Шрияс Виджайкумар, ведущий инженер по внедрению, расскажет про еще один элемент внутренней кухни системы Palantir.

Как организации управляются с данными, на текущий момент?
В существующих системах встречаются довольно распространенные артефакты, и многие из них, если не все, вам знакомы:
Что мы принципиально иначе делаем в Palantir?
Когда мы разрабатывали систему, мы много работали с обратной связью от сообщества. Первое, что мы постарались запроектировать — это максимальная гибкость системы, дающая возможность моделировать все что угодно.
Гибкость означает, возможность работать с любыми типами данных в одном общем пространстве: от высокоструктурированных, таких как базы данных с выстроенными отношениями, до неструктурированных, таких как хранилище трафика сообщений, а также всех, находящихся между этими крайностями. Это также означает возможность создавать множество разнообразных полей для исследования без привязки к одной модели построения. Как и организация, они могут изменяться и эволюционировать со временем.
Следующей вещью, которую мы спроектировали, стало обобщение данных без потерь. Нам нужна платформа, которая бы отслеживала каждый обрывок информации до его источника или источников. В мультиплатформенной системе важное значение имеет контроль доступа, особенно если такая система, позволяет совершать всю полноту действий с данными.

2:26 Следующая спроектированная нами вещь: открытый формат и API. Подлинная платформа для работы с данными позволяет вам вводить данные в систему, взаимодействовать с данными в этой системе, и выводить данные из системы, чтобы вы могли совершить с этими данными необходимые операции.
2:38 Объектная модель — ядро Palantir, и, так или иначе, её можно увидеть в каждом нашем видео.
2:45 Теперь давайте посмотрим как модель встроится в общую картину.

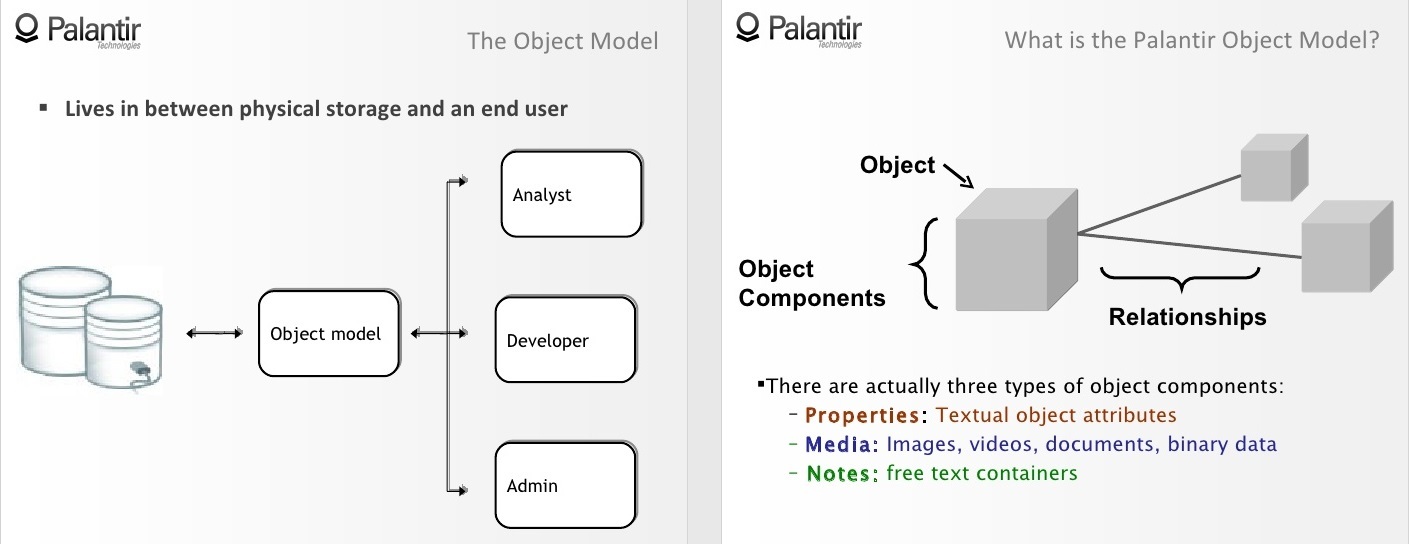
2:50 Объектная модель — это абстракция, находящаяся между физическим хранилищем данных и конечным пользователем. В нашем случае конечным пользователем может быть аналитик на рабочем месте, разработчик или администратор.
3:07 Через объектную модель все пользователи взаимодействуют с данными, как с абстрактным объектом первого порядка (first order conceptual object), вместо того чтобы собираться за общим столом, делиться видением, заниматься воспроизведением хранимых процедур (store procedure) снова и снова.
3:22 Теперь, когда у нас есть понимание, как модель выглядит в общей картине, давайте перейдем к структуре. Что собой представляют эти объекты?

3:36 Сперва, объект — это пустой контейнер, оболочка, которую мы наполни атрибутами и известной информацией. Примерами объектов могут служить такие сущности, как: люди, места, телефоны, компьютеры, события, такие как встреча, например, телефонные звонки, документы, электронные письма, и другое.
3:54 Все эти объекты обладают тем, что мы называем компонентами объекта (object components).
3:58 Есть четыре типа компонентов объекта, три из них мы сейчас перечислим:
— признаки, то есть текстовые атрибуты, такие как имена, мейлы и прочие;
— медиафайлы, что позволяет ассоциировать с объектом изображения, видео, тексты и любые другие бинарные форматы данных;
— заметки, то есть свободные текстовые поля для аналитиков.
4:18 Теперь у нас есть объекты, в которых мы храним информацию и есть связи, которые соединяют объекты.
4:28 Эта система объектов и компонентов объектов, дает представление об объектной модели. Причина, по которой мы можем моделировать такое количество «полей» (domain — поле, сфера, область; скорее всего, речь идет об отдельном рабочем пространстве в общем Palantir’е) в том, что мы не прописали никакой семантики внутри объекта как такового.
