«Победа искусственного интеллекта над футбольными экспертами» – таким мог стать заголовок этой статьи про результаты футбольного соревнования. Мог бы, но, увы, не стал.
Во время Чемпионата мира по футболу у нас в компании "НОРБИТ" проходил конкурс на лучший прогноз матчей по футболу. Я слишком поверхностно разбираюсь в футболе, чтобы на что-то претендовать, но желание принять участие в конкурсе все-таки победило мою лень. Под катом – история о том, как благодаря машинному обучению мне удалось добиться неплохих результатов среди знатоков футбольных команд. Правда, сорвать куш мне не удалось, зато открыл для себя новый увлекательный мир Data Science.

Начал я с гипотезы, что помимо индивидуального мастерства игроков национальных сборных есть еще неизмеримые, но важные факторы — командный дух + сыгранность (например, команда в игре с более сильным соперником, но в зачетном матче и на своем поле чаще одерживает победу). Задача не такая уж и простая для человека, но вполне понятная для машинного обучения.
Когда-то у меня уже был небольшой опыт работы с ML (с библиотекой BrainJS), но в этот раз решил проверить утверждение, что Python гораздо лучше подходит для таких задач.
Знакомство с Python я начал с отличного курса на Coursera, а основы машинного обучения почерпнул из серии статей от Open Data Science на Хабре.
Довольно быстро нашелся отличный Dataset с историей всех игр международных сборных с начала XX века. После импорта в Pandas dataframe:

Всего в базе содержится информация о 39 тысячах игр международных сборных.
Pandas позволяет очень удобно анализировать данные, например, самый результативный матч был между Австралией и Американским Самоа в 2001 году, который закончился со счетом 31:0.

Теперь нужно добавить объективную оценку уровню команды в год проведения матча. Такими оценками занимается FIFA.
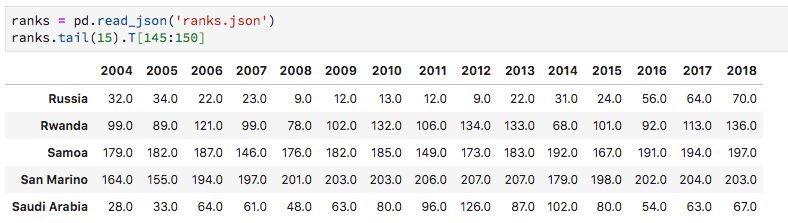

Но, к большому сожалению, рейтинг FIFA ведется только с 1992 года. И, судя по графику рейтинги команд сильно подвержены изменениям, и очень бы не хотелось усреднять позиции команд в мировом рейтинге до этого года.
UEFA ведет свою статистику с более древних времен, но готовый dataset я так и не смог найти, поэтому на помощь пришел этот сайт. Под Node.js для таких задач есть мощный и удобный Сheerio, но под Python все оказалось не менее просто (да простит меня администратор этого сайта).
Колебания рейтинга после добавления рейтинга UEFA (и небольшой правки названий стран по итогам геополитических рокировок):
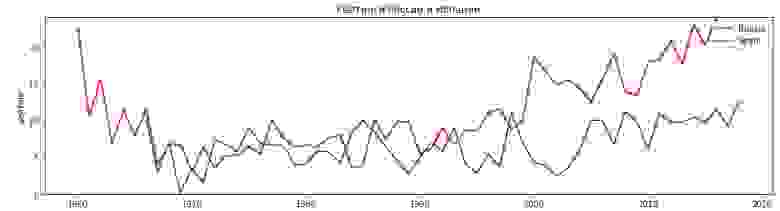
Но и тут не обошлось без бочки дегтя — UEFA ведет рейтинг только европейских команд (стоит иногда задумываться, что скрывается под распространенными аббревиатурами, перед их использованием). К счастью, плей-офф сложился практически «европейский».
Осталось немного поудобнее разделить результаты на отдельные игры и добавить в таблицу рейтинги.
Самая интересная часть – обучение модели. Гугл сразу подсказал самый простой и быстрый вариант – это классификатор MLPClassifier из библиотеки Python — Sklearn. Попробуем обучить модель на примере Швеции.
Accuracy: 0.62
Не сильно точнее бросания монеты, но, вероятно, уже лучше моих потенциальных «экспертных» прогнозов. Тут было бы разумно попробовать обогатить данные, поиграть гиперпараметрами, но я решил пойти другим путем и попробовать библиотеку градиентного бустинга Catboost от Yandex. С одной стороны, это более патриотично, с другой — они обещают качественную работу с категориальными признаками, что подтверждается многочисленными сравнениями.
Взял настройки из примера:
Accuracy: 0.73
Уже лучше, пробуем в деле.

