Всем привет! В интернете довольно много статей, связанных с Declarative Jenkins pipeline, и совсем немного о Jenkins Scripting Pipeline, хотелось бы восполнить этот пробел.
В 2008 году Jenkins был ответвлен от проекта Hudson, принадлежащего компании Oracle, и стал самостоятельным продуктом с открытым кодом. В начале, как и его предок, Jenkins поддерживал только последовательное выполнение шелл скриптов (Windows cmd/linux bash). Многие проекты до сих пор с успехом пользуются классическим вариантом интерфейса для обеспечения процесса непрерывной интеграции и развертывания. Первым значительным улучшением стал переход на использование так называемого Jenkins Pipeline. В качестве языка для написания Jenkins Pipeline скрипта был выбран Groovy в связи с тем, что весь остальной код Jenkins написан на Java, а Groovy и Java тесно взаимосвязаны. К сожалению, переход к использованию Jenkins Pipeline сильно усложнил процесс непрерывной интеграции и развертывания, так как требовал дополнительных навыков в написании Groovy скриптов, а также характеризовался сложным процессом отладки этого скрипта. В результате был разработан Jenkins plugin Blue Ocean и редактор Jenkins Pipeline. Но это была немного другая версия Jenkins Pipeline, которая получила название Jenkins Declarative Pipeline. Это был тоже своего рода прорыв, так как позволял людям без особых навыков программирования Groovy описывать довольно сложные процессы интеграции и развертывания.
В нашем проекте мы используем Jenkins для запуска интеграционных (E2E) тестов, которые проверяют функционал системы в целом.
К использованию Jenkins Scripting Pipeline мы пришли не сразу. В начале мы использовали классический Jenkins CI, но довольно быстро перешли на Jenkins Declarative Pipeline, так как выяснилось, что мы не можем запускать тесты одним куском, а должны исполнять их несколькими группами с немного различающимися параметрами запуска. Использование Jenkins Pipeline так же позволило нам запускать параллельно различные группы тестов, что также ускорило общее время выполнения. По мере разрастания функционала и тестов время выполнения полного пакета тестов стало увеличиваться и достигло на пике 40-50 минут. Кроме того, стало понятно, что имеющиеся UI-mock тесты часто не позволяют отловить ошибку, что приводит к потере времени на анализ ошибки в релизной версии. В результате было решено, что помимо UI-mock тестов мы должны выполнять интеграционные тесты прежде, чем осуществить процесс слияния поднятого PR в релизную ветку. Было решено перевести проект на Multibranch Pipeline. За счет распараллеливания тестов удалось сократить время выполнения до 30-35 минут. Мы выделили специальную фазу с небольшим количеством тестов, которые выполнялись за 10 минут. Эта фаза стала использоваться для выполнения тестов на ветке кода перед процессом слияния с релизной веткой.
В результате перед нашей командой были поставлены две задачи, связанные с уменьшением общего времени прогона тестов и времени прогона тестов перед процессом слияния. Для этого мы решили действовать в двух направлениях:
- Проанализировать существующие тесты, по возможности перенести перебор значений из интеграционных тестов в UI-mock или BackEnd-mock тесты (что выходит за рамки этой статьи).
- Выделить из общего набора тестов те, которые покрывали бы 70-80 процентов функционала и при этом быстро выполнялись.
Для решения второй задачи пришлось перейти на использование Jenkins Scripting Pipeline по следующим причинам:
- По соображениям безопасности поддержка Pipeline Editor отключена, поэтому даже Declarative Pipeline надо писать вручную.
- Включение/исключение блока тестов из прогона перед слиянием превращалось в копирование большого количества кода из одного места в другое, что приводило к ошибкам в Jenkins-pipeline файле, которые сложно отлаживать, а также к увеличению размера Jenkins-pipeline файла.
Для решения второй причины мне показалось удобным осуществлять генерацию выполнения тестов в зависимости от конфигурации, прописанной в Jenkins Pipeline файле.
Информацией о том, что вышло в итоге и хочется поделиться, так как в процессе написания Jenkins-pipeline скрипта выяснилось, что в интернете достаточно информации про Declarative Jenkins Pipeline и довольно мало по Jenkins Scripting Pipeline.
Структура тестов
Прежде чем перейти к описанию получившегося Jenkins-pipeline скрипта, необходимо рассказать о структуре и запуске тестов, чтобы дать представление о том, почему стало возможным сделать генерацию выполнения групп тестов.
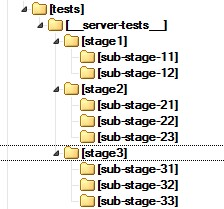
Все тесты разделены на группы исходя из функционала, который они тестируют, в свою очередь, группа может быть разделена на подгруппы.