4:42 Я не говорил, что отношения должны быть объединяющими, управляющими или иерархическими, объектная модель существует до этих понятий. Каждая организация индивидуально определяет семантику, используя динамическую онтологию.
4:56 Давайте посмотрим как объектная модель и динамическая онтология взаимодействуют, создавая необходимую организации семантику.
5:03 Воспользуемся примером. Здесь у нас очень простой граф, состоящий из двух объектов, содержащих некоторые компоненты, и отношений.
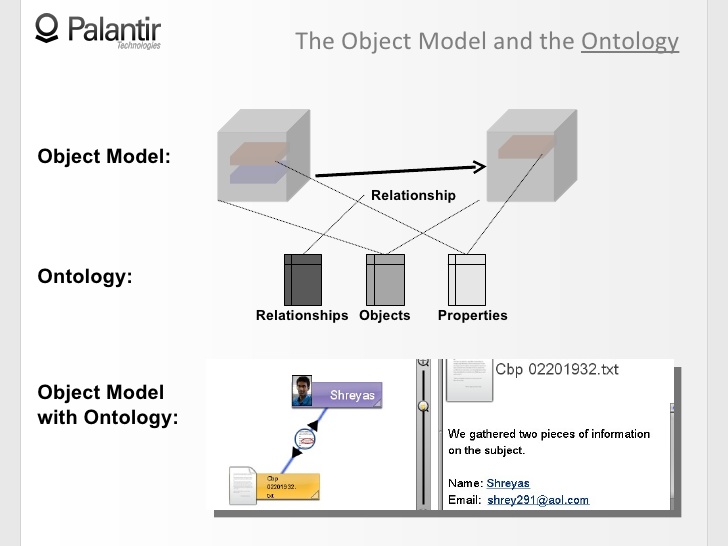
5:12 Здесь нет семантики. Некая организация сейчас будет выбирать типы объектов, признаков и отношений, нужные ей.
5:22 Если я занимаюсь сетевой безопасностью, это могут быть роутеры и хосты, если контр-терроризмом — это могут быть террористические организации, деньги и члены групп.
5:38 Если теперь совместить объектную модель с онтологией, вы ожидаемо получите некоторую семантику, например: Зак работает в Palantir.
5:50 Такой же, с объектной точки зрения, граф может нести совершенно другой смысл: он может указывать на наличие документа.
6:00 Абстрагировав семантику от структуры, мы получили возможность создавать широкий спектр «полей» доступным и гибким образом.
6:09 Есть дань которую нужно заплатить, если вы хотите гибкости, и эта дань вам должна быть очень знакома.
6:22 Цена за возможность для системы быть гибкой — это почти всегда потеря поддержки возможности создавать схемы.
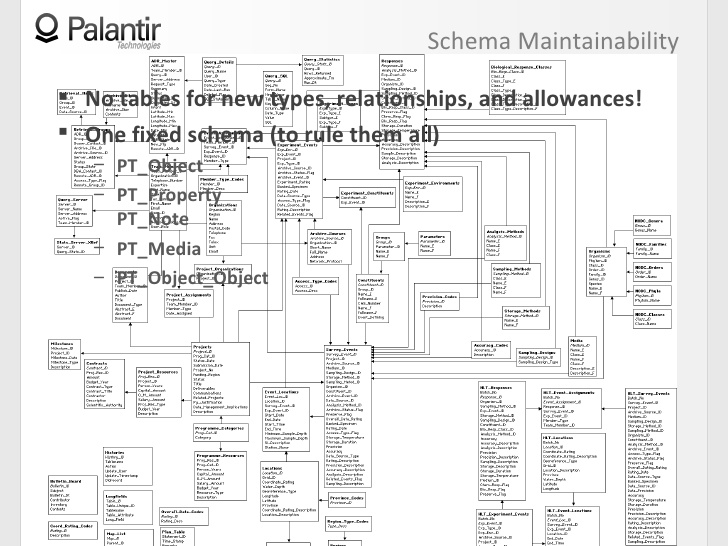
6:29 Вы можете добавить новый тип объектов или вид связей, но это будет стоить вам пяти отдельных связанных таблиц, с пояснениями, указаниями и прочим.
6:41 Так что это действительно сложно поддерживать и это не то, чего вы, в действительности, хотите от платформы по работе с данными.
6:45 В Palantir мы используем противоположный подход: нет необходимости в создании новых таблиц для типов объектов, отношений, допустимых ограничений.
6:57 Если быть точнее, то в Palantir есть одна схема, которую мы используем в каждой организации и при каждом внедрений.
7:02 Существует пять таблиц, из которых вы можете брать контент для любого объекта и любого компонента объектов, при этом неважно, моделируете ли вы документы на основе трафика сообщений или высокоструктурированной базы данных.
7:15 Так что, если взглянуть на то как объектная модель смотрится в общей картине, на структуру самой объектной модели и то, как она взаимодействует с динамической онтологией, мы увидим высокую гибкость и способность создавать множество «полей».
7:29 Сейчас поговорим о том, как мы внедрили извлечение данных без потерь.
7:35 Самое важное здесь — источники данных, ну, потому что вся информация, которая есть в Palantir, взялась из источников.
7:43 Примеры. Это может быть все что угодно: налоговые документы, электронные таблицы, файлы xml, базы данных, web-страницы. Созданное самим аналитиком во время работы, все равно основано на информации из источников.
7:58 Это почему важно? У вас что-то есть, продукт: вам нужно проследить, откуда он появился, на чем основан, вернуться к источникам и убедиться в отсутствии искажений, — это единственный способ быт уверенным в своих выводах.
8:11 Теперь посмотрим на связи между источниками данных и объектной моделью, которую я вам описал.
8:17 Каждый компонент объекта в Palantir содержит запись об источнике своих данных. Эта запись связывает информацию с источником или несколькими источниками.
