Привет, Хабр! Меня зовут Сергей, я Lead Software Engineer/Stream Lead в ЕРАМ, сертифицированный Google Cloud инженер и архитектор. Уже более 10 лет занимаюсь коммерческой разработкой для различных глобальных компаний, в основном с фокусом на бэкенд. А еще я очень люблю делиться своими знаниями. Сегодня хочу рассказать про Apache Airflow, который, на мой взгляд, является хорошим инструментом для построения ваших пайплайнов.
Какой план?
В двух словах расскажу про Airflow для тех, кто еще с ним не работал. Все это более подробно можно найти на просторах интернета, поэтому пройдусь лишь по базовым концепциям.
Посмотрим, что такое Google Cloud Composer, как он использует Airflow и упрощает разработку на реальных проектах.
Взглянем на development и deployment практики в рамках Google Cloud Composer, а также трудности и ограничения, с которыми можно столкнуться во время запуска Airflow в Cloud Composer.
И, конечно же, я поделюсь полезными инструментами, которые можно использовать в работе.
Airflow в нескольких абзацах
Итак, это инструмент для планирования, построения и мониторинга пайплайнов, написанных на Python. Есть и другие готовые решения для оркестровки процессов, например Luigi. Но сейчас поговорим о достоинствах Airflow:
Действительно хорош для построения пайплайнов. В основе всего у него стоит направленный ацикличный граф, который позволяет реализовывать последовательное или параллельное исполнение задач, а еще управлять их порядком и зависимостями.
Достаточно расширяем. Сегодня существуют много open-sourse решений либо библиотек, которые можно к нему подключить и использовать.
Веб-интерфейс: простой, хороший и удобный.
Идет в пачке с REST API, а значит запускать пайплайны или получать информацию о их состоянии мы можем с помощью API.
Рассмотрим ETL-pipeline из “живого” проекта. Предположим, у нас есть файлы разных типов в GCS бакете. Их необходимо скачать, прочитать содержимое, агрегировать все данные с разных файлов, а затем записать полученный результат. Кроме того, перед началом и в момент завершения пайплайна нужно отправить запрос на обновление статуса сервису, который хранит информацию о пайплайнах.

Разберемся со строительными блоками Airflow. Первым идет DAG (Directed Acyclic Graph) — ацикличный направленный граф, основа Airflow. В целом это коллекция задач, которые мы хотим запустить. Они организованы специальным образом, могут иметь между собой зависимости.
Tasks определяют единицу работы DAG и выражены как его узлы. Если проще, то задачи обозначают, что конкретно нам нужно сделать. А Operators в свою очередь описывают, как мы хотим это сделать, конкретизируют действия в рамках задачи. На картинке хорошо видно, что задачи — это узлы DAG-а. Они являются сущностями разных операторов — DataLoadOperator, GoogleCloudStorageListOperator и UpdateStatusOperator — каждый из которых описывает некую единицу логики, которую нужно будет сделать. Как видно, некоторые задачи, выстроенные в DAG-е, могут выполняться параллельно. Все зависит от типа исполнителя задач и количества воркеров.
Eще есть DAGs Run и Tasks Instances. DAGs Run — это объект самого DAGа, предназначенный к запуску в конкретные логические время и дату. Tasks Instance — объект задачи, ассоциированный с конкретным DAG Run. А логические дата и время для DAG Run и его Tasks Instances — это execution date.
Комбинируя операторы в DAG для того, чтобы составлять списки и порядок задач, мы можем строить комплексные и достаточно сложные pipeline-ы.
Плавно переходим к компонентам, которые участвуют в исполнении пайплайна внутри Airflow:
Планировщик (Scheduler) мониторит все DAG-и, задачи и отвечает за их своевременный запуск и отправку на исполнение.
Исполнители (или Executor) — сущность, которая следит за организацией исполнения задач. Они бывают разные: SequentialExecutor, CeleryExecutor и др. А некоторые из исполнителей могут иметь дополнительные зависимости. Например, CeleryExecutor требует Queue Broker.
