Мы в агентстве People & Screens много лет работаем с онлайн-бизнесами в качестве рекламного партнера. Когда у нас появилась идея оценить вклад медийной рекламы в продажи интернет-магазинов, она казалась нереализуемой и даже безумной. Как только мы поняли, что все элементы мозаики можно найти и сложить вместе, то решили попробовать. Первые гипотезы начали подтверждаться, вместе с компанией Data Insight мы углубились в эту историю и за несколько месяцев кропотливой работы создали такое исследование, которое, по сути, является прикладным рабочим инструментом – модель оценки эффективности рекламы в 12 товарных категориях e-commerce. В этой статье мы расскажем о результатах и используемых методах анализа.

Ключевая гипотеза нашего исследования: медийная реклама, развивая бренд интернет-магазина, увеличивает конверсию во всей воронке продаж. В ходе анализа данных о продажах, о размещении рекламы и внешних данных за последние четыре года гипотеза подтвердилась. В итоге мы построили эконометрические модели продаж для 60 интернет-магазинов в 12 товарных категориях.
Сбор данных для исследования происходил силами обоих компаний, учавствующих в исследовании. Со стороны People & Screens были собраны следующие данные:
Со стороны Data Insight были собраны и предоставлены следующие данные:
Сбор данных для исследования проводился в несколько этапов. Мы оставим за рамками статьи ту работу, которую провели наши коллеги из Data Insight, чтобы сформировать необходимые для исследования данные, но расскажем, какая работа была подела на стороне People&Screens:
Важно понимать, что если в какой-то момент запустилась реклама, но ожидаемое значение продаж, согласно модели, было не выше фактического, то модель покажет, что эта реклама в этот период не сработала. Конечно, такое поведение продаж может быть суперпозицией влияния нескольких факторов (например, рост цен/запуск конкурентов одновременно со стартом рекламной кампании, или «упавший» от притока клиентов сайт).
Поскольку мы усредняем эффекты на длинном периоде времени на большом количестве брендов, то эффект таких случайных совпадений должен нивелироваться на большой выборке, хотя и может приводить к переоценённым или недооценённым эффектам по отдельным брендам. В итоге это позволило определить общие правила и закономерности для категории e-commerce в целом. При этом для детального анализа влияния рекламы в рамках отдельных брендов, конечно, по-прежнему необходимо исследовать всю совокупность факторов влияния.
В рамках данного исследования мы ставили перед собой цель получить как можно более надежные результаты на основе данных из разнородных источников. Сами по себе эти данные не являются точными значениями, а лишь оценкой этих значений средствами стороннего наблюдения (мониторинг выходов рекламы, динамика трафика, поисковый интерес и, наконец, заказы).
В каждом из звеньев есть ограничения по качеству данных, и это та проблема, с которой аналитики и исследователи сталкиваются в том или ином масштабе каждый день. Надеемся, что в рамках данной статьи нам удалось показать, какие методы позволяют обеспечить надежность выводов аналитического исследования, сохранив объяснительную силу результатов.
Цели исследования и результаты
Ключевая гипотеза нашего исследования: медийная реклама, развивая бренд интернет-магазина, увеличивает конверсию во всей воронке продаж. В ходе анализа данных о продажах, о размещении рекламы и внешних данных за последние четыре года гипотеза подтвердилась. В итоге мы построили эконометрические модели продаж для 60 интернет-магазинов в 12 товарных категориях.
- Только краткосрочный вклад медийной рекламы составил 39% роста интернет-магазинов при динамике рынка в среднем на 50-60%.

- Медийная реклама позволяет поддерживать продажи за счет роста знания.

- Наибольшую отдачу в целом в e-commerce приносит онлайн видеореклама.

- Эффективность медиа сильно зависит от категории: в категориях одежды и интернет-гипермаркетов высокую эффективность показал ТВ, в электронике и автотоварах – онлайн-видеореклама.
