Нынче важнейшим вектором развития многих компаний является цифровизация. И почти всегда она так или иначе связана с машинным обучением, а значит, с моделями, для которых нужно считать признаки.
Можно делать это вручную, но также для этого существуют фреймворки и библиотеки, ускоряющие и упрощающие этот процесс.
Об одной из них, featuretools, а также о практическом опыте ее использования мы сегодня и поговорим.

Моднейший пайплайн
Всем привет! Я Александр Лоскутов, работаю в «Леруа Мерлен» аналитиком данных, или, как это модно сейчас называть, data-scientist-ом. В мои обязанности входит работа с данными, начиная c аналитических запросов и выгрузок, заканчивая обучением модели, оборачиванием ее, например, в сервис, настройкой доставки и развертывания кода, а также мониторинга его работы.
Предсказание отмен — один из продуктов, над которым я работаю.
Задача продукта: предсказать вероятность отмены заказа клиентом, сделанного онлайн. С помощью такого предсказания мы можем определить, кому из клиентов, сделавших заказ, нужно позвонить в первую очередь, чтобы попросить подтвердить заказ, а кому можно и не звонить вовсе. Во-первых, сам факт звонка и подтверждения заказа от клиента по телефону уменьшает вероятность отмены, а во-вторых, если мы позвоним и человек откажется, то мы сможем сэкономить ресурсы. У сотрудников высвободится больше времени, которое они бы потратили на то, чтобы собрать заказ. К тому же так товар останется на полке, и если в этот момент находящемуся в магазине покупателю он понадобится, то он сможет его купить. И таким образом уменьшится количество товаров, которые были собраны в отмененные позже заказы и не присутствовали на полках.
Для пилота продукта мы берем только заказы с постоплатой при самовывозе в нескольких магазинах.
Готовое решение работает примерно так: к нам приходит заказ, с помощью Apache NiFi мы обогащаем информацию по нему — например, подтягивая данные по товарам. Затем все это через брокера сообщений Apache Kafka передается в сервис, написанный на Python. Сервис рассчитывает признаки для заказа, а дальше за них берется модель машинного обучения, которая выдает вероятность отмены. После этого мы в соответствии с бизнес-логикой готовим ответ, нужно звонить клиенту сейчас или нет (например, если заказ сделан с помощью сотрудника внутри магазина или заказ сделали ночью, то звонить не стоит).
Казалось бы, что мешает звонить всем подряд? Дело в том, что количество ресурсов для звонков у нас ограничено, поэтому важно понимать, кому обязательно стоит звонить, а кто и без звонка точно заберет свой заказ.
Я занимался сервисом, моделью и, соответственно, расчетом признаков для модели, о котором и пойдет дальше речь.
При расчете признаков во время обучения мы используем три источника данных.
Стандартными методами Python и библиотекой pandas можно легко объединить все таблицы в одну большую, после чего, используя groupby, посчитать разного рода признаки вроде агрегатов по заказу, истории по товару, по категориям товаров и т. д. Но тут возникает несколько проблем.
Плюсом подхода «пишем все вручную» является, конечно же, полная свобода действий, можно дать своей фантазии развернуться.
Возникает вопрос: как можно оптимизировать эту часть работы. Одним из решений является использование библиотеки featuretools.
Тут мы уже переходим к сути этой статьи, а именно к самой библиотеке и практике ее применения.
Рассмотрим различные фреймворки для машинного обучения в виде таблички (сама картинка честно украдена отсюда, и наверняка там указаны не все, но все же):

Нас интересует в первую очередь блок Feature Engineering. Если рассмотреть все эти фреймворки и пакеты, то выяснится, что самым «навороченным» из них является featuretools, и он даже включает в себя функциональность некоторых других библиотек вроде tsfresh.
Также к достоинствам featuretools (совсем не реклама!) можно отнести:
Но не все так просто.
Приведу пример конфигурации featuretools.
Далее будет код с краткими объяснениями, более подробно про featuretools, его классы, методы, возможности можно почитать в том числе в документации на сайте фреймворка. Если вам будут интересны примеры практического применения с демонстрацией некоторых интересных возможностей в реальных задачах, то пишите в комментариях, возможно, запилю отдельную статью.