Воркеры (Workers) просто исполняют наши задачи (подобно воркерам Celery).
Веб-сервер нужен, чтобы при помощи, например, тех же HTTP-запросов, предоставлять информацию по DAG-ам и задачам. Он взаимодействует с базой, где хранятся данные о статусе задач, переменных Airflow, DAG-ах, соединениях и т. д.
Вся информация про исполнение задач пишется в Logs. Логирование происходит во время исполнения задач из самого кода, а также пишутся системные логи Airflow. Местом хранения логов могут быть просто файлы, база данных либо какое-нибудь решение от сloud-провайдера. Например, можно писать в Stackdriver или в GCS bucket .
С помощью Admin Panel мы активируем/деактивируем и запускаем DAG-и, устанавливаем переменные, смотрим логи, находим причины проблем (например, почему пайплайны “упали”).
Как это все работает вместе?
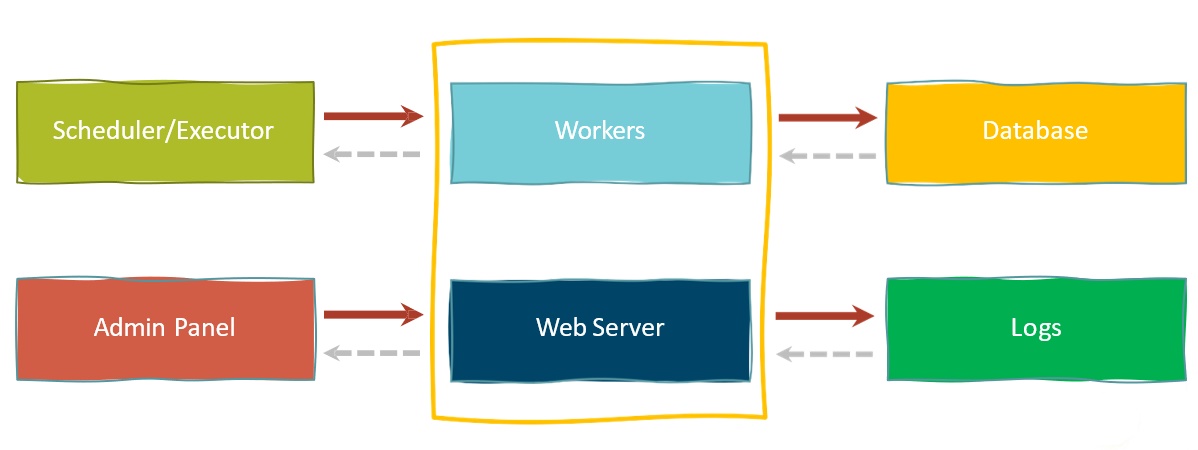
Операционная часть Airflow построена поверх базы данных, которая хранит информацию о задачах и DAG-ах. Планировщик отправляет задачи в очередь, а воркеры по мере доступности берут и выполняют их. Веб-сервер обычно запускается на той же машине, где и планировщик. Он использует базу данных для рендера состояния задач, получения task execution логов, а также обслуживает запросы Admin Panel. Важно отметить, что каждый выделенный блок может работать в изоляции от других. То есть это реально развертывать их абсолютно на разных серверах или узлах в определенном виде, в зависимости от настройки deployment-конфигурации.
Google Cloud Composer изнутри
Google Cloud Composer или просто Composer — это fully managed сервис оркестрации, который позволяет создавать, планировать и мониторить ваши пайплайн в cloud.
