Привет, Хабр!
Наконец дошли руки Пришло время рассказать, чем занимается наша компания DM Labs в области анализа данных, помимо образовательной деятельности (о ней мы уже писали 1).
За прошлый год мы начали плотно сотрудничать с институтом роботехники fortiss при Техническом университете Мюнхена (TUM) (совместно учим роботов не убивать людей), выпустили прототип антифрод системы, участвовали в международных конференциях по машинному обучению, и, самое главное, смогли сформировать сильную команду аналитиков.
Теперь DM Labs объединяет в себе уже три направления: исследовательскую лабораторию, разработку готовых коммерческих решений и обучение. В сегодняшнем посте мы расскажем о них подробнее, подведем итоги прошедшего года и поделимся целями на будущее.
Запуская образовательное направление, мы хотели создать программу для обмена знаниями между молодыми специалистами и экспертами и, как уже упоминалось, помочь формированию сообщества Data Science в России.
За этот год мы успели выпустить первый поток студентов и сейчас ведем программу для второго набора.
Учебный план очень сильно изменился, но мы поняли, что три элемента, которые лежат в основе философии нашего обучения, мы не будем менять:
Помимо продолжения учебной программы, в 2014 мы будем проводить еще больше различных образовательных инициатив:
После запуска учебного направления логичным продолжением стала проектная деятельность и новое направление data mining Projects, потому что с помощью машинного обучения можно решать множество интересных задач в самых разных областях:
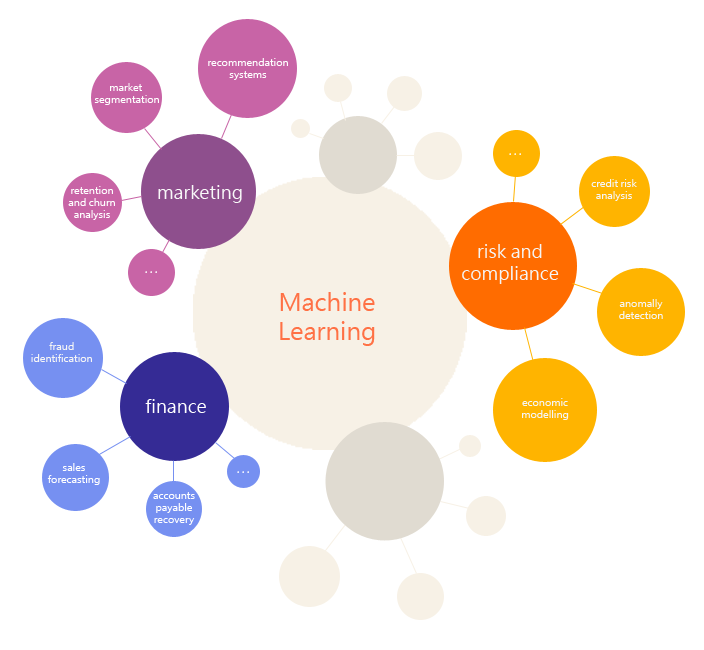
Сейчас наша команда работает над различными коммерческими проектами, среди которых задачи анализа трафика финансовых транзакций, обнаружение аномалий на основе log-файлов веб-сервисов, предсказание возврата пользователей и пр.
На конференции TechCrunch Moscow мы в общих чертах рассказывали, как можем помочь компании стать data-driven.
О конкретных кейсах проектов и нашем продукте, антифрод системе, напишем в следующих статьях.
Проектная работа — это хорошо, но душа data scientist’а всегда просит большего: хочется, чтобы и модели были точнее, и алгоритмы работали быстрее, а область их применения росла. Так было создано третье направление — Data Mining R&D.
Сейчас мы ведем работу над различными задачами, связанными с Gradient Boosting Machines [1,2,3]. Эти алгоритмы активно применяют такие компании как Yahoo!, Yandex в своем Matrixnet, Microsoft и другие. Если объяснять “на пальцах”, то основная идея алгоритма в том, чтобы построить множество деревьев решений таким образом, чтобы с каждым новым деревом суммарный выход алгоритма становился все более точным. Например, как на этой картинке:

Вроде все просто, но есть большой простор для творчества: как сделать так, чтобы для достижения той же точности требовалось меньшее число деревьев (как сократить их число)? Что будет, если сделать “глубокий” ансамбль? Или ансамбль полу-”глубоких” штуковин?"
Второе важное направление работ — методы Data Fusion. Идея в том, чтобы в рамках решения одной задачи использовать данные из разных областей: текста, видео, аудио, графов, сенсоров, а также различные их комбинации. Если запустить тот же самый алгоритм GBM «в лоб» на всех данных, распределения будут слишком разными, а число признаков неоправданно большим. В общем, описание причин, почему это не будет работать, — тема, достойная отдельной статьи.
Примером, с которым мы столкнулись в этой области оказалась задача определения финансовых рисков. Для этой задачи обычно используют количественную информацию о котировках с биржи — посмотрев на волатильность цен акций компании, можно достаточно точно спрогнозировать риски на следующий год. Однако, если учесть еще и информацию из годовых бухгалтерских отчетов компаний, эту точность можно повысить.
Главный вопрос — как сделать это наиболее эффективно, чтобы использовать всю информацию, содержащуюся в данных? Как сшивать модели, построенные на разных подпространствах данных? Сшивать только модели или некие промежуточные слои с representation, подобного тому как это предлагают делать в D-Wave:
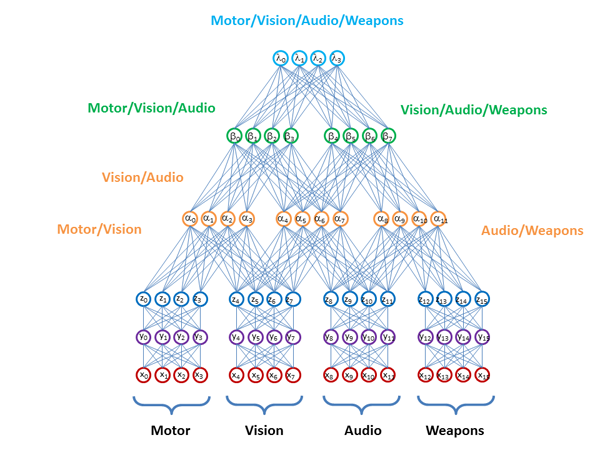
На этом наши исследования не заканчиваются. Нас, например, очень волнуют вопросы:
Это был год, богатый на события, новых хороших людей и интересные задачи. Надеемся, что и 2014 принесет много отличных идей и еще больше сил, чтобы их воплотить в жизнь и написать о каждой статью на Хабр. Да нам уже сейчас так много хочется рассказать, что мы решили провести небольшой опрос
За прошлый год мы начали плотно сотрудничать с институтом роботехники fortiss при Техническом университете Мюнхена (TUM) (совместно учим роботов не убивать людей), выпустили прототип антифрод системы, участвовали в международных конференциях по машинному обучению, и, самое главное, смогли сформировать сильную команду аналитиков.
Теперь DM Labs объединяет в себе уже три направления: исследовательскую лабораторию, разработку готовых коммерческих решений и обучение. В сегодняшнем посте мы расскажем о них подробнее, подведем итоги прошедшего года и поделимся целями на будущее.
Обучение
Запуская образовательное направление, мы хотели создать программу для обмена знаниями между молодыми специалистами и экспертами и, как уже упоминалось, помочь формированию сообщества Data Science в России.
За этот год мы успели выпустить первый поток студентов и сейчас ведем программу для второго набора.
| 2013 | 2013/ 2014 | |
|---|---|---|
| Студенты | 18 | 25 |
| Эксперты | 19 | 30+ |
Программа  |
Data Mining in Industry |
Data Mining in Industry + отдельные курсы по R, Machine Learning, Big Data |
| Лекции | 60 часов | Data Mining in Industry: 70+ часов, Курсы: 80 + часов |
| Компании | IBM, EMC, Siemens, fortiss, и др. | все те же + Delloite, Accenture, Одноклассники и др. |
Учебный план очень сильно изменился, но мы поняли, что три элемента, которые лежат в основе философии нашего обучения, мы не будем менять:
- Общение с экспертами.
- Практика. Студенты принимают участие в соревнованиях на kaggle, решают задачи, которые для них ставят эксперты из разных областей (1, 2 и 3).
- Проактивность. Мы пытаемся заинтересовать студентов в том, чтобы они делились знаниями друг с другом и сами организовывали внутренние семинары на разные темы, в том числе связанные не только с анализом данных.
Помимо продолжения учебной программы, в 2014 мы будем проводить еще больше различных образовательных инициатив:
- Data Mining Sauna — на рождественские каникулы мы пригласили студентов и экспертов в частный контактный зоопарк под Петербургом, чтобы в неформальной обстановке поделиться идеями друг с другом и обсудить исследования (об этом мероприятии мы скоро напишем подробнее).
- Сейчас мы готовим хакатон по анализу социальных сетей в Санкт-Петербурге.
- В наступившем году нам также очень хотелось бы организовать конференцию по Data Mining.
Проекты
После запуска учебного направления логичным продолжением стала проектная деятельность и новое направление data mining Projects, потому что с помощью машинного обучения можно решать множество интересных задач в самых разных областях:
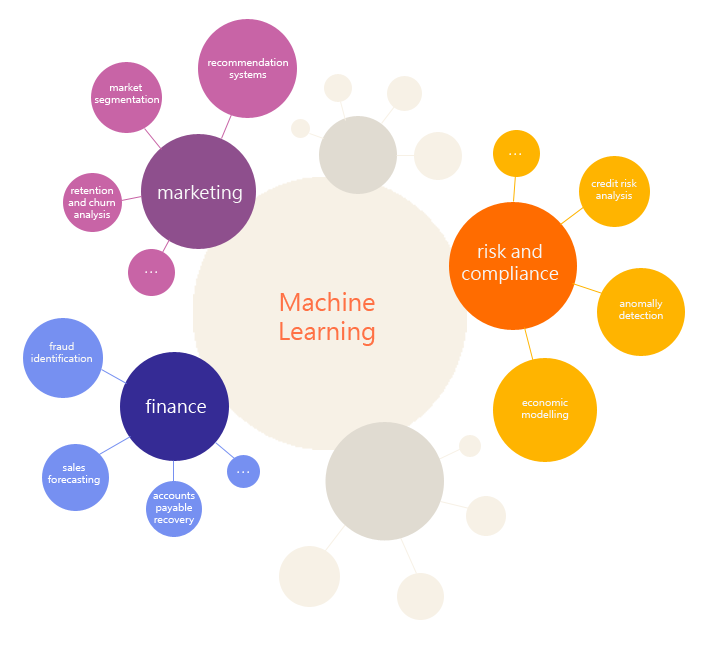
Сейчас наша команда работает над различными коммерческими проектами, среди которых задачи анализа трафика финансовых транзакций, обнаружение аномалий на основе log-файлов веб-сервисов, предсказание возврата пользователей и пр.
На конференции TechCrunch Moscow мы в общих чертах рассказывали, как можем помочь компании стать data-driven.
О конкретных кейсах проектов и нашем продукте, антифрод системе, напишем в следующих статьях.
Исследования
Проектная работа — это хорошо, но душа data scientist’а всегда просит большего: хочется, чтобы и модели были точнее, и алгоритмы работали быстрее, а область их применения росла. Так было создано третье направление — Data Mining R&D.
Сейчас мы ведем работу над различными задачами, связанными с Gradient Boosting Machines [1,2,3]. Эти алгоритмы активно применяют такие компании как Yahoo!, Yandex в своем Matrixnet, Microsoft и другие. Если объяснять “на пальцах”, то основная идея алгоритма в том, чтобы построить множество деревьев решений таким образом, чтобы с каждым новым деревом суммарный выход алгоритма становился все более точным. Например, как на этой картинке:
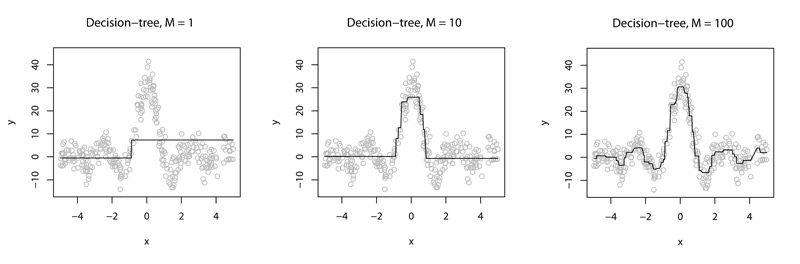
Вроде все просто, но есть большой простор для творчества: как сделать так, чтобы для достижения той же точности требовалось меньшее число деревьев (как сократить их число)? Что будет, если сделать “глубокий” ансамбль? Или ансамбль полу-”глубоких” штуковин?"
Второе важное направление работ — методы Data Fusion. Идея в том, чтобы в рамках решения одной задачи использовать данные из разных областей: текста, видео, аудио, графов, сенсоров, а также различные их комбинации. Если запустить тот же самый алгоритм GBM «в лоб» на всех данных, распределения будут слишком разными, а число признаков неоправданно большим. В общем, описание причин, почему это не будет работать, — тема, достойная отдельной статьи.
Примером, с которым мы столкнулись в этой области оказалась задача определения финансовых рисков. Для этой задачи обычно используют количественную информацию о котировках с биржи — посмотрев на волатильность цен акций компании, можно достаточно точно спрогнозировать риски на следующий год. Однако, если учесть еще и информацию из годовых бухгалтерских отчетов компаний, эту точность можно повысить.
Главный вопрос — как сделать это наиболее эффективно, чтобы использовать всю информацию, содержащуюся в данных? Как сшивать модели, построенные на разных подпространствах данных? Сшивать только модели или некие промежуточные слои с representation, подобного тому как это предлагают делать в D-Wave:
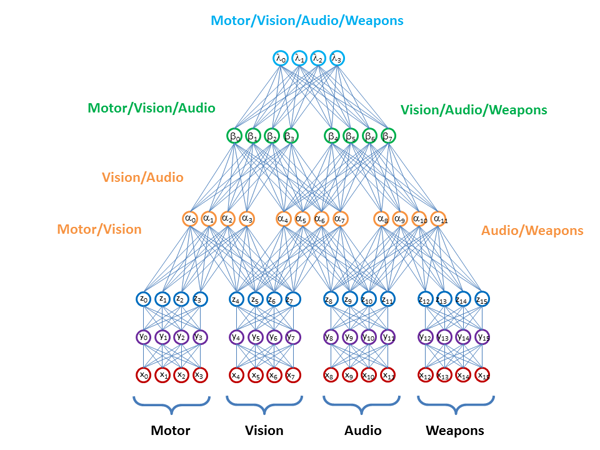
На этом наши исследования не заканчиваются. Нас, например, очень волнуют вопросы:
- Как отобрать значимые признаки, когда их очень много: десятки и сотни тысяч?
- Как искать аномалии в больших размерностях?
- Как запустить алгоритм GBM на миллиарде точек? А на триллионе? Это скорее общий вопрос для тех градиентных методов, где SGD и minibatch не применить (аналогичная история с ICA)
В заключение
Это был год, богатый на события, новых хороших людей и интересные задачи. Надеемся, что и 2014 принесет много отличных идей и еще больше сил, чтобы их воплотить в жизнь и написать о каждой статью на Хабр. Да нам уже сейчас так много хочется рассказать, что мы решили провести небольшой опрос
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Что бы вам хотелось почитать в нашем блоге?
41.97% Учебный процесс: события и задачки81
61.14% Обучающие материалы, которые мы используем118
56.48% Исследования в подробностях с матаном и прочим хардкором109
49.22% Исследования без подробностей: туториалы и мануалы95
67.88% Проектные идеи: где мы применяем машинное обучение131
32.64% Процессы в команде: что мы делаем сейчас и с какими проблемами сталкиваемся63
67.88% Прикладное применение Machine Learning и новости индустрии131
Проголосовали 193 пользователя. Воздержались 35 пользователей.