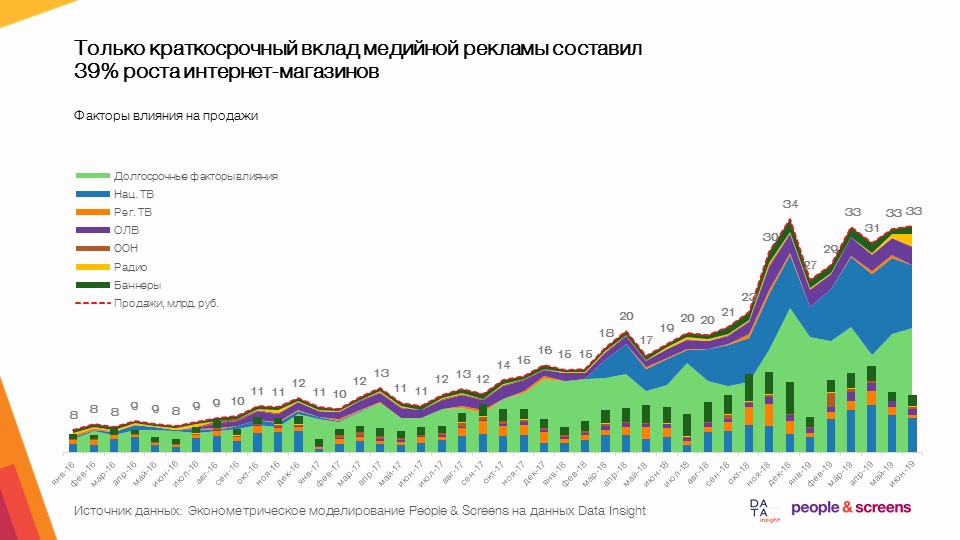
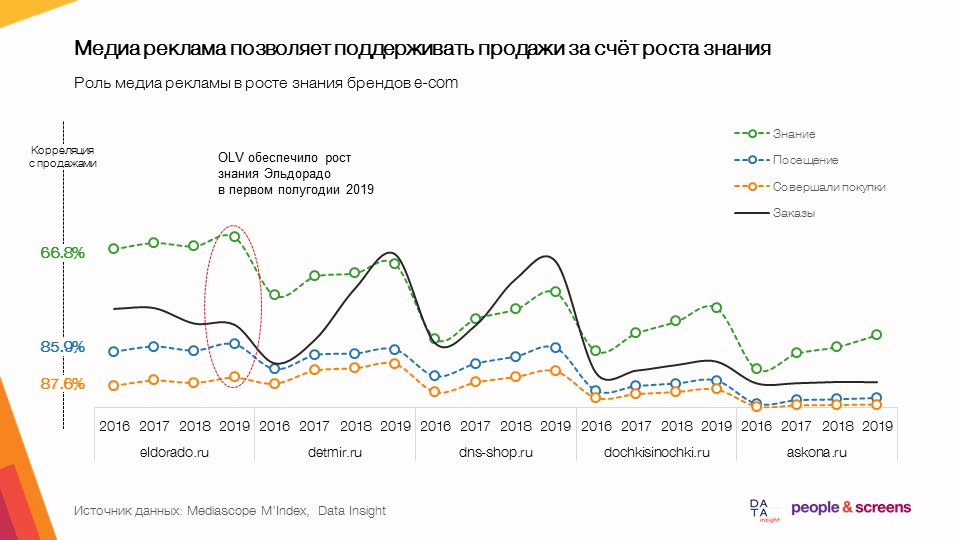
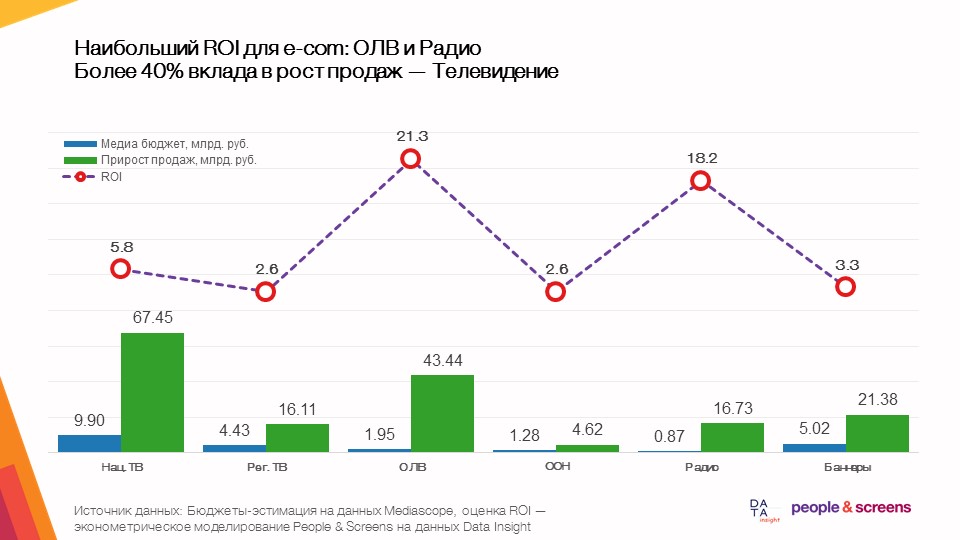
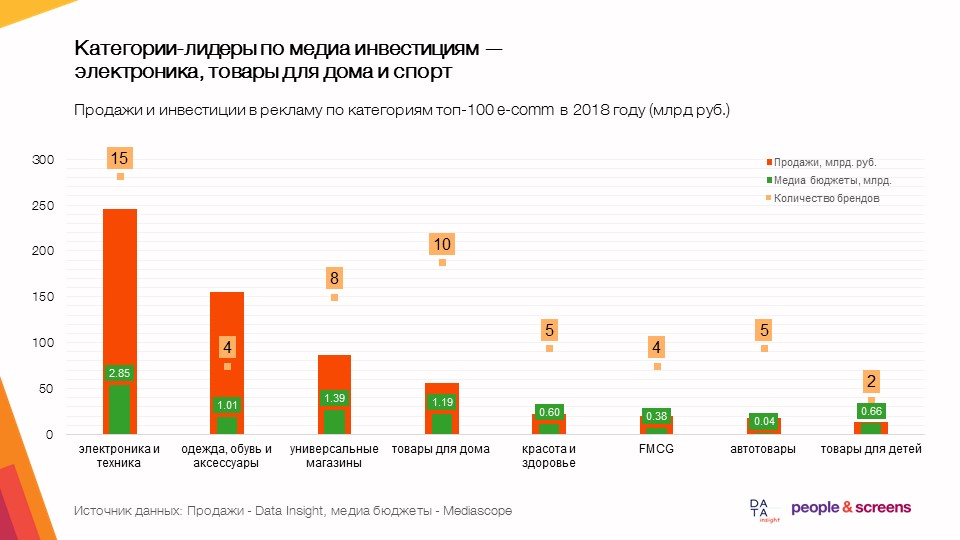
Что мы анализировали
Сбор данных для исследования происходил силами обоих компаний, учавствующих в исследовании. Со стороны People & Screens были собраны следующие данные:
- Данные о выходах медийной рекламы. Мы использовали выгрузки из баз данных компании Mediascope доступ к которым есть у всех рекламных групп. Мы выгружали рекламные затраты по всем медиа и рекламные контакты на широкую целевую аудиторию (Все 18+) в детализации по дням (для рекламы на ТВ, радио, в прессе, интернете) и по месяцам (для наружной рекламы) за период с января 2016 года по июнь 2019 года. Для максимизации скорости работы на этом этапе мы пользовались внутренними разработками Dentsu Aegis Network Russia для работы с индустриальными данными, в частности платформу Atomizer.
- Выгрузка данных из SimilarWeb по дням за последние 18 месяцев. Смотрели на динамику по дням Visits по Desktop/Mobile, динамику по дням десктоп трафика в разбивке по источникам (каналам) и динамику установок на Android.
- Динамика знания/посещения/покупок из базы данных TGI/Marketing Index за 2016-2019 год по кварталам. Это выгрузка из индустриального софта Gallileo компании Mediascope.
- Поисковые запросы Google Trends за январь 2016 – июль 2019 по России.
Со стороны Data Insight были собраны и предоставлены следующие данные:
- Динамика заказов по 72 интернет-магазинам из ТОП-100 рейтинга по месяцам за период с января 2016 по август 2019 года.
- Данные счётчика li.ru за период с января 2018 по август 2019 (трафик на сайт, отдельно суммарный, только по России и только мобайл) по ТОП-11 сайтам.
- Данные счетчика mail.ru за период с июня 2017 по сентябрь 2019 по 53 сайтам.
- Данные счетчика Rambler за период с июня 2017 по сентябрь 2019 по 38 сайтам.
- Данные поисковых запросов Yandex Wordstat за 24 месяца с октября 2017 по сентябрь 2019.
- Оценка средних чеков интернет-магазинов ТОП-100 по состоянию на 2018 год.
Алгоритм работы с данными
Сбор данных для исследования проводился в несколько этапов. Мы оставим за рамками статьи ту работу, которую провели наши коллеги из Data Insight, чтобы сформировать необходимые для исследования данные, но расскажем, какая работа была подела на стороне People&Screens:
- Поиск всех интернет-магазинов из рейтинга ТОП-100 в доступных нам индустриальных базах и составление словарей соответствия названий. Для этого мы использовали движок семантического поиска Elasticsearch.
- Формирование шаблонов и выгрузка данных по ним. На этом этапе самым важным было заранее продумать архитектуру таблиц данных.
- Объединение данных из всех источников в единый набор данных (датасет).
Для этого мы использовали обработку выгруженных данных в Python с использованием пакетов pandas и sqlalchemy. Набор лайфхаков тут достаточно стандартный:
при обработке сырых данных из csv таблиц размером более 1 млн. строк мы вначале прогружали названия столбцов таблиц запросом вида:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
затем типы данных добавляли через словарь:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
и сами данные грузили функцией
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
Результаты преобразований выгружались в PostgreSQL. - Кросс-валидация динамики заказов на основе анализа динамики трафика, поисковых запросов и фактических продаж по пулу клиентов агентства People & Screens. Здесь мы строили корреляционные матрицы с помощью df.corr() по разным наборам данных в рамках фиксированного сайта, затем детально анализировали «подозрительные» ряды с выбросами. Это один из ключевых этапов исследования, на котором мы проверяли надёжность динамики исследуемых показателей.
- Построение эконометрических моделей на валидированных данных. Здесь мы использовали прямое и обратное преобразование Фурье из пакета numpy (функции np.fft.fft и np.fft.ifft) для извлечения сезонности, кусочно-гладкую аппроксимацию для оценки тренда и модели линейной регрессии (linear_model) пакета sklearn для оценки вклада рекламы. При выборе класса моделей для этой задачи мы исходили из того, что результат моделирования должен быть легко интерпретирован и использован для численной оценки эффективности рекламы с учётом качества данных. Надежность моделей мы исследовали через разделение данных на обучающую и тестовую выборки переменного временного интервала. Т.е. мы сравнивали как на тестовом временном интервале с января по август 2019 года ведёт себя модель, обученная на данных с января 2016 по декабрь 2018, потом обучали модель на временном интервале с января 2016 по январь 2019 и смотрели как ведёт себя модель на данных с февраля по август 2019. Качество моделей исследовалось по стабильности вклада рекламных факторах на разных обучающих выборках качестве прогноза на тестовой выборке
- Заключительным этапом была подготовка презентации на основе полученных выводов. Здесь мы прокладывали мост математических моделей к практическим бизнес-выводам и ещё раз проверяли модели с точки зрения здравого смысла полученных результатов.
Специфика анализа e-commerce и сложности, которые возникают в процессе
- На этапе сбора данных возникли трудности с корректной оценкой поискового интереса к ресурсу. В Google Trends нет возможности группировать поисковые запросы и использовать минус-слова как в Yandex Wordstat. Важно было изучить семантическое ядро каждого интернет-магазина и выгружать центральный запрос. Например, М.Видео нужно писать по-русски – это центральный запрос для этой площадки.
