Комментарии 57
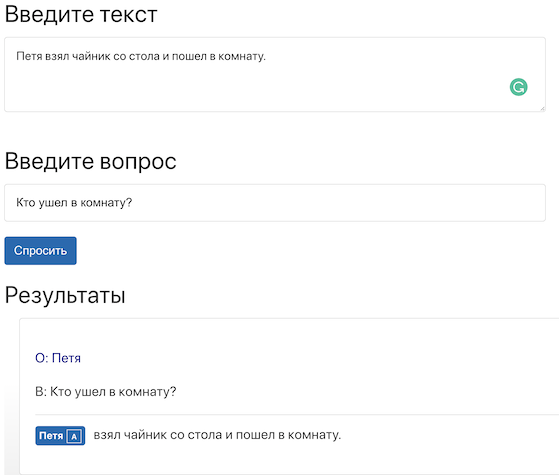
У меня такой вопрос: Петя взял чайник со стола. Как думаешь, куда он пойдёт? — с контекстом уже разобрались? Нейронка поймёт, что вопрос о Пете, а не о чайнике?
+1, и мне интересно.
Нейронка вам ответит: чайник — полое изделие с носиком для кипячения чая. Вы можете купить их в магазине…
А если серьёзно — нет там никакого смысла, тупой матчинг по количеству слов. Т.е. если вы попадёте в шаблон вопроса, в котором есть нужные слова — вам и ответят нужными ответами.
А если серьёзно — нет там никакого смысла, тупой матчинг по количеству слов. Т.е. если вы попадёте в шаблон вопроса, в котором есть нужные слова — вам и ответят нужными ответами.
Все таки не совсем «тупой матчинг»:
На демо страничке iPavlov можно поиграться.
Наверняка есть случаи когда модель ошибается, но прогресс ощутимый. Особенно, когда модель мощная. Мощные модели чаще на аглийском говорят.
И надо учитывать, что демонтрастрация от DeepPavlov основана на разработке Фейсбука, которой уже более трех лет.
Заголовок спойлера


На демо страничке iPavlov можно поиграться.
Наверняка есть случаи когда модель ошибается, но прогресс ощутимый. Особенно, когда модель мощная. Мощные модели чаще на аглийском говорят.
И надо учитывать, что демонтрастрация от DeepPavlov основана на разработке Фейсбука, которой уже более трех лет.
С контекстом судя по всему разобрались.
На демо страничке iPavlov можно поиграться.
Заголовок спойлера

На демо страничке iPavlov можно поиграться.
Справедливости ради, «Петя взял чайник со стола и пошел в комнату» и «Петя взял чайник со стола. Как думаешь, куда он пойдёт?» — вопросы очень разного уровня сложности для ИИ. В первом предложении ясно, кто куда пойдет, а во втором, по правилам русского языка, пойдет чайник, потому что его упоминают последним. Мне не удалось пока получить ответ.
Заголовок спойлера


Да нет же, чайник не умеет ходить, даже примитивная нейронка поймет что «ходить» ближе к Пете, чем к чайнику, не говоря о чем-то продвинутом. Куда интереснее задача «Петя встретил Сергея. Как думаешь, куда он пойдёт?». Кто запрещает задавать дополнительные вопросы при примерно одинаковых контекстах, как это делает человек?
О. Про «ходить» я не подумал. Моя нейросеть менее продвинутая. ;)
А в «Петя встретил Сергея. Как думаешь, куда он пойдёт?» действительно недостаточно контекста для ответа, это и человек не поймет.
А в «Петя встретил Сергея. Как думаешь, куда он пойдёт?» действительно недостаточно контекста для ответа, это и человек не поймет.
Мне кажется, человек подумает, что речь о Сергее, потому что Сергей появился в контексте повествования, возможно раз он появился, ему и идти куда-то. Но руский язык очень гибкий и если им неграмотно изъясняться, можно запутать собеседника, а программу и подавно. «Лена легла на диван и уронила ложку. Она долго лежала.»
Я с этим всем знаком поверхностно, но мне было удобно размышлять нормализуя понятия, собирая любую информацию об объекте, например Петя. Семантический разбор позволяет сделать вывод из «Петя взял чайник со стола», что есть подлежащее Петя, чайник и стол. Сказуемое указывает, что с этими объектами произошло, Петя получил чайник, стол лишился, чайник сменил владельца. Даже не имея никакого опыта можно предположить, что чайник это скорее про объект, а следовательно скорее всего действие будет делать не он, а субъект либо стол, либо вероятнее Петя, так как именно он умеет делать активные вещи, а стол не доказано.