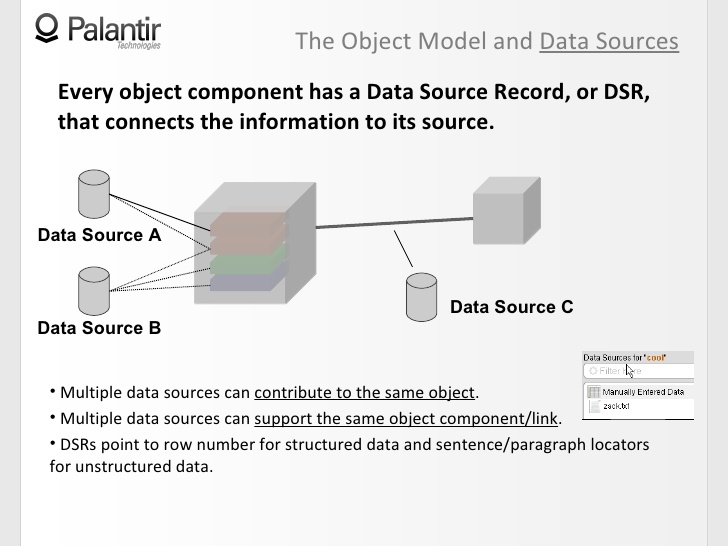
8:25 Так что, если я хочу обосновать свой граф, мы увидим что эти два объекта поддерживаются источниками A, B и C.
8:34 Еще вы можете увидеть что несколько источников поддерживают один компонент объекта, и я, таким образом, больше уверен в этом кусочке информации, ведь он опирается на данные из хранилища трафика и логов операторов, например. Оба источника подтверждают информацию, я могу двигаться дальше, основываясь на ней.
9:00 Записи об источниках данных информируют чуть более точно, чем просто указание на источники данных, если мы имеем дело с неструктурированными источниками. Так, например, если это документ, запись укажет на конкретное место в документе. В структурированных базах данных эта запись об источнике может указывать на первичный ключ.
9:17 Теперь когда мы увидели, как источники данных связаны с объектами, давайте посмотрим какие операции мы можем здесь совершить.
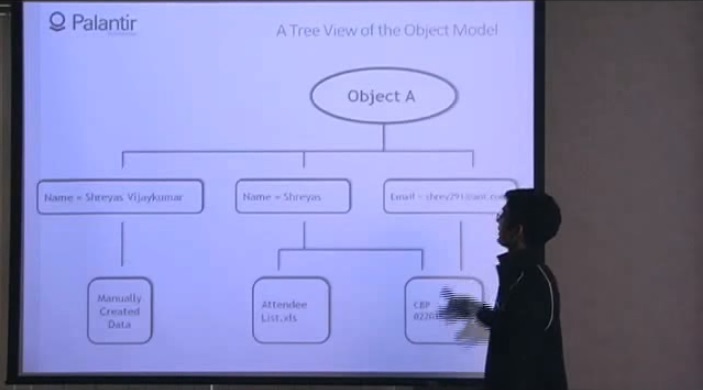
9:23 Мы видим граф упрощенный до предела, он состоит из одного объекта, содержащего два компонента, и двух признаков. «Имя: Шрияс», и «мейл: shrey291@aol.com».
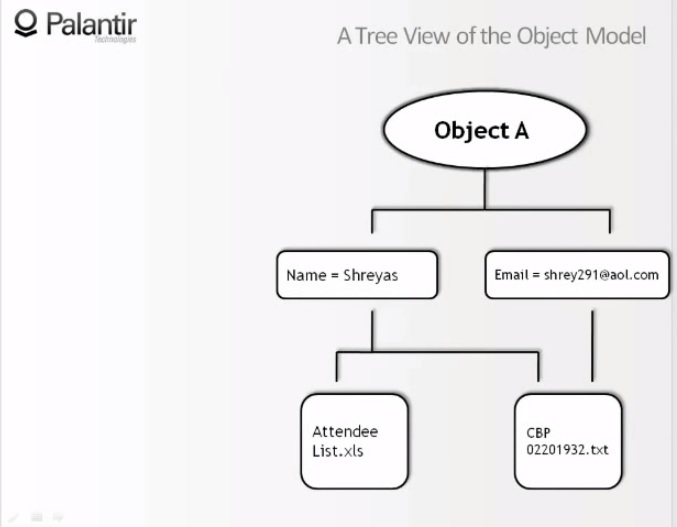
9:37 И мы видим, что имя взято из электронной таблицы посетителей (attendee — участник, слушатель, посетитель), и из текстового документа, а мейл взят только из текстового документа.
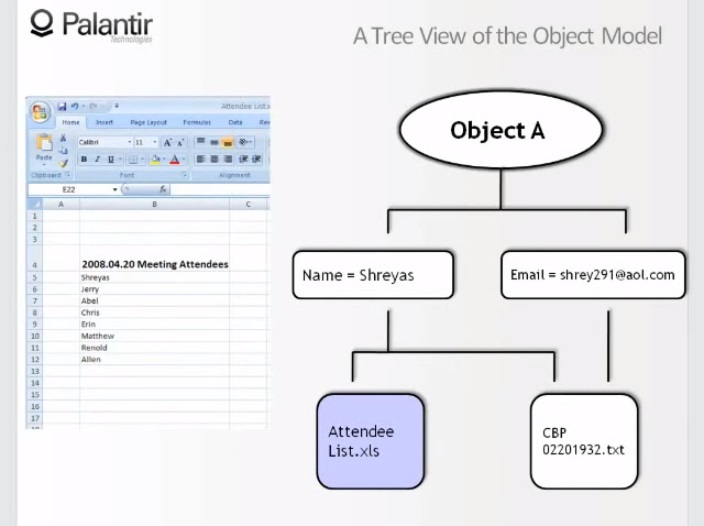
9:46 Давайте посмотрим на эти источники. Во-первых, список посетителей: мы видим, что имя Шрияс взято из сырого файла, чего-то вроде выдержки из другого источника.
