
Годами эксперты в С++ рассуждают о семантике значений, иммутабельности и разделении ресурсов за счет коммуникации. О новом мире без мьютексов и гонок, без паттернов Command и Observer. На деле все не так просто. Главная проблема по-прежнему в наших структурах данных.

Иммутабельные структуры данных не меняют своих значений. Чтобы что-то с ними сделать, нужно создавать новые значения. Старые же значения остаются на прежнем месте, поэтому их можно без проблем и блокировок читать из разных потоков. В итоге ресурсы можно совместно использовать более рационально и упорядоченно, ведь старые и новые значения могут использовать общие данные. Благодаря этому их куда быстрей сравнить между собой и компактно хранить историю операций с возможностью отмены. Все это отлично ложится на многопоточные и интерактивные системы: такие структуры данных упрощают архитектуру десктопных приложений и позволяют сервисам лучше масштабироваться. Иммутабельные структуры — секрет успеха Clojure и Scala, и даже сообщество JavaScript теперь пользуется их преимуществами, ведь у них есть библиотека Immutable.js, написанная в недрах компании Facebook.
Под катом — видео и перевод доклада Juan Puente с конференции C++ Russia 2019 Moscow. Хуан рассказывает про Immer — библиотеку иммутабельных структур для C++. В посте:
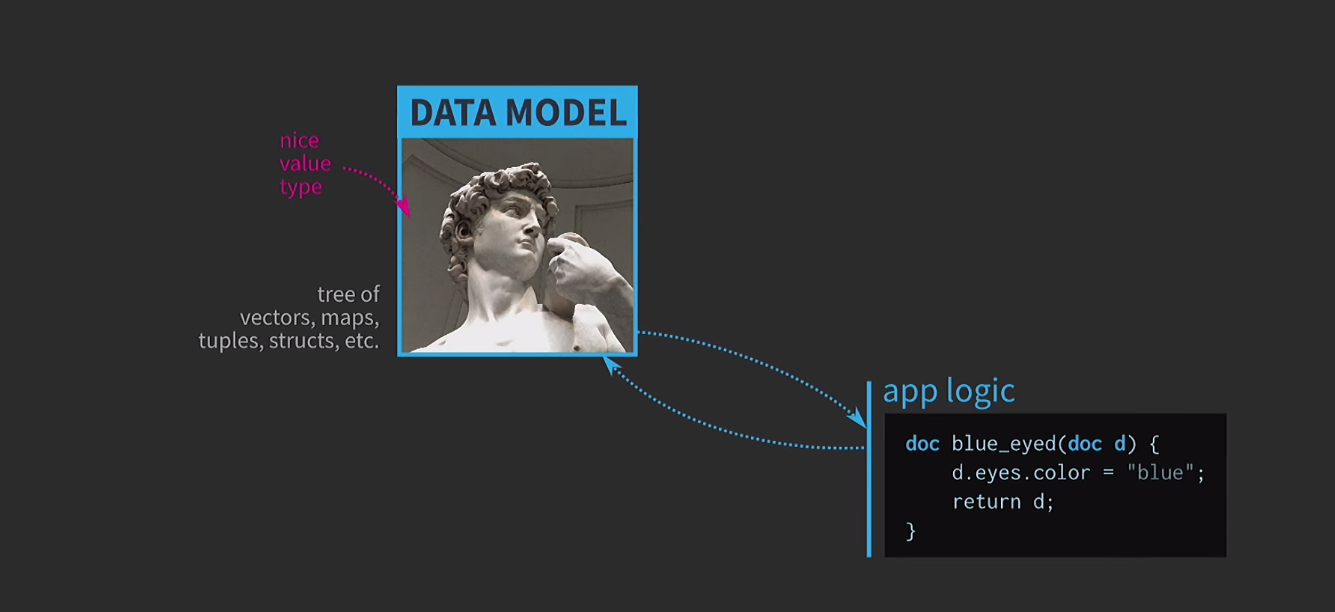
Чтобы понять значимость иммутабельных структур данных, обсудим семантику значений. Это очень важная особенность С++, я считаю её одним из главных достоинств этого языка. При всем при этом использовать семантику значений так, как нам хотелось бы, очень сложно. Я считаю, что в этом трагедия архитектуры, основанной на значениях, и дорога к этой трагедии вымощена благими намерениями. Предположим, нам необходимо написать интерактивное ПО на основе модели данных с репрезентацией редактируемого пользователем документа. При архитектуре, основанной на значениях, в основе этой модели используются простые и удобные типы значений, которые уже есть в языке:
Такую функцию очень легко анализировать и тестировать.
Раз мы работаем со значениями, попробуем реализовать отмену действия. Это бывает непросто, но при нашем подходе это тривиальная задача: у нас есть

Предположим, у нас также есть UI, и, чтобы обеспечить его отзывчивость, отображение UI необходимо сделать в отдельном потоке. Документ пересылается в другой поток сообщением, и взаимодействие происходит тоже на основе сообщений, а не через предоставление общего доступа к состоянию с использованием

Сохранение документа на диск зачастую выполняется очень медленно, в особенности если документ большой. Поэтому при помощи

Далее, предположим, у нас есть ещё и поток управления звуком. Как я уже говорил, я много работал с музыкальным ПО, и звук является еще одним представлением нашего документа, он обязательно должен быть в отдельном потоке. Поэтому для этого потока также необходима копия документа.
В итоге у нас получилась очень красивая, но не слишком реалистичная схема.
В ней постоянно приходится копировать документы, история действий для отмены занимает гигабайты, и для каждой отрисовки UI нужно сделать глубокую копию документа. В общем, все взаимодействия оказываются слишком затратными.

Что в этой ситуации делает разработчик на С++? Вместо того, чтобы принимать документ по значению, логика приложения теперь принимает ссылку на документ и обновляет её при необходимости. Возвращать в этом случае ничего не нужно. Но теперь мы имеем дело не со значениями, а с объектами и местоположениями. Это создает новые проблемы: если есть ссылка на состояние с общим доступом, для него нужен
Все эти элементы должны получать обновления при изменении документа, поэтому необходим некоторый механизм очереди для сигналов об изменениях. Далее, история документа уже не является набором состояний, она будет реализацией паттерна Команда. Операцию необходимо реализовать дважды, в одном направлении и в другом, и убедиться в том, чтобы всё было симметрично. Выполнять сохранение в отдельном потоке уже слишком сложно, так что от этого придется отказаться.

Пользователи уже привыкли к картинке песочных часов, так что ничего страшного, если они немного подождут. Страшно другое — нашим кодом теперь правит макаронный монстр.
В какой момент у нас всё пошло под откос? Мы отлично спроектировали наш код, а затем из-за копирования нам пришлось идти на компромиссы. Но в С++ копирование обязательно для передачи по значению лишь для мутабельных данных. Если же объект иммутабельный, то оператор присваивания можно реализовать так, чтобы он копировал только указатель на внутреннее представление и ничего больше.
Рассмотрим структуру данных, которая могла бы нам помочь. У вектора ниже все методы отмечены как
Изменения теперь можно напрямую проверять, они больше не являются скрытыми свойствами структуры данных. Эта возможность особенно ценна в интерактивных системах, где нам постоянно приходится изменять данные.
Другое важное свойство — структурный общий доступ (structural sharing). Теперь у нас не происходит копирования всех данных для каждой новой версии структуры данных. Даже при
Поскольку такой вектор, как мне кажется, крайне полезен, я реализовал его в отдельной библиотеке: это immer — библиотека иммутабельных структур, проект с открытым кодом.
При написании его мне хотелось, чтобы его использование было привычным для разработчиков на С++. Есть много библиотек, которые реализуют концепции функционального программирования в С++, но при этом создается впечатление, что разработчики пишут для Haskell, а не для С++. Это создает неудобства. Кроме того, я добивался хорошей производительности. Люди используют С++, когда наличные ресурсы ограничены. Наконец, мне хотелось, чтобы библиотека была настраиваемой. Это требование связано с требованием производительности.
Во второй части доклада мы рассмотрим, как устроен этот иммутабельный вектор. Проще всего понять принципы такой структуры данных, начав с обычного списка. Если вы немного знакомы с функциональным программированием (на примере Lisp или Haskell), вы знаете, что списки — наиболее часто встречающиеся иммутабельные структуры данных.

Для начала предположим, что у нас есть список с одним узлом,
Также можем создать форк реальности, то есть создать новый список, у которого то же окончание, но отличающееся начало.
Такие структуры данных изучаются уже давно: Крис Окасаки (Chris Okasaki) написал основополагающую работу Purely Functional Data Structures. Кроме того, весьма интересна предложенная Ральфом Хинце (Ralf Hinze) и Россом Патерсоном (Ross Paterson) структура данных Finger Tree. Но для С++ такие структуры данных подходят плохо. Они используют небольшие узлы, а мы знаем, что в С++ небольшие узлы означают отсутствие эффективности кэширования.
Кроме того, они зачастую полагаются на свойства, которых у С++ нет, например, отложенность (laziness). Поэтому для нас значительно полезнее работа Фила Бэгуэлла (Phil Bagwell) по иммутабельным структурам данных — ссылка, написанная в начале 2000-х, а также труд Рича Хики (Rich Hickey) — ссылка, автора языка Clojure. Рич Хики создал список, который на самом деле является не списком, а основан на современных структурах данных: векторах и хэш-мэпах. Эти структуры данных обладают эффективностью кэширования и прекрасно взаимодействуют с современными процессорами, для которых нежелательно работать с небольшими узлами. Такие структуры вполне можно использовать в С++.
Как построить иммутабельный вектор? В основе любой структуры, хотя бы отдаленно напоминающей вектор, должен быть массив. Но массив не обладает структурным общим доступом. Чтобы изменить любой элемент массива, при этом не теряя свойства персистентности, необходимо скопировать весь массив. Чтобы не делать этого, массив можно разбить на отдельные куски.
Теперь при обновлении элемента вектора нам необходимо скопировать только один кусок, а не весь вектор. Но сами по себе такие куски не являются структурой данных, они должны быть так или иначе объединены. Поместим их в другой массив. Вновь возникает та проблема, что массив может оказаться очень большим, и тогда копирование его опять займёт слишком много времени.
Поделим и этот массив на куски, поместим их вновь в отдельный массив, и повторим эту процедуру до тех пор, пока не останется один корневой массив. Получившаяся структура называется дерево остатков. Это дерево описывается константой M = 2B, то есть показатель ветвления дерева (branching factor). Этот показатель ветвления должен быть степенью двойки, и мы очень скоро узнаем, почему. В примере на слайде использованы блоки из четырех символов, но на практике используются блоки размером в 32 символа. Существуют эксперименты, при помощи которых можно найти оптимальный размер блока для определенной архитектуры. Это позволяет добиться наилучшего соотношения структурного общего доступа и времени доступа: чем дерево ниже, тем меньше время доступа.
Читая это, разработчики, пишущие на С++, наверное, думают: но ведь любые структуры на основе дерева очень медленные! Деревья растут при увеличении числа элементов в них, и из-за этого ухудшается время доступа. Именно поэтому программисты предпочитают
Давайте посмотрим, как выполняется доступ к элементу дерева. Предположим, необходимо обратиться к элементу 17. Мы берём бинарное представление индекса и разбиваем его на группы размером с фактор ветвления.
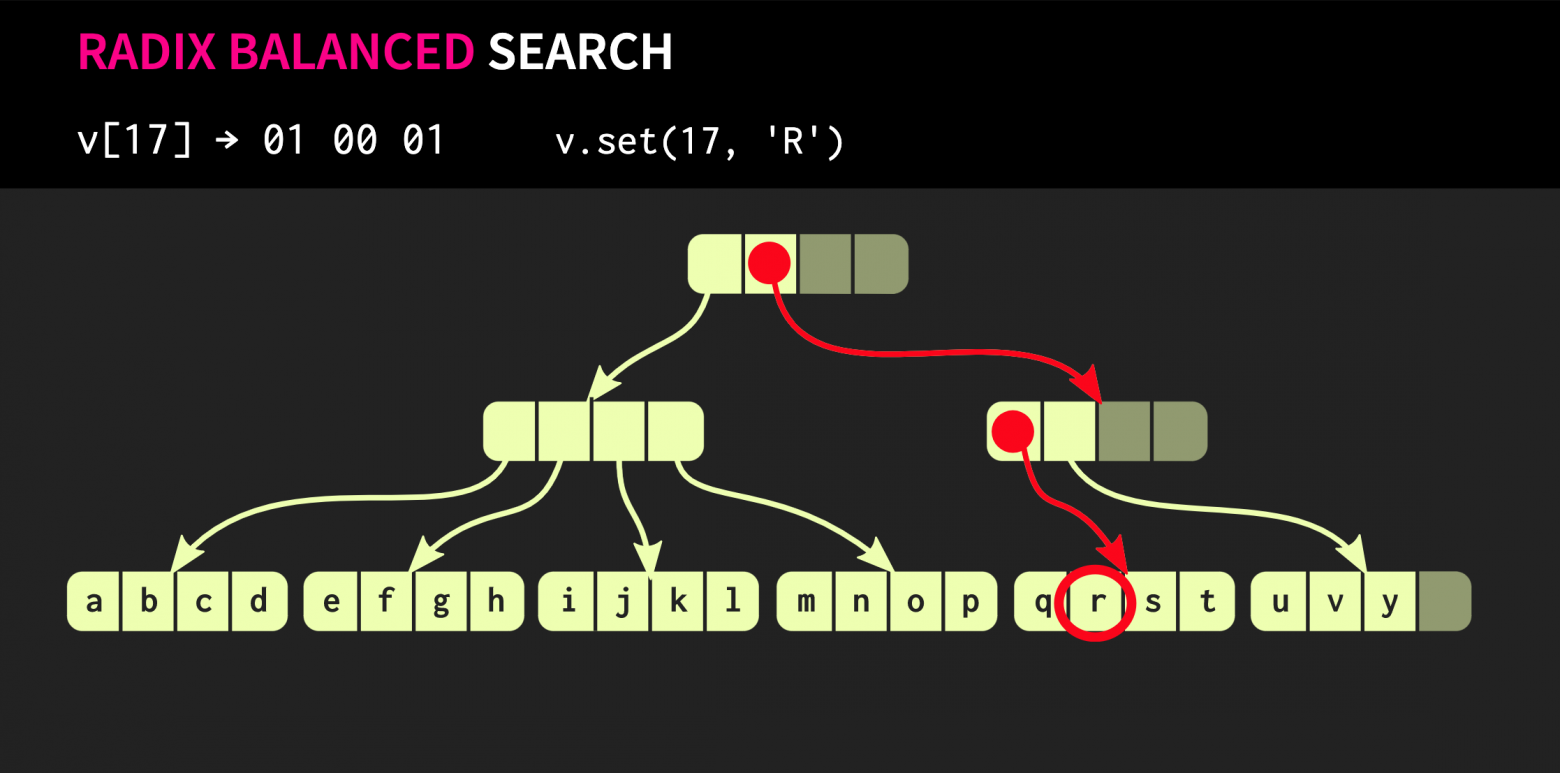
В каждой группе мы используем соответствующее бинарное значение и таким образом спускаемся вниз по дереву.
Далее, предположим, нам необходимо сделать изменение в этой структуре данных, то есть выполнить метод