Сразу несколько примеров, почему это удобно и классно. Допустим, у нас есть клиент, который хочет автоматизировать ежедневный перенос данных из storage A в storage B. Для этого мы напишем Airflow DAG, задеплоим его в Composer и будем запускать наш пайплайн в конкретный интервал времени. Задачи могут исполняться синхронно, стартовать в определенном порядке или параллельно. Если вдруг что-то упадет, то есть механизм retry, который поднимет задачу и попробует заново ее исполнить. В общем, весь процесс зависит от настроек задачи. Теперь представьте, что нам нужно было бы сделать cron jobs, строя при этом 100 разных пайплайнов, — без помощи Airflow и Composer оперирование, запуск и отладка дались бы гораздо труднее.
И еще немного о плюсах Composer:
Во-первых, с ним легко разрабатывать и деплоить. Composer построен поверх Airflow и предоставляет внутри Google Console весь необходимый UI “из коробки”, чтобы было удобно работать, создавать окружения и загружать файлы DAG-ов с легкостью. Там уже все есть, мы просто создаем файлы DAG-ов, плагинов и операторов, указываем дополнительные зависисмости, а после загружаем в заранее созданный Composer bucket в GCS. Дальше файлы из бакета будут исполняться в узлах воркеров.
Во-вторых, у Composer есть механизм для управления окружениями, причем все делается через UI. То есть мы можем создавать нужное количество окружений со своими версиями и отдельными Airflow, которые никак не будут пересекаться.
В-третьих, Composer тесно интегрирован с security-подходами и инструментами, которые есть в Google Cloud. Например, Private IPs, Authorization и т. д.
В-четвертых, Composer Console предоставляет страницу метрик запущенных окружений.
Давайте посмотрим на компоненты Composer. На возможное “Зачем, если это fully managed сервис и в нем все можно “накликать”?” сразу скажу, что знание механизмов, сильных и слабых сторон помогает сделать разработку решений более эффективной. Итак, компоненты:
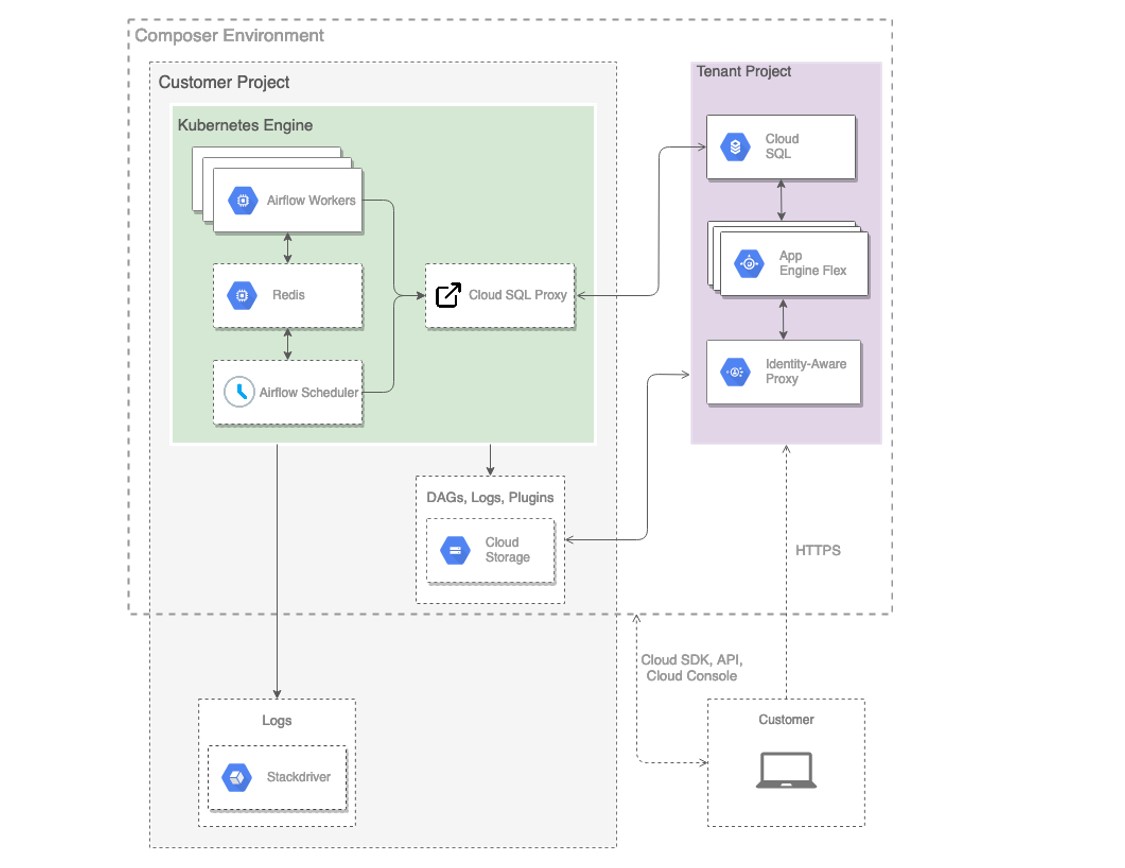
