Комментарии 7
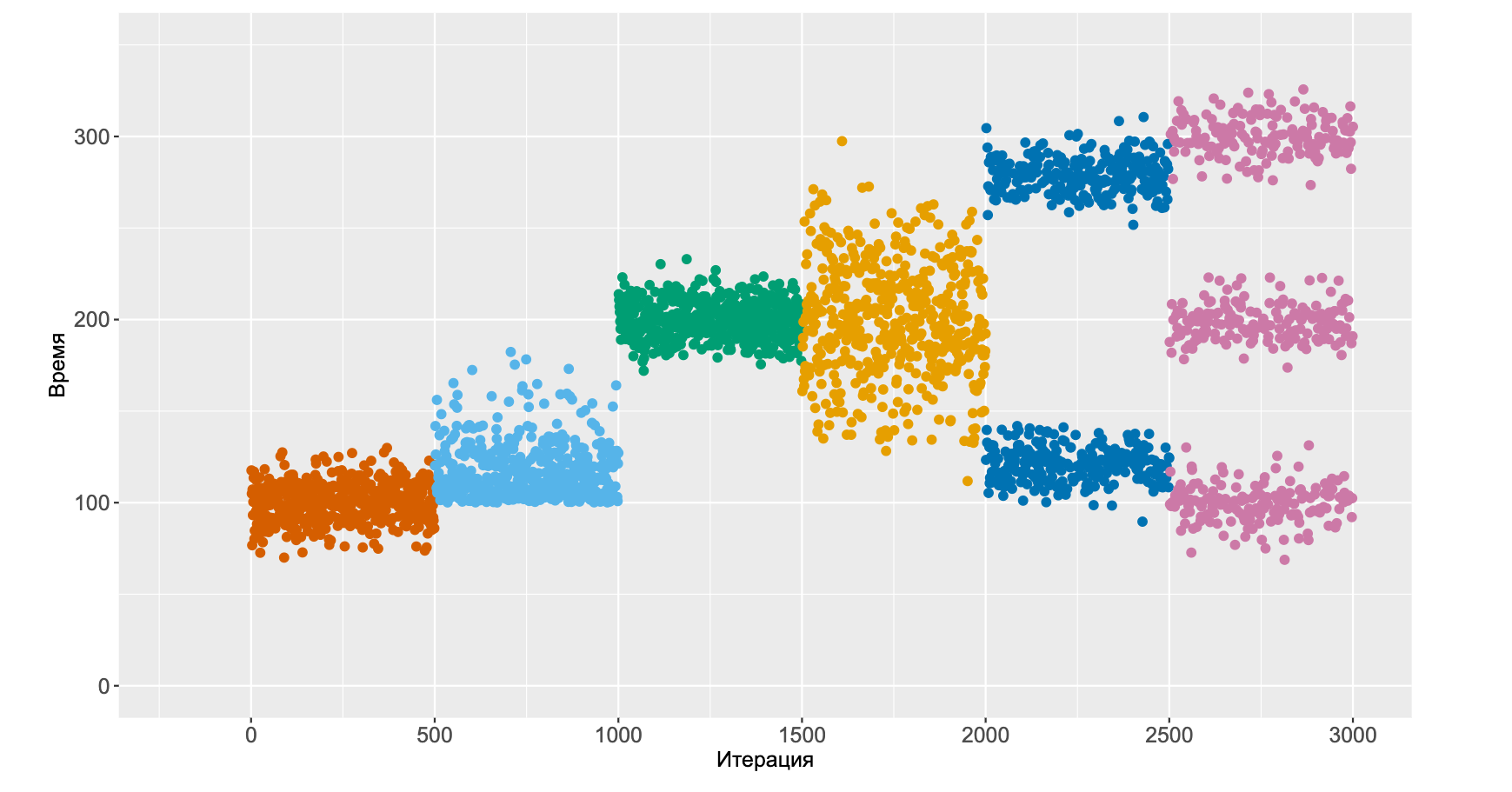
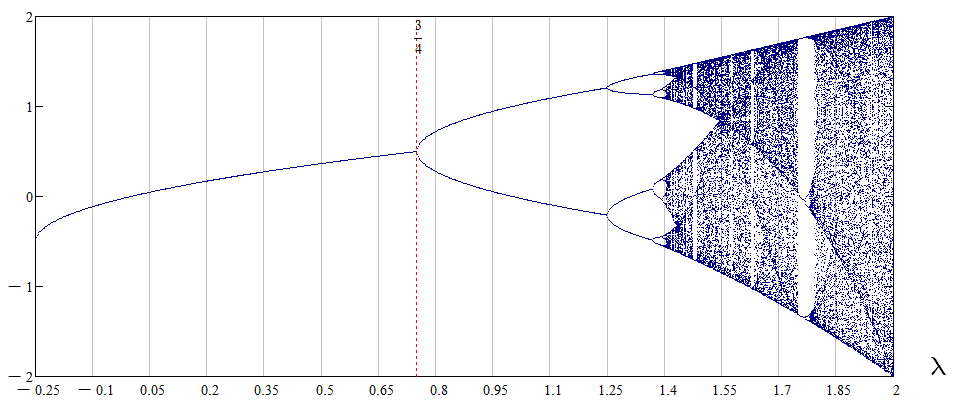
А потом наше распределение внезапно становится бимодальным. И тут уже сложно сказать деградация ли это или ускорение, но что-то важное определённо поменялось. А потом распределение и вовсе становится тримодальным.Картинка напомнила бифуркационную диаграмму обычно появляющуюся при анализе динамических нелинейных систем. Интересно, при увеличении числа операции система точно-также демонстрирует хаотическое поведение?
Типичная бифуркационная диаграмма
В тексте часто встречается опечатка «рейс» в значении «кейс»
Насколько я понял из статьи, в JB непрерывно тестируют производительность. Но в то же время за один запуск нельзя понять приносит ли патч деградацию или нет, потому что для анализа нужны метрики за какой-то период времени. Вопрос к DreamWalker: как вы управляете коммитами, которые принесли регрессию: откат изменений (иногда это сложно, потому что сверху уже есть другие изменения), оперативный фикс регрессии или что-то ещё?
В целом мы пытаемся добиться ситуации, в которой значимые деградации просто не могут вмёрджиться. Для этого у нас есть performance-тесты, которые динамически подбирают оптимальное количество итераций (в докладе я как раз про это рассказываю). Для пущей уверенности тесты перезапускаются на нескольких машинах, чтобы гарантированно избежать ложноположительных результатов.
