Комментарии 7
Расскажите, как у вас инфраструктура (самого опенстека) восстанавливается после перехода очереди на другой узел rabbit'а. Ещё интереснее, как вы убеждаете это сделать все компоненты новы и нейтрона.
Детальное описание процесса node failure handling есть в официальной документации
Графически это можно представить так:
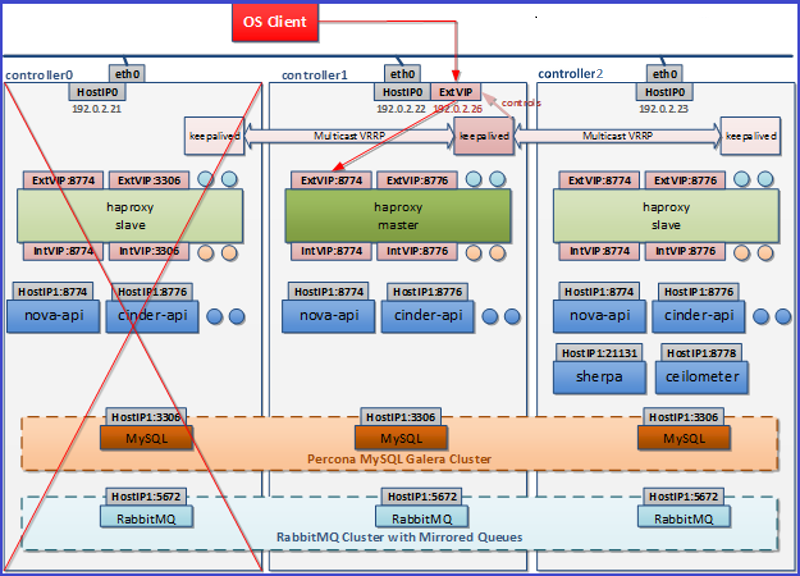
Графически это можно представить так:

В статье сказано, что «continue to operates». В то же время опытные товарищи, присутствующие в openstack-operators@, знают про замечательную фразу про 'rabbit croaks'. После чего надо идти и делать перезапуск всех сервисов, которые произвольным образом залипли на фейловере.
Я думал увидеть более детальное описание как вы с этой болью боритесь.
Я думал увидеть более детальное описание как вы с этой болью боритесь.
Как у вас с поддержкой bare metal инстансов (OpenStack Ironic)?
У вас есть планы поддерживать OpenStack Magnum?
У вас есть планы поддерживать OpenStack Magnum?
Можете ли вы пояснить на каких количествах одновременно запущенных виртуальных машин тестировалось данное решение? Есть ли информация о пределе, на котором ваше решение перестает работать корректно?
Out-of-box в текущей версии HP Helion OpenStack поддерживается до 100 физических узлов и до 4000 ВМ.
Есть техническая возможность реализации более крупных внедрений, что было сделано в ряде инсталляций, но это требует привлечения HP Helion Professional Services для детальной проработки архитектуры решения с последующим взятием его на поддержку.
В ожидаемом в конце года следующем релизе эти цифры с высокой вероятностью будут существенно увеличены за счет гораздо более гибкой и масштабируемой архитектуры развертывания, детали сообщить мы пока не можем.
Есть техническая возможность реализации более крупных внедрений, что было сделано в ряде инсталляций, но это требует привлечения HP Helion Professional Services для детальной проработки архитектуры решения с последующим взятием его на поддержку.
В ожидаемом в конце года следующем релизе эти цифры с высокой вероятностью будут существенно увеличены за счет гораздо более гибкой и масштабируемой архитектуры развертывания, детали сообщить мы пока не можем.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Высокая готовность облака HP Helion OpenStack