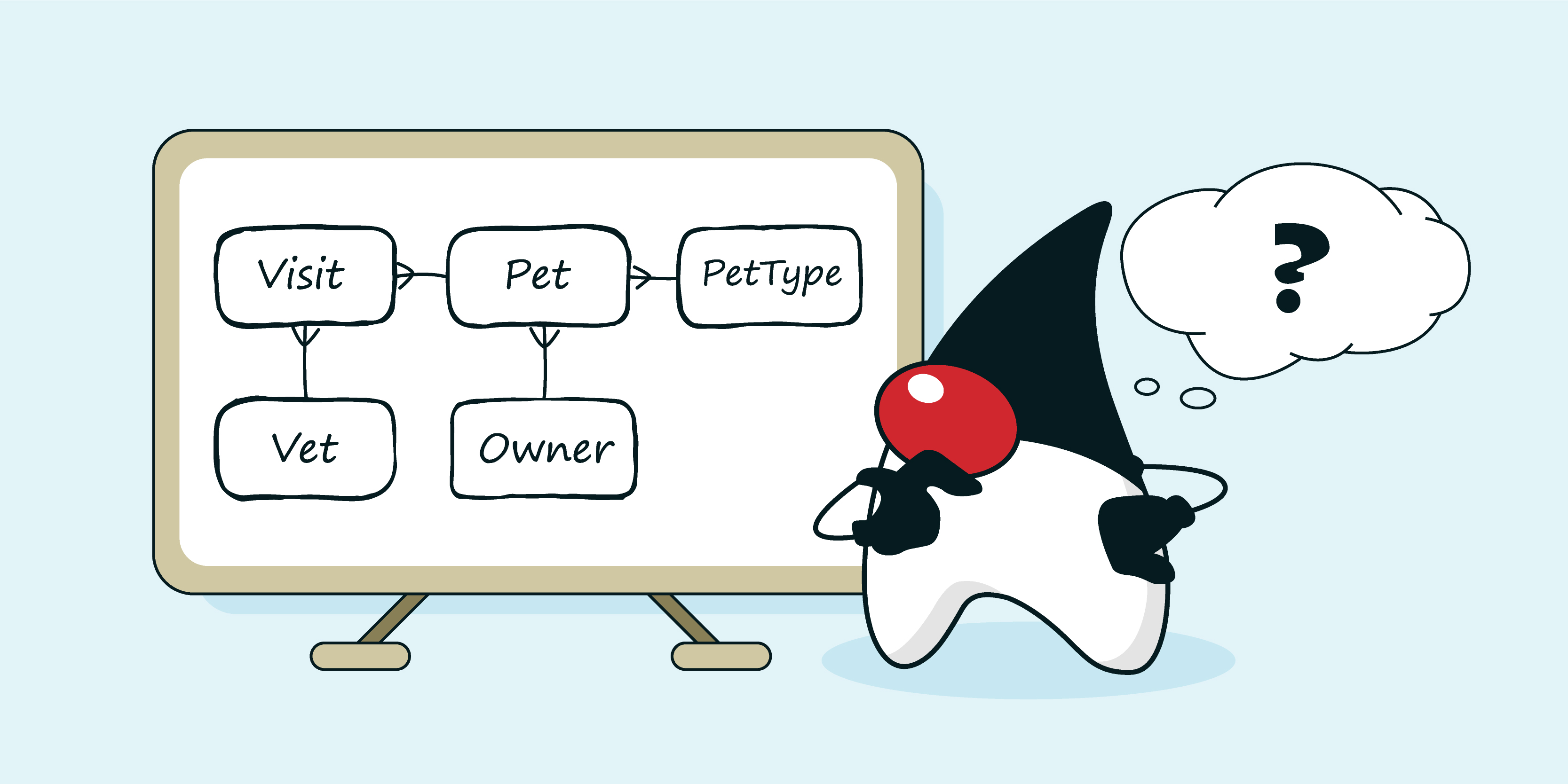
Введение
Практически любая информационная система так или иначе взаимодействует с внешними хранилищами данных. В большинстве случаев это реляционная база данных, и, зачастую, для работы с данными используется какой-либо ORM фреймворк. ORM устраняет большую часть рутинных операций, взамен предлагая небольшой набор дополнительных абстракций для работы с данными.