Итак.
Сначала нужно создать объект класса EntitySet, который содержит таблицы с данными и знает про их связи между собой.
Напомню, что у нас три таблицы с данными:
Пишем (далее используются данные только 3-х магазинов):

Ура! Теперь у нас есть объект, который позволит нам считать разного рода признаки.
Приведу код для расчета довольно простых признаков: для каждого заказа посчитаем различные статистики по ценам и количеству товаров, а также пару признаков по времени и самые частые товары и категории товаров в заказе (функции, выполняющие разного рода преобразования с данными, в featuretools называются примитивами).


Здесь в таблицах нет столбцов типа boolean, поэтому примитив any не был применен. Вообще удобно, что featuretools сам анализирует тип данных и применяет лишь соответствующие функции.
Также я вручную указал только несколько заказов для расчета. Это позволяет быстро дебажить свои вычисления (вдруг вы сконфигурировали что-то не то).
Теперь добавим к нашим признакам еще несколько агрегатов, а именно перцентили. Но в featuretools нет встроенных примитивов для их расчета. Значит, нужно написать самим.
И добавим их в расчет:
Дальше все то же самое. Пока все довольно просто и легко (относительно, конечно).
А что если мы хотим сохранить наш калькулятор признаков и использовать его на этапе исполнения модели, то есть в работе сервиса?
Тут-то и начинаются основные сложности.
Для расчета признаков по входящему заказу придется опять проделать все операции с созданием EntitySet. И если для больших таблиц закидывать pandas.DataFrame-объекты в EntitySet кажется вполне нормальным, то делать аналогичные операции для DataFrame-ов из одной строки (в таблице с чеками их больше, но в среднем 3.3 позиции на один чек, то есть мало) — уже не очень. Ведь создание таких объектов и расчеты с их помощью неизбежно содержат оверхед, то есть неустранимое количество операций, необходимых, например, для выделения памяти и инициализации при создании объекта любого размера или самого процесса распараллеливания при вычислении нескольких признаков одновременно.
Поэтому в режиме работы «один заказ за раз» в нашем продукте featuretools показывает не лучшую эффективность, занимая в среднем 75% времени ответа сервиса (в среднем 150-200 мс в зависимости от железа). Для сравнения: вычисление предсказания с помощью catboost-а на готовых признаках занимает 3% от времени ответа сервиса, т. е. не более 10 мс.
Помимо этого, есть еще один подводный камень, связанный с использованием кастомных примитивов. Дело в том, что мы не можем просто сохранить в pickle объект класса, содержащего созданные нами примитивы, так как последние не пиклятся.
Тогда почему бы не воспользоваться встроенной функцией save_features(), которая может сохранить список объектов класса FeatureBase, в том числе созданные нами примитивы?
Сохранить-то она их сохранит, а вот прочитать потом с помощью функции load_features() их не получится, если мы заранее их снова не создадим. То есть примитивы, которые мы по идее должны прочитать с диска, мы предварительно снова создаем, чтобы больше никогда их не использовать.
Выглядит это примерно так:
В функции load() приходится создавать примитивы (объявление переменной custom_primitives), которые не будут использоваться. Но без этого дальнейшая загрузка признаков в месте вызова функции load_features() упадет с ошибкой RuntimeError: Primitive «percentile05» in module «featuretools.primitives.base.aggregation_primitive_base» not found.
Получается не очень логично, зато работает, и можно сохранять как уже привязанный к определенному формату данных калькулятор (так как признаки завязаны на EntitySet, для которого они были посчитаны, хоть и без самих значений), так и калькулятор лишь с заданным списком примитивов.
Возможно, в будущем это поправят и можно будет удобно сохранять произвольный набор объектов FeatureBase.
Потому что с точки зрения времени разработки это дешево, при этом время ответа при существующей нагрузке укладывается в наш SLA (5 секунд) с запасом.
Однако стоит отдавать себе отчет в том, что для сервиса, который должен быстро отвечать на часто поступающие запросы, использовать featuretools без дополнительных «приседаний» вроде асинхронных вызовов будет проблематично.
