Комментарии 32
Я бы изменил заголовок, это Linux (Android и серверные применения) надо готовиться
www.ixbt.com/news/2020/05/02/windows-huawei-harmonyos-2-0.html
Можете пролить свет на эту ОС?
значимость производительности одного ядра снижаетсяПочему тогда дорогой проприетарный ARM, а не RISC-V?
Наверно потому что "но до определенного предела" + дальше еще про коммуникации между ядрами написано.
А до определенного предела написал вот почему — все же производительность софта зачастую определяется самым узким местом, сериальной частью кода. Поэтому не особо верю, что RISC-V заработает «из коробки»…
В специфику своей работы, мне нам всегда требовались либо мощные процессоры (для серверов) и видеокарты с большим количеством CUDA ядер (машинное зрение и машинное обучение), а вот проекты, где нужно что то среднее, пока не встречались.
А какие у вас ворклоады, если не секрет?:)
Просто пока еще не создан чип с таким количеством ядер(~150 по моим оценкам), который смог бы это делать.
Вот такие?
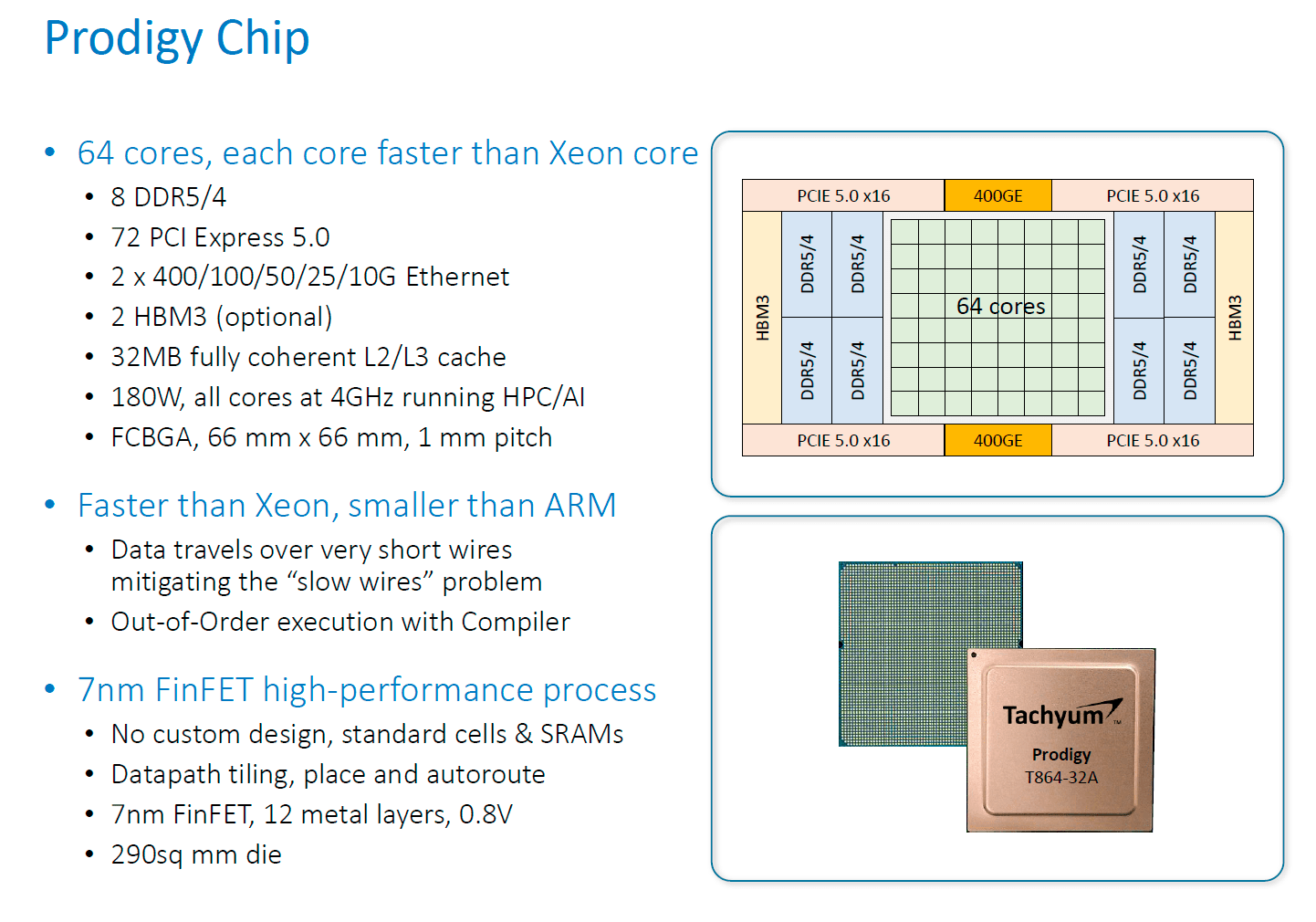
Чего-то попытался почитать про это, но так и не понял. Что за технология у них используется? ARM/MIPS/какая-то собственная? Их сайт больше похож на рекламную компанию хрен пойти чего.
