Большинство наших

Меня зовут Марина Калабина, я руководитель проектов в «Леруа Мерлен». Пришла в компанию в 2011 году. Первые пять лет открывала магазины (когда я пришла, их было 13, сейчас 107), потом работала в магазине в качестве руководителя торгового сектора и вот уже полтора года занимаюсь тем, что с позиции
«Леруализмы»
Поскольку я давно работаю в компании, то речь моя наполнена специфическими терминами, которые я называю «леруализмы». Чтобы мы говорили с вами на одном языке, привожу некоторые из них.
- Сток — запас товаров в магазине.
- Доступный для продажи сток — количество товара, свободное от блокировок и резервов для клиента.
- Экспо — витринный образец.
- Артикулы — товары.
- Оперативная инвентаризация — ежедневный пересчет 5 артикулов в каждом отделе каждого магазина.
Гарантированный сток
Возможно, вы не знаете, но когда вы оформляете заказ в «Леруа Мерлен», в 98% случаев он приходит в магазин и собирается из торгового зала.
Представьте себе огромные 8 000 кв. м магазина, 40 000 артикулов и задачу собрать заказ. Что может произойти с артикулами вашего заказа, которые ищет сборщик? Товар может быть уже в корзине клиента, который ходит по торговому залу, или даже может быть продан между тем моментом, когда вы его заказали, и тем, когда сборщик пошел за ним. На сайте товар есть, а в действительности он либо
Для того чтобы бороться с разными проблемами, и в том числе с этой, в прошлом году в компании было запущено подразделение Data Accelerator. Его миссия — привить
Суть продукта в том, что перед публикацией стока товара на сайте мы проверяем, можем ли собрать этот артикул клиенту, гарантируем ли ему это. Чаще всего это достигается чуть меньшим количеством стока, который мы публикуем на сайте.
У нас была классная команда: Data Scientist, Data Engineer, Data Analyst, Product Owner и
Целями нашего продукта были:
- сократить количество несобранных заказов, при этом не повредив количеству заказов в принципе (чтобы оно не сократилось);
- сохранить товарооборот в eCom, поскольку мы будем меньше показывать товаров на сайте.
В общем, при прочих равных сделать лучше.
Бюро расследований