Пройдемся по некоторым (держим в голове, что Composer все делает сам). На картинке видим Tenant Project — это для того, чтобы унифицировать Identity Access Management. Просто реализован дополнительный уровень безопасности. AppEngine Flexible используется для веб-сервера, Cloud SQL — как база данных Airflow. У Cloud SQL есть определенные плюсы, например, он дает ограниченный доступ для сервис-аккаунта, а еще каждый день автоматически делает бэкапы. Внутри Cloud Storage Composer создает bucket, который становится единой точкой для того, чтобы автоматически загружать/обновлять DAG-и, плагины и зависимости к ним. Файлы из бакета будут использоваться всеми воркерами, поднятыми в Kubernetes кластере. Core-компоненты, такие как планировщик, worker-ноды и, например, Redis, который используется для CeleryExecutor, поднимаются внутри Google Kubernetes Engine. Все это тоже автоматизировано: вместе с окружением создаются Kubernetes кластер, необходимое количество нодов, отдельно поднимаются воркеры и Redis. Кстати, Redis обслуживает очередь задач внутри Airflow, а также нужен как персистентное хранилище между рестартами контейнеров внутри Kubernetes Engine. Большой плюс, что Composer хорошо интегрирован со Stackdriver для мониторинга и логгинга — можно все логи и метрики собирать в одном месте. Это очень удобно, особенно когда у нас 100 узлов в кластере, а то и больше.
В общем, здорово, что столько реализовано за нас “из коробки”. Потому что, если бы мы держали это все отдельно, то, скорее всего, нужен был бы DevOps-специалист, который помогал бы и думал, например, если бы база разрасталась, как настраивать горизонтальное масштабирование и т. д.
Кстати, вот как происходит масштабирование окружения:
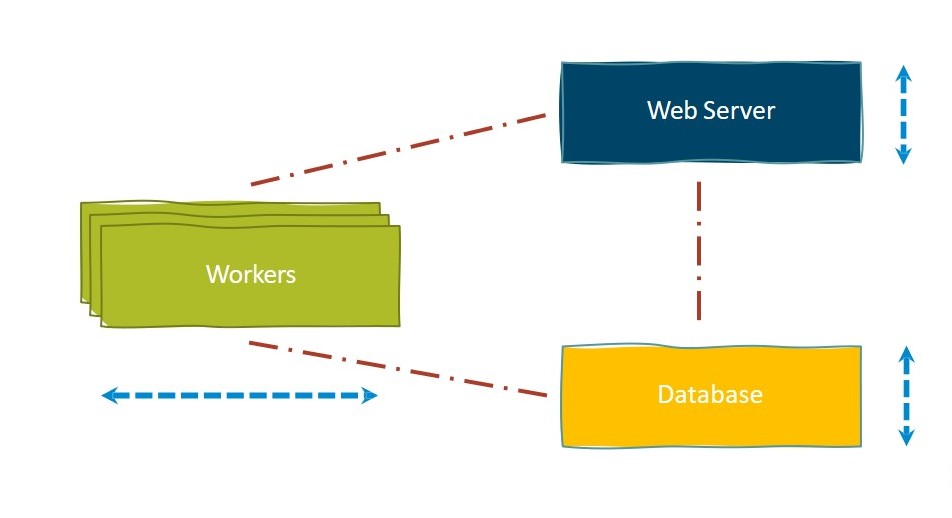
Веб-сервер, который находится в Tenant Project, и база данных в Cloud SQL автоматически масштабируются вертикально. А воркеры — горизонтально. Во время создания или в настройках уже работающего окружения мы можем либо увеличить, либо уменьшить количество воркеров, следовательно и число узлов в кластере.
