Представляю вам серию из двух постов, где я постараюсь рассказать о разработке довольно типового решения VDI для предприятия среднего размера. В первой части – подготовка к внедрению, планирование; во второй – реальные практически примеры.
Часто бывает так, что инфраструктура у нашего потенциального заказчика уже устоялась, и серьезные изменения в оборудовании недопустимы. Поэтому в рамках многих новых проектов возникают задачи по оптимизации работы текущего оборудования.
Например, у одного из заказчиков, крупной отечественной софтверной компании, имеется довольно большой парк серверов и систем хранения. В том числе — несколько серверов HP ProLiant 6-го и 7-го поколения и система хранения HP EVA, которые были в резерве. Именно на их базе нужно было разработать решение.
Озвученными требованиями к решению VDI были:
Мне предстояло просчитать какое количество серверов и систем хранения в итоге перейдут из резерва в состав решения.
В качестве среды виртуализации выбрана VMware. Схема работы получилась примерно такая:
Один из серверов выступает как connection broker, к нему подключаются клиенты. Connection broker выбирает из пула физических серверов на каком запустить виртуальную машину для обслуживания сессии.
Остальные серверы выступают ESX-гипервизорами, на которых запускаются виртуальные машины.
ESX-гипервизоры подключаются к системе хранения данных, на которой хранятся образы виртуальных машин.
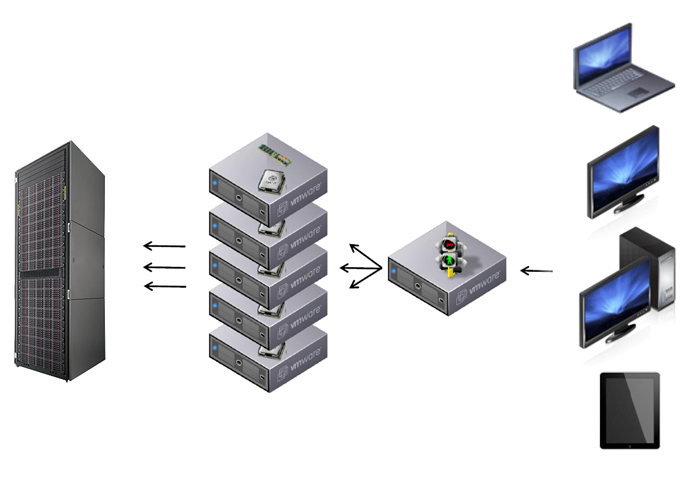
Под ESX-гипервизоры были отведены довольно мощные серверы с 6-ядерными процессорами Intel Xeon. При первом взгляде «слабым звеном» выступает система хранения данных, ведь для VDI скрытый убийца — это IOPS. Но конечно, при разработке VDI-решения нужно учесть еще много других моментов. Расскажу здесь о части из них:
И наконец, перейдем к I/O и основным связанным с вводом/выводом проблемам.
Windows, запущенная на локальном ПК с жестким диском, располагает примерно 40-50 IOPS’ами. Когда на таком ПК вместе с базовой ОС загружается набор сервисов – prefetching, сервисы индексации, сервисы аппаратной части и т.д. – часто это ненужный пользователю функционал, но он не несет больших потерь в производительности.
Но когда используется клиент VDI, почти все дополнительные сервисы контрпродуктивны — они производят большое количество запросов ввода/вывода в попытке оптимизировать скорость и время загрузки, но эффект получает обратным.
Также, Windows старается оптимизировать блоки данных таким образом, чтобы обращение к ним было по большей части последовательным, т.к. на локальном жестком диске для последовательного чтения и записи необходимо меньше перемещений головки жесткого диска. Для VDI этому нужно уделить особое внимание – см. в конце поста.
