб по быстрому накидать код и запилить mvp для презентации, вы же понимаете что будет тормозить в нагруженном продакшене, я бы попробовал выполнить у себя но есть большой риск что положу базу
Есть довольно популярное мнение, что честный ORM хорош для, прежде всего, CU из CRUD над отдельными сущностями. Для С (и то не групповых) из CQRS. А выборки, фильтрации, агрегации и т. п. лучше делать через голый SQL или мощный QueryBuilder с миниальным маппингом на readonly доменные объекты или вообще без него, если язык позволяет.
Вот как раз для U это ужас. Все эти обжект трекинги и прочее, это просто отвратителная чушь. Жалею, что в EF нет никакой альтернативы.
Почему?
Потому что я бы предпочел не писать подобных уродцев:
с хэлпер-методами, которые пытаются установить, было обновлено свойство, удалено или ещё что. Не говоря про перфоманс, я вынужден делать Select потому что нельзя обновлять сущность не по первичному ключу.
В SQL это было бы просто
DELETE FROM PrefferedPersons
WHERE CarId = @carId
INSERT INTO PrefferedPersons VALUES @newPersonsА тут куча логики "поменялось, не поменялось", лишние селекты, трейкинги-уекинги, ...
В целом ОРМ достаточно для большинства "обычных" запросов, для "Необычных" расчехлять SQL Это нормально. Но правило паретто говорит нам о том, что такой подход экономит много времени и нервов.
Не хочу утверждать, но для тех запросов, для которых хорош ORM скорее лучше хранить данные в noSQL базах. Все таки запросы либо не оптимальные либо уровня я пишу свой первый селект возьму ка что ни будь с простым джойом и парочкой фильтров
noSQL плох во-первых тем, что у него одинаково отвратительная производительность вне зависимости от навыков написания запросов к ней. Условная монга работает со скоростью Х и вот что хочешь делай, лучше не станет. с SQL же куда лучше в этом плане, дефолтный перфоманс на стандартных запросах может похуже чем та же монга, но зато есть пространство для оптимизаций.
Во-вторых очень редко нужно больше 1-2 джоинов делать, оно работает достаточно производительно.
Собственно, ОРМ и не делает джоинов которые не нужны. А если они нужны, значит они нужны, и ОРМ тут ничего не меняет.
Автор несколько раз упоминает «новую философию» и потом проносит это через комменты. И в этом, на мой взгляд, главная проблема этого сочинения. Ничего плохого в хранимках самих по себе нет, в простых кейсах, которые отписывает автор, тем более. Но давать этому идеологический контекст, вот это для меня звучит дико. Позиция «я пришёл, все переписал, стало зашибись, а раньше 2 года не могли» тоже, как по мне, выглядит так себе. Что вы там писали про проверку софт-скилов на интервью?
В рамках чего вы сюда добавили кадровые вопросы, уход старой команды вместе с техдиром не добавляет пунктов ни одной компании при найме новых сотрудников. И сильно сдаётся мне, что сначала технический директор вас покинул по доброй воле, а уже потом вы решили оптимизировать его позицию. А уж аргумент, что нужно чуть ли не записываться на приём к тех директору, в команде из 20 человек… )))
С технической точки зрения это статья про то, что сложные многоступенчатые запросы можно оптимизировать с использование хранимых процедур, а Postgres ещё и Json хорошо умеет. Вот так новость! Остальное напоминает комплекс превосходства. Печально такое читать на хабре, особенно про продукт, который некогда был очень хорошим!
Полезность такого рода статей еще и в том, что они показывают — бестпрактис привычные иногда стоит подвергать сомнению, а то и пересматривать.
Ну, и пока читал комментарии, в голове не переставая крутилось:
«Время пострелять, между нами пальба,
Попадая в базу остаешься там, хранимка.
Я просто трачу свой тайм, я просто трачу свой прайм на тебя, хранимка.»
