Привет! Я Павел, тимлид группы DWH, отвечающей за сбор, хранение и выдачу потребителям аналитических данных. Эту статью мы написали вместе с руководителем Data Office Олегом Сахно.
Сегодня многие говорят об управлении на основе данных, когда решения принимаются только после подкрепления цифрами. Идея заманчивая. Надо всего лишь:
Хранить все данные в понятном и структурированном виде.
Обеспечить пользователям оперативный доступ к данным.
…
Profit!
Хранение данных — тема отдельного разговора, и сейчас мы её поднимать не будем. Поговорим о том, как сделать эти данные доступными и легко применимыми для пользователей.
Немного о контексте. eLama — это платформа по управлению интернет-рекламой. У нас большая команда, ведь нужно не только обеспечивать работоспособность сервиса, но и осуществлять поддержку текущих клиентов (служба Заботы), привлекать новых клиентов (маркетинг и отдел продаж), всё это делится на несколько бизнес-юнитов с различной иерархией и правами доступа к данным и т.д.
А еще есть операционный отдел, финансовые службы и так далее. Всего в команде более 300 человек. И многим из них нужна информация, извлекаемая из данных! Все хотят принимать решения обоснованно, не просто «по велению сердца».
Иными словами, нам нужен инструментарий, который позволяет пользователю любой роли получить из хранилища витрину данных, отвечающую нужным ему условиям.
История вопроса в eLama
Немного о том, как мы пришли в точку «Сейчас».
Redash
После организации единого хранилища данных на базе Google BigQuery для визуализации мы прикрутили к нему сервис Redash. Для каждого юнита родились десятки дашбордов, каждый из которых насчитывал десятки виджетов-графиков .
Эти инструменты почти не давали пользователю возможности настраивать выборку под себя. Стоило, например, маркетологу захотеть выбрать юзеров, пришедших с его источников (при том, что визуализации в разрезе по источникам не было), Redash становился для него бесполезен.
Microsoft Power BI
На смену простенькому Redash (от которого в итоге полностью отказались) пришел Power BI со своим богатым арсеналом фильтров. Вдохновившись его возможностями, мы разработали пару, вроде как, универсальных отчетов, которые помогали настроить пользователю выгрузку под свои нужды.
Эти отчеты некоторые потребности закрыли, но далеко не все. Power BI все-таки предназначен не для такого. Из-за своей громоздкости он плохо уживается со сложными данными и алгоритмами расчета. Также у него есть существенные ограничения по объему данных — как на входе, так и на выходе. Действительно универсальным этот инструмент так и не стал.
Типовые запросы
Гибкости мы добавляли «вручную»: организовали институт дежурства, когда выделенный еженедельно сменяемый аналитик готовил SQL-запрос для выгрузки под каждое обращение внутренних заказчиков. Времени на это уходила масса, дежурный фактически выпадал из остальных процессов, часто ему еще и требовалась помощь.
Стремясь разгрузиться, аналитики стали создавать репозиторий… хотя какой там репозиторий... склад SQL-запросов под часто возникающие потребности сотрудников. Пользователь, не желающий ждать в очереди, теперь мог зайти на страницу с перечнем таких типовых запросов, подобрать себе нужный и выгрузить витрину самостоятельно. Конечно, мы снабдили код комментариями, где менять условия выборки, что по идее должно было еще более облегчить нам жизнь.
Подход «Типовые запросы» одарил нас целым букетом недостатков:
конечные пользователи не владели SQL (и не обязаны владеть!), а значит в их запросы могли закрасться ошибки;
с ростом количества узких запросов стало всё больше времени уходить на поиск нужного;
часто пользователи сохраняли запрос из репозитория куда-то к себе, то есть фактически «отключали» его от обновлений. А если поменяется логика? Запрос станет неактуален, но будет по-прежнему в чьем-то использовании!
по сути, весьма редко запросы являлись «типовыми», ведь данные для того и нужны, чтобы в поисках инсайтов вертеть и крутить их без ограничения свободы.
Короче, наш склад типовых выгрузок использовался редко и неохотно.