Мартин Фаулер опубликовал интересную статью, одна из ключевых мыслей там: “ORM’ы помогают нам решать большое количество задач в энтерпрайз приложениях… Этот инструмент нельзя назвать симпатичным, но и проблемы, с которыми он имеет дело, тоже не милашки. Я думаю, что ORM заслуживают больше уважения и больше понимания”
Мы очень интенсивно используем ORM во фреймворке CUBA, так что не понаслышке знаем о проблемах и ограничениях этой технологии, поскольку CUBA используется в различных проектах по всему миру. Есть много тем, которые можно обсудить в связи с ORM, но мы сосредоточимся на одной из них: выбор между “ленивым” (lazy) и “жадным” (eager) способами выборки данных. Поговорим о разных подходах к решению этой проблемы с иллюстрациями из JPA API и Spring, а также расскажем, как (и почему именно так) ORM используется в CUBA и какие работы мы ведем, чтобы улучшить работу с данными в нашем фреймворке.
Выборка данных: ленивая или нет?
Если в вашей модели данных только одна сущность, то никаких проблем при работе с ORM вы, скорее всего, не заметите. Давайте рассмотрим небольшой пример. Пусть у нас есть сущность User (Пользователь), у которой есть два атрибута: ID и Name (Имя):
public class User {
@Id
@GeneratedValue
private int id;
private String name;
//Getters and Setters here
}Чтобы вытащить экземпляр этой сущности из БД, нам нужно всего лишь вызвать один метод объекта EntityManager:
EntityManager em = entityManagerFactory.createEntityManager();
User user = em.find(User.class, id);Все становится немного интереснее, когда появляется отношение “один-ко-многим”:
public class User {
@Id
@GeneratedValue
private int id;
private String name;
@OneToMany
private List<Address> addresses;
//Getters and Setters here
}Если нам нужно извлечь из БД экземпляр пользователя, возникает вопрос: “А адреса тоже выбираем?”. И “правильный” ответ здесь: “Зависит от...” В некоторых случаях нам адреса будут нужны, в некоторых — нет. Обычно ORM предоставляет два способа выборки зависимых записей: ленивый и жадный. По умолчанию в большинстве ORM используется ленивый способ. Но, если мы напишем такой код:
EntityManager em = entityManagerFactory.createEntityManager();
User user = em.find(User.class, 1);
em.close();
System.out.println(user.getAddresses().get(0));… то получим исключение “LazyInitException”, которое ужасно сбивает с толку новичков, которые только начали работать с ORM. И тут наступает момент, когда нужно начинать рассказ о том, что такое “Attached” и “Detached” экземпляры сущности, что такое сессии и транзакции.
Ага, значит сущность должна быть “присоединена” к сессии, чтобы можно было выбирать зависимые данные. Хорошо, давайте не будем сразу закрывать транзакции, и жизнь сразу станет проще. И тут возникает другая проблема — транзакции становятся длиннее, что увеличивает риск взаимной блокировки. Делать транзакции короче? Можно, но если создавать много-много маленьких транзакций, то получим “Сказку про Комара Комаровича — длинный нос и про мохнатого Мишу — короткий хвост” про то, как орда крохотных комаров медведя победила — так получится и с базой данных. Если число мелких транзакций значительно возрастет, то возникнут проблемы с производительностью.
Как было сказано, при выборке данных о пользователе адреса могут или потребоваться или нет, поэтому, в зависимости от бизнес-логики, нужно или делать выборку коллекции, или нет. Нужно добавлять новые условия в код… Гммм… Что-то как-то все усложняется.
Так, а если попробовать другой тип выборки?
public class User {
@Id
@GeneratedValue
private int id;
private String name;
@OneToMany(fetch = FetchType.EAGER)
private List<Address> addresses;
//Getters and Setters here
}Ну… нельзя сказать, что это сильно поможет. Да, избавимся от ненавистного LazyInit и не надо проверять, прикреплена сущность к сессии или нет. Но теперь у нас могут возникнуть проблемы с производительностью, потому что адреса нам нужны не всегда, а мы все равно выбираем эти объекты в память сервера.
Ещё идеи?
Spring JDBC
Некоторые разработчики настолько устают от ORM, что переключаются на альтернативные фреймворки. Например, на Spring JDBC, который предоставляет возможность преобразования реляционных данных в объектные в “полуавтоматическом” режиме. Разработчик пишет запросы для каждого случая, где нужен тот или иной набор атрибутов (или один и тот же код повторно используется для случаев, где нужны одинаковые структуры данных).
Это дает нам большую гибкость. Например, можно выбрать только один атрибут, не создавая соответствующий объект-сущность:
String name = this.jdbcTemplate.queryForObject(
"select name from t_user where id = ?",
new Object[]{1L}, String.class);Или выбрать объект в привычном виде:
User user = this.jdbcTemplate.queryForObject(
"select id, name from t_user where id = ?",
new Object[]{1L},
new RowMapper<User>() {
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setName(rs.getString("name"));
user.setId(rs.getInt("id"));
return user;
}
});Также можно выбрать и список адресов для пользователя, нужно только написать чуть больше кода и правильно составить SQL запрос, чтобы избежать проблемы n+1 запроса.
Тааак, опять сложновато. Да, мы контролируем все запросы и то, как данные отображаются на объекты, но надо писать больше кода, учить SQL и знать, как запросы выполняются в базе данных. Лично я думаю, что знание SQL — это обязательный навык для прикладного программиста, но так думают не все, и я не собираюсь вступать в полемику. В конце концов, знание инструкций x86 ассемблера в наши дни тоже необязательно. Давайте лучше подумаем о том, как облегчить жизнь программистам.
JPA EntityGraph
А давайте сделаем шаг назад и подумаем, что нам вообще нужно? Похоже, что нам просто надо указывать, какие точно атрибуты нам нужны в каждом конкретном случае. Ну и давайте это делать! В JPA 2.1 появился новый API — EntityGraph (граф сущностей). Идея — очень простая: используем аннотации для того, чтобы описать то, что будем выбирать из базы. Вот пример:
@Entity
@NamedEntityGraphs({
@NamedEntityGraph(name = "user-only-entity-graph"),
@NamedEntityGraph(name = "user-addresses-entity-graph",
attributeNodes = {@NamedAttributeNode("addresses")})
})
public class User {
@Id
@GeneratedValue
private int id;
private String name;
@OneToMany(fetch = FetchType.LAZY)
private Set<Address> addresses;
//Getters and Setters here
}Для данной сущности описано два графа: user-only-entity-graph не выбирает атрибут Addresses (помеченный как lazy), в то время, как второй граф указывает ORM выбирать этот атрибут. Если мы пометим Addresses как eager, то граф будет проигнорирован и адреса будут выбраны в любом случае.
Итак, в JPA 2.1 можно делать выборку данных вот так:
EntityManager em = entityManagerFactory.createEntityManager();
EntityGraph graph = em.getEntityGraph("user-addresses-entity-graph");
Map<String, Object> properties = Map.of("javax.persistence.fetchgraph", graph);
User user = em.find(User.class, 1, properties);
em.close();Этот подход сильно упрощает работу, не нужно отдельно думать про lazy атрибуты, и длину транзакций. Дополнительный бонус — граф применяется на уровне SQL запроса, таким образом “лишние” данные не выбираются в Java приложение. Но есть одна небольшая проблема: нельзя сказать, какие атрибуты были выбраны, а какие — нет. Для проверки есть API, это делается при помощи класса PersistenceUtil:
PersistenceUtil pu = entityManagerFactory.getPersistenceUnitUtil();
System.out.println("User.addresses loaded: " + pu.isLoaded(user, "addresses"));Но это довольно-таки уныло и не все готовы делать такие проверки. А можно ещё что-нибудь упростить и просто не показывать атрибуты, которые не были выбраны?
Проекции Spring
В Spring Framework есть отличная штука, которая называется “Проекции” (и это не то же самое, что проекции в Hibernate). Если нужно выбрать только некоторые атрибуты сущности, то создается интерфейс с нужными атрибутами, и Spring выбирает “экземпляры” этого интерфейса из БД. В качестве примера, рассмотрим следующий интерфейс:
interface NamesOnly {
String getName();
}Теперь можно определить Spring JPA репозиторий для выборки сущностей User следующим образом:
interface UserRepository extends CrudRepository<User, Integer> {
Collection<NamesOnly> findByName(String lastname);
}В этом случае, после вызова метода findByName, в полученном списке мы получим сущности, у которых доступ открыт только к атрибутам, которые определены в интерфейсе! По такому же принципу можно выбирать и зависимые сущности, т.е. выбираем сразу отношение “master-detail”. Более того, Spring генерирует “правильный” SQL в большинстве случаев, т.е. из БД выбираются только те атрибуты, которые описаны в проекции, это очень похоже на то, как работают графы сущностей.