Мне например очень интересно наблюдать как переходить процесс переноса с уровня БД на уровень backend, который происходит на моих глазах.
Пока штат разработчиков вырос в 5 раз, вывод новых фич остановлен с мая.
Жду не дождусь когда дело дойдет до запросов к БД. Интересно будет посмотреть, что нагенерит ORM.
Я согласен, есть бизнес-задачи в которых использование backend для обработки данных оправдано. Но городить огород ради SELECT и формирования JSON?
Я предположу, почему большинство комментаторов не воспринимают «БД в БД» — они выращены на императивных языках. Перестроится на декоративный SQL, сложно.
У меня так главная проблема — сначала в голову приходит FOR, а потом мысль — а зачем в SQL FOR?
Это не ловушка. Это, можно сказать, часть определение best practices.
Декларативный стиль SQL-команд (что уже звучит противоречиво) мало отношения имеет к хранимым процедурам, которые пишутся на процедурном, то есть императивном PL/pgSQL. Речь ведь не о том, какие DML команды должна выполнять СУБД, речь о том, кто их отдаёт, кто склеивает результаты, формирует их последовательность, ветвления, обработку особых случаев и ошибок — императивный процедурный код на PL/pgSQL (или аналогичные расширения других вендоров) или императивный процедурный/ ООП код на ЯП общего назначения. Кстати, не рассмотрена опция управления DML командами декларативными функциями на ФП языках.
А я согласен, что есть есть бизнес-задачи, в которых использование хранимок для обработки данных в базе и даже внешних источниках, данных оправдано. Но городить огород ради SELECT и формирования JSON?

До сих пор иногда думаю что не проиграй Оракл сурс контрол, CI/CD, тестирование, средства разработки и прочее подобное мы бы сейчас жили в другом мире.
И ведь до сих пор ничего не изменилось.
Как хранили все в отдельных и несвязанных текстовых файликах так и хранят до сих пор.
Как мучались с историей изменений так и мучаются.
Как не было (да любая привычная фича) так ее и нет.
Видимо это неисправимо.
PS: Рефакторинг в таких системах делается sed'ом. Этот вопрос возникал выше в ветках.
Думаю, многие в нулевых попробовали такой подход, а потом отбросили или оставили для исключительных случаев, когда реально альтернатива — пересылка гигабайт данных между бэком и базой.
И ведь до сих пор ничего не изменилось.
В масштабах тиражей Oracle, полагаю, более чем так.
Видимо это неисправимо.
Или это — ниша, которую еще никто не смог заполнить. Может, недостает пары идей, чтобы решения, которые радуют лишь некоторых, понравились многим.
P.S. Но вот выкладывать в прод сырую версию, да еще и с потерей пользовательских данных — это очень плохо
Я сразу задал вопрос — зачем переписывать посредине разработки проекта то, что работает?
Ответа так и не получил.
Был работающий проект на хранимках.
Набрали толпу разрабов, внедрение новых фич остановили, переписывают то, что работает.
Зачем?
Кроме того, что им прикольно и драйвово я не могу придумать объяснения.
Еще более мне не понятно, как смогли объяснить бизнесу раздувание бюджета.
То, что делал один DB разработчик теперь делает группа backend. Нового backend нет с мая, будет со дня на день, жду. Очень интересно посмотреть, какие там запросы в результате получатся.
Eщё было прикольно в начале, я им говорю: «Вы понимаете, что сменив архитектуру вы начали разрабатывать новый продукт ?». Нет не понимают. Ну на выходе же тоже самое получится. Ага, взяли дом, сменили фундамент. Это тот же дом ;-)
В идеале все программисты мира должны раз в полгода менять компанию с повышением зарплатыи product owner тоже, у нас уже трое сменилось с декабря прошлого года.