Формулировка задачи
Все указанные выше инструменты не позволяли реализовать полный спектр задач автоматической выдачи данных:
Пользователи самостоятельно могут получить выгрузку из аналитического хранилища в соответствии с уровнем доступа к данным. Имеется учет доступа к данным.
Пользователи могут обогатить список user_id необходимыми данными. То есть, к имеющийся таблице добавить несколько полей.
Пользователи не должны самостоятельно писать или редактировать SQL-код. Необходим интерфейс в котором пользователь «натыкает» нужные галочки.
Инструмент постоянно развивается. Необходимо удобство развития инструмента, логика релизов и т.д.
Мы используем Google Cloud Platform, и решение должно гармонично вписываться в эту экосистему.
Решение на основе Colab
Оказалось, что решить поставленные перед нами задачи позволяет Google Colab — бесплатный облачный сервис на основе Jupyter Notebook. Сервис позволяет работать с Python-ноутбуками как с обычными документами Google. С той же логикой по правам на редактирование и на доступ и удобным доступом по ссылке в браузере. Таким образом, код на Python можно дистрибутировать без необходимости устанавливать программное обеспечение на клиентской стороне, при этом сам код можно скрыть, оставив только интерфейс ввода данных.
И итоге мы построили следующее решение.
Разработаны несколько «колабов» (так мы называем этот инструмент), из которых чаще всего используются 3-4 (вместо десятков «типовых запросов»).
При необходимости получить выгрузку с определенными условиями сотрудники компании открывают браузер, запускают скрипт, авторизуются и видят форму, в которой могут задать настройки для своей выгрузки.

По условиям пользователя формируется SQL-запрос, который с помощью соответствующей библиотеки исполняется в BigQuery. Полученная от BigQuery таблица выгружается либо в Google Sheet, либо в xlsx-файл в зависимости от количества строк.
Вот и всё, сотрудник радуется быстро полученной таблице. Не надо ждать, не надо звать, а можно взять и выгрузить всё что тебе надо!
Со стороны дата-аналитиков это большая разгрузка, поток обращений за выгрузками превратился в тонкий ручеек. Да и то теперь каждое обращение мы складываем в бэклог, откуда оно попадает в разработку новых возможностей для колабов.
Техническая реализация колаба
В общих чертах скрипт колаба состоит из 4 частей:
Авторизация в Google и подключение библиотек.
Построение и вывод формы для настройки условий выборки.
Формирование SQL-запроса.
Исполнение запроса и вывод результатов.
Авторизация и библиотеки
Для авторизации используем всего две строки кода:
from google.colab import auth # Авторизуемся в Google
auth.authenticate_user() # Получаем заветный токенПри его исполнении пользователю будет предложено пройти по ссылке, совершить вход через свой аккаунт в Гугле, получить строку-ключ и вставить ее в поле-замок.
Из библиотек мы используем:
pandas для работы с датафреймами, google.cloud.bigquery для обращения к BigQuery, gspread для работы с Google Sheet, ipywidgets для построения формы, а также pydrive при необходимости обращаться к Google Drive.
Форма пользователя
Форму строим на виджетах из библиотеки ipywidgets, которая дает всё необходимое — и основные контролы, и их форматирование, и расположение.
Выбранные через форму параметры передаются в функцию построения SQL-запроса.