Число IOPS, которые требует клиент в большей степени зависит от сервисов, которые ему необходимы. В среднем, эта цифра составляет 10-20 IOPS (замерить величину IOPS, которая необходима в каждом конкретном случае, можно с помощью механизмов, которые предоставляет, например, Liquidware Labs). Большая часть IOPS — это операции на запись. В среднем в виртуальной инфраструктуре соотношение операций на чтение/запись может достигать 20/80.
Что все это значит в деталях:
1. Проблема boot/logon storms – кэш и политики, политики и кэш
В тот момент, когда пользователь обращается к своей виртуальной машине для входа создается большая нагрузка на дисковую подсистему. Наша задача – сделать эту нагрузку прогнозируемой, то есть свести большую ее часть к операциям чтения, а потом эффективно использовать выделенный кэш для типовых считываемых данных.
Чтобы достичь этого, необходимо оптимизирозать не только образ виртуальной машины клиента, но и профили пользователей. Когда это настроено правильно, нагрузка на IOPS становится вполне прогнозируемой величиной. В хорошо отлаженной виртуальной инфраструктуре соотношение чтение/запись на момент загрузки будет составлять 90/10 или даже 95/5.
Но если мы имеем дело с одновременным началом работы сразу большого количества пользователей, то система хранения данных должна быть довольно большой, иначе процесс входа в систему для некоторых пользователей может затянуться на несколько часов. Единственный выход: правильно рассчитать объем системы, зная максимальное число одновременных подключений.
Например, если образ загружается 30 секунд, и если в пиковое время число одновременных подключений пользователей — 10% от их общего числа, то это создает двухкратную нагрузку на запись и десятикратную нагрузку на чтение, что составляет 36% от нормальной загрузки хранилища. Если число одновременных подключений — 3%, то нагрузка на систему хранения возрастает только на 11% по сравнению с обычной загрузкой. Даем совет заказчику — поощряйте опоздания на работу! (шутка)
Но не нужно забывать, что пропорции «чтение/запись» после фазы загрузки меняются диаметрально: IOPS на чтение падает до 5 IOPS на сессию, но число IOPS на запись не уменьшается. Если об этом забыть, это привет к серьезным проблемам.
2. OPS систем хранения – выбираем правильный RAID
Когда запросы от пользователей приходят в общую систему хранения (SAN, iSCSI, SAS), то все операции ввода/вывода с точки зрения хранилища — на 100% случайные. Производительность диска со скоростью вращения 15 000 RPM составляет 150-180 IOPS, в системе хранения SAS/SATA диски в RAID-группе (относящиеся к ATA, т.е. все диски в RAID ждут синхронизации) дадут на 30% меньше производительности, чем IOPS одного SAS/SATA диска. Пропорции такие:
Поэтому для виртуализации рекомендуется применять RAID с большей производительностью на запись (RAID1, RAID0).
3. Расположение на диске – выравнивание важнее всего
Т.к. мы хотим минимизировать операции ввода/вывода от системы хранения — наша главная задача, чтобы каждая операция была наиболее эффективной. Расположение на диске — это один из главных факторов. Каждый байт, запрошенный у системы хранения не читается отдельно от других. В зависимости от вендора, данные в системе хранения раделяются на блоки 32 KB, 64 KB, 128 KB. Если файловая система поверх этих блоков не «выровнена» относительно этих блоков, то запрос 1 IOPS со стороны файловой системы даст запрос 2 IOPS со стороны системы хранения. Если же эта система сидит на виртуальном диске, а этот диск на файловой системе, которая не выровнена, то запрос 1 IOPS операционной системой в этом случае приведет к запросу 3 IOPS со стороны файловой системы. Это показывает, что выравнивание по всем уровням имеет первостепенное значение.

К сожалению, Windows XP и Windows 2003 создают сигнатуру на первой части диска в процессе установки операционной системы и начинают запись на последних секторах первого блока, это полностью сдвигает файловую систему ОС относительно блоков системы хранения. Чтобы это исправить необходимо создавать разделы, презентованные хосту или виртуальной машине с помощью утилит diskpart или fdisk. И назначать старт записи с сектора 128. Сектор — 512 байт и мы ставим начало записи точно на 64KB маркер. Как только раздел выровнен мы получим 1 IOPS от системы хранения на запрос от файловой системы.
