Комментарии 4
Господа, вы вообще серьезно? ;)
«что со «Скалой-Р» происходит заметно реже, чем в случае Nutanix и Simplivity»
В таких случаях обычно спрашивают координаты места и врача, где выдавали рецепт.
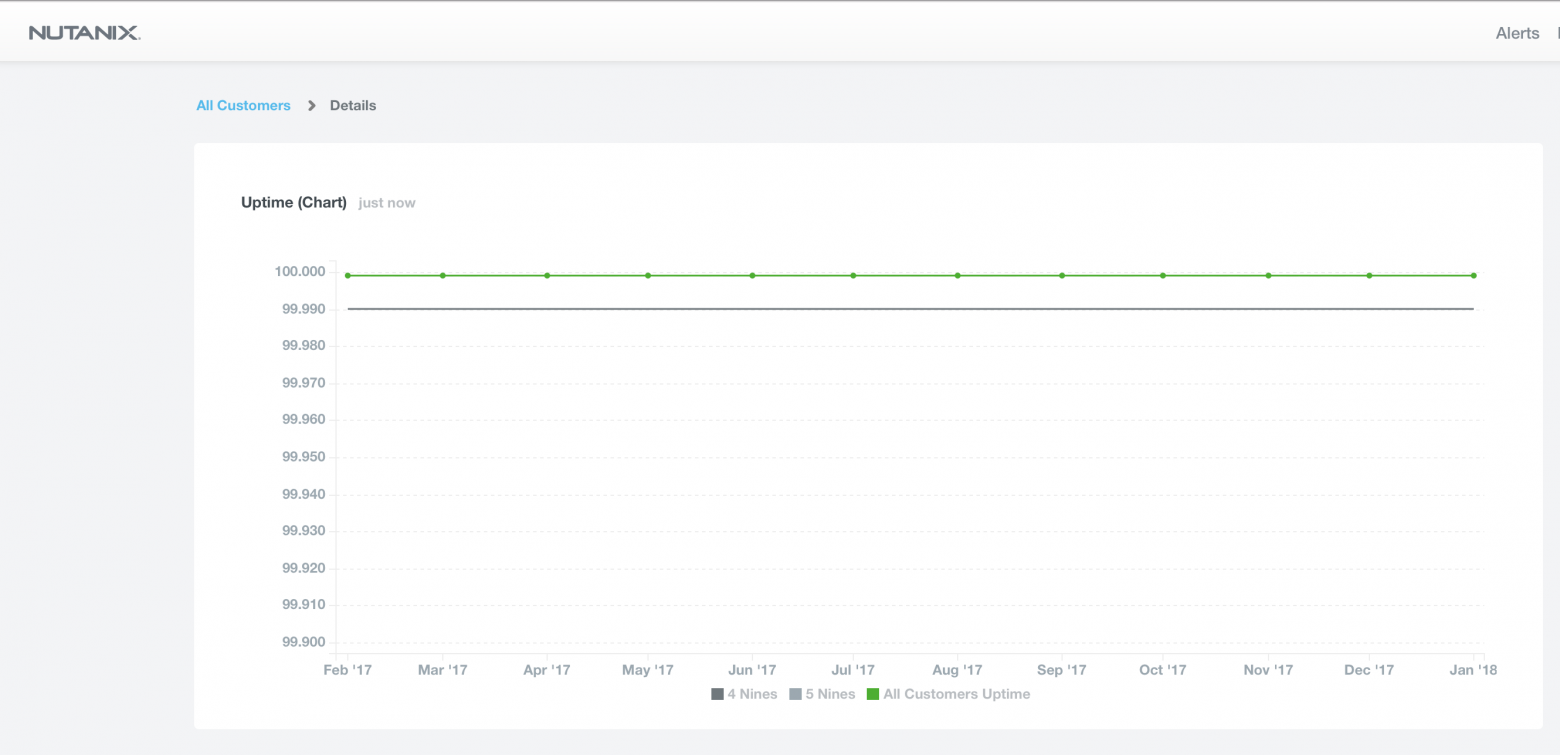
Типовая SLA всех клиентов нутаникс в мире — минимум 99.999% (5 минут «даунтайма» в год максимум), при легко достижимом 99.9999% (30 секунд в год).
Даже и статистика живая имеется — приложено (десятки тысяч кластеров в мире).
Не покажете статистику с тех нескольких инсталляций в РФ (про мир как-то даже неудобно спрашивать) по SLA?
«и при этом повлечет заметное снижение производительности» — приведите пожалуйста факты, а не ваши фантазии.
Просадка производительности Нутаникс даже при полном ребилде (после потери дисков / узлов) — минимальная, еще в 2014 году показывали.
На 2018 алогоритмы / производительность Nutanix ускорены во много раз. Ре-локализация даных — с точки зрения нагрузки вообще около нуля просадку дает.
www.nutanix.com/2014/03/03/nutanix-disk-self-healing-laser-surgery-vs-the-scalpel
При этом на «российской» Скала-Р — просадка достаточно катастрофическая может быть.
«что со «Скалой-Р» происходит заметно реже, чем в случае Nutanix и Simplivity»
В таких случаях обычно спрашивают координаты места и врача, где выдавали рецепт.
Типовая SLA всех клиентов нутаникс в мире — минимум 99.999% (5 минут «даунтайма» в год максимум), при легко достижимом 99.9999% (30 секунд в год).
Даже и статистика живая имеется — приложено (десятки тысяч кластеров в мире).
Не покажете статистику с тех нескольких инсталляций в РФ (про мир как-то даже неудобно спрашивать) по SLA?
«и при этом повлечет заметное снижение производительности» — приведите пожалуйста факты, а не ваши фантазии.
Просадка производительности Нутаникс даже при полном ребилде (после потери дисков / узлов) — минимальная, еще в 2014 году показывали.
На 2018 алогоритмы / производительность Nutanix ускорены во много раз. Ре-локализация даных — с точки зрения нагрузки вообще около нуля просадку дает.
www.nutanix.com/2014/03/03/nutanix-disk-self-healing-laser-surgery-vs-the-scalpel
При этом на «российской» Скала-Р — просадка достаточно катастрофическая может быть.

Нам даже не приходило в голову включать мониторинг uptime для всех клиентов. Работает себе и работает:-) Наш мониторинг отслеживает состояния виртуальных машин и прикладных задач, которые на них крутятся. Но специально для вас мы поднимем счётчики и через год обязательно опубликуем такую же прямую линию.
Ещё Вы говорите, что перенос данных с сервера на сервер (например, при падении хоста) — процесс, который совсем не нагружает ни сетевые интерфейсы, ни диски… А перенос 3—6 ТБ — разве это нагрузка?:-) А, между прочим, — это 1—2 часа на полной скорости 10GbE-интерфейса.
А вообще статья совсем не об этом, она о том, что принцип межузловой локальности к «энтерпрайзности» не имеет никакого отношения.
Ещё Вы говорите, что перенос данных с сервера на сервер (например, при падении хоста) — процесс, который совсем не нагружает ни сетевые интерфейсы, ни диски… А перенос 3—6 ТБ — разве это нагрузка?:-) А, между прочим, — это 1—2 часа на полной скорости 10GbE-интерфейса.
А вообще статья совсем не об этом, она о том, что принцип межузловой локальности к «энтерпрайзности» не имеет никакого отношения.
Если не открывается ссылка (хабрахабр особенности) — http://www.nutanix.com/2014/03/03/nutanix-disk-self-healing-laser-surgery-vs-the-scalpel/
Веб-сервер почему-то режет доступ для Referer: habrahabr.ru
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
О локальности данных в гиперконвергентных системах