Для этого вначале необходимо скопировать блок, в котором находится элемент, а затем скопировать каждый внутренний узел на пути к элементу. С одной стороны, копировать приходится довольно много данных, но при этом значительная часть этих данных общая, это компенсирует их объем.
Кстати говоря, существует значительно более старая структура данных, которая очень похожа на ту, которую я описал. Это страницы памяти (memory pages) с деревом таблицы страниц. Управление ей тоже осуществляется при помощи вызова
Попытаемся улучшить нашу структуру данных. Предположим, нам необходимо соединить два вектора. Пока что описанная структура данных обладает теми же ограничениями, что и
Попытаемся добиться лучшего результата. Существует изменённый вариант нашей структуры данных, который называется relaxed radix balanced tree. В этой структуре узлы, которые не находятся на самом левом пути, могут иметь пустые ячейки. Поэтому в таких неполных (или расслабленных) узлах необходимо подсчитывать размер поддерева. Теперь можно выполнить сложную, но логарифмическую операцию объединения. Эта операция постоянной временной сложности — О(log(32)). Поскольку деревья неглубокие, время доступа является константой, хоть и относительно большой. Благодаря тому, что у нас есть такая операция объединения, relaxed вариант этой структуры данных называют сливающимся (confluent): помимо того, что она персистентная, и можно сделать её форк, две таких структуры можно объединить в одну.
В том примере, с которым мы до сих пор работали, структура данных очень аккуратная, но на практике реализации в Clojure и других функциональных языках выглядят иначе. В них создаются контейнеры для каждого значения, то есть каждый элемент в векторе находится в отдельной ячейке, а листовые узлы содержат указатели на эти элементы. Но такой подход крайне неэффективный, в С++ обычно не помещают каждое значение в контейнер. Поэтому будет лучше, если эти элементы будут находиться в узлах напрямую. Тогда возникает другая проблема: у разных элементов разные размеры. Если элемент по размеру совпадает с указателем, наша структура будет выглядеть так, как показано ниже:
Но если элементы обладают большим размером, то структура данных теряет измеренные нами свойства (время доступа О(log(32)()), потому что копирование одного из листов теперь занимает больше времени. Поэтому я изменил эту структуру данных так, чтобы при увеличении размера содержащихся в ней элементов уменьшалось количество этих элементов в листовых узлах. Напротив, если элементы маленькие, то их теперь может поместиться больше. Новый вариант дерева называется embedding radix balanced tree. Оно описывается уже не одной константой, а двумя: одна из них описывает внутренние узлы, а вторая — листовые. Реализация дерева в С++ может рассчитать оптимальный размер листового элемента в зависимости от размеров указателей и самих элементов.
Наше дерево работает уже весьма неплохо, но его ещё можно улучшить. Взглянем на функцию, похожую на функцию
Она принимает на вход
Можно попробовать другую реализацию этой функции, в которой мы отказываемся от персистентности внутри функции. Можно использовать
Такая реализация более эффективная, и она позволяет повторно использовать новые элементы на самом правом пути. В конце функции выполняется вызов
Рассмотрим другой пример.
Функция не принимает и возвращает
Далее, чтобы помочь компилятору мы можем выполнить
До сих пор мы говорили о векторах, а помимо них есть ещё и хэш-мэпы. Им посвящён очень полезный доклад Фила Нэша (Phil Nash): The holy grail. A hash array mapped trie for C++. Там описываются хэш-таблицы, реализованные на основе тех же принципов, о которых я сейчас говорил.
Уверен, у многих из вас есть сомнения относительно производительности подобных структур. Быстро ли они работают на практике? Я провел множество тестов, и вкратце мой ответ: да. Если вы хотите подробнее познакомиться с результатами тестирования, они опубликованы в моей статье для International Conference of Functional Programming 2017. Сейчас, я думаю, лучше обсудить не абсолютные значения, а то влияние, которое эта структура данных оказывает на систему в целом. Конечно же, update нашего вектора выполняется медленнее, поскольку необходимо скопировать несколько блоков данных и выделить память для других данных. А вот обход нашего вектора выполняется почти с такой же скоростью, как и обычного. Мне было очень важно этого добиться, поскольку чтение данных выполняется значительно чаще, чем их изменение.
Кроме того, за счет более медленного update нет необходимости что-либо копировать, копируется только структура данных. Поэтому время, которое тратится на обновление вектора как бы амортизируется для всех копий, выполняемых в системе. Поэтому, если применять эту структуру данных в архитектуре наподобие той, которую я описал в начале доклада, производительность существенно вырастает.
Не буду голословным и продемонстрирую мою структуру данных на примере. Я написал небольшой текстовый редактор. Это интерактивный инструмент под названием ewig, в нём документы представлены иммутабельными векторами. У меня на диске сохранена копия всей википедии на эсперанто, она весит 1 гигабайт (вначале я хотел скачать английскую версию, но она чересчур уж большая). Каким бы текстовым редактором вы ни пользовались, я уверен, что этот файл ему не понравится. А при загрузке этого файла в ewig его сразу же можно редактировать, потому что загрузка идет асинхронно. Навигация файла работает, ничего не висит, нет
Прежде, чем рассматривать самые важные свойства этого инструмента, обратим внимание на забавную деталь.
В начале строки, выделенной белым в нижней части изображения, вы видите два дефиса. Этот UI, скорее всего, знаком пользователям emacs, дефисы там означают, что документ никак не был изменён. Если же внести какие-либо изменения, то вместо дефисов отображаются звездочки. Но, в отличие от других редакторов, если в ewig затем удалить эти изменения (не отменить, а именно удалить), то вместо звёздочек вновь отобразятся дефисы, поскольку в ewig сохраняются все предшествующие версии текста. Благодаря этому не нужен специальный флаг, показывающий, изменён ли документ: наличие изменений определяется сравнением с исходным документом.
Рассмотрим другое интересное свойство инструмента: скопируем текст целиком и вставим его пару раз в середину имеющегося текста. Как видим, это происходит моментально. Соединение векторов здесь является логарифмической операцией, и логарифм нескольких миллионов — не такая уж и длительная операция. Если же попытаться сохранить этот огромный документ на жёсткий диск, это займет значительно больше времени, поскольку текст уже не представлен как вектор, полученный от предыдущей версии этого вектора. При сохранении на диск происходит сериализация, поэтому теряется персистентность.
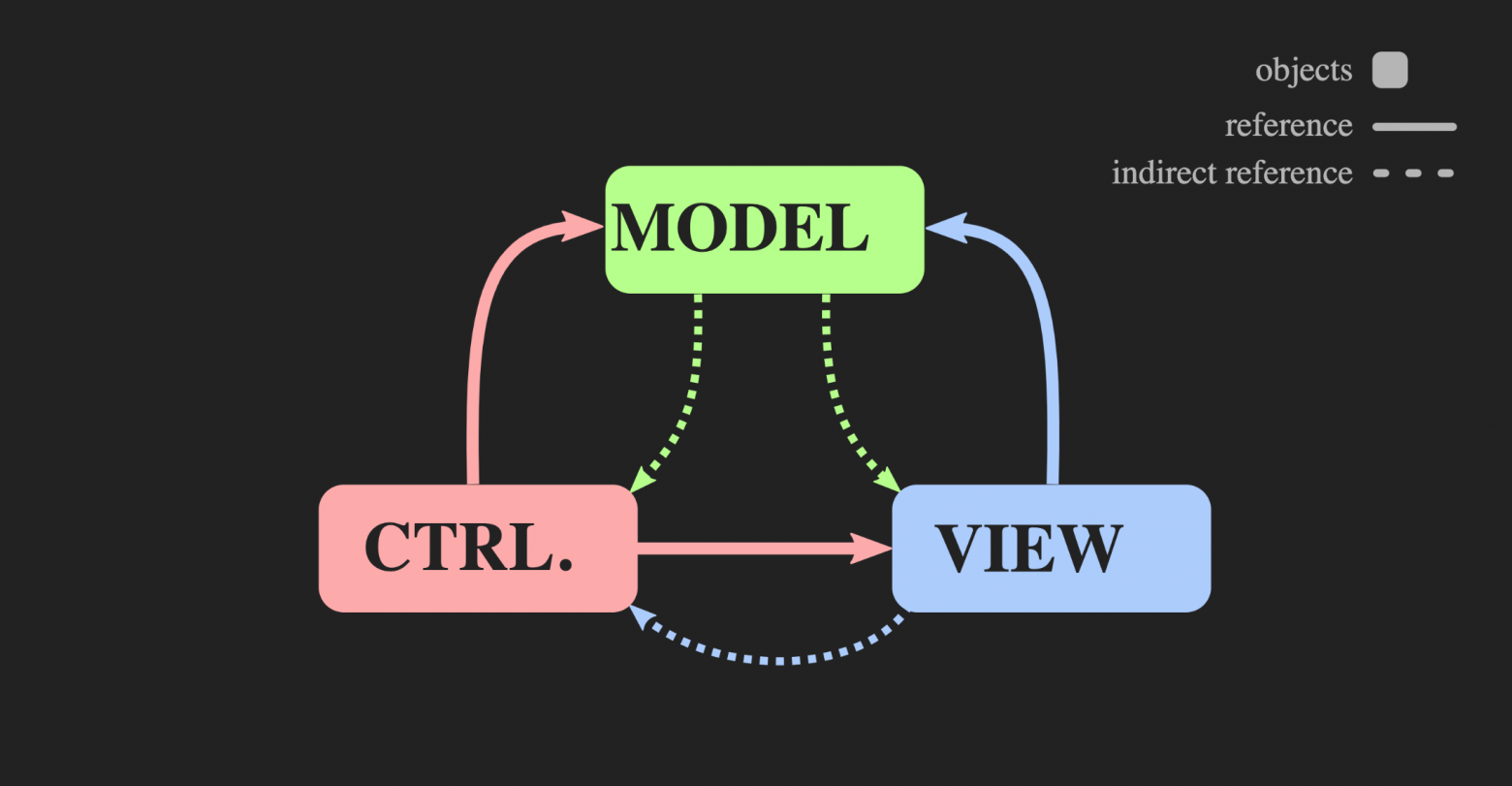
Начнём с того, как к этой архитектуре нельзя вернуться: с помощью обычных Controller, Model и View в стиле Java, которые чаще всего и используются для интерактивных приложений в С++. Ничего плохого в них нет, но для нашей проблемы они не подходят. С одной стороны, паттерн Model-View-Controller позволяет добиться разделения задач, но с другой, каждый из этих элементов является объектом, как с объектно-ориентированной точки зрения, так и с точки зрения С++, то есть это участки памяти с мутабельным состоянием. View знает о Model; что значительно хуже — Model косвенно знает о View, потому что почти наверняка существует некоторый callback, через который View получает оповещение при изменении Model. Даже при лучшей реализации объектно-ориентированных принципов мы получаем множество взаимных зависимостей.
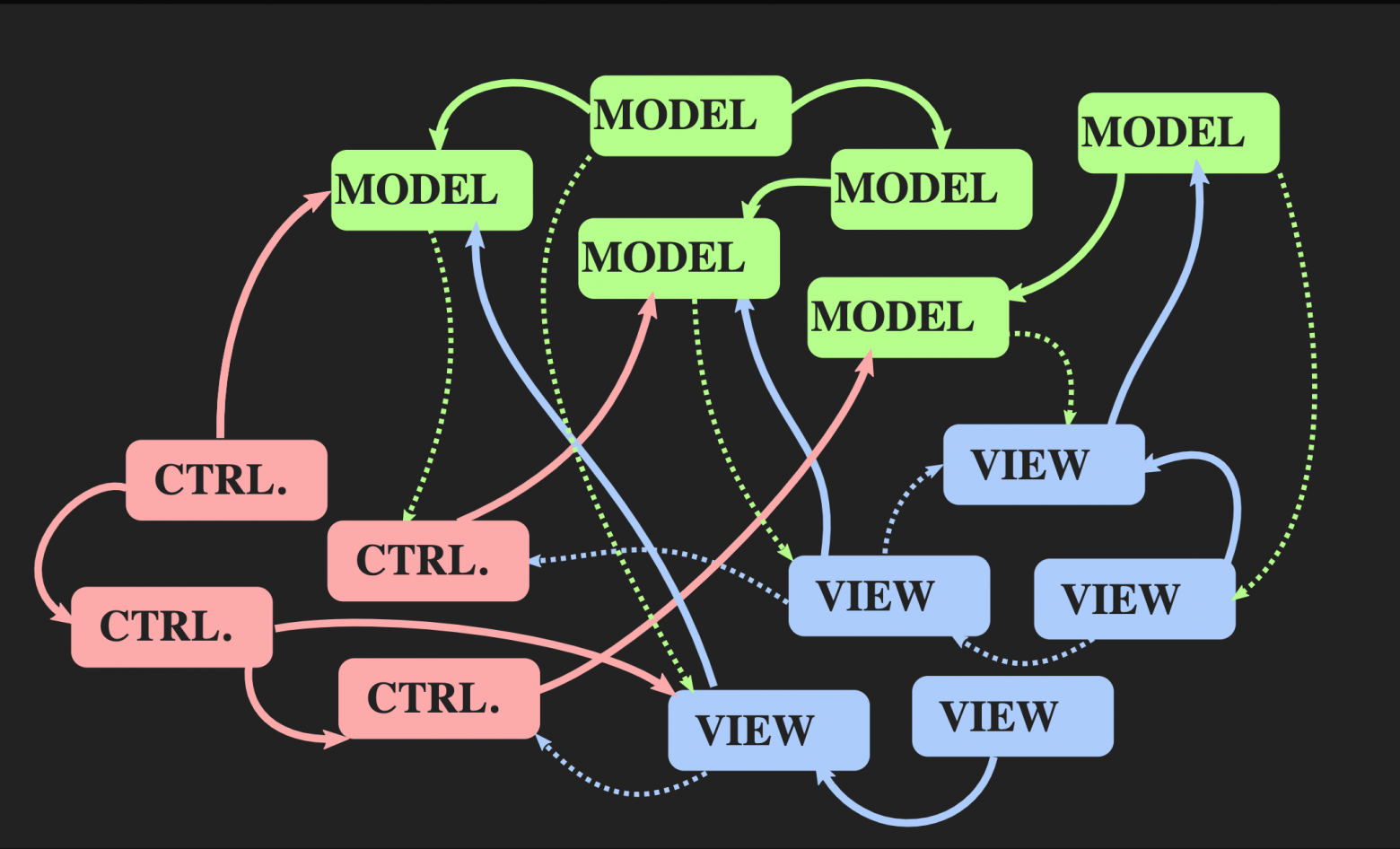
По мере роста приложения и добавления новых Model, Controller и View возникает ситуация, когда для изменения какого-либо сегмента программы необходимо знать о всех связанных с ним частях, обо всех View, которые получают оповещение через
Возможна ли другая архитектура? Есть альтернативный подход к паттерну Model-View-Controller, который называется «Архитектура с однонаправленным потоком данных». Это понятие придумал не я, оно используется довольно часто в веб-разработке. В Facebook это называется архитектура Flux, но в С++ пока что она не применяется.
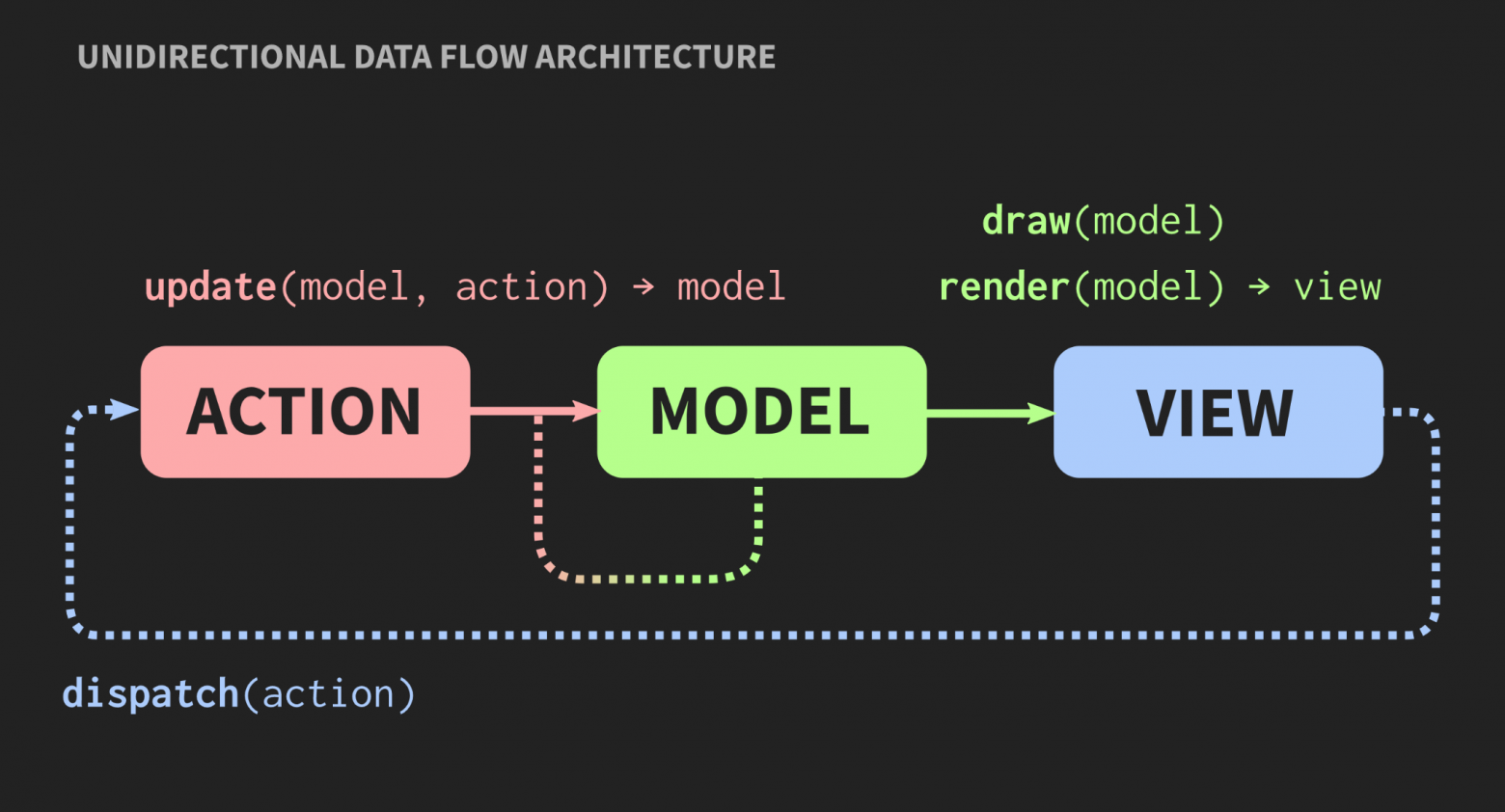
Элементы такой архитектуры нам уже знакомы: Action, Model и View, но значение блоков и стрелок другое. Блоки являются значениями, а не объектами и не участками с мутабельным состоянием. Это касается даже View. Далее, стрелки не являются ссылками, поскольку без объектов не может быть ссылок. Здесь стрелки — это функции. Между Action и Model существует функция update, которая принимает текущую Model, т. е. текущее состояние мира, и Action, которая является представлением некоторого события, например, щелчка мышкой, или события другого уровня абстракции, например, вставки элемента или символа в документ. Функция update обновляет документ и возвращает новое состояние мира. Model соединяется с View функцией render, который принимает Model и возвращает представление. Для этого требуется фреймворк, в котором можно представлять View в качестве значений.
При веб-разработке это делает React, но в С++ пока ничего подобного нет, хотя кто знает, если найдутся желающие заплатить мне, чтобы я написал нечто подобное, то может в скором времени и появится. Пока же можно пользоваться Immediate mode API, в которых функция draw позволяет создавать значение в качестве побочного эффекта.
Наконец, у View должен быть механизм, позволяющий пользователю или другим источникам событий отправлять Action. Существует простой способ это реализовать, он представлен ниже:
За исключением асинхронного сохранения и загрузки это код, который используется в только что представленном редакторе. Здесь есть объект
Разработчики Clojure называют это одноатомной архитектурой (single-atom architecture): на всё приложение есть одна единственная точка, через которую выполняются все изменения. Логика приложения никак не участвует в обновлении этой точки, это делает специально для этого предназначенный цикл. Благодаря этому логика приложения целиком состоит из чистых функций, вроде функции
При таком подходе к написанию приложений меняется и образ мышления о софте. Работа теперь начинается не с UML-диаграммы интерфейсов и операций, а собственно с данных. Здесь есть некоторое сходство с data-oriented design. Правда, data-oriented design обычно используется с целью получения максимальной производительности, здесь же помимо скорости мы стремимся к простоте и правильности. Акцент немного другой, но есть важные сходства в методологии.
Выше представлены основные типы данных нашего приложения. Основное тело приложения состоит из
Другой важный тип:
Следующий тип —
Следующий тип:
Скорее всего, многие из вас уже думают о том, как реализовать эти операции. Если принимать по значению и возвращать по значению, то в большинстве случаев операции довольно простые. Код моего текстового редактора выложен на github, так что вы можете посмотреть, как он в действительности выглядит. Сейчас же я подробно остановлюсь только на коде, реализующем функцию отмены.
Правильно написать отмену без соответствующей инфраструктуры не так-то просто. В моём редакторе я реализовал её по образцу emacs, так что вначале пару слов об основных ее принципах. Команда возврата здесь отсутствует, и благодаря этому нельзя потерять работу. Если необходимо сделать возврат, в текст вносится любое изменение, и тогда все действия отмены становятся снова частью истории отмены.

