Привет! Это вторая часть статьи, в которой мы будем разбирать практическое применение платформы Graylog.
В первой части мы разобрали как платформу установить и произвести ее базовую настройку, а сегодня рассмотрим пару примеров применения ее возможностей на практике.
В частности, разберем настройку сбора логов с веб-сервера и возможность визуализировать полученные данные.
Настраиваем сбор логов с сервера
Работаем в web-интерфейсе:

Начнем со сбора syslog
Создаём UDP Input для системных логов:
System/Overview → Inputs
Выбираем тип Input-а:
Select input → Syslog UDP
(Будем использовать UDP, но если кому-то удобнее использовать tcp - почему бы и да)
Нажимаем кнопку Launch new input.
Title: SyslogUDP
Bind address: 0.0.0.0
Port: 10514Внимание!
Порты меньше чем 1024 использовать можно только через костыли, поэтому будем использовать 10514:
http://docs.graylog.org/en/2.4/pages/faq.html#how-can-i-start-an-input-on-a-port-below-1024
Остальные значения можно оставить по умолчанию:
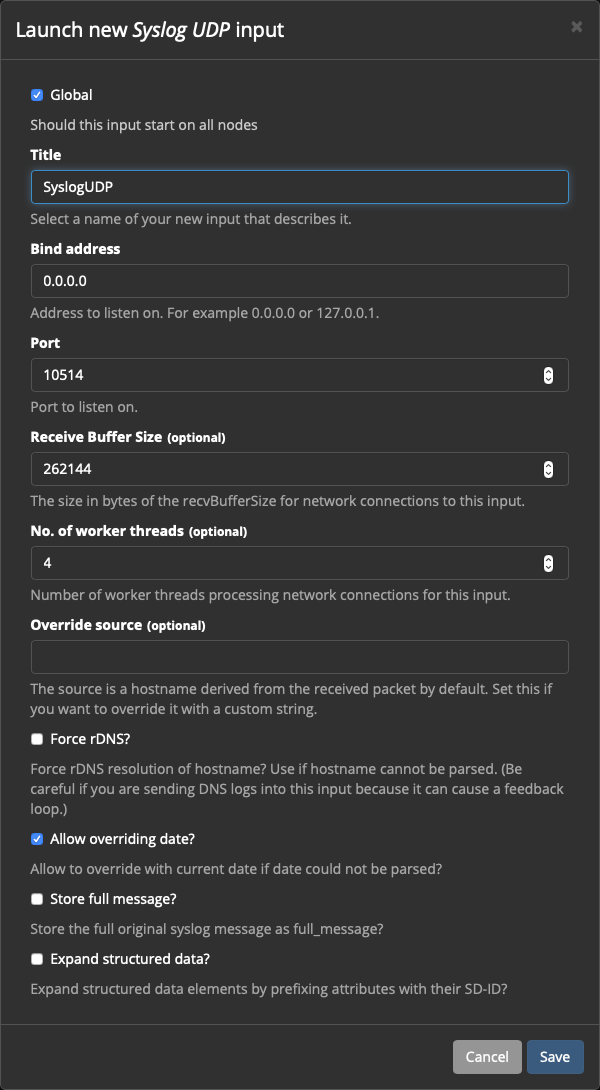
Сохраняем конфигурацию, получаем работающий Input:
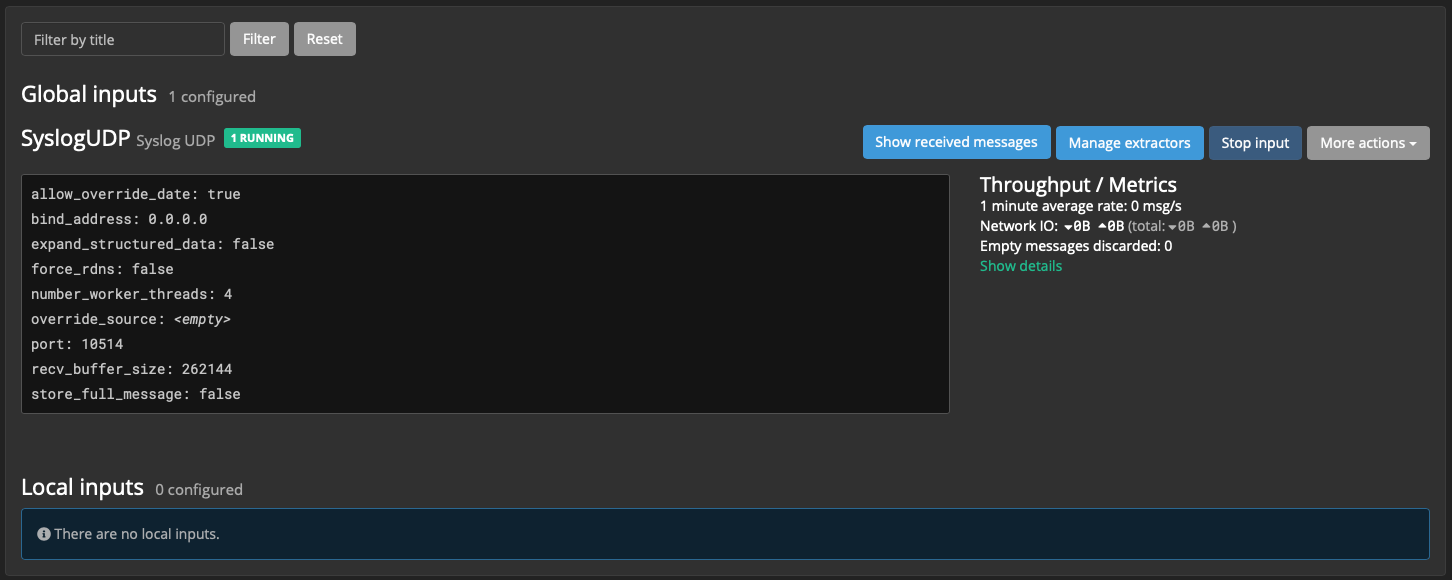
Для проверки работы Input выполним со своей рабочей станции или с любого другого хоста с linux/mac:
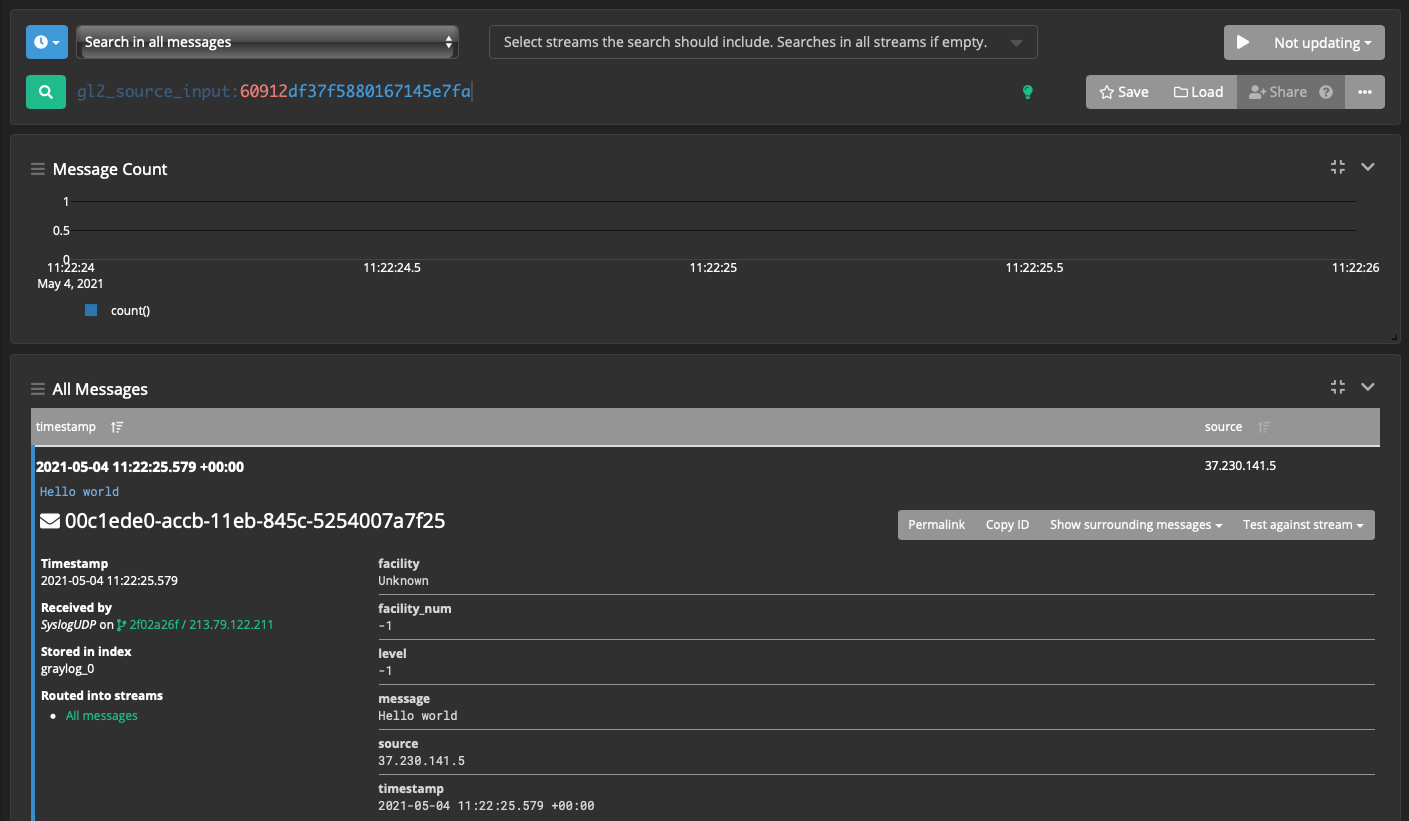
$ echo "Hello world" | nc -w 1 -u graylog.itsft.ru 10514Переходим в веб-интерфейсе Show received messages, видим полученное сообщение.
Настройки для сервера с которого собираем логи:
Уменьшаем количество логов
В CentOS 7 в /var/log/messages, как правило видим много спама, примерно такого:
May 1 11:01:01 localhost systemd: Created slice User Slice of root.
May 1 11:01:01 localhost systemd: Started Session 541 of user root.
May 1 11:01:01 localhost systemd: Removed slice User Slice of root.Данные сообщения не несут для нас полезной информации, можем их отключить:
# vim /etc/rsyslog.d/ignore-systemd-session-slice.conf
if $programname == "systemd" and ($msg contains "Starting Session" or $msg contains "Started Session" or $msg contains "Created slice" or $msg contains "Starting user-" or $msg contains "Starting User Slice of" or $msg contains "Removed session" or $msg contains "Removed slice User Slice of" or $msg contains "Stopping User Slice of") then
stopПередаём логи в Graylog:
# vim /etc/rsyslog.d/90-graylog2.confЕсли передаём данные по UDP, как сейчас настроено в инпуте Graylog-а:
*.* @11.22.33.44:10514;RSYSLOG_SyslogProtocol23FormatНо если нужно по TCP, добавляем ещё одну “@”:
*.* @@11.22.33.44:10514;RSYSLOG_SyslogProtocol23FormatПосле редактирования делаем рестарт сервиса:
# systemctl restart rsyslog.serviceПроверяем наличие данных от хоста в Graylog-е.
На этом настройку сбора syslog считаем завершённой. На случай чрезвычайных ситуаций, или просто для информации, полезны будут оповещения о событиях (ошибках дисков, нехватке памяти, логинах, etc).
Настраиваем оповещения
Для примера - отловим приход oom-killer-а c уведомлением в Slack:
Alerts → Alerts & Events → Get Started!
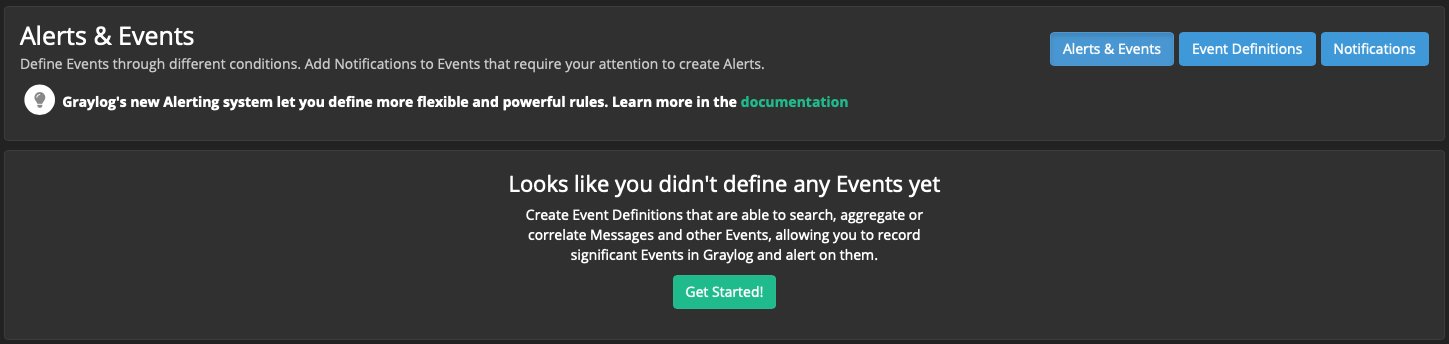

