
По прогнозам аналитиков, рынок дата-центров в ближайшие годы будет расти на 38% в год и за пять лет вырастет до $35 млрд, а самая ресурсоёмкая ниша (по интенсивности вычислений) — глубокое обучение, нейросети и задачи AI.
Конечно, Intel не собирается равнодушно смотреть, как Nvidia (и AMD, в меньшей степени) со своими GPU захватывают этот рынок, включая самый быстрорастущий сектор. На прошлой неделе гигант микроэлектронной промышленности сделал сразу несколько громких анонсов:
- процессоры для нейросетей Nervana NNP-T1000 и NNP-I1000 (NNP: neural network processors), а также чип Movidius VPU;
- 10-нанометровые процессоры Xeon Scalable (кодовое название Sapphire Rapids);
- унифицированные программные интерфейсы oneAPI (для CPU, GPU, FPGA) — конкурента Nvidia CUDA;
- 7-нанометровый GPU для дата-центров с кодовым названием Ponte Vecchio на новой архитектуре Xe.
Вычислительные модули Aurora
На этих CPU, GPU и oneAPI составят вычислительные модули Aurora для однооимённого суперкомпьютера с уровнем производительности в 1 эксафлопс (10^18 операций в секунду). Предполагается, что эту машину установят в Аргоннской национальной лаборатории министерства энергетики США.

В каждом вычислительном модуле два процессора Sapphire Rapids и шесть GPU, соединённых шиной CXL.

По подсчётам AnandTech, в системе из 200 стоек, как заявлено, если вычесть резерв на сеть и накопители, поместится примерно 2400 двухюнитовых узлов Aurora. То есть в общей сложности около 5000 процессоров Sapphire Rapids и 15 000 Ponte Vecchio. Если разделить заявленную производительность в 1 эксафлопс на количество GPU, то выходит около 66,6 терафлопс на GPU. Далее, предположив производительность CPU в 14 терафлопс, мы всё равно получаем около 50 терафлопс, то есть это пятикратное повышение производительности GPU в дата-центрах к 2021 году.
Конечно, планы не ограничиваются суперкомпьютером для министерства энергетики. Intel объявила, что компании Lenovo и Atos уже готовятся к выпуску серверных платформ на основе Xeon CPU, Xe GPU и oneAPI. Таким образом, вычислительные модули Aurora в каком-то виде найдут применение и в других дата-центрах.
Запустить суперкомпьютер должны в 2021 году. В те же сроки 7-нанометровые Xe GPU должны появиться на рынке.
По мнению Intel, сейчас традиционные высокопроизводительные решения (HPC) сходятся с ИИ, переходя к рабочим нагрузкам, которые используют глубокое обучение. HPC, AI и аналитика — это три основные рабочие нагрузки, стимулирующие спрос на вычислительные ресурсы: «Такое разнообразие вычислительных потребностей подталкивают к гетерогенным вычислениям. — сказал Раджиб Хазра (Rajeeb Hazra), вице-президент и генеральный директор группы Intel Enterprise and Government. — Здесь больше не подходят универсальные решения. В эту эпоху конвергенции следует смотреть на архитектуры, настроенные на различные потребности различных видов рабочих нагрузок».
GPU для дата-центров

Ponte Vecchio — первый графический процессор на новой архитектуре Xe. Сама архитектура станет основой для GPU в различных сегментах:
- высокопроизводительные вычисления;
- глубокое обучение;
- облачные вычисления;
- графика;
- транскодирование медиа;
- рабочие станции,
- игровые компьютеры;
- обычные настольные ПК;
- мобильные и ультрамобильные устройства.

Вице-президент подразделения Intel по архитектуре, графике и программному обеспечению Ари Раух (Ari Rauch) говорит, что одна архитектура GPU даст разработчикам «общую структуру», но в рамках этой архитектуры компания разрабатывает «много микроархитектур, которые обеспечивают максимальную эффективную производительность для каждой из этих рабочих нагрузок».
GPU Ponte Vecchio основан на микроархитектуре Xe именно для HPC и AI, а функции микроархитектуры включают в себя гибкий движок параллельных вычислений с векторными матрицами, высокую пропускную способность вычислений двойной точности с плавающей запятой (FP64) и сверхвысокую пропускную способность кэша и памяти. Для форматов INT8, Bfloat16 и FP32 будет отдельный движок Matrix Engine для параллельной обработки матриц (возможно, аналог TensorCore), а для FP64 ускорение составит до 40 раз на каждый вычислительный блок.
«Для этой рабочей задачи требуется высокая производительность вычислений, поэтому мы сосредоточились на добавлении большого количества векторных и матричных модулей и параллельных вычислений, которые адаптированы и оптимизированы для этой рабочей нагрузки», — сказал Раух.
Ponte Vecchio станет первым GPU нового поколения. В нём реализуют несколько новых технологий, которые Intel разрабатывает в последние годы:
- производственный процесс 7 нм;
- многоуровневая компоновка интегральных схем Foveros 3D;
- мост EMIB (Embedded Multi-Die Interconnect Bridge) для связи нескольких кристаллов на одной подложке;
- Xe Link на новом стандарте интерконнекта CXL (на базе PCI Express 5.0) — доступ к GPU через единое пространство памяти.


Многоуровневая компоновка интегральных схем Foveros 3D, из презентации Intel в декабре 2018 года
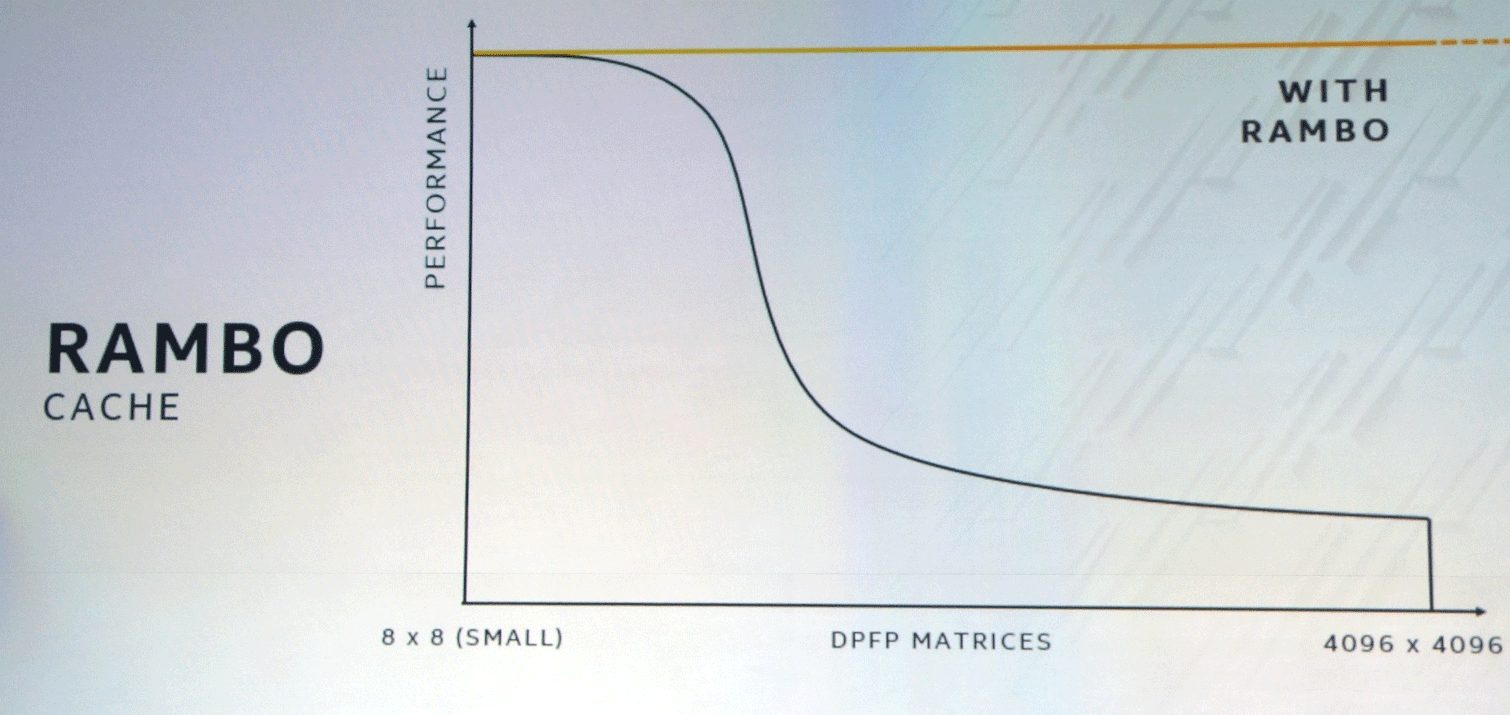
Технические характеристики чипа пока не объявлены. Говорят, в этих GPU будут тысячи исполнительных блоков (Executive Units), связанных посредством шины XEMF (XE Memory Fabric) с памятью и кэшем.