Формирование SQL-запроса
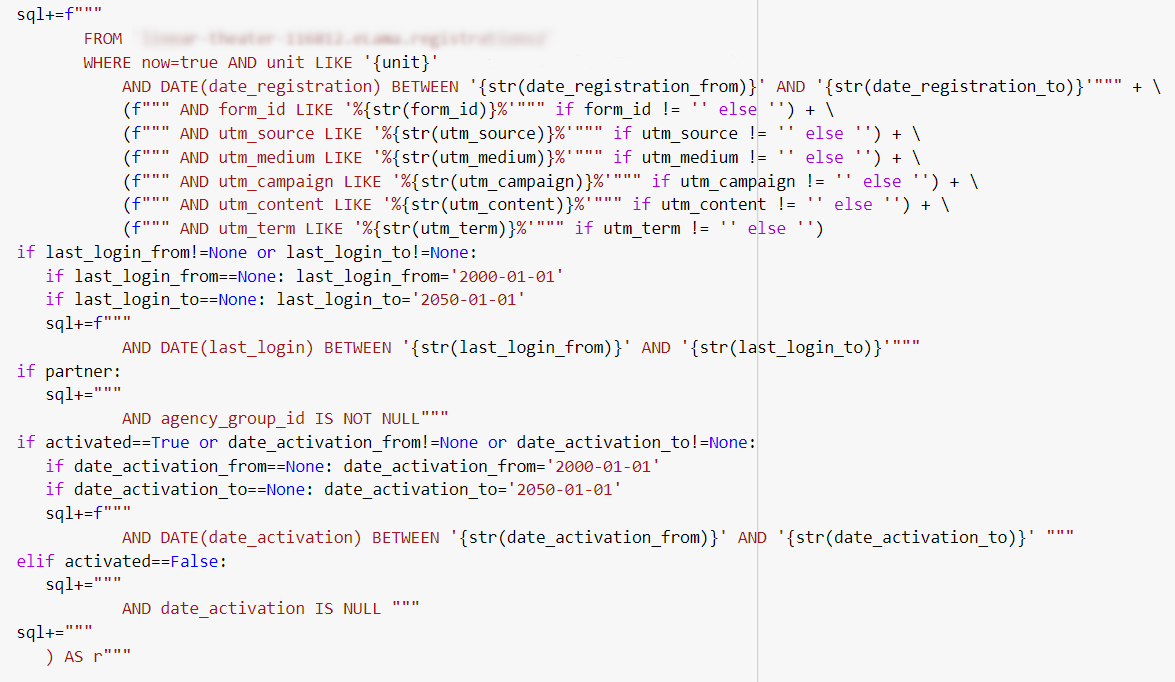
Запрос формируется в виде текстовой строки, в которой условия и выводимые поля добавляются исходя из переданных в функцию параметров, набранных юзером в форме. Идея в том, чтобы не выводить пользователю поля, которые он не просил, иначе итоговая таблица будет настолько широкой, что в ней легко потонуть.
Здесь обычно всё сводится к проверке условий и добавлении нужного кусочка SQL, если они принимают соответствующее значение.
Получение результатов
Когда SQL-запрос готов, запускаем его, а результат выводим в Google.Sheet, если строк менее 50 000, и в Excel-файл, если больше.
print("Running the query. Please wait...")
# запуск запроса в BQ, запись результата в датафрейм
result=bigquery.Client(project='BQ_PROJECT_ID').query(sql).to_dataframe()
if len(result)==0: print('Result is empty (0 rows)')
if len(result)<=50000 and len(result)>0:
source_google_sheet_file='query_'+str(datetime.now())
result_sheet='Лист1'
print("Saving result...")
# Запись результата в Google Sheet
id=save_to_sheets(result, source_google_sheet_file, result_sheet)
print('The result is written to Google SpreadSheet:')
print("https://docs.google.com/spreadsheets/d/%s" % id)
elif len(result)>50000:
display(widgets.HTML("<hr />"))
print('The result has more than 50 000 rows. Writing to Excel file...')
# Запись результата в файл xlsx
result.to_excel('query_result.xlsx')
display(widgets.HTML("<hr />"))
print('Please download the result file.')
from google.colab import files
files.download('query_result.xlsx')Сопровождение колаба
Так как количество видов данных, а также число идей по их использованию постоянно растет, мы непрерывно наращиваем функциональность наших колабов. Для этого мы внедрили ритмичный процесс, состоящий из 4-х этапов:
Сбор пожеланий. Здесь мы собираем в бэклог пожелания из обращений. Пожелание заносится сразу по мере поступления.
Планирование релиза. Изучаем пожелания, превращаем их в технические задачи и формируем план на ближайший спринт.
Разработка. Реализуем план, документируем нововведения.
Выкатывание релиза. Деплой и — важный шаг, о котором часто забывают — публикация перечня нововведений. В наших интересах — чтобы пользователи переходили от обращений к дежурным к самостоятельному использованию колаба, поэтому крайне важно раструбить о новшествах где только возможно.
Конечно, сейчас еще не всё идеально, но основные свои задачи инструмент выполняет: разгружает дата-аналитиков, ускоряет получение данных пользователями и при этом достаточно прост в сопровождении.
