
Еще одна статья от лица участника школы о проекте, реализованном в рамках очередного выезда:
«Я – Дмитрий Пасечнюк, и я хочу поделиться своим исследованием, сделанном на каникулах в рамках выездной весенней смены Школы GoTo под руководством Александра Петрова, asash, технического директора компании E-Contenta.
Как нам известно, онлайн-кинотеатры достаточно распространены и способны приносить неплохой доход. Но, как и в любом бизнесе, это не происходит само по себе. Одним из важных условий успешности онлайн-кинотеатра является грамотное составление предложений для просморта.
В каждом кинотеатре, будь то онлайн или реальный кинотеатр, есть сотрудник, занимающийся репертуарным планированием. Именно он определяет, какие фильмы будут показывать на экранах. Кинопрокатный процесс имеет свои подводные камни. Для того, чтобы выбрать удачный фильм, требуется учесть не только стоимость покупки прав, но и тысячу других нюансов. Системы отбора фильмов, как таковой не существует и зачастую фильмы выбираются, опираясь на собственное «чутье», рейтинг ожидания и экспертное мнение.
Принятие ответственного решения – тяжелое моральное бремя для человека, с одной стороны, с другой — всегда существуют риски излишнего влияния личностных и ситуационных факторов на принимаемое решение.
Современные технологии призваны облегчить труд людей, и в данном случае ожидания оправданы.
В своем исследовании я попробовал переложить задачу ранжирования фильмов в соответствии с ожиданиями целевой аудитории онлайн-кинотеатра с человека на машину. Безусловно, в общей постановке эта задача более сложная, и данное решение является только первым шагом. В дальнейшем я планирую продолжить исследования в этом направлении.
Обо всем по порядку под катом.
Подход к решению задачи
Для получения списка фильмов для обучения и тестирования моделей машинного обучения я использовал датасет с сайта GroupLens (MovieLens 20M Dataset ml-20m.zip).
Для получения списка анонсированных на 2018 год фильмов для тестирования алгоритма использовался TMDb API (the Movie Database API developers.themoviedb.org/3/getting-started).
Для получения информации о фильмах, такой как список актеров, режиссеров, краткое описание по их IMDb ID использовался SimAPI.
Наше решение было реализовано на языке Python с использованием библиотеки Scikit-learn, содержащей реализации основных алгоритмов машинного обучения.
Для решения задачи из фильмов были выделены следующие признаки: one-hot encoding признака жанры; год съемки; известный актер, режиссер, и страна производства фильма; tf-idf для 50 самых весомых слов в тексте по описанию фильма и усредненный по всем словам в описании (за исключением стоп-слов) word2vec.
В качестве целевой переменной использовалась доля активной в плане выставления оценок фильмам аудитории MovieLens, поставившая оценку конкретному фильму. Ниже представлены 15 наиболее весомых при предсказании популярности фильма признаков и их веса, определенные алгоритмом Random Forest.

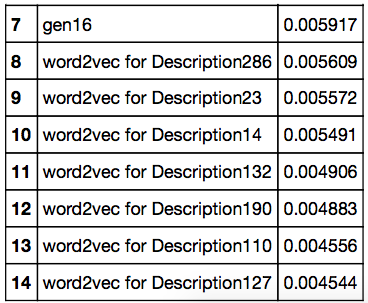
Для обучения и валидации изначальная выборка фильмов MovieLens была поделена в отношении 99:1, причем любой из фильмов в обучающей выборке вышел раньше любого фильма из валидационной выборки, что позволило избежать таких проблем, как знание алгоритмом того, какие фильмы будут иметь популярность после того момента, когда появится необходимость спрогнозировать популярность еще не вышедшего фильма (в тот момент мы не сможем точно сказать, какие фильмы будут актуальны в будущем).
Для определения качества работы алгоритма мы использовали долю количества уникальных пользователей MovieLens, просмотревших как минимум один из 10, 50, 200 фильмов, определенных алгоритмом как наиболее популярные от общего размера аудитории.
На валидационной выборке были протестированы такие алгоритмы, как Линейная регрессия, Случайный лес, K-ближайших соседей, Дерево решений и Градиентный бустинг над решающими деревьями. Результаты тестирования представлены в следующей таблице:

(В строке под номером 0 представлено значение определенной метрики для случая, когда нам известна целевая переменная).
Результаты первого этапа
Оптимальным из протестированных алгоритмом в плане определенной метрики качества показал себя Random Forest. Коэффициент корреляции Пирсона между реальными значениями целевой переменной и прогнозируемыми данным алгоритмом значениями равен 0.826. Ниже представлена диаграмма рассеяния для этих величин.
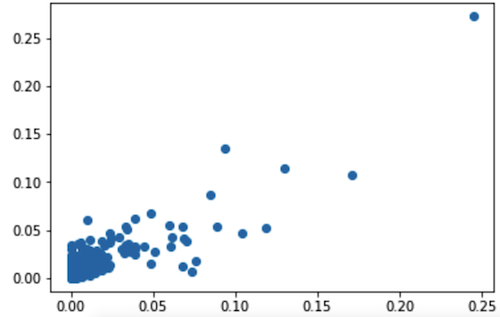
Далее, мы решили проверить, соответствуют ли результаты выбранного алгоритма фактическим результатам. Получили следующее: если ранжировать фильмы по доле целевой аудитории, интересующейся фильмом, предсказанной алгоритмом и вывести результат, то мы увидим, что те фильмы, которые оказались в первой пятерке действительно имели достаточно большое количество просмотров относительно размера аудитории MovieLens, а остальные фильмы действительно находятся в TOP 20-30, но при этом на более низких местах (ранжировались фильмы за период с 2001 по 2002 гг. в кол-ве 150 штук)