Для магазинов, которые продают товары и в онлайне, и в офлайне, в данных по Yandex wordstat коллеги из Data Insight придерживались следующего подхода:
Убедиться в отсутствии нерелевантных вопросов (главное – не оценка объема спроса, а отслеживание изменений динамики). Мы достаточно жестко подходили к фильтрации поисковых слов. Там, где по имени бренда был риск подцепить нецелевые запросы, брали статистику по ключевым комбинациям. Например, «магазин озон» вместо «озон» – при таком подходе поисковая популярность ритейлера занижается, зато динамика спроса измеряется надежнее и становится очищенной от “шумов”. Применительно к поисковой статистике есть методологическая проблема, у которой по всей видимости нет надежного решения — по многим ритейлерам эта статистика искажена SEO-инструментами, которые оптимизируют поисковые выдачи через поведенческие факторы, но искажают статистику по реальному спросу. - На этапе объединения данных из разных источников возникла необходимость приведения данных к единой гранулярности: данные по ТВ-рекламе и трафику из SimilarWeb были по дням, данные поисковых запросов – по неделям, а данные по заказам и данные счетчиков – по месяцам. В итоге мы сформировали отдельную базу с полями дат, позволяющими агрегировать данные на необходимом уровне, и кэшированную базу данных месячной агрегации для дальнейшей работы со всей детализацией данных продаж.
- На этапе кросс-валидации данных мы обнаружили заметные расхождения в динамике продаж с нашими собственными данными. Это потребовало обсуждения ситуации с коллегами из Data Insight. В итоге благодаря точному пониманию, в какие месяцы возникают наибольшие ошибки, аналитики выявили две ошибки, засевшие глубоко «внизу» алгоритма оценки месячной динамики продаж.
- На этапе разработки моделей возникло несколько сложностей. Для корректной оценки эффекта рекламы было необходимо изолировать внешние факторы. Любая динамика продаж (и e-commerce не исключение) связана не только с рекламой, но и с множеством других факторов: UX/UI изменения на сайте, цены, ассортимент, конкуренция, колебания курса валют и т.д.
Для решения этой задачи мы использовали подход на основе регрессионного анализа данных за длинный период – с января 2016 года по август 2019 года. В рамках этого подхода мы анализировали изменения (всплески) в динамике заказов, которые могут быть атрибуцированы к рекламе в этот период.
Важно понимать, что если в какой-то момент запустилась реклама, но ожидаемое значение продаж, согласно модели, было не выше фактического, то модель покажет, что эта реклама в этот период не сработала. Конечно, такое поведение продаж может быть суперпозицией влияния нескольких факторов (например, рост цен/запуск конкурентов одновременно со стартом рекламной кампании, или «упавший» от притока клиентов сайт).
Поскольку мы усредняем эффекты на длинном периоде времени на большом количестве брендов, то эффект таких случайных совпадений должен нивелироваться на большой выборке, хотя и может приводить к переоценённым или недооценённым эффектам по отдельным брендам. В итоге это позволило определить общие правила и закономерности для категории e-commerce в целом. При этом для детального анализа влияния рекламы в рамках отдельных брендов, конечно, по-прежнему необходимо исследовать всю совокупность факторов влияния.
Вывод
В рамках данного исследования мы ставили перед собой цель получить как можно более надежные результаты на основе данных из разнородных источников. Сами по себе эти данные не являются точными значениями, а лишь оценкой этих значений средствами стороннего наблюдения (мониторинг выходов рекламы, динамика трафика, поисковый интерес и, наконец, заказы).
В каждом из звеньев есть ограничения по качеству данных, и это та проблема, с которой аналитики и исследователи сталкиваются в том или ином масштабе каждый день. Надеемся, что в рамках данной статьи нам удалось показать, какие методы позволяют обеспечить надежность выводов аналитического исследования, сохранив объяснительную силу результатов.