Когда проект стартовал, мы поехали в магазины, к людям, которые каждый день работают с этим: мы сами пошли собирать заказы. Оказалось, что наш продукт настолько интересен и нужен магазинам, что нас попросили запуститься не через 3 месяца, как было запланировано вначале, а в два раза быстрее, то есть через 6 недель. Это, мягко говоря, было стрессом, но тем не менее…
Мы собрали гипотезы от экспертов и пошли искать, какие же у нас в принципе есть источники данных. Это был отдельный квест. Фактически «бюро расследований» показало, что у нас имеются такие товары, у которых обязательно есть витринный образец.
Например, смеситель — у таких товаров всегда есть образец в зале. Более того, мы не имеем права продать экспо, потому что он может быть уже поврежден и гарантия на него не распространяется. Мы находили такие товары, у которых не проставлен витринный образец, а доступный сток для продажи показан 1. Но, скорее всего, это тот самый экспо, который мы не сможем продать. А клиент может его заказать. Это одна из проблем.
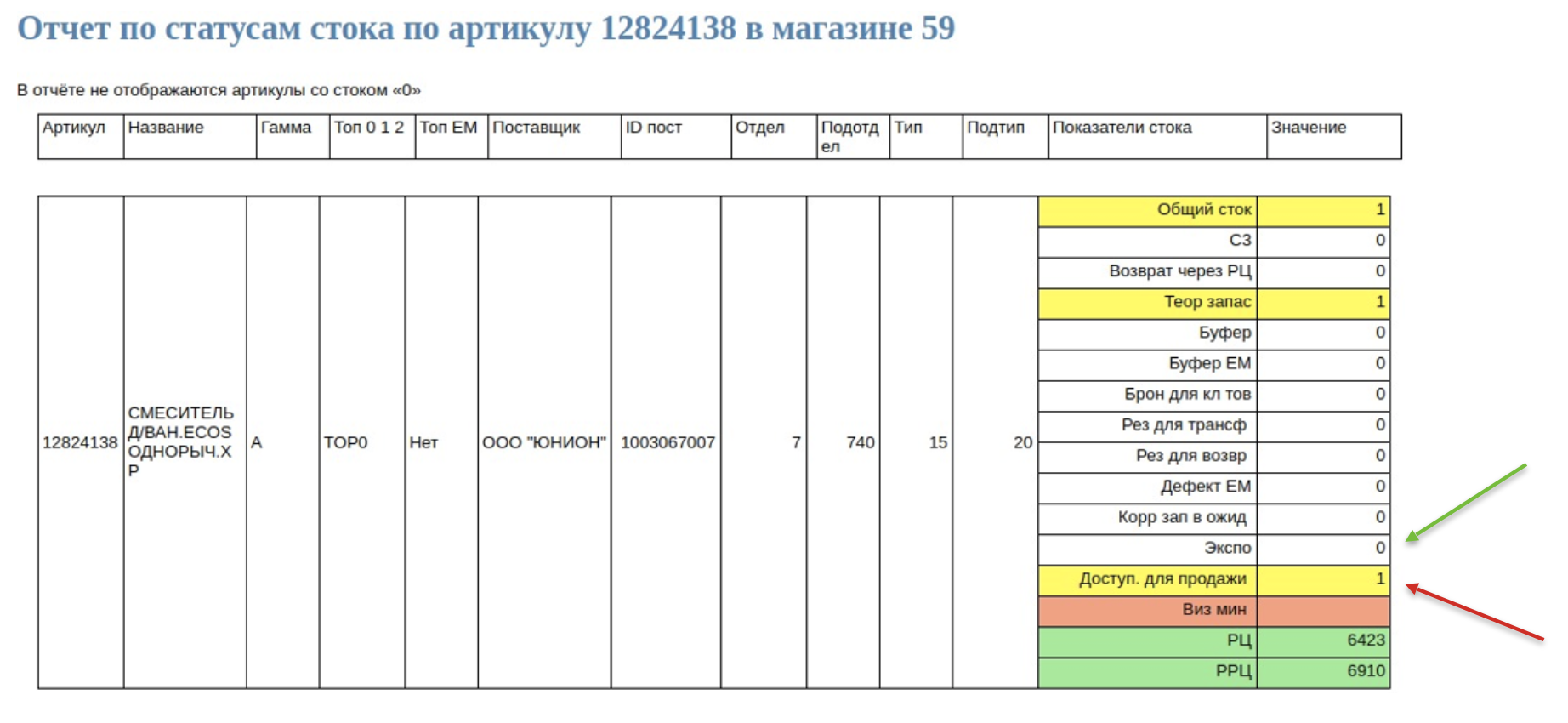
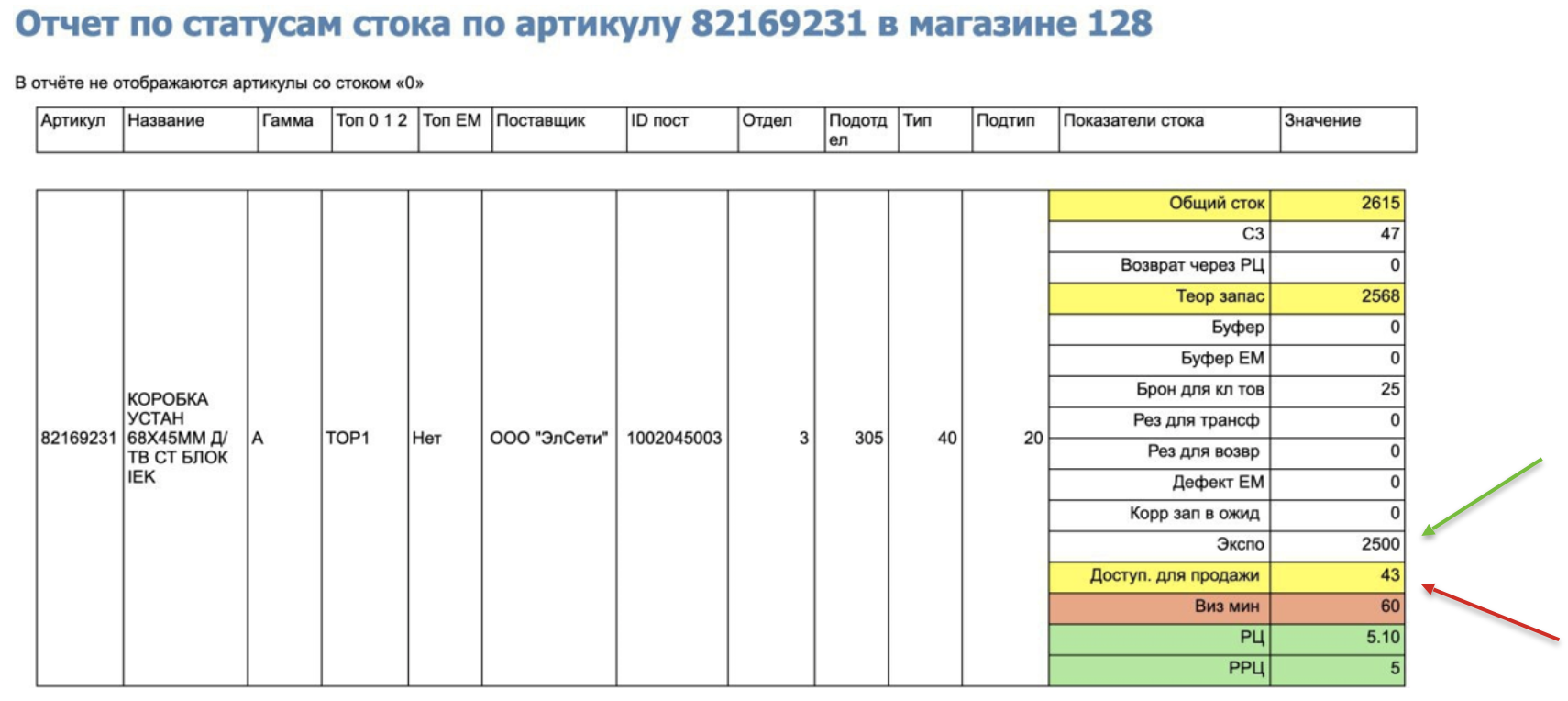
Следующая история — обратная. Мы обнаружили, что иногда у товаров бывает слишком большое количество витринных образцов. Скорее всего, либо произошел сбой системы, либо вмешался человеческий фактор. Вместо того чтобы на сайте показывать 2500 установочных коробок, мы можем показать только 43, потому что у нас сбой в системе. И мы научили наши алгоритмы находить в том числе и такие «косяки».
Валидация
Поисследовав данные, мы собирали
Что касается примеров, когда мы находили слишком большое количество витринных образцов, практически в 60% случаев мы были правы, предполагая ошибку. А когда мы искали недостаточное количество экспо или их отсутствие, то были правы в 81%, что, в
Запуск MVP. Первый этап
Поскольку нам надо было уложиться в 6 недель, мы запускали proof of concept вот с таким линейным алгоритмом, который находил аномальные значения, делал поправку на эти значения перед тем, как публиковать на сайт. И у нас было два магазина, в двух разных регионах, чтобы мы могли сравнить эффект.
