Комментарии 31
Каков должен быть поисковый запрос, чтобы увидеть в выдаче главную страницу любого популярного сайти — вики, гугла, яндекса, хабра, BBC, Apple, Microsoft, Boeing, Газпрома, Аэрофлота? Я честно больше 15 минут потратил, пытаясь это сделать, но у меня ничего не вышло… Идея интересная, но реально пользоваться пока невозможно.
Спасибо за отзыв. Скажем так, мы пока не делаем упор на главную страницу, все зависит от активности пользователей. Если 100 пользователей обсуждают сервис Аэрофлота на каком-то сайте, то эта информация будет важнее и выше 1 пользователя зашедшего на сайт Аэрофлота.
Я понимаю принцип, и я даже понимаю, почему вы хотите именно так сделать. С другой стороны, это может привести к сильной… как это назвать-то, фрагментации что-ли… выдачи. Ну например, я голоден, и хочу узнать как варить сосиски. Соответственно, я пишу в строке поиска «как варить сосиски», в надежде найти рецепт.
В это время, куча народу (например, на Хабре) обсуждает новую социальную сеть для любителей сосисок вСосисках, и я в выдаче получаю кучу ссылок на это обсуждение. И вроде бы с одной стороны это мне даже полезно, т.к. там я смогу выяснить все, что я давно хотел узнать о сосисках, но боялся спросить. Но с другой стороны, это мне сейчас совершенно не нужно, более того — тратит мое время и ставит меня под угрозу голодной смерти, т.к. все что мне нужно было узнать — это «киньте в воду, и варите пока не закипят».
Может быть вам нужно побольше настроек добавить, или еще что-то, не знаю… Кстати, если бы было много ползунков с настройками выдачи — это было бы весьма круто.
В это время, куча народу (например, на Хабре) обсуждает новую социальную сеть для любителей сосисок вСосисках, и я в выдаче получаю кучу ссылок на это обсуждение. И вроде бы с одной стороны это мне даже полезно, т.к. там я смогу выяснить все, что я давно хотел узнать о сосисках, но боялся спросить. Но с другой стороны, это мне сейчас совершенно не нужно, более того — тратит мое время и ставит меня под угрозу голодной смерти, т.к. все что мне нужно было узнать — это «киньте в воду, и варите пока не закипят».
Может быть вам нужно побольше настроек добавить, или еще что-то, не знаю… Кстати, если бы было много ползунков с настройками выдачи — это было бы весьма круто.
Да кстати, основной индекс сейчас представляет информация на английском, поиск на русском пока утруднен и печален в силу отсутствия пользователей :) Чем больше информации от пользователей мы получим — тем лучше сможем настроить поиск. Насчет примера с сосисками, в планах у нас есть добавление системы по типу категорий, предпочтений и интересов, хотя тут скорее вопрос текста запроса, ведь даже вСосисках могут присутствовать обсуждения как лучше сварить сосиски чем на том же сайте производителя (ну там пожарить может лучше, горчицы добавить, черт, пора мне на обед). Насчет настроек — думаем и работаем над этим
А не будет ли принцип "Если 100 пользователей обсуждают..." золотой жилой для черного SEO, продвижение сайтов, раскрутка Вашего сайта, попасть на первую страницу выдачи blippex бесплатно без смс?
Я пользуюсь блиппексом так (поставил экстеншн):
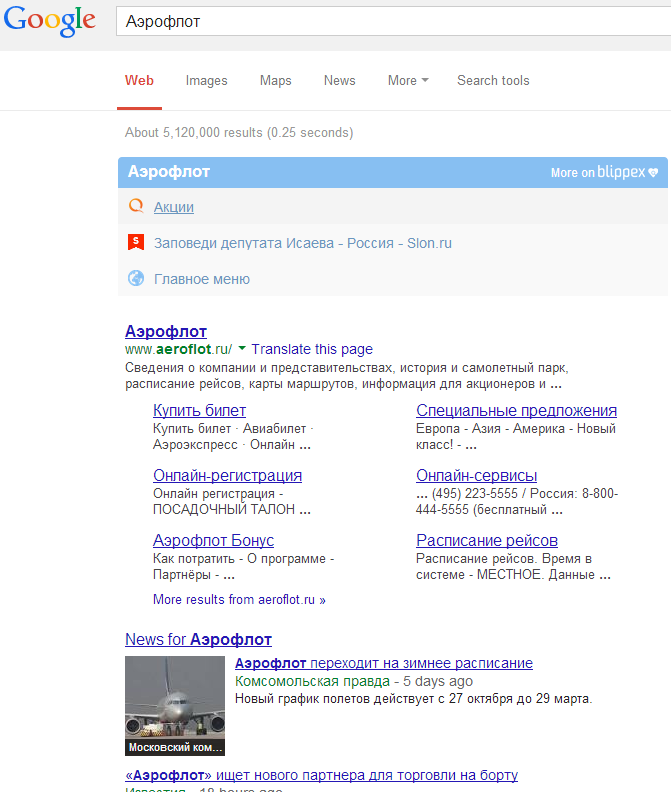
Мне нравится. )

Мне нравится. )
Что должен найти человек по запросу wikipedia? Вы предлагаете — murdos_bot? (musicbrainz.org/user/murdos_bot)
Может есть смісл приложить усилия в другом направлении?