Deployment и development, трудности и ограничения
В первую очередь хочется сказать про структуру кода проекта — она очень важна для удобства в разработке, поддержке и расширении. Приведу пример из практики:
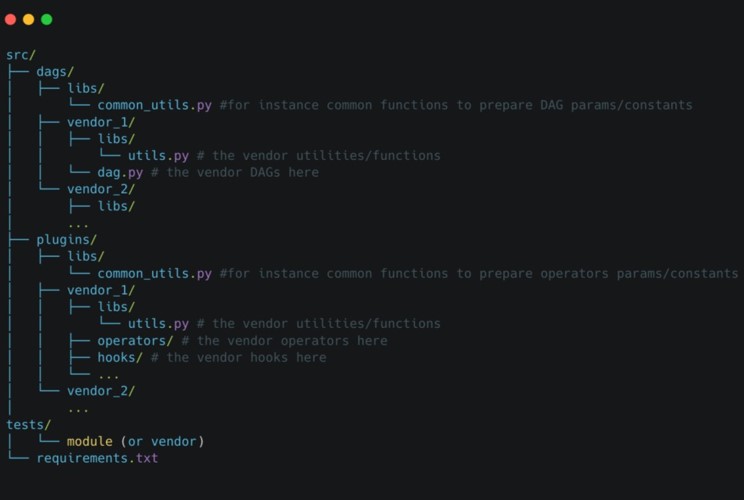
Обратите внимание, что код разбит по директориям вендоров либо по доменным областям продукта. А еще Airflow добавляет переменные DAGS_FOLDER и PLUGINS_FOLDER в sys.path и потом автоматически процессит файлы, которые в них находятся. Тут просто: в DAGS_FOLDER ищем DAG-и, а в PLUGINS_FOLDER — сущности плагинов для Airflow.
Итак, мы разделяем все на папки вендоров, каждая из которых может содержать внутри подпапку библиотек libs или utils. Все зависит от того, как вам будет удобнее держать вместе файлы. Подпапки внутри plugins относятся к Airflow PLUGINS, их структура соответствует конвенции оформления плагинов в Airflow. Я имею в виду operators, hooks, macros — все, что Airflow предоставляет “из коробки”.
Теперь поговорим про зависимости внутри проекта. Я рекомендую использовать pip и requirements.txt файл как можно чаще. Если работаем в Composer, то указывать в настройках UI, какие пакеты и версии необходимо установить в каждом из контейнеров. Или, если вы управляете окружениями внутри ваших CI/CD пайплайнов, можно устанавливать зависимости используя утилиту gcloud. Установка зависимостей с помощью pip хорошо описана в документации Composer.
Так как Airflow добавляет DAGS_FOLDER и PLUGINS_FOLDER в sys.path, необходимо, по возможности, держать локальные зависимости в DAGS_FOLDER, а не в PLUGINS_FOLDER. Все дело в том, как работает Airflow, и в его механизмах поиска, сканирования и исполнения этих директорий. Например, в Airflow есть настройка, которая позволяет указать, с какой периодичностью ресканировать папку с DAG-ами. А в PLUGINS_FOLDER все гораздо сложнее. Поэтому не стоит помещать много исполняемого кода или модулей внутрь plugins — при каждом рескане или запуске все файлы будут исполняться и загружаться. А это может нести за собой дополнительные накладные расходы. Вообще многие команды сталкиваются с тем, что перезагрузка окружения происходит так долго, что задачи сильно подвисают и просто не могут исполняться.
