Комментарии 40
Когда-нибудь и в нашем проекте будет полноценная поддержка видео от Intel.
Было бы полезно увидеть сравнение производительности с конкурентами от AMD и Nvidia
Так увидьте :) в посте есть прямая ссылка на именно такое сравнение на notebookcheck
Я сэкономлю вам немного времени:
Скрытый текст
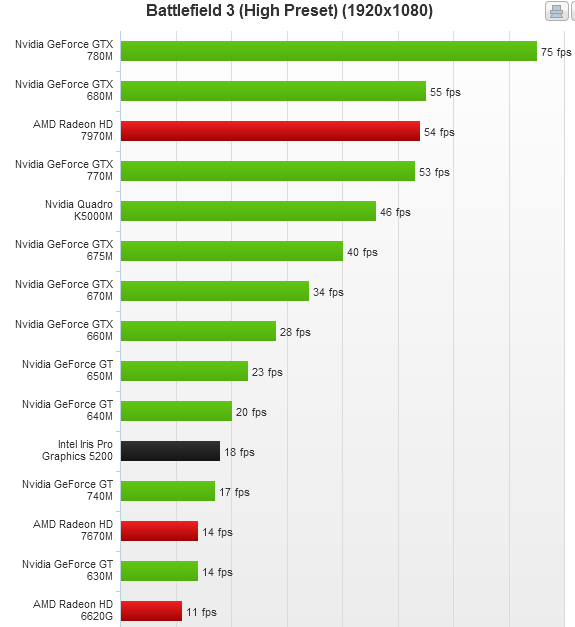


Есть у меня один проектик где надо декодировать много h264 видео файлов одновременно. Логично воспользоваться для этого аппаратным ускорением. И вот подбирая для него железо, я обнаружил, что никто из производителей не указывает сколько видео потоков одновременно может декодировать железо. Ясно, что это зависит от битрейта самих потоков, но и по количеству потоков должна быть верхняя граница. Для Intel HD4600 в i5 4XXX (не помню сейчас точно) я экспериментально установил, что при 8 потоках видео начинает подтормаживать. Потом в недрах интеловского сайта нашел для HD4600 цифру 12 как количество одновременных потоков видео. Значит если понизить битрейт, то я смогу выжать из него и 12. Правда, не очень понятно — это относится к декодированию или кодированию. У AMD я вообще подобных характеристик не нашел. У текущих чипсетов NVidia что то более менее похожее находится, но цифры не радуют — что то вроде 1 поток для 4К разрешения или 2 для FullHD. Но железо явно может больше — карта 3х летней давности спокойно тянет 6 моих потоков на железе (загрузка CPU 5-7%). Впрочем я все равно выбрал Intel HD4600 из-за компактности. Жалко у нас не доступны «дискретные» системы на Iris (мне не нужен ноутбук, мне нужен ПК в компактном корпусе, желательно в Rack Mount).
Для меня было шоком, что такая мегавстроенная графика без танцев с бубном не тянет десктоп разрешение выше 1920х1080. Надеюсь, это исправят.
Сильно выше 1920х1080? У меня (i7, Haswell) тянет 1980x1200 и 1280x1024 одновременно (в играх, конечно, второй монитор приходится отключать). С этими же мониторами работал на другом компе — i5 предыдущего поколения. Так что смею предположить, что проблема лежит не в графике. Или не только в ней.
(смотрел на Ubuntu 13.04 и Fedora сколько-то-там).
(смотрел на Ubuntu 13.04 и Fedora сколько-то-там).
Что то не так у вас. У меня Intel HD2000 тянет 1920х1200 + 1920х1080 одновременно — домашний комп.
А HD4600 запускал в нестандартном разрешении 1728х1296 на два канала и еще один 1280х1024.
А HD4600 запускал в нестандартном разрешении 1728х1296 на два канала и еще один 1280х1024.
Intel HD 4000, великолепно тянет 2560*1440 для системы и софта, игрушки обычно запускаю в 1920*1080, иногда приходится уменьшать.
i7-4770 (т.е. графика HD 4600), два монитора, один из них 2560х1440. У матплаты выходы DVI, HDMI и D-Sub, у монитора вход DVI-D и DisplayPort. Максимально возможное разрешение экрана для DVI у интела — 1920х1080. Может, как-то можно подключить hdmi выход к displayport входу, но развлечения с переходниками и кабелями стоят не намного дешевле нормальной видеокарты.
У меня мак мини, там только HDMI и mini DisplayPort. С первого есть переходник на DVI, но он лишь Single Link (который как раз и тянет лишь 1920*1080). Поэтому пришлось потерпеть, но дождаться доставки качественного (quard-lane) кабеля mini DisplayPort – DisplayPort, он и звук умеет гнать в цифре. Так что не в процессоре дело. Если подключаете по DVI, убедитесь, что все компоненты, особенно кабель – DualLink (см википедию).
Призываю binstream, таки интересно, почему дымка такая тяжелая (правильнее было бы, наверное, Frustum'a, но его нет на Хабре).
Я втайне надеялась, что кто- то из Unigine тут есть, но, конечно же, не знала кто. Теперь, благодаря вам, знаю. Посты писать полезно.
Тут не просто сотрудники Unigine есть, тут есть даже блог компании habrahabr.ru/company/unigine/
Цифры производительности из лаборатории Intel постоянно получаем по нашим бенчмаркам, спасибо за внимание и сотрудничество =)
Объемные облака в Heaven тяжелые, ага — там много слоев и достаточно сложный алгоритм генерации.
Это вовсе не обычные партиклы, короче.
Ну и вообще смысл Heaven — в аппаратной тесселяции, на фоне загруза от которой все остальное — мелочи. К сожалению, видеодрайвер от Intel пока не очень с ней дружит, но уже почти поддерживает.
Это вовсе не обычные партиклы, короче.
Ну и вообще смысл Heaven — в аппаратной тесселяции, на фоне загруза от которой все остальное — мелочи. К сожалению, видеодрайвер от Intel пока не очень с ней дружит, но уже почти поддерживает.
Отставание, вроде бы, несущественное, но если мы сравним максимально достижимую в тесте частоту кадров, то тут разница становится впечатляющей
Максимальный локально-достижимый FPS — это, пожалуй, одна из самых бесполезных характеристик 3D теста. Другое дело, если бы там было максимальное время на кадр.
… графика Iris, да и вообще вся верхняя серия GT3 используется исключительно в ноутбуках и моноблоках (All in One = AIO), в десктопные же CPU любого уровня интегрируются только более скромные модели Intel HD Graphics
А вот это что за зверь? i5-4570R
давно назрел вопрос, а интел по поводу него хранит молчание
как соотносится:
и это:
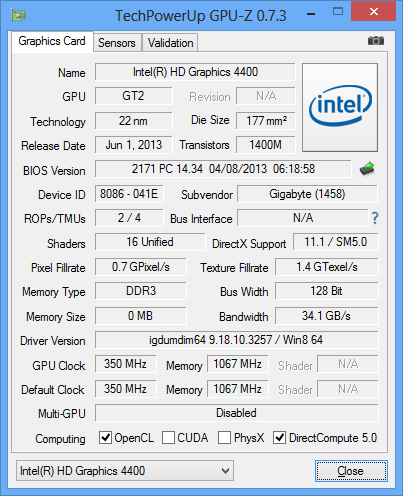
в вопросе числа исполнительных модулей?
если что, то картинка с gpu-z от Core i3-41xx
как соотносится:
GT2 с 20 EU — это, в зависимости от частоты, Intel HD Graphics 4200/4400/4600.
и это:

в вопросе числа исполнительных модулей?
если что, то картинка с gpu-z от Core i3-41xx
Универсальный совет что партиклы много жрут, отключайте их в первую очередь — не совсем корректен. Они тяжелые конкретно только в этой сцене, и проседание по филлрейту явно. Вообще в первую очередь я бы посоветовал резать всякие там mssa, во вторую — постэффекты, дальше резать тени, и только потом частицы и геометрию.
А так в целом материал полезный и интересный, спасибо. Не приходилось пока еще интеловские gpu тулзы использовать для профайлинга.
А так в целом материал полезный и интересный, спасибо. Не приходилось пока еще интеловские gpu тулзы использовать для профайлинга.
Отчасти, согласна. Но в данном случае 4xантиалиасинг делает железка, он почти «бесплатен». А вообще — читайте указанный в конце Developers Guide, там много полезного по теме написано.
Да как же он может быть бесплатен, если фрагментный шейдер будет выполняться в 4 раза чаще? А у вас между прочим проседаение именно по филлрейту.
подумала, согласилась.
Позвольте не согласиться и позанудствовать: фрагментный шейдер выполняется в 4 раза чаще только если на этот настаивают разработчики, и это называется super-sampling. На практике же есть много нюансов:
1) геометрия отрисовывается с тем же вызовом фрагментных шейдеров, а вот этапы rasterizer и pixel export уже будут тяжелее
2) post-processing как правило оптимизируют для того, чтобы минимальную работу делать на уровне сэмплов, так что там часть 4х и часть 1х.
3) полностью заполненные пиксели обычно фильтруют и обрабатывают на уровне пикселей, даже если всё остальное на уровне сэмплов, так что часть из 4х снова уходит в 1х
4) естественно, накладные расходы, требования к памяти и шинам данных — всё это выше
1) геометрия отрисовывается с тем же вызовом фрагментных шейдеров, а вот этапы rasterizer и pixel export уже будут тяжелее
2) post-processing как правило оптимизируют для того, чтобы минимальную работу делать на уровне сэмплов, так что там часть 4х и часть 1х.
