
Недавно Владимир Подольский vpodolskiy, аналитик в департаменте по работе с образованием IBS, закончил обучение по специализации Data Science на Coursera. Это набор из 9 курсеровских курсов от Университета Джонса Хопкинса + дипломная работа, успешное завершение которых дает право на сертификат. Для нашего блога на Хабре он написал подробный пост о своей учебе. Для удобства мы разбили его на 2 части. Добавим, что Владимир стал еще и редактором проекта по переводу специализации Data Science на русский язык, который весной запустили IBS и ABBYY LS.
Часть 1. О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных.
Привет, Хабр!
Не так давно закончился мой 7-месячный марафон по освоению специализации «Наука о данных» (Data Science) на Coursera. Организационные стороны освоения специальности очень точно описаны тут. В своём посте я поделюсь впечатлениями от контента курсов. Надеюсь, после прочтения этой заметки каждый сможет сделать для себя выводы о том, стоит ли тратить время на получение знаний по аналитике данных или нет.
О специальности в общих чертах
Специальность «Наука о данных» на Coursera – это набор из 9 взаимосвязанных курсов по разным темам, касающимся всевозможных аспектов анализа данных: от сбора данных и до разработки полноценного аналитического продукта (онлайн-приложения). Вишенкой на девятислойном пироге служит дипломный проект по специальности (так называемый Data Science Capstone), который даёт возможность не только попрактиковать все освоенные навыки в комплексе, но и попытаться решить реальную задачу. На проект даётся аж 2 месяца и стартует он три раза в год, тогда как каждый из 9 обычных курсов занимает месяц изучения и начинается каждый месяц.
Освоение всей специальности «Наука о данных» с получением сертификатов по каждому из 9 курсов удовольствие не из дешёвых. Мне, с оплатой курсов повезло – IBS полностью спонсировала моё обучение. Компания искала добровольцев для освоения профессии Data Science и предложила оплатить сертификат каждому сотруднику, кто успешно пройдет обучение на Coursera. Тем не менее, если не заморачиваться и не брать по три курса в месяц, вполне хватит и собственных средств – каждый курс стоит по 49$, за исключением первого, который дешевле остальных (в рублях, как правило, цена тоже фиксирована, но периодически меняется). Впрочем, никто не отменяет и бесплатный вариант на случай отсутствия потребности в сертификатах.
Признаться честно, обучение далось нелегко – смотреть лекции и выполнять задания получалось либо поздними вечерами после работы (привет, любимое Подмосковье!), либо по выходным. И не редкостью были типичные для студентов ситуации из разряда «сдать в последний момент». Дополнительные проблемы создавало ограниченное время сдачи тестов и отчётных материалов – если не успел вовремя, пеняй на себя – баллы за опоздание снимаются. В случае, если задание оценивают однокурсники, опоздавший не получает баллов вовсе. Тем не менее, такой подход держит в тонусе.
И, наконец, о том, что я получил от специальности «Наука о данных»
- систематизировал знания по аналитике данных. Мне и до освоения DSS доводилось формировать аналитику различного уровня сложности, но мои знания и навыки скорее были разрозненными. Хоть в Бауманке и давали качественно матстатистику и теорвер, но вот про то, как обрабатывать данные, не было сказано решительно ни слова (курс по базам данных был, но был он об оракле и sql-запросах);
- научился работать с языком R и RStudio. Очень удобные инструменты, к слову. Если нужно как-то изменить процесс обработки, мне оказалось гораздо легче внести изменения в код на R и перезапустить его, чем повторять ту же последовательность действий при помощи мышки в Excel. Впрочем, это дело вкуса. В любом случае, команды и функции R очень хорошо приспособлены для обработки данных любых видов: почти все нужные функции можно найти в свободно распространяемых пакетах, а ненайденные можно самостоятельно дописать (если есть соответствующие скиллы кодинга на C);
- получил представление о том, как с максимальной отдачей проводить исследование данных. Как и в любом исследовании, тут есть своя структура, свои правила, исходные данные и результаты. Всё, скажем так, встало на свои места: получаем данные, очищаем их и нормализуем, проводим разведочный анализ (попутно записываем его результаты), проводим полное исследование, записываем результат и создаём при необходимости приложение для обработки данных по придуманному методу. Это если в грубых чертах – в каждом процессе есть свои тонкости и подводные камни. Меня, например, особо заинтересовала подготовка отчётов по результатам анализа данных – лекторы привели очень хорошую с точки зрения понимания неподготовленным пользователем структуру отчёта;
- дополнительной плюшкой стало наличие в R специальных пакетов для обработки и визуализации графов. Дело в том, что я нагружен ещё и кандидатской диссертацией, где львиная доля используемых методов опирается на графовые подходы. Пожалуй, ничего проще и наглядней реализации R операций над графами я не видел. Изобретать велосипед не пришлось…
О курсах
По моим субъективным ощущениям, все 9 курсов специализации могут быть сгруппированы в пять блоков. Каждый такой блок перекрывает одновременно ряд основополагающих моментов в науке о данных. Группировка приведена в таблице.