10:00 Представьте, что второй, текстовый файл был отозван (recall), или у пользователя больше нет доступа к этому источнику. Как теперь будет выглядеть объект?
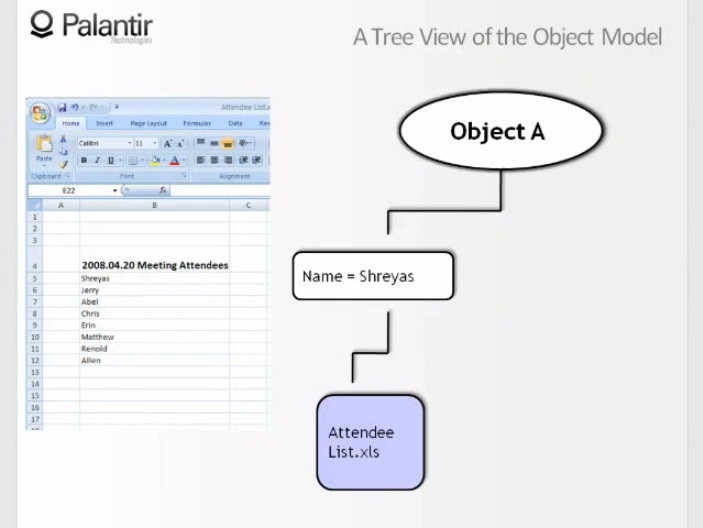
10:11 Если мы уберем текстовый файл, то увидим, что только компонент имя остался, таким образом мы эффективно привели объект к новому виду, так как второй его признак больше не поддерживается.
10:25 Вернемся к изначальному виду и взглянем на другой источник.
10:30 Мы видим текстовый документ, мы видим, что из документа извлечены имя и мейл. В случае, если список посетителей был отозван или в доступе нам отказали, объект наш по-прежнему выглядит так же. Это все потому, что оба компонента имеют подтвержденные источники.

10:55 Теперь мы увидели, что происходит, когда изменения происходят на уровне источников, и что мы можем смотреть и за признаки, туда, откуда они появляются, а это полезная возможность.
10:53 Давайте взглянем на свойства «Имя: Шрияс».

11:07 Мы видим, что имя взято из списка посетителей и из текстового файла. Для аналитика важно понимать, откуда берется информация.
11:18 Еще важно, что все о чем мы говорили, используется при контроле доступа к информации, при защите источников информации. Также, это позволяет нам совершать и другие действия.
11:30 Например, с помощью такого подхода легко поддерживать множественность признаков. Что означает «добавить новый признак» для признака «Имя: Шрияс»?
11:38 Это означает, что мы добавили новую ветку на мой граф, из источника «вручную созданные данные», и я могу совершать с этими данными те же манипуляции, что мы рассматривали раньше.

11:50 Используя объектную модель я могу производить ряд полезных манипуляций с данными.
11:58 Отдельно хочу упомянуть, что такой подход — один из компонентов пересинхронизации данных. Например, у вас есть некий внешний источник данных, который, возможно, меняет значение вашего признака, и не очень понятно, как не упустить это значение в Palantir.
12:12 Все, что нужно знать, — это то, что любые несовпадения возвращают к самому признаку, то есть, если возникло несовпадение, связанное с признаком «Имя: Шрияс», так как, этот признак в другом источнике меняется на «Шрияс Виджайкумар», вы не сможете просто изменить значение, ведь, старое значение опирается на свой собственный источник данных. Вам придется создать новый признак.
12:31 Теперь, когда мы увидели операции, которые можно производить с объектной моделью, давайте посмотрим, как вы сможете взаимодействовать с этой моделью, как будете вводить и извлекать данные.
12:39 Как я говорил в начале, мы поддерживаем очень открытый формат, открытый API, — это наши требования к платформе по работе с данными.
12:48 Обычно в таких средах существует проблема данных и инструментов. Это проблема данных, так как сложно получать данные из разных форматов и взаимодействовать с ними.
13:00 Но это также и проблема инструментов, так как вы можете встретить продукты, удерживающие вас в проприетарном или бинарном формате, и таким продуктам может быть сложно взаимодействовать с вашими данными.
13:08 В Palantir открытый xml формат, который так и называется Palantir XML, это воплощение объектной модели.
13:19 Это означает, что вы можете сделать всю свою работу и извлечь данные из Palantir в виде Palantir XML, или, если у вас есть некий набор данных, от неструктурированных документов, до целых файловых систем, вы можете внести их в Palantir, используя тот же Palantir XML.
13:33 Причина, по которой это возможно — то, что вы вносите данные как объектную модель.
13:36 Причина, по которой это важно — то, что объектная модель эффективно описывает каждую частичку информации в системе.
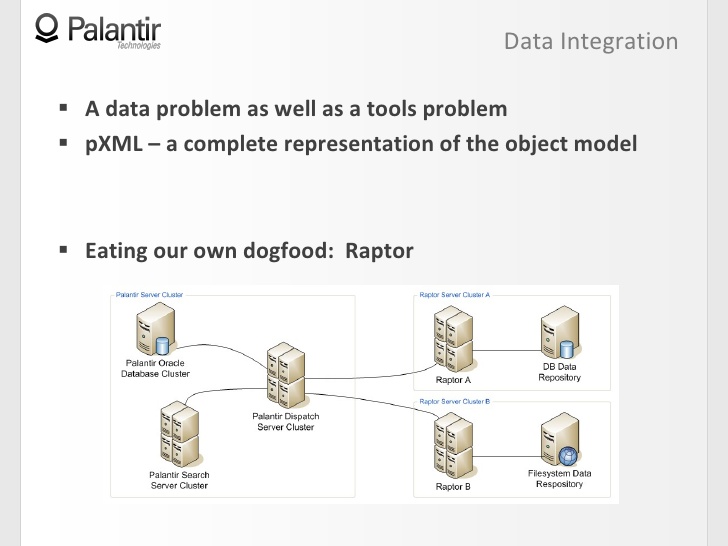
13:43 Последнее, чего я хочу коснуться — это то, как мы использовали объектную модель, когда проектировали собственную систему Raptor, — интегрированный компонент поиска.
