Один из типовых сценариев во всех привычных нам приложениях — поиск данных по определенным критериям и вывод их в удобном для чтения виде. Тут же могут быть дополнительные возможности по сортировке, группировке, постраничному выводу. Задача, по идее, тривиальная, но при ее решении многие разработчики делают ряд ошибок, из-за которых потом страдает производительность. Попробуем рассмотреть различные варианты решений этой задачи и сформулировать рекомендации по выбору наиболее эффективной реализации.

Самый простой вариант, который приходит в голову — это постраничный вывод результатов поиска в его самом классическом в виде.

Предположим, в приложении используется реляционная база данных. В этом случае для вывода информации в таком виде нужно будет выполнить два SQL запроса:
Рассмотрим первый запрос на примере тестовой MS SQL базы AdventureWorks для 2016 сервера. Для этой цели будем использовать таблицу Sales.SalesOrderHeader:
Приведенный выше запрос выведет первые 50 заказов из списка, отсортированного по убыванию даты добавления, другими словами — 50 последних заказов.
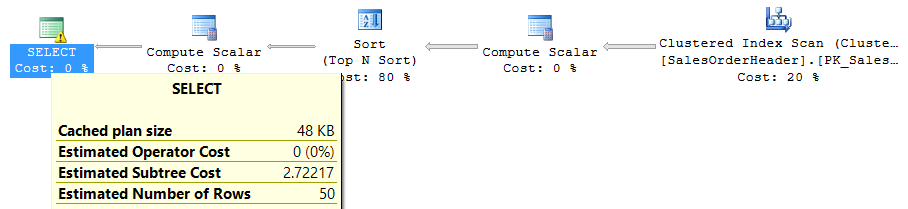
Выполняется он быстро на тестовой базе, но давайте посмотрим на план выполнения и статистику ввода-вывода:
Получить статистику ввода/вывода для каждого запроса можно, выполнив в среде выполнения запросов команду SET STATISTICS IO ON.
Как видно из плана выполнения, наиболее ресурсоемкой является сортировка всех строк исходной таблицы по дате добавления. И проблема в том, что чем больше в таблице будет появляться строк, тем «тяжелее» будет сортировка. На практике таких ситуаций следует избегать, поэтому добавим индекс на дату добавления и посмотрим, изменилось ли потребление ресурсов:
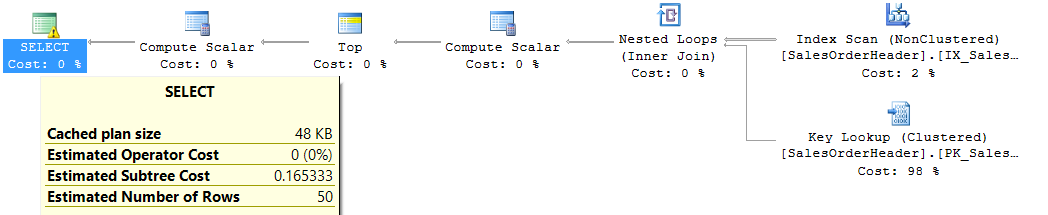
Очевидно, стало намного лучше. Но все ли проблемы решены? Изменим запрос на поиск заказов, где суммарная стоимость товаров превышает 100 долларов:

Имеем забавную ситуацию: план запроса ненамного хуже предыдущего, но фактическое количество логических чтений почти в два раза больше, чем при полном скане таблицы. Выход есть — если из уже существующего индекса сделать составной и вторым полем добавить суммарную цену товаров, то снова получим 165 logical reads:
Эту серию примеров можно продолжать еще долго, но две основных мысли, которые я хочу здесь выразить, такие:
Теперь перейдем ко второму запросу, упомянутому в самом начале — к тому, который считает количество записей, удовлетворяющих поисковому критерию. Возьмем тот же пример — поиск заказов, которые дороже 100 долларов:
При наличии составного индекса, указанного выше, получаем:

То, что запрос проходит весь индекс целиком — неудивительно, так как поле SubTotal стоит не на первой позиции, поэтому запрос не может им воспользоваться. Проблема решается добавлением еще одного индекса на поле SubTotal, и по итогу дает уже всего 48 logical reads.
Можно привести еще несколько примеров запросов на подсчет количества, но суть останется той же: получение порции данных и подсчет общего количества — это два принципиально разных запроса, и каждый требует своих мер для оптимизации. В общем случае не получится найти комбинацию индексов, которая одинаково хорошо работает для обоих запросов.
Соответственно, одно из важных требований, которое следует уточнить при разработке такого поискового решения — действительно ли бизнесу важно видеть общее количество найденных объектов. Зачастую бывает, что нет. А навигация по конкретным номерам страницы, на мой взгляд — решение с очень узкой областью применения, так как большинство сценариев с пейджингом выглядит как «перейти на следующую страницу».
Предположим, пользователям не важно знание общего количества найденных объектов. Попробуем упростить поисковую страницу:

По факту изменилось только то, что нет возможности переходить по конкретным номерам страниц, и теперь этой таблице для отображения не нужно знать, сколько всего их может быть. Но возникает вопрос — а как таблица узнает, есть ли данные для следующей страницы (чтобы правильно отобразить ссылку «Next»)?
Ответ очень простой: можно вычитывать из базы на одну запись больше, чем нужно для отображения, и наличие этой «дополнительной» записи и будет показывать, есть ли следующая порция. Таким образом, для получения одной страницы данных нужно будет выполнить всего один запрос, что существенно улучшает производительность и облегчает поддержку такой функциональности. У меня на практике был случай, когда отказ от подсчета общего количества записей ускорил выдачу результатов в 4-5 раз.
Для этого подхода существует несколько вариантов пользовательского интерфейса: команды «назад» и «вперед», как в примере выше, кнопка «загрузить еще», которая просто добавляет новую порцию в отображаемые результаты, «бесконечная прокрутка», которая работает по принципу «загрузить еще», но сигналом для получения следующей порции является прокрутка пользователем всех выведенных результатов до конца. Каким бы ни было визуальное решение, принцип выборки данных остается таким же.
Во всех примерах запросов, приведенных выше, используется подход «смещение + количество», когда в самом запросе указывается с какой по порядку строки результата и какое количество строк нужно вернуть. Сперва рассмотрим, как лучше организовать передачу параметров в этом случае. На практике я встречал несколько способов:
На первый взгляд может показаться, что это настолько элементарно, что никакой разницы нет. Но это не так — наиболее удобным и универсальным вариантом является второй (startIndex, count). На это есть несколько причин:
Теперь следует описать недостатки реализации пейджинга через «смещение + количество»:
Альтернативы есть, но они тоже неидеальны. Первый из таких подходов называется «keyset paging» или «seek method» и заключается в следующем: после получения порции можно запоминать значения полей в последней записи на странице, а затем использовать их для получения следующей порции. Например, мы выполняли такой запрос:
И в последней записи получили значение даты заказа '2014-06-29'. Тогда для получения следующей страницы можно будет попытаться выполнить такое:
Проблема в том, что OrderDate — неуникальное поле и условие, указанное выше, с большой вероятностью пропустит много нужных строк. Для внесения однозначности в этот запрос, необходимо добавить к условию уникальное поле (предположим, что 75074 — последнее значение первичного ключа из первой порции):
Этот вариант будет работать корректно, но в общем случае его будет тяжело оптимизировать, так как условие содержит оператор OR. Если с ростом OrderDate растет значение первичного ключа, то условие можно упростить, оставив только фильтр по SalesOrderID. Но если между значениями первичного ключа и поля, по которому отсортирован результат, нет строгой корреляции — в большинстве СУБД избежать этого OR не получится. Известным мне исключением является PostgreSQL, где в полной мере поддерживается сравнение кортежей, и указанное выше условие можно записать как «WHERE (OrderDate, SalesOrderID) < ('2014-06-29', 75074)». При наличии составного ключа с этими двумя полями подобный запрос должен быть достаточно легким.
Второй альтернативный подход можно встретить, например, в ElasticSearch scroll API или Cosmos DB — когда запрос помимо данных возвращает специальный идентификатор, с помощью которого можно получить следующую порцию данных. Если этот идентификатор имеет неограниченный срок жизни (как в Comsos DB), то это отличный способ реализации пейджинга с последовательным переходом между страницами (вариант #2 упомянутый выше). Его возможные недостатки: поддерживается далеко не во всех СУБД; полученный идентификатор следующей порции может иметь ограниченный срок жизни, что в общем случае не подходит для реализации взаимодействия с пользователем (как, например, ElasticSearch scroll API).
Усложняем задачу дальше. Предположим, появилось требование реализовать так называемый faceted search, отлично всем знакомый по Интернет-магазинам. Приведенные выше примеры на основе таблицы заказов не очень показательны в этом случае, поэтому переключимся на таблицу Product из базы AdventureWorks:
В чем идея faceted search? В том, что для каждого элемента фильтра показывается количество записей, соответствующих этому критерию с учетом фильтров, выбранных во всех остальных категориях.
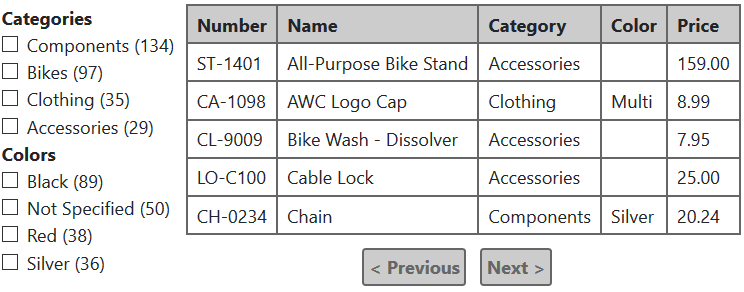
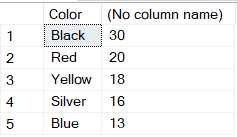
Например, если мы выберем в этом примере категорию Bikes и цвет Black, таблица будет выводить только велосипеды черного цвета, но при этом:
Вот пример вывода результата для таких условий:

Если вдобавок отметить категорию «Clothing», таблица покажет еще и одежду черного цвета, которая есть в наличии. Количество продуктов черного цвета в секции «Color» тоже будет пересчитано согласно новым условиям, только в секции «Categories» ничего не изменится… Надеюсь этих примеров достаточно, чтобы понять привычный алгоритм работы faceted search.
Теперь представим, как это можно реализовать на реляционной базе. Каждая группа критериев, такая как Category и Color, будет требовать отдельного запроса:
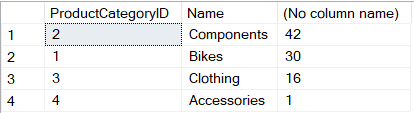
Что же не так с этим решением? Очень просто — оно плохо масштабируется. Каждая секция фильтра требует отдельного запроса для подсчета количеств и запросы эти не самые легкие. В интернет-магазинах в некоторых рубриках может быть и несколько десятков секций фильтра, что может оказаться серьезной проблемой для производительности.
Обычно после этих утверждений мне предлагают некоторые решения, а именно:
К счастью, подобная задача уже давно имеет достаточно эффективные решения, предсказуемо работающие на больших объемах данных. Для любого из этих вариантов имеет смысл разделить пересчет фасетов и получение страницы результатов на два параллельных обращения к серверу и организовать интерфейс пользователя таким образом, что загрузка данных по фасетам «не мешает» отображению результатов поиска.

Вариант пейджинга #1
Самый простой вариант, который приходит в голову — это постраничный вывод результатов поиска в его самом классическом в виде.

