Привет! В первой части мы рассказали, зачем вообще решили заняться этим вопросом, а также поделились переводом статьи, ставшей для нас отправной точкой для собственных изысканий. Теперь хотим рассказать, как мы доработали идею под нашего сотрудника.
Отдельное спасибо комментаторам, которые отметились в комментариях к первой части. Устройства с костной проводимостью, программные решения вроде Equalizer APO 1.2.1, слуховые устройства с поддержкой Bluetooth — мы собрали и передали все ваши идеи. Может быть, что-то из этого и выйдет. Но мы расскажем о своём варианте. Возможно, он тоже кому-то будет полезен.
Подготовка
Для проверки нужно построить свои HL-аудиграммы ('Hearing Levels'). Сгенерируем wav-образцы на ключевых частотах с постепенно возрастающей громкостью с помощью gen_hl_samples.py, прослушаем их и запишем время, когда стало слышно каждый из образцов. Далее по "линейке" сопоставим время с уровнем громкости и получим свою аудиограмму в виде набора "частота" — "уровень слышимости частоты".
В авторский код gen_hl_samples.py были внесены некоторые изменения:
во-первых, в дополнение к wav-файлам вместо вывода в консоль параметров "время — дБ" стали выводить своеобразную "линейку": текстовый файлик со шкалой, который помогает по моменту времени определить уровень слышимости (одинаковый для всех ключевых частот)
Пример линейки
MIN 0:00 0:01 0:02 0:03 0:04 0:05 0:06 0:07 0:08 0:09 0:10 MAX ──────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────── volume │ -90.00 dB │ -80.00 dB │ -70.00 dB │ -60.00 dB │ -50.00 dB │ -40.00 dB │ -30.00 dB │ -20.00 dB │ -10.00 dB │ 0.00 dB │ volume amplitude │ 0.00003 │ 0.00010 │ 0.00032 │ 0.00100 │ 0.00316 │ 0.01000 │ 0.03162 │ 0.10000 │ 0.31623 │ 1.00000 │ amplitude
во-вторых, сменили направление изменения громкости на возрастание, дабы сразу не оглохнуть, начав прослушивать образец. В оригинале громкость образцов убывала.
gen_hl_samples.py
Генератор образцов для построения своей HL-аудиограммы: генерирует для каждой частоты из списка [125, 250, 500, 1000, 2000, 4000, 6000] wav-файл, громкость нарастает от vol_min до vol_max со скоростью vol_delta дБ/сек
import numpy as np
from scipy.io import wavfile
def db_to_amplitude(level_dB): # преобразование дБ в амлитуду
return np.power(10.0, level_dB / 20.0)
def amplitude_to_db(amplitude): # преобразование амлитуты в дБ
return 20 * np.log10(amplitude)
def line_aka(time, frequency, volume, time_str='', scale_str='', vol_str='', amp_str=''):
if len(time_str) == 0 or len(scale_str) == 0 or len(vol_str) == 0 or len(amp_str) == 0:
time_str = f"MIN {time // 60:0>1.0f}:{time % 60:0>2.0f}" # временные отметки для шкалы
scale_str = f"──────────┼" # шкала
# vol_str = f" {frequency: >4} Hz │" # отметки уровня тона
vol_str = f" volume │" # отметки уровня тона
amp_str = f"amplitude │"
else:
time_str += f"{' ' * 8}{time // 60:0>1.0f}:{time % 60:0>2.0f}"
scale_str += f"{'─' * 11}┼"
vol_str += f"{volume: >7.2f} dB │"
amp_str += f" {db_to_amplitude(volume): >9.5f} │"
