 В последнее время в сети часто пишут про clustered index в InnoDB и таблицах MySQL, но, несмотря на это, на практике используют довольно редко.
В последнее время в сети часто пишут про clustered index в InnoDB и таблицах MySQL, но, несмотря на это, на практике используют довольно редко.В данной статье мы покажем на двух реальных примерах, как мы оптимизировали достаточно сложные системы Badoo, основываясь на понимании принципов работы clustered index.
Clustered index – форма организации таблицы в файле. В InnoDB данные хранятся в дереве, в таком же, в котором лежат обычные B-TREE ключи. Таблица InnoDB сама по себе уже является большим B-TREE. В качестве значений ключа используется clustered index. Согласно документации, в качестве clustered index выбирается PRIMARY KEY. Если PRIMARY KEY отсутствует – выбирается первый UNIQUE KEY. Если и такого нет, то используется внутренний 6-тибайтный код.
Что же вытекает из такой организации данных на диске?
- Вставка в середину таблицы может быть медленной из-за того, что надо перестраивать ключ.
- Обновление значения clustered index у строки приводит к физическому переносу информации на диске или к ее фрагментации.
- Необходимость использовать постоянно увеличивающееся значение clustered index для быстрой вставки в таблицу. Наиболее оптимальным будет автоинкрементное поле.
- Каждая строка имеет уникальный идентификатор-значение clustered index.
- Вторичные ключи просто ссылаются на эти уникальные идентификаторы.
- Фактически, вторичный ключ вида KEY `key` (a,b,c) будет иметь структуру KEY `key` (a,b,c,clustered_index).
- Данные на диске упорядочены по clustered index (мы не рассматриваем пример с SSD).
Мы же расскажем о двух видах оптимизации, которые помогли значительно ускорить работу наших скриптов.
Тестовое окружение
Чтобы уменьшить влияние кэширования на результаты исследования, добавим SQL_NO_CACHE к выборкам, а также будем сбрасывать кэш файловой системы перед каждым запросом. И, т.к. нас интересует худший случай, когда данные надо фактически вытягивать с диска, мы будем перезапускать MySQL перед каждым запросом.
Оборудование:
- Intel® Pentium® Dual CPU E2180 @ 2.00GHz
- RAM DIMM 800 MHz 4Gb
- Ubuntu 11.04
- MySQL 5.5
- HDD Hitachi HDS72161
Оптимизация глубоких offset-ов
Для примера возьмем абстрактную таблицу messages, в которой содержится пользовательская переписка.
CREATE TABLE messages (
message_id int not null auto_increment,
user1 int not null,
user2 int not null,
ts timestamp not null default current_timestamp,
body longtext not null,
PRIMARY KEY (message_id),
KEY (user1, user2, ts)
) ENGINE=InnoDBРассмотрим эту таблицу в свете перечисленных особенностей InnoDB.
Clustered index здесь совпадает с PRIMARY KEY и является автоинкрементным полем. Каждая строка имеет 4-хбайтный идентификатор. Вставка новых строк в таблицу оптимальна. Вторичный ключ на самом деле KEY (user1, user2, ts, message_id), и мы это будем использовать.
Добавим в нашу таблицу 100 миллионов сообщений. Этого вполне достаточно, чтобы выявить нужные особенности InnoDB. Пользователей в нашей системе всего 10, таким образом, у каждой пары собеседников будет в среднем по миллиону сообщений.
Предположим, что эти 10 тестовых пользователей обменялись множеством сообщений и часто перечитывают давнюю переписку – интерфейс позволяет переключиться на страницу с очень старыми сообщениями. А за этим интерфейсом стоит простой запрос:
SELECT * FROM messages WHERE user1=1 and user2=2 order by ts limit 20 offset PageNumber*20 Самый обычный, по сути, запрос. Посмотрим же на время его исполнения в зависимости от глубины offset:
| offset | execution time (ms) |
|---|---|
| 100 | 311 |
| 1000 | 907 |
| 5000 | 3372 |
| 10000 | 6176 |
| 20000 | 11901 |
| 30000 | 17057 |
| 40000 | 21997 |
| 50000 | 28268 |
| 60000 | 32805 |
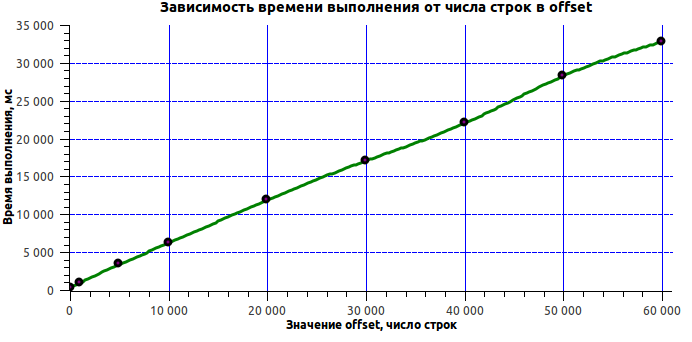
Наверняка многие ожидали увидеть линейный рост. Но получить 33 секунды на 60 тысячах записей – это слишком! Объяснить, на что уходит столько времени, довольно просто – стоит лишь упомянуть об одной из особенностей реализации MySQL. Дело в том, что MySQL для выполнения этого запроса вычитывает offset + limit строк с диска и из них возвращает limit. Теперь ситуация понятна: всё это время MySQL занимался вычитыванием с диска 60 тысяч не нужных нам строк. Что же делать в подобной ситуации? Напрашивается множество различных вариантов решения. Вот, кстати, интересная статья об этих вариантах.