Кроме того, был сделан дашборд, где, с одной стороны, мы мониторили технические параметры, а с другой — показывали нашим заказчикам, по сути магазинам, как отрабатывают наши алгоритмы. То есть мы сравнивали, как они работали до запуска и как стали работать после, показывали, сколько денег позволяет заработать использование этих алгоритмов.
Правило «-1». Второй этап
Эффект от работы продукта быстро стал заметен, и нас стали спрашивать, почему мы обрабатываем такое маленькое количество артикулов: «Давайте возьмем весь сток магазина, из каждого артикула вычтем одну штуку, и, может быть, это нам позволит решить проблему глобально». К этому моменту мы уже начали работать над моделью машинного обучения, нам казалось, что подобная «ковровая бомбардировка» может навредить, но возможность такого эксперимента упускать не хотелось. И мы запустили тест на 4 магазинах для того, чтобы проверить эту гипотезу.
Когда через месяц мы посмотрели на результаты, то выяснили два важных обстоятельства.
ML-модель . Третий этап
Итак, мы сделали
- Модель реализована с помощью градиентного бустинга на Catboost, и это дает предсказание вероятности того, что сток товара в данном магазине в данный момент является некорректным.
- Модель была обучена на результатах оперативной и ежегодной инвентаризаций, и в том числе на данных по отмененным заказам.
- В качестве косвенных указаний на возможность некорректного стока использовались такие признаки, как данные о последних движениях по стоку данного товара, о продажах, возвратах и заказах, о доступном для продажи стоке, о номенклатуре, о некоторых характеристиках товара и прочем.
- Всего в модели использовано около 70 фичей.
- Среди всех признаков были отобраны важные с использованием различных подходов к оценки важности, в том числе Permutation Importance и подходов, реализованных в библиотеке Catboost.
- Чтобы проверить качество и подобрать гиперпараметры модели, данные были разбиты на тестовую и валидационную выборки в соотношении 80/20.
- Модель была обучена на более старых данных, а проверялась на более новых.
- Финальная модель, которая в итоге пошла в прод, была обучена на полном датасете с использованием гиперпараметров, подобранных с помощью разбиения на train/
valid-части . - Модель и данные для обучения модели версионируются с помощью DVC, версии модели и датасетов хранятся на S3.