Я с этим всем знаком поверхностно, но мне было удобно размышлять нормализуя понятия, собирая любую информацию об объекте, например Петя. Семантический разбор позволяет сделать вывод из «Петя взял чайник со стола», что есть подлежащее Петя, чайник и стол. Сказуемое указывает, что с этими объектами произошло, Петя получил чайник, стол лишился, чайник сменил владельца. Даже не имея никакого опыта можно предположить, что чайник это скорее про объект, а следовательно скорее всего действие будет делать не он, а субъект либо стол, либо вероятнее Петя, так как именно он умеет делать активные вещи, а стол не доказано.
Звонок телефона оторвал Васю от телевизора? :)
Чисто по канону, да, речь о Сергее, потому что его упоминали последним. А чисто эмционально, мы, как в сериале, начали следит за Петей, и нам хочется продолжать следить за ним дальше, а не переключаться каждую секунду. Арка сезона, так сказать: куда пойдет Петя?)
Я к тому, что мозг человека тоже по какому-то алгоритму действует. Дети довольно примитивны до чудачеств, но при этом относительно дееспособны. От ИИ никакой дееспособности пока не требуется.
Дееспособности какого класса? Нести уголовную ответственность за сообщаемую информацию? Дети в этом плане тоже не слишком дееспособны. Я не спорю сейчас, а настраиваю парамерты нейросети на корректные термины.)
Простите, влезу в дискуссию со своим вопросом)
Я учусь на программиста. У меня есть мои данные небольшие — как проще всего доучить модель? Есть ли репы для этого?
Я учусь на программиста. У меня есть мои данные небольшие — как проще всего доучить модель? Есть ли репы для этого?
mbur, подскажете будущему программисту, как доучить модель? :)
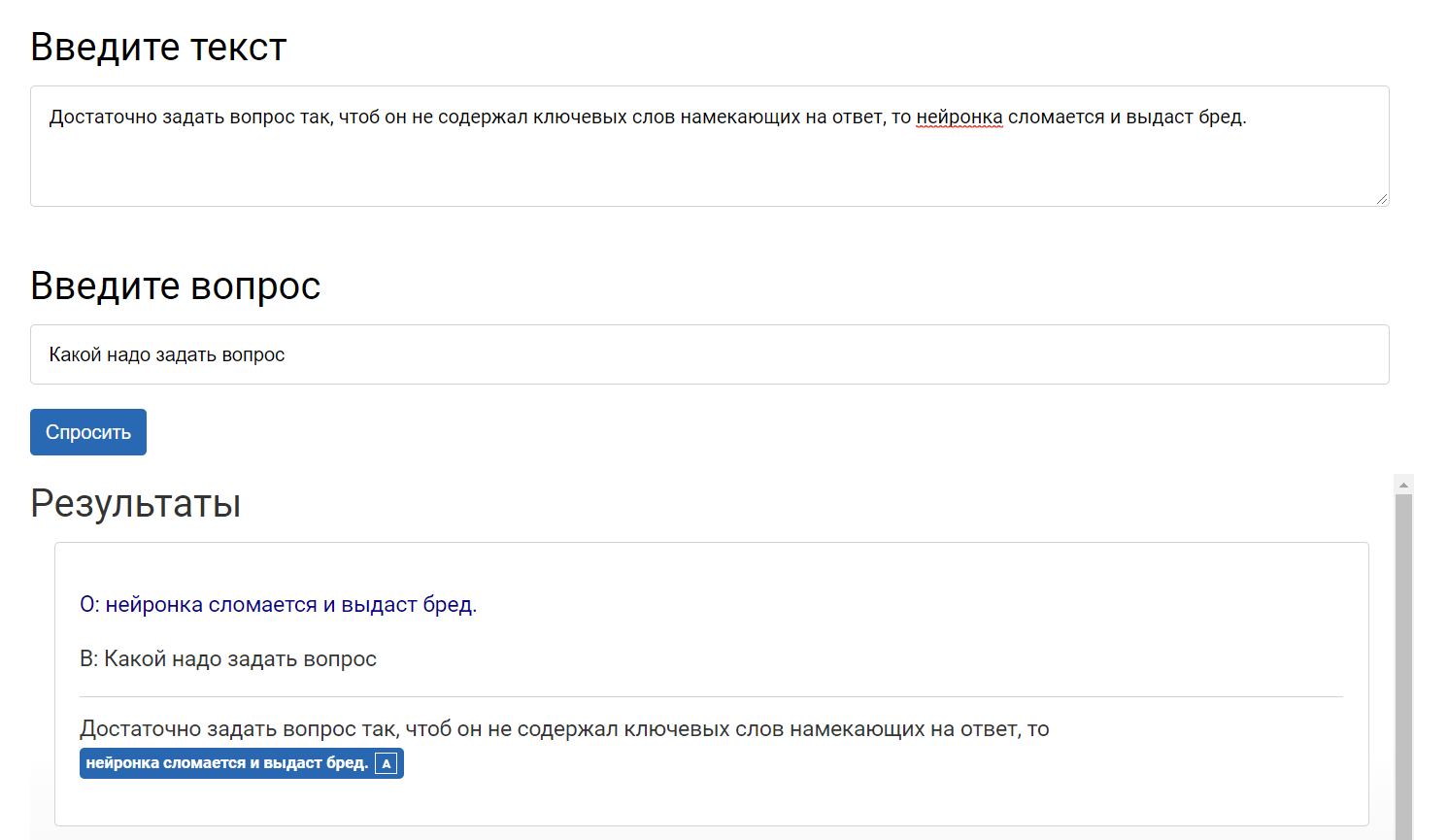
Только с очевидными вещами в пределах предложения, и это очень смахивает на матчинг. Выделяет слова, ищет предложение и подбирает остаток. Достаточно задать вопрос так, чтоб он не содержал ключевых слов намекающих на ответ, то нейронка сломается и выдаст бред.
Пример

Печаль, триггер на `как - так` сломался

Есть некоторые проблемы:
Скрытый текст

оч мало знаю о нейросетях, я бы предположил что там должно быть два слоя.
один преобразует челевеческий язык в искусственный где подобных проблем не существует, например