Не знаю вашу ситуацию, но в той с которой сталкивался лично (проект на хранимках и вьюхах mysql с минимальной прокладкой на PHP в качестве http-контроллера и html-презентера), основная проблема бизнеса была медленная и некачественная разработка, ситуация ухудшалась с каждым новым разработчиком. Основной причиной в своём отчёте типа аудиторского я указал неиспользование командами разработки нормальных средств коллективной разработки хранимых процедур, триггеров и т. п. для MySQL и сторонних библиотек для типовых задач (каждый раз свой велосипед).
На просьбу указать какие средства следует использовать, я сообщил, что в экосистеме MySQL, равно как PostgreSQL мне такие неизвестны. После чего было принято решение перейти на PostgreSQL с использованием хранимок (в широком смысле слова) только в качестве исключения для задач массовой обработки с совершенно отдельным от основной кодовой базы флоу разработки, практически немасштабируемым больше чем на 2-3 DBD, и то с трудом, только ради увеличения бас фактора.
И ведь решил задачу? Ну видимо, решил.
Просто в 2020 году кроме "решил задачу" есть ещё другие критерии, например насколько стабильно оно работает? Каковая кривая стоимости внесения изменений? Какой bus factor? И так далее.
В пределе, если вам программист-вундеркинд в соло на брейнфаке напишет реализацию системы, а пото уйдет в закат потому что ему неинтересно этим дальше заниматься — засчитаете такую работу за "решает бизнес-задачу"?
Все эти гигабайты зависимостей и гиты не на ровном месте появились. Хотя можете считать конечно, что ленивым программистам хочется нарочно поесть память и написать плохо, а не хорошо. Потому что на другом спектре "гигабайт зависимостей" — хранимки на SQL где подключить чужое решение можно исключительно методом копипасты со стаковерфлоу.
У меня есть инсайд от человека, который там некоторое время работал несколько лет назад, и соотнося что он говорит и что тут написано, с тем о чем прямо не сказано, но можно догадаться между строк, я думаю что во-первых ЛЮБОЕ переписывание имело бы похожий результат, можно было переписать с PHP на PHP с тем же профитом, а во-вторых эйфория достаточно быстро пройдет, у меня на текущей же работе коллега как раз с такого "всё в базе" проекта на котором несколько лет проработал, рассказывал много интересного.
За bus factor переживать что чего программистам, как и за стоимость разработки?
ИМХО хороший разработчик должен понимать, кому что и зачем он делает. Например если он берет поиграться редкую технологию поиграться, а потом сваливает и поддерживать это некому, то он — мудак, который "не переживал за бас фактор и стоимость разработки".
Все эти гигабайты зависимостей и гиты не на ровном месте появились.
Разумеется, и теплое и мягкое имеют свои причины. Про второе, полагаю, все очевидно. А про первое — это ли не js породил?)
Вас послушать — так все должны пожизненно сидеть на одном и том же проекте. А вы как долго работали на одном и тем же?
Мне выпал шанс увидеть к чему это приводит. Проект, который писался лет 10 назад на perl и хранимых процедурах, сегодня превратился в тыкву. Из коллектива разработчиков остался только один и то он пришёл уже на закате. Ему была поставлена задача написать ещё один «горизонтальный» компонент системы. За год он не смог справиться с задачей.
Тогда привлекли сторонних разработчиков perl для аудита. Их вердикт: если существует ад для программиста, то они его и увидели. Главный вопрос встал «можно ли на существующей архитектуре дописать то, что требуется?». Ответ был: «Дешевле и быстрее переписать с нуля».
Отсюда можно сделать выводы, «снова открыть Америку»:
— код нужно регулярно рефакторить
— нужно обновлять инфраструктуру и компоненты, чтобы не пришлось догонять ушедший поезд; заодно это поможет выявить недостаточную абстрагированность кода или проблемный хардкод
— нужно вливание свежей крови для расширения кругозора и развития проекта
— проект нужно документировать настолько, насколько возможно, чтобы новый разработчик мог в сжатые сроки адаптироваться
А критиковать в 2020-м использование VCS или автотестов — это я даже не знаю насколько нужно деградировать. Деплой на прод делаете всё ещё из WinSCP или Filezilla?
Действительно, очень часто дешевле и быстрее переписать с нуля. Так в топике и переписали. Через несколько лет опять перепишут и опять это будет дешевле и быстрее, чем «комбайн» все эти годы поддерживать на том уровне, чтобы любой программист с улицы за час разобрался. Часто именно это выгоднее, чем изначально вкладываться в архитектуру, которая может пригодится, а может и нет. Да и где вы прочитали, что я критикую сами технологии или может быть рефакторинг? Речь то вообще о другом
Если речь про чрезмерные абстракции и оверинжиниринг ради идеи вечного продукта — то вы правы. Рано или поздно продукт потребуется переписать. Но если сроки позволяют сделать более гибкое решение, то почему бы и нет.
Мне показался чрезмерным скептицизм в отношении новых технологий. Я, впрочем, тоже не люблю хайп, но если виден устоявшийся тренд спустя 3 года, то наверное стоит обратить внимание.
Проект, который писался лет 10 назад на perl и хранимых процедурах
…
Тогда привлекли сторонних разработчиков perl для аудита.
Как автор аналогичного проекта, впечатлен. Те, кто сейчас его поддерживают в проде, давненько на perl ничего не писали. И даже если в проекте есть "ад", искали бы его не в БД.
И да, это не про контроль версий или автотесты, там это все было сразу.
неиспользование… триггеров
как связано с
медленная и некачественная разработка
?
А также, просьба побольше деталей по
неиспользование… сторонних библиотек для типовых задач
О каких типовых задачах идет речь? Что подразумевается под библиотекой?
Я, конечно, рад, что ребята уменьшили издержки и увеличили производительность системы. Хотя и очень-очень сомнительными методами, мягко говоря.
Но хочется предупредить и предостеречь всех практикующих инженеров, что, когда вы слышите, что производительность чего-то резко возросла после переписывания с технологии А на технологию Б, и затраты на поддерживание системы резко упали, надо обязательно всегда помнить, что это словесная манипуляция.
Преподносится: главное, что переписали на _другую_технологию_.
На самом деле: главное, что _переписали_ на другую технологию.
10 секунд + множество косяков в странице — убыстрите/пофиксите, глядишь и конверсия подрастёт.
но нормальная архитектура большого и долгосрочного проекта должна зависеть от абстракций, а не от деталей, поэтому решения о выборе СУБД принимают в последнюю очередь. для этого и существуют ORM — чтобы не зависеть от СУБД. хранимки, в том количестве, в котором вы их используете — это вынос бизнес логики в БД и мёртвая привязка к деталям.
при нынешней стоимости аренды серверов, для бизнеса было бы лучше сделать всё так, чтобы при повышении нагрузки просто задеплоить ещё один контейнер, вместо того, чтобы находить/обучать людей, готовых писать бизнес-логику прямо в SQL.
У них экранирование не работает. При регистрации можно javascript загонять.
При регистрации можно сделать POST-запрос на https://api.lingualeo.com/SetSurveyUserData
{"apiVersion":"1.0.1","userId":1234567,"data":{"passed":true,"userName":"<script>alert('here');</script>/*нечто для проверки инъекции sql","dateOfBirth":"1234-04-01","sex":3}}1) 1234567 — это ваш юзер-id (интересно, а что если чужой передать?)
2) год даты произвольный (хотя интерфейс ограничивает 1920-м)
3) пола там 2, но я выбрал третий (а что, мы же живем в современном мире)
В результате получаем в интерфейсе пользователя вот что (фон тоже замечательный):
И это было первое, что я попробовал. Дальше пробовать не хочу — и так всё ясно.
Мне кажется, руководству нужно немедленно пересматривать техническую стратегию и менять руководителя разработки...
В целом согласен. Но, по-моему, тут тот случай, когда это не поможет. Если с 3-ей минуты изысканий мне попалось это, то что там глубже? Я копать не стал, но, ИМХО, там надо делать полноценный аудит системы.
