Как мы можем прочесть в первой главе книги Effective C++, язык С++ является по сути своей объединением 4 разных частей:
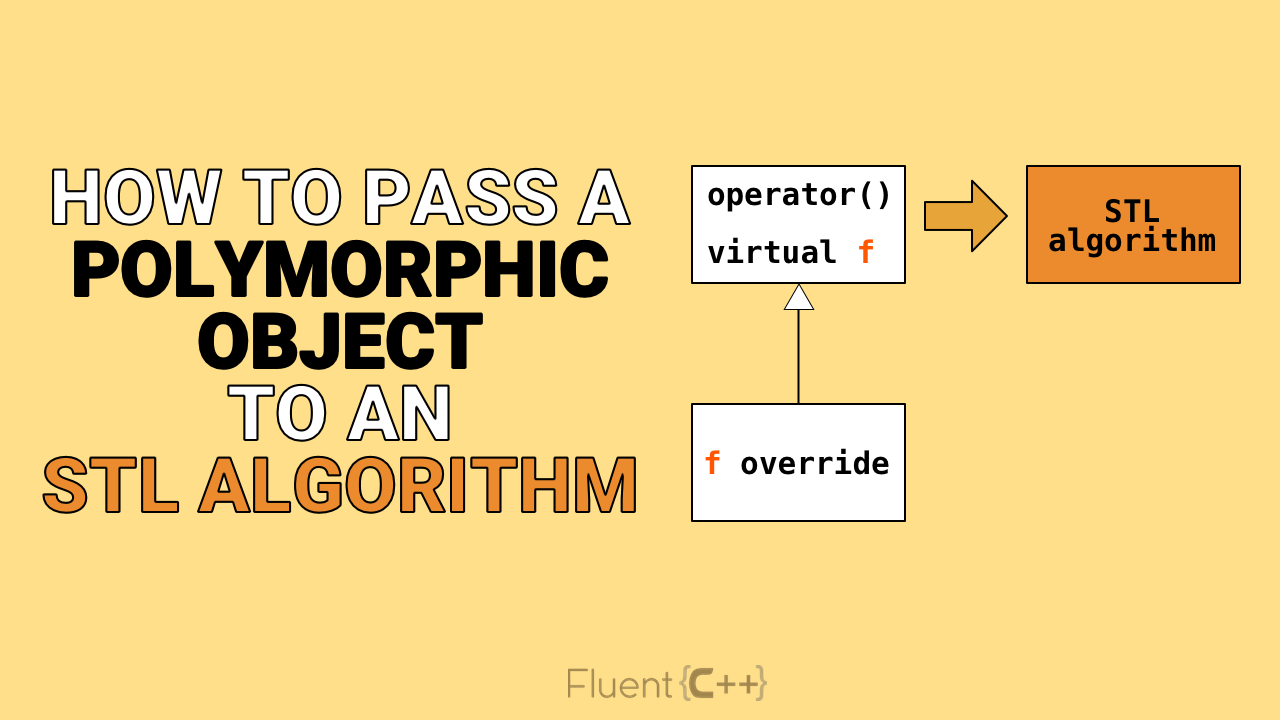
Эти четыре, по сути, подъязыка составляют то, что мы называем единым языком С++. Поскольку все они объединены в одном языке, то это даёт им возможность взаимодействовать. Это взаимодействие порой порождает интересные ситуации. Сегодня мы рассмотрим одну из них — взаимодействие объектно-ориентированной модели и STL. Оно может принимать разнообразные формы и в данной статье мы рассмотрим передачу полиморфных функциональных объектов в алгоритмы STL. Эти два мира не всегда хорошо контачат, но мы можем построить между ними достаточно неплохой мостик.
- Процедурная часть, доставшаяся в наследство от языка С
- Объектно-ориентировання часть
- STL, пытающийся следовать функциональной парадигме
- Шаблоны
Эти четыре, по сути, подъязыка составляют то, что мы называем единым языком С++. Поскольку все они объединены в одном языке, то это даёт им возможность взаимодействовать. Это взаимодействие порой порождает интересные ситуации. Сегодня мы рассмотрим одну из них — взаимодействие объектно-ориентированной модели и STL. Оно может принимать разнообразные формы и в данной статье мы рассмотрим передачу полиморфных функциональных объектов в алгоритмы STL. Эти два мира не всегда хорошо контачат, но мы можем построить между ними достаточно неплохой мостик.