Совершенствование алгоритма
После получения списка отранжированных по популярности фильмов мы заинтересовались, какой жанр доминирует на верхних позициях списка. Оказалось, что большинство фильмов, находящихся на верхних позициях являются драмами. По этой причине, в том случае, если бы мы просто брали N фильмов с верхних позиций списка и показывали бы в кинотеатре только эти фильмы, то мы скорее всего потеряли бы определенную часть аудитории, ведь некоторые люди любят смотреть не только драмы, а, например, документальные фильмы или ужасы.
Мы предположили, что оптимальным выходом из данной проблемы будет следующая схема формирования набора фильмов: для каждого фильма считать его “популярность”, как произведение результата, возвращаемого нашим алгоритмом для данного фильма на “популярность” жанра данного фильма.
Первым делом мы построили для каждого жанра гистограммы, на которых по оси абсцисс отложили количество фильмов X данного жанра, а по оси ординат отложили долю людей, просмотревших X фильмов данного жанра за промежуток времени с 1993 по 2003 г. от общей аудитории MovieLens. Результаты представлены ниже:

Далее было необходимо выбрать метрику популярности жанра. Оптимальным вариантом из протестированных оказалась нормированная сумма просмотров фильмов данного жанра каждым человеком из аудитории MovieLens. В результате каждый из жанров получил следующие баллы “популярности”:

Результаты второго этапа
Мы решили сравнить результаты, демонстрируемые усовершенствованной версией алгоритма с изначальной версией алгоритма, и получили следующие результаты. Если построить график, где по оси абсцисс отложено кол-во фильмов, которые необходимо отобрать для формирования ленты кинопроката, а по оси ординат <качество работы изначального алгоритма> — <качество работы нового алгоритма>, то получим следующий результат:

Как видно из графика, усовершенствованный нами в процессе работы алгоритм демонстрирует более высокое качество на отрезке X ∈ [60, 225], при этом демонстрирует такие же результаты при больших значениях X.
В целом, для формирования долгосрочных списков фильмов для закупки данный алгоритм вполне может использоваться.
Тестирование алгоритма в реальных условиях
Тестирование проводилось на списке фильмов, анонсированных на 2018 год, полученных с помощью The Movie DB API в количестве 128 штук. Отбирать меньше 60 фильмов из данного количества может не иметь смысла, а в совокупности с тем, что в реальных условиях “граница прибыльности” нового алгоритма может несколько сместиться вправо, было решено тестировать изначальный алгоритм. Если вывести отранжированный список фильмов и баллы их “популярности”, то получается следующее:
Первые 24 фильма в списке

Последние 24 фильма в списке
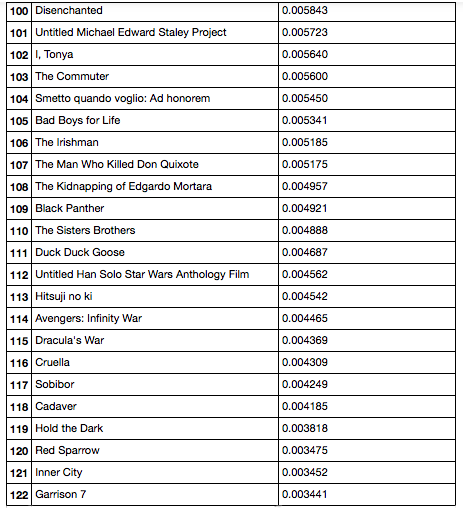
Если посмотреть на данный список, то в первой его части можно увидеть можно увидеть достаточно перспективные фильмы, например на позициях 4, 8, 9, 10, 12, 17, 18. Если посмотреть на последние фильмы в списке, то эти фильмы в целом не носят явной привлекательности, содержание их, также, не сильно впечатляют, разве что за исключением фильма на позиции 114. Почему так получилось? — если посмотреть на список признаков этого фильма, то можно увидеть, что режиссеров данного фильма нет в списке всех режиссеров (что может говорить только о том, что фильмов данной серии в обучающей выборке не было), а также нет информации о жанрах (возможно TMDb API и/или SimAPI, просто не нашли информации об этом фильме).
Перспективы
Изначально поставленная нами задача ранжирования новых фильмов по популярности была решена. Этот алгоритм станет частью продакшн-решения. При этом, это далеко не конец работы.
В дальнейшем мы планируем увеличить количество признаков, в том числе включив в них историю поиска фильма в Google и Яндекс, данные об отзывах о фильме (средняя тональность отзывов на наиболее популярных сервисах), а также данные об успешности фильмов, близких к рассматриваемому в плане содержания описания. Также возможно предсказывать долю аудитории, интересующейся фильмом, усредняя вероятность просмотра конкретного фильма каждым (из всех, или из какой-то доли всех) пользователем.»
Спасибо вам за внимание, а Дмитрию за статью. Будем рады любым идеям проектов от вас для новых школ, пишите на school@goto.msk.ru.