Таков наш опыт использования featuretools на этапах обучения и inference-а.
В качестве инструмента для быстрого расчета большого числа признаков для обучения этот фреймворк очень хорош, сильно сокращает время разработки и уменьшает вероятность ошибок.
Использовать ли его на этапе вывода — зависит от ваших задач.
Можно делать это вручную, но также для этого существуют фреймворки и библиотеки, ускоряющие и упрощающие этот процесс.
Об одной из них, featuretools, а также о практическом опыте ее использования мы сегодня и поговорим.

Моднейший пайплайн
Всем привет! Я Александр Лоскутов, работаю в «Леруа Мерлен» аналитиком данных, или, как это модно сейчас называть, data-scientist-ом. В мои обязанности входит работа с данными, начиная c аналитических запросов и выгрузок, заканчивая обучением модели, оборачиванием ее, например, в сервис, настройкой доставки и развертывания кода, а также мониторинга его работы.
Предсказание отмен — один из продуктов, над которым я работаю.
Задача продукта: предсказать вероятность отмены заказа клиентом, сделанного онлайн. С помощью такого предсказания мы можем определить, кому из клиентов, сделавших заказ, нужно позвонить в первую очередь, чтобы попросить подтвердить заказ, а кому можно и не звонить вовсе. Во-первых, сам факт звонка и подтверждения заказа от клиента по телефону уменьшает вероятность отмены, а во-вторых, если мы позвоним и человек откажется, то мы сможем сэкономить ресурсы. У сотрудников высвободится больше времени, которое они бы потратили на то, чтобы собрать заказ. К тому же так товар останется на полке, и если в этот момент находящемуся в магазине покупателю он понадобится, то он сможет его купить. И таким образом уменьшится количество товаров, которые были собраны в отмененные позже заказы и не присутствовали на полках.
Предтечи
Для пилота продукта мы берем только заказы с постоплатой при самовывозе в нескольких магазинах.
Готовое решение работает примерно так: к нам приходит заказ, с помощью Apache NiFi мы обогащаем информацию по нему — например, подтягивая данные по товарам. Затем все это через брокера сообщений Apache Kafka передается в сервис, написанный на Python. Сервис рассчитывает признаки для заказа, а дальше за них берется модель машинного обучения, которая выдает вероятность отмены. После этого мы в соответствии с бизнес-логикой готовим ответ, нужно звонить клиенту сейчас или нет (например, если заказ сделан с помощью сотрудника внутри магазина или заказ сделали ночью, то звонить не стоит).
Казалось бы, что мешает звонить всем подряд? Дело в том, что количество ресурсов для звонков у нас ограничено, поэтому важно понимать, кому обязательно стоит звонить, а кто и без звонка точно заберет свой заказ.
Разработка модели
Я занимался сервисом, моделью и, соответственно, расчетом признаков для модели, о котором и пойдет дальше речь.
При расчете признаков во время обучения мы используем три источника данных.
- Табличка с метаинформацией о заказе: номер заказа, timestamp, устройство клиента, способ доставки, способ оплаты.
- Табличка с позициями в чеках: номер заказа, артикул, цена, количество, количество товара на складе. Каждая позиция идет отдельной строкой.
- Таблица — справочник товаров: артикул, несколько полей с категорией товара, единицы измерения, описание.
Стандартными методами Python и библиотекой pandas можно легко объединить все таблицы в одну большую, после чего, используя groupby, посчитать разного рода признаки вроде агрегатов по заказу, истории по товару, по категориям товаров и т. д. Но тут возникает несколько проблем.
- Параллельность вычислений. Стандартный groupby работает в одном потоке, и на больших данных (до 10 млн строк) сотня признаков считается уже неприемлемо долго, притом что мощности остальных ядер простаивают.
- Количество кода: каждый такой запрос нужно отдельно написать, проверить на правильность, а потом все результаты еще нужно собрать. Это требует времени, особенно учитывая сложность некоторых вычислений — например, расчета последней истории по товару в чеке и агрегации этих признаков для заказа.
