Сложные системы подвержены сбоям многих компонентов, поэтому вполне целесообразно разделить сбои на два класса. К первому можно отнести повторяющиеся сбои, которые возможно предупреждать (например, отказ жесткого диска) и выявлять с помощью непосредственных проверок. Ко второму классу относятся непредвиденные сбои.
Итак, кто не против, чтобы одежду ему подбирала программа, машина, нейросеть?
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.
Логистическая регрессия является одним из статистических методов классификации с использованием линейного дискриминанта Фишера. Также она входит в топ часто используемых алгоритмов в науке о данных. В этой статье суть логистической регрессии описана так, что она станет понятна даже людям не очень близким к статистике.
В июле всех порадовала статья про deep dream или инцепционизм от Google. В статье подробно рассказывалось и показывалось как нейронные сети рисуют картины и зачем их заставили это делать. Вот эта статья на хабре.
Теперь все, у кого настроена среда caffe, кому скучно и у кого есть свободное время могут сделать собственные фотки в стиле инцепционизм. Одна проблема — почти на всех фотках получаются собаки. Как же избавится от элементов с псами в изображениях deep dream и обучить свою нейронную сеть пользоваться другими картинками?
BASIC был одним из самых распространенных языков программирования. В 80-х он шел в стандартном наборе программ на компьютере (например, Commodore 64 и Apple II), а в 90х и DOS и Windows 95 включали в себя QBasic IDE.
QBasic был также моим первым языком программирования. Я не программировал на Бейсике уже почти 20 лет и решил вспомнить этот действительно странный язык. Поскольку я провел много времени за байесовскими алгоритмами, я подумал, что будет интересно увидеть как байесовская аналитика будет выглядеть в утилите 20-летней давности.
Количество данных растет с каждым днем огромными рывками. Ежедневно в сеть заливается 2,3 триллиона гигабайт данных. К 2017 году ожидается, что количество данных вырастет на 800%. Чем больше данных, тем выше спрос на специалистов по их обработке.
Наука о данных настолько динамично развивается, что у каждого специалиста есть своя узкая зона ответственности. Мартин Джонс (Martin Jones), CEO и co-founder в Cambriano Energy предлагает выделить 14 основных ролей в работе с большими данными.
В последнее время слово big data звучит отовсюду и в некотором роде это понятие стало мейнстримом. С большими данными тесно связаны такие термины как наука о данных (data science), анализ данных (data analysis), аналитика данных (data analytics), сбор данных (data mining) и машинное обучение (machine learning).
Почему все стали так помешаны на больших данных и что значат все эти слова?
Схема отбора в выборку — это детальное описание того, какие данные и каким способом будут получены. Есть много схем для отбора в выборку, поэтому нужно выбрать для исследований такую, которая даст наиболее репрезентативные результаты. Репрезентативность выборки — это соответствие характеристик выборки характеристикам популяции.
В идеале лучше работать со всей генеральной совокупностью, но это занимает много времени и ресурсов. Поэтому можно исследовать только ее часть, что и называется выборкой. Затем исследуются элементы, которые попали в выборку. На основе полученных значений оцениваются неизвестные элементы выборки.
Мы обожаем работать с данными и мониторим все подряд. Несколько недель назад мы решили потрекать кто сколько жмет по клавишам и двигает мышкой в рабочее время.
У нас небольшая команда: 1 дизайнер, 2 девелопера и 2 контентщика. Конечно парочка менеджеров и один data scientist.
Мы установили простой плагин для Google Chrome на каждый ноутбук. На протяжении недели плагин собирал статистику о нажатии клавиш и движении мышек и отправлял в наш трекер t.onthe.io.
По исследованиям IBM, 80% информации, добавляемой в интернет — это хаотичные, деструктивные и никому не нужные данные. А человечество использует лишь 0,5% всего объема.
Контент стратегия — один из маркетинговых трендов последних лет. 89% маркетологов, которые используют контент-продвижение, признались в его эффективности.
Планируя контент-стратегию, важно продумать как попасть в эти ничтожные 5% полезного траффика. Можно писать по 100500 статей в день и не получить даже тысячи прочтений. А можно стать контент-хакером и покорить мир.
Перед прочтением статьи лучше пройти тест на уровень контент-хакерства.
Он считает, что с научной точки зрения энтропия не могла быть полностью изученной, пока технология парового двигателя не дала толчок к развитию термодинамики. Квантовые вычисления появились из-за потребности имитировать квантовую механику на компьютере. Так и алгоритмы человеческого разума могут быть изучены с появлением нейронных сетей. Энтропия используется во многих областях: например, при смарт кропе, в кодировании видео и изображений; в статистике.