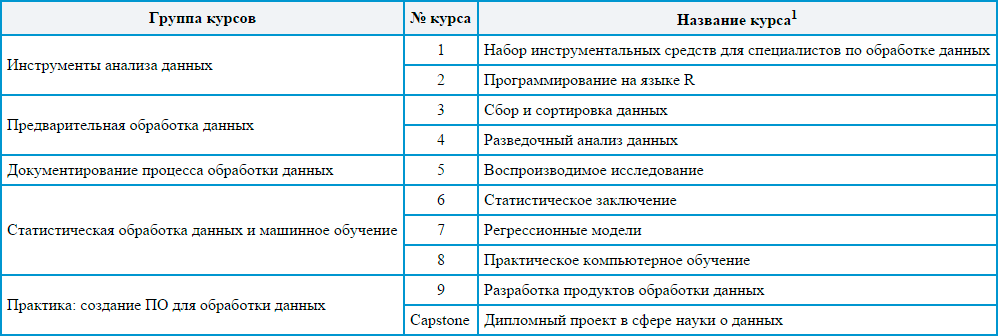
1 Названия даны в соответствии с официальным переводом DSS на русский язык на сайте Coursera
Инструменты анализа данных (курсы 1 и 2)
Существует расхожее мнение, что если на первой минуте занятия по инструментам (программным средствам, etc.) слушатели не заснули, то занятие можно считать удавшимся. В этом плане курсы по инструментарию DSS удались в полной мере – слушать интересно, а пробовать инструменты на ходу в сто крат интереснее, чем слушать. Внимание обоих курсов по инструментам анализа данных сосредоточено на языке программирования R. По сути, студента плавно вводят в тему анализа данных и тут же дают опробовать инструментарий на практике, чтобы освоиться. Курсы во многом неспешные, но охватывают все необходимые основы. Более глубокие знания по R даются в ходе остальных курсов – по мере необходимости. Где-то dplyr’у научат, а где-то поближе с ggplot познакомят. Такой практико-ориентированный подход «объяснять по мере необходимости», на мой взгляд, очень эффективен – сухие инструкции по использованию инструментов быстро испаряются из головы. Если вы не пользуете скилл, то он усыхает L На скрине – типичный RStudio.
Но, как водится, не без ложки дёгтя… Хотя авторы явно не ставили себе целью сделать исчерпывающий обзор всех инструментов R и дать возможность как следует опробовать каждый инструмент, приведённый обзор мне всё же показался недостаточным. В частности, очень слабо оказалась раскрыта тема создания собственных пакетов функций для R. Возможно, для неё стоило бы создать некий продвинутый блок, который бы не вошёл в вопросы тестов. По опыту работы с R могу сказать, что написание модулей является крайне важным для тех, кто всерьёз решил заняться аналитикой данных на R. Я бы с удовольствием углубился в эту тему (что, видимо, и сделаю, но уже самостоятельно).
Ещё бы хотелось иметь в видео-формате более детальную информацию по примерам применения функций из разных вспомогательных пакетов, но это скорее придирка – в большинстве своём работа с функциями из разных пакетов оказывается достаточно прозрачной при прочтении соответствующих мануалов.
Предварительная обработка данных (курсы 3 и 4)
В эту группу я закинул курсы по сбору данных, их предварительной обработке и разведочному анализу. В общем-то, это действительно всё фазы, которые предваряют процесс глубокого анализа данных. Мне эти курсы показались ну очень интересными, если не захватывающими. А всё почему? В рамках этих курсов нам показывают и рассказывают: а) как собирать данные из самых разных источников (в том числе соцсеток и с веб-страниц) и б) как строить простейшие графики, поясняющие, о чём собранные данные могут нам поведать. В общем, это получается такой куцый, но более-менее полный заход к анализу данных.