return time_str, scale_str, vol_str, amp_str
if __name__ == "__main__":
sampleRate = 44100
duration = 1 # сек, длительность звучания тона в образце на текущем уровнем громкости
sampleCount = sampleRate * duration
s = '' # шкала время/уровень громкости тона
for freq in [125, 250, 500, 1000, 2000, 4000, 6000]: # Гц, частота тонов образцов
samples = np.array([])
# amp = amp_delta = 0.01 # начальная амлитуда и шаг изменения амплитуды
# amp_max = 0.1 # конечная амплитуда
vol_min = -90 # дБ, начальный уровень громкости
vol_max = 0 # дБ, конечный уровень громкости
vol_delta = 1 # дБ, шаг
t = 0 # сек, начальный момент времени
s_time, s_scale, s_dB, s_amp = line_aka(t, freq, None)
for vol_dB in range(vol_min, vol_max + vol_delta, vol_delta):
time_points_array = np.linspace(t, t + duration, sampleCount)
samples_new = np.sin(2 * np.pi * freq * time_points_array)
samples_new *= db_to_amplitude(vol_dB)
samples = np.append(samples, samples_new)
t += duration
s_time, s_scale, s_dB, s_amp = line_aka(t, freq, vol_dB, s_time, s_scale, s_dB, s_amp)
# сохранение частотного образца в файл
wavfile.write(f"./wav_files/sine_{freq}.wav", sampleRate, samples)
print(f"{freq: >4} Hz wav file done!")
s = f"{s_time} MAX\n{s_scale}──────────\n{s_dB} volume\n{s_amp} amplitude"
# print(s)
with open(f"./wav_files/sine_hearing_levels_scale.txt", 'w', encoding='utf-8') as file_handle:
file_handle.write(s)
125 Hz wav file done!
250 Hz wav file done!
500 Hz wav file done!
1000 Hz wav file done!
2000 Hz wav file done!
4000 Hz wav file done!
6000 Hz wav file done!
Аудиограммы готовы. Визуализируем данные с помощью matplotlib и numpy.
image_builder.py
# https://blog.demofox.org/2015/04/14/decibels-db-and-amplitude/
# 0 дБ означает полный уровень сигнала: амплитуда == 1.0, т.е. 100% громкость
# каждые 6 дБ сигнал изменяется в ~2 раза
# +n дБ - увеличение громкости
# -n дЬ - уменьшение громкости
import matplotlib.pyplot as plt
from matplotlib.ticker import EngFormatter, FuncFormatter, PercentFormatter
import numpy as np
import matplotlib as mpl
from mpl_toolkits.axes_grid1 import make_axes_locatable
def db_to_amplitude(level_db): # преобразование дБ в амлитуду
return np.power(10.0, level_db / 20.0)
def amplitude_to_db(amplitude): # преобразование амлитуты в дБ
return 20 * np.log10(amplitude)
audiograms = { # decibel-frequency audiograms
1: np.array([ # An_
[125, -48.0],
[250, -42.0],
[500, -52.0],
[1000, -36.0],
[2000, -23.0],
[4000, -29.0],
[6000, -19.0],
]),
2: np.array([ # Mi_
[125, -76.0],
[250, -68.0],
[500, -72.0],
[1000, -73.0],
[2000, -77.0],
[4000, -83.0],
[6000, -78.0],
])}
for k, a in audiograms.items():
min_y, max_y = a[:, 1].min() * 1.1, 0
img_width, img_height = 16, 9
fig, ax = plt.subplots(1, 1, figsize=(img_width, img_height))
plt.xticks(rotation='vertical')
fig.suptitle(f"Аудиограмма {k} сотрудника Cloud4y") # , fontsize=14)
fig.patch.set_facecolor('white')
ax.plot(a[:, 0], a[:, 1], '-o')
ax.set_xscale('log')