Стоить сказать про ограничения настроек Airflow: их не все можно переопределить. Composer оставляет за собой право предоставлять некоторые настройки только в режиме read-only. Полный список защищенных настроек можно подсмотреть в документации.
Я бы еще посоветовал использовать .airflowignore файл. Он работает как .gitignore файл, который можно помещать в директории либо описывать в нем паттерны для того, чтобы механизмами Airflow исключать из сканирования эти директории или типы файлов внутри. Это достаточно удобно, когда у нас есть большая директория. Например, в PLUGINS_FOLDER очень много кода, а нам нужно хранить зависимости рядом с оператором в той же директории. Благодаря .airflowignore зависимости будут доступны внутри Python кода, но сам сканер их проигнорирует.
Немного про плагины в Airflow. Я рекомендую не использовать встроенный в Airflow механизм плагинов, разве что только для UI-вещей, например для создания View. А для operators, hooks или большой общей логики я бы взял простые классы. За счет того, что Airflow автоматически добавляет PLUGINS_FOLDER в sys.path, можно без проблем применять обычный импорт, как например, from vnd.operators.my_operator. Так мы не будем использовать никакие сущности, динамическую загрузку или нейминг, которые предоставляет нам Airflow. Пример, как может быть организован импорт внутри модулей:
from vnd.operators.my_operator import MyOperator
from vnd.sensors.my_sensor import MySensorКроме того, было бы хорошо держать операторы и хуки просто как семантику. Есть различные нейминговые конвенции, пускай они также называются операторами и хуками, но не должны быть сущностями Airflow plugins и наследоваться от AirflowPlugin класса.
Еще совет: избегать, на сколько это возможно, callable-кода внутри модулей, то есть использовать lazy подход. Это в целом относится и к плагинам, и к DAG-ам. За счет того, что рескан идет каждый раз c определенным интервалом, код будет исполняться тоже каждый раз. Это может повлечь за собой определенные ошибки, задержки в момент обновления самого окружения. Иногда встречаются кейсы, когда внутри на глобальном уровне самого модуля разработчики написали такой код, где мы ходим в базу данных, достаем какие-то записи, процессим и потом используем эти значения в качестве переменных в другом месте. Эти запросы будут выполняться каждый раз: мы каждую секунду будем ресканировать нашу директорию с DAG-ами и исполнять этот код.
CI/СD подход — тут нет ничего сложного. Мы используем те же самые подходы с linters, isorts для Gitlab CI/CD пайплайнов. В целом можно брать любой CI/СD инструмент на ваше усмотрение, ведь все они работают примерно одинаково: Jenkins, Gitlab pipeline, Spinnaker.

Например, мы в своем проекте используем linters, потом идет шаг unit тестов, дальше — интеграционных. Чтобы доставить это в Composer, вызываем gcloud rsync.
Так как весь код в Composer деплоится в бакет, то нам нужно просто обновить файлы до последней версии при помощи rsync, которые в последствии будут использованы воркерами Airflow. Конечно, можно взять команду gcloud composer, с ее помощью регистрировать новые DAG-и, плагины и из каких-то своих исходных файлов все будет автоматически доставляться в нужный бакет. Но, на мой взгляд, это выглядит как-то сложно. Поэтому хорошо бы иметь свой rsync, который будет складывать либо обновленные файлы, либо все фалы проекта в бакет одним общим подходом/способом.
Инструменты
Как и любая полноценная популярная система, Airflow поощряет и поддерживает разработку расширений. Они легко интегрируются, пишутся, сегодня их есть достаточное количество в плане операторов. Но, к сожалению, не так много инструментов относятся к самому Airflow. Один из них я могу привести. Это afctl — утилита командной строки или CLI-инструмент, который позволяет управлять Airflow проектом из командной строки. У него есть свои бойлерплейты или шаблоны, на базе которых можно создавать модули, DAG-и и др. Причем структура, в которой afctl создает свои директории, очень похожа на ту, что мы используем в своем проекте (я чуть выше отмечал ее как рекомендованную).
А еще есть достаточно много готовых интеграций, рабочих и хороших, для Airflow. Например, Google Cloud Platform, AWS, Azure, различные коннекторы к базам данных. Их можно найти в папке providers внутри самого пакета Airflow.
Стоит также зайти на проект Airflow Plugins — найдете всевозможные плагины, коннекторы к CRM системам, социальным сетям и т. д. Не забывайте заглядывать в поиск GitHub: популярность Airflow и сообщество растут, а значит постоянно появляются новые решения, которые можно подсмотреть.
Суммируем и резюмируем:
Все, что относится к Airflow и что можно сделать в self-service, запускается в Cloud Composer.
Cloud Composer, к сожалению, не масштабируется в “ноль” (scaling to zero). То есть, создав окружение, мы будем платить за него деньги. Но за счет этого можно управлять Composer инвайронментом: строить новый, проводить A/B-тесты, презентовать заказчику и удалить его. Естественно, если нет окружений и поднятого GKE кластера, то мы ни за что не платим.
Стоит разделять окружения внутри Composer, например, Prod/Dev/Staging. И еще держать их обновленными. В Composer используется версия Airflow, адаптированная под работу с ним, а команда Google тоже активно обновляет свои версии Airflow. Поэтому время от времени Composer предлагает апдейтнуть окружение: появляется кнопка, автоматически создается новый image, контейнеры и ваш инвайронмент переводится в новую версию Airflow.
Не реализовывайте логику внутри файлов DAG — лучше внутри операторов, которые будут потом исполняться как задачи. Операторы могут иметь локальные зависимости, либо установленные через pip.
Очень важно держать проект в определенной семантичной структуре, чтобы было понятно, что и откуда. Разделяем код между доменами и сущностями, вендорами и контрибьютерами проекта.
По возможности не используем AirflowPlugin сущности — только для UI вещей, которые предоставляет Airflow. Но для операторов я бы не рекомендовал.
Пользуемся .airflowignore файлом, чтобы пропускать определенные директории на момент работы сканера Airflow. Например, если мы поместим .airflowignore файл в директорию DAG-ов с внутренними зависимостями, то Airflow найдет все наши DAG-и и DAG-файлы. Но он не будет читать каждый, чтобы найти сущность DAG-а внутри директории, где, например, очень много файлов.
Механизм сериализации DAG-ов хорошо подходит для ускорения вашего окружения внутри Cloud Composer. В данном случае все наши DAG-и сохраняются в базе данных в сериализованном виде. Теперь нам не нужно каждый раз перечитывать реальные файлы — можно просто достать их из “хранилища”.
Присмотритесь к существующим решениям и интеграциям для Airflow. Например, GoogleCloudStorageListOperator позволяет нам обходить бакеты, искать нужные файлы, скачивать и загружать их. Еще есть различные расширения-коннекторы ко всевозможным хранилищам, базам данных и так далее.
Используйте KubernetesPodOperator для запуска зависимостей и утилит, написанных не на Python. Так как у нас все окружение загружается и исполняется в кластере Kubernetes, Airflow будет инициировать исполнение задачи в отдельном Pod-е. Для этого будут использованы дополнительные ноды кластера, созданные Composer-ом.
Помните про ограничение Composer, а именно про read-only настройки Airflow. Полный список защищенных настроек можно подсмотреть в документации.
Уверен, что вы сможете оптимизировать свои пайпланы, а Airflow и Composer станут в этом отличными помощниками :)