Запуск тестов осуществляется командой:
jest --config=jest.server.config.js --reporters='default' --reporters='jest-allure'Дополнительные параметры исполнения регулируются установкой переменных окружения. Одним из параметров окружения является PATH_TO_TESTS, в которую вносится путь до тестов относительно папки server-tests. То есть, например, если PATH_TO_TESTS=’stage1’, то выполняются все тесты из папки ‘stage1’, включая все тесты из поддиректорий: ‘sub-stage-11’ и ‘sub-stage-12’. А если PATH_TO_TESTS=’stage1/sub-stage-11’, то тесты только из этой папки.
Именно благодаря такой структуре тестов удалось создать Jenkins-pipeline файл, который в процессе исполнения создает фазы исполнения исходя из конфигурации этих этапов.
Конфигурация этапов выполнения
В качестве групп тестов использовали названия собранных по функционалу директорий, например, ‘stage1’. Для начала было решено выделить 3 больших пакета: Smoke Pack, Main Pack и Special Pack, в которые распределены имеющиеся группы тестов.
В результате выполнения должно было получиться следующее:
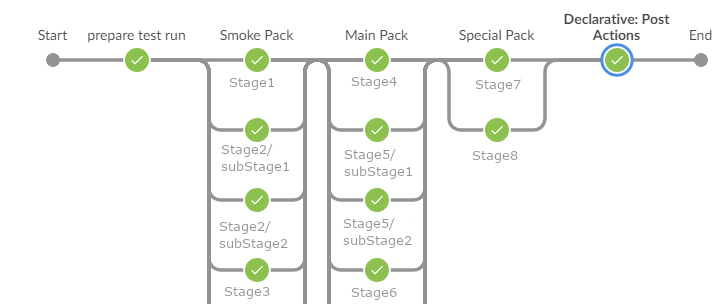
Выяснилось, что группа тестов в свою очередь может состоять из некоторых подгрупп, которые могут выполняться либо параллельно, либо последовательно. Для конфигурирования выполнения я стал использовать три map-коллекции:
- В качестве ключа используется название пакета тестов, в качестве значения – список групп тестов, входящих в пакет.
- В качестве ключа используется название группы тестов (он обязательно должен совпадать со значением из списка в коллекции 1), в качестве значения – список подгрупп тестов, которые выполняются параллельно
- В качестве ключа используется название группы тестов (он обязательно должен совпадать со значением из списка в коллекции 1), в качестве значения – список подгрупп тестов, которые выполняются последовательно. В этом случае последовательность подгрупп тестов важна.
jobPacks = [
'Smoke Pack' : ["Stage1", "Stage2", "Stage3"],
'Main Pack' : ["Stage4", "Stage5", "Stage6", "Stage7"],
'Special Pack': ["Stage8", "Stage9"]
]
parallelSubStages = [
'Stage6': ["sub stage 61", "sub stage 62", "sub stage 63", "sub stage 64"],
'Stage5': ["sub stage 51", "sub stage 52", "sub stage 53"],
'Stage9': ["sub stage 91", "sub stage 92", "sub stage 93", "sub stage 94", "sub stage 95"]
]
multiStepsStages = [
'Stage7': ["sub stage 71", "sub stage 72", "sub stage 73"],
'Stage8': ["sub stage 81", "sub stage 82"]
]Основная перегруппировка происходит в первой коллекции. Именно в ней я переставляю группы тестов по пакетам или переношу в новые группы.
Генерация этапов выполнения
Из-за особенностей Jenkins Scripting Pipeline пришлось выделить 2 обязательных этапа:
- Подготовка: из репозитория проекта скачивается код и устанавливаются необходимые node-modules.
- Завершение: выполняется создание allure-репорта прохождения тестов, очищается кэш прогона и удаляется Jenkins workspace.
Наконец, пишем основной скрипт генерации этапов выполнения.
Существует возможность запуска необходимых тестов вручную (пакетами, отдельными группами тестов), поэтому в переменной окружения STAGES_TO_BE_EXECUTED находится список запускаемых пакетов/групп тестов. По умолчанию он установлен в “Smoke Pack”, таким образом, если запуск происходит в результате изменения ветки кода (commit), то выполняются тесты, входящие в пакет “Smoke Pack”.
Алгоритм генерации довольно простой:
Для каждого пакета из jobPacks:
- На основании выбранных пакетов/групп тестов (“STAGES_TO_BE_EXECUTED”) создается список групп тестов, которые будут выполнены для этого пакета.
- Для каждого элемента из списка групп тестов создается Jenkins “stage” с необходимыми параметрами запуска.