13:57 Идея Raptor в том, чтобы эффективно работать с быстро меняющимися источниками данных, так что они должны быть синхронизированы с вашим Palantir.
14:09 Обычно, Palantir функционирует так: посылает запросы поисковому кластеру, поисковый кластер возвращает результат диспетчерскому серверу.
14:14 Raptor служит мостом между внешними источниками данных и диспетчерским сервером, и его задача распознавать правильные объекты, основываясь на объектной модели.
14:29 Когда вы запустили поиск через Raptor, он объединяет в себе весь поток данных, все корявые объекты отправляет обратно, а для пользователя это выглядит как плавный процесс, без единого разрыва.

14:36 Подытожив, скажу, что объектная модель — ядро платформы Palantir, и когда мы разрабатывали эту платформу, мы исходили из трех соображений:
(За помощь в подготовке статьи отдельное спасибо Алексею Ворсину, российскому эксперту по системе Palantir)
Еще про Palantir:
Как организации управляются с данными, на текущий момент?
В существующих системах встречаются довольно распространенные артефакты, и многие из них, если не все, вам знакомы:
- пользователи часто оставляют заметки для себя в имени файла, так что мы можем встретить конструкции вида отправить_по_почте.пятница.10_утра.не_стирать!!;
- каждое изменение онтологии требует модификации всей схемы;
- данные из разных источников невозможно исследовать вместе, в одной среде, так что у вас может быть база данных людей и трафика сообщений, которые приходится исследовать по отдельности;
- пересинхронизация данных нецелесообразна или невозможна, — а это часто бывает нужно;
- информация не может быть прослежена до её источника.
Что мы принципиально иначе делаем в Palantir?
Когда мы разрабатывали систему, мы много работали с обратной связью от сообщества. Первое, что мы постарались запроектировать — это максимальная гибкость системы, дающая возможность моделировать все что угодно.
Гибкость означает, возможность работать с любыми типами данных в одном общем пространстве: от высокоструктурированных, таких как базы данных с выстроенными отношениями, до неструктурированных, таких как хранилище трафика сообщений, а также всех, находящихся между этими крайностями. Это также означает возможность создавать множество разнообразных полей для исследования без привязки к одной модели построения. Как и организация, они могут изменяться и эволюционировать со временем.
Следующей вещью, которую мы спроектировали, стало обобщение данных без потерь. Нам нужна платформа, которая бы отслеживала каждый обрывок информации до его источника или источников. В мультиплатформенной системе важное значение имеет контроль доступа, особенно если такая система, позволяет совершать всю полноту действий с данными.
Подробнее о методологии тестирования, которую мы используем на проектах в EDISON Software Development Centre.


2:26 Следующая спроектированная нами вещь: открытый формат и API. Подлинная платформа для работы с данными позволяет вам вводить данные в систему, взаимодействовать с данными в этой системе, и выводить данные из системы, чтобы вы могли совершить с этими данными необходимые операции.
2:38 Объектная модель — ядро Palantir, и, так или иначе, её можно увидеть в каждом нашем видео.
2:45 Теперь давайте посмотрим как модель встроится в общую картину.
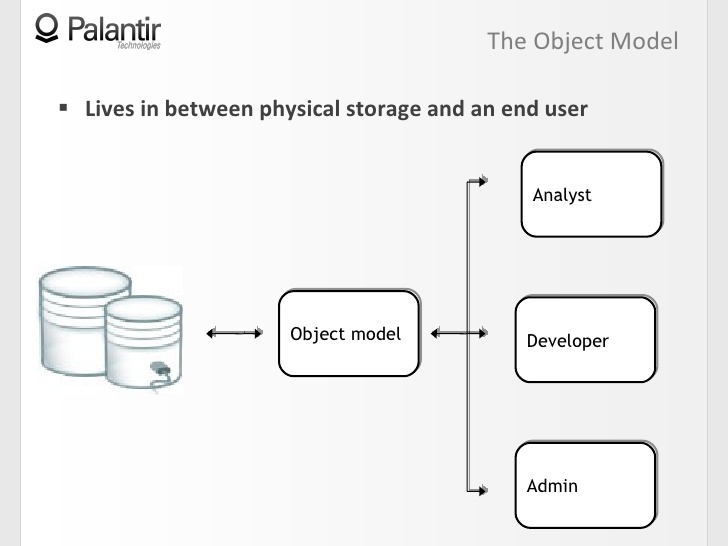
2:50 Объектная модель — это абстракция, находящаяся между физическим хранилищем данных и конечным пользователем. В нашем случае конечным пользователем может быть аналитик на рабочем месте, разработчик или администратор.
3:07 Через объектную модель все пользователи взаимодействуют с данными, как с абстрактным объектом первого порядка (first order conceptual object), вместо того чтобы собираться за общим столом, делиться видением, заниматься воспроизведением хранимых процедур (store procedure) снова и снова.
3:22 Теперь, когда у нас есть понимание, как модель выглядит в общей картине, давайте перейдем к структуре. Что собой представляют эти объекты?

3:36 Сперва, объект — это пустой контейнер, оболочка, которую мы наполни атрибутами и известной информацией. Примерами объектов могут служить такие сущности, как: люди, места, телефоны, компьютеры, события, такие как встреча, например, телефонные звонки, документы, электронные письма, и другое.
3:54 Все эти объекты обладают тем, что мы называем компонентами объекта (object components).
3:58 Есть четыре типа компонентов объекта, три из них мы сейчас перечислим:
— признаки, то есть текстовые атрибуты, такие как имена, мейлы и прочие;
— медиафайлы, что позволяет ассоциировать с объектом изображения, видео, тексты и любые другие бинарные форматы данных;
— заметки, то есть свободные текстовые поля для аналитиков.