Результаты прогноза для финала «Команда Crotia проиграет команде France с вероятностью 93,7%»
Хоть этот раз я не победил в конкурсе «НОРБИТ», но очень надеюсь, что эта статья для кого-нибудь снизит уровень магии в практическом использовании машинного обучения, а может, даже замотивирует на собственные эксперименты.
Во время Чемпионата мира по футболу у нас в компании "НОРБИТ" проходил конкурс на лучший прогноз матчей по футболу. Я слишком поверхностно разбираюсь в футболе, чтобы на что-то претендовать, но желание принять участие в конкурсе все-таки победило мою лень. Под катом – история о том, как благодаря машинному обучению мне удалось добиться неплохих результатов среди знатоков футбольных команд. Правда, сорвать куш мне не удалось, зато открыл для себя новый увлекательный мир Data Science.

Начал я с гипотезы, что помимо индивидуального мастерства игроков национальных сборных есть еще неизмеримые, но важные факторы — командный дух + сыгранность (например, команда в игре с более сильным соперником, но в зачетном матче и на своем поле чаще одерживает победу). Задача не такая уж и простая для человека, но вполне понятная для машинного обучения.
Когда-то у меня уже был небольшой опыт работы с ML (с библиотекой BrainJS), но в этот раз решил проверить утверждение, что Python гораздо лучше подходит для таких задач.
Знакомство с Python я начал с отличного курса на Coursera, а основы машинного обучения почерпнул из серии статей от Open Data Science на Хабре.
Довольно быстро нашелся отличный Dataset с историей всех игр международных сборных с начала XX века. После импорта в Pandas dataframe:

Всего в базе содержится информация о 39 тысячах игр международных сборных.
Pandas позволяет очень удобно анализировать данные, например, самый результативный матч был между Австралией и Американским Самоа в 2001 году, который закончился со счетом 31:0.

Теперь нужно добавить объективную оценку уровню команды в год проведения матча. Такими оценками занимается FIFA.

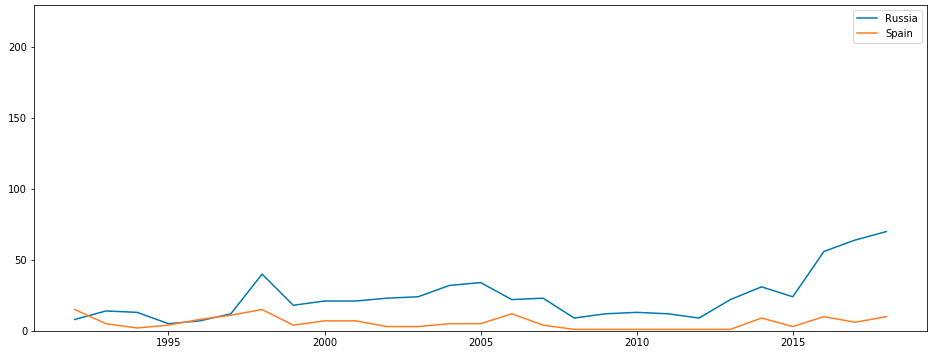
Но, к большому сожалению, рейтинг FIFA ведется только с 1992 года. И, судя по графику рейтинги команд сильно подвержены изменениям, и очень бы не хотелось усреднять позиции команд в мировом рейтинге до этого года.
UEFA ведет свою статистику с более древних времен, но готовый dataset я так и не смог найти, поэтому на помощь пришел этот сайт. Под Node.js для таких задач есть мощный и удобный Сheerio, но под Python все оказалось не менее просто (да простит меня администратор этого сайта).
Веб-скрапинг рейтинга
from requests import get
from requests.exceptions import RequestException
from contextlib import closing
from bs4 import BeautifulSoup
def query_url(url):
try:
with closing(get(url, stream=True)) as resp:
if is_good_response(resp):
return resp.content
else:
return None
except RequestException as e:
log_error('Error during requests to {0} : {1}'.format(url, str(e)))
return None
def is_good_response(resp):
content_type = resp.headers['Content-Type'].lower()
return (resp.status_code == 200
and content_type is not None
and content_type.find('html') > -1)
def log_error(e):
print(e)
def parse_ranks(raw_html, year):
html = BeautifulSoup(raw_html, 'html.parser')
ranks = []
for tr in html.select('tr'):
tds = tr.select("td")
if len(tds) == 10:
rank = (year, tds[2].text, tds[7].text)
ranks.append(rank)
return ranks
def get_url(year):
if year in range(1960, 1999): method = 1
if year in range(1999, 2004): method = 2
if year in range(2004, 2009): method = 3
if year in range(2009, 2018): method = 4
if year in range(2018, 2019): method = 5
return f"https://kassiesa.home.xs4all.nl/bert/uefa/data/method{method}/crank{year}.html"
ranks = []
for year in range(1960, 2019):
url = get_url(year)
print(url)
raw_html = query_url(url)
rank = parse_ranks(raw_html, year)
ranks += rank
with open('team_ranks.csv', 'w') as f:
writer = csv.writer(f , lineterminator='\n')
writer.writerow(['year', 'country', 'rank'])
for rank in ranks:
writer.writerow(rank)
Колебания рейтинга после добавления рейтинга UEFA (и небольшой правки названий стран по итогам геополитических рокировок):