Шаг 1: “Event Details”:
Title: oom-killer invoked
Description (Optional): oom-killer was invoked on server or virtual machine
Priority: Normal
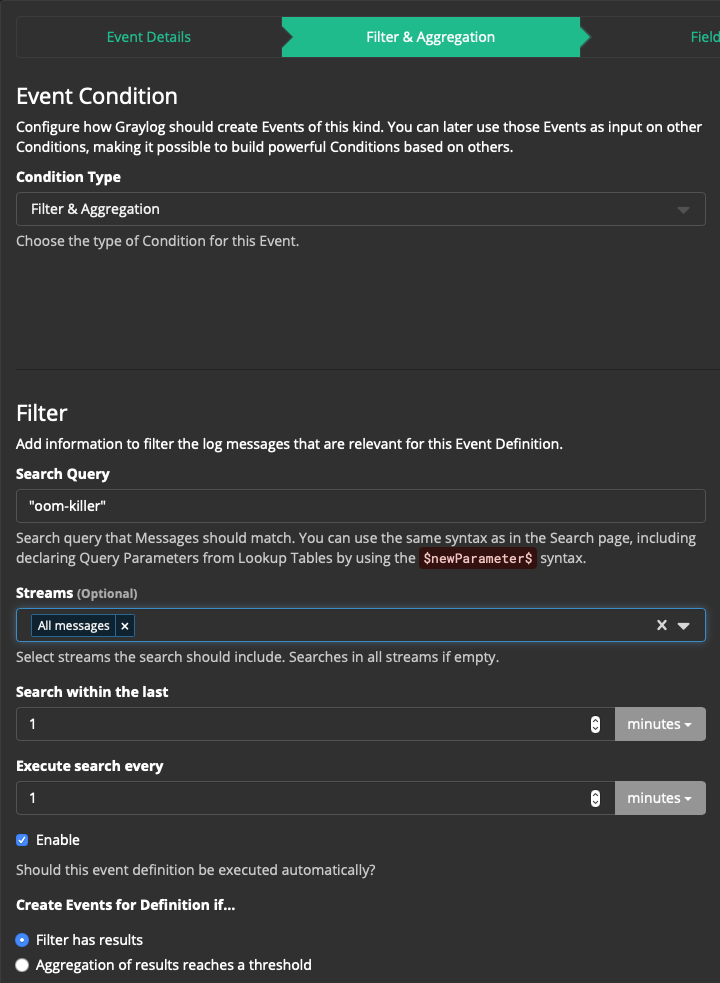
Шаг 2: “Filter & Aggregation”:
Condition Type: Filter & Aggregation
Search Query: "oom-killer"
(Тут правила построения запроса)
Streams (Optional): All messages
Search within the last: 10 minutes
Execute search every: 10 minutes
Устанавливаем чекбокс Enable
Create Events for Definition if… Filter has results
Если в логах уже есть такое событие, можно будет наблюдать его в Filter preview.
Шаг 3: "Fields" - не используем.
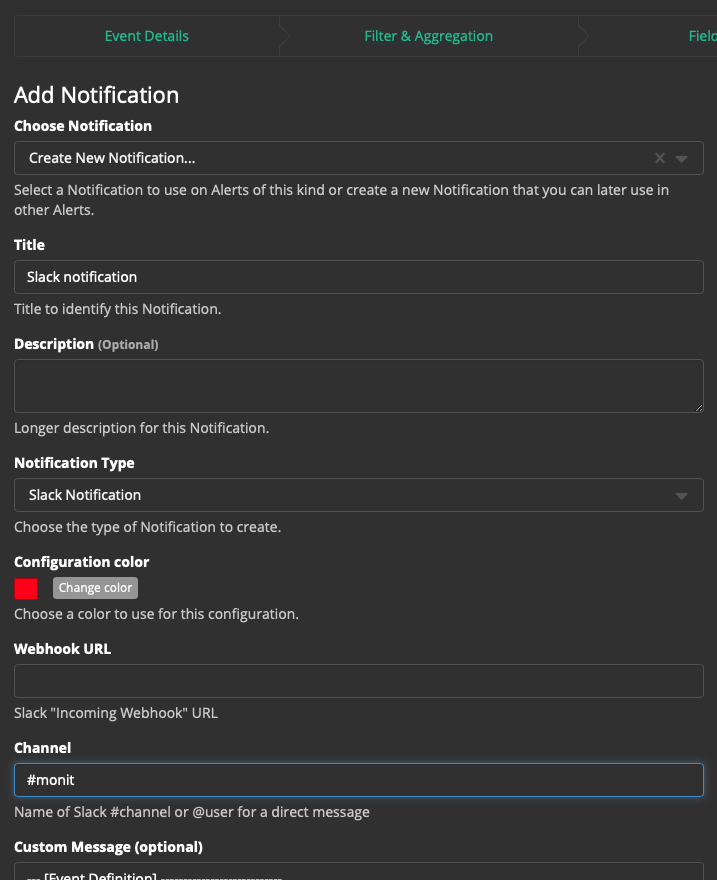
Шаг 4: "Notifications" → Add Notification:
Choose Notification: Create New Notification...
Title: Slack notification
Notification Type: Slack Notification
Configuration Color: можно выбрать цвет
Webhook URL: Выглядит как https://hooks.slack.com/services/aaa/bbb123 - можно создать его в настройках Slack.
Channel: #monit (в какой канал будут приходить данные уведомления).
Custom Message (optional): можно выбрать какие поля оставляем в сообщении.
Остальные настройки можно оставить по умолчанию.
Нажимаем кнопку Execute test notification, контролируем доставку сообщения в указанный канал Slack-а, и если всё работает - нажимаем кнопку Done.
В Notification Settings ничего изменять не будем:
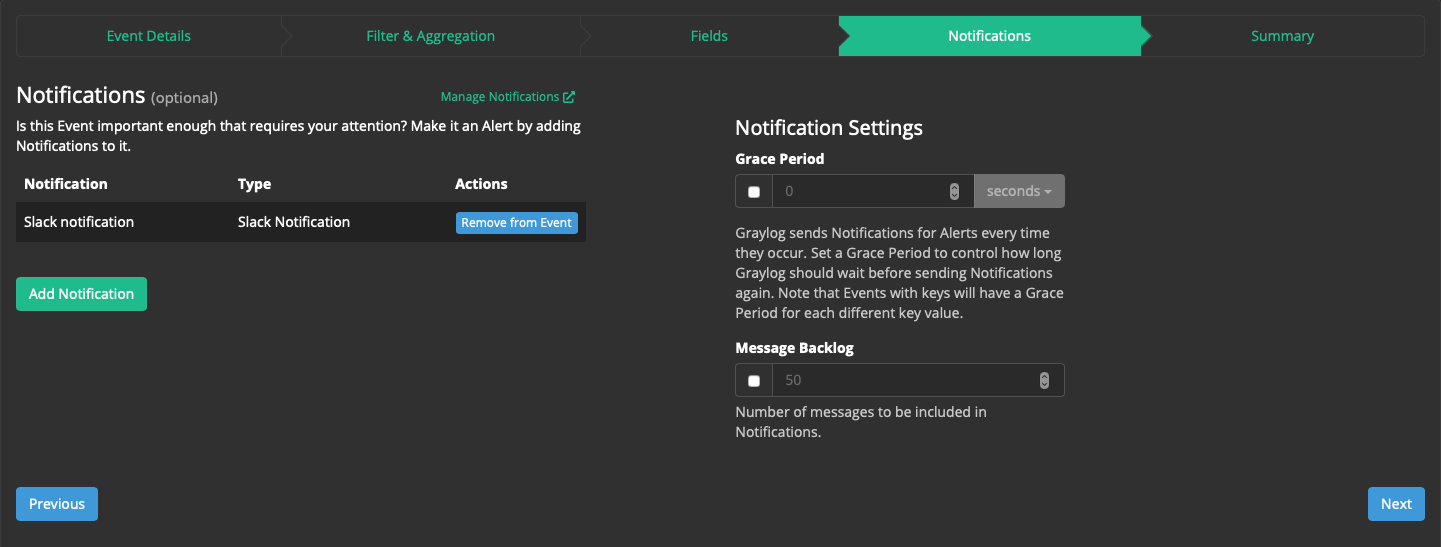
Шаг 5: "Summary": Ещё раз удостоверимся что настройки верны.
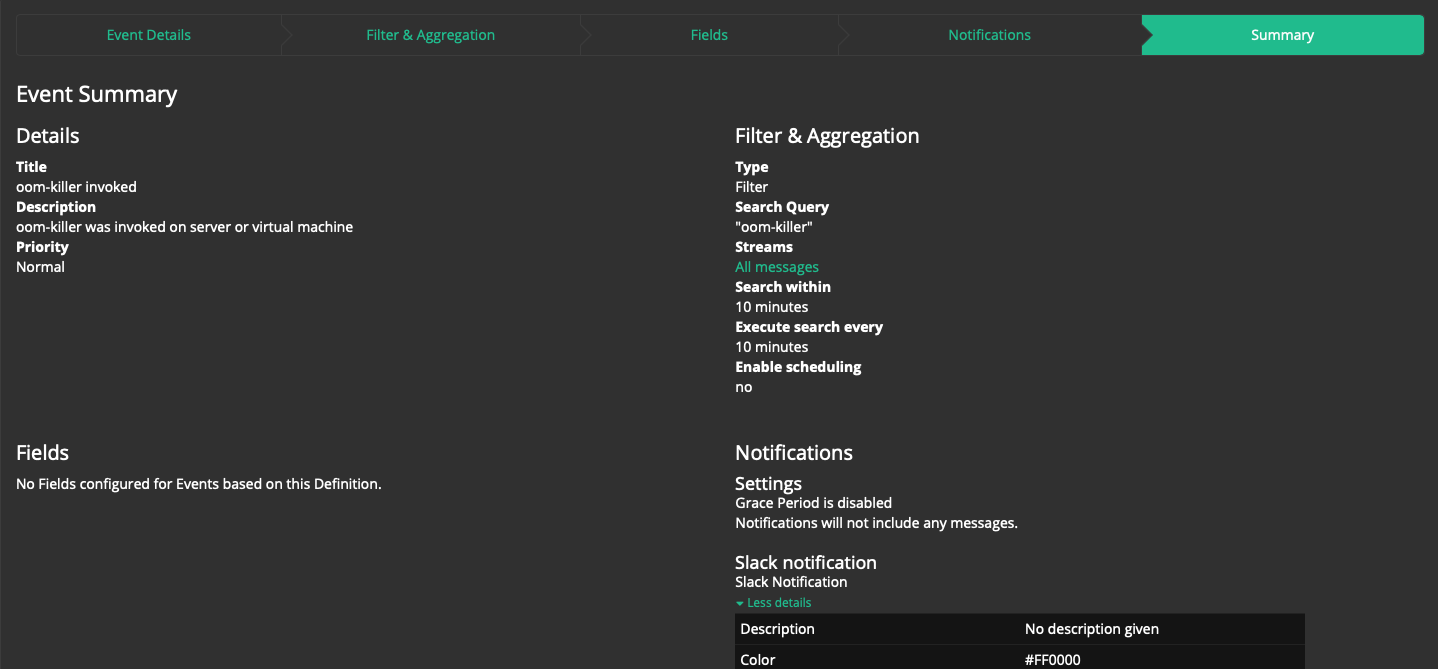
Нажимаем Done.
Тестируем оповещение. На хосте, с которого собираем syslog пишем маленькую программку на С:
# vi memtest1.c
#include <stdio.h>
#include <stdlib.h>
int main (void) {
int n = 0;
while (1) {
if (malloc(1<<20) == NULL) {
printf("malloc failure after %d MiB\n", n);
return 0;
}
printf ("got %d MiB\n", ++n);
}
}Компилируем и запускаем. Скрипт занимает всю доступную память, после чего приходит oom-killer и его убивает:
# gcc memtest1.c
# ./a.out
got 1 MiB
...
got 94372 MiB
KilledВ /var/log/messages можем наблюдать данный процесс:
May 4 17:24:50 docker kernel: Out of memory: Kill process 23219 (a.out) score 831 or sacrifice child
May 4 17:24:50 docker kernel: Killed process 23219 (a.out), UID 0, total-vm:659692616kB, anon-rss:2181712kB, file-rss:0kB, shmem-rss:0kB
May 4 17:27:19 docker kernel: dockerd-current invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=-500
May 4 17:27:19 docker kernel: dockerd-current cpuset=/ mems_allowed=0
May 4 17:27:19 docker kernel: CPU: 1 PID: 18617 Comm: dockerd-current Kdump: loaded Tainted: G ------------ T 3.10.0-1160.21.1.el7.x86_64 #1
May 4 17:27:19 docker kernel: Hardware name: Red Hat KVM, BIOS 1.11.0-2.el7 04/01/2014В Slack видим оповещение о событии (здесь сообщение стандартное, по умолчанию, но его можно кастомизировать под ваши требования):