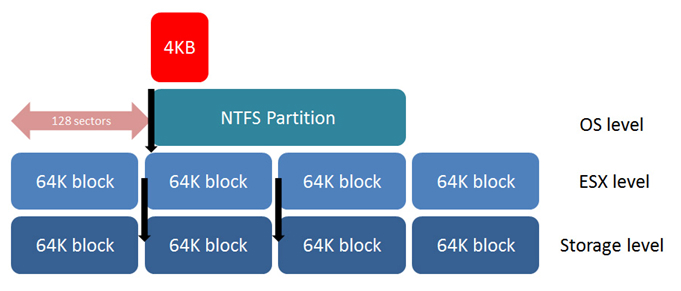
То же самое и для VMFS. Когда раздел создается через ESX Service Console, он не будет по умолчанию совпадать с системой хранения. В этом случае необходимо использовать fdisk или создавать раздел через VMware vCenter, который выполняет выравнивание автоматически. Windows Vista, Windows 7, Windows Server 2008 и более поздние продукты по умолчанию пытаются выровнять раздел на 1 MB, но лучше проверять выравнивание самостоятельно.
Увеличение производительности от выравнивания может составлять около 5% для больших файлов и 30-50% для маленьких файлов и random IOPS. И поскольку для VDI в больше степени характерна нагрузка random IOPS, то выравнивание имеет огромное значение.
4. Дефрагментация и prefetching должны быть отключены
Файловая система NTFS состоит из блоков по 4KB. К счастью, система Windows старается расположить блоки так, чтобы обращение было максимально последовательным. Когда пользователь запускает приложения, запросы в большей степени идут на запись, а не на чтение. Процесс дефрагментации же пытается угадать как данные будут читаться. Дефрагментация, в этом случае, генерирует нагрузку на IO не давая существенного положительно эффекта. Поэтому рекомендуется отключать процесс дефрагментации для решений VDI.
То же самое для процесса prefetching. Prefetching – это процесс, который помещает файлы, к которым идет больше всего обращений, в специальную кэш-директорию Windows так, чтобы чтение этих файлов было последовательным, минимизируя таким образом IOPS. Но поскольку запросы от большого числа пользователей делают IOPS совершенно случайными с точки зрения хранилища, то процесс prefetching не дает преимуществ, происходит только генерация трафика ввода/вывода «впустую». Выход — функция prefetching должна быть полностью отключена.
Если система хранения использует дедупликацию, то это еще один довод в пользу отключения функций prefetching и дефрагментации — процесс prefetching, перемещая файлы с одного диска на другой, серьезно снижает эффективность процесса дедупликации, для которого критично хранить таблицу редко изменяемых блоков данных диска.
Часто бывает так, что инфраструктура у нашего потенциального заказчика уже устоялась, и серьезные изменения в оборудовании недопустимы. Поэтому в рамках многих новых проектов возникают задачи по оптимизации работы текущего оборудования.
Например, у одного из заказчиков, крупной отечественной софтверной компании, имеется довольно большой парк серверов и систем хранения. В том числе — несколько серверов HP ProLiant 6-го и 7-го поколения и система хранения HP EVA, которые были в резерве. Именно на их базе нужно было разработать решение.
Озвученными требованиями к решению VDI были:
- Floating Desktops Pool (с сохранением изменений после окончания сессии);
- Начальная конфигурация — 700 пользователей, с расширением до 1000.
Мне предстояло просчитать какое количество серверов и систем хранения в итоге перейдут из резерва в состав решения.
В качестве среды виртуализации выбрана VMware. Схема работы получилась примерно такая:
Один из серверов выступает как connection broker, к нему подключаются клиенты. Connection broker выбирает из пула физических серверов на каком запустить виртуальную машину для обслуживания сессии.