Но и тут не обошлось без бочки дегтя — UEFA ведет рейтинг только европейских команд (стоит иногда задумываться, что скрывается под распространенными аббревиатурами, перед их использованием). К счастью, плей-офф сложился практически «европейский».
Осталось немного поудобнее разделить результаты на отдельные игры и добавить в таблицу рейтинги.
Самая интересная часть – обучение модели. Гугл сразу подсказал самый простой и быстрый вариант – это классификатор MLPClassifier из библиотеки Python — Sklearn. Попробуем обучить модель на примере Швеции.
from sklearn.neural_network import MLPClassifier
games = pd.read_csv('games.csv')
# Только игры Швеции
SwedenGames = games[(games.teamTitle == 'Sweden')]
# Результаты игр
y = SwedenGames['score']
y = y.astype('int')
# Таблица признаков
X = SwedenGames.drop(['score', 'teamTitle', 'againstTitle'], axis=1)
# Разделение выборки на обучающую и тестовую
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
mlp = MLPClassifier()
mlp.fit(X_train, y_train);
predictions = mlp.predict(X_test)
print('Accuracy: {:.2}'.format(
accuracy_score(y_test, mlp.predict(X_test))
))
Accuracy: 0.62
Не сильно точнее бросания монеты, но, вероятно, уже лучше моих потенциальных «экспертных» прогнозов. Тут было бы разумно попробовать обогатить данные, поиграть гиперпараметрами, но я решил пойти другим путем и попробовать библиотеку градиентного бустинга Catboost от Yandex. С одной стороны, это более патриотично, с другой — они обещают качественную работу с категориальными признаками, что подтверждается многочисленными сравнениями.
Взял настройки из примера:
# Индексы столбцов категориальных признаков
categorical_features_indices = [1, 2, 4]
train_pool = Pool(X_train, y_train, cat_features=categorical_features_indices)
validate_pool = Pool(X_test, y_test, cat_features=categorical_features_indices)
# Бустинг довольно чувствительный к настройке гиперпараметров, для автоматизации перебора я использовал GridSearchCV. Полученные значения
best_params = {
'iterations': 500,
'depth': 10,
'learning_rate': 0.1,
'l2_leaf_reg': 1,
'eval_metric': 'Accuracy',
'random_seed': 42,
'logging_level': 'Silent',
'use_best_model': True
}
cb_model = CatBoostClassifier(**best_params)
cb_model.fit(train_pool, eval_set=validate_pool)
print('Accuracy: {:.2}'.format(
accuracy_score(y_test, cb_model.predict(X_test))
))
Accuracy: 0.73
Уже лучше, пробуем в деле.
def get_prediction(country, against):
y = SwdenGames['score']
y = y.astype('int')
X = SwdenGames.drop(['score', 'againstTitle'], axis=1)
train_pool = Pool(X, y, cat_features=[1, 2, 4])
query = [ get_team_rank(country, 2018),
0,
1 if country == 'Russia' else 0,
get_team_rank(against, 2018),
against]
return cb_model.predict_proba([query])[0]
team_1 = 'Belgium'
team_2 = 'France'
result = get_prediction(team_1, team_2)
if result[0] > result[1]:
print(f"Команда {team_1} выиграет у команды {team_2} с вероятностью {result[0]*100:.1f}%")
else:
print(f"Команда {team_1} проиграет команде {team_2} с вероятностью {result[1]*100:.1f}%")

Результаты прогноза для финала «Команда Crotia проиграет команде France с вероятностью 93,7%»
Хоть этот раз я не победил в конкурсе «НОРБИТ», но очень надеюсь, что эта статья для кого-нибудь снизит уровень магии в практическом использовании машинного обучения, а может, даже замотивирует на собственные эксперименты.