- Можно допустить ошибки, если все кодить вручную.
Плюсом подхода «пишем все вручную» является, конечно же, полная свобода действий, можно дать своей фантазии развернуться.
Возникает вопрос: как можно оптимизировать эту часть работы. Одним из решений является использование библиотеки featuretools.
Тут мы уже переходим к сути этой статьи, а именно к самой библиотеке и практике ее применения.
Почему featuretools?
Рассмотрим различные фреймворки для машинного обучения в виде таблички (сама картинка честно украдена отсюда, и наверняка там указаны не все, но все же):
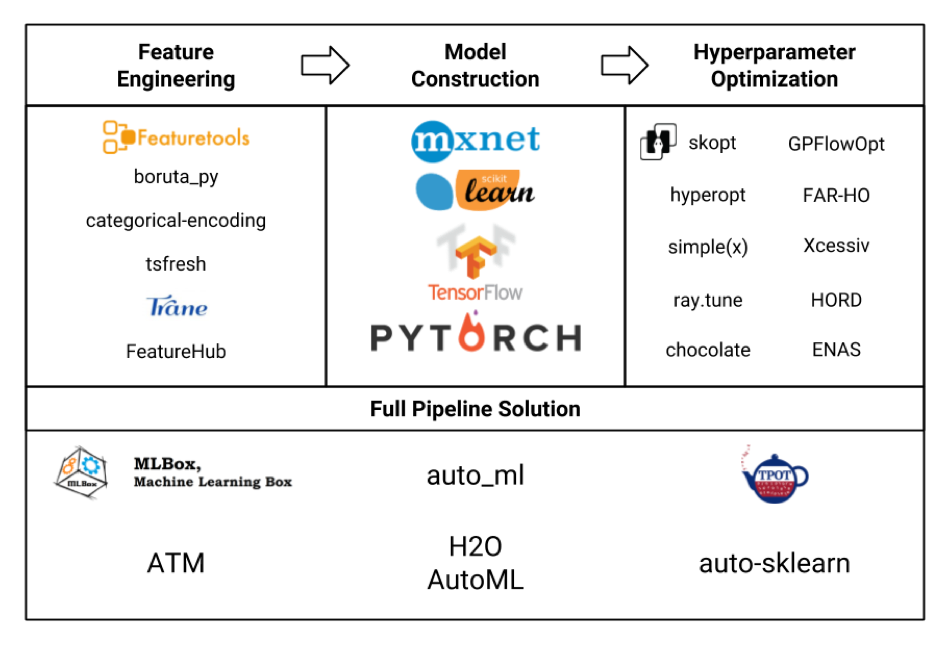
Нас интересует в первую очередь блок Feature Engineering. Если рассмотреть все эти фреймворки и пакеты, то выяснится, что самым «навороченным» из них является featuretools, и он даже включает в себя функциональность некоторых других библиотек вроде tsfresh.
Также к достоинствам featuretools (совсем не реклама!) можно отнести:
- параллельное вычисление «из коробки»
- доступность множества признаков «из коробки»
- гибкость в настройке — можно считать довольно сложные штуки
- учет отношений между разными табличками (реляционность)
- меньше кода
- меньшая вероятность допустить ошибку
- само собой все бесплатно, без регистрации и СМС (но с pypi)
Но не все так просто.
- Фреймворк требует некоторого изучения, а полное освоение и вовсе займет приличное количество времени.
- У него не такое большое комьюнити, хотя самые популярные вопросы все же хорошо гуглятся.
- Само использование также требует аккуратности, чтобы не раздувать пространство признаков без надобности и не увеличивать время расчета.
Обучение
Приведу пример конфигурации featuretools.
Далее будет код с краткими объяснениями, более подробно про featuretools, его классы, методы, возможности можно почитать в том числе в документации на сайте фреймворка. Если вам будут интересны примеры практического применения с демонстрацией некоторых интересных возможностей в реальных задачах, то пишите в комментариях, возможно, запилю отдельную статью.
Итак.
Сначала нужно создать объект класса EntitySet, который содержит таблицы с данными и знает про их связи между собой.