Graylog Sidecar
Graylog может собирать также логи сервисов, и вообще практически любые логи.
Будем использовать Graylog Sidecar для управления конфигурацией и бэкенд Filebeat, который собирает события и отправляет на Graylog-сервер. Схема работы для данного кейса:
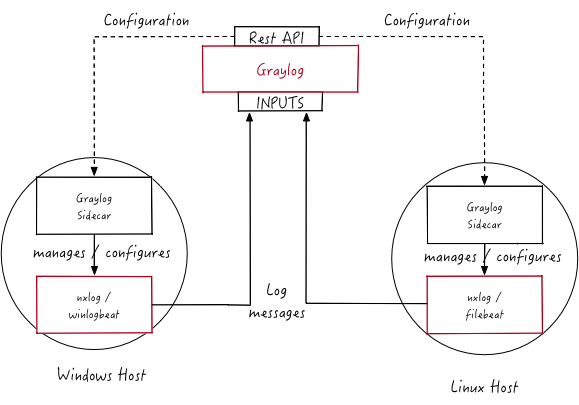
Мы будем работать с access-логами веб-сервера nginx, работающего под CentOS linux.
PS:
Готовые контент-паки для различных сервисов (apache, nginx, …) различной степени свежести есть тут.
Но, чтобы разобраться как всё работает мы пойдём своим путём.
Получаем токен
System → Sidecars:
Нажимаем на ссылку:
Do you need an API token for a sidecar? Create or reuse a token for the graylog-sidecar user

Ранее созданные токены также можно найти по этой ссылке.
Вводим имя токена:
Token Name: myToken
Нажимаем кнопку Create Token
Там же можно скопировать его в буфер обмена, если нужно кнопкой Copy to clipboard, предварительно убрав чекбокс Hide Tokens.