Этот принцип изображен выше. Красный ромб здесь показывает позицию в истории: если только что не была выполнена отмена, красный ромб всегда в самом конце. Если выполнить отмену, ромб переместится на одно состояние назад, но одновременно в конец очереди добавится еще одно состояние — такое же, какое в данный момент видит пользователь (S3). Если выполнить отмену ещё раз и вернуться к состоянию S2, в конец очереди добавится состояние S2. Если теперь пользователь выполнит какое-то изменение, оно добавится в конец очереди как новое состояние S5, и на него будет перемещён ромб. Теперь при отмене прошлых действий вначале будут пролистаны прошлые действия отмены. Чтобы реализовать такую систему отмены, достаточно следующего кода:
Тут два действия,
Итак, мы имеем операцию
О путешествиях во времени. Как мы сейчас увидим, это тема, связанная с отменой. Я продемонстрирую работу фреймворка, который добавит полезную функциональность любому приложению с похожей архитектурой. Фреймворк здесь называется ewig-debug. В этой версии ewig включены некоторые возможности отладки. Сейчас из браузера можно открыть отладчик, в котором можно исследовать состояние приложения.
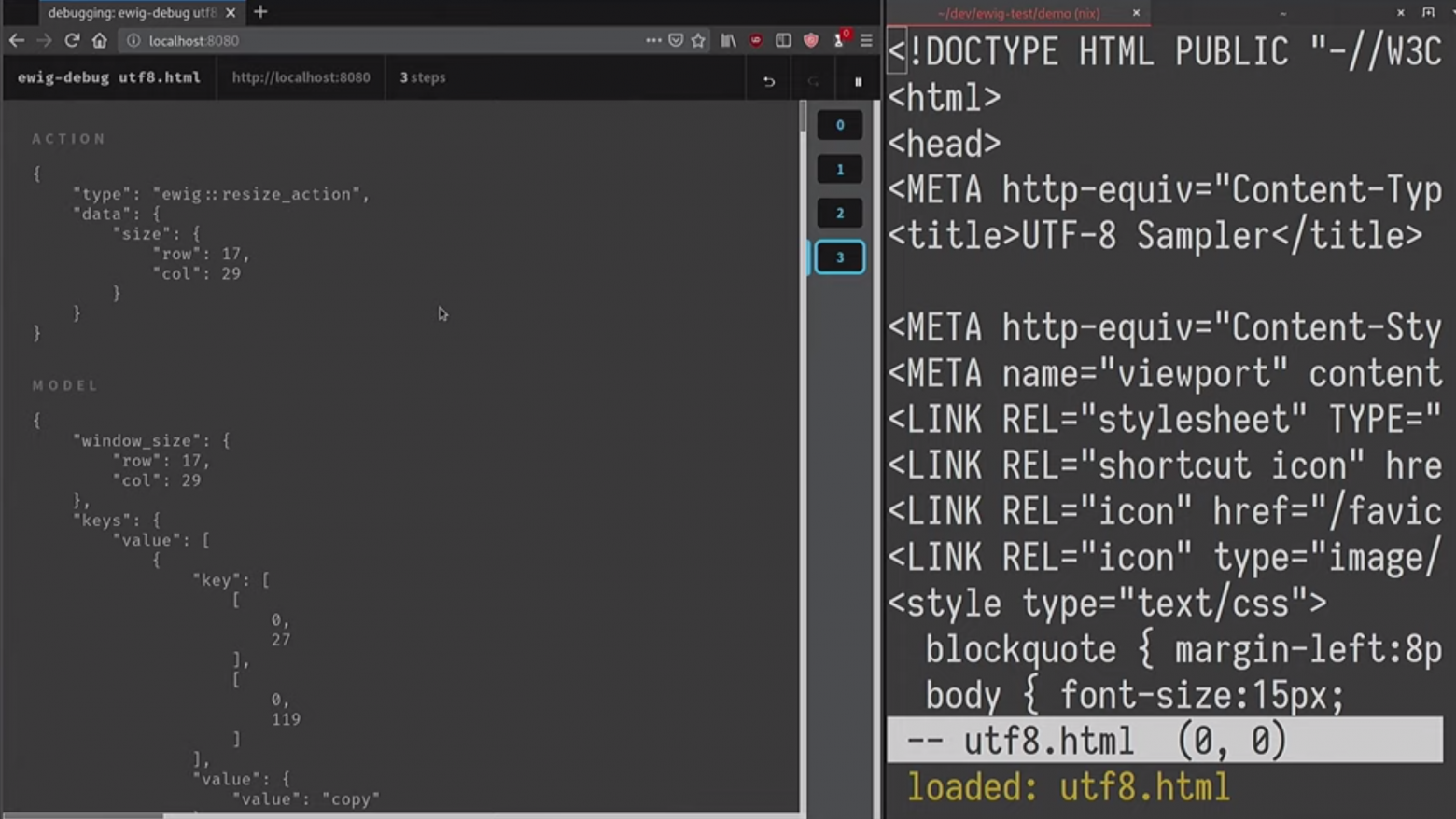
Мы видим, что последним действием было изменение размера, поскольку я открыл новое окно, и мой диспетчер окон автоматически поменял размер уже открытого окна. Конечно, для автоматической сериализации в JSON мне пришлось добавить аннотацию для struct из специальной библиотеки reflection. Но в остальном система вполне универсальная, её можно подключить к любому подобному приложению. Теперь в браузере можно увидеть всё совершённые действия. Конечно, есть и начальное состояние, у которого нет действия. Это состояние, которое было до выполнения загрузки. Больше того, двойным щелчком мыши я могу возвратить приложение к предыдущему состоянию. Это очень полезный инструмент отладки, который позволяет отследить возникновение неисправности в приложении.
Если вам интересно, то можете послушать мой доклад на CPPCON 19, The most valuable values, там я в подробностях рассматриваю этот отладчик.
Кроме того, там подробнее обсуждается архитектура, основанная на значениях. В нём я также рассказываю, как следует реализовывать действия и организовывать их иерархически. Это обеспечивает модульность системы и позволяет не держать всё в одной большой функции update. Кроме того, в том докладе говорится об асинхронности и о многопоточной загрузке файла. Есть ещё одна версия этого доклада, в которой полчаса дополнительного материала — Postmodern immutable data structures.
Думаю, пришло время подвести итоги. Приведу цитату Энди Винго (Andy Wingo) — он отличный разработчик, посвятил много времени V8 и компиляторам в целом, наконец, он занимается поддержкой Guile, реализацией Scheme для GNU. Недавно он написал в своём твиттере: «Чтобы добиться небольшого ускорения работы программы, мы измеряем каждое небольшое изменение и оставляем только те, которые дают положительный результат. А действительно существенного ускорения мы добиваемся, вслепую, вкладывая большие усилия, не имея 100%-й уверенности и руководствуясь только интуицией. Какая странная дихотомия».
Мне кажется, что разработчики на С++ преуспевают именно в первом жанре. Дайте нам закрытую систему, и мы, вооружившись нашими инструментами, выжмем из неё всё, что можно. Но вот во втором жанре мы работать не привыкли. Конечно, второй подход более рискованный, и зачастую он приводит к пустой трате больших усилий. С другой стороны, полностью переписав программу, её часто можно сделать и проще, и быстрее. Надеюсь, мне удалось убедить вас хотя бы попробовать этот второй подход.

Иммутабельные структуры данных не меняют своих значений. Чтобы что-то с ними сделать, нужно создавать новые значения. Старые же значения остаются на прежнем месте, поэтому их можно без проблем и блокировок читать из разных потоков. В итоге ресурсы можно совместно использовать более рационально и упорядоченно, ведь старые и новые значения могут использовать общие данные. Благодаря этому их куда быстрей сравнить между собой и компактно хранить историю операций с возможностью отмены. Все это отлично ложится на многопоточные и интерактивные системы: такие структуры данных упрощают архитектуру десктопных приложений и позволяют сервисам лучше масштабироваться. Иммутабельные структуры — секрет успеха Clojure и Scala, и даже сообщество JavaScript теперь пользуется их преимуществами, ведь у них есть библиотека Immutable.js, написанная в недрах компании Facebook.
Под катом — видео и перевод доклада Juan Puente с конференции C++ Russia 2019 Moscow. Хуан рассказывает про Immer — библиотеку иммутабельных структур для C++. В посте:
- архитектурные преимущества иммутабельности;
- создание эффективного персистентного векторного типа на основе RRB-деревьев;
- разбор архитектуры на примере простого текстового редактора.
Трагедия архитектуры, основанной на значениях
Чтобы понять значимость иммутабельных структур данных, обсудим семантику значений. Это очень важная особенность С++, я считаю её одним из главных достоинств этого языка. При всем при этом использовать семантику значений так, как нам хотелось бы, очень сложно. Я считаю, что в этом трагедия архитектуры, основанной на значениях, и дорога к этой трагедии вымощена благими намерениями. Предположим, нам необходимо написать интерактивное ПО на основе модели данных с репрезентацией редактируемого пользователем документа. При архитектуре, основанной на значениях, в основе этой модели используются простые и удобные типы значений, которые уже есть в языке:
vector, map, tuple, struct. Логика приложения создается из функций, которые принимают документы по значению и возвращают новую версию документа по значению. Этот документ может изменяться внутри функции (как это происходит ниже), но семантика значений в С++, применяемая к аргументу по значению и возвращаемому типу по значению, обеспечивает отсутствие побочных эффектов.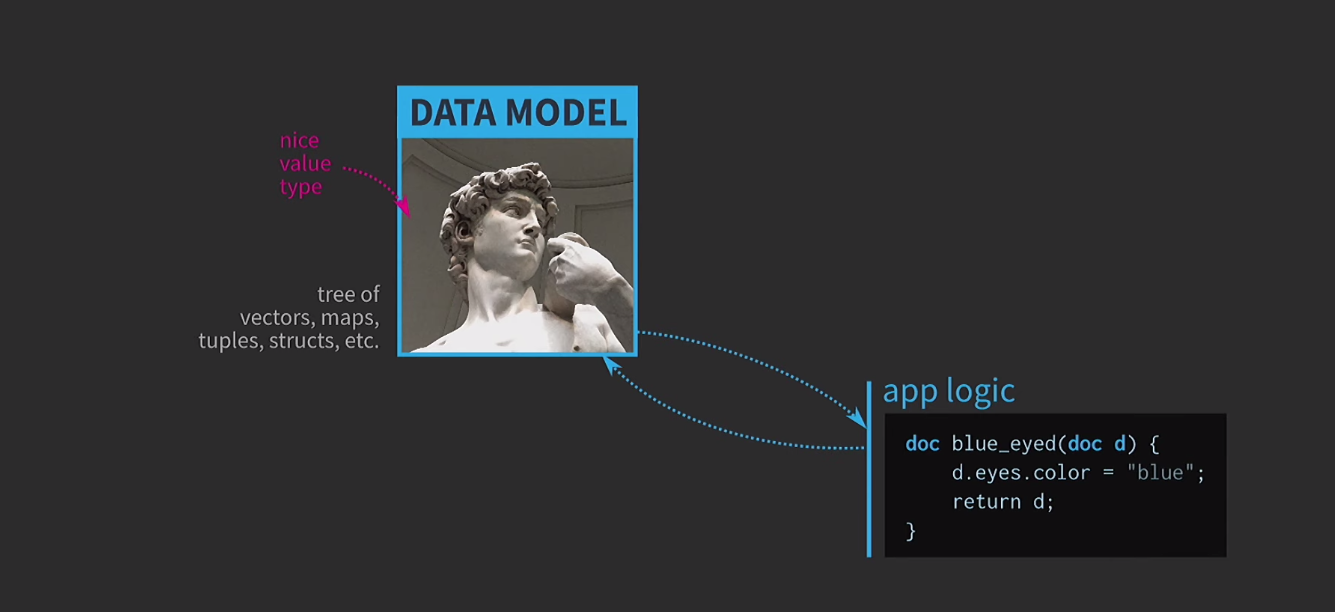
Такую функцию очень легко анализировать и тестировать.