Напомню, что у нас три таблицы с данными:
- orders_meta (мета-информация о заказах)
- orders_items_lists (информация о позициях в заказах)
- items (справочник артикулов и их свойств)
Пишем (далее используются данные только 3-х магазинов):
import featuretools as ft
es = ft.EntitySet(id='orders') # создаем пустой объект класса EntitySet
# по очереди добавляем в него pandas.DataFrame-ы как сущности (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
# объявляем отношения между сущностями
# для задания отношения сначала указываем сущность-родителя,
# затем сущность-ребенка
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
# добавляем отношения
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Ура! Теперь у нас есть объект, который позволит нам считать разного рода признаки.
Приведу код для расчета довольно простых признаков: для каждого заказа посчитаем различные статистики по ценам и количеству товаров, а также пару признаков по времени и самые частые товары и категории товаров в заказе (функции, выполняющие разного рода преобразования с данными, в featuretools называются примитивами).
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)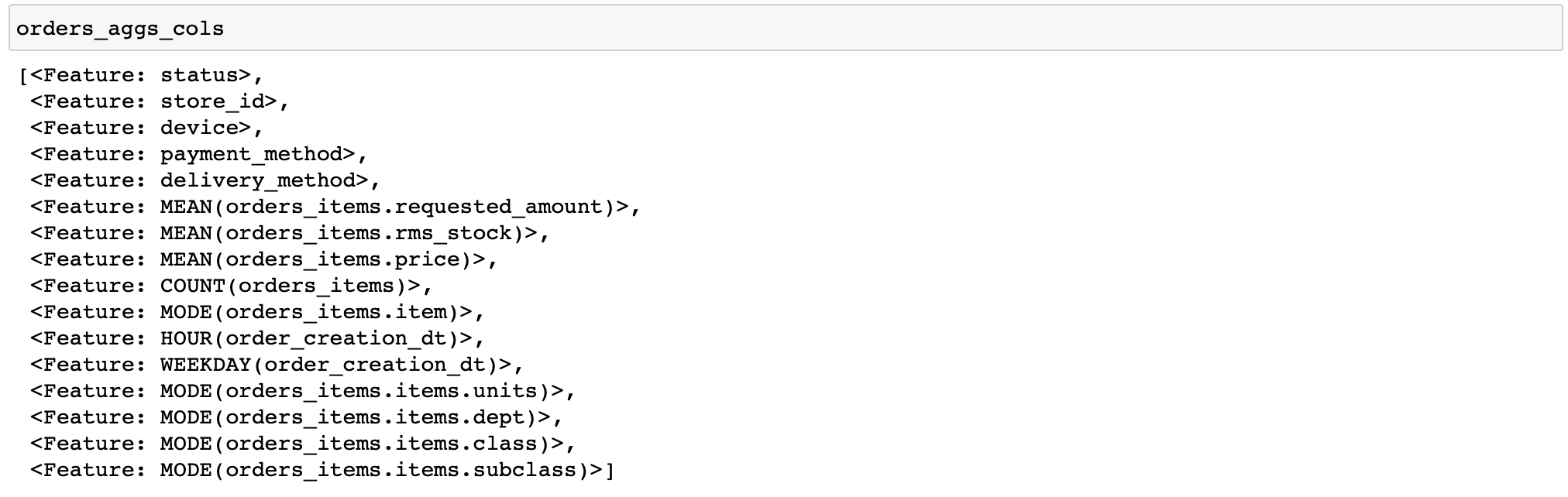

Здесь в таблицах нет столбцов типа boolean, поэтому примитив any не был применен. Вообще удобно, что featuretools сам анализирует тип данных и применяет лишь соответствующие функции.
Также я вручную указал только несколько заказов для расчета. Это позволяет быстро дебажить свои вычисления (вдруг вы сконфигурировали что-то не то).
Теперь добавим к нашим признакам еще несколько агрегатов, а именно перцентили. Но в featuretools нет встроенных примитивов для их расчета. Значит, нужно написать самим.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
И добавим их в расчет:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Дальше все то же самое. Пока все довольно просто и легко (относительно, конечно).