Может есть смісл приложить усилия в другом направлении?
К сожалению мы еще не идеальны, и наверное никогда ими не будем (как впрочем и любая система), но активно стремимся к этому, работа ведется
«Не идеальны»? Вы стебетесь?
Результаты офигенно не релевантны, безумно не релевантны. Если алгоритм работает неправильно при 1000 пользователей, то почему он заработает правильно на 10 миллиардах пользователей? Если же вы все таки уверены в этом, то стоит либо самостоятельно собрать базу данных, а потом запускать проект, либо читерствовать, и использовать свой супер алгоритм для улучшенной фильтрации традиционных выдач. В данный момент вашим сервисом пользоваться вообще невозможно
Результаты офигенно не релевантны, безумно не релевантны. Если алгоритм работает неправильно при 1000 пользователей, то почему он заработает правильно на 10 миллиардах пользователей? Если же вы все таки уверены в этом, то стоит либо самостоятельно собрать базу данных, а потом запускать проект, либо читерствовать, и использовать свой супер алгоритм для улучшенной фильтрации традиционных выдач. В данный момент вашим сервисом пользоваться вообще невозможно
Если алгоритм работает неправильно при 1000 пользователей, то почему он заработает правильно на 10 миллиардах пользователей?
В силу вот этого. Далее учите матчасть и соображайте, при чём здесь это.
(На самом деле величины могут быть распределены вообще как угодно, главное, чтобы они были независимы и их было много, чем больше, тем лучше.)
поисковую информацию должны предоставлять сами пользователи
ru.wikipedia.org/wiki/Wikia_Search, прожил полтора года.
отправлять информацию о посещённых страницах
Тоже не новая история, habrahabr.ru/post/124538/
Не сказал бы, что DuckDuckGo мимикрирует под Google Search. Да, общие черты те же, но результаты обычно другие (сказывается, в частности, отсутствие персонализации). Оригинальный и быстрый Zero-Click, открытый исходный код (самого движка) — всё меня привлекает. Перешёл с Google около полугода назад и очень доволен. Теперь только изредка завершаю поисковый запрос символами !g.
И всё-таки желаю удачи. Здоровая конкуренция никогда не помешает.
И всё-таки желаю удачи. Здоровая конкуренция никогда не помешает.
Глупый вопрос сейчас задам, но любопытство перевешивает.
| "… открытый исходный код.."
Что мешает выставлять на публику «чистый» код, и параллельно использовать его имитацию с темными фичами в самом продукте? Чем выступает гарант, ограждающий от подобной махинации?
| "… открытый исходный код.."
Что мешает выставлять на публику «чистый» код, и параллельно использовать его имитацию с темными фичами в самом продукте? Чем выступает гарант, ограждающий от подобной махинации?
Последнее предложение вернее выстроить так: «Что выступает гарантом, ограждающим от подобной махинации?»
Конечно же, гарантии не даст никто. С другой стороны, есть API для создания плагинов. Можно с их помощью попытаться исследовать внутренности системы. Хотя и здесь может быть западня в хитром построении API или перехвате «неудобных» вызовов. В остальном согласен — в web быть в чём-то уверенным сложно. Доверие возникает, потому что считаешь реализацию таких лазеек излишне сложной.
Интересно, возможно ли применить нечто вроде алгоритмов zero knowledge для доказательства того, что система соответствует исходному коду…
Интересно, возможно ли применить нечто вроде алгоритмов zero knowledge для доказательства того, что система соответствует исходному коду…
Возможность сборки приложения из «чистого» исходного кода.