ax.set_xlabel(r'Частота сигнала')
ax.set_ylabel(r'лучше <<< Уровень слуха (слышимость сигнала) >>> хуже')
ax.set_ylim(min_y, max_y)
ax.xaxis.set_major_formatter(EngFormatter(unit='Гц'))
ax.yaxis.set_major_formatter(EngFormatter(unit='дБ'))
ax.xaxis.set_ticks(a[:, 0])
ax.yaxis.set_major_locator(plt.MultipleLocator(10))
ax.yaxis.set_minor_locator(plt.MultipleLocator(2))
ax.grid(axis='y')
# дополнительные вертикальные оси - способ 1
y2 = ax.secondary_yaxis('right', functions=(db_to_amplitude, amplitude_to_db))
y2.set_yscale('log')
y2.set_ylabel(r'Амплитуда сигнала')
y2.yaxis.set_major_formatter(FuncFormatter(lambda x, pos: f"{x: .3f}"))
y3 = ax.secondary_yaxis(1.1, functions=(db_to_amplitude, amplitude_to_db))
y3.set_yscale('log')
y3.set_ylabel(r'Громкость сигнала')
# y3.yaxis.set_major_formatter(FuncFormatter(lambda x, pos: f"{x * 100:5.1f} %"))
y3.yaxis.set_major_formatter(PercentFormatter(xmax=1, decimals=1, symbol=' %', is_latex=False))
# # дополнительные вертикальные оси - способ 2 - происходит наложение 2го графика на 1й вместо добавления Y-оси
# # чтобы графики совпадали, нужно подправлять пределы
# ax2 = ax.twinx()
# ax2.set_yscale('log')
# ax2.plot(df[:, 0], db_to_amplitude(df[:, 1]), 'y:x')
# ax2.set_ylabel(r'Signal Amplitude')
# ax2.set_ylim(db_to_amplitude(min_y), db_to_amplitude(max_y))
# ax2.yaxis.set_major_formatter(FuncFormatter(lambda x, pos: f"{x:.3f}"))
# ax2.xaxis.set_ticks(df[:, 0])
ax.axhline(y=a[:, 1].max() + 1, linestyle="-", color='C2') # demo_1_audible_normally
ax.axhline(y=np.median(a[:, 1]), linestyle="-", color='C1') # demo_2_audible_partially
ax.axhline(y=a[:, 1].min() - 1, linestyle="-", color='C3') # demo_3_not_audible
labels = [
"HL-Аудиограмма (Hearing Level)",
f"demo_1: {a[:, 1].max() + 1: .0f} дБ ≡ {db_to_amplitude(a[:, 1].max() + 1): .5f}, корректировка не потребуется",
f"demo_2: {np.median(a[:, 1]): .0f} дБ ≡ {db_to_amplitude(np.median(a[:, 1])): .5f}, для частичной корректировки",
f"demo_3: {a[:, 1].min() - 1: .0f} дБ ≡ {db_to_amplitude(a[:, 1].min() - 1): .5f}, для полной корректировки по аудиограмме",
]
plt.legend(labels=labels)
divider = make_axes_locatable(ax)
cax = divider.append_axes("left", size="0.7%", pad=-.09)
cax.set_ylim(min_y, max_y)
norm = mpl.colors.Normalize(vmin=min_y, vmax=max_y)
cmap = mpl.cm.ScalarMappable(norm=norm, cmap='RdYlGn_r', )
fig.colorbar(cmap, cax=cax)
cax.yaxis.set_major_locator(plt.MultipleLocator(10))
cax.yaxis.set_minor_locator(plt.MultipleLocator(2))
cax.set_yticklabels([])
fig.tight_layout()
plt.show()


На каждой аудиограмме отмечены три уровня громкости, 'нормально слышно', 'частично слышно', 'совсем не слышно', на которых мы сгенерируем с помощью gen_continuous_sample.py демки, которые затем обработаем их алгоритмом, чтобы понять, насколько хорошо проходит обработка.
gen_continuous_sample.py
Генерация образцов с тремя разными постоянными уровнями громкости, частота меняется от freq_start до freq_end со скоростью freq_inc/time_inc Гц/сек.
from scipy.io import wavfile
import numpy as np
def db_to_amplitude(level_db): # преобразование дБ в амлитуду
return np.power(10.0, level_db / 20.0)
def amplitude_to_db(amplitude): # преобразование амлитуты в дБ
return 20 * np.log10(amplitude)
def generate_samples(sample_rate, level=-20.0):
amp = db_to_amplitude(level) # коэффициент амлитуды (уровня громкости) сигнала (1 ≡ 0 dB)
freq_start = 125 # Гц
freq_end = 8000 # Гц
freq_inc = 25 # Гц, шаг увеличения тональности
time_inc = .25 # сек, длительность сигнала перед увеличением тональности
print(f"amplitude {amp: .5f} ≡ {np.round(20 * np.log10(amp), 2)} dB")
inc_sample_count = int(sample_rate * time_inc)
sample = np.array([])
freq = freq_start
t = 0.0
while freq < freq_end:
time_points_array = np.linspace(t, t + time_inc, inc_sample_count, endpoint=False)
new_samples = np.sin(2 * np.pi * freq * time_points_array)
new_samples *= amp
sample = np.append(sample, new_samples)
freq += freq_inc
t += time_inc
return sample
if __name__ == '__main__':
levels_a = {'demo_1_audible_normally': -18.0, 'demo_2_audible_partially': -36.0, 'demo_3_not_audible': -53.0} # An_
levels_m = {'demo_1_audible_normally': -67.0, 'demo_2_audible_partially': -76.0, 'demo_3_not_audible': -84.0} # Mi_
levels = {1: levels_a, 2: levels_m}
sampleRate = 44100
for k, l in levels.items():
for name, level in l.items():
generated_samples = generate_samples(sampleRate, level=level)
wavfile.write(f"./wav_files/{k}_{name}.wav", sampleRate, generated_samples)
amplitude 0.12589 ≡ -18.0 dB
amplitude 0.01585 ≡ -36.0 dB
amplitude 0.00224 ≡ -53.0 dB
amplitude 0.00045 ≡ -67.0 dB
amplitude 0.00016 ≡ -76.0 dB
amplitude 0.00006 ≡ -84.0 dB
Демо-wav готовы для обработки с помощью gain.py.
gain.py
from scipy.io import wavfile
import numpy as np
import time
import os.path
# находит и возвращает главную частоту в заданном окне и уровень сигнала
def get_dominant_freq(sample_rate, window):
# область частот окна
yf = np.fft.fft(window)
yf = np.abs(2 * yf / len(window))
window_size = len(window)
window_half = len(window) // 2
max_amp = yf[:window_half].max()
max_amp_idx = yf[:window_half].argmax()
# поиск частоты по её индексу
frequency = sample_rate * max_amp_idx / window_size # frequency = (sample_rate/2) * max_amp_idx / (window_size/2)
return frequency, amplitude_to_db(max_amp)
def get_gain(freq, dB, audiogram): # возвращает необходимый сдвиг уровня для сигнала для указанной частоты согласно аудиограмме
threshold = None
if freq < audiogram[0][0]:
threshold = audiogram[0][1]
else:
for i in range(len(audiogram) - 1):
if freq >= audiogram[i + 1][0]:
continue
threshold = (audiogram[i + 1][1] - audiogram[i][1]) * \
(freq - audiogram[i][0]) / (audiogram[i + 1][0] - audiogram[i][0]) + audiogram[i][1]
break
if threshold is None:
threshold = audiogram[-1][1]
if threshold <= dB: # уровень сигнала уже в зоне слышимости
return 0.0
else: # сдвиг уровня сигнала в зону слышимости
return threshold - dB + 3
def db_to_amplitude(dB): # преобразование дБ в амлитуду
return np.power(10.0, dB / 20.0)
def amplitude_to_db(amp): # преобразование амлитуты в дБ
return 20 * np.log10(amp)
if __name__ == "__main__":
start_time = time.time()
df_1 = np.array([ # An_
[125, -48.0],
[250, -42.0],
[500, -52.0],
[1000, -36.0],
[2000, -23.0],
[4000, -29.0],
[6000, -19.0],
])
df_2 = np.array([ # Mi_
[125, -76.0],
[250, -68.0],
[500, -72.0],
[1000, -73.0],
[2000, -77.0],
[4000, -83.0],
[6000, -78.0],
])
# считывание демо-файлов
wavfiles = [
['1_demo_1_audible_normally.wav', '1_demo_2_audible_partially.wav', '1_demo_3_not_audible.wav'],
['2_demo_1_audible_normally.wav', '2_demo_2_audible_partially.wav', '2_demo_3_not_audible.wav']
]
for files, audiogram in zip(wavfiles, [df_1, df_2]):
for file in files:
file_name = file.split('.')[0]
sampleRate, samples = wavfile.read(os.path.join(os.getcwd(), 'wav_files', file), mmap=True)
outSamples = np.array([]) # набор обработанных участков для нового файла
windowSize = 512
sampleIdx = 0
while sampleIdx < len(samples):
window = samples[sampleIdx:sampleIdx + windowSize]
freq, dB = get_dominant_freq(sampleRate, window)
gain = get_gain(freq, dB, audiogram=audiogram)
startSec = np.round(sampleIdx / sampleRate, 2)
endSec = np.round((sampleIdx + windowSize) / sampleRate, 2)
if gain > 0.0:
# print(f"{file_name}\t{startSec: >6.3f}..{endSec: <6.3f}s\tGAINED\t{freq: >8.2f} Hz\tvol {dB: >6.2f} dB\tgain: {gain: >6.2f} dB")
amp = db_to_amplitude(gain)
amplified = window * amp
else:
# print(f"{file_name}\t{startSec: >6.3f}..{endSec: <6.3f}s\tSTOCK\t{freq: >8.2f} Hz\tvol {dB: >6.2f} dB\tgain: {gain: >6.2f} dB")
amplified = window
outSamples = np.append(outSamples, amplified)
sampleIdx += windowSize
processed_file = os.path.join(os.getcwd(), 'wav_files', f"{file_name}_processed.wav")
wavfile.write(processed_file, sampleRate, outSamples)
print('ready', os.path.relpath(processed_file))
print(f"{(time.time() - start_time)} seconds")
ready wav_files\1_demo_1_audible_normally_processed.wav
ready wav_files\1_demo_2_audible_partially_processed.wav
ready wav_files\1_demo_3_not_audible_processed.wav
ready wav_files\2_demo_1_audible_normally_processed.wav
ready wav_files\2_demo_2_audible_partially_processed.wav
ready wav_files\2_demo_3_not_audible_processed.wav
180.6359121799469 seconds
Всё готово! Можно послушать демки, оценить обработку, попробовать обработать реальные аудиофайлы, наконец. Результат не идеален, но вполне рабочий, демки стало слышно.
Ради интереса и объективного сравнения можно даже посмотреть файлы "до" и "после" в Praat. Становится видно изъян алгоритма: усиливаются те частоты, которые заведомо находятся в зоне слышимости и усиливаться не должны. Это особенно заметно на первой демке, которая была сгенерирована заведомо слышимой на всем частотном диапазоне:
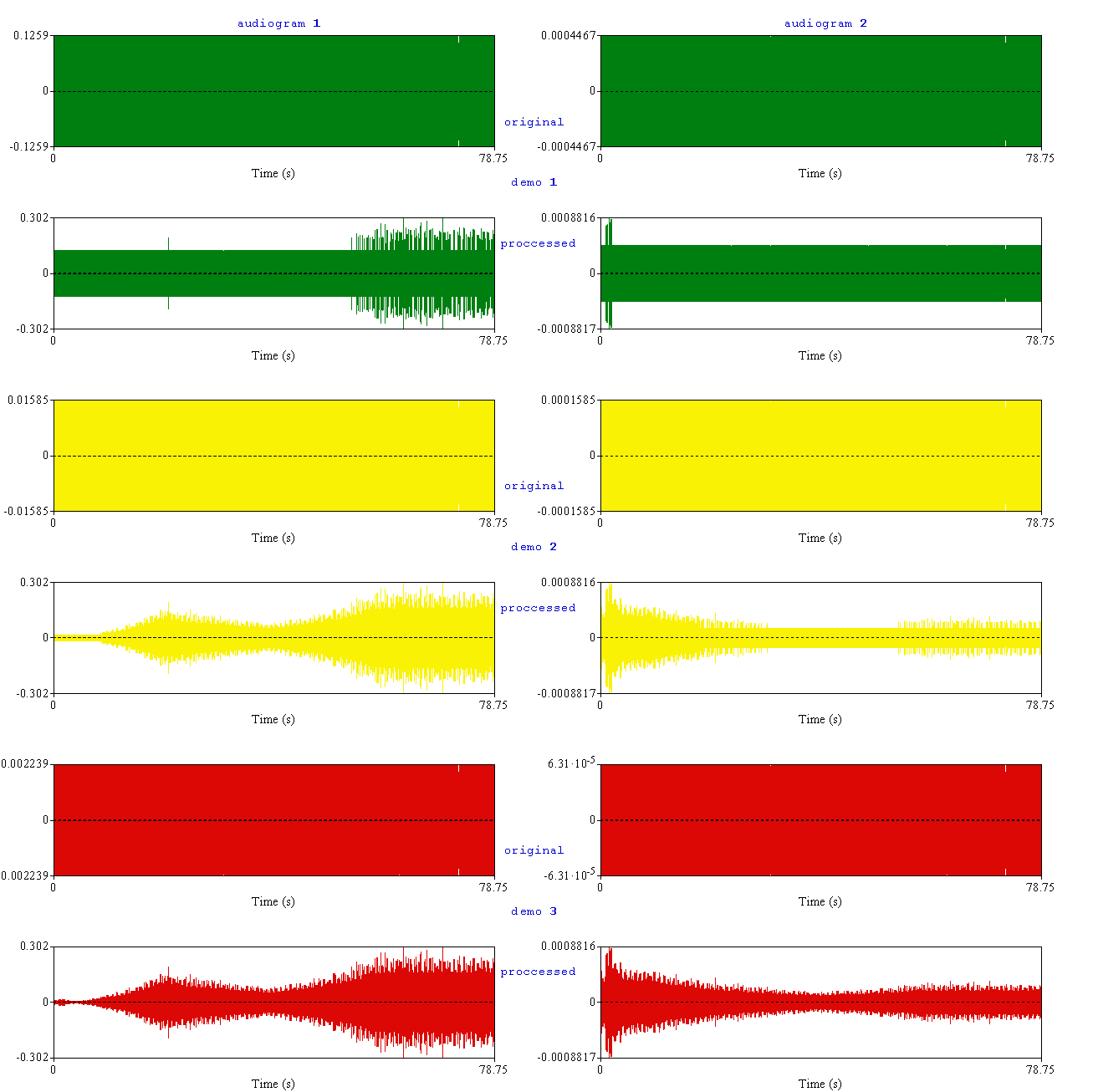
Спасибо за внимание и будьте здоровы!
Что ещё интересного есть в блоге Cloud4Y
→ Изучаем своё железо: сброс паролей BIOS на ноутбуках
→ Частые ошибки в настройках Nginx, из-за которых веб-сервер становится уязвимым
→ Хомяк торгует криптовалютой не хуже, чем трейдер
→ Облачная кухня: готовим данные для мониторинга с помощью vCloud API и скороварки
→ Эксперимент для сотрудника с нарушением слуха, ч. 1
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