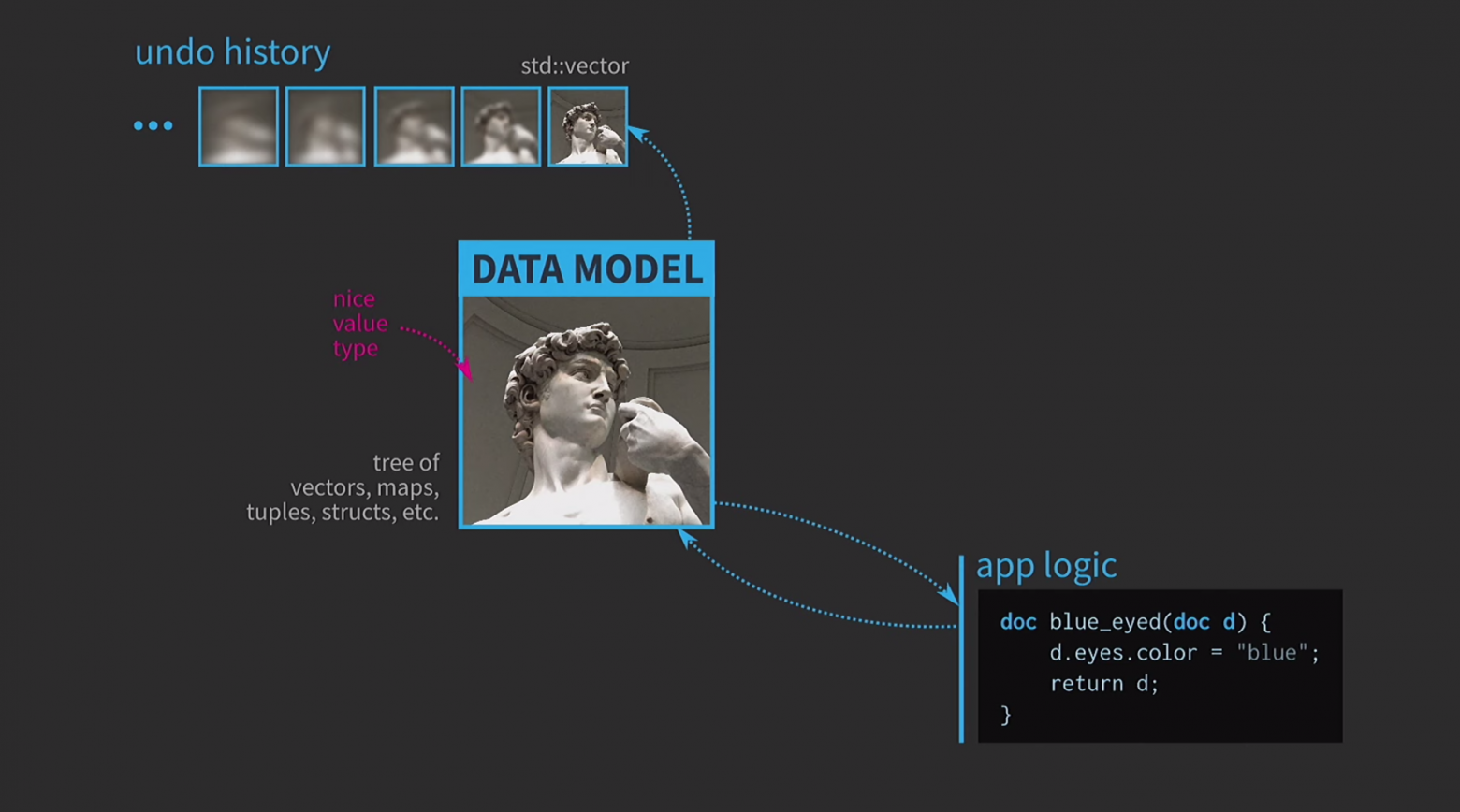
Раз мы работаем со значениями, попробуем реализовать отмену действия. Это бывает непросто, но при нашем подходе это тривиальная задача: у нас есть
std::vector с различными состояниями различных копий документа. 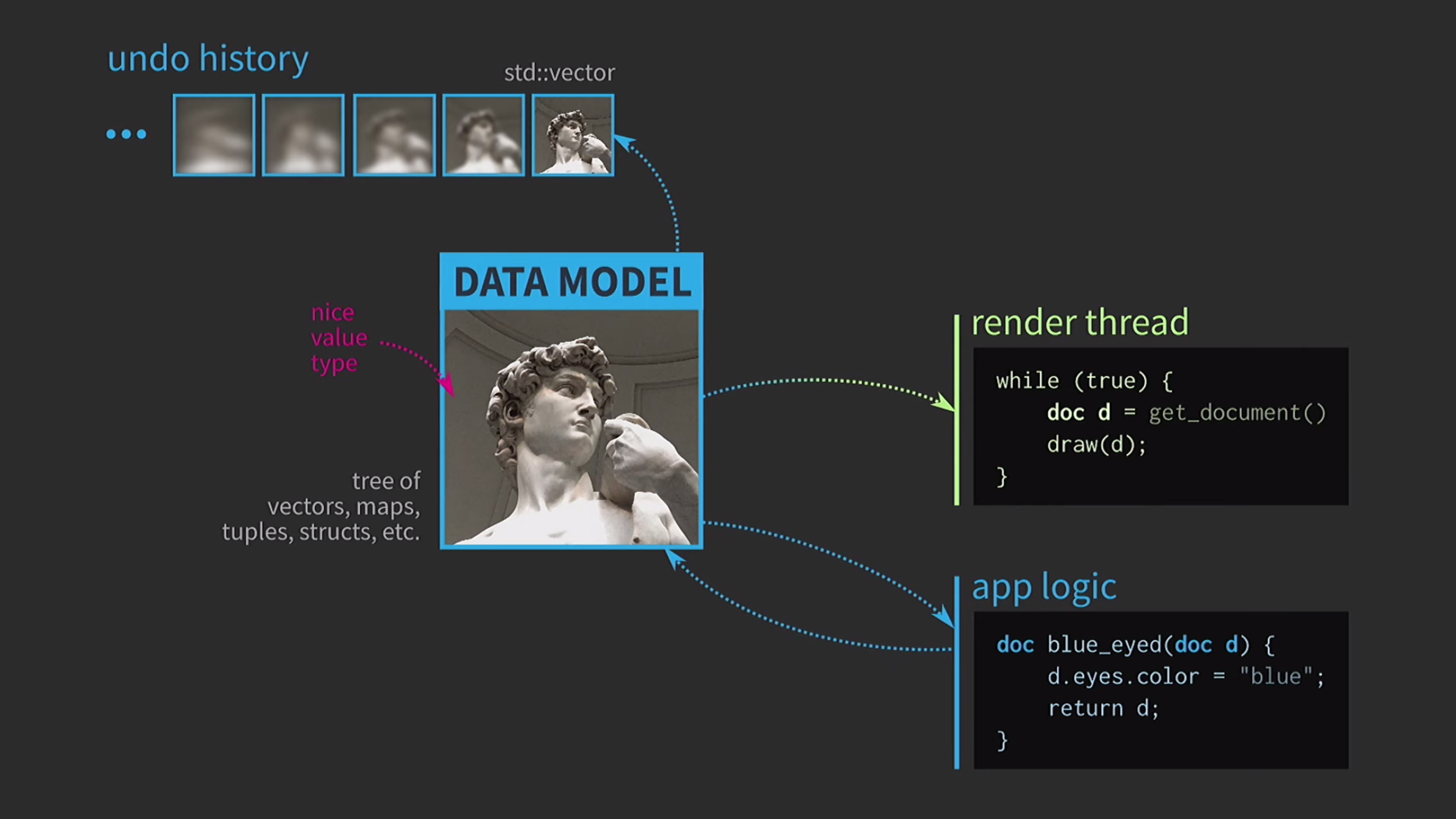
Предположим, у нас также есть UI, и, чтобы обеспечить его отзывчивость, отображение UI необходимо сделать в отдельном потоке. Документ пересылается в другой поток сообщением, и взаимодействие происходит тоже на основе сообщений, а не через предоставление общего доступа к состоянию с использованием
mutexes. Когда копия получена вторым потоком, там можно выполнять все необходимые операции.
Сохранение документа на диск зачастую выполняется очень медленно, в особенности если документ большой. Поэтому при помощи
std::async эта операция выполняется асинхронно. Мы используем лямбду, внутрь неё помещаем знак равенства, чтобы иметь копию, и теперь можно выполнять сохранение без других примитивных типов синхронизации.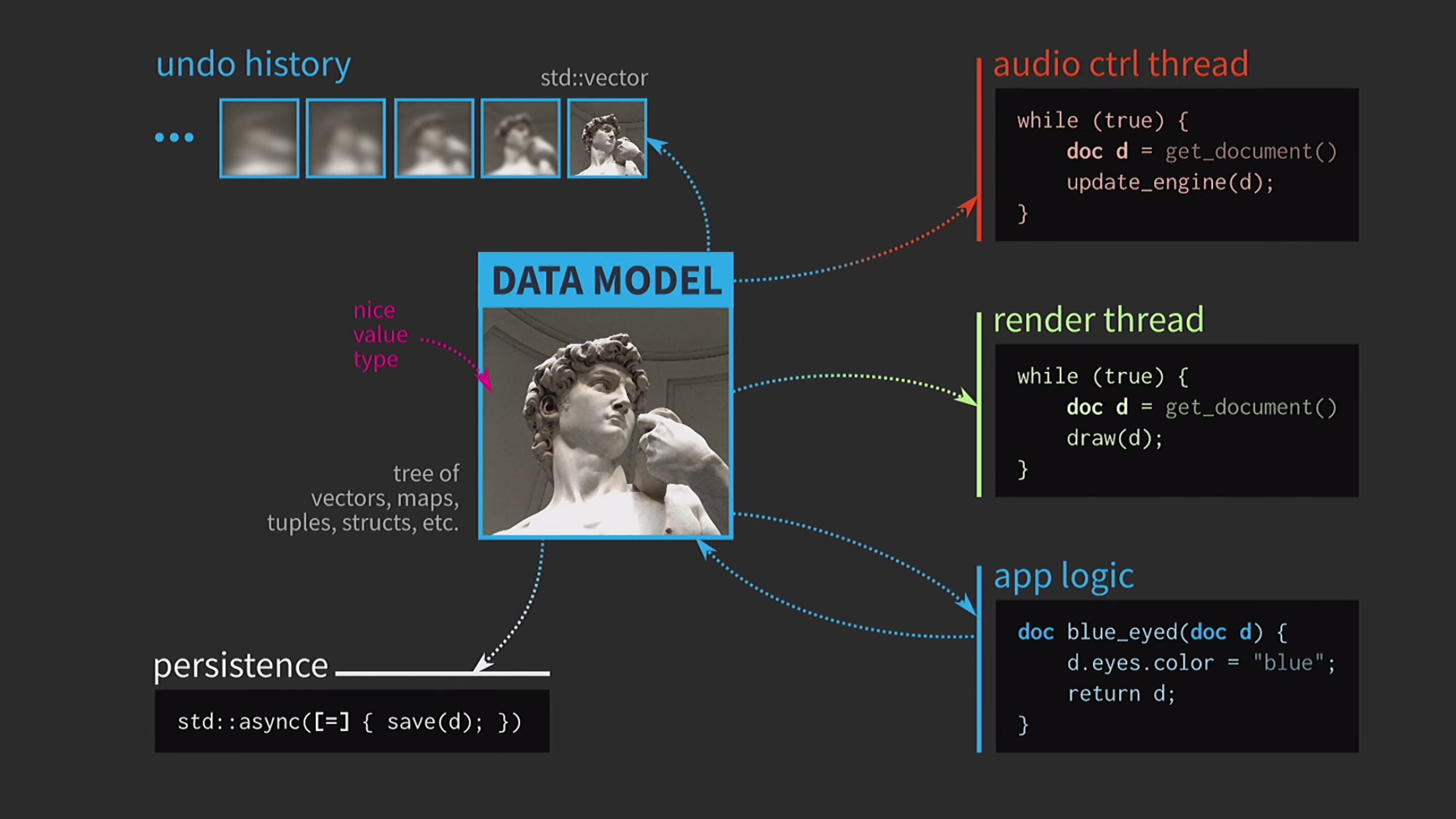
Далее, предположим, у нас есть ещё и поток управления звуком. Как я уже говорил, я много работал с музыкальным ПО, и звук является еще одним представлением нашего документа, он обязательно должен быть в отдельном потоке. Поэтому для этого потока также необходима копия документа.
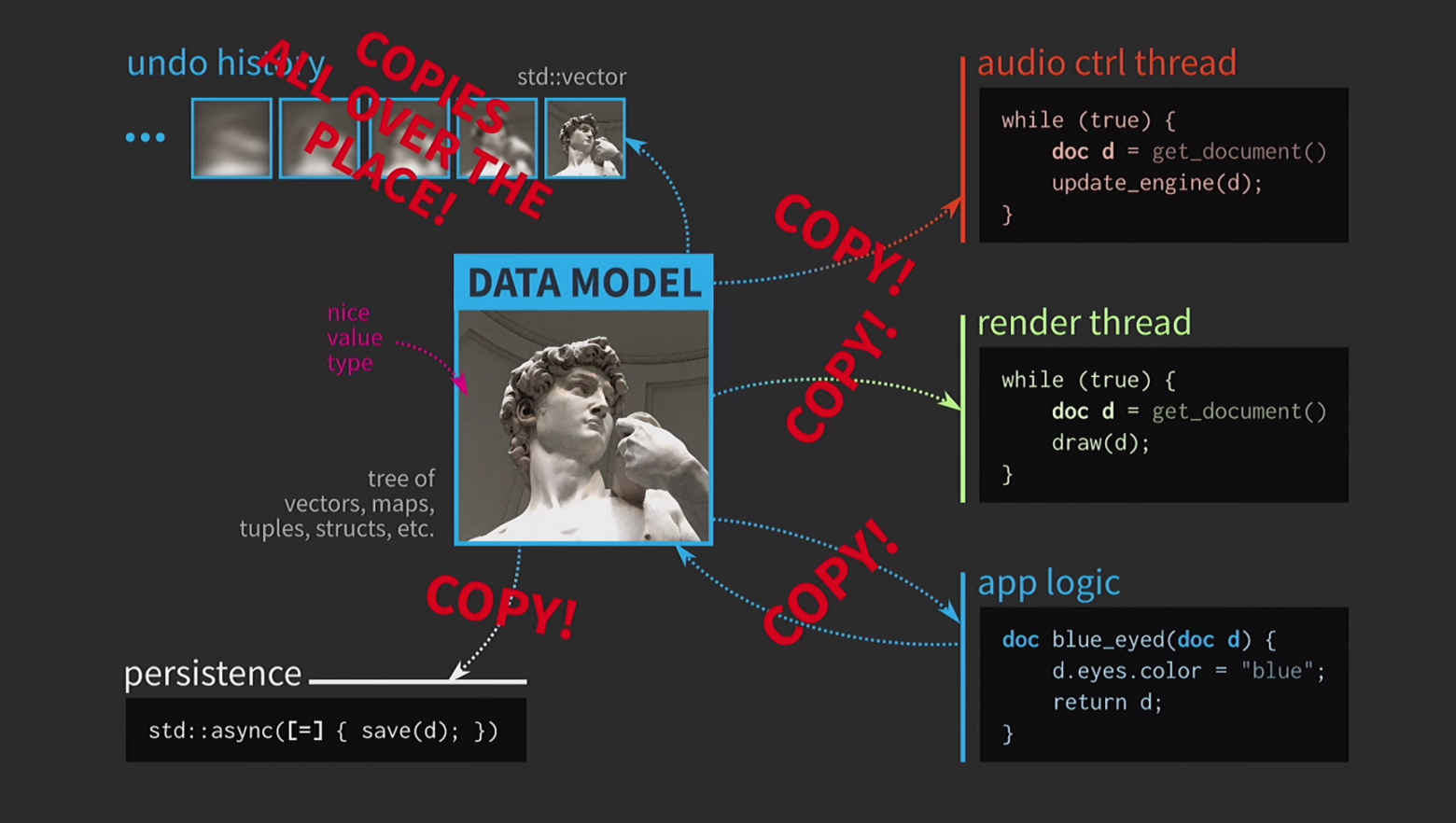
В итоге у нас получилась очень красивая, но не слишком реалистичная схема.
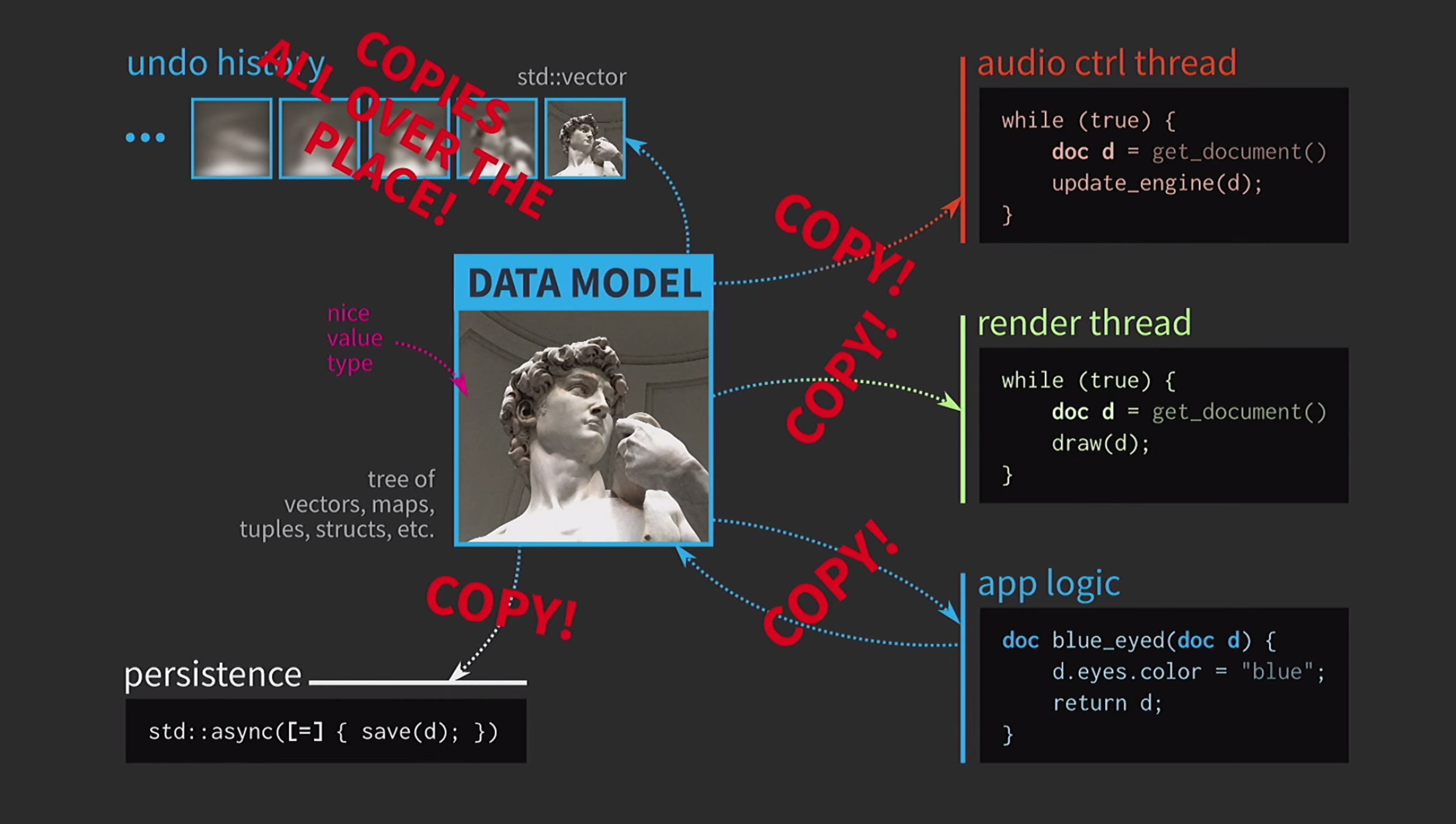
В ней постоянно приходится копировать документы, история действий для отмены занимает гигабайты, и для каждой отрисовки UI нужно сделать глубокую копию документа. В общем, все взаимодействия оказываются слишком затратными.
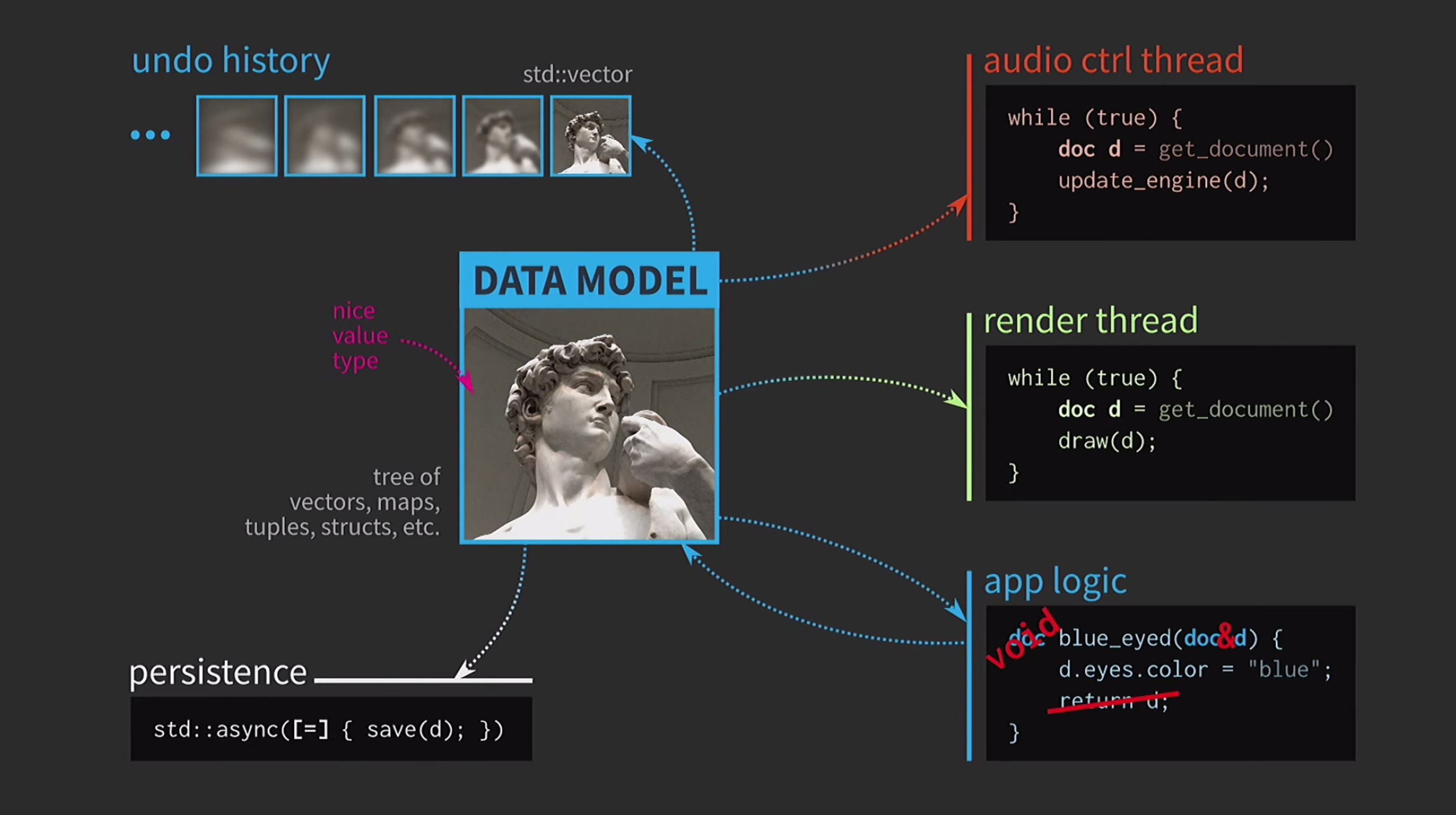
Что в этой ситуации делает разработчик на С++? Вместо того, чтобы принимать документ по значению, логика приложения теперь принимает ссылку на документ и обновляет её при необходимости. Возвращать в этом случае ничего не нужно. Но теперь мы имеем дело не со значениями, а с объектами и местоположениями. Это создает новые проблемы: если есть ссылка на состояние с общим доступом, для него нужен
mutex. Это крайне затратно, поэтому здесь будет некоторое представление нашего UI в виде крайне сложного дерева из различных Widget-ов.Все эти элементы должны получать обновления при изменении документа, поэтому необходим некоторый механизм очереди для сигналов об изменениях. Далее, история документа уже не является набором состояний, она будет реализацией паттерна Команда. Операцию необходимо реализовать дважды, в одном направлении и в другом, и убедиться в том, чтобы всё было симметрично. Выполнять сохранение в отдельном потоке уже слишком сложно, так что от этого придется отказаться.
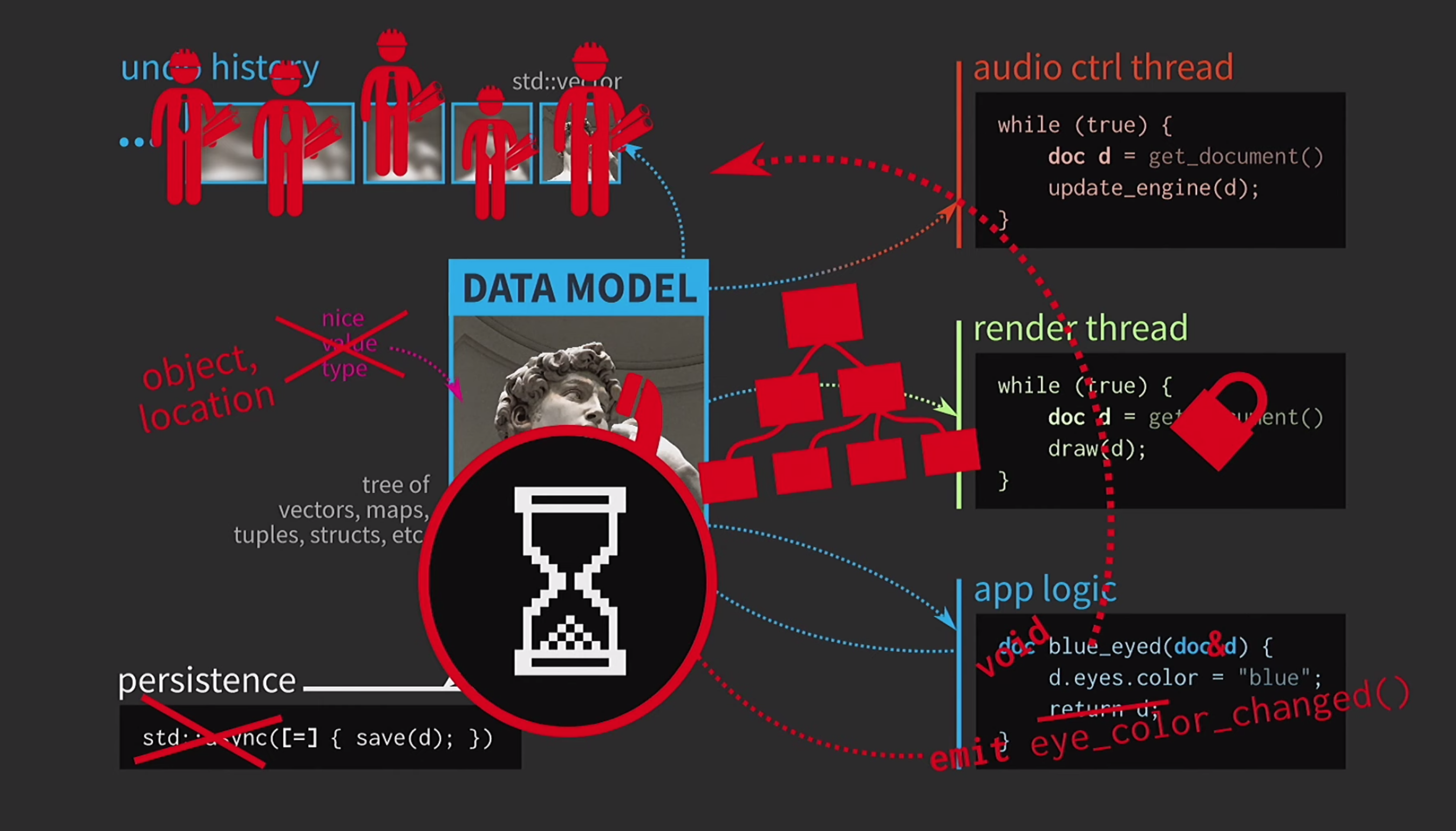
Пользователи уже привыкли к картинке песочных часов, так что ничего страшного, если они немного подождут. Страшно другое — нашим кодом теперь правит макаронный монстр.
В какой момент у нас всё пошло под откос? Мы отлично спроектировали наш код, а затем из-за копирования нам пришлось идти на компромиссы. Но в С++ копирование обязательно для передачи по значению лишь для мутабельных данных. Если же объект иммутабельный, то оператор присваивания можно реализовать так, чтобы он копировал только указатель на внутреннее представление и ничего больше.
const auto v0 = vector<int>{};Рассмотрим структуру данных, которая могла бы нам помочь. У вектора ниже все методы отмечены как
const, поэтому он иммутабельный. При выполнении .push_back не происходит обновления вектора, вместо этого возвращается новый вектор, к которому добавлены переданные данные. К сожалению, квадратными скобками при таком подходе мы пользоваться не можем из-за того, как они определены. Вместо этого можно использовать функцию .set, которая возвращает новую версию с обновленным элементом. Наша структура данных теперь обладает свойством, которое в функциональном программировании называется персистентность. Имеется ввиду не то, что мы сохраняем эту структуру данных на жёсткий диск, а тот факт, что при её обновлении старое содержимое не удаляется — вместо этого создается новый форк нашего мира, то есть структуры. Благодаря этому мы можем сравнивать прошлые значения с настоящими — это делается при помощи двух assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);Изменения теперь можно напрямую проверять, они больше не являются скрытыми свойствами структуры данных. Эта возможность особенно ценна в интерактивных системах, где нам постоянно приходится изменять данные.
Другое важное свойство — структурный общий доступ (structural sharing). Теперь у нас не происходит копирования всех данных для каждой новой версии структуры данных. Даже при
.push_back и .set копируются не все данные, а лишь небольшая их часть. Все имеющиеся у нас форки имеют общий доступ к компактному представлению, которое пропорционально количеству изменений, а не количеству копий. Отсюда также следует, что сравнение выполняется очень быстро: если всё хранится в одном блоке памяти, в одном указателе, то можно просто сравнить указатели и не исследовать элементы, которые находятся внутри них, в случае, если они равны.Поскольку такой вектор, как мне кажется, крайне полезен, я реализовал его в отдельной библиотеке: это immer — библиотека иммутабельных структур, проект с открытым кодом.