Фишка в том, что эта уязвимость — не баг, а логичное следствие архитектуры "храним чо передали, внешние ключи зло, бекенд БЫСТРЫЙ". Ну, оказывается он быстрый не потому что PG быстрый, а потому что просто 90% нужной логики теперь не делают, типа вот таких вот проверок, замедляют же.
У них есть мобильные клиенты, которым более чем пофиг на html
Так что конретный вышеописанный случай — проблема конкретного фронта (или его генератора, если html отдаётся с сервера)
Но да, можно всё подряд заэнкодить, и что тогда делать с мобилами?
Показывать <>? )
Вы помните, что мы про поле юзернейм? Во-первых теперь когда в БД сохранен мусор нужно нигде не забыть эскейпить. Хоть где-то забыли, получили дырень гигантских масштабов. Во-вторых мне даже чисто эстетически поле юзернейм неограниченной длины с HTML разметкой не кажется хорошей идеей.
Во-первых, дело не в экранировании данных (в базу надо сохранять, как есть; за редким исключением), а в том, что валидация у них только на фронте (и даже не валидация, а фильтрация ввода). Вот зачем разрешать в имени пользователя угловые скобки?
И уже, во-вторых, вне зависимости от того, как и какие сохраняются данные, конечно же надо думать об экранировании на фронте.
Ну и вопрос о дате рождения горца с третьим полом — как вам такое? Это нормально пропускать в систему заведомо невалидные данные? И я ведь не копал далее (если сами попросят, могу, конечно, продолжить). С таким подходом ненулевая гарантия
- иметь возможность получить read или write доступ к чужим данными;
- иметь возможность уронить сервис (просто по причине того, что в базе объявятся неожиданные для разработчика данные).
Валидация (и санация опционально) данных нужна как на фронте, так и на бэке, причем на бэке обязательно, а на фронте опционально.
Дата рождения — ну такое, не паспортные данные всё же спрашивают. Третий пол — тоже мелочи.
Вы так говорите, как будто спорите со мной :)
На счет даты и пола — если фронтенд не позволяет такое, а бэкэнду все равно, то в датском королевстве что-то уже не так. Если программист будет исходить из того, что пола бывает только два, а человеку не может быть более 100 лет, то возникает undefined behavior, и могут различные казусы вылезти (вплоть до падения кода).
судя по тому что вы говорите вы не знаете что такое undefined behavior/
Цитата из Вики:
In computer programming, undefined behavior (UB) is the result of executing a program whose behavior is prescribed to be unpredictable, in the language specification to which the computer code adheres.
Чему противоречит моё высказывание?
in the language specification to which the computer code adheres.
Отлично, а теперь покажите спецификация какого языка запрещает/разрешает иметь больше 2 полов.
Хорошо, убедили. Пусть будет "непредсказуемое поведение". Три пола имеют отношение к тому, что если программист исходил, что пола два (а UI красноречиво показывало два пола, где 1 — м, 2 — ж), то при рендеринге могут быть баги, при запросах к базе могут быть баги, при миграциях могут быть баги, при апи-запросах могут быть баги. Рассказывать какие и чем это может закончиться?
P.S. Если что, речь вообще не о полах. Могло быть о чем угодно. Да хоть о палатах в парламенте (верхняя/нижняя).
"Подобных" — это каких? При нормальной постановке задачи или проектировании определяются обычно ограничения к допустимому набору значений каждой сущности. Например, поле username — буквы, цифры и строгий набор спецсимволов из Unicode, не более 40 знаков. Вот сижу прямо сейчас и занимаюсь этим для нескольких сотен полей, консультируясь при каждом сомнении, а потом ещё и на ревью отправлю.
Хочу отметить, что я им написал сразу после того, как запостил свой коммент. Но баг до сих пор на месте (как минимум, мой аккаунт подвержен проблеме). Так что либо ребятам по барабану, либо не знают, как исправить. И то, и другое печально.