Итоговые метрики полученной модели на валидационном наборе данных:
ROC-AUC : 0.68- Recall: 0.77
Архитектура
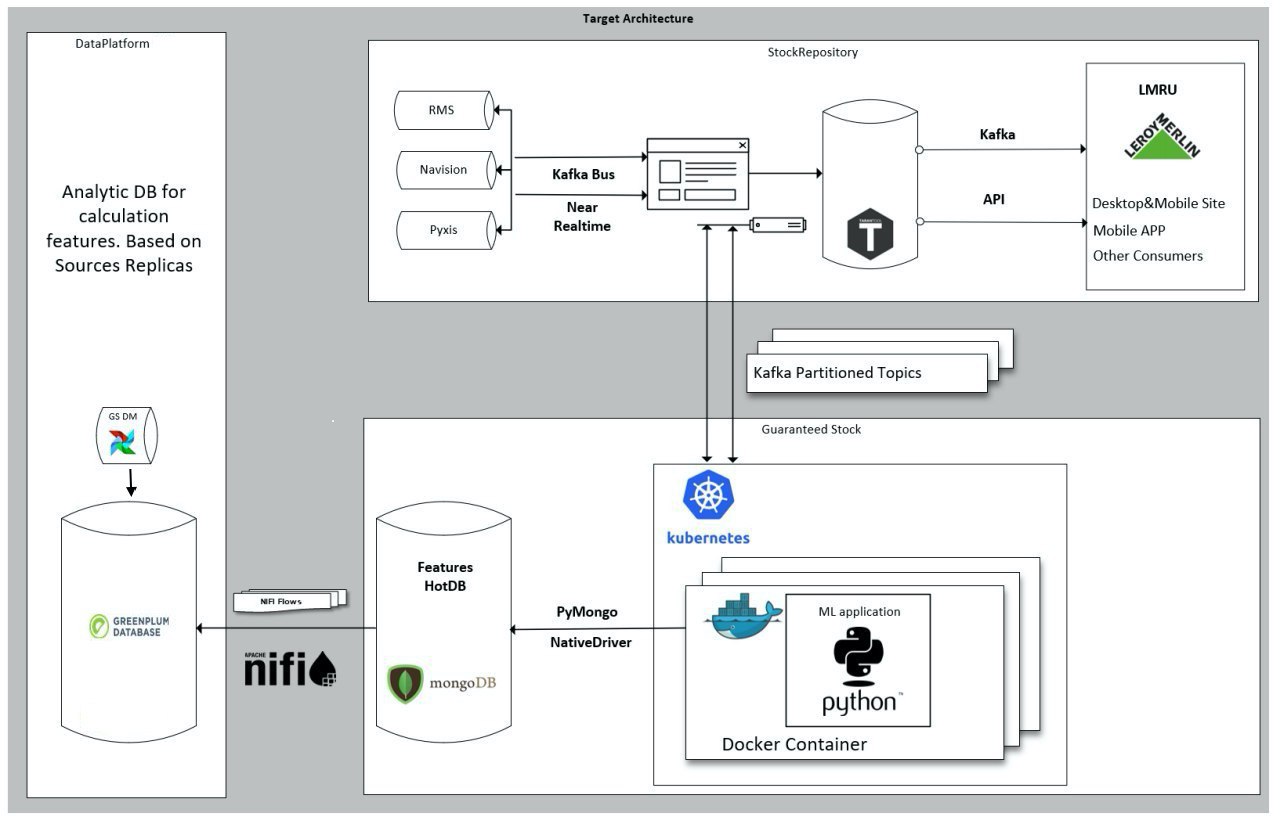
Немного про архитектуру — как это у нас реализуется в проде. Для обучения модели используются реплики операционных и продуктовых систем компании, консолидированные в едином DataLake на платформе GreenPlum. На основе реплик рассчитываются фичи, хранящиеся в MongoDB, что позволяет организовать горячий доступ к ним. Оркестрация расчета фичей и интеграция GreenPlum и MongoDB реализована с использованием
Модель машинного обучения представляет собой контейнеризованное
Результаты
У нас было 6 магазинов и результаты показали, что из плановых 15% мы смогли сократить количество несобранных заказов на 12%, при этом у нас выросли товарооборот
На данный момент, обученная нами модель используется не только для редактирования стока перед публикацией на сайте, но и для улучшения алгоритмов оперативной инвентаризации. Какие артикулы нужно сегодня посчитать именно в этом отделе, именно в этом магазине — такие, за которыми придут клиенты, и которые хорошо было бы проверить. В общем модель оказалась еще и мультифункциональной и переиспользуется в компании в других подразделениях.
p.s.Статья написана по выступлению на митапе Avito.Tech, посмотреть видео можно по ссылке.