Из предварительной обработки стоит, пожалуй, выделить крайне полезную информацию о том, как лучше всего приводить данные к нормальной форме. Под нормальной формой подразумевается такая форма организации данных, при которой каждый столбец таблицы данных соответствует лишь одной переменной, а каждая строка – лишь одному наблюдению. Именно такие таблицы проще всего в дальнейшем обрабатываться и анализировать. Однако, как правило, данные к нам попадают в плохо организованном виде или и вовсе в неструктурированном (например, сообщения в социальных сетях представляют собой массивы символов, текст). Для дальнейшей обработки такие массивы данных надо привести к нормальной форме, что можно сделать при помощи разнообразных команд пакета dplyr. Причём важно понимать, что для каждого нового источника данных должна быть определена собственная последовательность переходов для осуществления окончательной нормализации. Без ручного кодирования тут, как водится, никуда…
На примере двух таблиц я попытался показать, что это за зверь такой – «нормализация». Данные для таблиц придуманы на основе проекта по работе…
Если исходная таблица с данными выглядит примерно так:
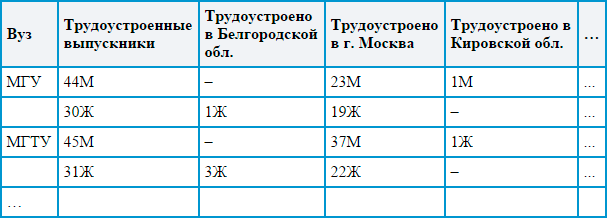
То при нормализации мы должны получить примерно такую табличку:
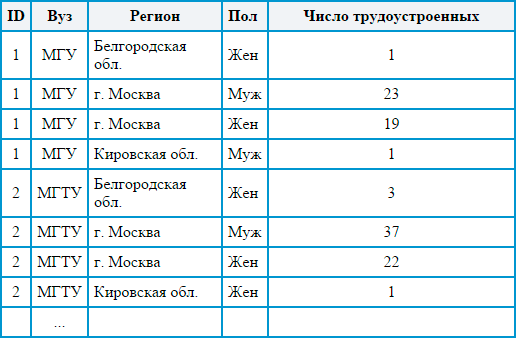
Согласитесь, второй вариант легче обработать автоматически при помощи формул и функций, да и выглядит он куда презентабельнее. Тут и уникальный идентификатор есть у каждого наблюдения, и значение каждой переменной можно отдельно выбрать, и в целом структура оказывается более логичной и простой для восприятия. Обработка таблиц в нормализованной форме оказывается лёгкой и быстрой при помощи средств автоматизации (как правило, для людей эта форма не всегда удобна). На основе таких данных R позволяет с лёгкостью строить разнообразные описательные диаграммы, наподобие той, что приведена ниже. Данные для диаграмм взяты с официального сайта Минобрнауки РФ.
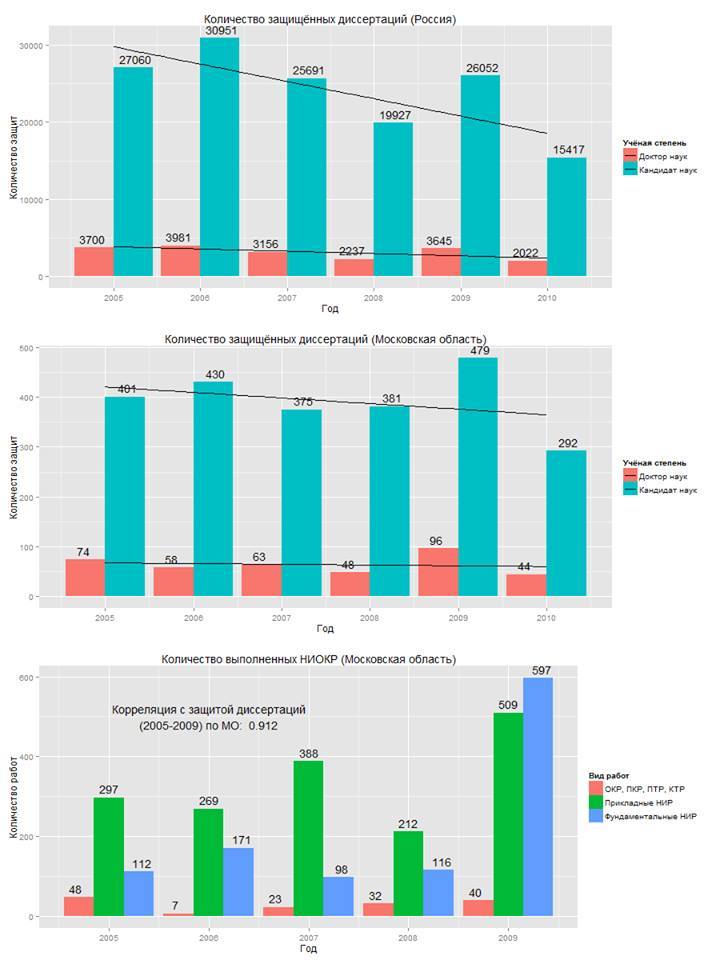
Стилистика диаграмм R мне нравится – они сочетают простоту со строгостью научного стиля и наглядностью. Функционал позволяет раскрашивать диаграммы, но этим всё же не стоит чрезмерно увлекаться – пользователям будет непросто сориентироваться в пестрящей всеми цветами радуги диаграмме. Помимо этого, диаграммы можно сохранить в отдельные файлы и в дальнейшем использовать как иллюстрации в научных статьях, презентациях или других работах. Между прочим, для построения одной диаграммы достаточно написать лишь простую строчку кода (хотя с предварительной обработкой данных для построения диаграммы иногда придётся повозиться).