4:18 Теперь у нас есть объекты, в которых мы храним информацию и есть связи, которые соединяют объекты.
4:28 Эта система объектов и компонентов объектов, дает представление об объектной модели. Причина, по которой мы можем моделировать такое количество «полей» (domain — поле, сфера, область; скорее всего, речь идет об отдельном рабочем пространстве в общем Palantir’е) в том, что мы не прописали никакой семантики внутри объекта как такового.
4:42 Я не говорил, что отношения должны быть объединяющими, управляющими или иерархическими, объектная модель существует до этих понятий. Каждая организация индивидуально определяет семантику, используя динамическую онтологию.
4:56 Давайте посмотрим как объектная модель и динамическая онтология взаимодействуют, создавая необходимую организации семантику.
5:03 Воспользуемся примером. Здесь у нас очень простой граф, состоящий из двух объектов, содержащих некоторые компоненты, и отношений.

5:12 Здесь нет семантики. Некая организация сейчас будет выбирать типы объектов, признаков и отношений, нужные ей.
5:22 Если я занимаюсь сетевой безопасностью, это могут быть роутеры и хосты, если контр-терроризмом — это могут быть террористические организации, деньги и члены групп.
5:38 Если теперь совместить объектную модель с онтологией, вы ожидаемо получите некоторую семантику, например: Зак работает в Palantir.
5:50 Такой же, с объектной точки зрения, граф может нести совершенно другой смысл: он может указывать на наличие документа.
6:00 Абстрагировав семантику от структуры, мы получили возможность создавать широкий спектр «полей» доступным и гибким образом.
6:09 Есть дань которую нужно заплатить, если вы хотите гибкости, и эта дань вам должна быть очень знакома.
6:22 Цена за возможность для системы быть гибкой — это почти всегда потеря поддержки возможности создавать схемы.
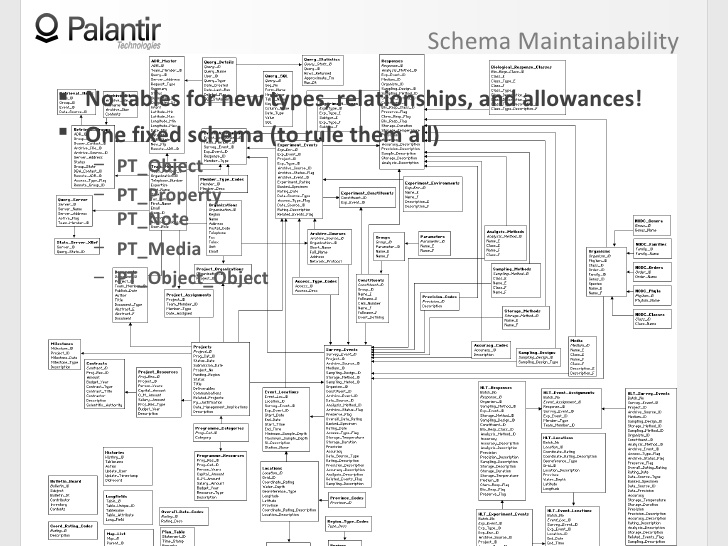
6:29 Вы можете добавить новый тип объектов или вид связей, но это будет стоить вам пяти отдельных связанных таблиц, с пояснениями, указаниями и прочим.
6:41 Так что это действительно сложно поддерживать и это не то, чего вы, в действительности, хотите от платформы по работе с данными.
6:45 В Palantir мы используем противоположный подход: нет необходимости в создании новых таблиц для типов объектов, отношений, допустимых ограничений.
6:57 Если быть точнее, то в Palantir есть одна схема, которую мы используем в каждой организации и при каждом внедрений.
7:02 Существует пять таблиц, из которых вы можете брать контент для любого объекта и любого компонента объектов, при этом неважно, моделируете ли вы документы на основе трафика сообщений или высокоструктурированной базы данных.
7:15 Так что, если взглянуть на то как объектная модель смотрится в общей картине, на структуру самой объектной модели и то, как она взаимодействует с динамической онтологией, мы увидим высокую гибкость и способность создавать множество «полей».
7:29 Сейчас поговорим о том, как мы внедрили извлечение данных без потерь.
7:35 Самое важное здесь — источники данных, ну, потому что вся информация, которая есть в Palantir, взялась из источников.
7:43 Примеры. Это может быть все что угодно: налоговые документы, электронные таблицы, файлы xml, базы данных, web-страницы. Созданное самим аналитиком во время работы, все равно основано на информации из источников.
7:58 Это почему важно? У вас что-то есть, продукт: вам нужно проследить, откуда он появился, на чем основан, вернуться к источникам и убедиться в отсутствии искажений, — это единственный способ быт уверенным в своих выводах.
8:11 Теперь посмотрим на связи между источниками данных и объектной моделью, которую я вам описал.
8:17 Каждый компонент объекта в Palantir содержит запись об источнике своих данных. Эта запись связывает информацию с источником или несколькими источниками.

8:25 Так что, если я хочу обосновать свой граф, мы увидим что эти два объекта поддерживаются источниками A, B и C.
8:34 Еще вы можете увидеть что несколько источников поддерживают один компонент объекта, и я, таким образом, больше уверен в этом кусочке информации, ведь он опирается на данные из хранилища трафика и логов операторов, например. Оба источника подтверждают информацию, я могу двигаться дальше, основываясь на ней.
9:00 Записи об источниках данных информируют чуть более точно, чем просто указание на источники данных, если мы имеем дело с неструктурированными источниками. Так, например, если это документ, запись укажет на конкретное место в документе. В структурированных базах данных эта запись об источнике может указывать на первичный ключ.
9:17 Теперь когда мы увидели, как источники данных связаны с объектами, давайте посмотрим какие операции мы можем здесь совершить.