Петя взял чайник со стола. Как ты думаешь, куда Петя сейчас пойдет.
И дальше уже дальнейшая свертка.
Нейросеть не знает кто такой петя, так что петя превращается в «человек» и дальше по идее этот вопрос должен разбираться в абстрактном ключе. Можно решить что данных не достаточно, и ответить не знаю и выбрать для него форму более соотвествующую абстрактному вопросу и ответить «хз» или «сложно сказать». но также можно и посмотреть альтернативные значения «пойдет» и рассмотреть альтернативный вариант «человек взял со стола чайник что он собирается делать» и ответить «пить чай».
один преобразует челевеческий язык в искусственный где подобных проблем не существует, например
Петя взял чайник со стола. Как ты думаешь, куда Петя сейчас пойдет.
И дальше уже дальнейшая свертка.
Нейросеть не знает кто такой петя, так что петя превращается в «человек» и дальше по идее этот вопрос должен разбираться в абстрактном ключе. Можно решить что данных не достаточно, и ответить не знаю и выбрать для него форму более соотвествующую абстрактному вопросу и ответить «хз» или «сложно сказать». но также можно и посмотреть альтернативные значения «пойдет» и рассмотреть альтернативный вариант «человек взял со стола чайник что он собирается делать» и ответить «пить чай».
С какой-то вероятностью нейронка сможет это понять. Тут под контекстом понимаются знания о мире, имеющиеся у читателя и помогающие дать правильный ответ. Современные нейросетевые модели, частично выучивают такие знания в скрытой форме, и их можно использовать для решения задачи кореференции из примера.
С другой стороны, возможности современных моделей ограничены, как это удалось понять по экспериментам с демкой нашего проекта в треде :) Но качество постоянно растет, и подобные задачи все лучше и лучше решаются.
С другой стороны, возможности современных моделей ограничены, как это удалось понять по экспериментам с демкой нашего проекта в треде :) Но качество постоянно растет, и подобные задачи все лучше и лучше решаются.
Современные нейросетевые модели, частично выучивают такие знания в скрытой форме
Экспериментирвать с возможностями демки было крайне познавательно. А что значит «выучивают в скрытой форме»?
Но качество постоянно растет, и подобные задачи все лучше и лучше решаются.
