 Сегодня видеочаты стали частью нашей повседневной жизни. Хотя пропускная способность сетей растёт, по-прежнему востребована качественная связь на низком битрейте. Проблема особенно для звука, потому что именно звук передаёт информацию в чате. На самом низком битрейте принято использовать параметрические кодеки с роботизированным голосом, а не нормальные кодеки, которые описывают форму сигнала.
Сегодня видеочаты стали частью нашей повседневной жизни. Хотя пропускная способность сетей растёт, по-прежнему востребована качественная связь на низком битрейте. Проблема особенно для звука, потому что именно звук передаёт информацию в чате. На самом низком битрейте принято использовать параметрические кодеки с роботизированным голосом, а не нормальные кодеки, которые описывают форму сигнала.Поэтому разработчики из компании Google разработали высококачественный речевой кодек Lyra с очень низким битрейтом. В разработке использованы генеративные модели, обученные на тысячах часов данных. Теперь машинное обучение применили и в этой области.
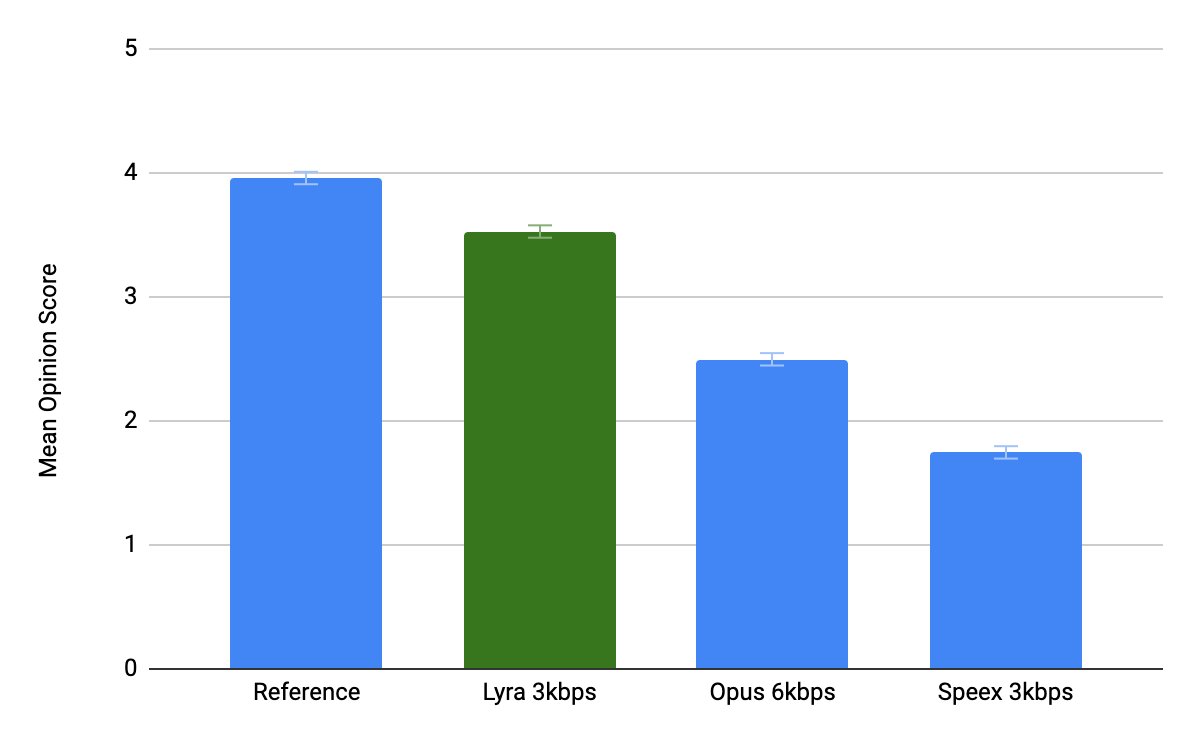
Lyra на 3kbps сжимает речь примерно как Opus на 8kbps.
Базовая архитектура кодека Lyra довольно проста. Признаки, то есть отличительные речевые атрибуты, извлекаются из речи каждые 40 мс, а затем сжимаются для передачи. Сами признаки представляют собой мел-спектрограммы (Mel Spectrogram) — список чисел, представляющих речевую энергию в различных частотных диапазонах, которые традиционно используются для перцептивной релевантности, поскольку они моделируются по образцу человеческого слуха. С другой стороны, генеративная модель использует эти признаки для воссоздания речевого сигнала. В этом смысле Lyra очень похожа на другие традиционные параметрические кодеки, такие как MELP.

Традиционные параметрические кодеки просто кодируют критические параметры речи, чтобы воссоздать её на стороне приёма. Они показывают низкий битрейт, но часто звучат роботизированно и неестественно. Эти недостатки привели к разработке нового поколения генеративных моделей звука, которые произвели революцию в этой области, сумев не только различать сигналы, но и генерировать совершенно новые.
Первой генеративной моделью была WaveNet от DeepMind. Она проложила путь для остальных. Кроме того, WaveNetEQ, основанная на генеративной модели система сокрытия потерь пакетов, используемая в настоящее время в Duo, продемонстрировала, как эта технология может быть использована в реальных сценариях.
Новый подход к сжатию
Для Lyra была разработана новая модель. Lyra использует низкий битрейт, как у параметрических кодеков, но за счёт генеративных моделей передаёт высокое качество звука, наравне с самыми лучшими кодеками формы сигнала (waveform codecs), которые используются в большинстве медиаплатформ. Недостатком кодеков формы сигнала является то, что они сжимают и передают по сети целые сэмплы, что требует более высокого битрейта и в большинстве случаев не является необходимым для достижения естественного звучания речи.
Одна из проблем генеративных моделей — их вычислительная сложность. Чтобы упростить вычисления, Lyra использует более дешёвую рекуррентную генеративную модель, вариацию WaveRNN. Она медленнее, но генерирует параллельно несколько сигналов в разных частотных диапазонах, которые позже объединяются в один выходной сигнал с требуемой частотой дискретизации. Этот трюк позволяет Lyra работать не только на облачных серверах, но и на устройствах среднего класса в режиме реального времени (с задержкой обработки 90 мс, что соответствует традиционным речевым кодекам). Эта генеративная модель затем обучается на тысячах часов речевых данных и оптимизируется, подобно WaveNet, для точного воссоздания входного звука.
Сравнение с существующими кодеками
Основная задача Lyra состояла в том, чтобы обеспечить наилучшее качество звука на битрейте конкурентов или лучше. В настоящее время самый популярный в VoIP-телефонии опенсорсный кодек Opus на битрейте 32 Кбита/с обычно обеспечивает качество речи, неотличимое от оригинала. Но его можно использовать и на низких битрейтах, вплоть до 6 Кбит/с. Другие кодеки способны работать со скоростью ещё ниже (Speex, MELP, AMR), но каждый из них страдает от артефактов и роботизированного звучания.
Lyra сейчас специализируется на битрейте 3 Кбита/с, и по тестам превосходит все кодеки на этом битрейте, даже Opus на скорости 8 Кбит/с. Lyra может использоваться везде, где пропускной способности недостаточно для более высокого битрейта.
Чистая речь
Оригинал
Opus@6kbps
Lyra@3kbps
Speex@3kbps
Шумное окружение
Оригинал
Opus@6kbps
Lyra@3kbps
Speex@3kbps
Образец
Opus@6kbps
Lyra@3kbps
Модель Lyra обучалась на тысячах часов звука на более чем 70 языках из опенсорсных аудиотек.
Сопряжение Lyra с новейшими видеокодеками типа AV1 позволит проводить видеоконференции даже для пользователей на коммутируемом соединении 56 Кбит/с.
Google продолжит улучшать Lyra, задействуя нейросети на GPU и TPU (тензорные процессоры). Возможно, получится обучить кодек сжимать музыку и другой звук.
