Комментарии 43
Чугун, в отличие от аллюминия уже не является чистым металлом — это «сплав» железа с углеродом.
не обращайте внимания, это просто пример под впечатлением от этого видео. Я не очень хорошо разбираюсь в металлах, и был искренне впечатлен тем, что в «реальный сектор» настолько круто пришли технологии машинного обучения.
Моя фантазия слегка подвисла, пытаясь придумать хоть один нормальный пример линейной регрессии кроме соотношения рост-вес, поэтому была выдумана такая абсолютно некорректная, но довольно понятная история.
Моя фантазия слегка подвисла, пытаясь придумать хоть один нормальный пример линейной регрессии кроме соотношения рост-вес, поэтому была выдумана такая абсолютно некорректная, но довольно понятная история.
Почему в кавычках? На самом деле — сплав. А ещё точнее — многофазная система из твёрдого раствора углерода в железе, цементита и графита.
Как сказал один мой знакомый: с использованием нейронных сетей есть всегда отличная отмазка — если не работает, то значит вы учили ее на плохих примерах.
Ну, это довольно корректное утверждение. Была история, как в 70-е (кажется), на волне увлечения перцептронами, какой-то НИИ объявил, что сможет распознать на фото танки, отличить их от всего остального. Это сейчас мы понимаем, что на тех мощностях это невозможно, но каким-то образом все в это верили.
Но почему-то у них это заработало. Все успешно сдали, но вдруг в реальных условиях она перестает работать. Все в паники, начинают разбираться.
Оказалось, дело было в том, что выборка была наведенной. Фото вражеских танков всегда делали в безоблачную погоду, а остальные картинки для обучения были сделаны как угодно. В итоге перцептрон видел небо и говорил «да, это похоже на те картинки, что вы мне подсовывали».
Поэтому большая часть работы — это корректная подготовка примеров для обучения, перетасовка, кроссвалидация, вот это все.
Но почему-то у них это заработало. Все успешно сдали, но вдруг в реальных условиях она перестает работать. Все в паники, начинают разбираться.
Оказалось, дело было в том, что выборка была наведенной. Фото вражеских танков всегда делали в безоблачную погоду, а остальные картинки для обучения были сделаны как угодно. В итоге перцептрон видел небо и говорил «да, это похоже на те картинки, что вы мне подсовывали».
Поэтому большая часть работы — это корректная подготовка примеров для обучения, перетасовка, кроссвалидация, вот это все.
С детьми примерно так же…
тема бэкпропагэйшен не раскрыта
нейронные сети != deep learning. В сети с одним скрытым слоем не нужен механизм back propagation, при этом понимание того, как данные «текут» через узлы и почему нам нужны отдельно линейные преобразования и отдельно активации — куда более важно для понимания того, как сети работают. К тому же количество материала и так огромное получилось (если считать вместе с кодом, выложенным на runkit).
Планируется еще одна статья про сверточные сети (там уже backprop необходим) и, возможно, про LSTM/RNN.
Планируется еще одна статья про сверточные сети (там уже backprop необходим) и, возможно, про LSTM/RNN.
Эта статья отличная. Буду очень ждать статью про сверточные сети.
Я недавно писал статью про машинное обучение на JS, там как раз очень нехватало такой теоретической части как у Вас. Я добавил линк на вашу статью. Очень хорошо и доступно получилось.
Я очень рад, что могу где-то восполнить пробелы :)
В этом и была проблема, почему написал такую статью — есть куча «ну вот мы делаем на фреймворке», и есть очень крутые с точки зрения тех, кто уже понимает, как это работает, и они разжевывают вот так, например — https://geektimes.ru/post/277088/. Статья крутая, но она работает так же, как паттерны разработки — ты читаешь, киваешь головой, вроде все понимаешь, но реальное понимание приходит только потом, после опыта.
А я постарался по свежей памяти объяснить это все так, как объяснил бы самому себе, еще не знающему про то, как это работает, но при этом понимающему код.
И да. Переходите с brain, он мертв, в смысле deprecated :) Подключайтесь к Synaptic, я надеюсь, релиз в январе будет.
В этом и была проблема, почему написал такую статью — есть куча «ну вот мы делаем на фреймворке», и есть очень крутые с точки зрения тех, кто уже понимает, как это работает, и они разжевывают вот так, например — https://geektimes.ru/post/277088/. Статья крутая, но она работает так же, как паттерны разработки — ты читаешь, киваешь головой, вроде все понимаешь, но реальное понимание приходит только потом, после опыта.
А я постарался по свежей памяти объяснить это все так, как объяснил бы самому себе, еще не знающему про то, как это работает, но при этом понимающему код.
И да. Переходите с brain, он мертв, в смысле deprecated :) Подключайтесь к Synaptic, я надеюсь, релиз в январе будет.
Давайте поговорим о том, как написать с нуля нейронную сеть на JavaScript.
вопрос только один — зачем?
как обычно, сделать плагин для PostCSS.
А если серьезно — то ответ на вопрос «зачем написать», я не видел ни одной статьи, где не было бы реально внятного объяснения без матричных операций.
А если вопрос «зачем на JS», то в реальности нет никакой разницы, с чем ты работаешь. R и Python с их супер-библиотеками на поверку оказываются тупо биндингами к C-шным библиотекам (окей, иногда с абстракциями), и чтобы начать работать с TensorFlow или XGBoost достаточно написать эти самые биндинги для Nodejs. Вся сила в экосистеме, и сделать эту экосистему не так сложно, как кажется — с учетом количества JS-разработчиков, желающих делать что-то большее чем формочки на сайтах
А если серьезно — то ответ на вопрос «зачем написать», я не видел ни одной статьи, где не было бы реально внятного объяснения без матричных операций.
А если вопрос «зачем на JS», то в реальности нет никакой разницы, с чем ты работаешь. R и Python с их супер-библиотеками на поверку оказываются тупо биндингами к C-шным библиотекам (окей, иногда с абстракциями), и чтобы начать работать с TensorFlow или XGBoost достаточно написать эти самые биндинги для Nodejs. Вся сила в экосистеме, и сделать эту экосистему не так сложно, как кажется — с учетом количества JS-разработчиков, желающих делать что-то большее чем формочки на сайтах
А если вопрос «зачем на JS», то в реальности нет никакой разницы, с чем ты работаешь. R и Python
ну смотря чем заниматься, если вы бекендер, то разницы нет, хотя на эр будет трудновато
а вот если вы занимаетесеь машинным обучением, по настоящему, а не сеточку на жс накидать, то на жс вы не то что бы страдать будите, вы просто не сможете им заниматься, вообще никак
так что если вы делали это упражнение ради фана, то все ок, нужно только подписать внизу, что не стоит повторять ваших ошибок, лучше сразу писать на том языке, который приспособлен для этих целей (ага и я тоже этот опыт проходил, гляньте один из моих первых посто, я там на шарпе делал тоже самое, больше я шарп не юзаю)
R и Python с их супер-библиотеками на поверку оказываются тупо биндингами к C-шным библиотекам (окей, иногда с абстракциями), и чтобы начать работать с TensorFlow или XGBoost достаточно написать эти самые биндинги для Nodejs
Theano например полноценный фреймворк для глубокого обучения и написан почти полностью на питоне, и дифференцирование вычислительного графа и всякая другая наркомания, далее он генерит немного куда-си кода и компилит его, что бы все еще и н гпу работало
А если серьезно — то ответ на вопрос «зачем написать», я не видел ни одной статьи, где не было бы реально внятного объяснения без матричных операций.
думаю вы плохо гуглите, таких статей море, и видюшек на ютубе и курсов на курсере
а то что сети используют матричные операции, это не просто так наверное, да?
Вся сила в экосистеме, и сделать эту экосистему не так сложно, как кажется — с учетом количества JS-разработчиков, желающих делать что-то большее чем формочки на сайтах
что бы делать что то большее чем формочки для сайтов, нужно как минимум выучить матан и линейную алгебру, тогда не будет проблем с пониманием матричных вычислений, не будет возникать вопросов вообще о том почему нужно сразу писать правильно, и вообще будет выбираться сразу нужный инструмент
скажем сиквел тоже Тьюринг полный язык, но у вас не возникло желания написать сеть на нем, так же после осознания линейной алгебры, у вас не возникнет вопросов почему нужно юзать питон, эр или матлаб
а вот если вы занимаетесеь машинным обучением, по настоящему, а не сеточку на жс накидать, то на жс вы не то что бы страдать будите, вы просто не сможете им заниматься, вообще никак
Для реальных (ну насколько реальные вещи можно делать без аренды сервера в 100gb RAM) вещей я использую в основном XGBoost и Keras, плюс кучка вещей поменьше. Synaptic — это работа на перспективу в надежде, что получится принести ML в JS.
думаю вы плохо гуглите, таких статей море, и видюшек на ютубе и курсов на курсере
а то что сети используют матричные операции, это не просто так наверное, да?
в том-то и дело, что нет. Уровень «разжеванности» в статье выше, чем где-либо кроме увиденного, где была бы реальная реализация, а не абстрактный разговор, и несколько ребят из OpenDataScience это подтвердили.
Theano например полноценный фреймворк для глубокого обучения и написан почти полностью на питоне, и дифференцирование вычислительного графа и всякая другая наркомания, далее он генерит немного куда-си кода и компилит его, что бы все еще и н гпу работало
На один Theano, который почти без си, у нас есть TensorFlow, AutoML, XGBoost, Caffe, MXNet, которые работают как биндинги к сям. И это то что я вспомнил сходу, в реальности кроме theano и либ поверх него ничего не работает без нативного слоя.
что бы делать что то большее чем формочки для сайтов, нужно как минимум выучить матан и линейную алгебру, тогда не будет проблем с пониманием матричных вычислений, не будет возникать вопросов вообще о том почему нужно сразу писать правильно, и вообще будет выбираться сразу нужный инструмент
Я удивлю, но большое количество JS-разработчиков довольно хорошо шарят в матане. Алгоритмы и структуры данных — они везде нужны.
скажем сиквел тоже Тьюринг полный язык, но у вас не возникло желания написать сеть на нем, так же после осознания линейной алгебры, у вас не возникнет вопросов почему нужно юзать питон, эр или матлаб
Это у вас не возникло желания ;) Поверх Postgres, Neo4j, ну и вишенкой на торте — поверх Redis
плюс кучка вещей поменьше. Synaptic — это работа на перспективу в надежде, что получится принести ML в JS
ну а я о чем, что для нормальных мл задач жс не пригоден, вы сами это и доказываете, используя что то другое
Я удивлю, но большое количество JS-разработчиков довольно хорошо шарят в матане. Алгоритмы и структуры данных — они везде нужны.
это оценочное суждение, пруфов то нет, по моим знакомым 1 из 10 шарит, опять же смещенная выборка
ну а я о чем, что для нормальных мл задач жс не пригоден, вы сами это и доказываете, используя что то другое
я и не отрицаю, что в данный момент не годен, я расчитываю на него в перспективе. причем не через месяц или два.
это оценочное суждение, пруфов то нет, по моим знакомым 1 из 10 шарит, опять же смещенная выборка
угу, а почему тогда в Питере Papers We Love сделали два фронтэндщика и позвали выступать третьего про CRDT, а датасатанисты бегали и удивлялись, как это не они сами сделали? :)
А вообще — да, верно, 10% JS-еров шарят. Это те ребята, которые делают транспиляторы, синхронизацию между клиентами, статический анализ, фреймворки для webGL и так далее. Но фронтэндщиков в целом дохрена, и эти 10% в численном представлении не то чтобы сильно меньше, кмк, чем специалистов с аналогичным уровнем знаний, которые умеют в R модельки крутить, например.
Где можно прочитать больше похожей информации (помимо вашей wiki на github)?
Пожалуй, я бы посоветовал начать с курса machine learning от Andrew Ng на Coursera, если нет проблем с английским
Или вопрос конкретно про Synaptic?
Вы бы указали, что обе картинки с анимацией из того курса взяли. Просто из уважения к трудам профессора Ng.
По существу хочется дать небольшой совет: попробуйте в качестве функции активации использовать не сигмоидную функцию, а функцию, называемую rectified linear activation, имеющую очень простой вид: rect(x) = max(0, x), поэтому очень дешевую с точки зрения вычислительных ресурсов, что немаловажно для JS.
По существу хочется дать небольшой совет: попробуйте в качестве функции активации использовать не сигмоидную функцию, а функцию, называемую rectified linear activation, имеющую очень простой вид: rect(x) = max(0, x), поэтому очень дешевую с точки зрения вычислительных ресурсов, что немаловажно для JS.
Я, к сожалению, не знал, что она из этого курса — я ее нашел на каком-то непонятном портале три месяца назад, и банально не смог восстановить авторство :( Непонятно было, откуда она. И да, это одна гифка, не две.
То, что она была у Эндрю в курсе — попросту забыл, увы. Спасибо большое за ваше замечание.
Говоря по быстродействию:
1. по сравнению с операциями перемножения матриц для больших размерностей скорость работы функции активации ничтожна — несмотря на то, что разовое перемножение дешевле, O(n,m) в итоге на полносвязном слое куда дороже чем O(n) на слое активации.
2. Для маленьких сетей есть более полезные для обучения сеточек реализации — ломанная сигмоида и т.н. Leaky ReLU. Стоимость расчета примерно аналогичная, а обучение работает в большинстве случаев эффективнее (если не считать выходного слоя для задач классификации, там ReLU очень хорошо ложится).
3. Бенчмарки утверждают, что скорость V8 и Chakra в задачах математики на JIT-оптимизированных функциях (которые исполнились несколько сотен или тысяч раз) довольно сильно приближается к скорости аналогичного кода на сях
4. развивая мысль. Такие задачи все-таки обычно по возможности решаются на GPGPU — WebCL и OpenCL/CUDA в ноде.
То, что она была у Эндрю в курсе — попросту забыл, увы. Спасибо большое за ваше замечание.
Говоря по быстродействию:
1. по сравнению с операциями перемножения матриц для больших размерностей скорость работы функции активации ничтожна — несмотря на то, что разовое перемножение дешевле, O(n,m) в итоге на полносвязном слое куда дороже чем O(n) на слое активации.
2. Для маленьких сетей есть более полезные для обучения сеточек реализации — ломанная сигмоида и т.н. Leaky ReLU. Стоимость расчета примерно аналогичная, а обучение работает в большинстве случаев эффективнее (если не считать выходного слоя для задач классификации, там ReLU очень хорошо ложится).
3. Бенчмарки утверждают, что скорость V8 и Chakra в задачах математики на JIT-оптимизированных функциях (которые исполнились несколько сотен или тысяч раз) довольно сильно приближается к скорости аналогичного кода на сях
4. развивая мысль. Такие задачи все-таки обычно по возможности решаются на GPGPU — WebCL и OpenCL/CUDA в ноде.
ReLU хорош не сколько тем, что он быстрый, а тем что градиент в области >0 не затухает [Leaky ReLU чтобы совсем везде был]. У сигмоида он нормальный только в окрестности 0, поэтому случается vanishing gradient problem.
Раз затронули быстродействие, то еще наброшу.
Для обучения кажется не так перспективно, потому что сети учатся долго. Не так сложно сделать фреймворк, нужно чтобы он быстро учил сеть. Мне кажется сомнительным, что этот проект окажется быстрее существующих решений. Если я не прав, дайте ссылку на benchmark когда оно станет сравнимым с tensorflow/theano.
Но вещь крайне полезная в плане применения обученной сети на девайсах, где есть js. Аналогично такой штуке: tf на android device
Где-то обучили сеть, закинули веса в protobuf, затем загрузили обученную сеть в tensorflow на мобильном девайсе и (1) не грузим сервер (2) не нужно быть online. Одна из killer features TF.
Правда нужно предварительно загрузить тяжелые веса. Но тут от автора Keras есть приличного качества сеть всего в 100Mb: https://arxiv.org/abs/1610.02357 (речь идет о распознавании картинок)
Но, в силу своей необразованности, я не знаю девайсов js-only. Данный проект был бы крайне полезен именно для них. Придумал только один пример. Prediction на стороне клиента прямо в браузере. Загружаем веса обученной в keras/tensorflow сети в браузер, берем вход клиента, делаем предсказание (а вероятно много предсказаний), не тратя ресурсы сервера. Но есть сомнения, что это реально нужно.
Jabher напиши пожалуйста видишь ли ты применение этого js фреймворка в устройствах? В каких?
Раз затронули быстродействие, то еще наброшу.
Для обучения кажется не так перспективно, потому что сети учатся долго. Не так сложно сделать фреймворк, нужно чтобы он быстро учил сеть. Мне кажется сомнительным, что этот проект окажется быстрее существующих решений. Если я не прав, дайте ссылку на benchmark когда оно станет сравнимым с tensorflow/theano.
Но вещь крайне полезная в плане применения обученной сети на девайсах, где есть js. Аналогично такой штуке: tf на android device
Где-то обучили сеть, закинули веса в protobuf, затем загрузили обученную сеть в tensorflow на мобильном девайсе и (1) не грузим сервер (2) не нужно быть online. Одна из killer features TF.
Правда нужно предварительно загрузить тяжелые веса. Но тут от автора Keras есть приличного качества сеть всего в 100Mb: https://arxiv.org/abs/1610.02357 (речь идет о распознавании картинок)
Но, в силу своей необразованности, я не знаю девайсов js-only. Данный проект был бы крайне полезен именно для них. Придумал только один пример. Prediction на стороне клиента прямо в браузере. Загружаем веса обученной в keras/tensorflow сети в браузер, берем вход клиента, делаем предсказание (а вероятно много предсказаний), не тратя ресурсы сервера. Но есть сомнения, что это реально нужно.
Jabher напиши пожалуйста видишь ли ты применение этого js фреймворка в устройствах? В каких?
Касательно быстродействия — Synaptic планируется обновить, чтобы он стал похожим на Keras. Т.е. вся вычислительная мощность будет находиться в одном из бэкэндов, например, в том же TensorFlow. Я думаю, дальше объяснять не надо :)
Для задачи «загружаем веса» уже есть keras.js.
Вообще предполагаемое применение — очень простое. Есть JS-сообщество, и многим в нем очень хочется поиграться с machine learning. На уровне «распознавать котиков, чтобы включать брызгалку». Если им дать доступ к чему-то не очень сложному для них, то они начнут с этим играться. Если не дать — вряд ли они для этого будут изучать питон. Что будет дальше — неизвестно, но когда этим людям дали ноду, случился какой-то чудовищный буст в развитии и фронтэнда, и бэкэнда. Я очень надеюсь, что тут случится такая же история.
Для задачи «загружаем веса» уже есть keras.js.
Вообще предполагаемое применение — очень простое. Есть JS-сообщество, и многим в нем очень хочется поиграться с machine learning. На уровне «распознавать котиков, чтобы включать брызгалку». Если им дать доступ к чему-то не очень сложному для них, то они начнут с этим играться. Если не дать — вряд ли они для этого будут изучать питон. Что будет дальше — неизвестно, но когда этим людям дали ноду, случился какой-то чудовищный буст в развитии и фронтэнда, и бэкэнда. Я очень надеюсь, что тут случится такая же история.
> Для задачи «загружаем веса» уже есть keras.js.
Я так понял, что Synaptic были первее. Цитата со страницы keras.js. Но да, получается что сейчас keras.js для такой задачи удобнее.
> Inspiration is drawn from a number of deep learning / neural network libraries for JavaScript and the browser, including Tensorflow Playground, ConvNetJS, synaptic, brain, CaffeJS, MXNetJS. However, the focus of this library is on inference only.
Ок, если TF будет бэкэндом, то да, получится js wrapper, который кому-то может быть удобен.
Я так понял, что Synaptic были первее. Цитата со страницы keras.js. Но да, получается что сейчас keras.js для такой задачи удобнее.
> Inspiration is drawn from a number of deep learning / neural network libraries for JavaScript and the browser, including Tensorflow Playground, ConvNetJS, synaptic, brain, CaffeJS, MXNetJS. However, the focus of this library is on inference only.
Ок, если TF будет бэкэндом, то да, получится js wrapper, который кому-то может быть удобен.
Еще на Coursera есть классный курс по основам анализа данных и машинного обучения от Яндекса и МФТИ: https://www.coursera.org/learn/mathematics-and-python/
А можно подборку книг, блогов, сайтиков каких-то на данную тематику?
Понимаю, конечно, что надо бы и самому поискать, но может всё же да? (-:
Понимаю, конечно, что надо бы и самому поискать, но может всё же да? (-:
Господа, вопрос в лоб — почему сигмоиду всегда рисуют сжатой по оси X?
Она ведь намного более пологая (производная у нее довольно невелика). По этому типичному графику с диспропорциями осей можно делать другие выводы…
Она ведь намного более пологая (производная у нее довольно невелика). По этому типичному графику с диспропорциями осей можно делать другие выводы…
Запрашиваю перевод hacker's guide и таки внос кода в статью с комментариями.
Если вы под hacker's guide подразумеваете то, что выложено на RunKit — то оно изначально делалось как на русском, так и на английском же, и ссылки обе есть. Или вы о чем?
Hacker's guide to neural networks — более понятно и обширно рассказывает содержимое вашей статьи. А вот как смотреть код на runkit мне непонятно.
Да и вообще vanilla.js был бы понятнее, благо языковые средства позволяют использовать тот же
Слишком легко можно сделать что-то не так.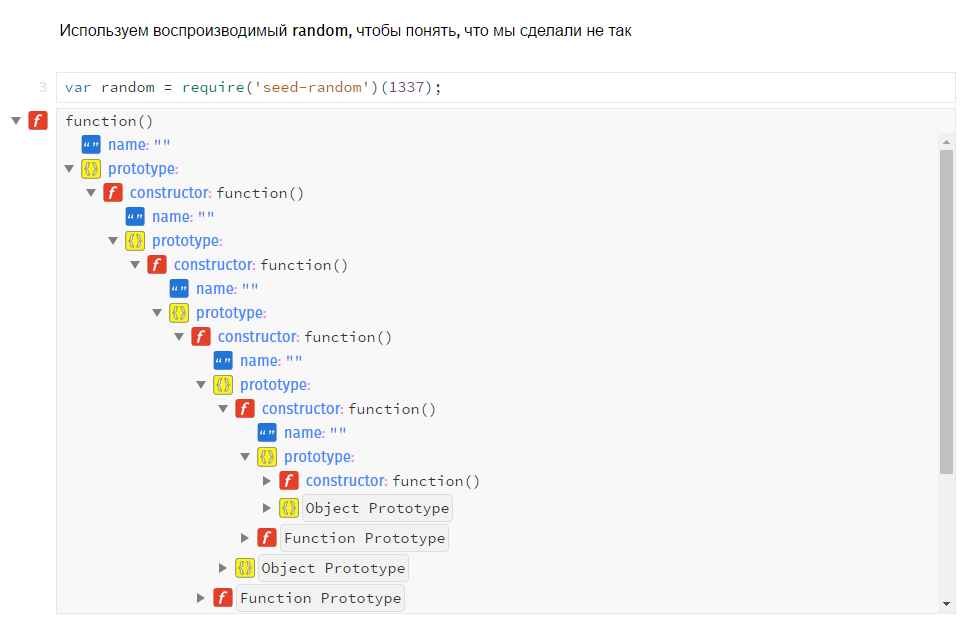

Да и вообще vanilla.js был бы понятнее, благо языковые средства позволяют использовать тот же
map() использовать. А то как-то не с нуля оно в итоге выходит. Еще дополнительно придется смотреть что там за _.mean() и прочие функции loadash. Конечно же ждем продолжения с рассказом как из вот такого простого кирпича сделать что-то более полезное, чем предсказатель xor
Можете посмотреть еще мою статью:
Нейронные сети на Javascript
Наконец-то хоть кто-то человеческим языком без лишнего матана объяснил как нейронные сети работают.
tensorflow nodejs
тоже в свободное время занимаюсь счетом на gpu, планировал добраться и до нейронных сетей но за два года руки так и не дошли.
Первый признак хорошей статьи – комментарии к деталям, зачастую не самым важным. Спасибо, очень интересно и доступно!
Не могли бы разъяснить что делает нейронная сеть, которая XOR? И чему она обучается? Что означают веса в этом случае? Она что, просто считает XOR? Или как?
О боооже, яростно благодарю! когда у меня в универе был предмет «искусственный интеллект», мне реально не хватало этой статьи! да и преподу она тоже не помешала бы.
Прочитал уже не один десяток статей по нейронным сетям, но только после этой у меня осталось ощущение, что я действительно начал что-то понимать. Спасибо!
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Нейронные сети на JS. Создавая сеть с нуля