Это очень мощный API, при определении интерфейсов можно использовать выражения SpEL, использовать классы с какой-то встроенной логикой вместо интерфейсов и ещё много чего, в документации все расписано очень подробно.
Единственная проблема с проекциями в том, что внутри они реализованы в виде пар “ключ — значение”, т.е. предназначены только для чтения. А это значит, что, даже если мы и определим setter метод для проекции, то изменения сохранить не сможем ни через CRUD репозитории, ни через EntityManager. Так что проекции — это такие DTO, которые можно преобразовать обратно в Entity и сохранять, только если написать свой собственный код для этого.
Как выбираются данные в CUBA
С самого начала разработки фреймворка CUBA мы старались оптимизировать часть кода, который работает с БД. В CUBA мы используем EclipseLink как основу для API доступа к данным. Что хорошо в EclipseLink — он с самого начала поддерживал частичную загрузку сущностей, и это стало решающим фактором в выборе между ним и Hibernate. В EclipseLink можно было указать атрибуты для загрузки задолго до того, как появился стандарт JPA 2.1. В CUBA существует собственный способ описания графа сущностей, называется CUBA Views (представления CUBA). Представления CUBA — довольно-таки развитый API, можно наследовать одни представления от других, комбинировать их, применяя как к master, так и к detail сущностям. Ещё одна мотивация для создания CUBA представлений — мы хотели использовать короткие транзакции, чтобы можно было работать с открепленными сущностями в пользовательском web-интерфейсе.
В CUBA представления описываются в XML файле, как в примере ниже:
<view class="com.sample.User"
extends="_minimal"
name="user-minimal-view">
<property name="name"/>
<property name="addresses"
view="address-street-only-view"/>
</property>
</view>Это представление выбирает сущность User и его локальный атрибут name, а также выбирает адреса, применяя к ним представление address-street-only-view. Все это происходит (внимание!) на уровне SQL запроса. Когда представление создано, можно его использовать в выборке данных при помощи класса DataManager:
List<User> users = dataManager.load(User.class).view("user-edit-view").list();Этот подход отлично работает, при этом экономно расходуя сетевой трафик, поскольку неиспользуемые атрибуты просто не передаются от БД к приложению, но, как и в случае с JPA, есть проблема: нельзя сказать, какие атрибуты сущности были загружены. И в CUBA есть исключение “IllegalStateException: Cannot get unfetched attribute [...] from detached object”, которое, как и LazyInit, наверняка встречалось всем, кто пишет с использованием нашего фреймворка. Как и в JPA, есть способы проверки того, какие атрибуты были загружены, а какие нет, но, опять же, написание таких проверок — нудное, кропотливое занятие, которое очень расстраивает разработчиков. Нужно придумать что-то ещё, чтобы не нагружать людей работой, которую, в теории, могут сделать машины.
Концепт — CUBA View Interfaces
А что, если все-таки попробовать совместить графы сущностей и проекции? Мы решили попробовать это сделать и разработали интерфейсы для представления сущностей (entity view interfaces), которые повторяют подход из проекций Spring. Эти интерфейсы транслируются в CUBA представления при старте приложения и могут быть использованы в DataManager. Идея проста: описываем интерфейс (или набор интерфейсов), который и представляет из себя граф сущностей.
interface UserMinimalView extends BaseEntityView<User, Integer> {
String getName();
void setName(String val);
List<AddressStreetOnly> getAddresses();
interface AddressStreetOnly extends BaseEntityView<Address, Integer> {
String getStreet();
void setStreet(String street);
}
}Стоит отметить, что для каких-то конкретных случаев можно делать локальные интерфейсы, как в случае AddressStreetOnly из примера выше, чтобы не “загрязнять” публичный API своего приложения.