При написании его мне хотелось, чтобы его использование было привычным для разработчиков на С++. Есть много библиотек, которые реализуют концепции функционального программирования в С++, но при этом создается впечатление, что разработчики пишут для Haskell, а не для С++. Это создает неудобства. Кроме того, я добивался хорошей производительности. Люди используют С++, когда наличные ресурсы ограничены. Наконец, мне хотелось, чтобы библиотека была настраиваемой. Это требование связано с требованием производительности.
В поисках волшебного вектора
Во второй части доклада мы рассмотрим, как устроен этот иммутабельный вектор. Проще всего понять принципы такой структуры данных, начав с обычного списка. Если вы немного знакомы с функциональным программированием (на примере Lisp или Haskell), вы знаете, что списки — наиболее часто встречающиеся иммутабельные структуры данных.
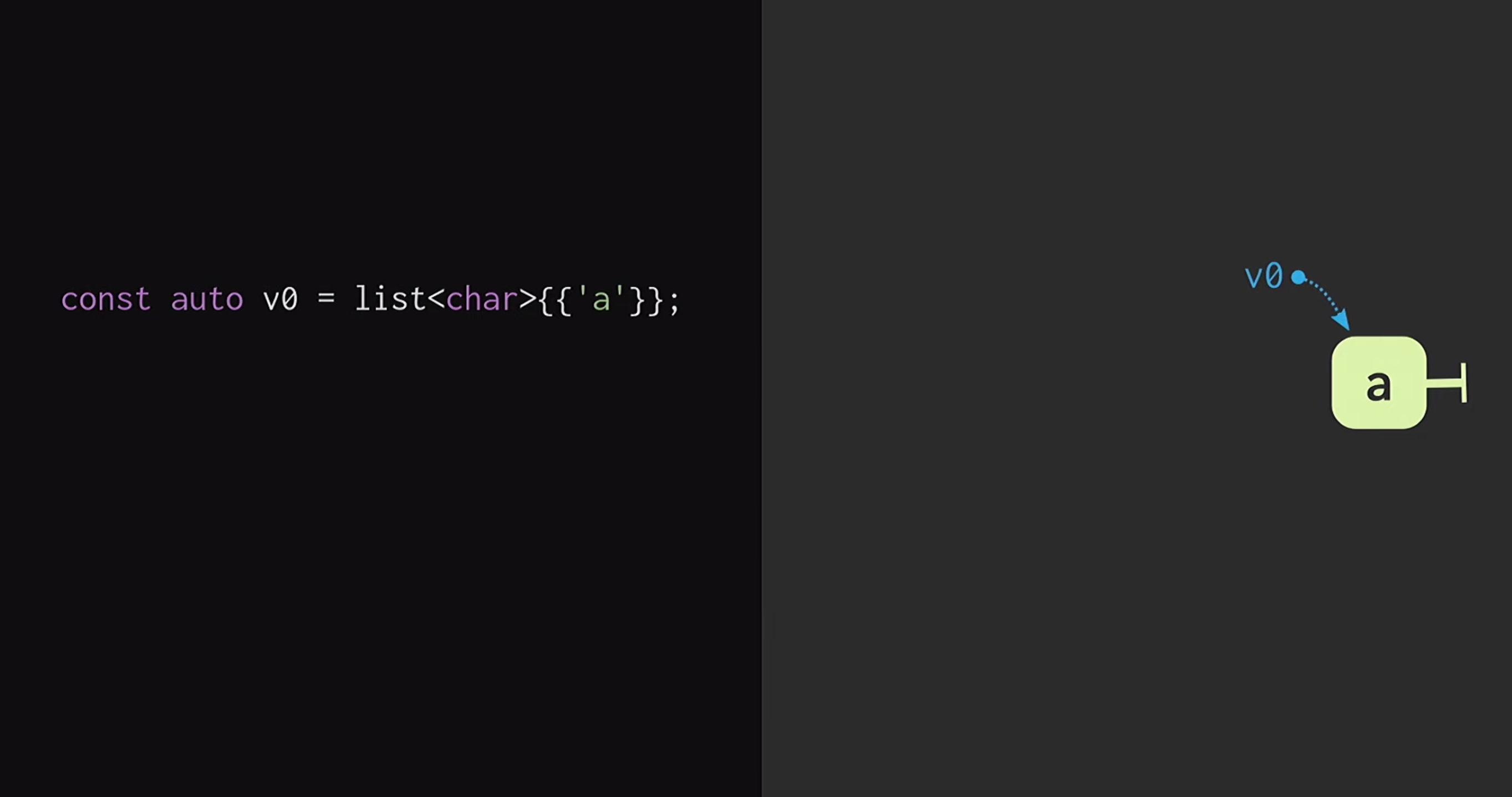
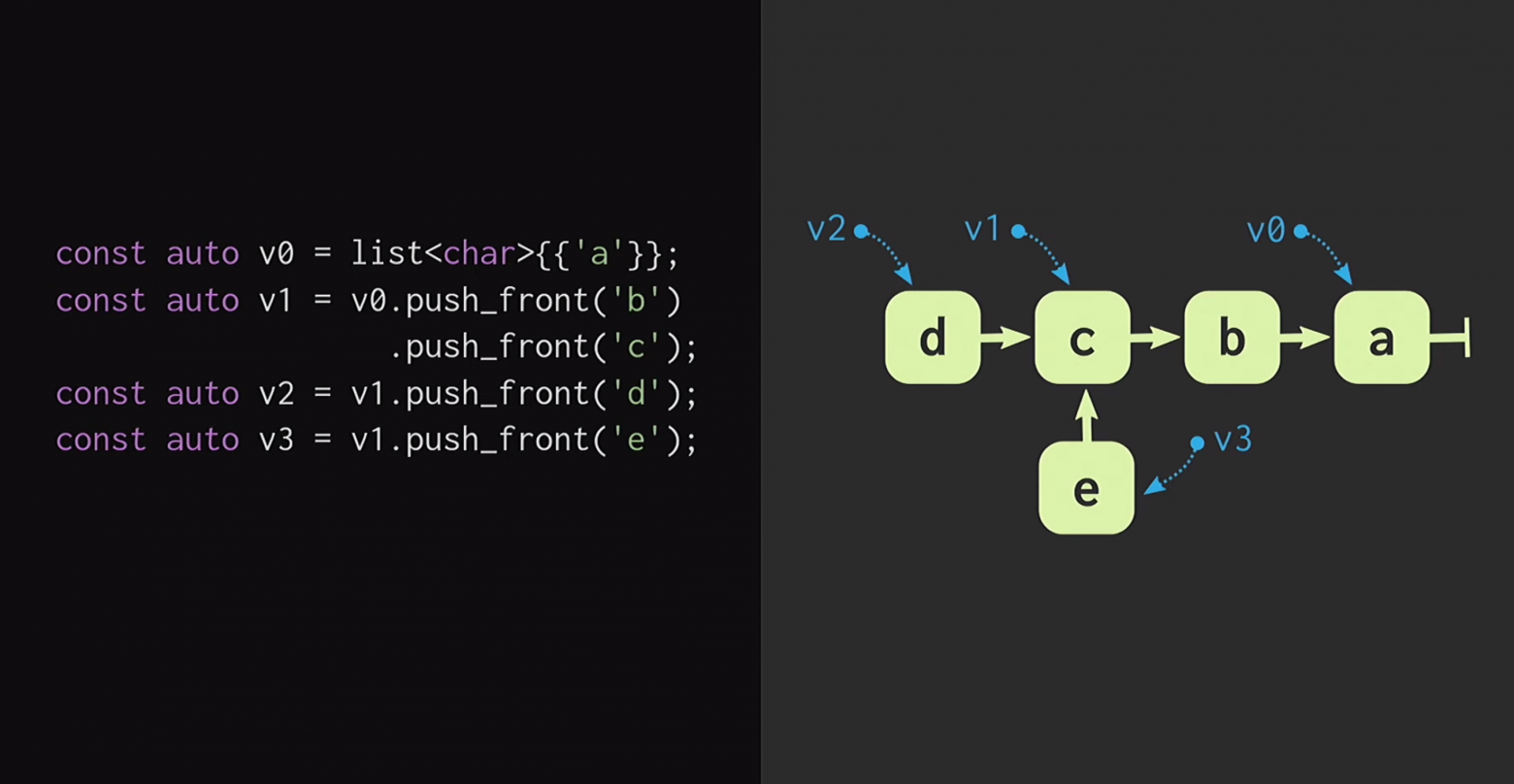
Для начала предположим, что у нас есть список с одним узлом,
а. При добавлении новых элементов в начало списка создаются новые узлы, в каждом из которых есть указатель на уже существующий узел. Поэтому в примере на слайде мы имеем не три копии одного списка, а три элемента в памяти, то есть v1 и v0 указывают на разные элементы. 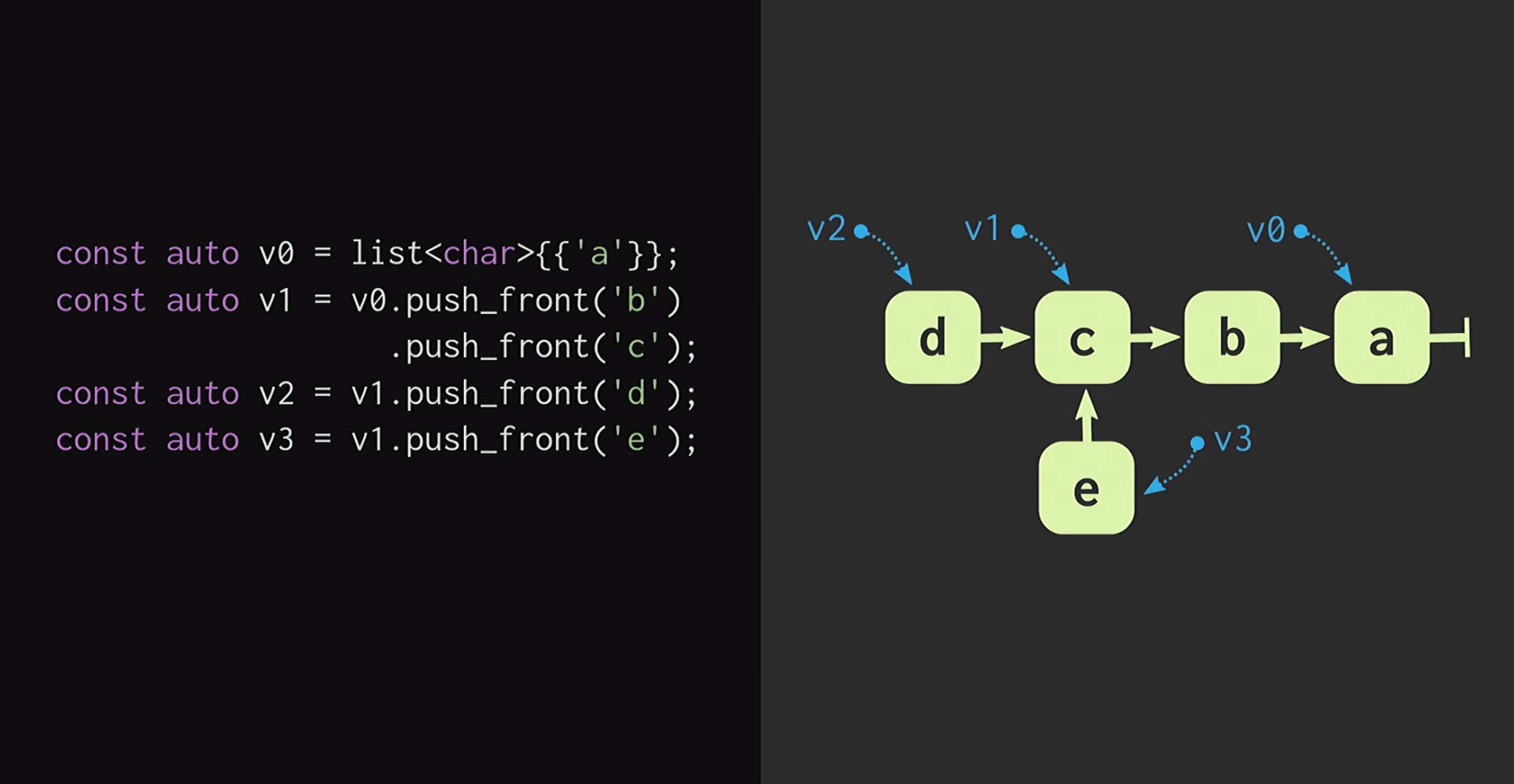
Также можем создать форк реальности, то есть создать новый список, у которого то же окончание, но отличающееся начало.
Такие структуры данных изучаются уже давно: Крис Окасаки (Chris Okasaki) написал основополагающую работу Purely Functional Data Structures. Кроме того, весьма интересна предложенная Ральфом Хинце (Ralf Hinze) и Россом Патерсоном (Ross Paterson) структура данных Finger Tree. Но для С++ такие структуры данных подходят плохо. Они используют небольшие узлы, а мы знаем, что в С++ небольшие узлы означают отсутствие эффективности кэширования.
Кроме того, они зачастую полагаются на свойства, которых у С++ нет, например, отложенность (laziness). Поэтому для нас значительно полезнее работа Фила Бэгуэлла (Phil Bagwell) по иммутабельным структурам данных — ссылка, написанная в начале 2000-х, а также труд Рича Хики (Rich Hickey) — ссылка, автора языка Clojure. Рич Хики создал список, который на самом деле является не списком, а основан на современных структурах данных: векторах и хэш-мэпах. Эти структуры данных обладают эффективностью кэширования и прекрасно взаимодействуют с современными процессорами, для которых нежелательно работать с небольшими узлами. Такие структуры вполне можно использовать в С++.
Как построить иммутабельный вектор? В основе любой структуры, хотя бы отдаленно напоминающей вектор, должен быть массив. Но массив не обладает структурным общим доступом. Чтобы изменить любой элемент массива, при этом не теряя свойства персистентности, необходимо скопировать весь массив. Чтобы не делать этого, массив можно разбить на отдельные куски.
Теперь при обновлении элемента вектора нам необходимо скопировать только один кусок, а не весь вектор. Но сами по себе такие куски не являются структурой данных, они должны быть так или иначе объединены. Поместим их в другой массив. Вновь возникает та проблема, что массив может оказаться очень большим, и тогда копирование его опять займёт слишком много времени.
Поделим и этот массив на куски, поместим их вновь в отдельный массив, и повторим эту процедуру до тех пор, пока не останется один корневой массив. Получившаяся структура называется дерево остатков. Это дерево описывается константой M = 2B, то есть показатель ветвления дерева (branching factor). Этот показатель ветвления должен быть степенью двойки, и мы очень скоро узнаем, почему. В примере на слайде использованы блоки из четырех символов, но на практике используются блоки размером в 32 символа. Существуют эксперименты, при помощи которых можно найти оптимальный размер блока для определенной архитектуры. Это позволяет добиться наилучшего соотношения структурного общего доступа и времени доступа: чем дерево ниже, тем меньше время доступа.
Читая это, разработчики, пишущие на С++, наверное, думают: но ведь любые структуры на основе дерева очень медленные! Деревья растут при увеличении числа элементов в них, и из-за этого ухудшается время доступа. Именно поэтому программисты предпочитают
std::unordered_map, а не std::map. Спешу вас успокоить: наше дерево растёт очень медленно. Вектор, содержащий все возможные значения 32-битного int, в высоту содержит всего 7 уровней. Можно экспериментально показать, что при таком размере данных отношение кэша к объему нагрузки значительно больше влияет на производительность, чем глубина дерева.Давайте посмотрим, как выполняется доступ к элементу дерева. Предположим, необходимо обратиться к элементу 17. Мы берём бинарное представление индекса и разбиваем его на группы размером с фактор ветвления.