Мы же нашли очень простое решение: первым запросом выбрали только значения clustered index, а затем выбирали исключительно из них. Нам известно, что на конце вторичного ключа пристутствует значение clustered index, поэтому, если заменить в запросе * на message_id, то получаем запрос, работающий только по ключу, соотвественно, скорость такого запроса высока.
Было:
mysql> explain select * from messages where user1=1 and user2=2 order by ts limit 20 offset 20000; +----+-------------+----------+------+---------------+-------+---------+-------------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+-------+---------+-------------+--------+-------------+ | 1 | SIMPLE | messages | ref | user1 | user1 | 8 | const,const | 210122 | Using where | +----+-------------+----------+------+---------------+-------+---------+-------------+--------+-------------+ 1 row in set (0.00 sec)
Стало:
mysql> explain select message_id from messages where user1=1 and user2=2 order by ts limit 20 offset 20000; +----+-------------+----------+------+---------------+-------+---------+-------------+--------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+-------+---------+-------------+--------+--------------------------+ | 1 | SIMPLE | messages | ref | user1 | user1 | 8 | const,const | 210122 | Using where; Using index | +----+-------------+----------+------+---------------+-------+---------+-------------+--------+--------------------------+ 1 row in set (0.00 sec)
Using index в данном случае означает, что MySQL сможет получить все данные из вторичного ключа, и не будет обращаться к clustered index. Подробнее об этом можно узнать здесь.
А теперь лишь остаётся извлечь непосредственно значения строк запросом
SELECT * FROM messages WHERE message_id IN (....) Посмотрим, насколько производительнее это решение:
| offset | execution time (ms) |
|---|---|
| 100 | 243 |
| 1000 | 164 |
| 5000 | 213 |
| 10000 | 337 |
| 20000 | 618 |
| 30000 | 756 |
| 40000 | 971 |
| 50000 | 1225 |
| 60000 | 1477 |
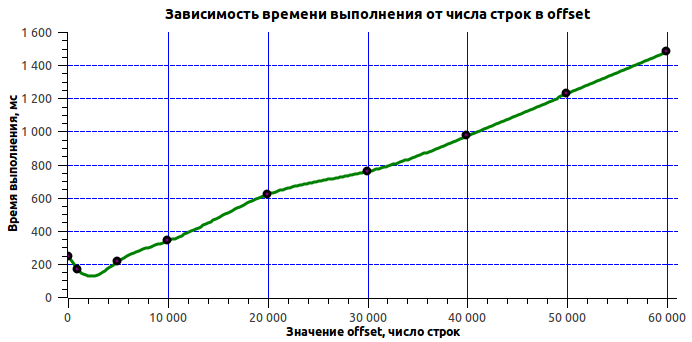
Достигнутый результат устроил всех, потому дальнейшие поиски было решено не проводить. К тому же неизвестно, возможно ли принципиально быстрее обращаться к этим данным, не меняя саму процедуру работы с историей. Следует отметить еще раз, что стояла задача оптимизировать конкретный запрос, а не саму структуру данных.
Оптимизация процедуры обновления большой таблицы
Вторая необходимость в оптимизации возникла, когда нам понадобилось раз в сутки собирать актуальные данные о наших пользователях в одной большой таблице. Пользователей у нас к тому моменту насчитывалось 130 миллионов. Скрипт, обходящий все наши базы и собирающий новые данные, отрабатывает за полчаса и выбирает 30 миллионов изменившихся строк. Результат работы скрипта – десятки тысяч текстовых файлов с сериализованными новыми значениями на жёстком диске. В каждом файле содержится информация о сотнях пользователей.
Переносим информацию из этих текстовых файлов в базу данных. Читаем файлы последовательно, группируем строки в пачки по несколько тысяч и обновляем. Время выполнения скрипта колеблется от 3-х до 20-ти часов. Естественно, такое поведение скрипта неприемлемо. Более того, очевидно, что процесс необходимо оптимизировать.