Остальные серверы выступают ESX-гипервизорами, на которых запускаются виртуальные машины.
ESX-гипервизоры подключаются к системе хранения данных, на которой хранятся образы виртуальных машин.
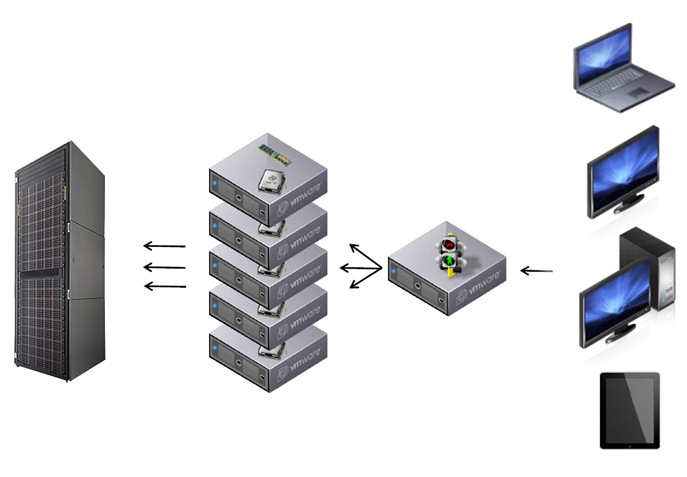
Под ESX-гипервизоры были отведены довольно мощные серверы с 6-ядерными процессорами Intel Xeon. При первом взгляде «слабым звеном» выступает система хранения данных, ведь для VDI скрытый убийца — это IOPS. Но конечно, при разработке VDI-решения нужно учесть еще много других моментов. Расскажу здесь о части из них:
- О чем необходимо помнить — весомую часть стоимости решения будут составлять лицензии на ПО. Чаще всего, выгоднее рассматривать предложения от хардверных вендоров, т.к. стоимость OEM-лицензий на ПО для виртуализации меньше.
- Во-вторых, стоит рассмотреть возможность установки карт графических ускорителей для работы большого количества пользователей с мультимедиа или в графических редакторах.
- Интересным решением у HP является блейд-сервер рабочих станций HP ProLiant WS460c Gen8. Его отличительная особенность: возможность установки графических карт прямо в блейд, не теряя пространство для 2-х жестких дисков, 2-х процессоров и 16 планок памяти. Графические ускорители поддерживают до 240 ядер CUDA, 2.0 ГБ памяти GDDR5 (интересное чтение здесь).
- В-третьих, необходимо просчитать заранее совокупную стоимость владения (она же TCO). Покупка оборудования — это, безусловно, большая трата, но можно и нужно показать экономию от внедрения решения, стоимость обновления и ремонта, а также стоимость продления лицензий на ПО.
И наконец, перейдем к I/O и основным связанным с вводом/выводом проблемам.
Windows, запущенная на локальном ПК с жестким диском, располагает примерно 40-50 IOPS’ами. Когда на таком ПК вместе с базовой ОС загружается набор сервисов – prefetching, сервисы индексации, сервисы аппаратной части и т.д. – часто это ненужный пользователю функционал, но он не несет больших потерь в производительности.
Но когда используется клиент VDI, почти все дополнительные сервисы контрпродуктивны — они производят большое количество запросов ввода/вывода в попытке оптимизировать скорость и время загрузки, но эффект получает обратным.
Также, Windows старается оптимизировать блоки данных таким образом, чтобы обращение к ним было по большей части последовательным, т.к. на локальном жестком диске для последовательного чтения и записи необходимо меньше перемещений головки жесткого диска. Для VDI этому нужно уделить особое внимание – см. в конце поста.