В каждой группе мы используем соответствующее бинарное значение и таким образом спускаемся вниз по дереву.
Далее, предположим, нам необходимо сделать изменение в этой структуре данных, то есть выполнить метод
.set. 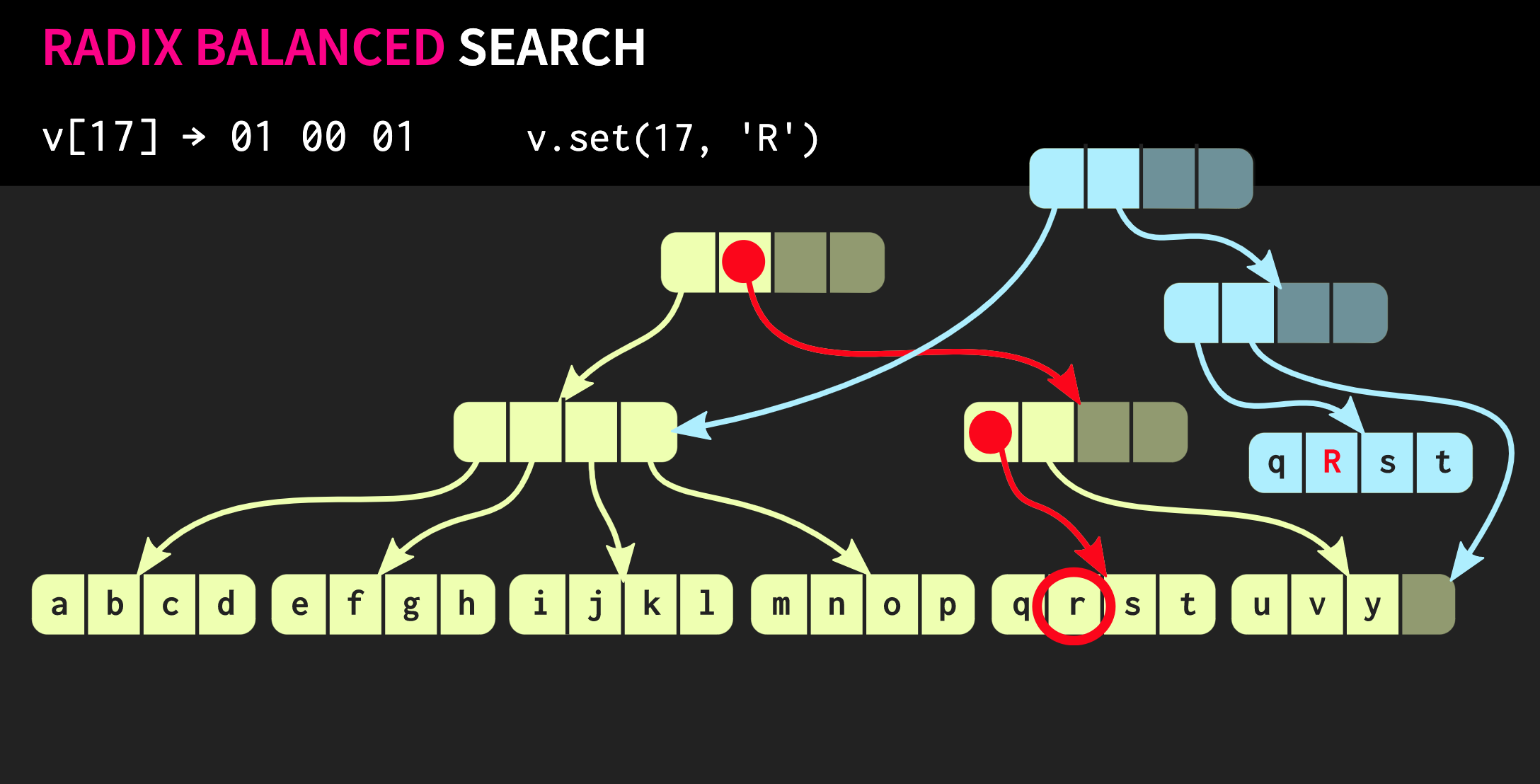
Для этого вначале необходимо скопировать блок, в котором находится элемент, а затем скопировать каждый внутренний узел на пути к элементу. С одной стороны, копировать приходится довольно много данных, но при этом значительная часть этих данных общая, это компенсирует их объем.
Кстати говоря, существует значительно более старая структура данных, которая очень похожа на ту, которую я описал. Это страницы памяти (memory pages) с деревом таблицы страниц. Управление ей тоже осуществляется при помощи вызова
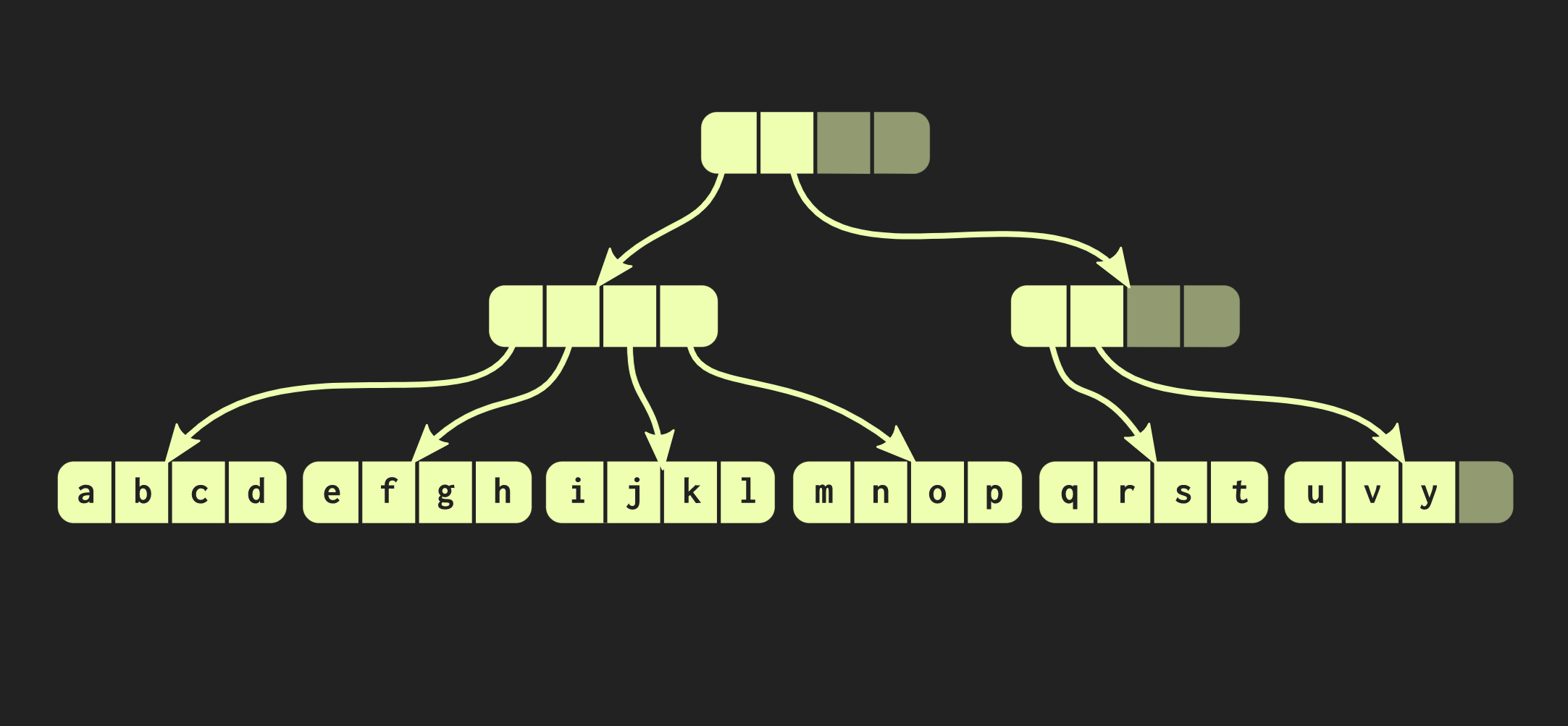
fork.Попытаемся улучшить нашу структуру данных. Предположим, нам необходимо соединить два вектора. Пока что описанная структура данных обладает теми же ограничениями, что и
std::vector: в ней есть пустые ячейки в самой правой её части. Поскольку структура идеально сбалансирована, эти пустые ячейки не могут находиться в середине дерева. Поэтому если существует второй вектор, который мы хотим объединить с первым, нам необходимо будет скопировать элементы в пустые ячейки, что создаст пустые ячейки во втором векторе, и в итоге придётся копировать целиком второй вектор. Такая операция обладает вычислительной сложностью O(n), где n – размер второго вектора.Попытаемся добиться лучшего результата. Существует изменённый вариант нашей структуры данных, который называется relaxed radix balanced tree. В этой структуре узлы, которые не находятся на самом левом пути, могут иметь пустые ячейки. Поэтому в таких неполных (или расслабленных) узлах необходимо подсчитывать размер поддерева. Теперь можно выполнить сложную, но логарифмическую операцию объединения. Эта операция постоянной временной сложности — О(log(32)). Поскольку деревья неглубокие, время доступа является константой, хоть и относительно большой. Благодаря тому, что у нас есть такая операция объединения, relaxed вариант этой структуры данных называют сливающимся (confluent): помимо того, что она персистентная, и можно сделать её форк, две таких структуры можно объединить в одну.
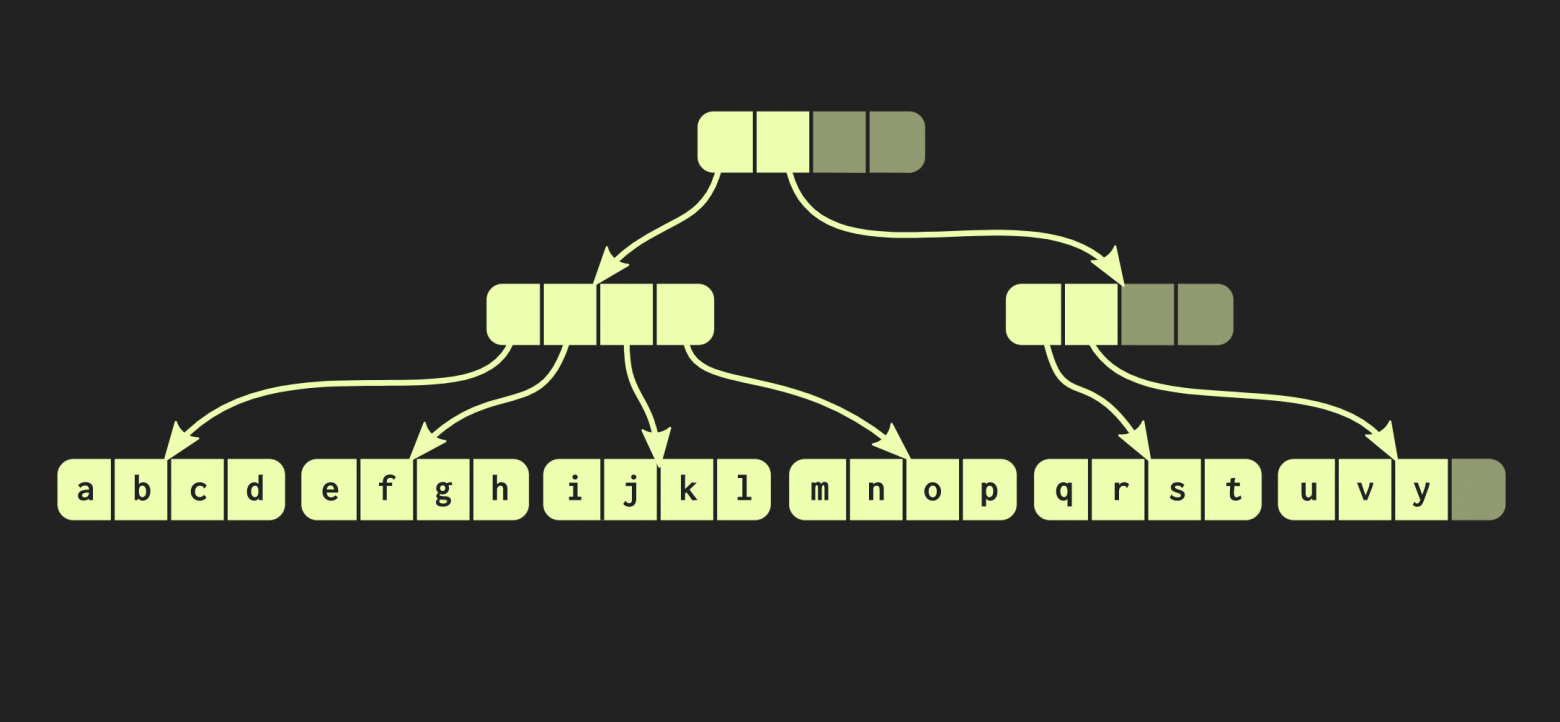
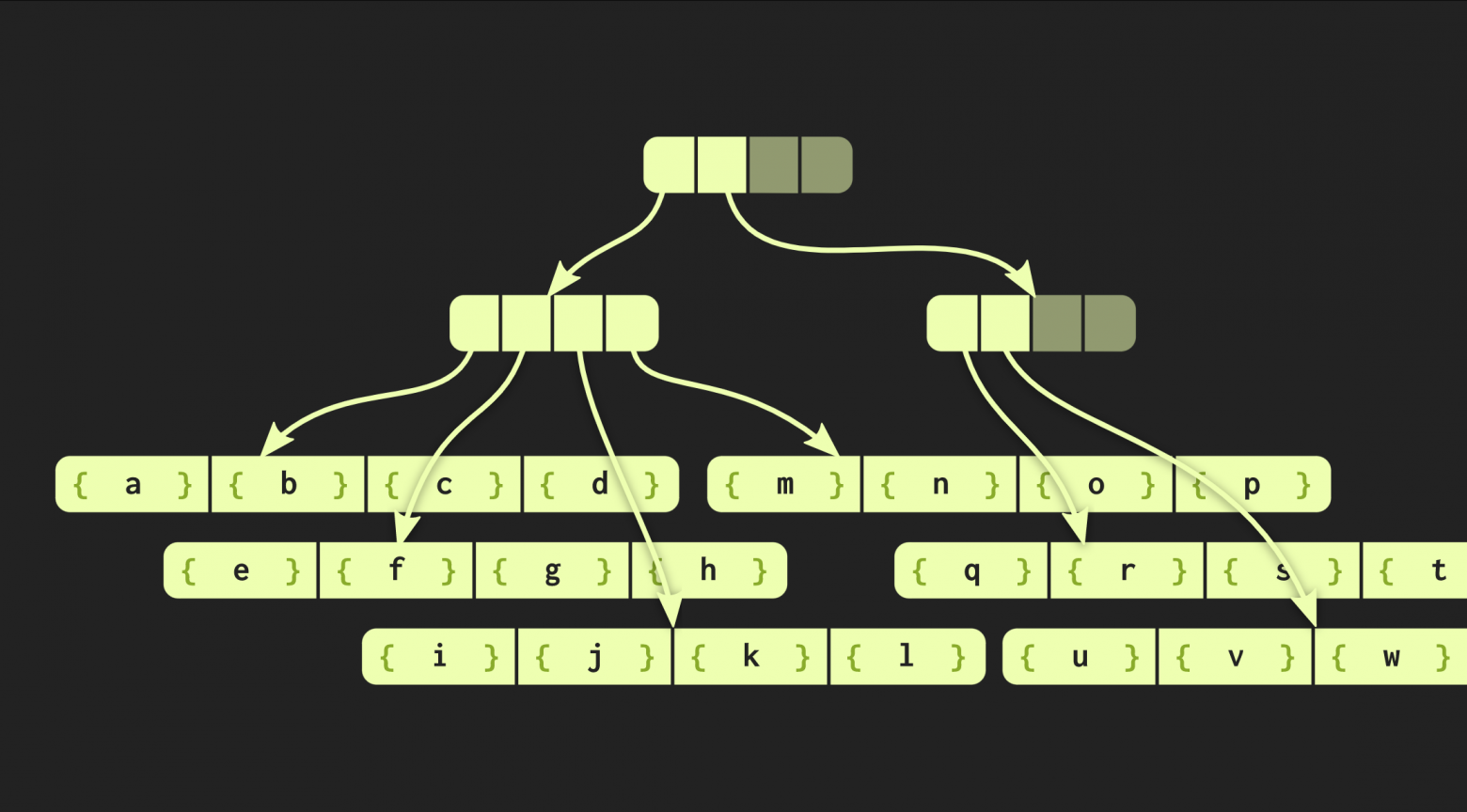
В том примере, с которым мы до сих пор работали, структура данных очень аккуратная, но на практике реализации в Clojure и других функциональных языках выглядят иначе. В них создаются контейнеры для каждого значения, то есть каждый элемент в векторе находится в отдельной ячейке, а листовые узлы содержат указатели на эти элементы. Но такой подход крайне неэффективный, в С++ обычно не помещают каждое значение в контейнер. Поэтому будет лучше, если эти элементы будут находиться в узлах напрямую. Тогда возникает другая проблема: у разных элементов разные размеры. Если элемент по размеру совпадает с указателем, наша структура будет выглядеть так, как показано ниже:
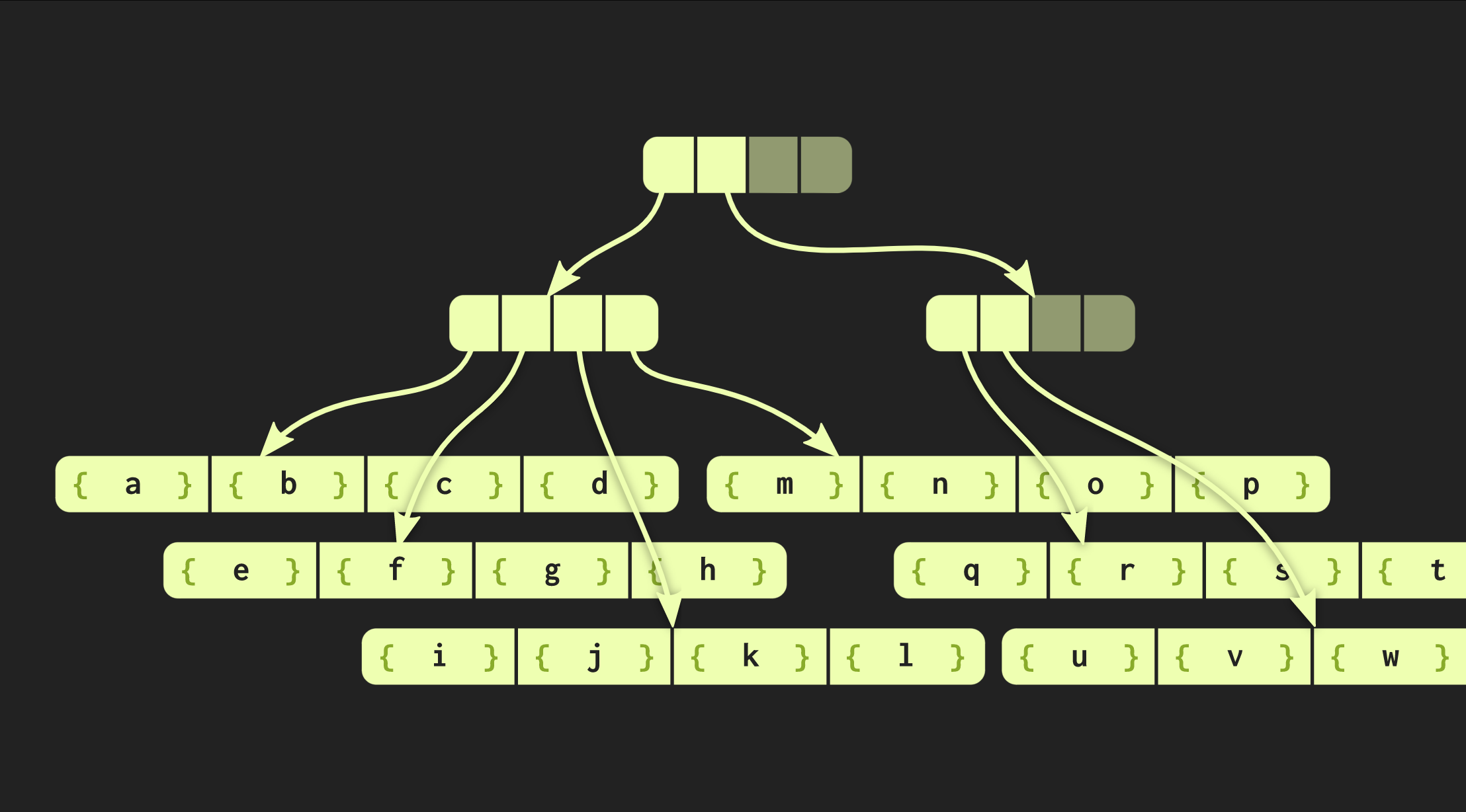
Но если элементы обладают большим размером, то структура данных теряет измеренные нами свойства (время доступа О(log(32)()), потому что копирование одного из листов теперь занимает больше времени. Поэтому я изменил эту структуру данных так, чтобы при увеличении размера содержащихся в ней элементов уменьшалось количество этих элементов в листовых узлах. Напротив, если элементы маленькие, то их теперь может поместиться больше. Новый вариант дерева называется embedding radix balanced tree. Оно описывается уже не одной константой, а двумя: одна из них описывает внутренние узлы, а вторая — листовые. Реализация дерева в С++ может рассчитать оптимальный размер листового элемента в зависимости от размеров указателей и самих элементов.
Наше дерево работает уже весьма неплохо, но его ещё можно улучшить. Взглянем на функцию, похожую на функцию
iota: vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Она принимает на вход
vector, выполняет push_back в конец вектора для каждого целого числа между first и last, и возвращает то, что получилось. С правильностью этой функции всё в порядке, но она работает неэффективно. Каждый вызов push_back копирует самый левый блок без всякой нужды: следующий вызов выполняет push ещё одного элемента и копирование повторяется заново, а скопированные предшествующим методом данные удаляются. Можно попробовать другую реализацию этой функции, в которой мы отказываемся от персистентности внутри функции. Можно использовать
transient vector с мутабельным API, который совместим с API обычного vector. Внутри такой функции каждый вызов push_back изменяет структуру данных. vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Такая реализация более эффективная, и она позволяет повторно использовать новые элементы на самом правом пути. В конце функции выполняется вызов
.persistent(), который возвращает иммутабельный vector. Возможные побочные эффекты остаются невидимы извне функции. Изначальный vector как был, так и остается иммутабельным, изменяются только данные, созданные внутри функции. Как я уже говорил, важное преимущество такого подхода в том, что можно использовать std::back_inserter и стандартные алгоритмы, которые требуют мутабельных API.Рассмотрим другой пример.
vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
Функция не принимает и возвращает
vector, а внутри выполняется цепочка вызовов push_back. Здесь, как и в прошлом примере, может происходить ненужное копирование внутри вызова push_back. Обратим внимание, что первое значение, с которым выполняется push_back, является именованным (named value), а остальные — r-value, то есть анонимные ссылки. Если у вас используется подсчёт ссылок, то метод push_back может обратиться к счетчикам ссылок для узлов, для которых выделена память в дереве. И в случае с r-value, если количество ссылок является единицей, становится ясно, что никакая другая часть программы к этим узлам не обращается. Здесь производительность ровно такая же, как и в случае с transient. vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Далее, чтобы помочь компилятору мы можем выполнить
move(v), поскольку v больше нигде в функции не используется. У нас появилось важное преимущество, которого не было в transient варианте: если функции «say_hi» передать возвращенное значение другого «say_hi», то не возникнет никаких лишних копий. В случае же с transient существуют границы, на которых может происходить лишнее копирование. Иначе говоря, мы имеем персистентную, иммутабельную структуру данных, производительность которой зависит от действительного объема общего доступа в рантайме. Если же общего доступа нет, то производительность будет такой же, как и у мутабельной структуры данных. Это крайне важное свойство. Пример, который я вам уже показывал выше, можно переписать с методом move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
До сих пор мы говорили о векторах, а помимо них есть ещё и хэш-мэпы. Им посвящён очень полезный доклад Фила Нэша (Phil Nash): The holy grail. A hash array mapped trie for C++. Там описываются хэш-таблицы, реализованные на основе тех же принципов, о которых я сейчас говорил.
Уверен, у многих из вас есть сомнения относительно производительности подобных структур. Быстро ли они работают на практике? Я провел множество тестов, и вкратце мой ответ: да. Если вы хотите подробнее познакомиться с результатами тестирования, они опубликованы в моей статье для International Conference of Functional Programming 2017. Сейчас, я думаю, лучше обсудить не абсолютные значения, а то влияние, которое эта структура данных оказывает на систему в целом. Конечно же, update нашего вектора выполняется медленнее, поскольку необходимо скопировать несколько блоков данных и выделить память для других данных. А вот обход нашего вектора выполняется почти с такой же скоростью, как и обычного. Мне было очень важно этого добиться, поскольку чтение данных выполняется значительно чаще, чем их изменение.
Кроме того, за счет более медленного update нет необходимости что-либо копировать, копируется только структура данных. Поэтому время, которое тратится на обновление вектора как бы амортизируется для всех копий, выполняемых в системе. Поэтому, если применять эту структуру данных в архитектуре наподобие той, которую я описал в начале доклада, производительность существенно вырастает.
EWIG
Не буду голословным и продемонстрирую мою структуру данных на примере. Я написал небольшой текстовый редактор. Это интерактивный инструмент под названием ewig, в нём документы представлены иммутабельными векторами. У меня на диске сохранена копия всей википедии на эсперанто, она весит 1 гигабайт (вначале я хотел скачать английскую версию, но она чересчур уж большая). Каким бы текстовым редактором вы ни пользовались, я уверен, что этот файл ему не понравится. А при загрузке этого файла в ewig его сразу же можно редактировать, потому что загрузка идет асинхронно. Навигация файла работает, ничего не висит, нет
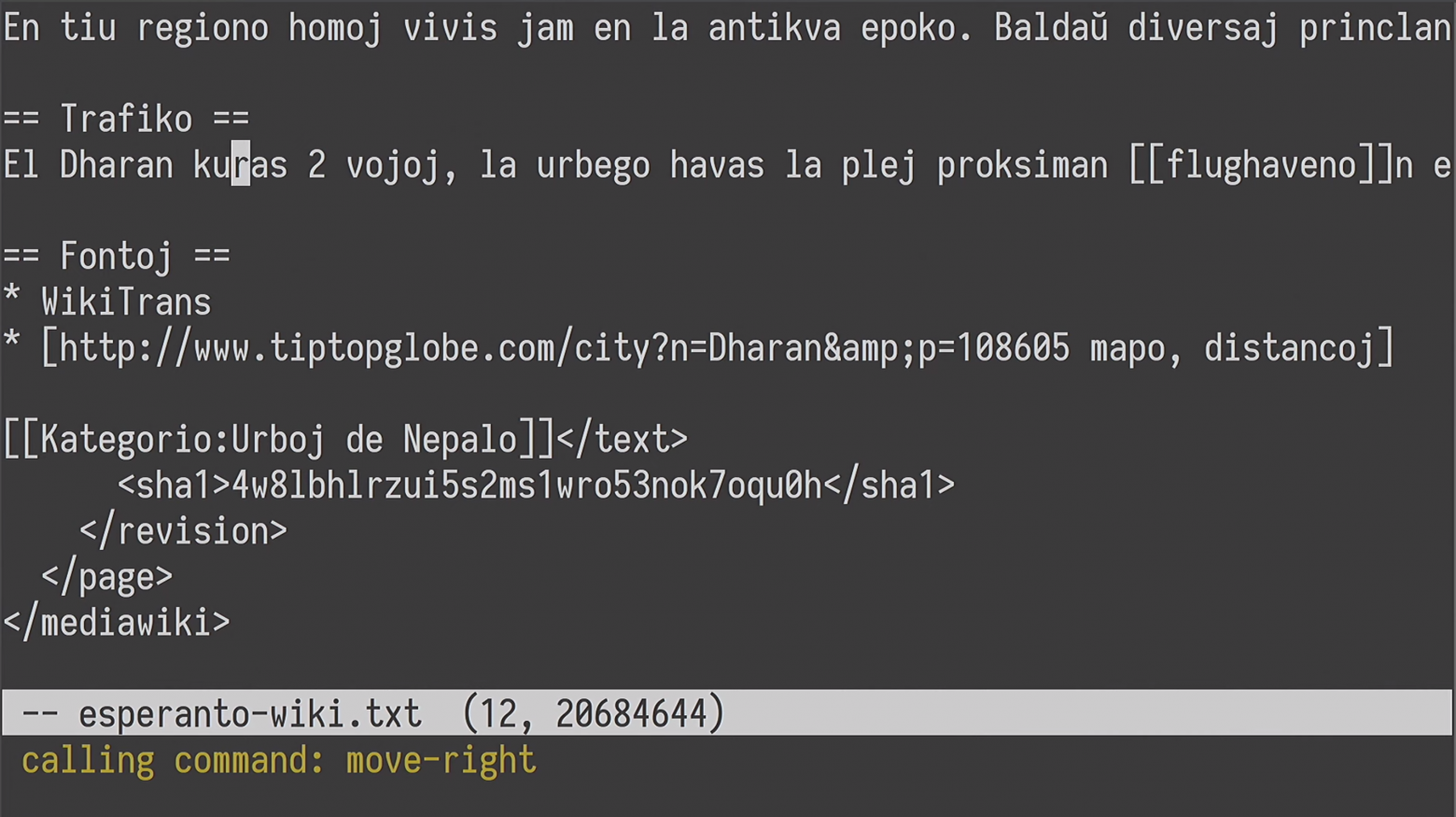
mutex, нет синхронизации. Как видим, загруженный файл занимает 20 млн. строк кода.Прежде, чем рассматривать самые важные свойства этого инструмента, обратим внимание на забавную деталь.