9:23 Мы видим граф упрощенный до предела, он состоит из одного объекта, содержащего два компонента, и двух признаков. «Имя: Шрияс», и «мейл: shrey291@aol.com».
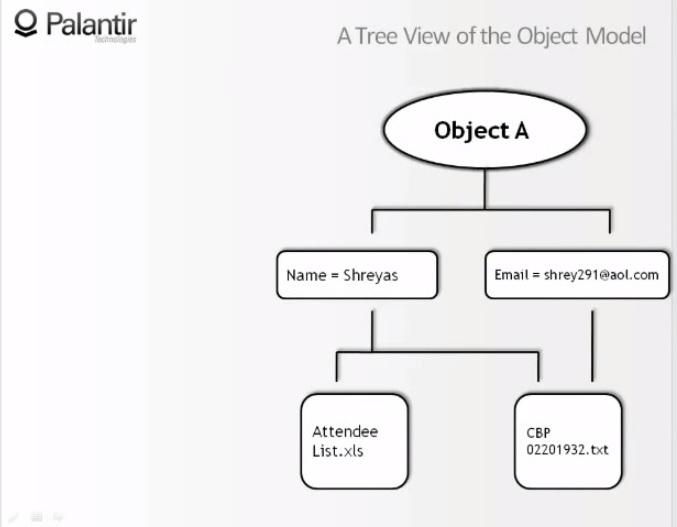
9:37 И мы видим, что имя взято из электронной таблицы посетителей (attendee — участник, слушатель, посетитель), и из текстового документа, а мейл взят только из текстового документа.
9:46 Давайте посмотрим на эти источники. Во-первых, список посетителей: мы видим, что имя Шрияс взято из сырого файла, чего-то вроде выдержки из другого источника.
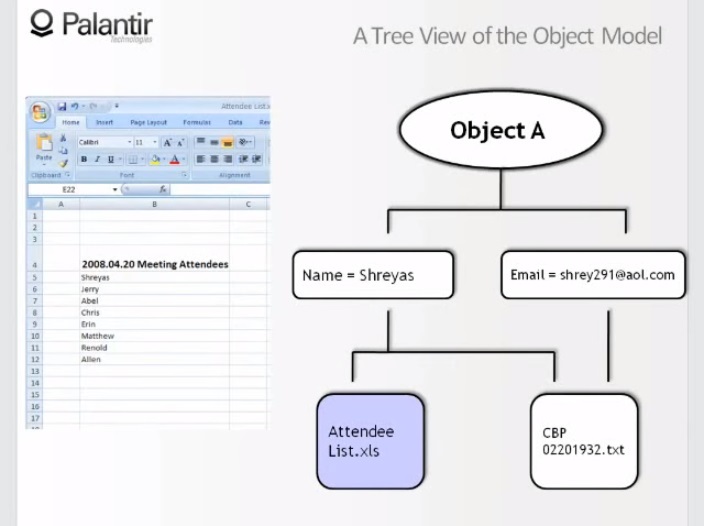
10:00 Представьте, что второй, текстовый файл был отозван (recall), или у пользователя больше нет доступа к этому источнику. Как теперь будет выглядеть объект?
10:11 Если мы уберем текстовый файл, то увидим, что только компонент имя остался, таким образом мы эффективно привели объект к новому виду, так как второй его признак больше не поддерживается.
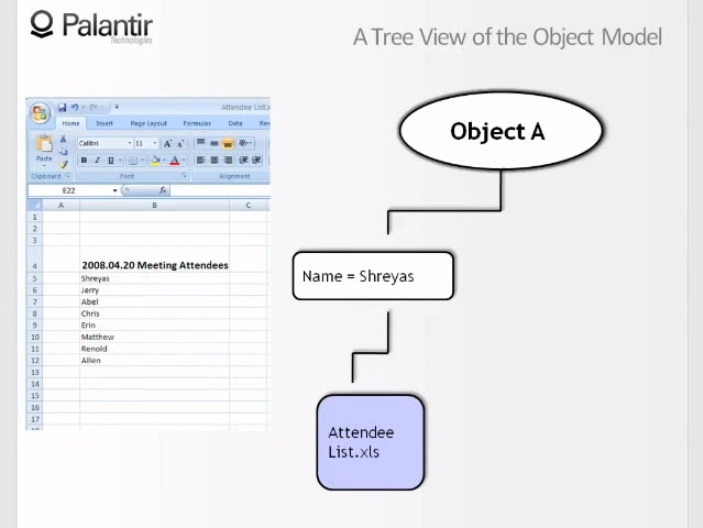
10:25 Вернемся к изначальному виду и взглянем на другой источник.
10:30 Мы видим текстовый документ, мы видим, что из документа извлечены имя и мейл. В случае, если список посетителей был отозван или в доступе нам отказали, объект наш по-прежнему выглядит так же. Это все потому, что оба компонента имеют подтвержденные источники.

10:55 Теперь мы увидели, что происходит, когда изменения происходят на уровне источников, и что мы можем смотреть и за признаки, туда, откуда они появляются, а это полезная возможность.
10:53 Давайте взглянем на свойства «Имя: Шрияс».
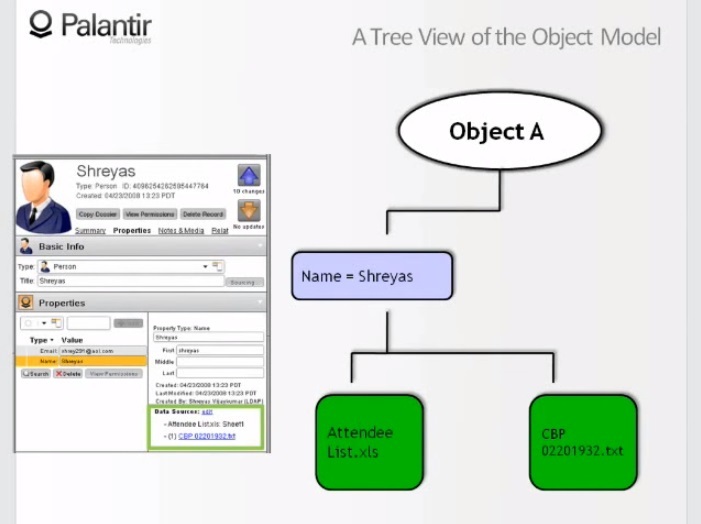
11:07 Мы видим, что имя взято из списка посетителей и из текстового файла. Для аналитика важно понимать, откуда берется информация.