3) полностью заполненные пиксели обычно фильтруют и обрабатывают на уровне пикселей, даже если всё остальное на уровне сэмплов, так что часть из 4х снова уходит в 1х
4) естественно, накладные расходы, требования к памяти и шинам данных — всё это выше
Ну скажем так, по ссылке что я привел написано что это именно msaa, и там написано:
A pixel shader runs for each 2x2 pixel area to support derivative calculations (which use x and y deltas).
Я все таки подозреваю что оптимизации там есть, а даже если и нет, то «бонусные» фрагментные шейдеры будут выполняться в 99% по кешу, что уже на порядок легче.
A pixel shader runs for each 2x2 pixel area to support derivative calculations (which use x and y deltas).
Я все таки подозреваю что оптимизации там есть, а даже если и нет, то «бонусные» фрагментные шейдеры будут выполняться в 99% по кешу, что уже на порядок легче.
3) полностью заполненные пиксели обычно фильтруют и обрабатывают на уровне пикселей, даже если всё остальное на уровне сэмплов, так что часть из 4х снова уходит в 1хКак я уже привел цитату выше из описания от ms — похоже что не фильтруют, но я подозреваю что зависит от вендора. Ну ладно, для color они может и отфильтруют, а вот для буфера глубины рендер выполняется гарантированно для каждого семпла.
post-processing как правило оптимизируют для того, чтобы минимальную работу делать на уровне сэмпловпост процессинг поспроцессингу рознь. Если dof может например скрыть лестницы отсутствия семплинга, то hdr — нет. Если используется честный hdr — то там рендер в флоатпоинт текстуру, а это опять же дороже, ибо 4 байта на канал. В общем поспроцесс — это постпроцесс, а антиалиазинг — это антиалиазинг. И то и другое требует немалых затрат, и никак не бесплатен как сказали выше, и часто они являются одной из самых тяжелых операций.
A pixel shader runs for each 2x2 pixel area to support derivative calculations (which use x and y deltas).
К MSAA это не имеет отношения — речь идёт не о сэмплах, а о пикселях, и в режиме 2х2 они обрабатываются независимо от MSAA.
Как я уже привел цитату выше из описания от ms — похоже что не фильтруют, но я подозреваю что зависит от вендора.
Фильтрует не драйвер, а движок игры, так что вендор тут не при чём.
Ну ладно, для color они может и отфильтруют, а вот для буфера глубины рендер выполняется гарантированно для каждого семпла.
Вы путаете выполнение фрагментного шейдера с фиксированными блоками (растеризатор, интерполяторы, depth/stencil test). Последние будут работать на частоте сэмплов, что не мешает тяжёлому шейдеру отработать раз на пиксел.
пост процессинг поспроцессингу рознь. Если dof может например скрыть лестницы отсутствия семплинга, то hdr — нет.
Я о том и говорю, что разработчики стараются как можно меньше пост-процессинга делать на частоте сэмплов.
Я лишь опровергаю утверждение «фрагментный шейдер будет выполняться в 4 раза чаще», но пытаюсь показать, что MSAA почти бесплатен. А Вы спорите зря: я на этом собаку сьел, а может и две ;)
Ах, да, прошу прощения, не фрагментный выполняется 4 раза (выполняется 1 раз всегда), а 4 раза происходит запись. И по факту пишется 4 семпла:
Но вот с тем что MSAA почти бесплатен я согласиться не могу. Можно попросить автора темы провести еще одно измерение для скажем того же DirectX9 но с отключенным MSAA, я ожидаю прирост производительности процентов на 40.
For a triangle, a coverage test is performed for each sample location (not for a pixel center). If more than one sample location is covered, a pixel shader runs once with attributes interpolated at the pixel center. The result is stored (replicated) for each covered sample location in the pixel that passes the depth/stencil test.
A line is treated as a rectangle made up of two triangles, with a line width of 1.4.
Вы путаете выполнение фрагментного шейдера с фиксированными блокамиНе путаю, просто память подвела. Перечитал топик от ms внимательнее. :)
Но вот с тем что MSAA почти бесплатен я согласиться не могу. Можно попросить автора темы провести еще одно измерение для скажем того же DirectX9 но с отключенным MSAA, я ожидаю прирост производительности процентов на 40.
Хотел почитать, у вас там ссылка на Intel Processor Graphics Developer's Guide for 4th Generation Intel® Core™ Processor Graphics битая. Page not found кажет.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Хозяйка из настоящего — интегрированная графика (Intel GPU) 2013 или «миелофон у меня!»