Число IOPS, которые требует клиент в большей степени зависит от сервисов, которые ему необходимы. В среднем, эта цифра составляет 10-20 IOPS (замерить величину IOPS, которая необходима в каждом конкретном случае, можно с помощью механизмов, которые предоставляет, например, Liquidware Labs). Большая часть IOPS — это операции на запись. В среднем в виртуальной инфраструктуре соотношение операций на чтение/запись может достигать 20/80.
Что все это значит в деталях:
1. Проблема boot/logon storms – кэш и политики, политики и кэш
В тот момент, когда пользователь обращается к своей виртуальной машине для входа создается большая нагрузка на дисковую подсистему. Наша задача – сделать эту нагрузку прогнозируемой, то есть свести большую ее часть к операциям чтения, а потом эффективно использовать выделенный кэш для типовых считываемых данных.
Чтобы достичь этого, необходимо оптимизирозать не только образ виртуальной машины клиента, но и профили пользователей. Когда это настроено правильно, нагрузка на IOPS становится вполне прогнозируемой величиной. В хорошо отлаженной виртуальной инфраструктуре соотношение чтение/запись на момент загрузки будет составлять 90/10 или даже 95/5.
Но если мы имеем дело с одновременным началом работы сразу большого количества пользователей, то система хранения данных должна быть довольно большой, иначе процесс входа в систему для некоторых пользователей может затянуться на несколько часов. Единственный выход: правильно рассчитать объем системы, зная максимальное число одновременных подключений.
Например, если образ загружается 30 секунд, и если в пиковое время число одновременных подключений пользователей — 10% от их общего числа, то это создает двухкратную нагрузку на запись и десятикратную нагрузку на чтение, что составляет 36% от нормальной загрузки хранилища. Если число одновременных подключений — 3%, то нагрузка на систему хранения возрастает только на 11% по сравнению с обычной загрузкой. Даем совет заказчику — поощряйте опоздания на работу! (шутка)
Но не нужно забывать, что пропорции «чтение/запись» после фазы загрузки меняются диаметрально: IOPS на чтение падает до 5 IOPS на сессию, но число IOPS на запись не уменьшается. Если об этом забыть, это привет к серьезным проблемам.
2. OPS систем хранения – выбираем правильный RAID
Когда запросы от пользователей приходят в общую систему хранения (SAN, iSCSI, SAS), то все операции ввода/вывода с точки зрения хранилища — на 100% случайные. Производительность диска со скоростью вращения 15 000 RPM составляет 150-180 IOPS, в системе хранения SAS/SATA диски в RAID-группе (относящиеся к ATA, т.е. все диски в RAID ждут синхронизации) дадут на 30% меньше производительности, чем IOPS одного SAS/SATA диска. Пропорции такие:
- В RAID5: 30-45 IOPS с диска на запись, 160 IOPS на чтение;
- В RAID1: 70-80 IOPS с диска на запись, 160 IOPS на чтение;
- В RAID0 140-150 IOPS с диска на запись, 160 IOPS на чтение.
Поэтому для виртуализации рекомендуется применять RAID с большей производительностью на запись (RAID1, RAID0).
3. Расположение на диске – выравнивание важнее всего
Т.к. мы хотим минимизировать операции ввода/вывода от системы хранения — наша главная задача, чтобы каждая операция была наиболее эффективной. Расположение на диске — это один из главных факторов. Каждый байт, запрошенный у системы хранения не читается отдельно от других. В зависимости от вендора, данные в системе хранения раделяются на блоки 32 KB, 64 KB, 128 KB. Если файловая система поверх этих блоков не «выровнена» относительно этих блоков, то запрос 1 IOPS со стороны файловой системы даст запрос 2 IOPS со стороны системы хранения. Если же эта система сидит на виртуальном диске, а этот диск на файловой системе, которая не выровнена, то запрос 1 IOPS операционной системой в этом случае приведет к запросу 3 IOPS со стороны файловой системы. Это показывает, что выравнивание по всем уровням имеет первостепенное значение.