В начале строки, выделенной белым в нижней части изображения, вы видите два дефиса. Этот UI, скорее всего, знаком пользователям emacs, дефисы там означают, что документ никак не был изменён. Если же внести какие-либо изменения, то вместо дефисов отображаются звездочки. Но, в отличие от других редакторов, если в ewig затем удалить эти изменения (не отменить, а именно удалить), то вместо звёздочек вновь отобразятся дефисы, поскольку в ewig сохраняются все предшествующие версии текста. Благодаря этому не нужен специальный флаг, показывающий, изменён ли документ: наличие изменений определяется сравнением с исходным документом.
Рассмотрим другое интересное свойство инструмента: скопируем текст целиком и вставим его пару раз в середину имеющегося текста. Как видим, это происходит моментально. Соединение векторов здесь является логарифмической операцией, и логарифм нескольких миллионов — не такая уж и длительная операция. Если же попытаться сохранить этот огромный документ на жёсткий диск, это займет значительно больше времени, поскольку текст уже не представлен как вектор, полученный от предыдущей версии этого вектора. При сохранении на диск происходит сериализация, поэтому теряется персистентность.
Возврат к архитектуре, основанной на значениях

Начнём с того, как к этой архитектуре нельзя вернуться: с помощью обычных Controller, Model и View в стиле Java, которые чаще всего и используются для интерактивных приложений в С++. Ничего плохого в них нет, но для нашей проблемы они не подходят. С одной стороны, паттерн Model-View-Controller позволяет добиться разделения задач, но с другой, каждый из этих элементов является объектом, как с объектно-ориентированной точки зрения, так и с точки зрения С++, то есть это участки памяти с мутабельным состоянием. View знает о Model; что значительно хуже — Model косвенно знает о View, потому что почти наверняка существует некоторый callback, через который View получает оповещение при изменении Model. Даже при лучшей реализации объектно-ориентированных принципов мы получаем множество взаимных зависимостей.
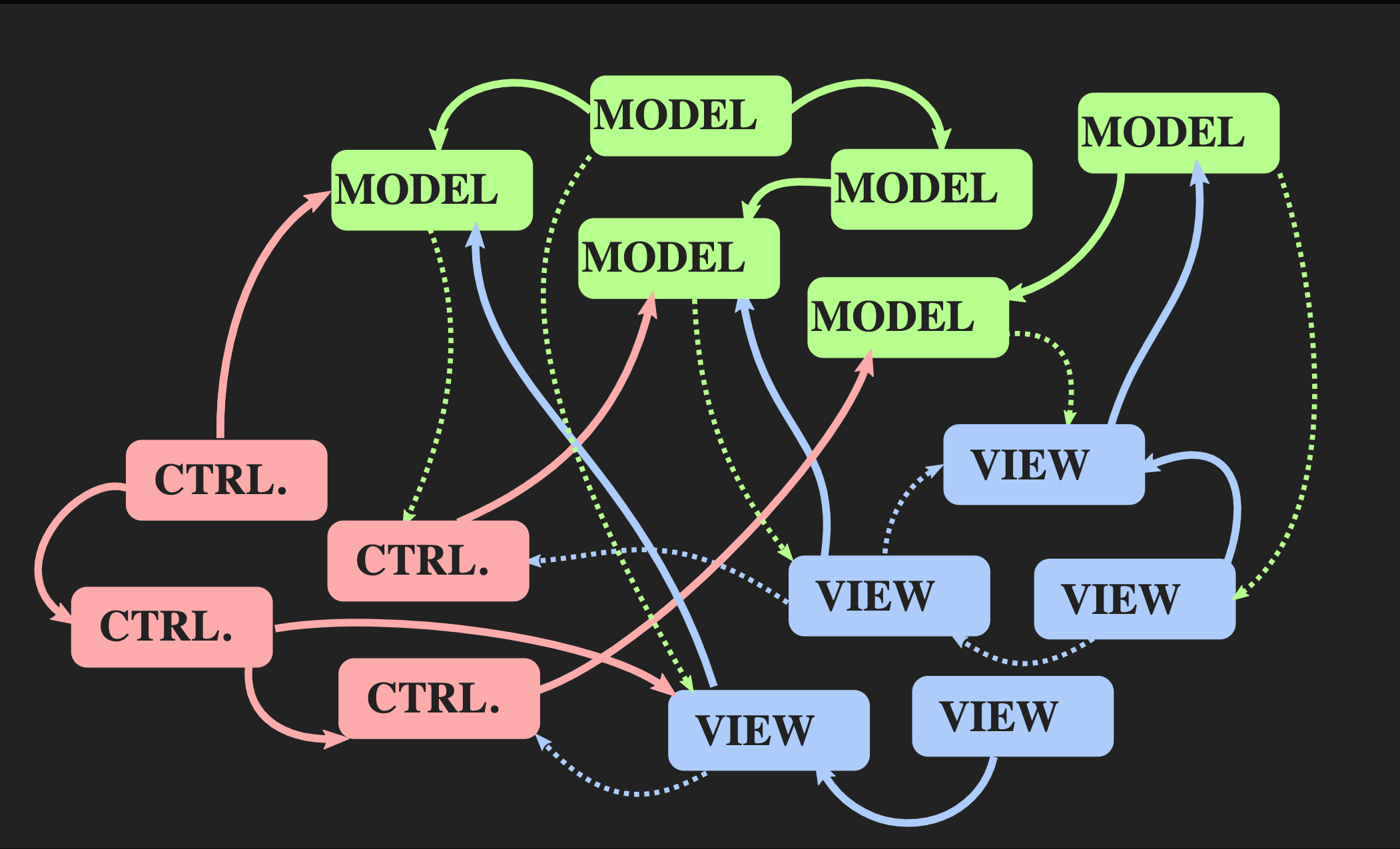
По мере роста приложения и добавления новых Model, Controller и View возникает ситуация, когда для изменения какого-либо сегмента программы необходимо знать о всех связанных с ним частях, обо всех View, которые получают оповещение через
callback, и т. д. В итоге за всеми этими зависимостями начинает проглядывать знакомый нам всем макаронный монстр.Возможна ли другая архитектура? Есть альтернативный подход к паттерну Model-View-Controller, который называется «Архитектура с однонаправленным потоком данных». Это понятие придумал не я, оно используется довольно часто в веб-разработке. В Facebook это называется архитектура Flux, но в С++ пока что она не применяется.
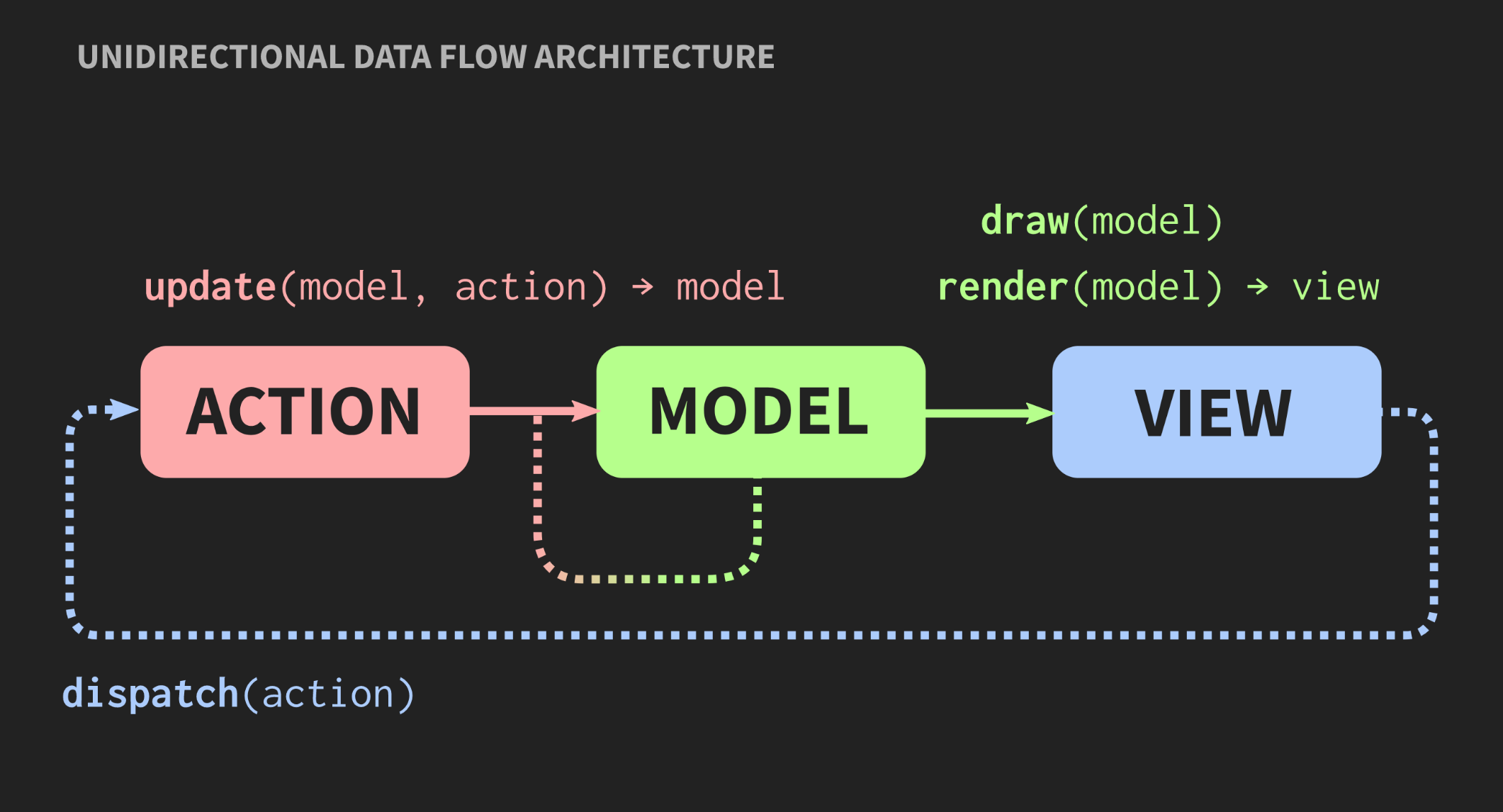
Элементы такой архитектуры нам уже знакомы: Action, Model и View, но значение блоков и стрелок другое. Блоки являются значениями, а не объектами и не участками с мутабельным состоянием. Это касается даже View. Далее, стрелки не являются ссылками, поскольку без объектов не может быть ссылок. Здесь стрелки — это функции. Между Action и Model существует функция update, которая принимает текущую Model, т. е. текущее состояние мира, и Action, которая является представлением некоторого события, например, щелчка мышкой, или события другого уровня абстракции, например, вставки элемента или символа в документ. Функция update обновляет документ и возвращает новое состояние мира. Model соединяется с View функцией render, который принимает Model и возвращает представление. Для этого требуется фреймворк, в котором можно представлять View в качестве значений.
При веб-разработке это делает React, но в С++ пока ничего подобного нет, хотя кто знает, если найдутся желающие заплатить мне, чтобы я написал нечто подобное, то может в скором времени и появится. Пока же можно пользоваться Immediate mode API, в которых функция draw позволяет создавать значение в качестве побочного эффекта.
Наконец, у View должен быть механизм, позволяющий пользователю или другим источникам событий отправлять Action. Существует простой способ это реализовать, он представлен ниже:
application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
За исключением асинхронного сохранения и загрузки это код, который используется в только что представленном редакторе. Здесь есть объект
terminal, который позволяет выполнять чтение и запись из командной строки. Далее, application — это значение Model, в нём сохраняется всё состояние приложения. Как видно вверху экрана, есть функция, которая возвращает новую версию application. Цикл внутри функции выполняется до тех пор, пока приложению не нужно будет закрыться, т. е. пока !state.done. В цикле происходит отрисовка нового состояния, затем выполняется запрос следующего события. Наконец, состояние сохраняется в локальной переменной state, и цикл запускается снова. У этого кода есть очень важное достоинство: лишь одна мутабельная переменная существует на протяжении всего выполнения программы, это объект state. Разработчики Clojure называют это одноатомной архитектурой (single-atom architecture): на всё приложение есть одна единственная точка, через которую выполняются все изменения. Логика приложения никак не участвует в обновлении этой точки, это делает специально для этого предназначенный цикл. Благодаря этому логика приложения целиком состоит из чистых функций, вроде функции
update.При таком подходе к написанию приложений меняется и образ мышления о софте. Работа теперь начинается не с UML-диаграммы интерфейсов и операций, а собственно с данных. Здесь есть некоторое сходство с data-oriented design. Правда, data-oriented design обычно используется с целью получения максимальной производительности, здесь же помимо скорости мы стремимся к простоте и правильности. Акцент немного другой, но есть важные сходства в методологии.
using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };Выше представлены основные типы данных нашего приложения. Основное тело приложения состоит из
line, которая является flex_vector, а flex_vector, это vector, для которого можно выполнять операцию объединения. Далее, text является вектором, в котором хранятся line. Как видим, это очень простое представление текста. Text сохраняется при помощи file, у которого есть имя, т. е. адрес в файловой системе, и собственно text. В file используется еще один тип, простой но очень полезный: box. Это контейнер на один элемент. Он позволяет поместить в кучу и перемещать объект, копирование которого может быть слишком ресурсозатратным.Другой важный тип:
snapshot. На основе этого типа действует функция отмены. В нём содержится документ (в виде text) и положение курсора (coord). Это позволяет возвращать курсор на то положение, в котором он был во время правки. Следующий тип —
buffer. Это термин из vim и emacs, так там называются открытые документы. В buffer есть файл, из которого был загружен текст, а также содержание текста — это позволяет проверять наличие изменений в документе. Для выделения части текста есть необязательная переменная selection_start, указывающая на начало выделения. Вектор из snapshot — это история текста. Заметьте, мы не используем паттерн Команда, история состоит только из состояний. Наконец, если только что была выполнена отмена, нам необходим индекс положения в истории состояний — history_pos. Следующий тип:
application. В нём содержится открытый документ (buffer), key_map и key_seq для комбинаций клавиш, а также вектор из text для буфера обмена и другой вектор для сообщений, отображаемых внизу экрана. Пока что в дебютной версии приложения будет только один поток и один тип действий, принимающий на вход key_code и coord.Скорее всего, многие из вас уже думают о том, как реализовать эти операции. Если принимать по значению и возвращать по значению, то в большинстве случаев операции довольно простые. Код моего текстового редактора выложен на github, так что вы можете посмотреть, как он в действительности выглядит. Сейчас же я подробно остановлюсь только на коде, реализующем функцию отмены.
Отмена
Правильно написать отмену без соответствующей инфраструктуры не так-то просто. В моём редакторе я реализовал её по образцу emacs, так что вначале пару слов об основных ее принципах. Команда возврата здесь отсутствует, и благодаря этому нельзя потерять работу. Если необходимо сделать возврат, в текст вносится любое изменение, и тогда все действия отмены становятся снова частью истории отмены.