11:18 Еще важно, что все о чем мы говорили, используется при контроле доступа к информации, при защите источников информации. Также, это позволяет нам совершать и другие действия.
11:30 Например, с помощью такого подхода легко поддерживать множественность признаков. Что означает «добавить новый признак» для признака «Имя: Шрияс»?
11:38 Это означает, что мы добавили новую ветку на мой граф, из источника «вручную созданные данные», и я могу совершать с этими данными те же манипуляции, что мы рассматривали раньше.
11:50 Используя объектную модель я могу производить ряд полезных манипуляций с данными.
11:58 Отдельно хочу упомянуть, что такой подход — один из компонентов пересинхронизации данных. Например, у вас есть некий внешний источник данных, который, возможно, меняет значение вашего признака, и не очень понятно, как не упустить это значение в Palantir.
12:12 Все, что нужно знать, — это то, что любые несовпадения возвращают к самому признаку, то есть, если возникло несовпадение, связанное с признаком «Имя: Шрияс», так как, этот признак в другом источнике меняется на «Шрияс Виджайкумар», вы не сможете просто изменить значение, ведь, старое значение опирается на свой собственный источник данных. Вам придется создать новый признак.
12:31 Теперь, когда мы увидели операции, которые можно производить с объектной моделью, давайте посмотрим, как вы сможете взаимодействовать с этой моделью, как будете вводить и извлекать данные.
12:39 Как я говорил в начале, мы поддерживаем очень открытый формат, открытый API, — это наши требования к платформе по работе с данными.
12:48 Обычно в таких средах существует проблема данных и инструментов. Это проблема данных, так как сложно получать данные из разных форматов и взаимодействовать с ними.
13:00 Но это также и проблема инструментов, так как вы можете встретить продукты, удерживающие вас в проприетарном или бинарном формате, и таким продуктам может быть сложно взаимодействовать с вашими данными.
13:08 В Palantir открытый xml формат, который так и называется Palantir XML, это воплощение объектной модели.
13:19 Это означает, что вы можете сделать всю свою работу и извлечь данные из Palantir в виде Palantir XML, или, если у вас есть некий набор данных, от неструктурированных документов, до целых файловых систем, вы можете внести их в Palantir, используя тот же Palantir XML.
13:33 Причина, по которой это возможно — то, что вы вносите данные как объектную модель.
13:36 Причина, по которой это важно — то, что объектная модель эффективно описывает каждую частичку информации в системе.
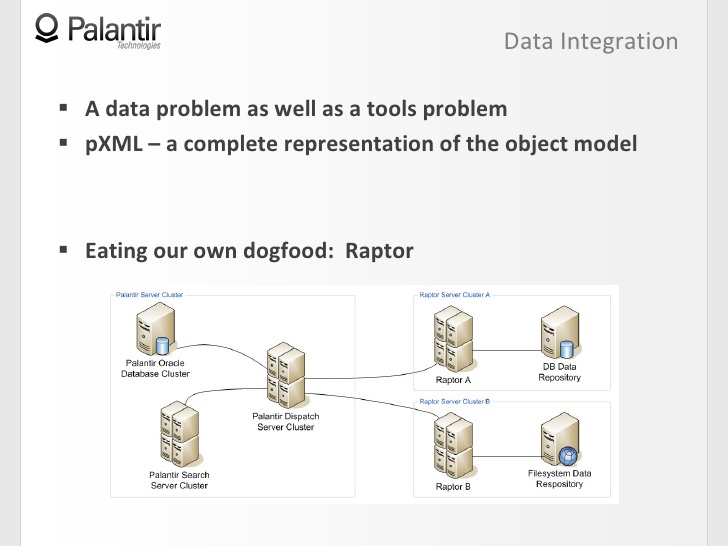
13:43 Последнее, чего я хочу коснуться — это то, как мы использовали объектную модель, когда проектировали собственную систему Raptor, — интегрированный компонент поиска.
13:57 Идея Raptor в том, чтобы эффективно работать с быстро меняющимися источниками данных, так что они должны быть синхронизированы с вашим Palantir.
14:09 Обычно, Palantir функционирует так: посылает запросы поисковому кластеру, поисковый кластер возвращает результат диспетчерскому серверу.
14:14 Raptor служит мостом между внешними источниками данных и диспетчерским сервером, и его задача распознавать правильные объекты, основываясь на объектной модели.
14:29 Когда вы запустили поиск через Raptor, он объединяет в себе весь поток данных, все корявые объекты отправляет обратно, а для пользователя это выглядит как плавный процесс, без единого разрыва.

14:36 Подытожив, скажу, что объектная модель — ядро платформы Palantir, и когда мы разрабатывали эту платформу, мы исходили из трех соображений:
- гибкость в моделировании чего бы то ни было;
- необходимость извлечения данных без потерь;
- открытый формат и API.
(За помощь в подготовке статьи отдельное спасибо Алексею Ворсину, российскому эксперту по системе Palantir)
Еще про Palantir:
- Динамическая онтология. Как инженеры Palantir объясняют это ЦРУ, АНБ и военным
- Киберконтрразведка. Как Palantir может «сноуденов» ловить
- Palantir: как обнаружить ботнет
- Palantir и отмывание денег
- Palantir: торговля оружием и распространение пандемии
- Palantir, мафия PayPal, спецслужбы, мировое правительство
- Palantir 101. Что позволено знать простым смертным о второй по крутоcти частной компании в Кремниевой Долине