Шина XEMF работает с особым сверхбыстрым кэшем Rambo Cache, чтобы устранить бутылочное горлышко при доступе к памяти. Этот кэш соединяется с вычислительными блоками через Foveros, а для подключения HBM-памяти будет использоваться EMIB.
Сочетание подходов SIMT и SIMD, характерных для GPU и CPU, соответственно, и векторные инструкции переменной длины обеспечат существенный прирост производительности в некоторых классах задач.

Многие ждут, что Intel сможет составить конкуренцию Nvidia и AMD на рынке дата-центров и AI. Речь идёт не только о ценовой конкуренции, но и появлении альтернативных технологической платформы, которая подстегнёт общий технологический прогресс.
OneAPI: вершина абстракции для гетерогенного железа
Кроме анонса нового оборудования, Intel выпустила бета-версию единого программных интерфейсов oneAPI. Они призваны облегчить работу разработчиков, которым для максимальной оптимизации своих программ традиционно приходилось переключаться между различными языками программирования и библиотеками, используя промежуточный софт (middleware) и фреймворки.
По умолчанию в индустрии принято, что на низком уровне нужно подготовить разный код для каждой архитектуры. Например, TensorFlow изначально в момент выпуска вообще был полностью оптимизирован для GPU одного поставщика (для Nvidia CUDA).
«OneAPI пытается решить эти проблемы, предлагая общий интерфейс низкого уровня для разнородного оборудования с бескомпромиссной производительностью, — говорит Билл Сэвидж (Bill Savage), вице-президент подразделения Intel по архитектуре, графике и программному обеспечению. — Чтобы разработчики могли писать программы непосредственно на аппаратном обеспечении через языки и библиотеки, общие для разных архитектур и поставщиков, а также убедиться, что middleware и фреймворки работают на oneAPI и полностью оптимизированы для разработчиков, которые находятся на вершине этой абстракции».
Intel рекламирует oneAPI как «открытый стандарт для поддержки сообщества и отрасли», который позволит «повторно использовать код на разных архитектурах и оборудовании разных производителей».
Спецификация oneAPI включит в себя стандартный кросс-архитектурный язык программирования DPC++, основанный на C++ и SYCL, а также «мощные API для ускорения ключевых домен-специфических функций».
Кроме компилятора DPC++ и библиотеки API, будут выпущены специальные инструменты, в том числе VTune Inspector Advisor, отладчик и «инструмент совместимости» для переноса кода CUDA (Nvidia) на DPC++.
Чтобы стимулировать переход на oneAPI, компания Intel запустила в DevCloud «песочницу» для разработки и тестирования программ на ряде CPU, GPU и FPGA. Работа с песочницей не требует установки у себя никакого оборудования или программного обеспечения.
Тем временем доходы Nvidia за квартал выросли до $3 млрд, а на рынке дата-центров рост за три месяца 11% ($726 млн). Продажи процессоров V100 и T4 бьют все рекорды. Intel пока смотрит на это со стороны, но мы уже знаем, какой будет ответ. Самое интересное только начинается.