Предположим, в приложении используется реляционная база данных. В этом случае для вывода информации в таком виде нужно будет выполнить два SQL запроса:
- Получить строки для текущей страницы.
- Посчитать общее количество строк, соответствующее критериям поиска — это нужно для показа страниц.
Рассмотрим первый запрос на примере тестовой MS SQL базы AdventureWorks для 2016 сервера. Для этой цели будем использовать таблицу Sales.SalesOrderHeader:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
Приведенный выше запрос выведет первые 50 заказов из списка, отсортированного по убыванию даты добавления, другими словами — 50 последних заказов.
Выполняется он быстро на тестовой базе, но давайте посмотрим на план выполнения и статистику ввода-вывода:

Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Получить статистику ввода/вывода для каждого запроса можно, выполнив в среде выполнения запросов команду SET STATISTICS IO ON.
Как видно из плана выполнения, наиболее ресурсоемкой является сортировка всех строк исходной таблицы по дате добавления. И проблема в том, что чем больше в таблице будет появляться строк, тем «тяжелее» будет сортировка. На практике таких ситуаций следует избегать, поэтому добавим индекс на дату добавления и посмотрим, изменилось ли потребление ресурсов:

Table 'SalesOrderHeader'. Scan count 1, logical reads 165, physical reads 0, read-ahead reads 5, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Очевидно, стало намного лучше. Но все ли проблемы решены? Изменим запрос на поиск заказов, где суммарная стоимость товаров превышает 100 долларов:
SELECT * FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY

Table 'SalesOrderHeader'. Scan count 1, logical reads 1081, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Имеем забавную ситуацию: план запроса ненамного хуже предыдущего, но фактическое количество логических чтений почти в два раза больше, чем при полном скане таблицы. Выход есть — если из уже существующего индекса сделать составной и вторым полем добавить суммарную цену товаров, то снова получим 165 logical reads:
CREATE INDEX IX_SalesOrderHeader_OrderDate_SubTotal on Sales.SalesOrderHeader(OrderDate, SubTotal);
Эту серию примеров можно продолжать еще долго, но две основных мысли, которые я хочу здесь выразить, такие:
- Добавление любого нового критерия или порядка сортировки в поисковый запрос может существенно повлиять на скорость его выполнения.
- Но если нам необходимо вычитать только часть данных, а не все результаты, подходящие под условия поиска — есть много способов оптимизировать такой запрос.
Теперь перейдем ко второму запросу, упомянутому в самом начале — к тому, который считает количество записей, удовлетворяющих поисковому критерию. Возьмем тот же пример — поиск заказов, которые дороже 100 долларов:
SELECT COUNT(1) FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
При наличии составного индекса, указанного выше, получаем:

Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.То, что запрос проходит весь индекс целиком — неудивительно, так как поле SubTotal стоит не на первой позиции, поэтому запрос не может им воспользоваться. Проблема решается добавлением еще одного индекса на поле SubTotal, и по итогу дает уже всего 48 logical reads.
Можно привести еще несколько примеров запросов на подсчет количества, но суть останется той же: получение порции данных и подсчет общего количества — это два принципиально разных запроса, и каждый требует своих мер для оптимизации. В общем случае не получится найти комбинацию индексов, которая одинаково хорошо работает для обоих запросов.
Соответственно, одно из важных требований, которое следует уточнить при разработке такого поискового решения — действительно ли бизнесу важно видеть общее количество найденных объектов. Зачастую бывает, что нет. А навигация по конкретным номерам страницы, на мой взгляд — решение с очень узкой областью применения, так как большинство сценариев с пейджингом выглядит как «перейти на следующую страницу».
Вариант пейджинга #2
Предположим, пользователям не важно знание общего количества найденных объектов. Попробуем упростить поисковую страницу:

По факту изменилось только то, что нет возможности переходить по конкретным номерам страниц, и теперь этой таблице для отображения не нужно знать, сколько всего их может быть. Но возникает вопрос — а как таблица узнает, есть ли данные для следующей страницы (чтобы правильно отобразить ссылку «Next»)?
Ответ очень простой: можно вычитывать из базы на одну запись больше, чем нужно для отображения, и наличие этой «дополнительной» записи и будет показывать, есть ли следующая порция. Таким образом, для получения одной страницы данных нужно будет выполнить всего один запрос, что существенно улучшает производительность и облегчает поддержку такой функциональности. У меня на практике был случай, когда отказ от подсчета общего количества записей ускорил выдачу результатов в 4-5 раз.
Для этого подхода существует несколько вариантов пользовательского интерфейса: команды «назад» и «вперед», как в примере выше, кнопка «загрузить еще», которая просто добавляет новую порцию в отображаемые результаты, «бесконечная прокрутка», которая работает по принципу «загрузить еще», но сигналом для получения следующей порции является прокрутка пользователем всех выведенных результатов до конца. Каким бы ни было визуальное решение, принцип выборки данных остается таким же.
Нюансы реализации пейджинга
Во всех примерах запросов, приведенных выше, используется подход «смещение + количество», когда в самом запросе указывается с какой по порядку строки результата и какое количество строк нужно вернуть. Сперва рассмотрим, как лучше организовать передачу параметров в этом случае. На практике я встречал несколько способов:
- Порядковый номер запрашиваемой страницы (pageIndex), размер страницы (pageSize).
- Порядковый номер первой записи, которую нужно вернуть (startIndex), максимальное количество записей в результате (count).
- Порядковый номер первой записи, которую нужно вернуть (startIndex), порядковый номер последней записи, которую нужно вернуть (endIndex).
На первый взгляд может показаться, что это настолько элементарно, что никакой разницы нет. Но это не так — наиболее удобным и универсальным вариантом является второй (startIndex, count). На это есть несколько причин:
- Для подхода с вычиткой +1 записи, приведенного выше, первый вариант с pageIndex и pageSize крайне неудобен. Например, мы хотим отображать 50 записей на странице. Согласно приведенному выше алгоритму, нужно читать на одну запись больше, чем надо. Если этот «+1» не заложен на сервере, получается, что для первой страницы мы должны запрашивать записи с 1 по 51, для второй — с 51 по 101 и т.д. Если указать размер страницы 51 и увеличивать pageIndex, то вторая страница вернет с 52 по 102 и т.д. Соответственно, в первом варианте единственный способ нормально реализовать кнопку перехода на следующую страницу — закладывать на сервере вычитку «лишней» строки, что будет очень неявным нюансом.
- Третий вариант вообще не имеет смысла, так как для выполнения запросов в большинстве баз данных все равно нужно будет передать количество, а не индекс последней записи. Пусть вычитание startIndex из endIndex и элементарная арифметическая операция, но она здесь лишняя.
Теперь следует описать недостатки реализации пейджинга через «смещение + количество»:
- Получение каждой следующей страницы будет затратнее и медленнее, чем предыдущей, потому что базе данных все равно нужно будет пройти все записи «с начала» согласно критериям поиска и сортировки, после чего остановиться на нужном фрагменте.
- Не все СУБД могут поддерживать этот подход.
Альтернативы есть, но они тоже неидеальны. Первый из таких подходов называется «keyset paging» или «seek method» и заключается в следующем: после получения порции можно запоминать значения полей в последней записи на странице, а затем использовать их для получения следующей порции. Например, мы выполняли такой запрос:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
И в последней записи получили значение даты заказа '2014-06-29'. Тогда для получения следующей страницы можно будет попытаться выполнить такое:
SELECT * FROM Sales.SalesOrderHeader
WHERE OrderDate < '2014-06-29'
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
Проблема в том, что OrderDate — неуникальное поле и условие, указанное выше, с большой вероятностью пропустит много нужных строк. Для внесения однозначности в этот запрос, необходимо добавить к условию уникальное поле (предположим, что 75074 — последнее значение первичного ключа из первой порции):
SELECT * FROM Sales.SalesOrderHeader
WHERE (OrderDate = '2014-06-29' AND SalesOrderID < 75074)
OR (OrderDate < '2014-06-29')
ORDER BY OrderDate DESC, SalesOrderID DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
Этот вариант будет работать корректно, но в общем случае его будет тяжело оптимизировать, так как условие содержит оператор OR. Если с ростом OrderDate растет значение первичного ключа, то условие можно упростить, оставив только фильтр по SalesOrderID. Но если между значениями первичного ключа и поля, по которому отсортирован результат, нет строгой корреляции — в большинстве СУБД избежать этого OR не получится. Известным мне исключением является PostgreSQL, где в полной мере поддерживается сравнение кортежей, и указанное выше условие можно записать как «WHERE (OrderDate, SalesOrderID) < ('2014-06-29', 75074)». При наличии составного ключа с этими двумя полями подобный запрос должен быть достаточно легким.
Второй альтернативный подход можно встретить, например, в ElasticSearch scroll API или Cosmos DB — когда запрос помимо данных возвращает специальный идентификатор, с помощью которого можно получить следующую порцию данных. Если этот идентификатор имеет неограниченный срок жизни (как в Comsos DB), то это отличный способ реализации пейджинга с последовательным переходом между страницами (вариант #2 упомянутый выше). Его возможные недостатки: поддерживается далеко не во всех СУБД; полученный идентификатор следующей порции может иметь ограниченный срок жизни, что в общем случае не подходит для реализации взаимодействия с пользователем (как, например, ElasticSearch scroll API).
Сложная фильтрация
Усложняем задачу дальше. Предположим, появилось требование реализовать так называемый faceted search, отлично всем знакомый по Интернет-магазинам. Приведенные выше примеры на основе таблицы заказов не очень показательны в этом случае, поэтому переключимся на таблицу Product из базы AdventureWorks:

В чем идея faceted search? В том, что для каждого элемента фильтра показывается количество записей, соответствующих этому критерию с учетом фильтров, выбранных во всех остальных категориях.
Например, если мы выберем в этом примере категорию Bikes и цвет Black, таблица будет выводить только велосипеды черного цвета, но при этом:
- Для каждого критерия группы «Categories» будет показано число продуктов из этой категории черного цвета.
- Для каждого критерия группы «Colors» будет показано число велосипедов этого цвета.
Вот пример вывода результата для таких условий:

Если вдобавок отметить категорию «Clothing», таблица покажет еще и одежду черного цвета, которая есть в наличии. Количество продуктов черного цвета в секции «Color» тоже будет пересчитано согласно новым условиям, только в секции «Categories» ничего не изменится… Надеюсь этих примеров достаточно, чтобы понять привычный алгоритм работы faceted search.
Теперь представим, как это можно реализовать на реляционной базе. Каждая группа критериев, такая как Category и Color, будет требовать отдельного запроса:
SELECT pc.ProductCategoryID, pc.Name, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
INNER JOIN Production.ProductCategory pc ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE p.Color = 'Black'
GROUP BY pc.ProductCategoryID, pc.Name
ORDER BY COUNT(1) DESC

SELECT Color, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE ps.ProductCategoryID = 1 --Bikes
GROUP BY Color
ORDER BY COUNT(1) DESC