А можно с какой-то вероятностью прогнозировать этот рост качества? Когда, например, она сможет отвечать на вопрос про Петю и чайник из первого комментария?
Распил это всегда прикольно.
НЛО прилетело и опубликовало эту надпись здесь
:) Дело не в теплоходе, а в знании математики. Рериху (первое, что на ум пришло) помогали путешествия, а Фейнману — ударные. Это не значит, что каждый, кто схватил палатку и ломанулся в лес, завтра будет писать мощные картины, а всех, кто схватил барабан, ждут в Калтехе. У меня были сомнения по поводу не убрать ли теплоход, чтобы не цепляллись, что боже мой, кто-то поплыл на теплоходе, но если у человека реально там кристаллизовалась идея, которая пошла в рост, почему нет.
Я вот не участвовала в том теплоходе, но много про него слышала позитивного от людей разного градуса цинизма. Похоже, там было неплохо и это многим людям дало импульс на несколько лет. И это интересно, мне очень всегда интересно, что было в самом начале проекта, первой искрой. Кроме знания математики, конечно.
Я вот не участвовала в том теплоходе, но много про него слышала позитивного от людей разного градуса цинизма. Похоже, там было неплохо и это многим людям дало импульс на несколько лет. И это интересно, мне очень всегда интересно, что было в самом начале проекта, первой искрой. Кроме знания математики, конечно.
НЛО прилетело и опубликовало эту надпись здесь
Ну как бы скорее наоборот логично, вы 10 лет пилили статьи и разбирались с тем, как это технически работает (Михаил, кажется, трудился в Келдыше и Курчатовском). На мероприятии организованном НТИ встретили людей, которые готовы дать денег под проект-продукт-исследования и знают других людей, которые готовы работать над темой. У них же есть админ ресурс оформить это при университете в виде лаборатории (где вы, например, могли уже читать спецкурсы и просто уже знать людей).
Я тут однажды помогал делать простой тест на питоне для Хабра и ребята такие говорят, неплохо получилось, мы разговорились и оказалось, что я с ними почти одними темами занимался в исследованиях (последние лет так 7) — позвали преподавать в MADE при mail.ru и вместе пишем заявку на крупные исследования по теме.
Всего-то нужно было оказаться в одном месте и поговорить. И так в общем-то устроены почти все конференции.
Я тут однажды помогал делать простой тест на питоне для Хабра и ребята такие говорят, неплохо получилось, мы разговорились и оказалось, что я с ними почти одними темами занимался в исследованиях (последние лет так 7) — позвали преподавать в MADE при mail.ru и вместе пишем заявку на крупные исследования по теме.
Всего-то нужно было оказаться в одном месте и поговорить. И так в общем-то устроены почти все конференции.
НЛО прилетело и опубликовало эту надпись здесь
:-) Вот Форсайт тут точно ни при чем. Я не удивлюсь, если автор даже не знает, что это вообще такое. Но я уловила вашу мысль и буду просить убирать названия и аббревиатуры, чтобы не будоражить без дела «критическое воприятие».
А «мы» — это команда. Я не знаю этих людей, но спикер про них очень внятно рассказал: почему команду собрали быстро, что делали. Ну и самое главное — на чем бы там ни плавали, а продукт у них крепкий, серьезная работа, хоть с науки к нему заходи, хоть с практики, хоть на корабле.
А «мы» — это команда. Я не знаю этих людей, но спикер про них очень внятно рассказал: почему команду собрали быстро, что делали. Ну и самое главное — на чем бы там ни плавали, а продукт у них крепкий, серьезная работа, хоть с науки к нему заходи, хоть с практики, хоть на корабле.
Участие в форсайте начиналось очень негативно для меня. Было ощущение впустую потраченного времени. Но то что получилось в результате форсайта — выделение рынков и барьеров\технологий — мне показалось вполне адекватным. В целом формат форсайта выгляди логичным на бумаге, но в реальности гораздо более хаотичен. Однако, как показывает мой опыт, может часто быть полезен для синхронизации участников и фокусировке их на выделенном направлении.
Для создания проекта, который позволял бы реализовать мои научные интересы, и был бы интересен в НТИ, пришлось потратить еще год после форсайта. Так что можно сказать, что вклад именно этого мероприятия был не велик, но оно точно было отправной точкой, создавшей возможность реализации проекта.