Но вы правы в том, что такие тесты не всегда спасают от регрессий. Пожалуй, самая главная проблема в том, что таких тестов не очень много (т.к. они очень долго идут), покрыты только наиболее критичные сценарии. Поэтому есть система мониторинга, которая шлёт в Slack разнообразные нотификации об уже замёрдженных деградациях. Какого-то красивого универсального подхода к таким проблемам нет, мы просто разбираем все проблемы вручную и пытаемся найти наиболее правильное решение. Обычно, оно попадает в одну из следующих категорий:
- Преднамеренная деградация (например, security fix или новая фича, за которую мы все вместе согласились заплатить производительностью): ничего не делаем
- Непреднамеренная незначительная деградация: чаще всего нет смысла тратить время на расследование, ничего не делаем
- Непреднамеренная значительная деградация:
- Если легко откатить — вмёрдживаем revert commit, после чего спокойно разбираемся в проблеме
- Если сложно откатить — подключаем всех релевантных разработчиков и пытаемся максимально оперативно пофиксить проблему
По сути, починка вмёрдженной performance-регрессии не особо отличается от починки вмёрдженной обычной регрессии по функциональности: либо откатываем, либо фиксим прямо в master-ветке. Насколько мне известно, принципиально других подходов в индустрии пока не появилось. Единственное отличие performance-регрессий в том, что от них чаще можно отмахнуться и сказать “ну и ладно, не так уж и медленно оно работает, у нас и поважнее задачи есть”, но нужно глубокое понимание продукта для того, чтобы определить ситуации, в которых так сказать действительно можно.
Поговорим про перформанс-анализ