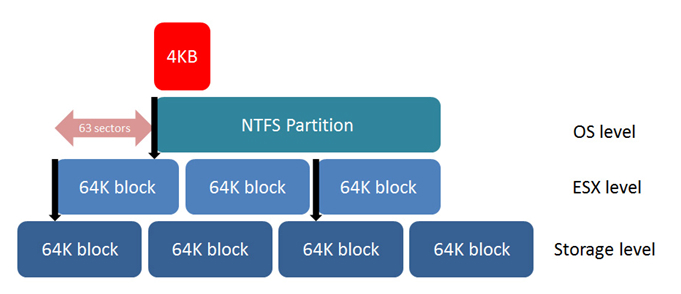
К сожалению, Windows XP и Windows 2003 создают сигнатуру на первой части диска в процессе установки операционной системы и начинают запись на последних секторах первого блока, это полностью сдвигает файловую систему ОС относительно блоков системы хранения. Чтобы это исправить необходимо создавать разделы, презентованные хосту или виртуальной машине с помощью утилит diskpart или fdisk. И назначать старт записи с сектора 128. Сектор — 512 байт и мы ставим начало записи точно на 64KB маркер. Как только раздел выровнен мы получим 1 IOPS от системы хранения на запрос от файловой системы.
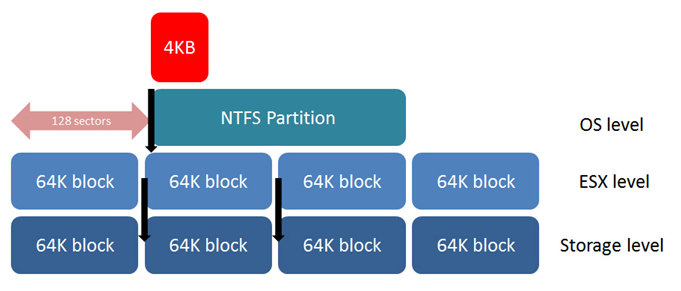
То же самое и для VMFS. Когда раздел создается через ESX Service Console, он не будет по умолчанию совпадать с системой хранения. В этом случае необходимо использовать fdisk или создавать раздел через VMware vCenter, который выполняет выравнивание автоматически. Windows Vista, Windows 7, Windows Server 2008 и более поздние продукты по умолчанию пытаются выровнять раздел на 1 MB, но лучше проверять выравнивание самостоятельно.
Увеличение производительности от выравнивания может составлять около 5% для больших файлов и 30-50% для маленьких файлов и random IOPS. И поскольку для VDI в больше степени характерна нагрузка random IOPS, то выравнивание имеет огромное значение.
4. Дефрагментация и prefetching должны быть отключены
Файловая система NTFS состоит из блоков по 4KB. К счастью, система Windows старается расположить блоки так, чтобы обращение было максимально последовательным. Когда пользователь запускает приложения, запросы в большей степени идут на запись, а не на чтение. Процесс дефрагментации же пытается угадать как данные будут читаться. Дефрагментация, в этом случае, генерирует нагрузку на IO не давая существенного положительно эффекта. Поэтому рекомендуется отключать процесс дефрагментации для решений VDI.
То же самое для процесса prefetching. Prefetching – это процесс, который помещает файлы, к которым идет больше всего обращений, в специальную кэш-директорию Windows так, чтобы чтение этих файлов было последовательным, минимизируя таким образом IOPS. Но поскольку запросы от большого числа пользователей делают IOPS совершенно случайными с точки зрения хранилища, то процесс prefetching не дает преимуществ, происходит только генерация трафика ввода/вывода «впустую». Выход — функция prefetching должна быть полностью отключена.
Если система хранения использует дедупликацию, то это еще один довод в пользу отключения функций prefetching и дефрагментации — процесс prefetching, перемещая файлы с одного диска на другой, серьезно снижает эффективность процесса дедупликации, для которого критично хранить таблицу редко изменяемых блоков данных диска.