System → Inputs:
Выбираем тип инпута Beats, жмём Launch New Input
Настройка в данном случае практически не отличается от той, что делали для syslog
Устанавливаем чекбокс Global:
Title: graylog-sidecar
Bind address: 0.0.0.0
Port: 5044
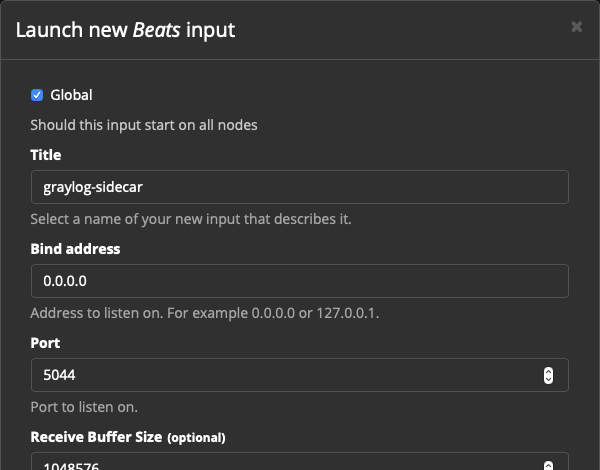
Остальное оставляем по умолчанию (разумеется, в продакшн-среде, особенно при передаче сенситивных данных нужно будет добавить SSL-сертификаты, но пока обойдемся без них).
Нажимаем кнопку Save.
Не забываем добавить правило для 5044/tcp в Firewall.
Также нужен будет 443-й порт, но он у нас уже должен быть открыт:
# firewall-cmd --permanent --zone=itsoft --add-port=5044/tcp
# firewall-cmd --reloadSystem → Sidecars → Configuration
В секции Configuration нажимаем кнопку Create Configuration:

Name: filebeat_conf
Configuration color: можно выбрать желаемый цвет
collector: filebeat on linux
Configuration редактируем следующим образом
(paths - путь, где лежат лог-файлы сервиса,
hosts - ip-адрес и порт graylog-сервера):
# Needed for Graylog
fields_under_root: true
fields.collector_node_id: ${sidecar.nodeName}
fields.gl2_source_collector: ${sidecar.nodeId}
filebeat.inputs:
- input_type: log
paths:
- /var/log/nginx/access.log
type: log
output.logstash:
hosts: ["213.79.122.211:5044"]
path:
data: /var/lib/graylog-sidecar/collectors/filebeat/data
logs: /var/lib/graylog-sidecar/collectors/filebeat/logНажимаем кнопку Create:

Далее необходимо установить менеджер конфигурации и коллектор на хосте, с которого будет производиться сбор логов:
Sidecar
# rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-sidecar-repository-1-2.noarch.rpm
# yum -y install graylog-sidecar
# vim /etc/graylog/sidecar/sidecar.ymlОбязательно, вносим в файл конфигурации строки:
server_url: "https://graylog.itsft.ru/api/"
server_api_token: "1m6dk8vu3dk6uim9nbvmk1nkup4mvak2mrjfbtom3kgdafg2ms49"
# graylog-sidecar -service install
# systemctl enable graylog-sidecar.service
# systemctl start graylog-sidecar.service
# systemctl status graylog-sidecar.service
● graylog-sidecar.service - Wrapper service for Graylog controlled collector
Loaded: loaded (/etc/systemd/system/graylog-sidecar.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-05-05 11:11:20 MSK; 6s agoПолезная информация:
https://graylog.itsft.ru/api/api-browser - REST API Browser
filebeat
# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
# vim /etc/yum.repos.d/elastic.repo
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum -y install filebeat
# systemctl enable filebeat.service
# systemctl start filebeat.service
# systemctl status filebeat.service
● filebeat.service - Filebeat sends log files to Logstash or directly to Elasticsearch.
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-05-05 12:16:37 MSK; 6s agoНе забываем про правило firewall с соответствующим портом, если это необходимо:
# firewall-cmd --zone=itsoft --add-ports=5044/udp
# firewall-cmd --runtime-to-permanentТеперь Sidecar должен быть виден в System → Sidecars → Overview
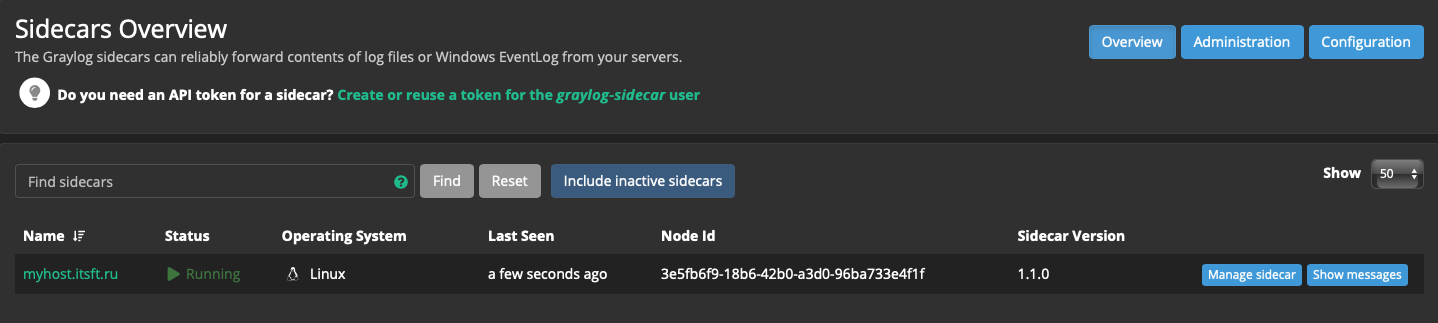
Назначим созданную конфигурацию на этот Sidecar.
Нажимаем кнопку Administration:

filebeat → Configure → выбираем нужную конфигурацию:

В открывшемся поп-апе подтверждаем, что всё верно → Confirm:
Контролируем статус - Running.
Идём в System → Inputs, на инпуте graylog-sidecar нажимаем Show received messages,
наблюдаем логи nginx:
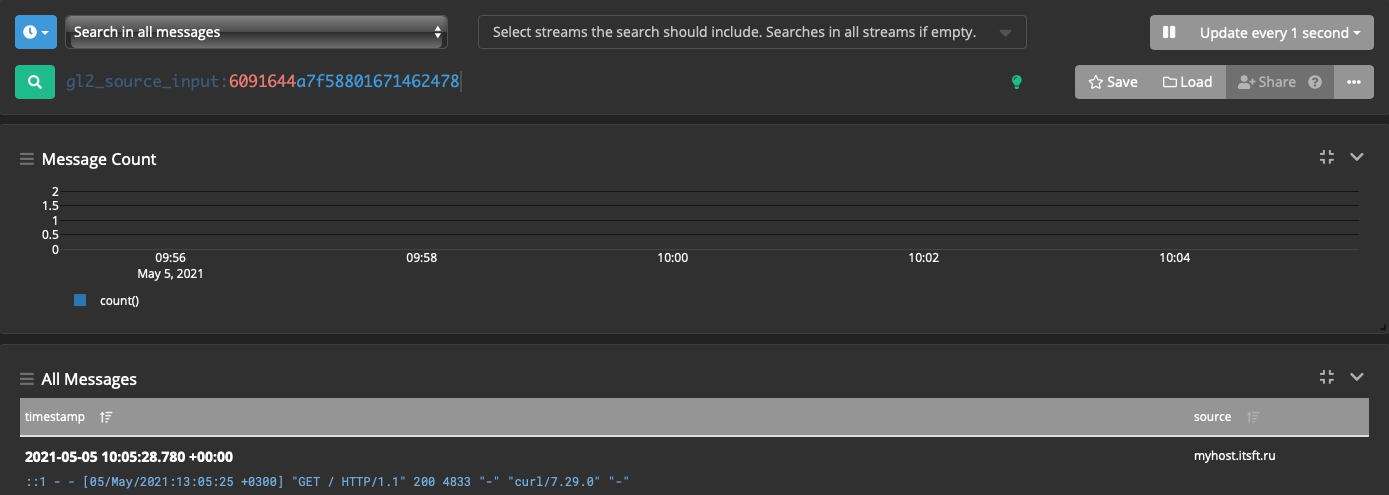
Extractor
Полезные ссылки:
Просто хранение лога - не та задача к которой мы шли. Нам нужно парсить и анализировать эти логи!
Настраиваем экстрактор:
System → Inputs → Manage extractors
В секции Add extractor нажимаем единственную кнопку - Get started
Выбираем нужный Sidecar, затем нажимаем кнопку Load Message
Recent message выбирает последнее пришедшее сообщение, но удобнее выбрать нужное сообщение по message_id и index.