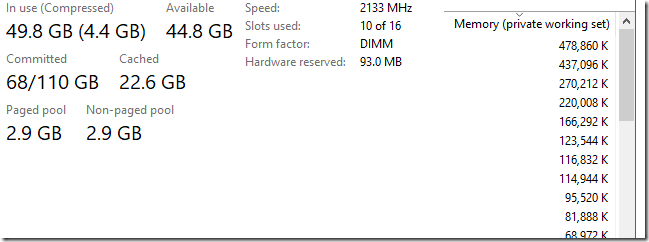
 Иногда бывает нужно перечислить все процессы или потоки, которые в данный момент работают в ОС Windows. Это может понадобиться по разным причинам. Возможно, мы пишем системную утилиту вроде
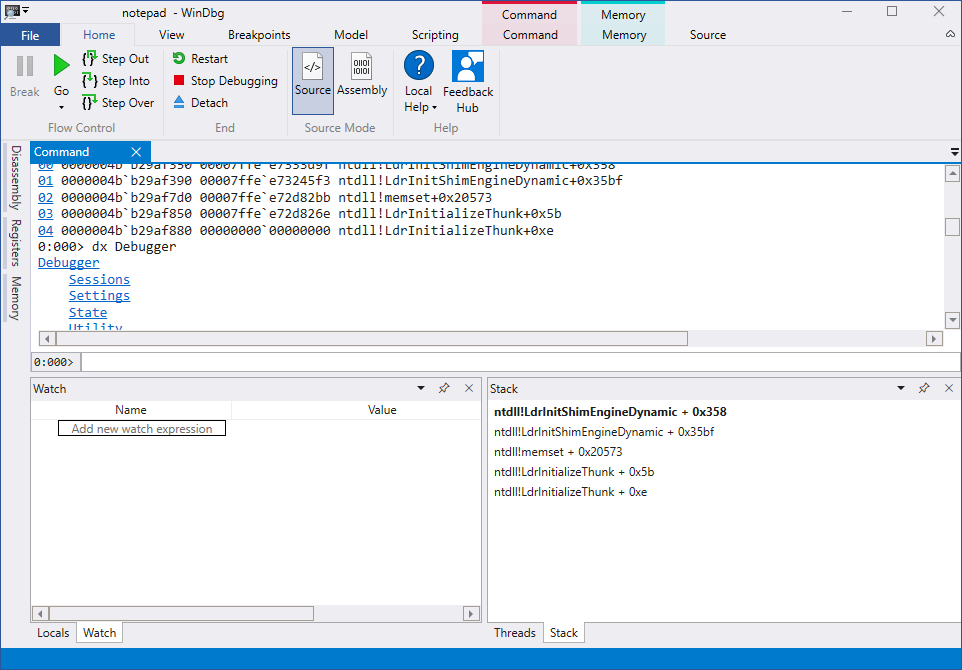
Иногда бывает нужно перечислить все процессы или потоки, которые в данный момент работают в ОС Windows. Это может понадобиться по разным причинам. Возможно, мы пишем системную утилиту вроде  Гейзенбаг — это худшее, что может произойти. В описанном ниже исследовании, которое растянулось на 20 месяцев, мы уже дошли до того, что начали искать аппаратные проблемы, ошибки в компиляторах, линкерах и делать другие вещи, которые стоит делать в самую последнюю очередь. Обычно переводить стрелки подобным образом не нужно (баг скорее всего у вас в коде), но в данном случае нам наоборот — не хватило глобальности виденья проблемы. Да, мы действительно нашли баг в линкере, но кроме него мы ещё нашли и баг в ядре Windows.
Гейзенбаг — это худшее, что может произойти. В описанном ниже исследовании, которое растянулось на 20 месяцев, мы уже дошли до того, что начали искать аппаратные проблемы, ошибки в компиляторах, линкерах и делать другие вещи, которые стоит делать в самую последнюю очередь. Обычно переводить стрелки подобным образом не нужно (баг скорее всего у вас в коде), но в данном случае нам наоборот — не хватило глобальности виденья проблемы. Да, мы действительно нашли баг в линкере, но кроме него мы ещё нашли и баг в ядре Windows.