P.S. Пора статью писать на Хабр. Материала уже достаточно :)
Т.е. один сидел и просто гыгыкал, второй пошёл чуть дальше и мрачно офигел, ещё куча народу ради лулзов потыкали палочкой, а потом вы такие молодцы приходите (спустя ТРИ НЕДЕЛИ) и заявляете "ничего не было"? Ну да, все кругом клинические идиоты и конечно же ничего не понимают.
Не, ну самому не стыдно? Реально детсад же.
Спасибо за статью. Есть один вопрос. Если понадобится интегрировать в продукт модель машинного обучения, например на каждый запрос пользователя прогонять бустинг, ответ отдавать пользователю и одновременно где-то кешировать, как это можно будет уложить в представленную архитектуру?
Чтобы внедрить даже небольшую новую фичу, уходило 2 месяца
Интересно, а сколько сейчас нужно времени, чтобы внедрить фичу?
Причем сколько времени нужно отдельно ее затестить?
"ни в одном большом проекте никто и никогда не будет использовать ОРМ" — я один такой проект знаю. С интересом наблюдаю, чем все кончится. Все мои вопросы, тех лидам и архитекторам — а зачем? Пока тонут в тишине.
Думаю по итогам наберётся материал на статью.
Ребята молодые, им играться интересно, а мне интересно наблюдать.
Я сразу спросил — а кто из вас Йордана читал, путь камикадзе? В ответ тишина.
Потому, я и не удивлен.
По всем признакам — классический безнадёжный проект выходит.
Посмотрю, чем кончится.
Ну насчёт бесперстивняка это наверное несколько категорично. Проект никуда не денется, бюджет выделен, заказчик никуда не денется у него нет выбора, разработчиков набирают, уже два скрам мастера, несколько архитекторов, тех лиды, Тим Лиды, все при деле, все заняты, встречи ретроспективы планирование, процесс кипит только пар идёт :-)
А выдержки короткие и сейчас готовы — те фичи которые программировал один DB разработчик сейчас программируют уже пять backend разработчик плюс техлид.
Разработка новых фич остановлена с мая, идёт переписывание хранимых функций на sequelize, node.js, elastic search. До сих пор не получил ответы на некоторые вопросы — противодействие sql инъекции, ссылочная и транзакционная целостность между микросервисами, разделение доступа к строкам, ссылочная целостность данных БД, валидация данных, сертификация, журналирование DML.
Да записываю в блокнотик, интересно будет.
В моей жизни первый случай когда меняют архитектуру в процессе разработки продукта.
Наверное будет интересно.
Мне например очень интересно посмотреть на запросы которые генерит ORM, мониторинг запросов, ожиданий и блокировок есть, вот и отладка будет полезная.
А от разработки меня отодвинули, возвращаюсь в DBA :-)
Основные проблемы при использовании ORM идут от того, что этот подход используется бездумно. Анализ запросов не проводится. Программисты работают с кодом без оглядки на базу данных. У меня сейчас есть один проект под рукой, который использует Doctrine2. В активной разработке с 2011 года и активно используется заказчиком. Никаких проблем с производительностью нет — все запросы тщательно выверяются по профайлеру и оптимизируются по необходимости. Более того написаны функциональные тесты, которые отлавливают неэффективные запросы.
В общем, суть такова: любой инструмент покажется негодным, если им неверно пользоваться.
А можно чуть поподробнее про функциональные тесты?
Я планирую мониторить запросы и смотреть уже какие запросы в топы попадают по утилизации ресурсов и ожиданиям/блокировкам.
У меня был кейс когда продакшн вешался, хотя тесты проходили нормально. Там проблема была в том, что разработчики решили сделать свой механизм блокировок взамен БД.
А можно чуть поподробнее про функциональные тесты?
Вот документация Symfony об этом говорит: https://symfony.com/doc/current/testing/profiling.html
Не знаю, подойдет ли в вашем use case, но у нас очень даже.