Подводя итог этой части моего опуса, отмечу необычайную важность описанных в этом разделе шагов для проведения анализа на высоком уровне. В аналитике данных как и в работе с зенитными установками – если прицел собьётся хотя бы на полградуса, снаряд не попадёт по цели. Чтобы обеспечить высокую точность «прицела», нужно уже на первых этапах хорошенько подготовить данные к анализу, а также выяснить, на какие вопросы и каким образом они помогут ответить. Для второй цели очень помогает тот самый разведочный анализ данных – построенные уже на начальном этапе простейшие графики способны продемонстрировать базовые закономерности и даже в общих чертах ответить на вопрос о том, нужен ли дальнейший анализ и может ли он быть проведён на имеющихся данных или нет.
Документирование процесса обработки данных (курс 5)
Документирование чего бы то ни было всегда мне казалось невероятно скучным действом. Когда всё сделано и прекрасно работает, казалось бы, зачем документировать выполненные действия? Зачем порождать новые и новые документы? К чему вся эта макулатура?
Но в аналитике данных одного проведённого исследования и полученных результатов мало – чтобы убедить остальных представителей когорты аналитиков, необходимо поведать о том, как и над какими данными осуществлялась обработка. Так, если ваше исследование не смогут повторить, то грош цена такому исследованию. Поэтому в рамках одного из курсов DSS учат, как лучше всего документировать выполненную обработку данных. По сути, учат правилам хорошего тона в науке: сделал – расскажи всем, как сделал.
Документирование в рамках курса даётся довольно развёрнуто. Для этого процесса используется встроенный инструментарий RStudio. Документ, описывающий ваше исследование данных, будет создан на основе Rmd-файла, в котором вы как раз и опишете, как и над чем работали. Примеры документов можно найти вот тут.
Вообще, в рамках курса порекомендовали придерживаться примерно такой структуры подачи информации:
- резюме выполненных работ (включая цель);
- описание набора данных (расшифровка переменных, описание порядка получения, ссылки на наборы данных);
- описание процедуры предварительной обработки данных (очистка данных, нормализация);
- описание условий обработки данных (например, инициация значения счётчика случайных чисел);
- результаты разведочного анализа данных;
- результаты углублённого анализа;
- выводы;
- приложения: таблицы, графики и пр.
Конечно, это не панацея – от заданной структуры стоит отступить, если нужно описать что-то дополнительно или что-то описывать нецелесообразно. Тем не менее, именно такая структура позволяет читателю довольно быстро вникнуть в суть выполненного вами исследования и, при необходимости, повторить его.
Чем мне нравится R в плане документирования, так это тем, что в Rmd-файле можно текстовое описание снабжать врезками кода обработки данных, который при компиляции Rmd файла в PDF преобразуется в результаты обработки: результаты расчётов, красивые графики и так далее. На самом деле, это очень удобно – не нужно думать, куда и как добавлять очередную иллюстрацию.
Из Rmd-файла можно сформировать весьма аккуратный PDF или HTML документ (в том числе презентацию, но это уже немного другая история). Такой док не стыдно показать коллегам по цеху анализа данных. Да и для себя это будет полезно: уж поверьте, когда вы захотите спустя год вернуться к вашему исследованию, вы, скорее всего, и не вспомните, откуда брали данные, как их обрабатывали и зачем вообще проводили исследование.
Конец первой части
Читайте во второй части: Курсы по стат. обработке данных и машинному обучению; Практика: создание ПО для обработки данных (дипломный проект); другие полезные курсы на Курсере.
