

Недавно перед нами встала задача развернуть Dgraph в кластере Kubernetes. В этой статье я поделюсь полученным опытом: с чем мы столкнулись во время деплоя и последующего использования этого приложения в различных окружениях, от dev до production.
Что вообще такое Dgraph? Это горизонтально масштабируемая графовая (GraphQL) база данных с открытым кодом, созданная в стартапе Dgraph Labs. Краткое сравнение её основных возможностей с другими подобными решениями приведено здесь. В целом же не буду подробно останавливаться на описании Dgraph, т.к. на хабре уже была подробная статья о причинах появления проекта и особенностях реализации. Для желающих начать практическое знакомство с Dgraph также рекомендую официальную документацию.
В контексте статьи нам важно знать, что инсталляция Dgraph состоит из следующих компонентов:
- Dgraph Zero, который контролирует кластер Dgraph, присваивает серверы группам и балансирует данные между группами серверов;
- Dgraph Alpha, содержащий предикаты и индексы;
- Ratel — пользовательский интерфейс.
Деплой в Kubernetes
Для деплоя в Kubernetes мы использовали Helm-чарт, предлагаемый в официальной документации проекта. По умолчанию он разворачивает по 3 экземпляра Dgraph Zero и Dgraph Alpha (в StatefulSet'ах), а также один Deployment с Ratel.
Значительных модификаций чарта мы не производили, хотя изменили число реплик, добавили requests/limits, node affinity, tolerations и добавили дополнительный контейнер (nginx) в pod’ы компонента Alpha (о его назначении см. ниже) и Ingress для отдачи дампа.
Особенности Ratel
После деплоя чарта кластер Dgraph успешно собрался: никаких дополнительных манипуляций для этого не потребовалось, все работает «из коробки». Чтобы увидеть это собственными глазами и убедиться, что кластер собрался, достаточно в веб-браузере зайти в Ratel (например, по ClusterIP сервиса
ratel-public), во вкладку «Cluster». Вот как выглядит страница, когда у нас одна группа узлов Alpha: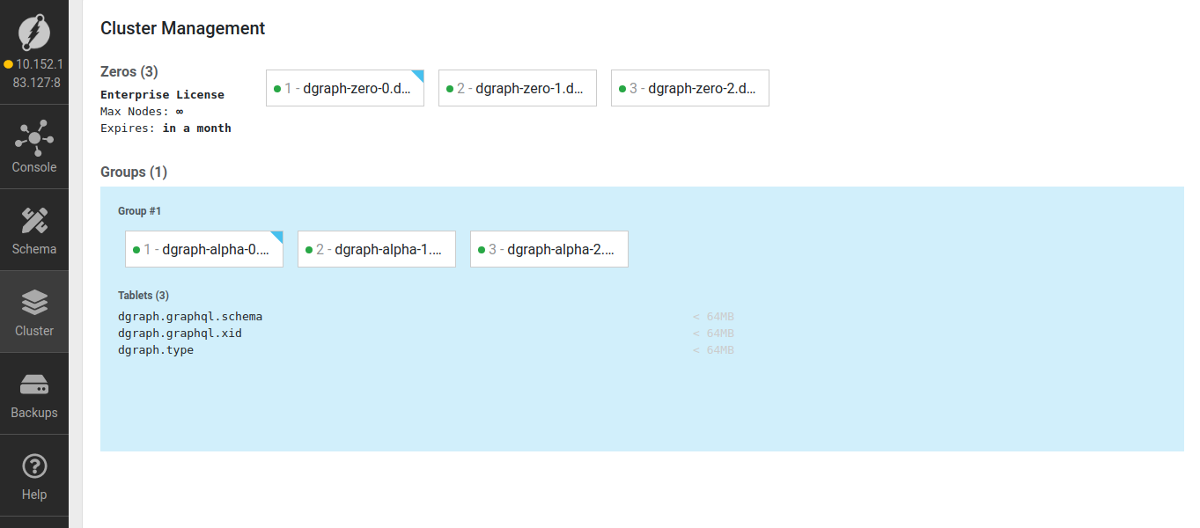
А вот — когда две:
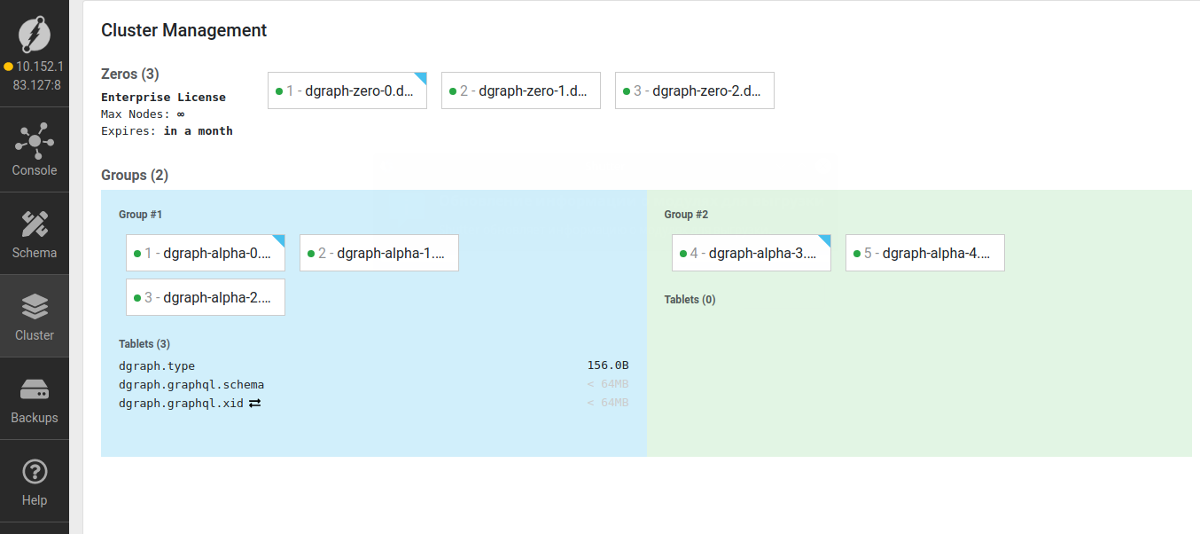
В данной вкладке отображаются группы узлов, состав каждой группы экземпляров Alpha, а также шарды в этих группах. Из данного интерфейса можно вручную назначать шарды на нужную группу узлов.
Здесь же мы столкнулись и с первой особенностью полученной инсталляции: Ratel работает в режиме direct access mode, то есть мы обращаемся к серверу Dgraph напрямую из браузера.
Все заголовки, с которыми мы «приходим» в Ratel, пробрасываются в запрос к Dgraph Alpha — это стоит учитывать, если вы хотите использовать базовую авторизацию или HTTPS при добавлении Ingress для Ratel и Dgraph Server (Alpha). Также стоит учитывать, что при работе с Dgraph через Ratel конечный пользователь должен иметь доступ как до Ratel, так и до Server: иначе подключение не произойдет, так как сам Ratel в коннекте к серверу не участвует и никакие запросы не проксирует.
Примечание по масштабированию и шардированию
Dgraph шардирует данные между группами узлов. По умолчанию мы имеем настройку по 3 узла на группу, а чартом в начале статьи выкатывается 3 реплики Alpha и 3 Zero. Соответственно, если будет добавлен 4-й экземпляр Alpha, Zero создаст еще одну группу узлов, на 7-м экземпляре — 3-ю группу и т.д.
Поскольку часть данных будет находиться в новой группе, это важно учитывать при экспорте данных. Экспорт может пригодиться, например, для восстановления данных в другом окружении или для бэкапа. В случае, когда в Dgraph не одна группа узлов, необходимо делать экспорт с любого экземпляра из каждой группы и импортировать файлы дампа либо в группы узлов аналогично источнику (если на принимающей стороне у нас несколько групп), либо по очереди в одну группу узлов. Последнее может потребоваться, например, при переносе production-базы с несколькими группами в dev-окружение с единственным инстансом.
