
Управление и устойчивая обработка данных являются важнейшим фактором успеха практически во всех организациях. В то время как платформа Cloudera Data Platform (CDP) уже поддерживает весь жизненный цикл данных от 'Периферии до ИИ', мы в Cloudera полностью осознаем, что предприятия имеют больше систем за пределами CDP. Очень важно избегать того, чтобы CDP становилась ещё одной обособленной платформой в вашем ИТ-ландшафте. Чтобы исправить это, она может быть полностью интегрирована в существующую корпоративную ИТ-среду, какой бы разнообразной она ни была, и даже помогать отслеживать и классифицировать широкий спектр существующих активов данных, чтобы обеспечить полную картину от начала и до конца. В этом блоге мы выделим ключевые аспекты CDP, которые обеспечивают управление данными и lineage, и покажем, как их можно расширить, чтобы включить в них метаданные из не связанных с CDP систем со всего предприятия.
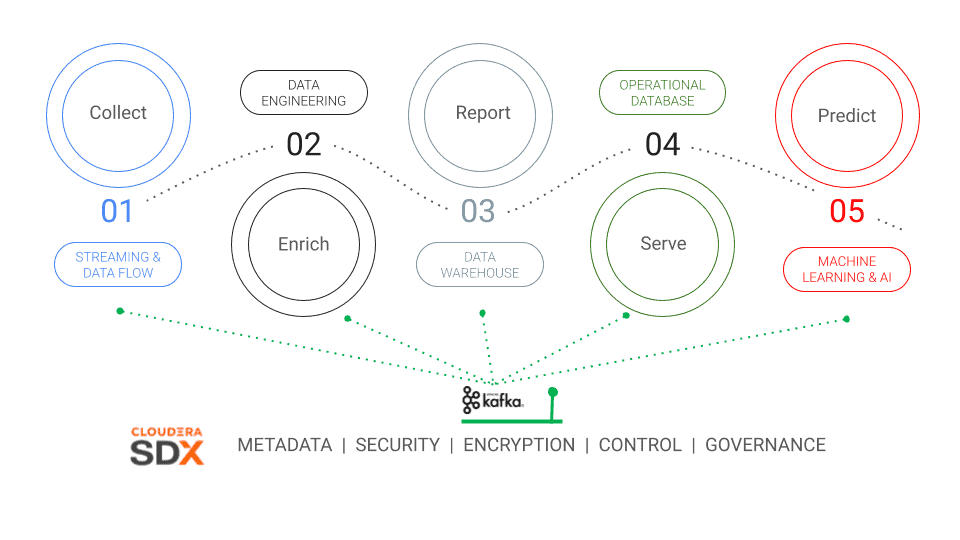
SDX (Shared Data Experience)
Apache Atlas как фундаментальная часть SDX в CDP обеспечивает согласованную защиту данных и управление ими во всем спектре аналитических инструментов, развернутых в гибридной архитектуре, благодаря технологии Shared Data Experience (SDX). Как и сама CDP, SDX построена на проектах с открытым исходным кодом, где Apache Ranger и Apache Atlas играют главные роли. Atlas предоставляет возможности управления метаданными и создания единого дата каталога, а также классификации и управления этими активами данных. SDX в CDP использует все возможности Atlas для автоматического отслеживания и управления всеми активами данных со всех инструментов на платформе.
Использование возможностей Atlas для активов данных за пределами CDP
Atlas предоставляет базовый набор предопределенных определений типов (называемых typedefs) для различных Hadoop и non-Hadoop метаданных для удовлетворения всех потребностей CDP. Но Atlas - это невероятно гибкий и настраиваемый фреймворк для метаданных, который позволяет добавлять активы из сторонних источников данных, даже те, которые находятся за пределами CDP.
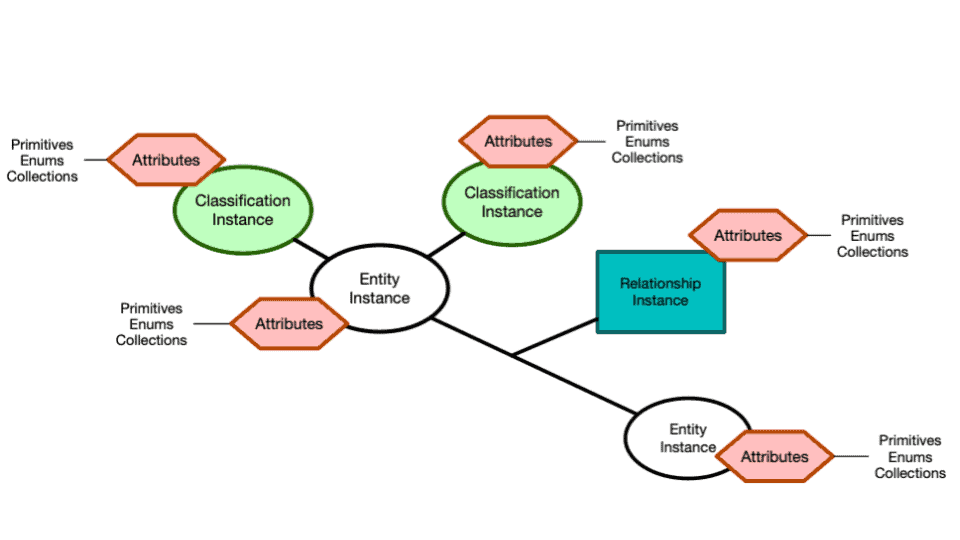
Все построено вокруг основной структуры модели метаданных, состоящей из определений типов (type definitions) и объектов (entities) (подробнее см. документацию Atlas):
Определения каждого типа (typedef)
может быть выведено из определения супертипа
может быть частью высшего класса, позволяя создавать древовидное, структурированное хранилище для активов данных
может иметь неограниченное количество характеристик (атрибутов) для сохранения всех нужных описаний
может определить допустимый набор классификационных определений, которые впоследствии могут быть добавлены к каждой сущности данного typedef. В следующем примере мы используем определенный сервер для типа 'database_server'. Классификации могут также использоваться для указания, содержит ли таблица Персональную идентифицируемую информацию (PII).
Объекты являются примерами определенного typedef и:
могут быть связаны друг с другом
могут быть связаны с любым количеством классификаций. Например, каждому приложению или случаю использования может быть присвоена уникальная классификация; в примере ниже используется "xyz" в качестве приложения. После добавления, связанные объекты могут быть непосредственно привязаны к классификации, что дает четкое представление об артефактах и о том, как они соотносятся друг с другом.
Наконец, Atlas предоставляет богатый набор REST API, которые могут использоваться для:
управления основными typedef и классификациями
управления объектами (сущности typedef )
управления отношениями между объектами
Расширение модели метаданных в Атласе
Следующие шаги описывают, как Atlas может быть расширен для добавления метаданных из третьих источников. На различных этапах используются готовые скрипты из репозитория Github.
Эскиз сквозной линии передачи данных.
Ниже приведен очень простой, но распространенный сценарий ETL пайплайна:
Исходная система (например, транзакционное приложение для банковского приложения) отправляет файл с данными в CSV на какое-то хранилище (не HDFS). Затем ETL-процесс считывает файл, выполняет некоторые проверки качества и загружает проверенные записи в СУБД, а также в таблицу Hive. Проблемные записи сохраняются в отдельном файле ошибок.

Чтобы запечатлеть этот сквозной поток данных в Атласе, нам нужны следующие typedef'ы:
Субъекты:
- Сервер
Активы (typedef):
- Файлы
- Таблица в СУБД
- таблица Hive *обратите внимание, что этот актив уже доступен в Атласе в CDP в качестве неотъемлемой части платформы CDP. Нет необходимости создавать typedef, но мы покажем, как сторонние активы могут подключаться к активам CDP для построения сквозного прослеживания.
Процессы:
- Процесс передачи файлов
- процесс загрузки ETL/DB
2. Определение требуемых определений типов (typedef's).
С точки зрения дизайна, typedef аналогичен определению класса. Существуют предопределенные определения типов (typedefs) для всех активов, которые используются в CDP, например, таблицы Hive. Определения, которые не существуют из коробки, могут быть определены с помощью следующего синтаксиса в простом JSON-файле. В примере 1_typedef-server.json описывается сервер typedef, используемый в этом блоге.
Тип: сервер
Производная форма: ENTITY
Специальные характеристики для этого typedefа:
- имя хоста (host_name)
- ip_адрес (ip_address)
- зона (zone)
- платформа (platform)
- стойка (rack_id)

3. Добавление typedef'ов через REST API в Атлас
Для повышения надежности CDP все хуки Atlas используют Apache Kafka в качестве асинхронного транспортного уровня. Тем не менее, Atlas также предоставляет свой собственный богатый набор RESTful API. На этом шаге мы используем именно те конечные точки REST API v2 - документацию по полной конечной точке REST API можно найти здесь, а для вызова REST API будет использоваться curl.
Примечание: При желании вы можете использовать локальную установку на базе докера для первых шагов:
docker pull sburn/apache-atlas:latest
docker run -d -p 21000:21000 --name atlas
sburn/apache-atlas
/opt/apache-atlas-2.1.0/bin/atlas_start.pyTypedef JSON запрос хранится в файле 1_typedef-server.json, и мы вызываем конечную точку REST следующей командой:
curl -u admin:admin -X POST -H
Content-Type:application/json -H Accept:application/json -H C
ache-Control:no-cache
http://localhost:21000/api/atlas/v2/types/typedefs -d
@./1_typedef-server.jsonДля создания всех требуемых typedef'ов для всего конвейера данных можно также использовать следующий bash скрипт (create_typedef.sh):
4. Проверка интерфейса Atlas после добавления типов и классификации внешних источников, чтобы убедиться, что новые сущности были добавлены
Новые типы сгруппированы под обьектом "3party".

Также были добавлены новые классификации:

5. Создание сущности "server"
Чтобы создать субъект, используйте REST API "/api/atlas/v2/entity/bulk" и обратитесь к соответствующей типизации (например, "typeName": "server").
Полезно знать: Create vs Modify. Каждый типдеф определяет, какие поля должны быть уникальными. Если вы отправите запрос, в котором эти значения не являются уникальными, существующий экземпляр (с одинаковыми значениями) будет обновлен, а не вставлен.
Следующая команда показывает, как создать субъект сервера:
curl -u admin:admin -H Content-Type:application/json -H Accept:application/json http://localhost:21000/api/atlas/v2/entity/bulk -d '
{
"entities": [
{
"typeName": "server",
"attributes": {
"description": "Server: load-node-0 a landing_zone_incoming in the prod environment",
"owner": "mdaeppen",
"qualifiedName": "load-node-0.landing_zone_incoming@prod",
"name": "load-node-0.landing_zone_incoming",
"host_name": "load-node-0",
"ip_address": "10.71.68.009",
"zone": "prod",
"platform": "darwin19",
"rack_id": "swiss 1.0"
},
"classifications": [
{"typeName": "landing_zone_incoming"}
]
}
]
}'Скрипт create_entities_server.sh из репозитория github иллюстрирует создание субъекта сервера с помощью общего сценария с некоторыми параметрами. На выходе получается GUID созданного/измененного артефакта (например, SERVER_GUID_LANDING_ZONE=f9db6e37-d6c5-4ae8-976c-53df4a55415b).
SERVER_GUID_LANDING_ZONE=$(./create_entities_server.sh \
-ip 10.71.68.009 \ <-- ip of the server (unique key)
-h load-node-0 \ <-- host name of the server
-e prod \ <-- environment (prod|pre-prod|test)
-c landing_zone_incoming) <-- classification6. Создание сущности типа "datafile"
Аналогично созданию субъекта сервера, снова используйте REST API "/api/atlas/v2/entity/bulk" и обратитесь к типу "dataset".
curl -u admin:admin -H Content-Type:application/json -H Accept:application/json http://localhost:21000/api/atlas/v2/entity/bulk -d '
{
"entities": [
{
"typeName": "dataset",
"createdBy": "ingestors_xyz_mdaeppen",
"attributes": {
"description": "Dataset xyz-credit_landing.rec is stored in /incommingdata/xyz_landing",
"qualifiedName": "/incommingdata/xyz_landing/xyz-credit_landing.rec",
"name": "xyz-credit_landing",
"file_directory": "/incommingdata/xyz_landing",
"frequency":"daily",
"owner": "mdaeppen",
"group":"xyz-credit",
"format":"rec",
"server" : {"guid": "00c9c78d-6dc9-4ee0-a94d-769ae1e1e8ab","typeName": "server"},
"col_schema":[
{ "col" : "id" ,"data_type" : "string" ,"required" : true },
{ "col" : "scrap_time" ,"data_type" : "timestamp" ,"required" : true },
{ "col" : "url" ,"data_type" : "string" ,"required" : true },
{ "col" : "headline" ,"data_type" : "string" ,"required" : true },
{ "col" : "content" ,"data_type" : "string" ,"required" : false }
]
},
"classifications": [
{ "typeName": "xyz" }
]
}
]
}'Скрипт create_entities_file.sh из репозитория github показывает, как создать сущность dataset и вернуть GUID для каждого файла.
CLASS="systemOfRecord"
APPLICATION_ID="xyz"
APPLICATION="credit"
ASSET="$APPLICATION_ID"-"$APPLICATION"
FILE_GUID_LANDING_ZONE=$(./create_entities_file.sh \
-a "$APPLICATION_ID" \
-n "$ASSET"_"landing" \ <-- name of the file
-d /incommingdata/"$APPLICATION_ID"_landing \ <-- directory
-f rec \ <-- format of the file
-fq daily \
-s "$ASSET" \
-g "$SERVER_GUID_LANDING_ZONE" \ <-- guid of storage server
-c "$CLASS")7. Поддерживание информации о классификациях, связанных с приложениями
Чтобы не потерять информацию о том, какая сущность является какой, если их существует много, мы можем создать дополнительную классификацию для каждого приложения. Скрипт create_classification.sh поможет нам создать дополнительную классификацию для каждого приложения, которая может быть использована для привязки всех активов к нему.
CLASS="systemOfRecord"
APPLICATION_ID="xyz"
APPLICATION="credit"
ASSET="$APPLICATION_ID"-"$APPLICATION"
$(./create_classification.sh -a "$APPLICATION_ID")Вызов REST endpoint:
curl -u admin:admin -H Content-Type:application/json -H Accept:application/json http://localhost:21000/api/atlas/v2/types/typedefs -d '{
"classificationDefs": [
{
"category": "CLASSIFICATION",
"name": "xyz",
"typeVersion": "1.0",
"attributeDefs": [],
"superTypes": ["APPLICATION"]
}
]
}'8. Построение отношения между активами
Для активов конвейера данных, которые мы спроектировали и создали выше, нам нужны два разных типа для процессов, которые их соединяют:
Передача данных (см. typedef & create_entities_dataflow.sh)
# add file transfer "core banking" to "landing zone"
FILE_MOVE_GUID=$(./create_entities_dataflow.sh \
-a "$APPLICATION_ID" \
-t transfer \ <-- type of process
-ip 192.168.0.102 \ <-- execution server
-i "$ASSET"_"raw_dataset" \ <-- name of the source file
-it dataset \ <-- type of the source
-ig "$FILE_GUID_CORE_BANING" \ <-- guid of the source
-o "$ASSET"_"landing_dataset" \ <-- name of the target file
-ot dataset \ <-- type of the target
-og "$FILE_GUID_LANDING_ZONE" \ <-- guid of the target
-c sftp) <-- classification
echo "$FILE_MOVE_GUID"ETL / Загрузка (см. typedef & create_entities_dataflow.sh)
# add etl "landing zone" to "DB Table"
FILE_LOAD_GUID=$(./create_entities_dataflow.sh \
-a "$APPLICATION_ID" \
-t etl_load \ <-- type of process
-ip 192.168.0.102 \ <-- execution server
-i "$ASSET"_"landing_dataset" \ <-- name of the source file
-it dataset \ <-- type of the source
-ig "$FILE_GUID_LANDING_ZONE" \ <-- guid of the source
-o "$ASSET"_"database_table" \ <-- name of the target file
-ot db_table \ <-- type of the target
-og "$DB_TABLE_GUID" \ <-- guid of the target
-c etl_db_load) <-- classification
echo "$FILE_LOAD_GUID"9. Собераем все вместе
Теперь у нас собраны все кусочки головоломки. Скрипт sample_e2e.sh показывает, как собрать их вместе, чтобы создать сквозную линию данных. Пайплайн также может содержать активы, которые уже были CDP, нужно просто установить между ними связь (как показано выше).
Последовательность действий:
Создайте уникальную классификацию для данного приложения
Создайте необходимые сущности серверов
Создайте необходимые сущности датасетов на ранее созданных серверах (Mainframe, Landing zone).
Создайте необходимые сущности таблиц БД на ранее созданном сервере БД
Создайте процесс с типом 'transfer' между набором данных Mainframe > Landing
Создайте процесс с типом 'etl_load' между Landing zone > DB table
Создайте процесс с типом 'etl_load' между Landing zone > таблицей HIVE
Создайте процесс с типом 'etl_load' между Landing zone > набором данных Error
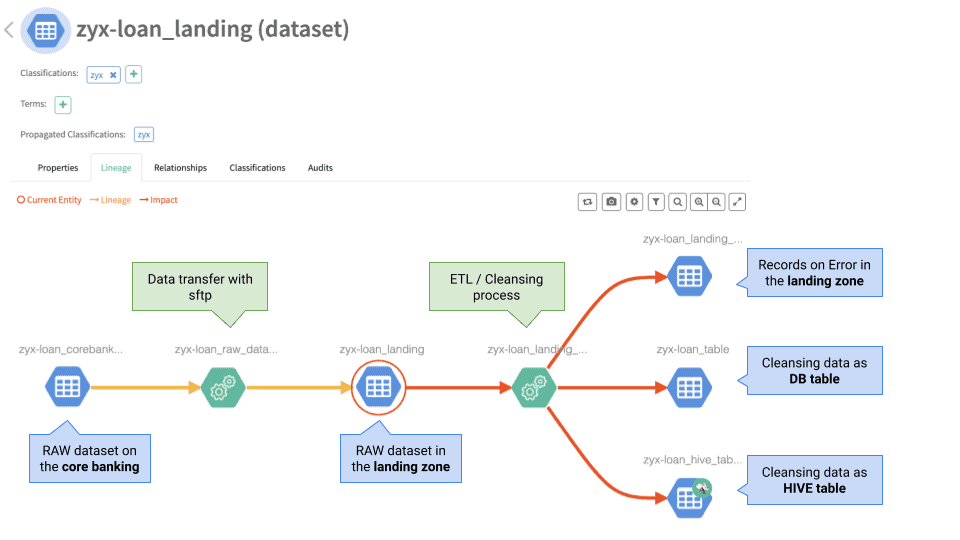
Сценарий, описанный выше, то и дело встречается практически во всех компаниях в такой или похожей форме. Atlas - это очень гибкий каталог метаданных, который может быть адаптирован для всех видов активов. При интеграции активов третьих источников он обеспечивает истинную добавленную стоимость за счет более полной иллюстрации существующих потоков данных. Связи между всеми активами имеют решающее значение для оценки последствий изменений или просто для понимания происходящего. Я рекомендую придерживаться подхода "начни с малого" и записывать первоисточник каждого набора данных по мере его подключения к CDP или во время технического обслуживания. Используйте возможности того, что уже есть, и со временем дополните картину.