Выглядит это следующим образом:
node {
stage('prepare test run') {
git branch: '$BRANCH_NAME', changelog: true, url: 'ssh://git@my-super-puper-repository.git'
nodejs(nodejsConfig) {
sh "yarn install"
}
}
//--------------------------------------------
// собственно ради этого все и затеивалось:
jobPacks.each {
packName, stages ->
List<String> stagesToExecute = generateExecuteStagesList(packName)
if (!stagesToExecute.isEmpty()) {
stage(packName) {
// parallel в данном месте заставляет Jenkins выполнять stages параллельно
parallel stagesToExecute.collectEntries { ["${it}": generateStage([it, packName])] }
}
}
}
//--------------------------------------------
stage('Declarative: Post Actions') {
allure includeProperties: false, jdk: 'openjdk-linux-intel64-1.8.0_211-1', reportBuildPolicy: 'ALWAYS', results: [[path: 'allure-results']]
nodejs(nodejsConfig) {
sh label: 'clear jest cache', script: "node_modules/.bin/jest --clearCache || true"
}
cleanWs()
}
}Алгоритм функции создания списка групп выполнения:
- Если текущий пакет входит в STAGES_TO_BE_EXECUTED, то все группы тестов, которые к нему относятся, попадают в список выполнения.
- Все группы тестов, выбранные пользователем (содержащиеся в STAGES_TO_BE_EXECUTED) и входящие в данный пакет выполнения на основании jobPack, также добавляются в список выполнения.
- Если список выполнения содержит группы тестов, которые могут быть выполнены параллельно (входят в parallelSubStages), то они заменяются на входящие в него подгруппы.
def generateExecuteStagesList(String packName) {
List<String> stagesToBeExecuted
if (env.STAGES_TO_BE_EXECUTED.contains(packName) || env.STAGES_TO_BE_EXECUTED.contains('Full Pack')) {
// if pack is selected add all stages in pack
stagesToBeExecuted = jobPacks[packName]
}
else {
def selectedStages = env.STAGES_TO_BE_EXECUTED.split(', ')
stagesToBeExecuted = jobPacks[packName].findAll { selectedStages.contains(it) }
}
// now replace all stages with sub stages (from parallelSubStages) with related sub stages
parallelSubStages.each {
multiStage, stages ->
if (stagesToBeExecuted.contains(multiStage)) {
stagesToBeExecuted.remove(multiStage) // remove muliStage (for example "Stage5")
stagesToBeExecuted.addAll(stages.collect{ "${multiStage}/${it}" }) // add multi-stage sub stages (for examples "Stage5/sub stage 51")
}
}
return stagesToBeExecuted
}Алгоритм функции генерации фазы выполнения (stage) в Jenkins:
- Если группа тестов состоит из группы последовательных тестов (входит в multiStepsStages), то создается Jenkins-stage, в котором для каждой группы тестов запускается генерация шагов выполнения.
- Если группа тестов не составная, то для нее создается Jenkins-stage с генерацией шага выполнения.
def generateStage(input) {
def (stageName, packName) = input
// multi-steps stage
if (multiStepsStages.containsKey(stageName)) {
return {
stage("${packName}: ${stageName}") {
// for example generateStep('stage5/sub-stage-51')
multiStepsStages.getAt(stageName).each { stepName -> generateStep(stageName + '/' + stepName) }
}
}
}
// single step stage
return {
stage("${packName}: ${stageName}") {
timeout(15) {
generateStep(stageName)
}
}
}
}Шаги выполнения тестов одинаковые, благодаря чему получилось создать данный генератор:
def generateStep(stageName) {
return catchError(buildResult: 'SUCCESS', stageResult: 'FAILURE') {
withEnv(stageEnv(stageName.toLowerCase().replace(" ", "-"))) {
nodejs(nodejsConfig) {
sh "${jestCommand}"
}
}
}
}В stageEnv устанавливаются дополнительные переменные окружения, с которыми должна выполнятся та или иная группа тестов. В основном это установка роли пользователя, от которого эти тесты выполняются, а также относительный путь к тестам из этой группы на основании имени фазы выполнения. Для этого в generateStage и в generateExecuteStagesList создавались имена с “/” типа “Stage5/sub stage 51”.
Итоги и выводы
Удалось сократить размер Jenkinsfile в 2 раза за счет удаления повторяющегося кода, который был написан в Declarative Jenkins pipeline.
Стало удобнее перемещать группы тестов между пакетами выполнения. Появилась возможность легко разделить группу тестов на несколько подгрупп с последующим параллельным выполнением.
Грамотно подобранная конфигурация позволила сократить время выполнения полного пакета тестов примерно в 2 раза (с 25-30 минут до 13-16 минут).
Было:

Стало:

Smoke пакет при этом выполняется от 2 до 5 минут (около половины тестов):

