
В основу этой статьи легла наша внутренняя документация для DevOps-инженеров, объясняющая, как работает Prometheus под управлением Prometheus Operator в разворачиваемых и обслуживаемых кластерах Kubernetes.

С первого взгляда Prometheus может показаться достаточно сложным продуктом, но, как и любая хорошо спроектированная система, она состоит из явно выраженных функциональных компонентов и по сути делает всего три вещи: а) собирает метрики, б) выполняет правила, в) сохраняет результат в базу данных временных рядов (time series). Статья посвящена не столько самому Prometheus, сколько интеграции этой системы с Kubernetes, для чего мы активно используем вспомогательный инструмент под названием Prometheus Operator. Но начать всё же необходимо с самого Prometheus…
Итак, если подробнее остановиться на двух первых функциях Prometheus, то они работают следующим образом:
У сервера Prometheus есть config и rule files (файлы с правилами).
В config имеются следующие секции:
Общий алгоритм работы Prometheus выглядит следующим образом:
В
Таким образом, Prometheus сам отслеживает:
Изменение конфига требуется в следующих случаях:
Разобравшись с основами Prometheus, перейдём к его «оператору» — специальному вспомогательному компоненту для Kubernetes, упрощающему развёртывание и эксплуатацию Prometheus в реалиях кластера.
Для пресловутого «упрощения», во-первых, в Prometheus Operator с помощью механизма CRD (Custom Resource Definitions) заданы три ресурса:
Во-вторых, оператор следит за ресурсами
Наконец, оператор также следит за ресурсами
Под состоит из двух контейнеров:

Под использует три тома (volumes):
Подробнее о том, как мы используем Prometheus (и не только) для мониторинга в Kubernetes, я планирую рассказать на конференции RootConf 2018, что будет проходить 28 и 29 мая в Москве, — приходите послушать и пообщаться.
Читайте также в нашем блоге:

С первого взгляда Prometheus может показаться достаточно сложным продуктом, но, как и любая хорошо спроектированная система, она состоит из явно выраженных функциональных компонентов и по сути делает всего три вещи: а) собирает метрики, б) выполняет правила, в) сохраняет результат в базу данных временных рядов (time series). Статья посвящена не столько самому Prometheus, сколько интеграции этой системы с Kubernetes, для чего мы активно используем вспомогательный инструмент под названием Prometheus Operator. Но начать всё же необходимо с самого Prometheus…
Prometheus: что он делает?
Итак, если подробнее остановиться на двух первых функциях Prometheus, то они работают следующим образом:
- Для каждой цели мониторинга (target), каждый
scrape_interval, выполняется HTTP-запрос к этой цели. В ответ получаются метрики в своём формате, которые сохраняются в базу. - Каждый
evaluation_intervalобрабатываются правила (rules), на основании которых:- или отправляются алерты,
- или записываются (себе же в базу) новые метрики (результат выполнения правила).
Prometheus: как он настраивается?
У сервера Prometheus есть config и rule files (файлы с правилами).
В config имеются следующие секции:
-
scrape_configs— настройки поиска целей для мониторинга (подробнее см. в следующем разделе); -
rule_files— список директорий, где лежат правила, которые необходимо загружать:
rule_files: - /etc/prometheus/rules/rules-0/* - /etc/prometheus/rules/rules-1/* -
alerting— настройки поиска Alertmanager'ов, в которые отправляются алерты. Секция очень похожа наscrape_configsс тем отличием, что результатом её работы является список endpoints, в которые Prometheus будет отправлять алерты.
Prometheus: откуда берётся список целей?
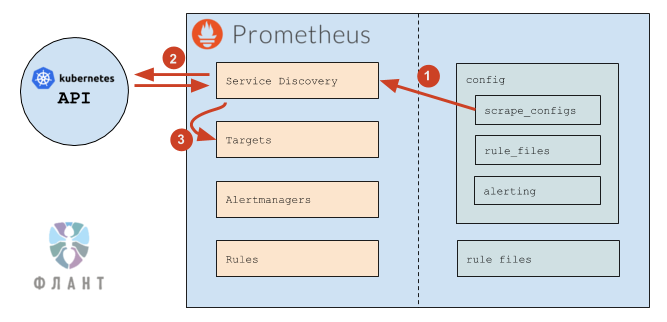
Общий алгоритм работы Prometheus выглядит следующим образом:

- Prometheus читает секцию конфига
scrape_configs, согласно которой настраивает свой внутренний механизм обнаружения сервисов (Service Discovery). - Механизм Service Discovery взаимодействует с Kubernetes API (в основном для получения endpoints).
- На основании данных из Kubernetes механизм Service Discovery обновляет Targets (список целей).
В
scrape_configs указан список scrape job'ов (это внутреннее понятие Prometheus), каждый из которых определяется следующим образом:scrape_configs:
# Общие настройки
- job_name: kube-prometheus/custom/0 # просто название scrape job'а
# показывается в разделе Service Discovery
scrape_interval: 30s # как часто собирать данные
scrape_timeout: 10s # таймаут на запрос
metrics_path: /metrics # path, который запрашивать
scheme: http # http или https
# Настройки Service Discovery
kubernetes_sd_configs: # означает, что targets мы получаем из Kubernetes
- api_server: null # использовать адрес API-сервера из переменных
# окружения (которые есть в каждом поде)
role: endpoints # targets брать из endpoints
namespaces:
names: # искать endpoints только в этих namespaces
- foo
- baz
# Настройки "фильтрации" (какие enpoints брать, какие — нет) и "релейблинга"
# (какие лейблы добавить или удалить — для всех получаемых метрик)
relabel_configs:
# Фильтр по значению лейбла prometheus_custom_target,
# полученного из service, связанного с endpoint
- source_labels: [__meta_kubernetes_service_label_prometheus_custom_target]
regex: .+ # подходит любой НЕ пустой лейбл
action: keep
# Фильтр по имени порта
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: http-metrics # подходит, если порт называется http-metrics
action: keep
# Добавляем лейбл job, используем значение лейбла prometheus_custom_target
# у service, к которому добавляем префикс "custom-"
#
# Лейбл job — служебный в Prometheus. Он определяет название группы,
# в которой будет показываться target на странице targets, а также он будет
# у каждой метрики, полученной у этих targets (чтобы можно было удобно
# фильтровать в rules и dashboards)
- source_labels: [__meta_kubernetes_service_label_prometheus_custom_target]
regex: (.*)
target_label: job
replacement: custom-$1
action: replace
# Добавляем лейбл namespace
- source_labels: [__meta_kubernetes_namespace]
regex: (.*)
target_label: namespace
replacement: $1
action: replace
# Добавляем лейбл service
- source_labels: [__meta_kubernetes_service_name]