Для создания проекта, который позволял бы реализовать мои научные интересы, и был бы интересен в НТИ, пришлось потратить еще год после форсайта. Так что можно сказать, что вклад именно этого мероприятия был не велик, но оно точно было отправной точкой, создавшей возможность реализации проекта.
Есть какой-то простой способ написать своего чат-бота на русском? Тьюториал или шаблон? Мы даже однажды вытащили из наших айтишников целый пост про бота, но там все равно не просто.
Да, это вопрос жизни и смерти в наше время. Попросил спикера ответить, выложу, как напишет.
Посмотрите — just-ai.com
А уже можно как-то поиграть с GPT-3?
Это тоже отправил спикеру. Ждем.
Он же вроде опенсорсный, скачивай и играй? Точно недавно про это было на Хабре. О, вот, нашла.
Вот тут он вроде живет: github.com/openai/gpt-3
Была партнерская программа для тестирования. Сейчас, кажется все права переданы MS. Вам стоит посмотреть сайт OpenAI, чтобы узнать текущий статус.
Удивительно, но это не так. Иван Скороходов из нашей лаборатории показал (.pdf), что в пространстве функции потерь нейросети можно найти практически любой двухмерный паттерн.
Есть же теорема на этот счёт, доказанная ещё в 60-ых годах. Это я что-то неправильно понял?
Хочу изучать tensorflow — с чего лучше начать?
я бы начал с www.tensorflow.org/resources/learn-ml#curriculums
mbur, а есть какие-то идеи или планы по гибридизации с викидатой или другими открытыми источниками-базами?
Да, уже есть —
1. Модель привязки сущностей к Wikidata — docs.deeppavlov.ai/en/master/features/models/entity_linking.html
2. модель для ответа на вопросы по Wikidata — docs.deeppavlov.ai/en/master/features/models/kbqa.html
1. Модель привязки сущностей к Wikidata — docs.deeppavlov.ai/en/master/features/models/entity_linking.html
2. модель для ответа на вопросы по Wikidata — docs.deeppavlov.ai/en/master/features/models/kbqa.html
А может ИИ поставить оценки «красиво/не красиво»? Например, даем на вход пул телефонных номеров, а в ответ получаем стоимость по шкале сотового оператора (часто +79585858585 будет золотым и задорого, а +79588855885 обычным и бесплатно). Или даем на вход пул выданных автомобильных номеров и данные по датам и времени выдачи этих номеров автовладельцам, а потом сопоставляем уровень «красоты» номера с временем «придерживания» в отделе.
mbur Зацепил прям этот вопрос, распопаю его немножко: а насколько нейросети вообще натаскиваются на понятие «красивого»? Потому что люди часто красивое не алгоритмизируют: 90 человек из 100 согласны, что это красивое, а вон то нет, а почему, фиг его знает. Это может относиться к цвету, тексту, дизайну, номерам, запахам, к чему угодно — такие сложносоставные контекстные консрукции, которые мозг почему-то оценивает позитивно или негативно. И можно строить поверх объясняющие гипотезы, но, по-честному, не всегда понятно, почему одно красивое, а другое нет.
Да, можно такое сделать если будет несколько сотен или тысяч примеров.
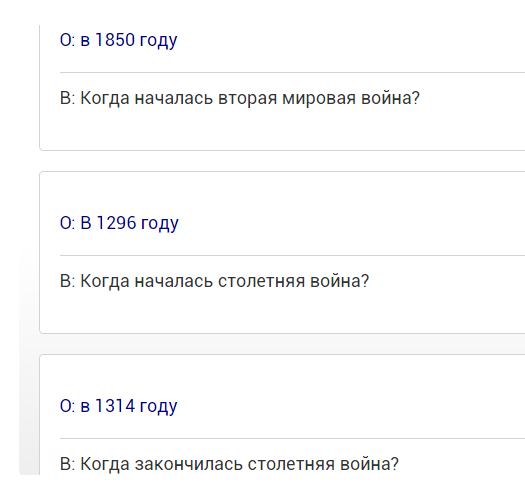
В поиске по википедии с датами грустно:(
В наиболее релевантных статьях по событию, даты начала/окончания указаны только в легенде, без ключевых слов типа «началось/закончилось»
В наиболее релевантных статьях по событию, даты начала/окончания указаны только в легенде, без ключевых слов типа «началось/закончилось»
Заголовок спойлера






Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Куда катится мир нейросетей: интервью с создателем iPavlov