А что если мы хотим сохранить наш калькулятор признаков и использовать его на этапе исполнения модели, то есть в работе сервиса?
Featuretools в бою
Тут-то и начинаются основные сложности.
Для расчета признаков по входящему заказу придется опять проделать все операции с созданием EntitySet. И если для больших таблиц закидывать pandas.DataFrame-объекты в EntitySet кажется вполне нормальным, то делать аналогичные операции для DataFrame-ов из одной строки (в таблице с чеками их больше, но в среднем 3.3 позиции на один чек, то есть мало) — уже не очень. Ведь создание таких объектов и расчеты с их помощью неизбежно содержат оверхед, то есть неустранимое количество операций, необходимых, например, для выделения памяти и инициализации при создании объекта любого размера или самого процесса распараллеливания при вычислении нескольких признаков одновременно.
Поэтому в режиме работы «один заказ за раз» в нашем продукте featuretools показывает не лучшую эффективность, занимая в среднем 75% времени ответа сервиса (в среднем 150-200 мс в зависимости от железа). Для сравнения: вычисление предсказания с помощью catboost-а на готовых признаках занимает 3% от времени ответа сервиса, т. е. не более 10 мс.
Помимо этого, есть еще один подводный камень, связанный с использованием кастомных примитивов. Дело в том, что мы не можем просто сохранить в pickle объект класса, содержащего созданные нами примитивы, так как последние не пиклятся.
Тогда почему бы не воспользоваться встроенной функцией save_features(), которая может сохранить список объектов класса FeatureBase, в том числе созданные нами примитивы?
Сохранить-то она их сохранит, а вот прочитать потом с помощью функции load_features() их не получится, если мы заранее их снова не создадим. То есть примитивы, которые мы по идее должны прочитать с диска, мы предварительно снова создаем, чтобы больше никогда их не использовать.
Выглядит это примерно так:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# класс-калькулятор признаков
# при инициализации мы указываем целевую сущность,
# для объектов которой мы будем считать признаки
# передаем также список агрегирующих примитивов
# еще можно передать список наших кастомных примитивов (в виде параметров их создания),
# глубину расчета признаков и паттерны признаков, которые мы считать не хотим
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # список признаков (объектов типа ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
# метод для создания списка признаков из наших примитивов
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# функция, считающая матрицу значений признаков
# для некоторых списка признаков и набора сущностей
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
# непосредственно вызываемый метод класса для расчета признаков
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
# метод для сохранения калькулятора
# список признаков сразу запиклить нельзя,
# поэтому сначала вызывается метод save_features()
# после чего пиклятся все аргументы конструктора
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
# метод для загрузки ранее сохраненного калькулятора
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# нужно инициализировать кастомные примитивы...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
# иначе в этом месте будет ошибка
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorВ функции load() приходится создавать примитивы (объявление переменной custom_primitives), которые не будут использоваться. Но без этого дальнейшая загрузка признаков в месте вызова функции load_features() упадет с ошибкой RuntimeError: Primitive «percentile05» in module «featuretools.primitives.base.aggregation_primitive_base» not found.
Получается не очень логично, зато работает, и можно сохранять как уже привязанный к определенному формату данных калькулятор (так как признаки завязаны на EntitySet, для которого они были посчитаны, хоть и без самих значений), так и калькулятор лишь с заданным списком примитивов.
Возможно, в будущем это поправят и можно будет удобно сохранять произвольный набор объектов FeatureBase.
Почему же тогда мы его используем?
Потому что с точки зрения времени разработки это дешево, при этом время ответа при существующей нагрузке укладывается в наш SLA (5 секунд) с запасом.
Однако стоит отдавать себе отчет в том, что для сервиса, который должен быстро отвечать на часто поступающие запросы, использовать featuretools без дополнительных «приседаний» вроде асинхронных вызовов будет проблематично.
Таков наш опыт использования featuretools на этапах обучения и inference-а.
В качестве инструмента для быстрого расчета большого числа признаков для обучения этот фреймворк очень хорош, сильно сокращает время разработки и уменьшает вероятность ошибок.
Использовать ли его на этапе вывода — зависит от ваших задач.