Мда. Где гарантия что ваш компилятор/линкер (который вы по-любому скачали из интернета в бинарном виде — вы не могли построить компилятор без компилятора) не добавит закладку при сборке?
Решение есть
Строим комплиятор двумя разными другими комплияторами и сравниваем.
который вы по-любому скачали из интернета в бинарном виде
Была статья по этому поводу. и там предложили собрать свой компилятор. Далее с помощью своего кривого компилятора компилируем из исходников тот же gcc. Чем не вариант?
баг решения
А где гарантия что и они без закладок(одинаковых)? Ах да и о закладках в процессоре не забудьте.
Строим комплиятор двумя разными другими комплияторами и сравниваем.
А где гарантия что и они без закладок(одинаковых)? Ах да и о закладках в процессоре не забудьте.
Ну я собственно из этой статьи и взял собственно идею. Но как я вижу, вы её читали, так что ничего нового.
Если есть закладки в процессоре (ну или ещё где-то в аппаратуре), то какая нам разница, есть ли они в софте? ;)
Если есть закладки в процессоре (ну или ещё где-то в аппаратуре), то какая нам разница, есть ли они в софте? ;)
На счет закладок в аппаратуре с вами полностью согласен.
Кстати, для «не параноиков» — годика два назад познакомился с интересным на вид вирусом: ничего предосудительного, программка как программка. Его даже антивирусы не ловили, определенное время, и эвристика не спасала. Работа его заключалась в модификации всего нескольких файликов — да же не бинарников, а *.pas. Что делало компилятор Delphi 7 просто таки фабрикой троянов.
Так что проблема доверенного компилятора — не так далека от реальности, как это может показаться на первый взгляд. Да и следить за его «чистотой» и «девственностью» его стандартных библиотек то же необходимо.
Кстати, для «не параноиков» — годика два назад познакомился с интересным на вид вирусом: ничего предосудительного, программка как программка. Его даже антивирусы не ловили, определенное время, и эвристика не спасала. Работа его заключалась в модификации всего нескольких файликов — да же не бинарников, а *.pas. Что делало компилятор Delphi 7 просто таки фабрикой троянов.
Так что проблема доверенного компилятора — не так далека от реальности, как это может показаться на первый взгляд. Да и следить за его «чистотой» и «девственностью» его стандартных библиотек то же необходимо.
Я в детстве в школе писал похожую штуку для BP7. Модификация файлов заключалась в добавлении к Uses модуля PasVirus. Ещё копировался файл TPU и PAS. Если память не изменяет, TPU-файл при создании был объявлен с большим куском, заполненным нулями, а после компиляции TPU туда помещалась копия исходника pasvirus.pas (не помню, зачем pas был нужен). Всё интересное происходило в секции инициализации модуля (begin-end).
Конечно, всё это было примитивно, но работало :)
Конечно, всё это было примитивно, но работало :)
Когда открываешь окошко расширения, неплохо бы, чтоб курсор сразу в строку поиска прыгал.
Мы считаем, что количество времени, потраченного на просмотр определенной страницы или сайта является хорошим показателем важности и релевантности информации.
Не боитесь, что у вас в топе всегда будут ВКонтакте и Одноклассники?
НЛО прилетело и опубликовало эту надпись здесь
TypeError: Property 'scrollTo' of object [object global] is not a function
at Object.$scope.changeit (https://www.blippex.org/js/script.js:257:24)
at https://www.blippex.org/js/angular.min.js:74:98
at Object.e.$eval (https://www.blippex.org/js/angular.min.js:92:272)
at Object.e.$apply (https://www.blippex.org/js/angular.min.js:92:379)
at HTMLFormElement.<anonymous> (https://www.blippex.org/js/angular.min.js:156:220)
at https://www.blippex.org/js/angular.min.js:24:49
at Array.forEach (native)
at n (https://www.blippex.org/js/angular.min.js:6:470)
at HTMLFormElement.c (https://www.blippex.org/js/angular.min.js:24:20)
Это я попытался поискать Amsterdam. Ничего не произошло, тогда полез в консоль.
OS X, Chrome 30.0.1599.101
И Яндекс и Гугл давно уже используют анализ поведения пользователей, в частности, заход на сайты и время, проведенное на отдельных страницах для ранжирования результатов. Инструменты для этого — браузеры Хром и Яндекс, Я.Элементы.
Чем Ваш подход лучше?
Чем Ваш подход лучше?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Blippex — википедия поиска