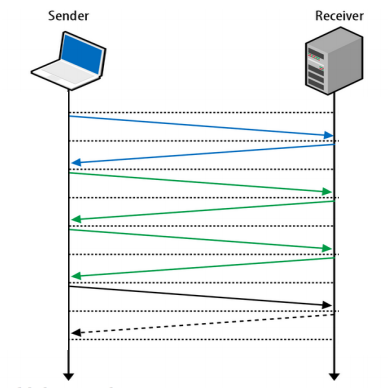
Возможно, вы знаете, что у браузере Google Chrome есть встроенный профилировщик. Но даже из тех людей, кто его видел, большинство считает, что использовать его можно только для отладки Javascript или отрисовки кадров в браузере. Но на самом деле его весьма просто можно прикрутить в качестве средства визуализации данных профилирования в вашем проекте.
Я не открою здесь каких-то уникальных секретов, например, Colt McAnlis писал о подобном применении профилировщика Chrome в игровых проектах ещё в 2012 году. Всё, написанное там, всё ещё является правдой, а я напишу ещё один материал — просто для лучшего распространения знаний о столь полезном инструменте.
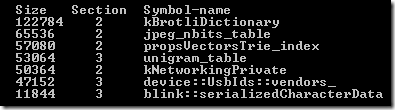
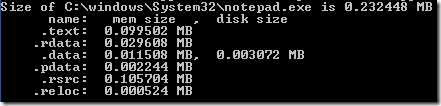
Для некоторой части нашей системы сборки кода мы когда-то написали простенький профилировщик (называется TinyProfiler). Он достаточно тривиален — замеряет время выполнения определенных блоков кода и создаёт набор HTML+SVG файлов, которые визуализируют эти данные в стиле flame-графов:
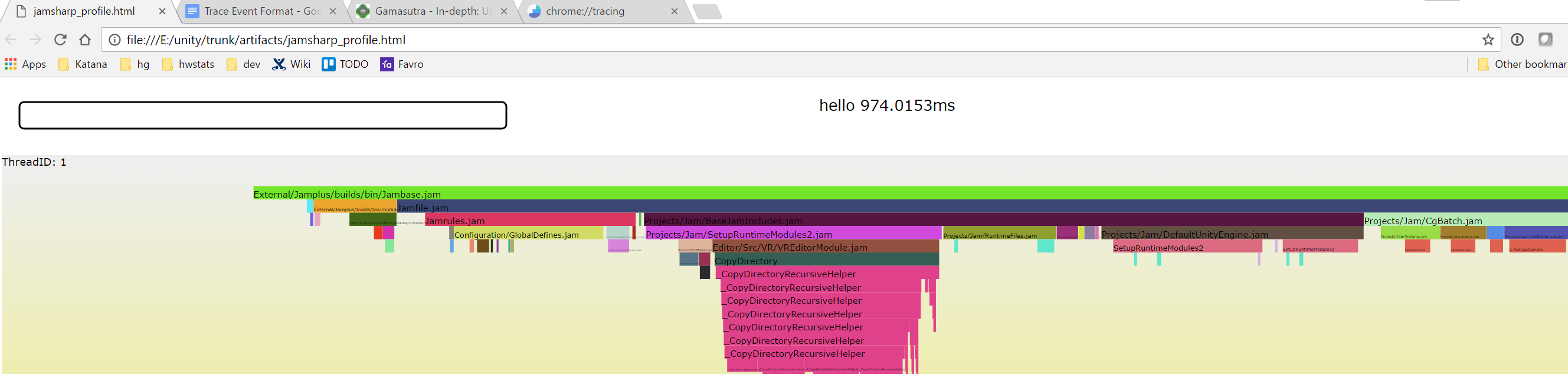
Это, в принципе, неплохо работало, но полученный HTML был не очень интерактивным. Можно было подвести мышку к определенному блоку и увидеть его название во всплывающей подсказке, но на этом все удобства и заканчивались. Не было ни зума, ни фильтрации, ни скрола, ни поиска — в общем ничего, чего хотелось бы получить от более-менее профессионального инструмента. Всё это можно было, конечно, сесть и написать, но… зачем же это делать, если можно этого не делать? Ведь уже есть кто-то (разработчики Chrome), кто всё это уже сделал.
Я не открою здесь каких-то уникальных секретов, например, Colt McAnlis писал о подобном применении профилировщика Chrome в игровых проектах ещё в 2012 году. Всё, написанное там, всё ещё является правдой, а я напишу ещё один материал — просто для лучшего распространения знаний о столь полезном инструменте.
Предыстория
Для некоторой части нашей системы сборки кода мы когда-то написали простенький профилировщик (называется TinyProfiler). Он достаточно тривиален — замеряет время выполнения определенных блоков кода и создаёт набор HTML+SVG файлов, которые визуализируют эти данные в стиле flame-графов:
Это, в принципе, неплохо работало, но полученный HTML был не очень интерактивным. Можно было подвести мышку к определенному блоку и увидеть его название во всплывающей подсказке, но на этом все удобства и заканчивались. Не было ни зума, ни фильтрации, ни скрола, ни поиска — в общем ничего, чего хотелось бы получить от более-менее профессионального инструмента. Всё это можно было, конечно, сесть и написать, но… зачем же это делать, если можно этого не делать? Ведь уже есть кто-то (разработчики Chrome), кто всё это уже сделал.
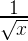




 Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой.
Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой.