
После того как мы рассказали о переносе хранилищ сотен отделений крупного банка в центральный ЦОД, используя решения Riverbed, мы решили немного углубиться технически в «стораджовую» составляющую продуктов, а заодно и подумать над вариантом консолидации данных, например, у крупного ретейлера, проверить эффективность систем SteelFusion Core и Edge, а также оценить инженерные усилия и выгоду заказчика.
По нашему опыту типичный региональный филиал ретейлера строится на паре сетевых коммутаторов, паре серверов, ленточной библиотеке и уборщице, которая меняет кассеты. Иногда библиотеке предпочитают внешний диск. Кассеты могут просто хранить, а могут вывозить с определённой периодичностью. То же самое и с внешним диском. Ширина WAN-канала ограничена парой Мбит/с и редко когда достигает высоких значений.
Инфраструктура центрального офиса ретейлера чуть сложнее: есть и большое количество серверов, и мид-рейндж СХД, и даже встречаются резервные площадки. Поэтому в целом идея консолидации данных региональных филиалов ретейлера применима для такого случая. Тестовый стенд в нашей лавке мы собрали за считанные часы. Вот что получилось.

Одну из лабораторий мы приняли за воображаемый центральный офис (ЦОД), где развернули vCenter и собрали простенький HA-кластер...
В лаборатории, выполняющей роль филиала, мы установили единственную железку Edge. Узкий канал имитировали эмулятором WANem, получая характеристики пропускной способности 2048–3072 кбит/с при задержке 20 мс. Потери пакетов в тестировании моделировать не стали.
Блоки данных между площадками совершают движения после сжатия и дедупликации потока iSCSI-трафика оптимизатором. Упрощённая схема для лучшего понимания — ниже.

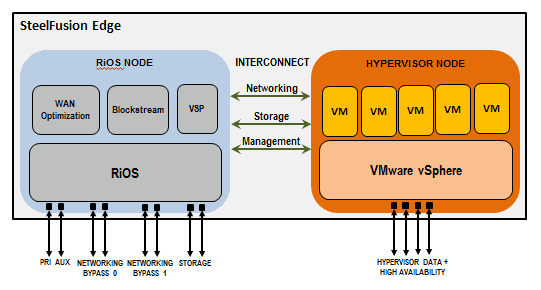
Для проекции дискового пространства в филиал используется шлюз SteelFusion Core (SFC). Мы установили его в качестве виртуальной машины в ЦОДе. Для оптимизации трафика в ЦОДе мы также использовали виртуальный SteelHead VCX, на котором настроили соответствующее правило перехвата трафика и перенаправление его через оптимизатор.
Филиальная железка устроена оригинально. Сервер Edge (в нашем случае 3100) разделён на две ноды:
• RiOS-нода, отвечающая за работу сервисов Riverbed (оптимизация трафика, управление blockstore, гипервизором и т. п.).
• Нода с гипервизором ESXi, преднастроенная в сетевой части.
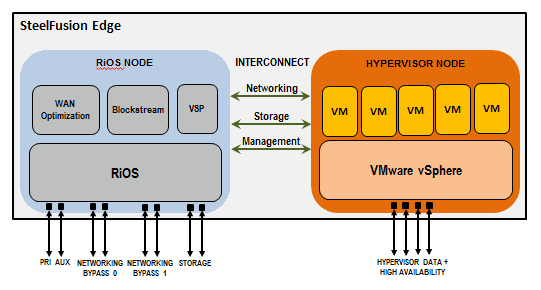
Диски в сервере — это кеш blockstore Edge. Управляется он только нодой RiOS, которая, в свою очередь, выделяет равное луну пространство в кеше для ESXi. При этом доступ ESXi-ноды к blockstore (фактически к дискам в той же железной коробке) осуществляется по протоколу iSCSI на скорости 1 Гбит/с через внутренний интерконнект.
У нас в конфигурации стояли 4 диска 2ТБ SATA 7.2К в RAID10 и 4 диска SSD 240 GB также в RAID10. Hot-spare дисков нет, но зато можно из-под CLI принудительно вернуть неисправный диск в группу. Это полезно, когда необходимо восстановить данные при отказе сразу нескольких дисков. Всего под blockstore доступно чуть более 3 ТБ.
В настройке маршрутизации и оптимизации Rdisk-трафика сложно ошибиться, если сделать всё правильно. Есть чёткие схемы, которым необходимо следовать. В противном случае в качестве бонуса к сумасшедшей системе даются постоянные разрывы прямой связки Edge — Core, нестабильная работа RiOS-соединений и плохое настроение, что мы сперва и получили, банально завернув трафик с Edge на неправильный интерфейс оптимизатора VCX.
Когда наконец дзен был обретён, мы принялись за тестирование типовых операций с хранилищем Edge. Под смешанной нагрузкой с учётом кеширования на SSD-диски мы получили производительность, соответствующую скорости интерконнекта, с приемлемым временем отклика.


Далее мы решили капитально нагрузить Edge виртуальной машиной с Exchange и через LoadGen имитировали активную работу порядка 500 человек. При этом операционная система ВМ была установлена на vmdk-диск, а сам Exchange — на RDM объёмом 150 Гб.
Понятное дело, что для таких нагрузок SFED не предназначен, но чем чёрт не шутит… Дополнительно мы решили поиграться с разрывом связки Core — Edge, чтобы убедиться в корректном поведении и стабильности системы.
При работающей оптимизации и сокращении объёма передаваемых данных до 90%, кеш blockstore заполнялся настолько стремительно, что не только не успевал реплицироваться, но и нехило вешал систему. Когда SFED с завидным аппетитом проглотил 3 ТБ места в blockstore, хост начал получать ошибки записи.

Как оказалось, наша конфигурация не была правильной с точки зрения демонстрации работы оптимизации трафика. Причины следующие:
И с этого момента поподробнее.
Различные типы форматирования VMDK-дисков по-разному кешируются в blockstore.
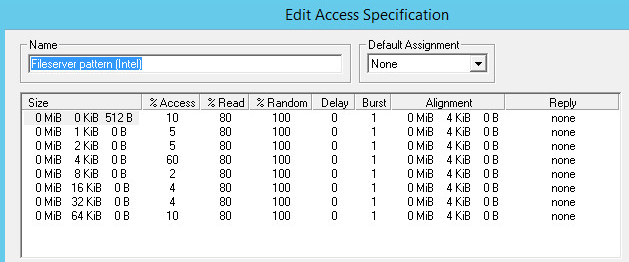
Пример: VMDK-диск объёмом 100 Гб с использованными 20 Гб
Так, наиболее эффективно утилизируется blockstore при использовании тонких томов. Двукратное увеличение количества кешированных и реплицируемых данных наблюдается при использовании Lazy Zeroed дисков за счёт зануления блоков VMFS Datastore при первой записи. Наиболее «прожорливым» является метод Eager Zeroed, т. к. кешируются и нулевые блоки на весь объём, и блоки записанных данных. Дальнейшее тестирование кеширования дисков различных типов привело к ожидаемым результатам — кеш заполнялся ровно настолько, насколько был должен.
Следующим нашим шагом стала проверка эффективности использования системы при разворачивании новой инфраструктуры. Мы обнулили кеш blockstore для чистоты эксперимента, подготовили в ЦОДе VMFS-хранилище с виртуальной машиной и приступили.

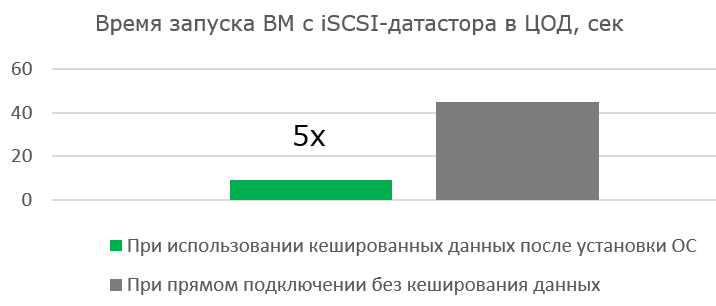
Работа с широким каналом не столь эффективна при первой загрузке готовой виртуальной машины. Но сама работа ВМ ощутимо быстрее, т. к. полезных блоков передаётся всё меньше, а Read Hit в кеше blockstore становится всё больше.

Преимущества оптимизации очевидны там, где канала практически нет.
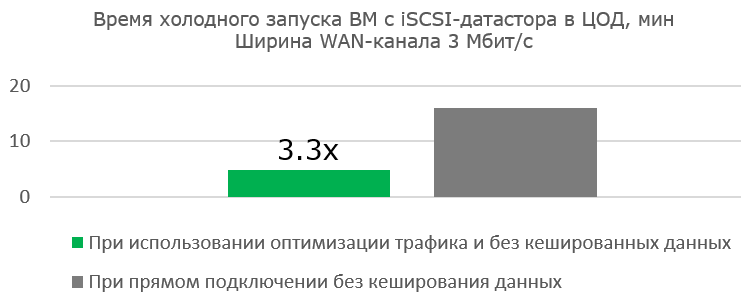
Когда мы устанавливали ВМ на Edge, мы, конечно же, разместили загрузочный образ на спроецированном датасторе, тем самым не давая ему откешироваться в blockstore заранее.
Процесс установки ВМ и результаты оптимизации передаваемых данных:

Статистика blockstore по показателям Read Hit и Read Miss:
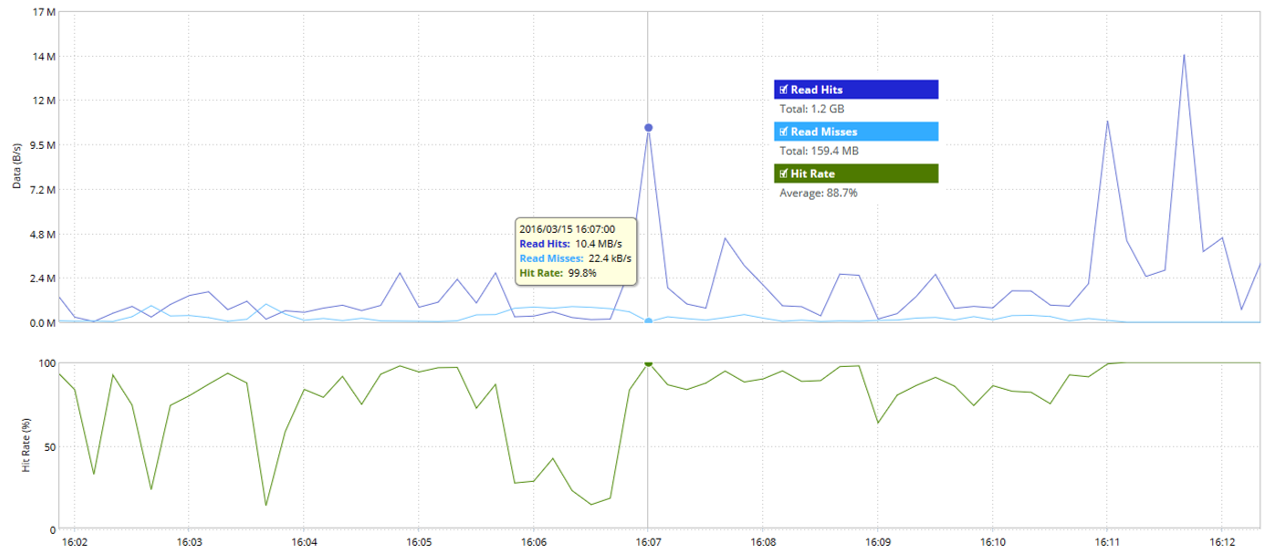
Статистика оптимизации TCP-соединений:
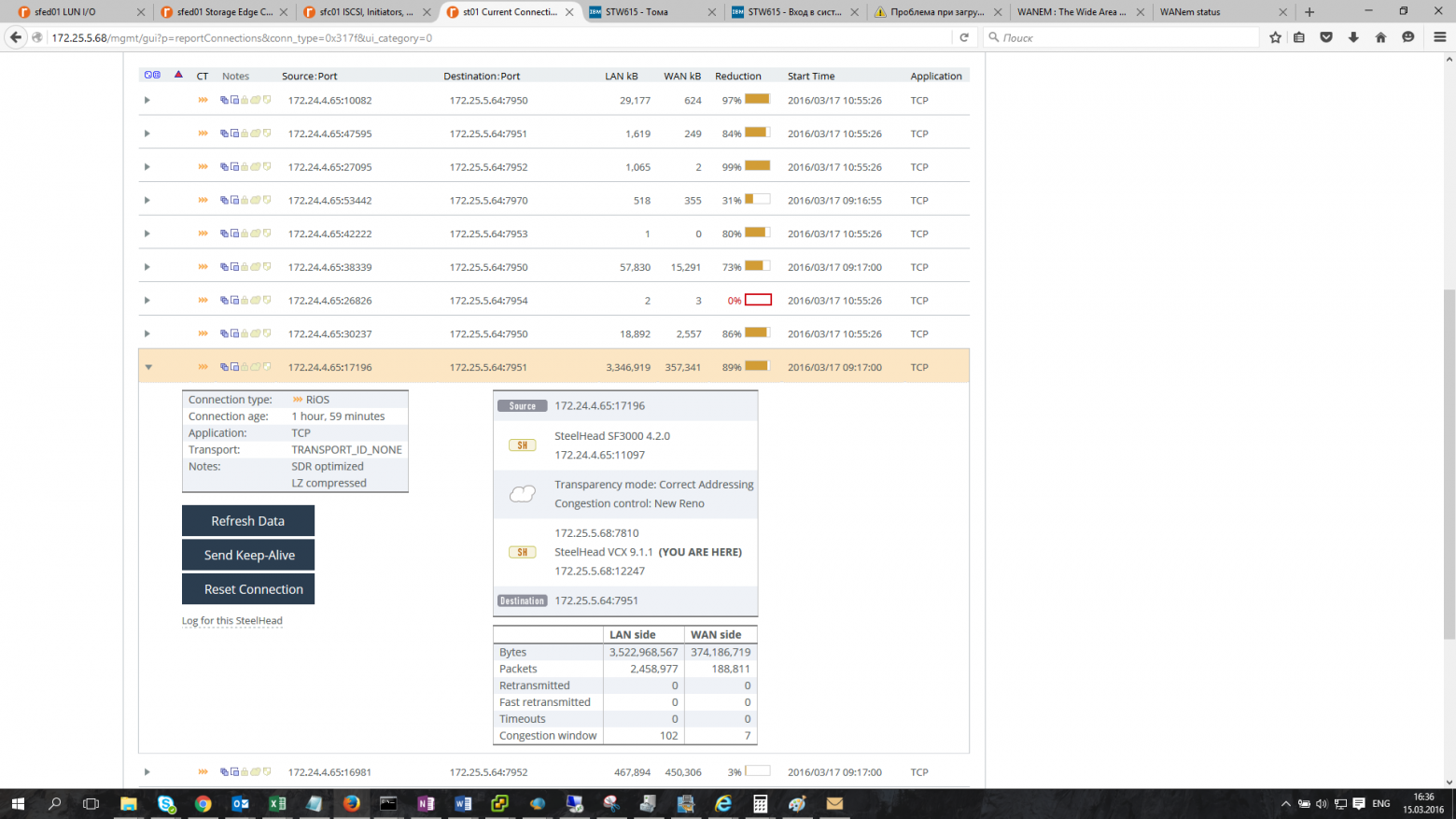
Загруженность WAN- и LAN-каналов:

Здесь мы видим, насколько по факту утилизирован WAN-канал и какую фактическую скорость передачи данных обеспечивает оптимизация трафика.
Спустя час наша свежеустановленная ВМ полностью уехала в ЦОД. На графике видим, как снижается объём реплицируемых данных.

Оставался главный вопрос: как всё это дело бекапить, и желательно с большей долей автоматизации? Ответ: использовать встроенный в Edge-Core функционал снапшотов.
Снапшоты могут быть двух типов — Application Consistent (приложение записывает буферы данных на диск, после чего делается снимок тома) и Crash Consistent (снимок тома без записанных данных из буферов, равносилен запуску приложения после аварийного завершения).
Application Consistent снепшоты работают с виртуальными машинами через VMWare Tools в случае использования VMDK, а также через VSS в случае с NTFS.
Мы тестировали данный функционал в связке ESXi и СХД IBM Storwize V7000.
Как это работает:

Механизм:
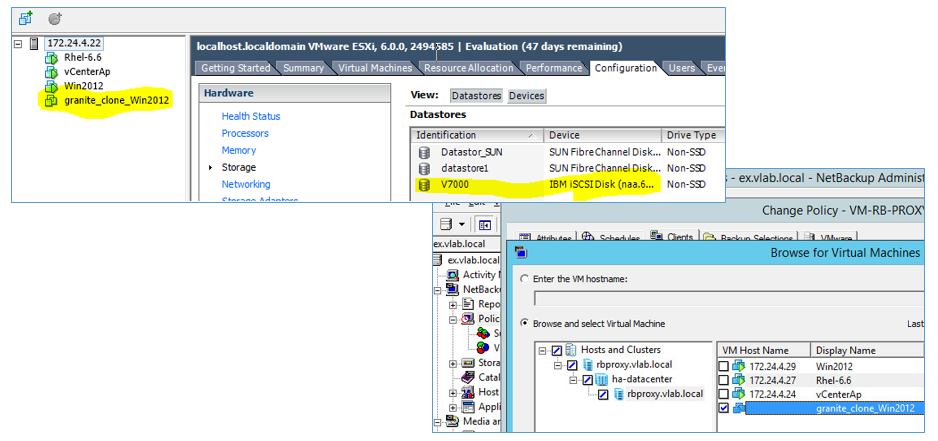
И всё. Виртуальные машины доступны для бекапа любым совместимым с vSphere софтом. Мы взяли Netbackup и успешно сделали резервную копию тестовой машины.

В итоге что мы получаем: использовать отдельные серверы и локальные диски в серверах — это дёшево и быстро, но возникают вопросы с долгосрочным хранением данных и множеством накладных расходов. При этом бекап, конечно, можно делать как на ленту в филиале, так и используя различный софт, к примеру, CommVault со своими механизмами дедупликации и сжатия трафика.
В случае консолидации данных в ЦОД, используя SteelFusion, необходимо изначально располагать соответствующим количеством ресурсов для хранения региональных данных и их бекапа. Дополнительная экономия на бекапе возможна, если лицензировать Proxy Backup серверы в ЦОД по количеству сокетов в зависимости от планируемой нагрузки филиалов.
Если рассматривать классическую компоновку филиала и её примерную стоимость по ключевым позициям, то получим следующую картину:
Используя конфигурации SteelFusion в филиале, получаем:
В ЦОД ставим две виртуальные машины SteeFusion Core и два железных Steelhead.
Рассматривая TCO за 5 лет, получаем экономию как минимум $300 000 при использовании решения SteelFusion. И это без дополнительных накладных расходов в классическом варианте. А учитывая возможности сжатия не только блочного потока репликации, но и различных прикладных протоколов, можно дополнительно сократить расходы на каналы связи.
По нашему опыту типичный региональный филиал ретейлера строится на паре сетевых коммутаторов, паре серверов, ленточной библиотеке и уборщице, которая меняет кассеты. Иногда библиотеке предпочитают внешний диск. Кассеты могут просто хранить, а могут вывозить с определённой периодичностью. То же самое и с внешним диском. Ширина WAN-канала ограничена парой Мбит/с и редко когда достигает высоких значений.
Инфраструктура центрального офиса ретейлера чуть сложнее: есть и большое количество серверов, и мид-рейндж СХД, и даже встречаются резервные площадки. Поэтому в целом идея консолидации данных региональных филиалов ретейлера применима для такого случая. Тестовый стенд в нашей лавке мы собрали за считанные часы. Вот что получилось.

Одну из лабораторий мы приняли за воображаемый центральный офис (ЦОД), где развернули vCenter и собрали простенький HA-кластер...
В лаборатории, выполняющей роль филиала, мы установили единственную железку Edge. Узкий канал имитировали эмулятором WANem, получая характеристики пропускной способности 2048–3072 кбит/с при задержке 20 мс. Потери пакетов в тестировании моделировать не стали.
Блоки данных между площадками совершают движения после сжатия и дедупликации потока iSCSI-трафика оптимизатором. Упрощённая схема для лучшего понимания — ниже.

Для проекции дискового пространства в филиал используется шлюз SteelFusion Core (SFC). Мы установили его в качестве виртуальной машины в ЦОДе. Для оптимизации трафика в ЦОДе мы также использовали виртуальный SteelHead VCX, на котором настроили соответствующее правило перехвата трафика и перенаправление его через оптимизатор.
Филиальная железка устроена оригинально. Сервер Edge (в нашем случае 3100) разделён на две ноды:
• RiOS-нода, отвечающая за работу сервисов Riverbed (оптимизация трафика, управление blockstore, гипервизором и т. п.).
• Нода с гипервизором ESXi, преднастроенная в сетевой части.
Диски в сервере — это кеш blockstore Edge. Управляется он только нодой RiOS, которая, в свою очередь, выделяет равное луну пространство в кеше для ESXi. При этом доступ ESXi-ноды к blockstore (фактически к дискам в той же железной коробке) осуществляется по протоколу iSCSI на скорости 1 Гбит/с через внутренний интерконнект.
У нас в конфигурации стояли 4 диска 2ТБ SATA 7.2К в RAID10 и 4 диска SSD 240 GB также в RAID10. Hot-spare дисков нет, но зато можно из-под CLI принудительно вернуть неисправный диск в группу. Это полезно, когда необходимо восстановить данные при отказе сразу нескольких дисков. Всего под blockstore доступно чуть более 3 ТБ.
В настройке маршрутизации и оптимизации Rdisk-трафика сложно ошибиться, если сделать всё правильно. Есть чёткие схемы, которым необходимо следовать. В противном случае в качестве бонуса к сумасшедшей системе даются постоянные разрывы прямой связки Edge — Core, нестабильная работа RiOS-соединений и плохое настроение, что мы сперва и получили, банально завернув трафик с Edge на неправильный интерфейс оптимизатора VCX.
Когда наконец дзен был обретён, мы принялись за тестирование типовых операций с хранилищем Edge. Под смешанной нагрузкой с учётом кеширования на SSD-диски мы получили производительность, соответствующую скорости интерконнекта, с приемлемым временем отклика.

Далее мы решили капитально нагрузить Edge виртуальной машиной с Exchange и через LoadGen имитировали активную работу порядка 500 человек. При этом операционная система ВМ была установлена на vmdk-диск, а сам Exchange — на RDM объёмом 150 Гб.
Понятное дело, что для таких нагрузок SFED не предназначен, но чем чёрт не шутит… Дополнительно мы решили поиграться с разрывом связки Core — Edge, чтобы убедиться в корректном поведении и стабильности системы.
Что интересного заметили
При работающей оптимизации и сокращении объёма передаваемых данных до 90%, кеш blockstore заполнялся настолько стремительно, что не только не успевал реплицироваться, но и нехило вешал систему. Когда SFED с завидным аппетитом проглотил 3 ТБ места в blockstore, хост начал получать ошибки записи.

Как оказалось, наша конфигурация не была правильной с точки зрения демонстрации работы оптимизации трафика. Причины следующие:
- RDM-диск кешируется в blockstore, но при репликации поток не дедуплицируется. Оптимизация работает только при использовании VMFS-хранилищ и дисков VMDK внутри них. Отсюда крайне медленная репликация тома с Exchange.
- К работе Exchange в нашей виртуальной машине активно привлекался файл подкачки, который лежал на системном диске ОС внутри датастора. Соответственно под оптимизацию попадал именно он и его динамические изменения. Отсюда большой процент сокращения объёма данных на графиках и поспешное ликование.
- Непропорциональное заполнение кеша связано с типом используемого под систему диска Thick, Lazy Zeroed.
И с этого момента поподробнее.
Различные типы форматирования VMDK-дисков по-разному кешируются в blockstore.
Пример: VMDK-диск объёмом 100 Гб с использованными 20 Гб
| Vmdk type |
WAN traffic usage |
Space utilized on array thick luns |
Space utilized on array thin luns |
Vmdk Fragmentation |
| Thin |
20 GB |
20 GB |
20 GB |
High |
| Thick eager Zero |
100 GB + 20 GB = 120 GB |
100 GB |
100 GB |
None (flat) |
| Thick lazy zero (default) |
20 GB + 20 GB = 40 GB |
100 GB |
20 GB |
None (flat) |
Так, наиболее эффективно утилизируется blockstore при использовании тонких томов. Двукратное увеличение количества кешированных и реплицируемых данных наблюдается при использовании Lazy Zeroed дисков за счёт зануления блоков VMFS Datastore при первой записи. Наиболее «прожорливым» является метод Eager Zeroed, т. к. кешируются и нулевые блоки на весь объём, и блоки записанных данных. Дальнейшее тестирование кеширования дисков различных типов привело к ожидаемым результатам — кеш заполнялся ровно настолько, насколько был должен.
Следующим нашим шагом стала проверка эффективности использования системы при разворачивании новой инфраструктуры. Мы обнулили кеш blockstore для чистоты эксперимента, подготовили в ЦОДе VMFS-хранилище с виртуальной машиной и приступили.
| ОС виртуальной машины |
Ubuntu |
Ubuntu |
| Хранилище виртуальной машины |
ЦОД через Core |
ЦОД |
| Объём диска ВМ |
16 GB |
16 GB |
| Объём boot-данных |
~ 370 МБ |
|
| Ширина WAN-канала |
100 Мбит/с |
|
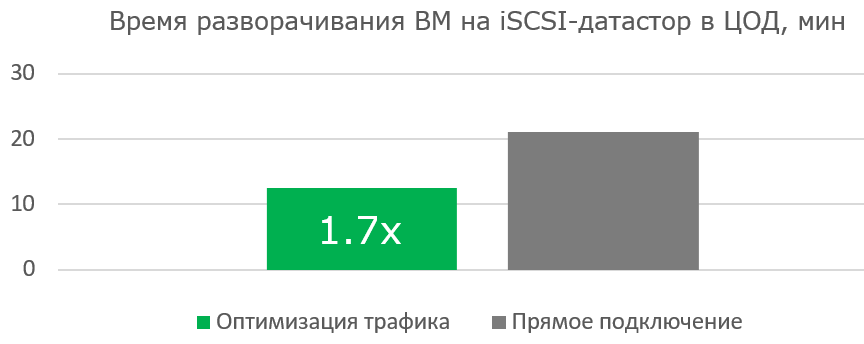

Работа с широким каналом не столь эффективна при первой загрузке готовой виртуальной машины. Но сама работа ВМ ощутимо быстрее, т. к. полезных блоков передаётся всё меньше, а Read Hit в кеше blockstore становится всё больше.
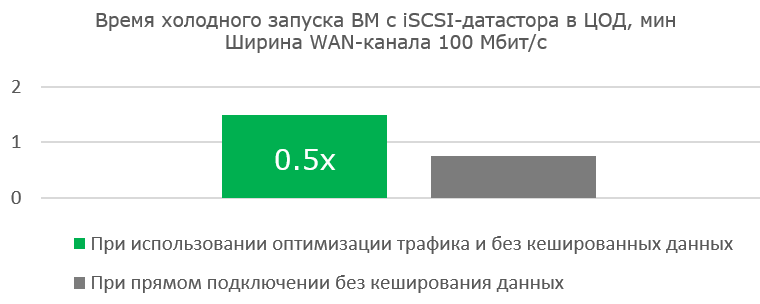
Преимущества оптимизации очевидны там, где канала практически нет.
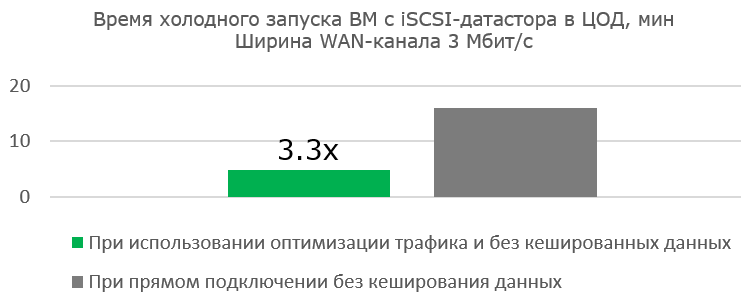
Когда мы устанавливали ВМ на Edge, мы, конечно же, разместили загрузочный образ на спроецированном датасторе, тем самым не давая ему откешироваться в blockstore заранее.
Процесс установки ВМ и результаты оптимизации передаваемых данных:

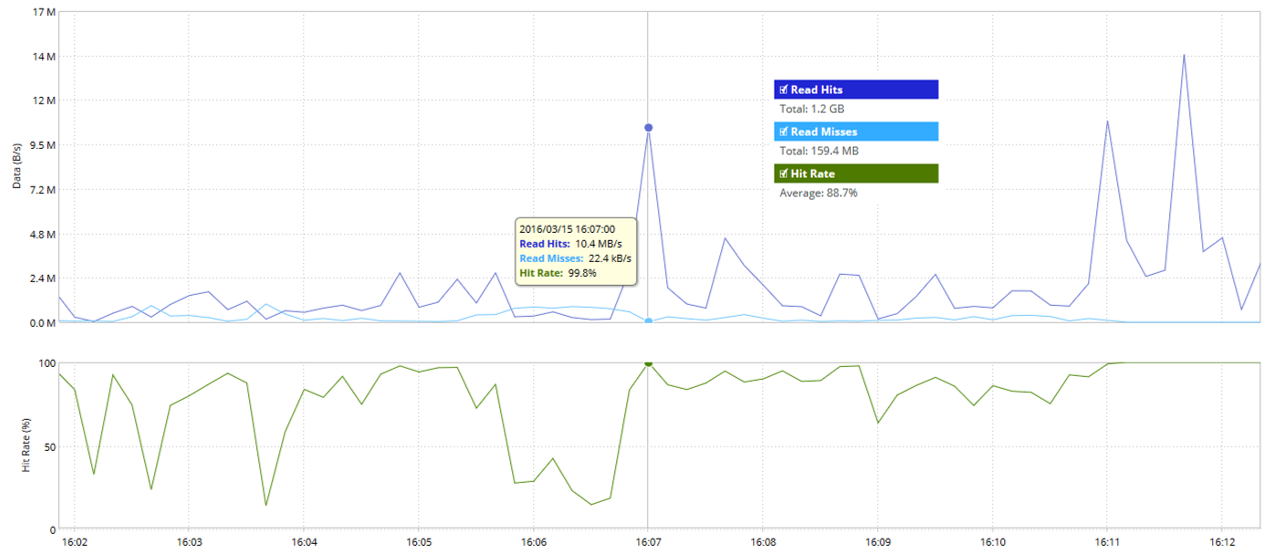
Статистика blockstore по показателям Read Hit и Read Miss:
Статистика оптимизации TCP-соединений:
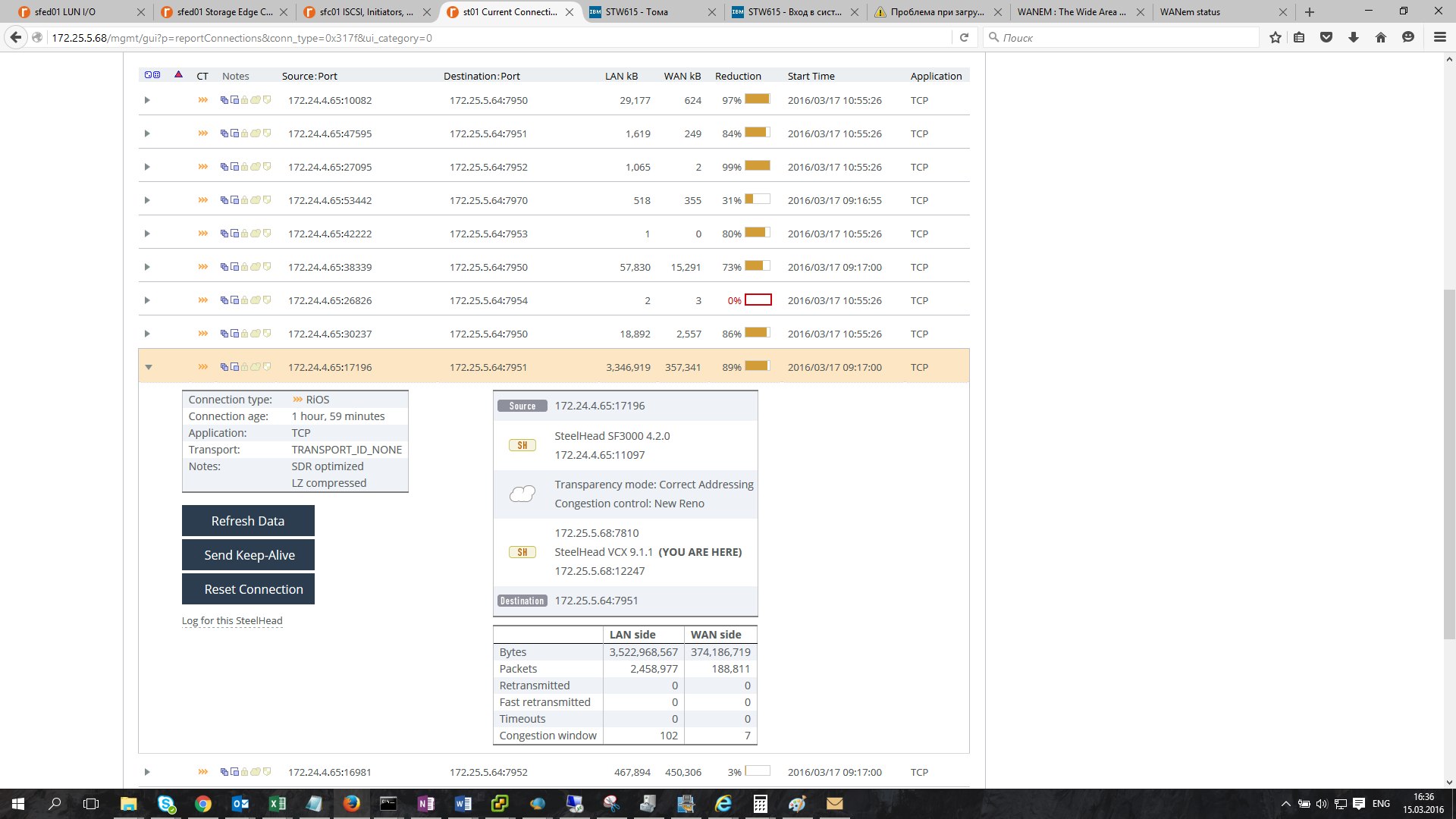
Загруженность WAN- и LAN-каналов:

Здесь мы видим, насколько по факту утилизирован WAN-канал и какую фактическую скорость передачи данных обеспечивает оптимизация трафика.
Спустя час наша свежеустановленная ВМ полностью уехала в ЦОД. На графике видим, как снижается объём реплицируемых данных.

Оставался главный вопрос: как всё это дело бекапить, и желательно с большей долей автоматизации? Ответ: использовать встроенный в Edge-Core функционал снапшотов.
Снапшоты могут быть двух типов — Application Consistent (приложение записывает буферы данных на диск, после чего делается снимок тома) и Crash Consistent (снимок тома без записанных данных из буферов, равносилен запуску приложения после аварийного завершения).
Application Consistent снепшоты работают с виртуальными машинами через VMWare Tools в случае использования VMDK, а также через VSS в случае с NTFS.
Мы тестировали данный функционал в связке ESXi и СХД IBM Storwize V7000.
Как это работает:
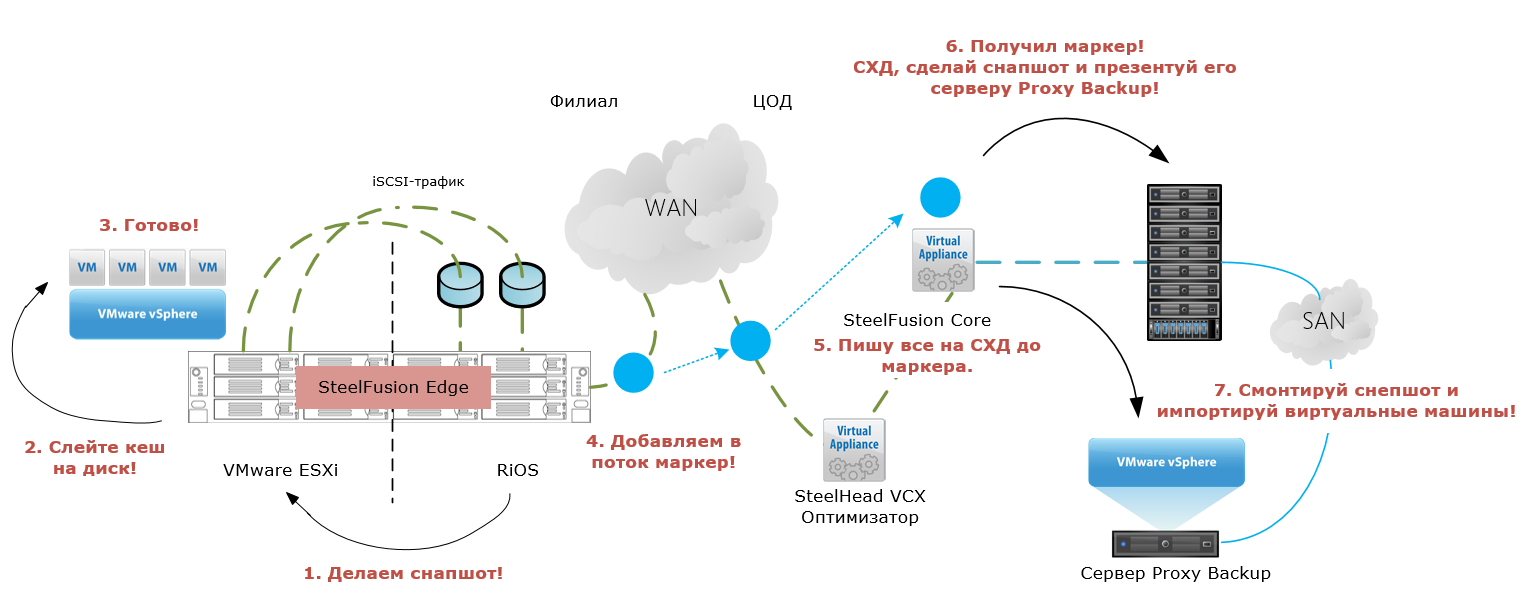
Механизм:
- По заданному расписанию Edge посылает команду ESXi-хосту на создание Application Consistent снепшота.
- Получая команду, ESXi-хост посылает через VMware Tools команду гостевым ВМ записать данные из своих буферов.
- После завершения процесса flushing буферов Edge помещает специальный маркер в поток данных, реплицируемых в ЦОД (commit string).
- Edge соединяется с прежним ESXi-хостом и удаляет ранее снятый снепшот.
- Маркер в WAN-канале достигает Core, все данные до маркера записываются на лун на дисковом массиве.
- После записи данных до маркера Core обращается к дисковому массиву с командой на инициализацию снепшота луна.
- После того как дисковый массив создал снепшот, Core соединяется с Proxy-Backup-сервером также на ESXi, дерегистрирует прошлые ВМ и отключает datastore.
- Затем Core снова соединяется с дисковым массивом, создаёт клон снепшота и презентует его с массива прокси-серверу.
- После этого Core инструктирует прокси-сервер смонтировать снепшот и импортировать виртуальные машины.
И всё. Виртуальные машины доступны для бекапа любым совместимым с vSphere софтом. Мы взяли Netbackup и успешно сделали резервную копию тестовой машины.
В итоге что мы получаем: использовать отдельные серверы и локальные диски в серверах — это дёшево и быстро, но возникают вопросы с долгосрочным хранением данных и множеством накладных расходов. При этом бекап, конечно, можно делать как на ленту в филиале, так и используя различный софт, к примеру, CommVault со своими механизмами дедупликации и сжатия трафика.
В случае консолидации данных в ЦОД, используя SteelFusion, необходимо изначально располагать соответствующим количеством ресурсов для хранения региональных данных и их бекапа. Дополнительная экономия на бекапе возможна, если лицензировать Proxy Backup серверы в ЦОД по количеству сокетов в зависимости от планируемой нагрузки филиалов.
Если рассматривать классическую компоновку филиала и её примерную стоимость по ключевым позициям, то получим следующую картину:
| Классическая компоновка (филиал) |
Примерная стоимость, $ |
| 2 x Сервер (1 CPU, 32GB RAM, 5×600GB HDD) |
20 000 |
| Ленточная библиотека (1 драйв) |
10 000 |
| Расширенная поддержка (24/7/6h), 1 год |
7 000 |
| VMware vSphere Std.: лицензия на 2 сокета |
4 000 |
| Подписка на 2 сокета, 1 год |
1 500 |
| Резервное копирование: лицензия на 2 сокета |
2 000 |
| Поддержка, 1 год |
5 000 |
| CAPEX (первый год) |
49 500 |
| OPEX (последующие 4 года) |
54 000 |
| TCO (5 лет) |
103 500 |
| TCO на 30 филиалов (5 лет) |
3 105 000 |
Используя конфигурации SteelFusion в филиале, получаем:
| Компоновка SteelFusion (филиал) |
Примерная стоимость, $ |
| Оборудование: |
|
| 2 х SteelFusion Edge 2100 |
31 000 |
| Поддержка оборудования и ПО: |
|
| SteelFusion Edge Appliance 2100 Gold Support, 1год |
9 500 |
| Лицензии ПО: |
|
| VSP, BlockStream, WAN Opt (1500 Connections, 20 Mbps) |
7 800 |
| CAPEX (первый год) |
48 300 |
| OPEX (последующие 4 года) |
38 000 |
| TCO (5 лет) |
86 300 |
| TCO (30 филиалов, 5 лет) |
2 589 000 |
В ЦОД ставим две виртуальные машины SteeFusion Core и два железных Steelhead.
| Компоновка SteelFusion (ЦОД) |
Примерная стоимость, $ |
| Оборудование: |
|
| 2 х SteelFusion Core VGC-1500 |
46 800 |
| 2 х SteelHead CX 770 |
30 400 |
| Поддержка оборудования, 1 год: |
|
| SteelFusion Core Virtual Appliance 1500 Gold Support, 1год |
9 400 |
| SteelHead CX Appliance 770 Gold Support, 1год |
5 400 |
| Лицензии ПО: |
|
| License SteelHead CX |
21 600 |
| CAPEX (первый год) |
113 600 |
| OPEX (последующие 4 года) |
59 200,00 |
| TCO (ЦОД, 5 лет) |
172 800 |
Рассматривая TCO за 5 лет, получаем экономию как минимум $300 000 при использовании решения SteelFusion. И это без дополнительных накладных расходов в классическом варианте. А учитывая возможности сжатия не только блочного потока репликации, но и различных прикладных протоколов, можно дополнительно сократить расходы на каналы связи.
Ссылки
- Упомянутый перенос сотен филиалов в центр без потери скорости в банке
- Ликбез про оптимизацию трафика
- Пример сетевого детектива
- История оптимизация каналов для месторождений полезных ископаемых в жутких холодах
- Сносящий мозг ликбез про распределённые и СХД
- Байки нашего подразделения, чтобы расслабиться
- Ну и моя почта — Smesilov@croc.ru