Теперь — подробнее об операциях экспорта/импорта в контексте реальных задач.
Возможности экспорта и импорта
При использовании Dgraph у нас была потребность в организации стендов для разработки, идентичных production, т.е. содержащих тот же набор данных. В нашем случае в production- и dev-окружениях по одной группе узлов.
Dgraph имеет два инструмента для загрузки файлов экспорта:
- Bulk Loader используется для инициализации нового кластера Dgraph с существующими данными;
- Live Loader — для импорта данных в уже работающий кластер.
Поскольку мы делали импорт данных с production-окружения в dev, необходимости инициализировать кластер при каждом импорте не было. Для такой задачи подходит второй инструмент — Live Loader.
В pod с Alpha мы добавили контейнер с nginx для раздачи файлов экспорта, а в pod'ы Dgraph — скрипты для экспорта и импорта. Получившаяся конфигурация скриптов импорта и экспорта выглядела следующим образом:
apiVersion: v1
kind: ConfigMap
metadata:
name: dump-scripts
data:
dump.sh: |
#!/bin/bash
mkdir -p /dgraph/export
rm -rf /dgraph/export/*
curl localhost:8080/admin/export
LAST_DIR=$(ls -ltr /dgraph/export/ | grep '^d' | tail -1| awk '{print $NF}')
LAST_RDF=$(ls -t /dgraph/export/"$LAST_DIR" | grep rdf | head -n1)
LAST_SCHEMA=$(ls -t /dgraph/export/"$LAST_DIR" | grep 'schema' | head -n1)
cp /dgraph/export/"$LAST_DIR"/"$LAST_RDF" /dgraph/export/rdf.gz
cp /dgraph/export/"$LAST_DIR"/"$LAST_SCHEMA" /dgraph/export/schema.gz
chmod -R 755 /dgraph/export
restore.sh: |
#!/bin/bash
mkdir -p /dgraph/restored
rm -rf /dgraph/restored/*
curl -o /dgraph/restored/rdf.gz https://someurl/export/rdf.gz
curl -o /dgraph/restored/schema.gz https://someurl/export/schema.gz
dgraph live -f /dgraph/restored/rdf.gz --format=rdf -s /dgraph/restored/schema.gz -z dgraph-zero-0.dgraph-zero.${POD_NAMESPACE}.svc.cluster.local:5080Далее остается лишь запускать
dump.sh в pod'е dgraph-alpha в окружении-источнике и restore.sh в окружении, где требуется получить актуальную БД.Описанная схема будет актуальна и для обновления между разными версиями Dgraph. Переключение между минорными версиями мы пока не пробовали, но просто изменить тег образа, скажем, с 1.2.6 на 20.03.3 и запустить Dgraph с теми же данными, ожидаемо, не выйдет. Зато успешно проходит обновление через инициализацию нового кластера версии 20.03.3 и последующую загрузку в него файла экспорта из 1.2.6.
Заключение
По имеющемуся у нас сейчас опыту, Dgraph работает стабильно: при запуске этой БД в эксплуатацию с Kubernetes в production-среде проблем не возникало. В документации проекта есть отдельный раздел, посвящённый разворачиванию БД в K8s. Кстати, ее авторы сообщают, что проверяли запуск в Kubernetes 1.14 и 1.15 для GKE и EKS, а в нашем случае инсталляция работает в K8s 1.16 на bare metal.
На что стоит обратить внимание?
- Когда групп экземпляров Alpha становится несколько (просто >1), следите за балансировкой шардов, чтобы избежать неравномерной нагрузки на экземпляры групп.
- Как написано выше, есть особенности в работе с графическим интерфейсом (Ratel). Хотя лично нам ограничения, связанные с direct access mode, не показались критичными.
P.S.
Читайте также в нашем блоге:
