Ну что ж, Хабражители, пришло время подытожить цикл статей (часть 1 и часть 2), посвященных моему приключению с автоматизацией развертывания Hadoop кластера.

Мой проект практически готов, осталось только оттестировать процесс и можно делать себе насечку на фюзеляже.
В этой статье я расскажу про поднятие «движущей силы» нашего кластера — Slaves, а также подведу итоги и предоставлю полезные ссылки на ресурсы, которыми я пользовался на протяжении своего проекта. Возможно, кому-то статьи показались скудными на исходный код и детали реализации, поэтому в конце статьи я предоставлю ссылку на Github
Что ж, по привычке, в самом начале приведу схему архитектуры, которую удалось развернуть в облако.
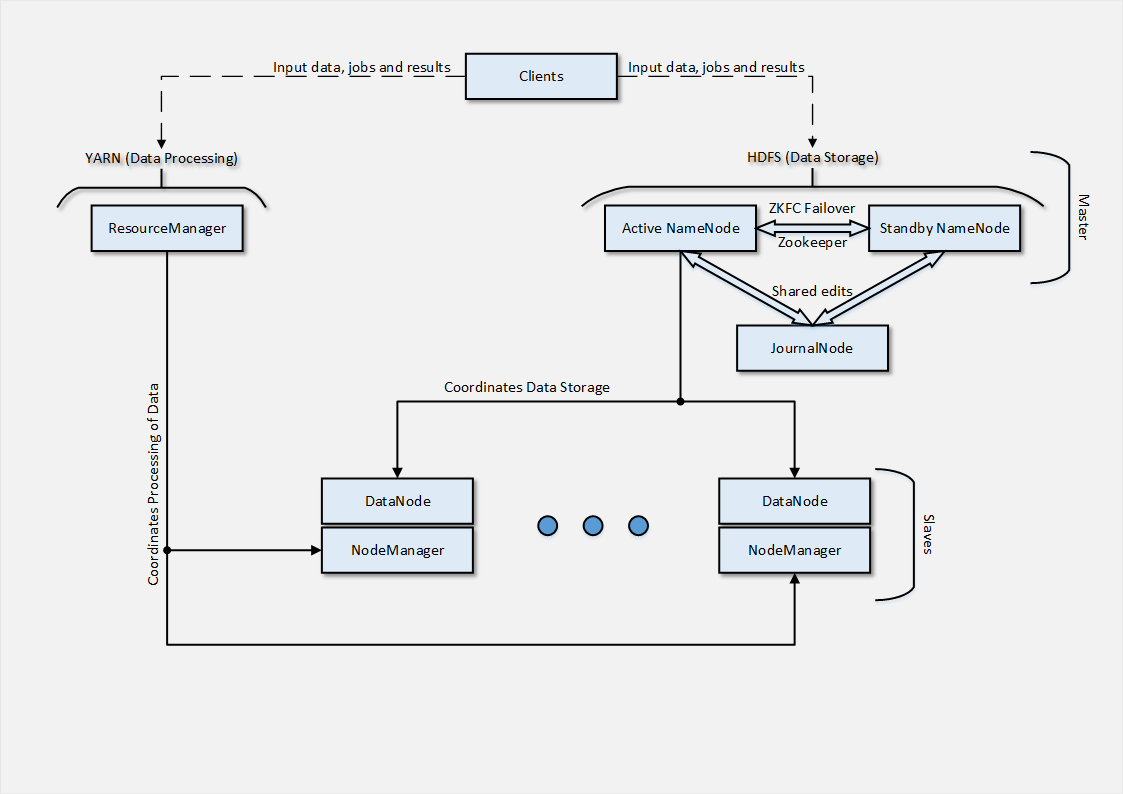
В нашем случае, учитывая тестовый характер прогона, было использовано всего 2 Slave-узла, однако в реальных условиях их были бы десятки. Далее, я расскажу вкратце как было организовано их развертывание.
Как можно догадаться из архитектуры — Slave-узел состоит из 2 частей, каждая из которых отвечает за действия, связанные с частями Masters-архитектуры. DataNode является точкой взаимодействия Slave-узла с NameNode, которая координирует распределенное хранение данных.
Процесс DataNode подключается к сервису на NameNode-узле, после чего Clients могут обращаться с файловыми операциями напрямую к DataNode-узлам. Также стоит отметить, что DataNode-узлы ведут коммуникации между собой в случае репликации данных, что в свою очередь позволяет уйти от использования RAID-массивов, т.к. механизм репликации уже заложен программно.
Процесс развертывания DataNode достаточно прост:
В итоге, если все данные указаны верно и конфигурация применена — на web-интерфейсе NameNode-узлов можно будет увидеть добавленных Slave-узлов. Это означает, что DataNode-узел теперь доступен для файловых операций, связанных с распределенным хранением данных. Скопируйте файл в HDFS и убедитесь сами.
NodeManager, в свою очередь, отвечает за взаимодействие с ResourceManager, который управляет задачами и ресурсами, доступными для их выполнения. Процесс развертывания NodeManager аналогичен процессу в случае с DataNode, с разницей в имени пакета для установки и сервиса (hadoop-yarn-nodemanager).
После успешного завершения развертывания Slaves-узлов — можно считать наш кластер готовым. Стоит обратить внимание на файлы, устанавливающие переменные среды (hadoop_env, yarn_env, etc.) — данные в переменных должны соответствовать реальным значениям в кластере. Также, стоит обратить внимание на верность значений переменных, в которых указываются доменные имена и порты, на которых работает тот или иной сервис.
Как мы можем проверить работоспособность кластера? Самый доступный вариант — запуск задания с одного из Clients-узлов. Например, вот так:
где hadoop-mapreduce-examples-2.2.0.jar — имя файла с описанием задания (доступно в базовой инсталяции), pi — указывает на тип задания (MapReduce Task в данном случае), а 2 и 5 — отвечают за параметры дистрибуции заданий (детальнее — тут).
Результатом, после проведения всех вычислений, будет вывод в терминал со статистикой и результатом вычислений, либо создание output-файла с выводом данных туда (характер данных и формат вывода их зависит от задания, описанного в .jar-файле).
<Конец/>
Вот такие кластеры и пироги, уважаемые Хабражители. На данном этапе — я не претендую на идеальность данного решения, т.к. впереди еще этапы тестирования и внесения улучшений/правок в код cookbook-а. Хотелось поделится опытом, описать еще один подход к развертыванию кластера Hadoop — подход не самый простой и ортодоксальный, я бы сказал. Но именно в таких нетрадиционных условиях — закаляется «сталь». Моя финальная цель — скромный аналог Amazon MapReduce сервиса, для нашего приватного облака.
Я очень приветствую советы от всех, кто уделит и уделил внимание этому циклу статей (отдельное спасибо ffriend, который уделил внимание и задавал вопросы, некоторые из которых навели меня на новые идеи).
Как и обещал, вот перечень материалов, которые, на ряду с моими коллегами, помогли довести проект до приемлемого вида:
— Детальная документация по HDP дистрибутиву — docs.hortonworks.com
— Wiki от отцов, Apache Hadoop — wiki.apache.org/hadoop
— Документация от них же — hadoop.apache.org/docs/current
— Немного устаревшая (в терминах) статья-описание архитектуры — тут
— Неплохой tutorial в 2 частях — тут
— Адаптированный перевод tutorial от martsen — habrahabr.ru/post/206196
— Community cookbook "Hadoop", на основе которого я сделал свой проект — Hadoop cookbook
— В итоге — мой скромный проект как он есть (впереди обновления) — GitHub
Всем спасибо за внимание! Комментарии — приветствуются! Если могу чем-то помочь — обращайтесь! До новых встреч.
UPD. Добавил ссылку на статья на Хабре, перевод tutorial-а.

Мой проект практически готов, осталось только оттестировать процесс и можно делать себе насечку на фюзеляже.
В этой статье я расскажу про поднятие «движущей силы» нашего кластера — Slaves, а также подведу итоги и предоставлю полезные ссылки на ресурсы, которыми я пользовался на протяжении своего проекта. Возможно, кому-то статьи показались скудными на исходный код и детали реализации, поэтому в конце статьи я предоставлю ссылку на Github
Что ж, по привычке, в самом начале приведу схему архитектуры, которую удалось развернуть в облако.
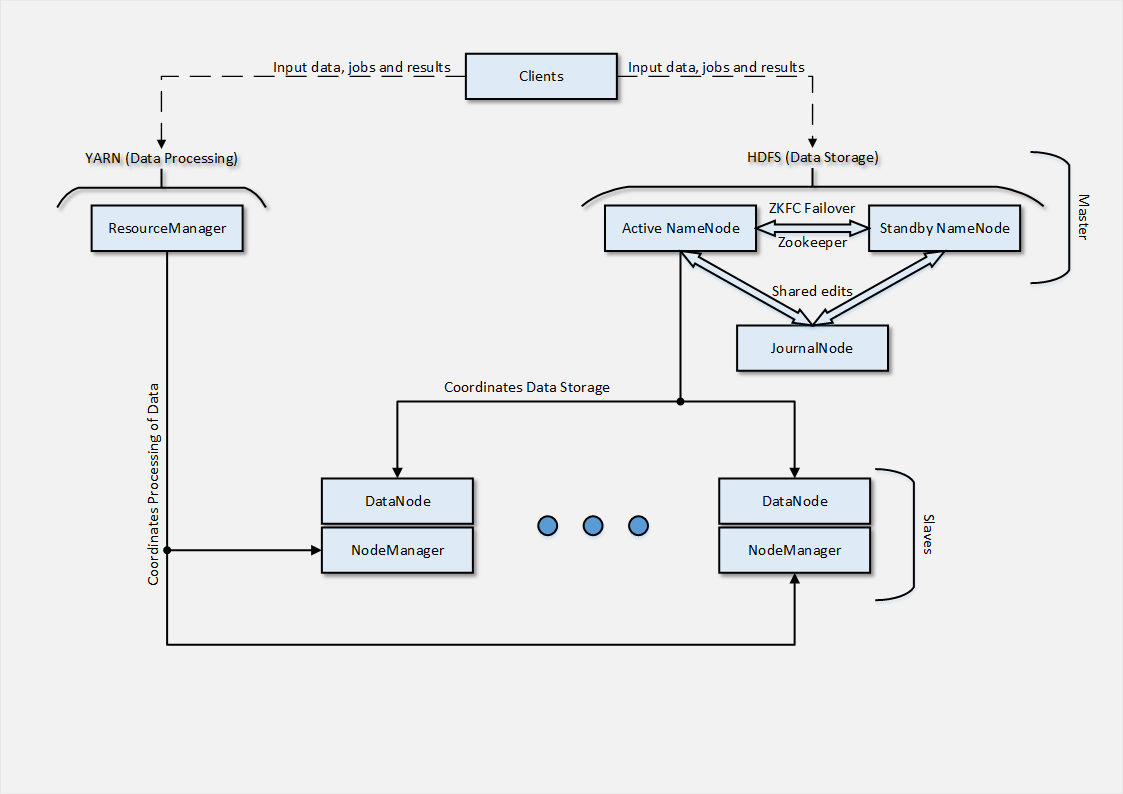
В нашем случае, учитывая тестовый характер прогона, было использовано всего 2 Slave-узла, однако в реальных условиях их были бы десятки. Далее, я расскажу вкратце как было организовано их развертывание.
Развертывание Slaves-узлов
Как можно догадаться из архитектуры — Slave-узел состоит из 2 частей, каждая из которых отвечает за действия, связанные с частями Masters-архитектуры. DataNode является точкой взаимодействия Slave-узла с NameNode, которая координирует распределенное хранение данных.
Процесс DataNode подключается к сервису на NameNode-узле, после чего Clients могут обращаться с файловыми операциями напрямую к DataNode-узлам. Также стоит отметить, что DataNode-узлы ведут коммуникации между собой в случае репликации данных, что в свою очередь позволяет уйти от использования RAID-массивов, т.к. механизм репликации уже заложен программно.
Процесс развертывания DataNode достаточно прост:
- Установка пререквизитов в виде Java;
- Добавление репозиториев с пакетами Hadoop дистрибутива;
- Создание костяка директорий, необходимых для установки DataNode;
- Генерация файлов конфигурации на основе шаблона и атрибутов cookbook-а
- Установка пакетов дистрибутива (hadoop-hdfs-datanode)
- Запуск процесса DataNode путем
service hadoop-hdfs-datanode start; - Регистрация статуса процесса развертывания.
В итоге, если все данные указаны верно и конфигурация применена — на web-интерфейсе NameNode-узлов можно будет увидеть добавленных Slave-узлов. Это означает, что DataNode-узел теперь доступен для файловых операций, связанных с распределенным хранением данных. Скопируйте файл в HDFS и убедитесь сами.
NodeManager, в свою очередь, отвечает за взаимодействие с ResourceManager, который управляет задачами и ресурсами, доступными для их выполнения. Процесс развертывания NodeManager аналогичен процессу в случае с DataNode, с разницей в имени пакета для установки и сервиса (hadoop-yarn-nodemanager).
После успешного завершения развертывания Slaves-узлов — можно считать наш кластер готовым. Стоит обратить внимание на файлы, устанавливающие переменные среды (hadoop_env, yarn_env, etc.) — данные в переменных должны соответствовать реальным значениям в кластере. Также, стоит обратить внимание на верность значений переменных, в которых указываются доменные имена и порты, на которых работает тот или иной сервис.
Как мы можем проверить работоспособность кластера? Самый доступный вариант — запуск задания с одного из Clients-узлов. Например, вот так:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 5
где hadoop-mapreduce-examples-2.2.0.jar — имя файла с описанием задания (доступно в базовой инсталяции), pi — указывает на тип задания (MapReduce Task в данном случае), а 2 и 5 — отвечают за параметры дистрибуции заданий (детальнее — тут).
Результатом, после проведения всех вычислений, будет вывод в терминал со статистикой и результатом вычислений, либо создание output-файла с выводом данных туда (характер данных и формат вывода их зависит от задания, описанного в .jar-файле).
<Конец/>
Вот такие кластеры и пироги, уважаемые Хабражители. На данном этапе — я не претендую на идеальность данного решения, т.к. впереди еще этапы тестирования и внесения улучшений/правок в код cookbook-а. Хотелось поделится опытом, описать еще один подход к развертыванию кластера Hadoop — подход не самый простой и ортодоксальный, я бы сказал. Но именно в таких нетрадиционных условиях — закаляется «сталь». Моя финальная цель — скромный аналог Amazon MapReduce сервиса, для нашего приватного облака.
Я очень приветствую советы от всех, кто уделит и уделил внимание этому циклу статей (отдельное спасибо ffriend, который уделил внимание и задавал вопросы, некоторые из которых навели меня на новые идеи).
Ссылки на материалы
Как и обещал, вот перечень материалов, которые, на ряду с моими коллегами, помогли довести проект до приемлемого вида:
— Детальная документация по HDP дистрибутиву — docs.hortonworks.com
— Wiki от отцов, Apache Hadoop — wiki.apache.org/hadoop
— Документация от них же — hadoop.apache.org/docs/current
— Немного устаревшая (в терминах) статья-описание архитектуры — тут
— Неплохой tutorial в 2 частях — тут
— Адаптированный перевод tutorial от martsen — habrahabr.ru/post/206196
— Community cookbook "Hadoop", на основе которого я сделал свой проект — Hadoop cookbook
— В итоге — мой скромный проект как он есть (впереди обновления) — GitHub
Всем спасибо за внимание! Комментарии — приветствуются! Если могу чем-то помочь — обращайтесь! До новых встреч.
UPD. Добавил ссылку на статья на Хабре, перевод tutorial-а.