Первое, на что пало подозрение – «паразитная» нагрузка на диск сервера БД. Но многочисленные наблюдения не выявили подтверждений этой гипотезы. Мы пришли к выводу, что проблема скрывается в недрах БД и надо думать, как это исправить. Как данные лежат на диске? Что приходится делать ОС, MySQL и оборудованию, чтобы обновить эти данные? Пока мы отвечали на эти вопросы, заметили, что данные обновляются в том же порядке, в котором их собрали. А это значит, что каждый запрос обновляет совершенно случайное место в этой большой таблице, что влечет за собой потерю времени на позиционирование головок диска, потерю кэша файловой системы и потерю кэша базы данных.
Отметим, что процесс обновления каждой строки в MySQL состоит из трёх этапов: вычитка значений, сравнение старого и нового значения, запись значения. Это можно увидеть даже из того, что в результате запроса MySQL отвечает, сколько строк совпало и сколько действительно обновилось.
Затем мы посмотрели, сколько строк реально изменяется в таблице. Из 30-ти миллионов строк изменились только 3 миллиона (что логично, т.к. таблица содержит весьма урезанную информацию о пользователях). А это означает, что 90% времени MySQL тратит именно на вычитку, а не на обновление. Решение пришло самой собой: следует проверить, насколько проигрывает случайный доступ к clustered index последовательному. Результат можно будет обобщить и в случае обновления таблицы (перед её обновлением всё равно происходит вычитка и сравнение).
Методика предельно проста – измерить разницу в скорости выполнения запроса
SELECT * FROM messages where message_id in ($values)где в качестве values передавать массив из 10К элементов. Значения элементов сделать совершенно случайными для проверки случайного доступа. Для тестирования последовательного доступа надо сделать последовательно 10К элементов, начиная с некоего случайного смещения.
function getValuesForRandomAccess(){
$arr = array();
foreach(range(1, 10000) as $i){
$arr[] = rand(1,100000000);
}
return $arr;
}
function getValuesForSequencialAccess(){
$r = rand(1, 100000000-10000);
return range($r, $r+10000);
} Время выполнения запроса со случайным доступом и последовательным:
| N | random | sequential |
|---|---|---|
| 1 | 38494 | 171 |
| 2 | 40409 | 141 |
| 3 | 40868 | 147 |
| 4 | 37161 | 138 |
| 5 | 38189 | 137 |
| 6 | 36930 | 134 |
| 7 | 37398 | 176 |
| 8 | 38035 | 144 |
| 9 | 39722 | 140 |
| 10 | 40720 | 146 |
Как видим, разница во времени выполнения – 200 раз. Следовательно, за это надо бороться. Чтобы оптимизировать выполнение, надо отсортировать исходные данные по первичному ключу. Можем ли мы достаточно быстро отсортировать 30 миллионов значений в файлах? Ответ однозначный – можем!
После проведения этой оптимизации время работы скрипта сократилось до 2,5 часов. На предварительную сортировку 30-ти миллионов строк уходит 30 минут (и большую часть времени занимает gzip).
Та же самая оптимизация, но на SSD
Уже после написания статьи у нас нашёлся один лишний SSD, на котором мы также провели тестирование.
Выборка с глубоким offset-ом:
| offset | execution time (ms) |
|---|---|
| 100 | 117 |
| 1000 | 406 |
| 5000 | 1681 |
| 10000 | 3322 |
| 20000 | 6561 |
| 30000 | 9754 |
| 40000 | 13039 |
| 50000 | 16293 |
| 60000 | 19472 |
Оптимизированная выборка с глубоким offset-ом:
| offset | execution time (ms) |
|---|---|
| 100 | 101 |
| 1000 | 21 |
| 5000 | 24 |
| 10000 | 32 |
| 20000 | 47 |
| 30000 | 94 |
| 40000 | 84 |
| 50000 | 95 |
| 60000 | 120 |
Сравнение случайного и последовательного доступа:
| N | random | sequential |
|---|---|---|
| 1 | 5321 | 118 |
| 2 | 5583 | 118 |
| 3 | 5881 | 117 |
| 4 | 6167 | 117 |
| 5 | 6349 | 120 |
| 6 | 6402 | 126 |
| 7 | 6516 | 125 |
| 8 | 6342 | 124 |
| 9 | 6092 | 118 |
| 10 | 5986 | 120 |
Эти цифры показывают, что SSD, конечно, имеет преимущество перед обычным диском, однако его использование не отменяет необходимости оптимизации.
И в заключение нашей статьи мы можем сказать, что нам удалось увеличить скорость выборки данных в 20 раз. Мы ускорили фактическое обновление таблицы до 10 раз (суррогатный тест ускорили в 200 раз). Напомним, что опыты проводились на системе с отключенным кэшированием. Прирост на реальной системе оказался менее впечатляющим (кэш всё-таки неплохо исправляет ситуацию).
Вывод из вышеизложенного лежит на поверхности: мало знать сильные и слабые стороны ПО, с которым вы работаете, важно уметь применять эти знания на практике. Знание внутреннего устройства MySQL иногда позволяет ускорять запросы в десятки раз.
Алексей alexxz Еремихин, разработчик Badoo