Этот принцип изображен выше. Красный ромб здесь показывает позицию в истории: если только что не была выполнена отмена, красный ромб всегда в самом конце. Если выполнить отмену, ромб переместится на одно состояние назад, но одновременно в конец очереди добавится еще одно состояние — такое же, какое в данный момент видит пользователь (S3). Если выполнить отмену ещё раз и вернуться к состоянию S2, в конец очереди добавится состояние S2. Если теперь пользователь выполнит какое-то изменение, оно добавится в конец очереди как новое состояние S5, и на него будет перемещён ромб. Теперь при отмене прошлых действий вначале будут пролистаны прошлые действия отмены. Чтобы реализовать такую систему отмены, достаточно следующего кода:
buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Тут два действия,
record и undo. Record выполняется при любой операции. Это очень удобно, поскольку нам нет необходимости знать, произошло ли какое-либо редактирование документа. Функция прозрачна для логики приложения. После любого действия функция проверяет изменился ли документ. Если изменение произошло, выполняется push_back содержания и положения курсора для history. Если действие не привело к изменению history_pos (то есть полученные на вход buffer не вызваны действием отмены), то history_pos присваивается значение null. Если же необходимо выполнить undo, мы проверяем history_pos. Если у него нет значения, мы считаем, что history_pos находится в конце истории. Если история отмены не пуста (то есть history_pos не в самом начале истории), выполняется отмена. Текущие content и cursor заменяются, и изменяется history_pos. Неотменяемость операции отмены достигается функцией record, которая также вызывается при операции отмены. Итак, мы имеем операцию
undo, которая занимает 10 строк кода, и которую без изменений (или с минимальными изменениями) можно использовать практически в любом другом приложении.Путешествия во времени
О путешествиях во времени. Как мы сейчас увидим, это тема, связанная с отменой. Я продемонстрирую работу фреймворка, который добавит полезную функциональность любому приложению с похожей архитектурой. Фреймворк здесь называется ewig-debug. В этой версии ewig включены некоторые возможности отладки. Сейчас из браузера можно открыть отладчик, в котором можно исследовать состояние приложения.

Мы видим, что последним действием было изменение размера, поскольку я открыл новое окно, и мой диспетчер окон автоматически поменял размер уже открытого окна. Конечно, для автоматической сериализации в JSON мне пришлось добавить аннотацию для struct из специальной библиотеки reflection. Но в остальном система вполне универсальная, её можно подключить к любому подобному приложению. Теперь в браузере можно увидеть всё совершённые действия. Конечно, есть и начальное состояние, у которого нет действия. Это состояние, которое было до выполнения загрузки. Больше того, двойным щелчком мыши я могу возвратить приложение к предыдущему состоянию. Это очень полезный инструмент отладки, который позволяет отследить возникновение неисправности в приложении.
Если вам интересно, то можете послушать мой доклад на CPPCON 19, The most valuable values, там я в подробностях рассматриваю этот отладчик.
Кроме того, там подробнее обсуждается архитектура, основанная на значениях. В нём я также рассказываю, как следует реализовывать действия и организовывать их иерархически. Это обеспечивает модульность системы и позволяет не держать всё в одной большой функции update. Кроме того, в том докладе говорится об асинхронности и о многопоточной загрузке файла. Есть ещё одна версия этого доклада, в которой полчаса дополнительного материала — Postmodern immutable data structures.
Подведем итоги
Думаю, пришло время подвести итоги. Приведу цитату Энди Винго (Andy Wingo) — он отличный разработчик, посвятил много времени V8 и компиляторам в целом, наконец, он занимается поддержкой Guile, реализацией Scheme для GNU. Недавно он написал в своём твиттере: «Чтобы добиться небольшого ускорения работы программы, мы измеряем каждое небольшое изменение и оставляем только те, которые дают положительный результат. А действительно существенного ускорения мы добиваемся, вслепую, вкладывая большие усилия, не имея 100%-й уверенности и руководствуясь только интуицией. Какая странная дихотомия».
Мне кажется, что разработчики на С++ преуспевают именно в первом жанре. Дайте нам закрытую систему, и мы, вооружившись нашими инструментами, выжмем из неё всё, что можно. Но вот во втором жанре мы работать не привыкли. Конечно, второй подход более рискованный, и зачастую он приводит к пустой трате больших усилий. С другой стороны, полностью переписав программу, её часто можно сделать и проще, и быстрее. Надеюсь, мне удалось убедить вас хотя бы попробовать этот второй подход.
Juan Puente выступил на конференции C++ Russia 2019 Moscow и рассказал о структурах данных, которые позволяют делать интересные вещи. Часть магии этих структур кроется в сopy elision — именно об этом на грядущей конференции расскажут Антон Полухин и Роман Русяев. За обновлениями программы следите на сайте.