Парсить будем само сообщение:
На поле message нажимаем Select extractor type → Grok pattern

Лог nginx по умолчанию имеет формат (можем найти его в nginx.conf):
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';Grok pattern будет выглядеть так:
%{IP:remote_addr} - - \[%{HTTPDATE:time_local;date;dd/MMM/yyyy:HH:mm:ss Z}\] \"%{NOTSPACE:request_method} %{DATA:request_uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status_code} %{NUMBER:body_bytes_sent} %{QS:http_referrer} %{QS:http_user_agent} %{QS:http_x_forwarded_for}Нажимаем Try against example и в Extractor preview проверяем правильность паттерна:
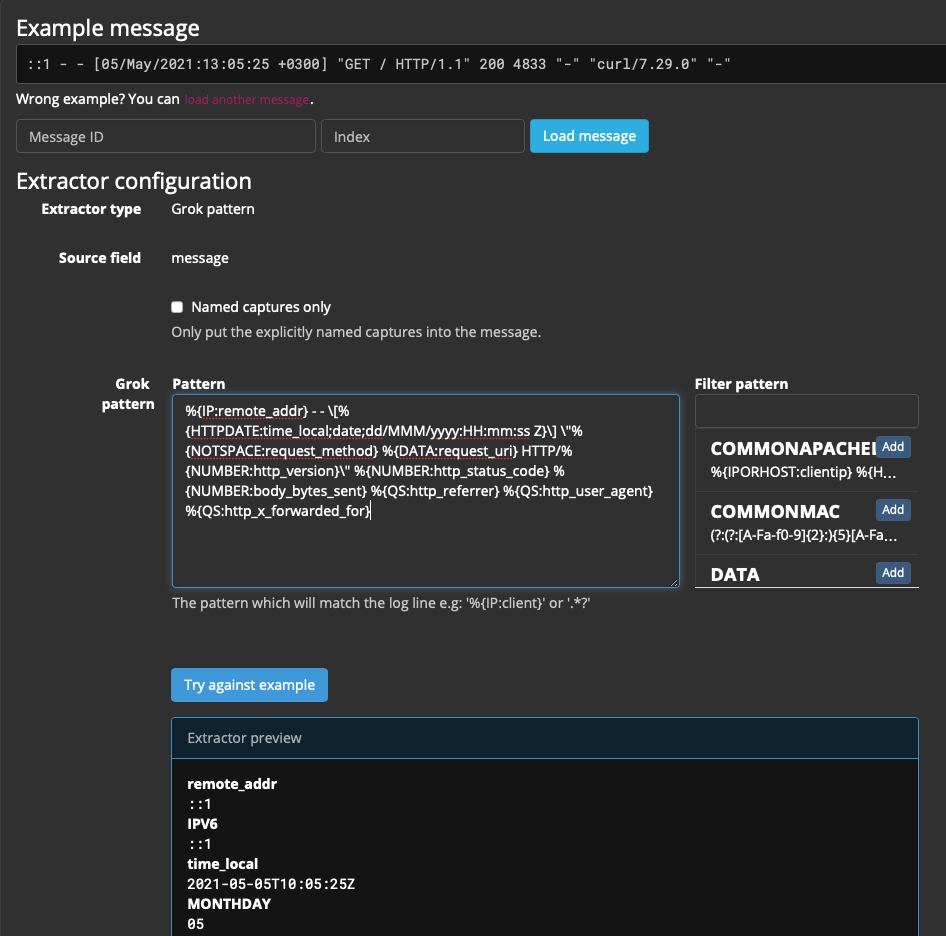
Остальные параметры можно оставить по умолчанию, только имя нужно будет указать:
Condition: Always try to extract
Extraction strategy: Copy
Extractor title: nginx combined
Нажимаем Create extractor
Переходим в меню System → Inputs → Show received messages, в инпуте graylog-sidecar.
Теперь все новые логи будут содержать отдельные поля message:
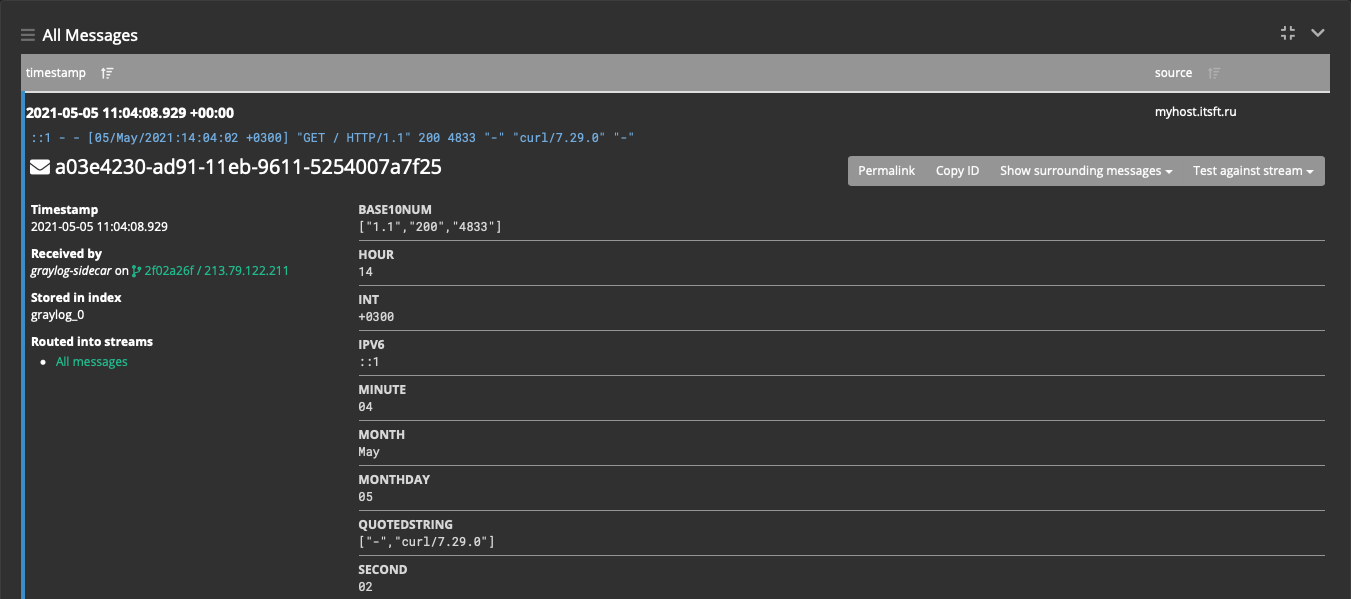
Поиск по логам стал намного проще, например:
gl2_source_input:6091644a7f58801671462478 - все сообщения с данного инпута;
gl2_source_input:6091644a7f58801671462478 AND request_method:POST - все сообщения с методом POST;
gl2_source_input:6091644a7f58801671462478 AND NOT http_status_code:200 - не 200-й ответ.
При составлении запроса Graylog подсказывает параметры, что довольно удобно:

Также будет полезно создать Stream (поток).
Он нам нужен будет в дальнейшем:
Streams → Create stream
Title: Sidecars
Description: Nginx access logs
Index Set: Default index set
Сохраняем кнопкой Save