Что же не так с этим решением? Очень просто — оно плохо масштабируется. Каждая секция фильтра требует отдельного запроса для подсчета количеств и запросы эти не самые легкие. В интернет-магазинах в некоторых рубриках может быть и несколько десятков секций фильтра, что может оказаться серьезной проблемой для производительности.
Обычно после этих утверждений мне предлагают некоторые решения, а именно:
- Объединить все подсчеты количества в один запрос. Технически это возможно с помощью ключевого слова UNION, только производительности это не сильно поможет — базе данных все равно придется выполнить «с нуля» каждый из фрагментов.
- Кешировать количества. Это мне предлагают практически каждый раз, когда я описываю проблему. Нюанс в том, что это в общем случае невозможно. Предположим, у нас 10 «фасетов», в каждом из которых 5 значений. Это очень «скромная» ситуация на фоне того, что можно увидеть в тех же интернет-магазинах. Выбор одного элемента фасета влияет на количества в 9-ти других, другими словами, для каждой комбинации критериев количества могут быть разными. Всего в нашем примере 50 критериев, которые пользователь может выбрать, соответственно возможных комбинаций будет 250. На заполнение такого массива данных не хватит ни памяти, ни времени. Тут можно возразить и сказать, что не все комбинации реальны и пользователь редко когда выберет больше 5-10 критериев. Да, можно сделать ленивую загрузку и кеширование количества только для того, что когда-либо было выбрано, но чем больше будет вариантов выбора, тем менее эффективным будет такой кеш и тем более заметными будут проблемы с временем отклика (особенно если набор данных регулярно изменяется).
К счастью, подобная задача уже давно имеет достаточно эффективные решения, предсказуемо работающие на больших объемах данных. Для любого из этих вариантов имеет смысл разделить пересчет фасетов и получение страницы результатов на два параллельных обращения к серверу и организовать интерфейс пользователя таким образом, что загрузка данных по фасетам «не мешает» отображению результатов поиска.
- Вызывать полный пересчет «фасетов» как можно реже. Например, не пересчитывать все на каждом изменении критериев поиска, а вместо этого находить общее количество результатов, соответствующих текущим условиям, и предлагать пользователю их показать — «1425 записей найдено, показать?» Пользователь может либо продолжить менять условия поиска, либо нажать кнопку «показать». Только во втором случае будут выполнены все запросы по получению результатов и пересчету количеств на всех «фасетах». При этом, как несложно заметить, придется иметь дело с запросом на получение общего количества результатов и его оптимизацией. Этот способ можно встретить во многих небольших интернет-магазинах. Очевидно, что это не панацея для данной проблемы, но в простых случаях может быть неплохим компромиссом.
- Использовать search engine для поиска результатов и подсчета фасетов, такие как Solr, ElasticSearch, Sphinx и другие. Все они рассчитаны на построение «фасетов» и делают это достаточно эффективно за счет инвертированного индекса. Как устроены поисковые системы, почему они в таких случаях эффективнее баз данных общего назначения, какие есть практики и подводные камни — это тема для отдельной статьи. Здесь же я хочу обратить внимание, что search engine не может быть заменой основного хранилища данных, используется он как дополнение: любые изменения в основной базе, имеющие значение для поиска, синхронизируются в поисковый индекс; механизм поиска взаимодействует обычно только с search engine и не обращается к основной базе. Один из самых важных моментов здесь — как организовать эту синхронизацию надежно. Все зависит от требований к «времени реакции». Если время между изменением в основной базе и его «проявлением» в поиске не критично, можно сделать сервис, который раз в несколько минут ищет недавно измененные записи и их индексирует. Если требуется минимально возможное время реакции, можно реализовать что-то типа transactional outbox для отправки обновлений в поисковый сервис.
Выводы
- Реализация пейджинга на стороне сервера — серьезное усложнение, и применять его имеет смысл только для быстрорастущих или просто больших наборов данных. Как оценить «большой» или «быстрорастущий» — абсолютно точного рецепта нет, но я бы придерживался такого подхода:
- Если получение полной коллекции данных с учетом серверного времени и передачи по сети нормально укладывается в требования по производительности — реализовывать пейджинг на стороне сервера смысла нет.
- Может быть такая ситуация, что на ближайшее время проблем с производительностью не предвидится, так как данных мало, но коллекция данных постоянно растет. Если какой-то набор данных в перспективе может перестать удовлетворять предыдущему пункту — лучше пейджинг заложить сразу.
- Если со стороны бизнеса нет жесткого требования по показу общего количества результатов или по отображению номеров страниц, и при этом в вашей системе нет поискового движка — лучше эти моменты не реализовывать и рассматривать вариант #2.
- Если есть четкое требование о faceted search, у вас есть два варианта не пожертвовать производительностью:
- Не пересчитывать все количества на каждом изменении критериев поиска.
- Использовать search engine такие как Solr, ElasticSearch, Sphinx и другие. Но следует понимать, что он не может быть заменой основной базе данных, и должен использоваться как дополнение к основному хранилищу для решения поисковых задач.
- Также в случае faceted search имеет смысл разделить получение страницы результатов поиска и подсчет количеств на два параллельных запроса. Подсчет количеств может занять большее время, чем получение результатов, в то время как результаты важнее для пользователя.
- Если вы используете SQL базу для поиска, любое изменение кода, относящееся к этой части, должно хорошо тестироваться в отношении производительности на соответствующем объеме данных (превосходящем объем в «живой» базе). Желательно также использовать мониторинг времени выполнения запросов на всех экземплярах базы, и особенно — на «живом». Даже если на этапе разработки с планами запросов все было хорошо, с ростом объема данных ситуация может заметно измениться.