Производства которое мы автоматизируем, на роботов которых мы делаем или лично на меня? )
Или на сервера от Huawei которые мы используем)))
Для понимания приведу пример обработки видеопотока, точнее время выполнения цикла процессов для полного выполнения задачи:
1. При обработке на процессоре на Сервере с выделенными для софта 32 ядрами цикл выполняется за 3минуты.
2. При обработке на видеокарте на ПК с GTX1070, полный цикл проходит за 30 секунд.
3. При обработке на видеокарте на Сервере с RTX2080 Super, завершается за 10 секунд.
Софт использует многопоточность, соответственно чем больше CUDA ядер, тем лучше. Может и на Асиках считать. И высоко производительные ядра тут не требуются.
По поводу машинного обучения. У нас для этого используется три RTX 2070.
Как бы изначально на них строили, так что сравнений с другим железом нет.
Fujitsu A64FX это сейчас самое топовое HPC решение по производительности среди CPU, обладающее эффективностью выше чем GPU.
www.nextplatform.com/2020/05/18/with-fugaku-supercomputer-installed-riken-takes-on-coronavirus
A64FX и ThunderX3 — 2 ARM процессора с производительностью > 3TFLOPS в DP.
Потому что критерием скорости 99% серверных приложений является время обработки одного запроса, а это в 99% случаев не параллелится (пока). Поэтому нужна большая single-thread производительность.
А при возникновении выбора — купить более дешевое, но слабое в single-thread производительсноти железо или использовать более простую, но CPU-затратную технологию (напр., Python вместо C++) — обычно выбирают второе, потому что труд программиста супердорог (по сравнению с другими профессиями в большинстве стран мира), и технологии надо упрощать, пусть и засчет увеличения потребления CPU.
Потому что критерием скорости 99% серверных приложений является время обработки одного запроса, а это в 99% случаев не параллелится (пока). Поэтому нужна большая single-thread производительность.
Это серверы. А для них в первую очередь имеет значение кол-во кол-во обработанных запросов в единицу времени (точнее, кол-во удовлетворенных юзеров), которое зависит и от кол-ва ядер и от их производительности.
Шардирование до бесконечности -> трата всей энергии земли.
…
Хотел написать по какому алгоритму желательно бы работали процы, но уже в с самом начале остановился на том, что это должен/ны решать какие-то отдельные ядра. А не будет ли при этом трата энергии на эти ядра больше, чем задача, которую они решают?
В текущих процах это скорее всего делает "кто-то" (не поднялась рука на "что-то") типа гипервизора. Судя по времени жизни от аккумов на разных смартах эти алгоритмы для этих гипервизорах отличаются сильно.
Потому что критерием скорости 99% серверных приложений является время обработки одного запроса, а это в 99% случаев не параллелится (пока). Поэтому нужна большая single-thread производительность.
так вроде бы у армов прогресс в этом направлении
Неожиданная встреча на Хабре. Привет-привет. Заодно узнал чем ты сейчас занимаешься)
Offtop off
Прогнозы дело не благородное. Я бы склонился к подходу ниши всякие нужны, ниши всякие важны. Пусть расцветают множество архитектур и решений, а уж мы потом выберем)
Это то на чем могут выстрелить сервера с ARM. Если нужен только inference, а не training, то Nvidia не нужна.
О тенденциях развития архитектуры процессоров, или почему я верю в успех Huawei на серверном рынке