Stream создан, но пока неактивен.
Добавляем правило для этого потока (кнопка Manage Rules):
Выбираем нужный Input, создаём правило (кнопка Add stream rule).
В поп-апе New Stream Rule:
Требуется все сообщения из Sidecar-а поместить в этот поток, поэтому:
Type: match input
Value: graylog-sidecar
Сохраняем кнопкой Save.
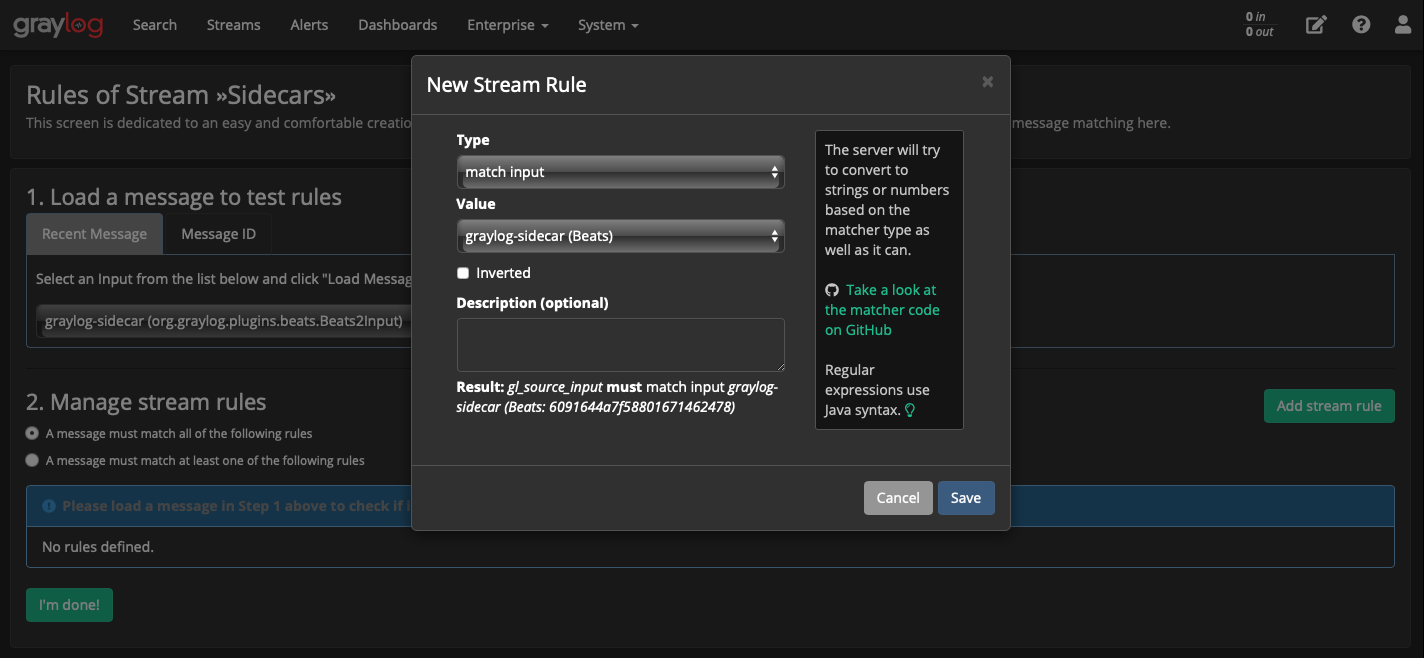
Правило добавлено, сохраняем кнопкой I’m done!:
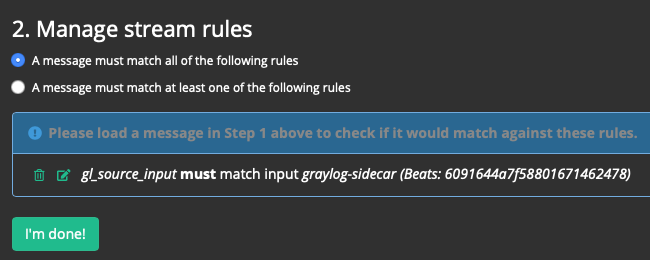
Запускаем поток: Start stream.
Нажав на имя потока Sidecars можем также просматривать сообщения в нём и производить поиск по этим сообщениям.
Немного бесполезного, но красивого
На этапе установки, в первой части статьи мы прикрутили к graylog-у базу geoip.
Теперь посмотрим, как её использовать, а также выведем карту мира, визуально демонстрирующую, откуда к нам на сайт приходят посетители.
Создаём data adapter
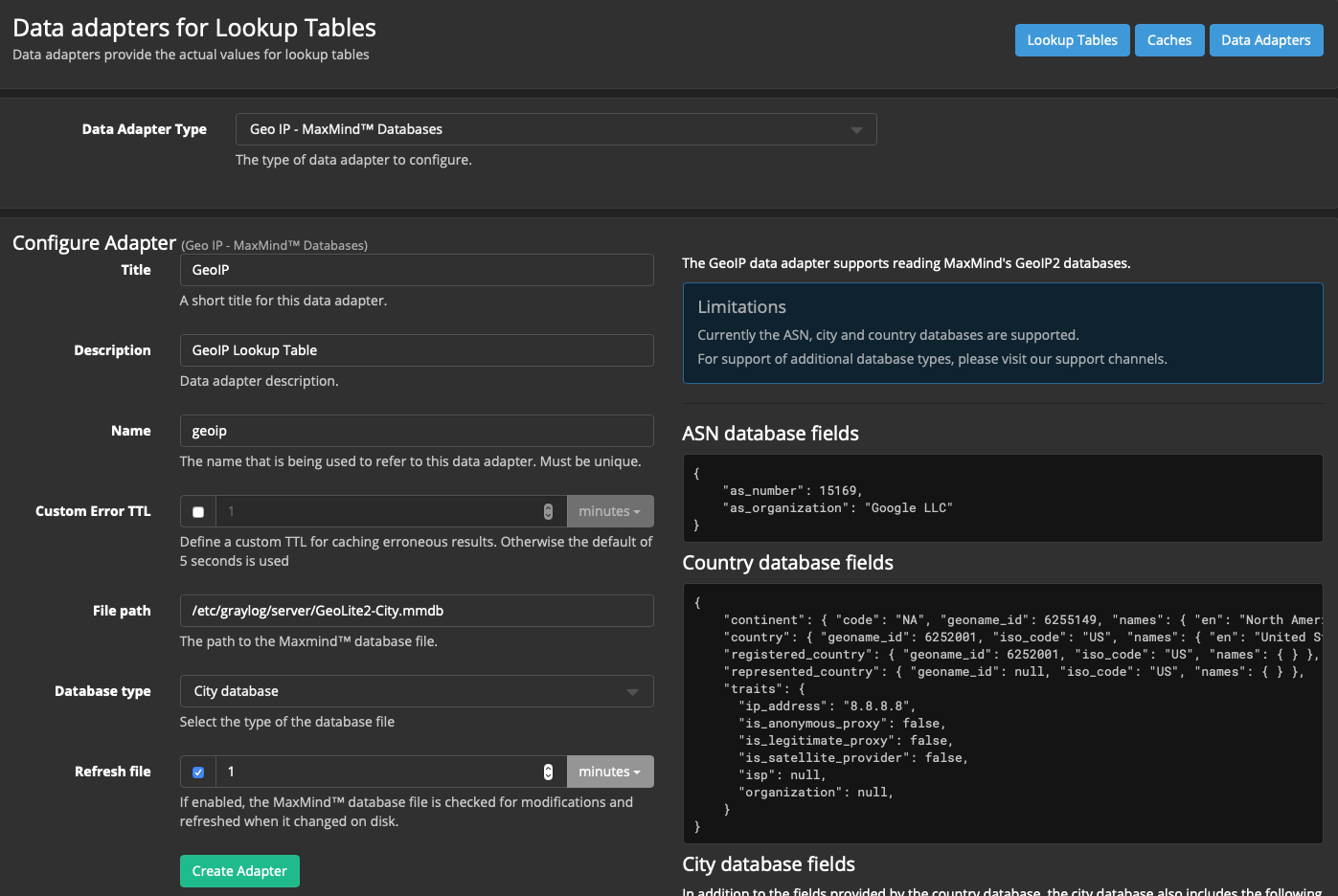
System → Lookup Tables → кнопка Data Adapters → Create data adapter:
Data adapter type → Geo IP - MaxMindTM Databases

Title: GeoIP
Description: GeoIP Lookup Table
Name: geoip
File Path: /etc/graylog/server/GeoLite2-City.mmdb
Database type: City database
Остальное по умолчанию.
Для завершения нажимаем кнопку Create adapter.
Когда результаты кешируются - всё становится лучше
Создаём Caches:
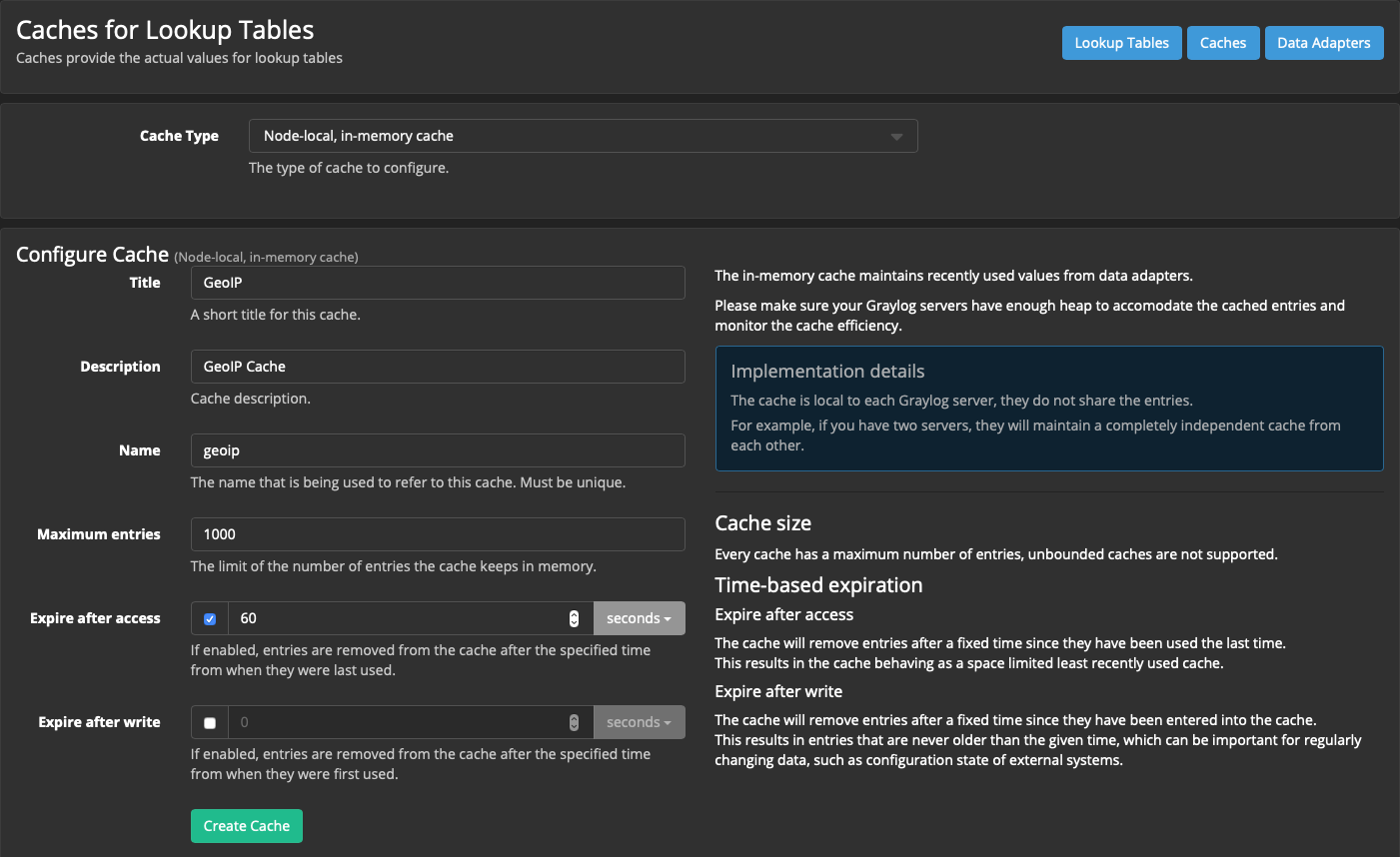
System → Lookup Tables → кнопка Caches → кнопка Create cache