regex: (.*)
target_label: service
replacement: $1
action: replace
# Добавляем лейбл instance (в нём будет имя пода)
- source_labels: [__meta_kubernetes_pod_name]
regex: (.*)
target_label: instance
replacement: $1
action: replaceТаким образом, Prometheus сам отслеживает:
- добавление и удаление подов (при добавлении/удалении подов Kubernetes изменяет endpoints, а Prometheus это видит и добавляет/удаляет цели);
- добавление и удаление сервисов (точнее, endpoints) в указанных пространствах имён (namespaces).
Изменение конфига требуется в следующих случаях:
- нужно добавить новый scrape config (обычно это новый вид сервисов, которые надо мониторить);
- нужно изменить список пространств имён.
Разобравшись с основами Prometheus, перейдём к его «оператору» — специальному вспомогательному компоненту для Kubernetes, упрощающему развёртывание и эксплуатацию Prometheus в реалиях кластера.
Prometheus Operator: что он делает?
Для пресловутого «упрощения», во-первых, в Prometheus Operator с помощью механизма CRD (Custom Resource Definitions) заданы три ресурса:
-
prometheus— определяет инсталляцию (кластер) Prometheus; -
servicemonitor— определяет, как мониторить набор сервисов (т.е. собирать их метрики); -
alertmanager— определяет кластер Alertmanager'ов (мы ими не пользуемся, поскольку отправляем метрики напрямую в свою систему уведомлений, которая принимает, агрегирует и ранжирует данные из множества источников — в том числе, интегрируется со Slack и Telegram).
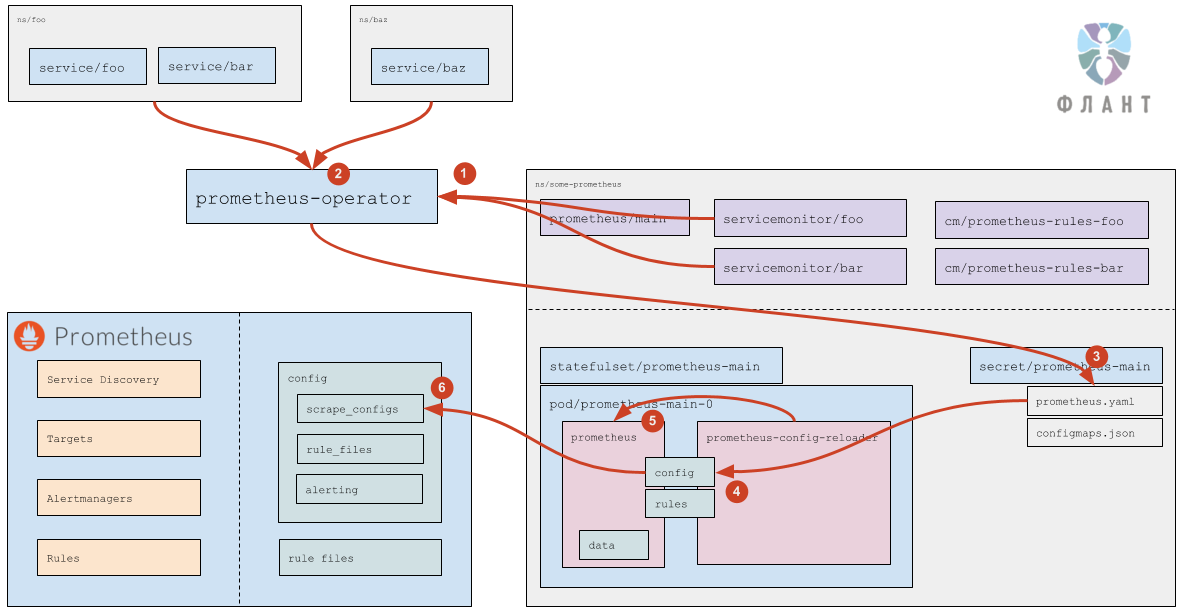
Во-вторых, оператор следит за ресурсами
prometheus и генерирует для каждого из них:- StatefulSet (с самим Prometheus);
- Secret с
prometheus.yaml(конфиг Prometheus) иconfigmaps.json(конфиг дляprometheus-config-reloader).
Наконец, оператор также следит за ресурсами
servicemonitor и за ConfigMaps с правилами, и на их основании обновляет конфиги prometheus.yaml и configmaps.json (они хранятся в секрете).Что в поде с Prometheus?
Под состоит из двух контейнеров:
-
prometheus— сам Prometheus; -
prometheus-config-reloader— обвязка, которая следит за изменениямиprometheus.yamlи при необходимости вызывает reload конфигурации Prometheus (специальным HTTP-запросом — см. подробнее ниже), а также следит за ConfigMaps с правилами (они указаны вconfigmaps.json— см. подробнее ниже) и по необходимости скачивает их и перезапускает Prometheus.

Под использует три тома (volumes):
-
config— примонтированный секрет (два файла:prometheus.yamlиconfigmaps.json). Подключён в оба контейнера; -
rules—emptyDir, который наполняетprometheus-config-reloader, а читаетprometheus. Подключён в оба контейнера, но вprometheus— в режиме только для чтения; -
data— данные Prometheus. Подмонтирован только вprometheus.
Как обрабатываются Service Monitors?

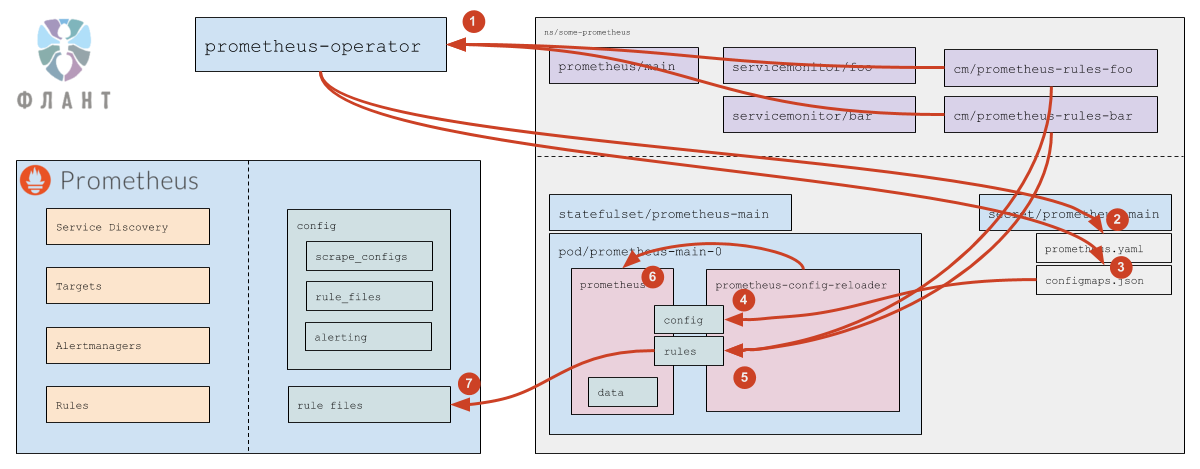
- Prometheus Operator читает Service Monitors (а также следит за их добавлением/удалением/изменением). Какие именно Service Monitors — указано в самом ресурсе
prometheus(подробнее см. в документации). - Для каждого Service Monitor, если в нём не указан конкретный список namespaces (т.е. указано
any: true), Prometheus Operator вычисляет (обращаясь к Kubernetes API) список пространств имён, в которых есть Services, подходящие под лейблы, указанные в Service Monitor. - На основании прочитанных ресурсов
servicemonitor(см. документацию) и на основании вычисленных пространств имён, Prometheus Operator генерирует часть конфига (секциюscrape_configs) и сохраняет конфиг в соответствующий секрет. - Штатными средствами самого Kubernetes данные из секрета приходят в под (файл
prometheus.yamlобновляется). - Изменение файла замечает
prometheus-config-reloader, который по HTTP отправляет запрос в Prometheus на перезагрузку. - Prometheus перечитывает конфиг и видит изменения в
scrape_configs, которые обрабатывает уже согласно своей логике работы (см. подробнее выше).
Как обрабатываются ConfigMaps с правилами?

- Prometheus Operator следит за ConfigMaps, подходящими под
ruleSelector, указанный в ресурсеprometheus. - Если появился новый (или был удален существующий) ConfigMap, Prometheus Operator обновляет
prometheus.yaml, после чего срабатывает логика, в точности соответствующая обработке Service Monitors (см. выше). - Как в случае добавления/удаления ConfigMap, так и при изменении содержимого ConfigMap, Prometheus Operator обновляет файл
configmaps.json(в нём указан список ConfigMaps и их контрольные суммы). - Штатными средствами самого Kubernetes данные из секрета приходят в под (файл
configmaps.jsonобновляется). - Изменение файла замечает
prometheus-config-reloader, который скачивает изменившиеся ConfigMaps в директориюrules(этоemptyDir). - Тот же
prometheus-config-reloaderотправляет по HTTP запрос в Prometheus на перезагрузку. - Prometheus перечитывает конфиг и видит изменившиеся правила.
Вот и всё!
Подробнее о том, как мы используем Prometheus (и не только) для мониторинга в Kubernetes, я планирую рассказать на конференции RootConf 2018, что будет проходить 28 и 29 мая в Москве, — приходите послушать и пообщаться.
P.S.
Читайте также в нашем блоге:
- «Мониторинг и Kubernetes (обзор и видео доклада)»;
- «Операторы для Kubernetes: как запускать stateful-приложения»;
- «Мониторинг с Prometheus в Kubernetes за 15 минут»;
- «Истории успеха Kubernetes в production. Часть 4: SoundCloud (авторы Prometheus)»;
- «Представляем loghouse — Open Source-систему для работы с логами в Kubernetes»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Инфраструктура с Kubernetes как доступная услуга».