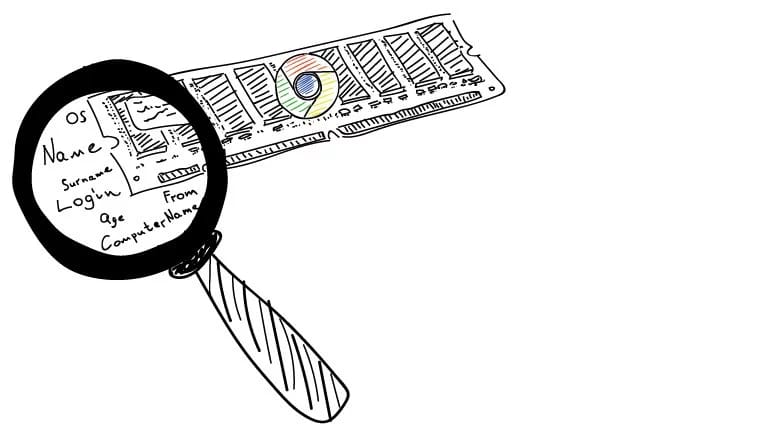
Всем известно, что находясь внутри браузера, нельзя извлечь достаточное количество информации о его пользователе с помощью простого JavaScript. Служебная информация, вроде имени браузерного движка, операционной системы и их версий хоть и дает общее представление о пользователе (и об аудитории в целом), но все же не является всеобъемлющей.
Для комплексного анализа пользователя используется User-ID в Universal Analytics, но с помощью независимых программных компонентов, запущенных и находящихся где-то в памяти компьютера рядом с браузером, тоже можно собирать данные о пользователе. Полученная непосредственно из памяти браузера информация позволит осуществить анализ как отдельного пользователя, так и всей аудитории. Здесь будет рассмотрено семейство браузеров на движке Webkit и на конкретном примере браузера Google Chrome.
Кто-то с помощью Хабра пиарится, кто-то ведет свою контент стратегию, а кто-то просто делится интересной информацией. Но всем хочется знать заранее что будет с опубликованным материалом, будет он популярным или нет, понравится ли читателям. Можно ли предугадать сколько просмотров получит статья по первым трем часам ее жизни?
Сэмплирование данных значительно снижает нагрузку на вычислительные мощности. Но как можно судить о количестве дырок в сыре по одному куску? Что если из-за сэмплирования легко можно терять 20 тысяч и больше долларов в день?
Часто сэмплирование мешает проводить точный анализ потока данных, чему свидетельствует кейс под катом.
Умные алгоритмы уже умеют находить и распознавать лица, определять главную часть картинки, узнавать различные предметы. А нейронные сети пошли дальше и даже могут самостоятельно создавать произведения искусства.
Недавно Google на своем блоге опубликовали интересный способ использования нейронных сетей, распознающих картинки. Далее свободный перевод публикации.
Когортный анализ — метод анализа эффективности бизнеса. Суть состоит в том, чтобы анализировать поведение групп людей, объединенных по какому-либо признаку во времени.
Оценка продукта происходит не по итоговой метрике, а по каждой отдельной когорте этой метрики. Когорта — группа людей, которые сделали одно и то же действие в определенный период времени.
Уже очень давно самыми популярными форматами остаются: JPEG — для lossy сжатия, PNG — для сжатия без потерь и GIF для анимации. Эти форматы поддерживаются всеми браузерами и веб-приложениями.
Но чем больше картинок заливается в интернет, тем острее ощущается потребность в лучшем формате. Для экономии места на сервере, для ускорения загрузки страницы и для экономии времени дизайнера.
Если измерить вес всех фотографий на странице — иногда можно получить сердечный приступ. Чем больше фотографий, тем больше весит страница и тем дольше она загружается.
Сейчас уже созданы несколько форматов, имеющих все шансы заменить и JPEG и GIF и PNG. Очень хорошие результаты показывают гугловский WebP и «свободный» BPG.
WebP — сравнительно новый формат от Google. Картинки в этом формате занимают на 30% меньше места на странице благодаря особому сжатию, построенному на кодировании ключевых кадров в видеокодеке VP8.
WebP поддерживает сжатие с потерями и без, разные степени прозрачности, метаданные и может содержать встроенный ICC-профиль. Но пока не все браузеры и приложения поддерживают формат.
Все графические файлы делятся на два глобальных типа — растровые и векторные. Иногда нужно сделать конвертацию из растра в черно-белый вектор. Например, для трассировки черно-белых иконок, QR-кодов, штрих-кодов, картинок с растровыми надписями, чеков или картинок в блоге.