Cache Type: Node-local, in-memory cache
Title: GeoIP
Description: GeoIP Cache
Name: geoip
Остальное можно оставить по умолчанию.
Нажимаем кнопку Create Cache:
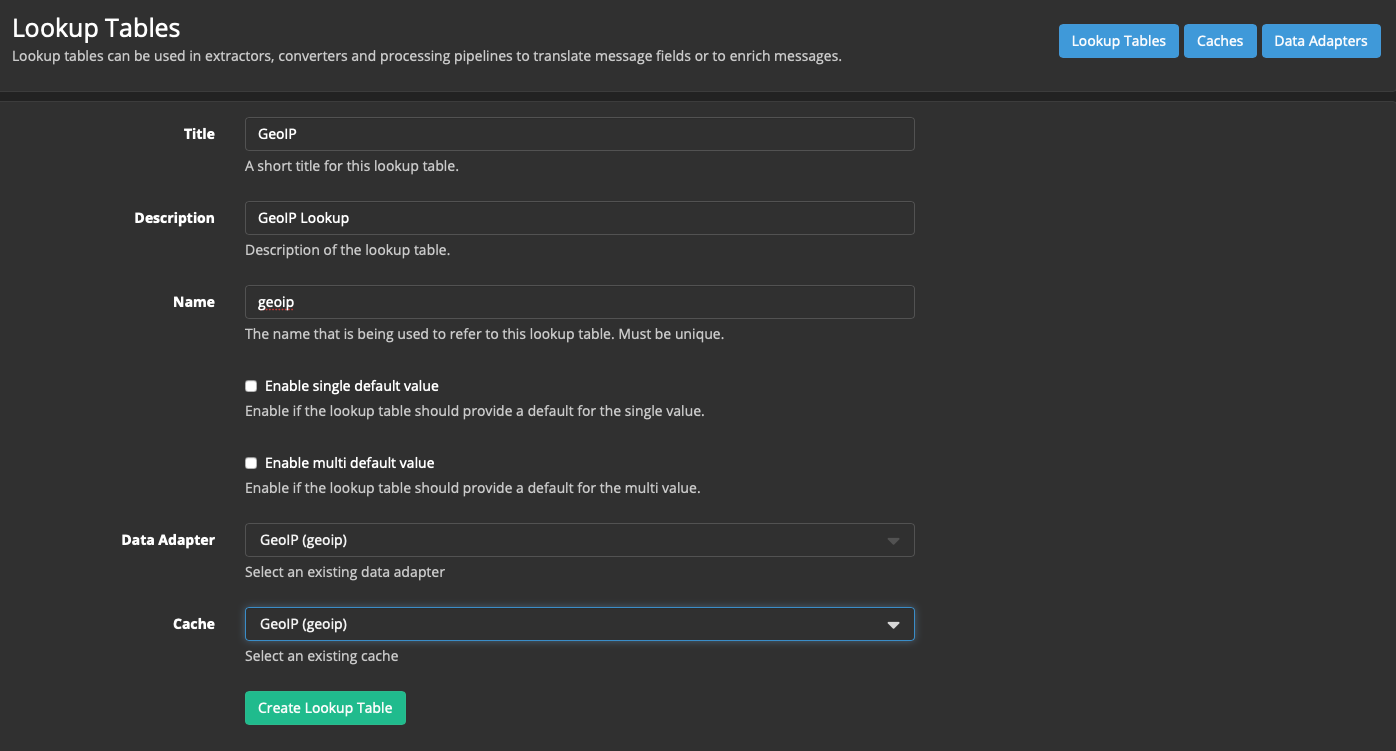
Создаём Lookup table:
System → Lookup Tables → Lookup Tables (активна по умолчанию) → Create Lookup Table