вначале нужно построить хорошую архитектуру, которая позволит легко изменять код без больших последствий для функциональности системы (топикстартер сам пишет о том, что была проблема с добавлением новых фич — обычно причина именно в неудачной архитектуре. то же самое будет через несколько лет с этой). затем, если есть такая необходимость, оптимизировать, там, где это действительно нужно. подход «сразу запихать всю бизнес-логику в sql» можно считать случаем преждевременной оптимизации, он не позволит использовать TDD и тестировать код — что скажется на читабельности, возможности повторного использования, поддерживаемости кода.
для оптимизации и масштабируемости давно уже есть свои наработанные методики — кэширование, шардинг, репликация, микросервисы, load balancer, что там ещё? не нужно для этого уродовать архитектуру системы.
отвечая на ваш вопрос, «какой большой проект вы знаете??». Symfony по умолчанию использует Doctrine. Symfony используют, например:
Spotify
Blablacar
Vogue France
Porn hub — «1 billion of traffic per week. Symfony is used to support more than 700 million requests for the same time.»
Trivago — «More than 120 million visitors»
Dailymotion
National Geographic
Про «ваш интернет магазин??» вы верно заметили. к нашему проекту в области е-коммерции подключено 10 000 мерчантов, в числе мерчантов и партнёров MediaMarkt, Tesla, Ford, Microsoft. на проекте использовалась Doctrine, теперь TypeORM (перешли с php на nodejs — работает быстрее, при разработке языка учли многие детские болезни php). так вот, в прошлую чёрную пятницу сайты многих крупных мерчантов просто лежали. наш даже не шелохнулся. для этого потребовалось сделать только то, что я написал выше — мы просто задеплоили несколько новых контейнеров.
хотя, если очень хочется всё оптимизировать с начала проекта — ну пишите сразу на ассемблере, чё.
кстати, судя по доступной информации, у авторов поста всего-то 10 000 посетителей в день, ну в апреле количество выросло примерно до 60 000 — это что, хайлоад? Alexa, SimilarWeb, etc подтверждают эти цифры. если у них в БД 23 млн пользователей, из них 10 000 активных, и они со своей базы пользователей даже не могут оплатить хостинг, то проблема, скорее, в монетизации. $1000 в год — да блин, посчитайте же зарплату ОДНОГО программиста за год и сравните. может, станет понятно, что пора бы начать зарабатывать, а не пытаться экономить на спичках.
1.
Однако каким бы ярым приверженцем объектных техно-Фаулер(с)
логий вы ни становились, не отбрасывайте сценарий транзакции: существует множество
простых проблем, и их решения также должны быть простыми.
2. «Преждевременная оптимизация» опасна для стартапа, так как высок риск с завтрашнего дня вместо продажи солнечных батарей заняться услугами йоги. А зрелый бизнес с устоявшийся за 10 лет бизнес-логикой как раз таки нуждается в оптимизации и рефакторинге.
3. Порн-хаб и Symfony, это безусловно круто. Но зачем эти техники местечковому бизнесу который выбрал практически всю доступную аудиторию? Видимо собственники решили, что дальше расти им особо некуда и перешли к стадии оптимизации расходов. Если принять цифру 2млн посетителей в день (согласно SimilarWeb) и 20 программистов, это 200k$ железо + 1kk$ прогеры. Вполне себе деньги, есть что экономить. И судя по статье, автору это удалось.
4. Автор в 2019 году реализовал некое решение. В 2020 описал этот результат. Учитывая, что сделано это в офф. блоге компании, логично предположить, что «поток денег в кассу» за год не снизился. В противном случае автор писал бы не статью, а резюме.
Все это очень интересно, и ряд вопросов появился.
А как вы обрабатываете ситуацию, когда одна хранимка не справляется с ситуацией, слишком долго выполняется? Обычно кешируют в редис (или аналог) с постобновлением кеша после получения результата с backend-а. А у вас как?