В процессе старта CUBA приложения (бОльшая часть которого — это инициализация контекста Spring), мы программно создаем CUBA представления и помещаем их во внутренний бин — репозиторий в контексте.
Теперь нужно немного изменить имплементацию класса DataManager, чтобы он принимал представления-интерфейсы, и можно делать выборку сущностей вот таким образом:
List<UserMinimalView> users = dataManager.load(UserMinimalView.class).list();Под капотом генерируется прокси-объект, который реализует интерфейс и оборачивает экземпляр сущности, выбранный из БД (примерно так же, как это делается в Hibernate). И, когда разработчик обращается за значением атрибута, то прокси делегирует вызов метода “настоящему” экземпляру сущности.
При разработке этого концепта мы пытаемся убить одним выстрелом двух зайцев:
- Данные, которые не описаны в интерфейсе, не загружаются в приложение, тем самым мы экономим ресурсы сервера.
- Разработчик может использовать только те атрибуты, которые доступны через интерфейс (и, следовательно, выбраны из БД), тем самым убираются
UnfetchedAttributeисключения, про которые мы писали выше.
В отличие от проекций Spring, мы оборачиваем сущности в прокси-объекты, кроме того, каждый интерфейс наследует стандартный интерфейс CUBA — Entity. Это значит, что атрибуты Entity View можно изменять, а потом сохранять эти изменения в БД, используя стандартный API CUBA для работы с данными.
И, кстати, “третий заяц” — можно делать атрибуты доступными только для чтения, если определить интерфейс только с getter методами. Таким образом, мы уже на уровне API сущности задаем правила модификации.
В дополнение, можно сделать некоторые локальные операции для открепленных сущностей, используя доступные атрибуты, например, преобразование строки имени, как в примере ниже:
@MetaProperty
default String getNameLowercase() {
return getName().toLowerCase();
}Заметьте, что вычисляемые атрибуты можно вынести из модели классов сущностей и перенести в интерфейсы, применимые к конкретной бизнес логике.
Ещё одна интересная возможность — наследование интерфейсов. Можно сделать несколько представлений с разными наборами атрибутов, а затем их комбинировать. Например, можно создать интерфейс для сущности User с атрибутами name и email, и другой — с атрибутами name и addresses. Теперь, если нужно выбирать name, email и addresses, то не нужно копировать эти атрибуты в третий интерфейс, нужно просто унаследоваться от первых двух представлений. И да, экземпляры третьего интерфейса можно передавать в методы, которые принимают параметры с типом интерфейсов-родителей, правила ООП одинаковы для всех.
Также было реализовано преобразование между представлениями — в каждом интерфейсе есть метод reload(), в который можно передать класс представления в качестве параметра:
UserFullView userFull = userMinimal.reload(UserFullView.class);Представление UserFullView может содержать дополнительные атрибуты, так что сущность будет загружена заново из БД, если необходимо. И этот процесс — отложенный. Обращение к БД будет произведено только тогда, когда произойдет первое обращение к атрибутам сущности. Это немного замедлит первое обращение, но такой подход был выбран намеренно — если экземпляр сущности используется в модуле “web”, в котором находится UI и собственные REST контроллеры, то этот модуль может быть развернут на отдельном сервере. А это значит, что принудительная перегрузка сущности создаст дополнительный сетевой трафик — обращение к модулю core и затем к БД. Таким образом, откладывая перегрузку до того момента, когда это необходимо, мы экономим трафик и уменьшаем количество запросов к БД.
Концепт оформлен в виде модуля для CUBA, пример использования можно скачать с GitHub.
Заключение
Кажется, что в ближайшем будущем мы все ещё будем массово использовать ORM в энтерпрайз приложениях просто потому, что нам нужно что-то, что будет превращать реляционные данные в объекты. Конечно, для сложных, уникальных, сверхвысоконагруженных приложений будут разрабатываться какие-то специфичные решения, но, похоже, что ORM фреймворки будут жить столько же, сколько реляционные базы данных.
В CUBA мы стараемся упростить работу с ORM по максимуму, и в следующих версиях мы будем вводить новые возможности для работы с данными. Будут ли это интерфейсы-представления или что-то другое — сейчас сложно сказать, но я уверен в одном: мы будем продолжать упрощать работу с данными в следующих версиях фреймворка.