Title: GeoIP
Description: GeoIP Lookup
Name: geoip
Data Adapter: GeoIP (geoip)
Cache: GeoIP (geoip)
Нажимаем кнопку Create Lookup Table:
Создаём Pipeline (пайплайны позволяют обрабатывать сообщения из потоков):
Сначала правило:
System → Pipelines → кнопка Manage rules → кнопка Create Rule
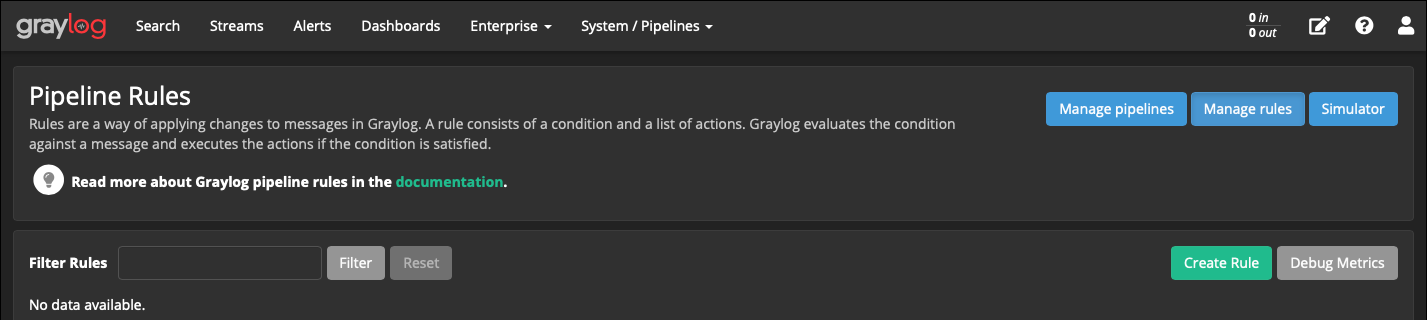
Description: Incoming connections
Rule source:
rule "GeoIP lookup: remote_addr"
when
has_field("remote_addr")
then
let geo = lookup("geoip", to_string($message.remote_addr));
set_field("remote_addr_geo_location", geo["coordinates"]);
set_field("remote_addr_geo_country", geo["country"].iso_code);
set_field("remote_addr_geo_city", geo["city"].names.en);
endНажимаем кнопку Save&Close.
Теперь пайплайн:
System → Pipelines → кнопка Manage pipelines → кнопка Add new pipeline
Title: Web
Description: Incoming connections
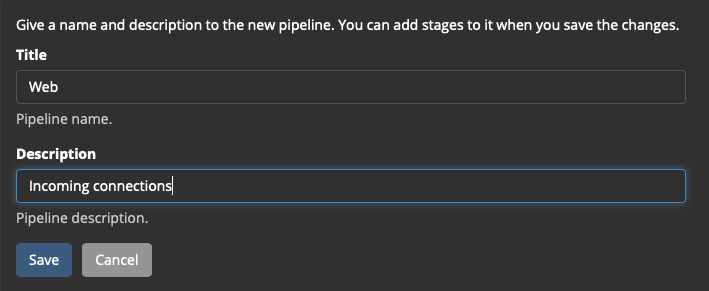
Наблюдаем сообщение, что только что созданный пайплайн не подключен ни к одному потоку:
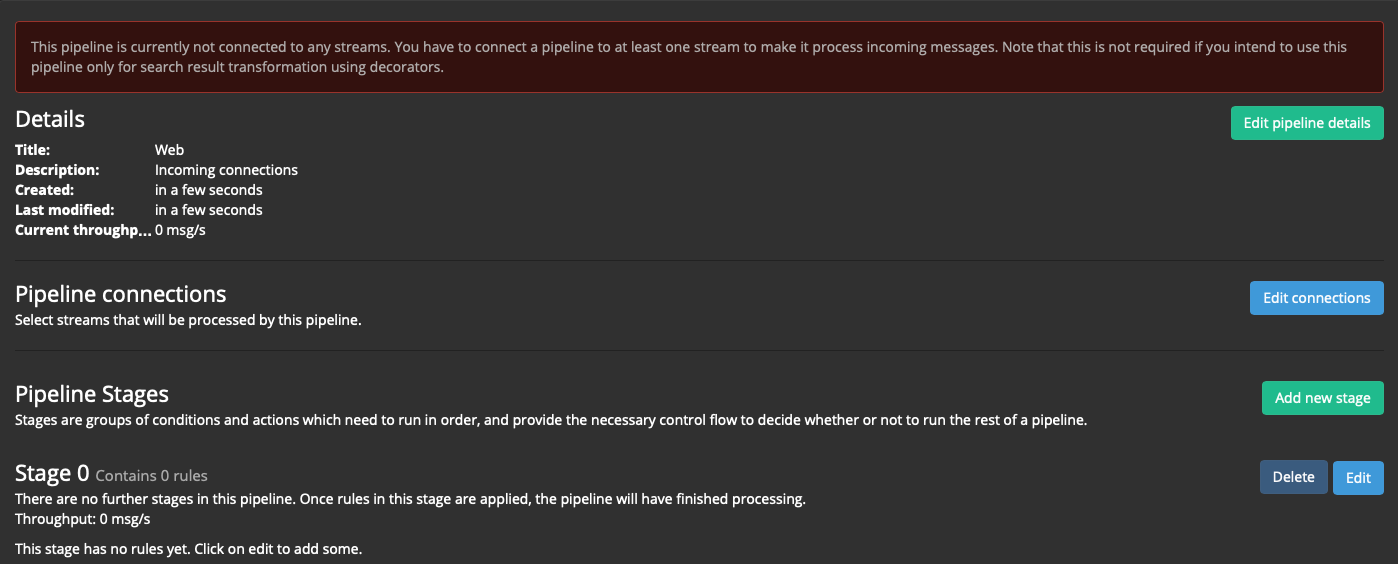
Нажимаем кнопку Edit connections, подключаем:
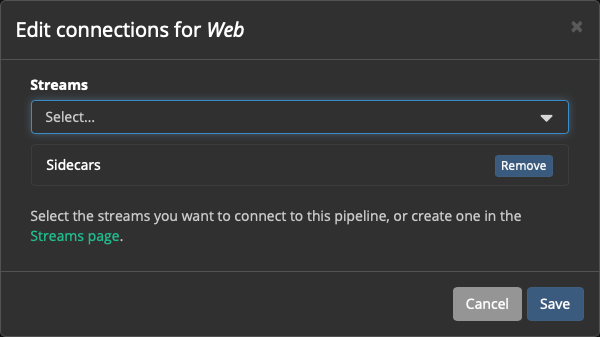
А также в Stage 0 нажимаем Edit и добавляем к нему правило:
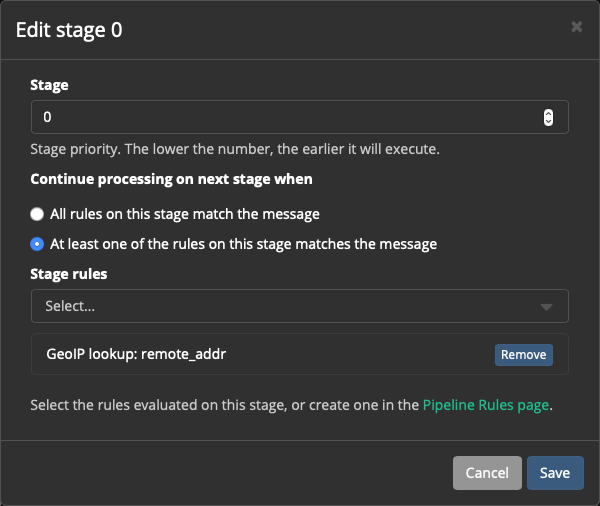
Идём в Streams → Sidecars, смотрим новые сообщения...
Проблема - ничего не происходит. Никаких гео-тегов не видно.
Проблема возникает из-за порядка обработки правил.
Идём в System → Configurations
По умолчанию так:
1 AWS Instance Name Lookup
2 GeoIP Resolver
3 Pipeline Processor
4 Message Filter Chain
А нам нужно так:
1 AWS Instance Name Lookup
2 GeoIP Resolver
3 Message Filter Chain
4 Pipeline Processor
Нажимаем кнопку Update, перетаскиванием располагаем правила в правильном порядке:
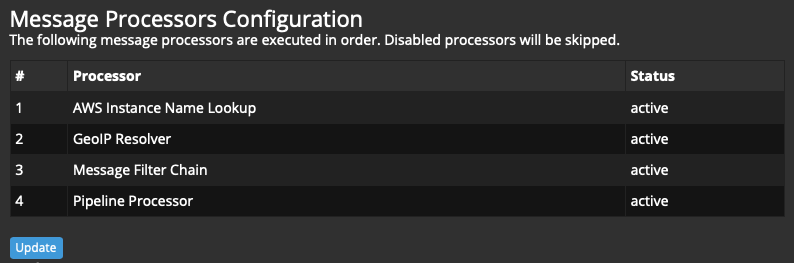
Снова идём в Streams → Sidecars, смотрим новые сообщения и видим в них искомые геоданные:
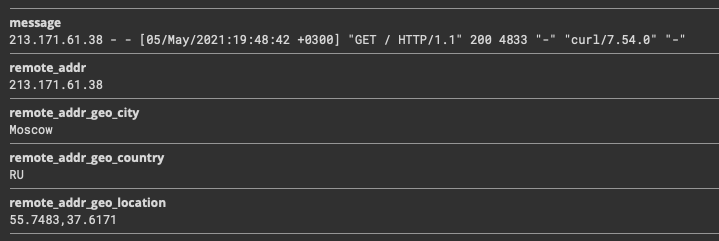
Теперь будем смотреть красивую карту:
В Streams → Sidecars добавляем Aggregation:
Нажимаем Edit:
Visualization type: World Map
Rows: remote_addr_geo_location
Сохраняем: Save
Теперь можно визуально оценить откуда к нам на сайт приходят посетители:
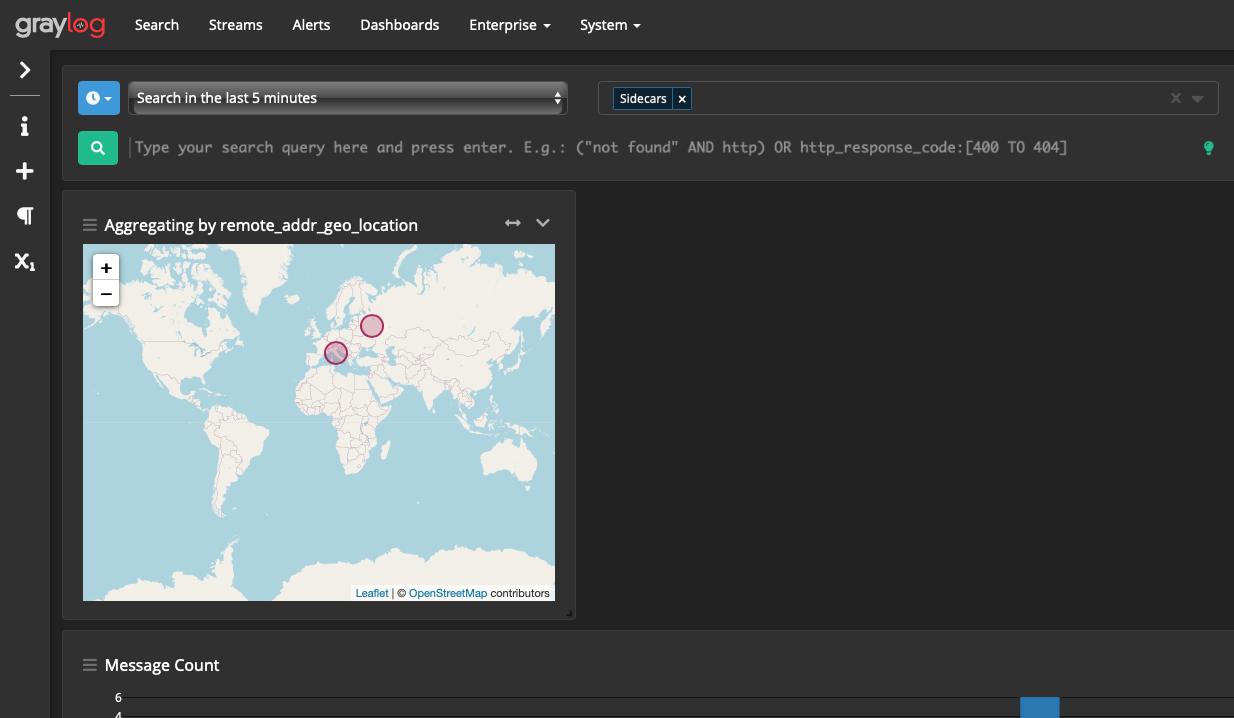
На этом всё, надеемся, что данная информация будет вам полезна.
Данная статья изначально появилась в виде заметки / howto для внутреннего использования, поэтому может местами быть немного запутанной. Ждем ваши вопросы, предложения и замечания в комментариях!
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. За последние годы UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.









{kind=link}