Есть ли у вас план по горизонтальному масштабированию базы? Что тянет за собой оптимизация join-ов… На каком уровне архитектуры планируется объединение данных?
Есть ли у вас разнесенные таблицы на разные sql сервера под определенные микросервисы? На какой стадии происходит объединение данных?
А как происходит тестирование хранимок командой QA? Имею ввиду вот 20 тикетов с изменениями хранимок. Тестер сам берет каждую хранимку, пихает в отведенную для него (или общую) тестовую базу через PgAdmin, тестирует функционал...
Кстати, а как происходит мердж изменений над одной хранимкой разными разработчиками? На какой стадии каждой хранике присваивается версия? А если присваивается разработчиком, как выбирается главная? Есть какой-то общий счетчик версий?
Добрый день!
Будет ли продолжение цикла статей про перенос логики в БД?
К сожалению, статья лицемерная от начала до конца.
Пользовался сервисом с 2017 года. Сервис идеально подходил под мои предпочтения в изучении английского. Фактически, я не знал, есть ли у сервиса поддержка и как она работает, мне это ни разу не понадобилось. Сервис активно поощрял долгосрочные платные подписки, и люди подписывались на годы(!!!) вперед.
Потом в один прекрасный момент сервис был приведен на 95% в нерабочее состояние. Фактически, людей переселили из уютных обжитых квартир в грязный котлован. В котором пообещали начать закладывать фундамент новостройки, в которой может быть когда-нибудь будет гораздо лучше чем было раньше. Клиенты просто взвыли от возмущения, у многих это была любимая игрушка, да к тому же оплаченная наперед на значительный срок, что вселяло уверенность.
Рты клиентам быстро позатыкали, возмущенные возгласы не то, что прекратились, а их не стало слышно. В основном коммуникация шла через поддержку, через официальный блог и через соцсети.
Поддержка на обращения стала отвечать цитатами из пользовательского соглашения, которое читали, мягко говоря, не все, и в котором компания отказывалась вообще от любой ответственности. То, что люди считали оплатой за сервис, оказалось, вообще ни к чему не обязывало компанию. Сегодня компания могла взять предоплату за год вперед, а завтра просто перестать оказывать услугу. Поддержка принимала к сведению факты потери сервисом 95% функционала, но не называла сроков восстановления, и вообще не обещала восстановления всего. Многие функции объявлялись неактуальными и не подлежащими восстановлению, и таких со временем становилось все больше.
Блог и соцсети подверглись грубому и неаккуратному модерированию. Критические комментарии удалялись под корень, от чего многие обсуждения выглядят довольно странно. Непонятно, чему возражают и с чем соглашаются люди в немногих оставшихся сообщениях.
Два года спустя уже можно подводить итоги. Функционал и близко не восстановлен. В поддержку обращаться бесполезно, я отказался от этого занятия. Официальный блог премодерируемый, сначала в нем пропускали довольно много панических воплей от обескураженных клиентов. Это жалобы были разбавлены обещаниями восстанавливать функционал и убирать баги. От разговоров от сроках администрация тщательно уклонялась. Потом модераторы просто перестали пропускать комментарии с критикой, даже с самой конструктивной. Соцсети заполнены лицемерными самовосхвалениями администрации, примерно в стиле обсуждаемой статьи, и ни-никакой критики.
Отдельная фишечка это стилизация. Раньше Лео был милым шаловливым львенком, а стал наглым циничным лгуном.
К модераторам: пишу этот безобразно длинный пост в надежде, что его прочитает хоть один человек, уже готовый подписаться на три года вперед с прекрасной скидкой, буквально даром.
Регнулся только из-за этого, попал на статью по ссылке с другого форума и был ошарашен лицемерием автора.
«В карантин нагрузка выросла в 5 раз, но мы были готовы». Как Lingualeo переехал на PostgreSQL с 23 млн юзеров